
零代码打造“智能健身助手“:我的 Nexent 智能体构建全流程实录
作为一名想要保持健康生活方式的上班族,我有一个困扰已久的痛点:健身知识太碎片化了。网上关于健身的信息铺天盖地——有的说空腹运动好,有的说饭后运动好;有的说要做有氧,有的说力量训练更重要......各种说法五花八门,不知道该信谁。
一、前言:为什么我要做一个智能健身助手
作为一名想要保持健康生活方式的上班族,我有一个困扰已久的痛点:健身知识太碎片化了。网上关于健身的信息铺天盖地——有的说空腹运动好,有的说饭后运动好;有的说要做有氧,有的说力量训练更重要......各种说法五花八门,不知道该信谁。
而且我的健身资料散落在各种地方——收藏的健身文章、教练发的训练计划、APP里的运动记录......想系统复习某个动作要领时,经常要翻好几个地方。
几周前朋友向我推荐了 Nexent 智能体平台,说是可以直接用自然语言描述需求,自动生成智能体,不需要写代码。这一听就戳中了我的痛点——我想要的就是一个能帮我:
- 整合所有健身知识
- 根据我的身体状况制定训练计划
- 解答健身相关问题
- 能联网搜索最新健身资讯的
智能健身助手
于是,我花了一个周末,泡在 Nexent 平台里,从零开始构建了这个智能体。整个过程有惊喜也有踩坑,想把这些第一手的实操感受完整记录下来。
二、初识 Nexent:平台概览
打开 Nexent 首页,界面设计简洁清爽。左侧导航栏的功能分区很清晰:
- 模型管理:接入各类AI模型
- 知识库:上传和管理文档资料
- MCP 工具:接入外部工具和能力
- 智能体开发:核心功能,创建和配置智能体
- 智能体市场:浏览和使用他人分享的智能体
- 记忆管理:配置跨对话记忆能力
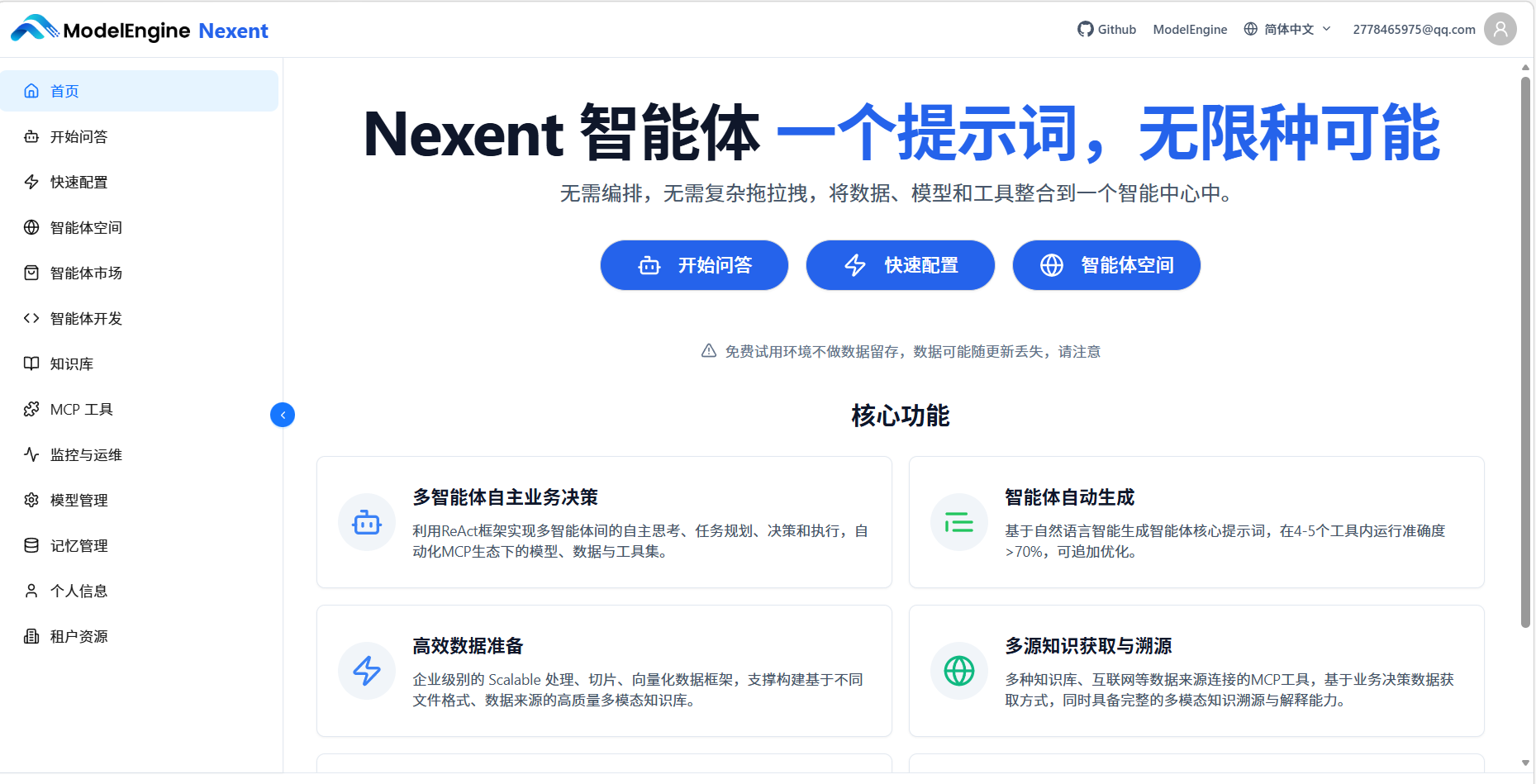
平台提供了"快速配置"入口,会引导用户按顺序完成模型、知识库和智能体的设置。这个引导设计对新手非常友好。
三、模型接入:批量导入与单个配置
3.1 单个模型添加
进入"模型管理"页面,点击"添加模型",填写模型名称、API URL、API Key 等信息。
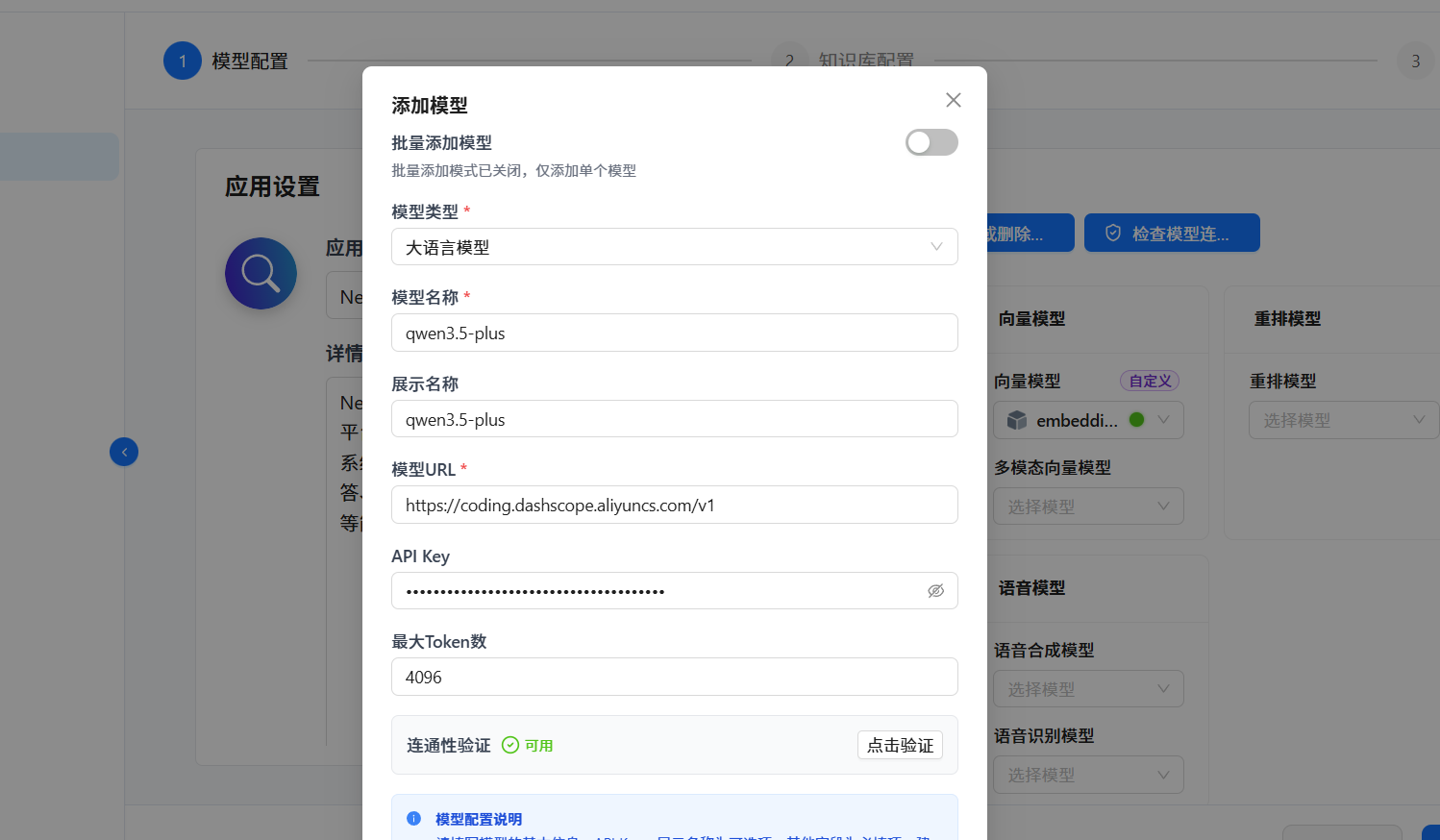
填完之后点击"连通性验证",显示"连接成功"即可。
3.2 批量导入
我想同时接入多个模型做对比,逐个填写太低效。批量导入功能可以填入 API URL 和 Key,点击"拉取模型列表",系统自动枚举该供应商下的全部可用模型。

这种方式省了大量重复操作,一次性导入了多个模型,整个过程不到 2 分钟。
3.3 配置系统模型
接完模型后配置"系统模型",我的配置:
- 基础模型(LLM):qwen3.5-plus
- 向量模型(Embedding):智谱 embedding-2
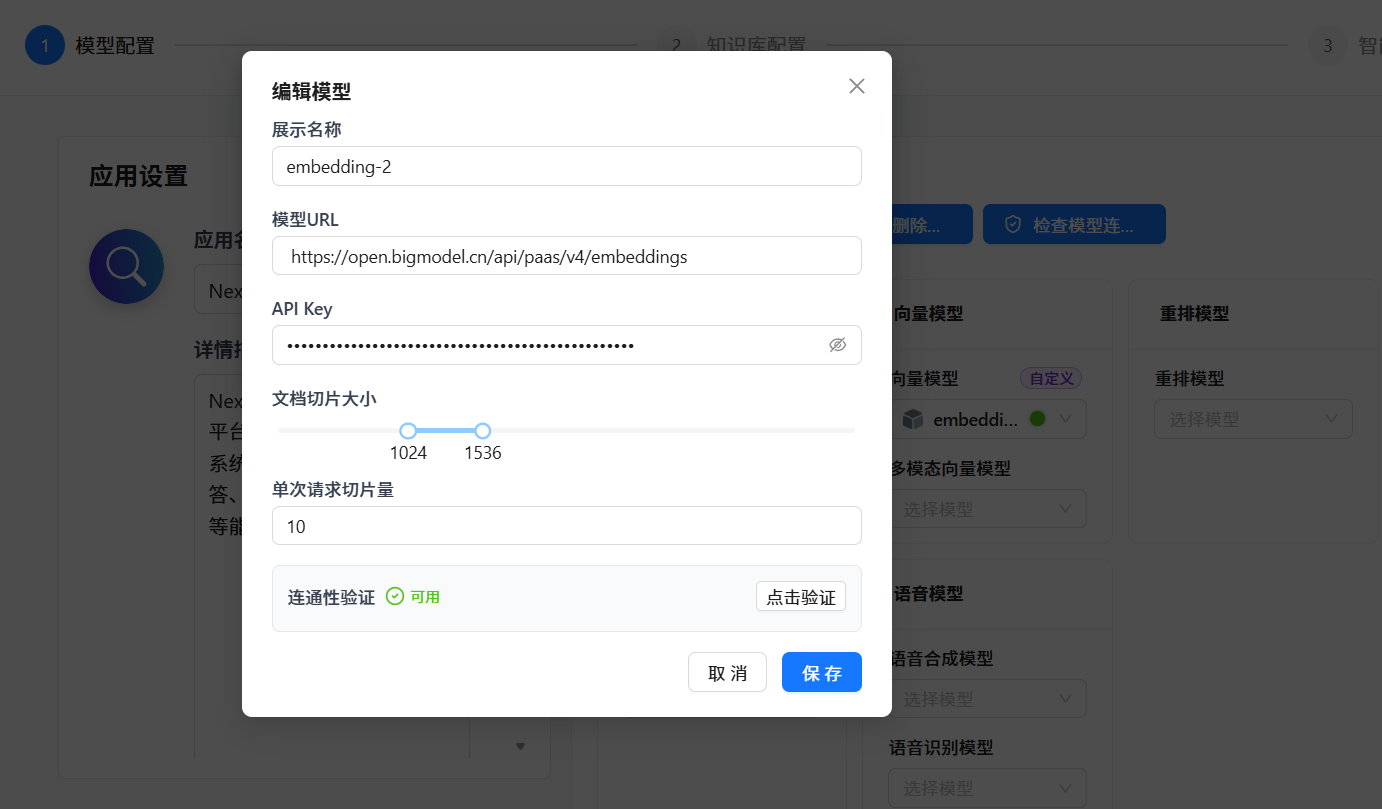
⚠️ 踩坑:向量模型我一开始用硅基流动一直配不通,后来换成智谱AI才成功。
四、知识库配置:健身知识整理
我的场景里有三份文档需要让智能体参考:
- 健身基础知识手册(Markdown 格式,整理了常见健身知识)
- 一周健身计划表(包含每天的训练安排)
- 健身动作要领
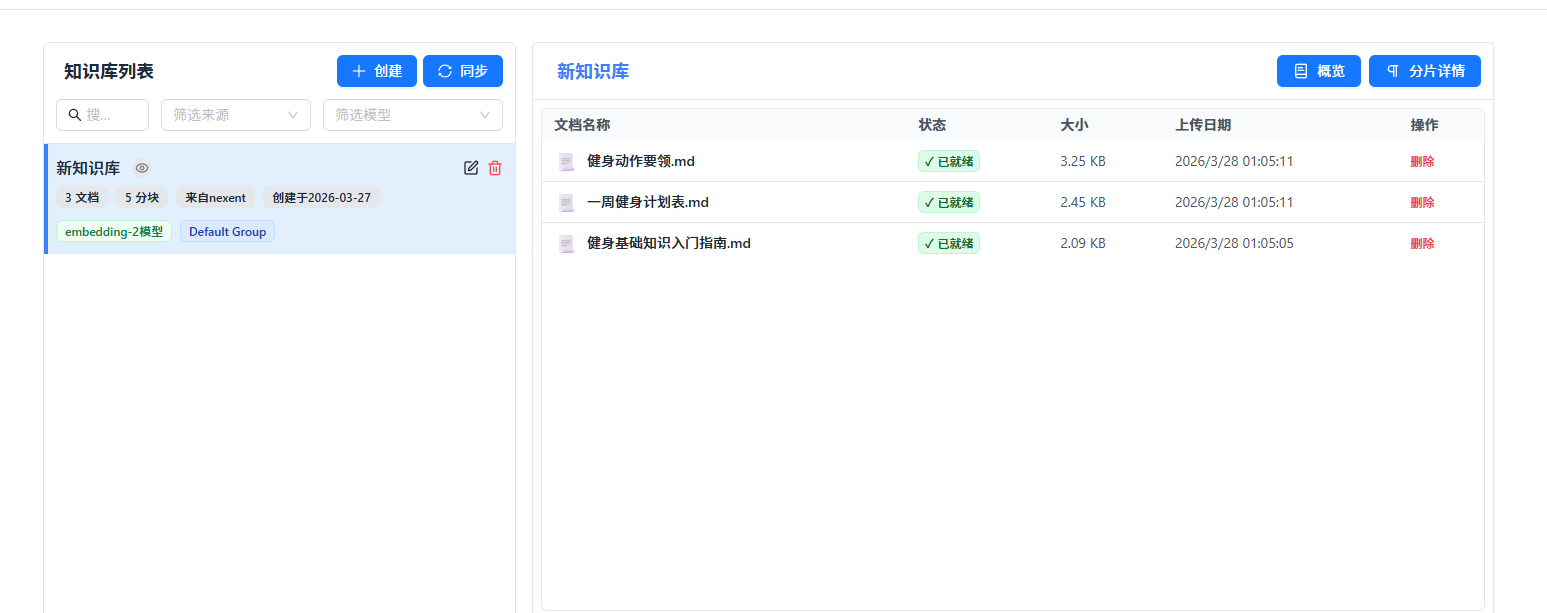
4.1 上传文档
在"知识库配置"模块,点击"新建知识库",将三份文档直接拖入上传区。平台自动解析和入库,状态依次显示为:解析中 → 入库中 → 已就绪。
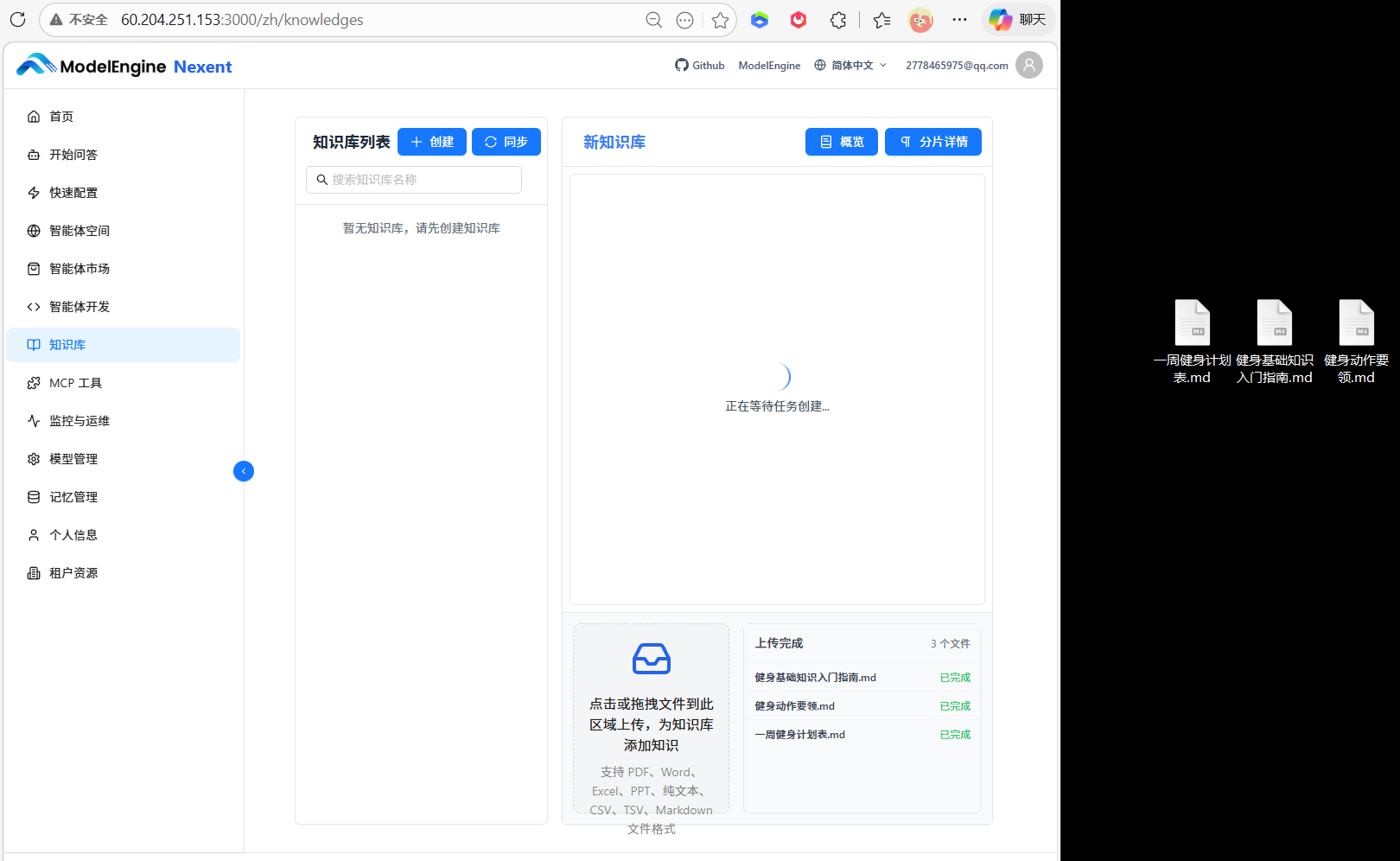
Markdown处理速度很快,不到 10 秒进入就绪。
- 这里我们使用大模型进行一键总结
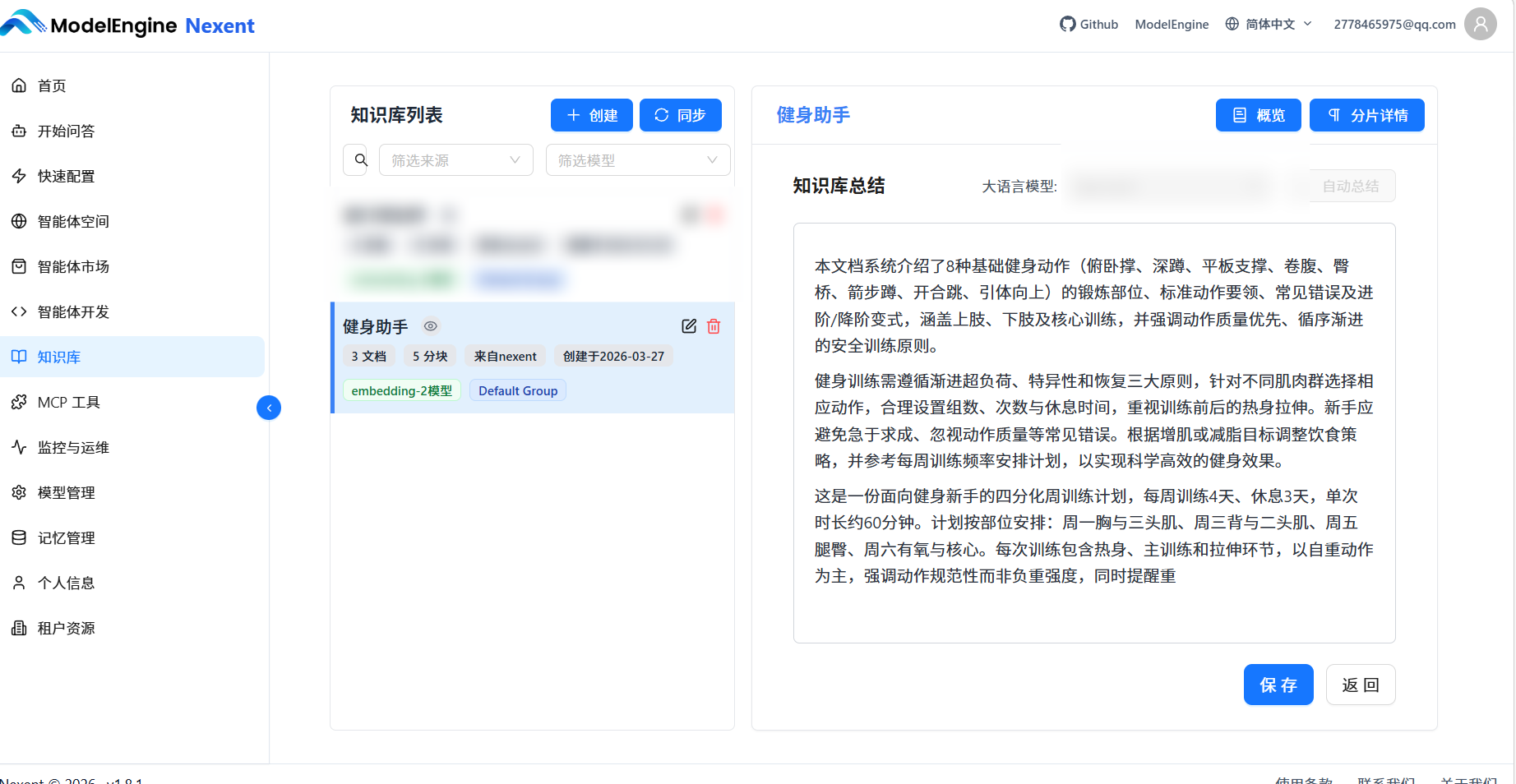
总结后保存即可!
五、MCP 工具接入:二种方式实践
5.1 方式一:通过 URL 接入(推荐新手)
- 由于Nexent的MCP的工具在开发中,我们就可以从其他地方先选择工具
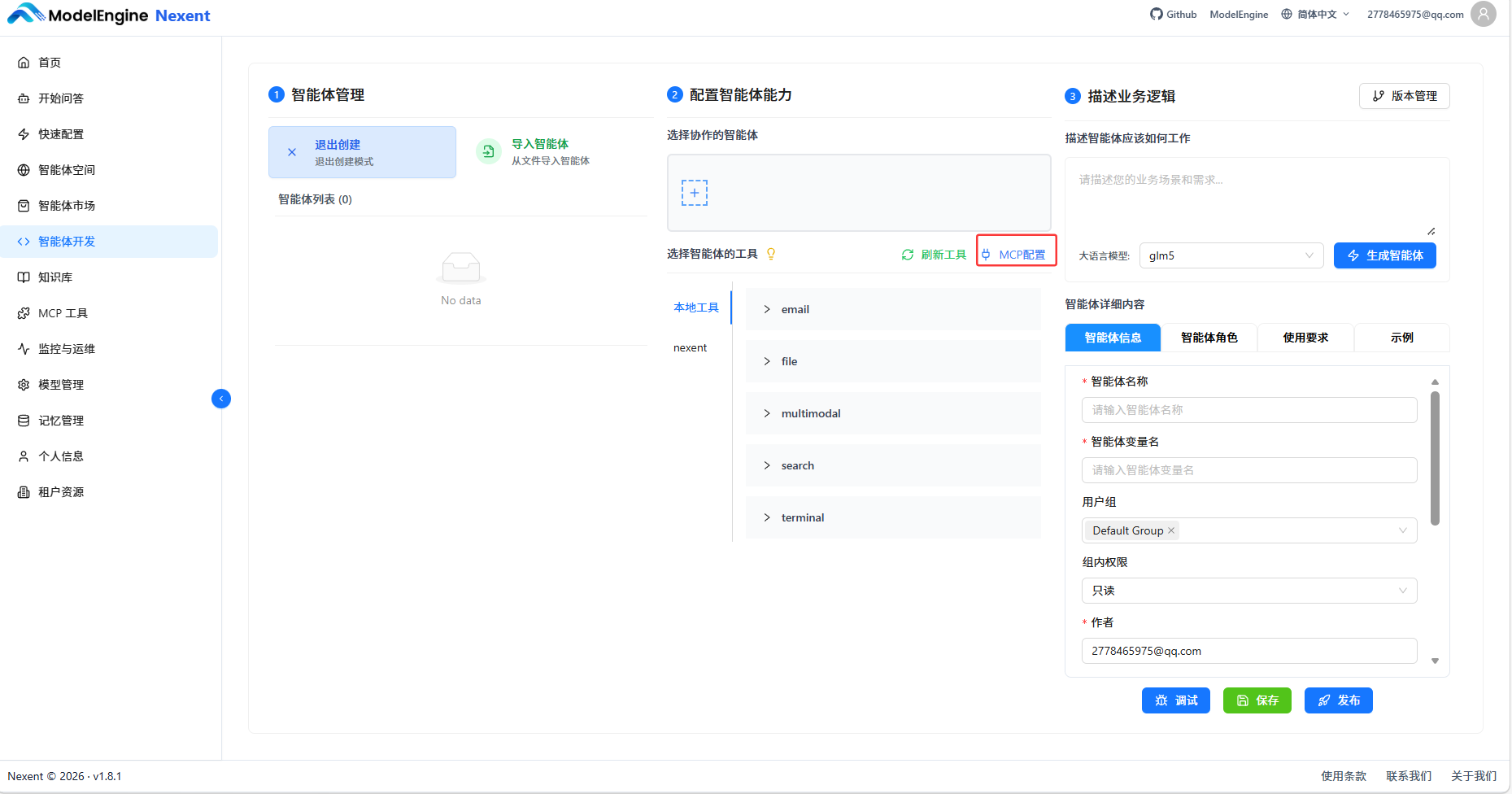
- 我直接去 ModelScope MCP 广场 找现成的工具。登录后获取专属 SSE 地址。(由于目前其广场没有很明确的健身MCP,但是我找到了一个很好的天气查询,可以用来室外健身时的健身状况)
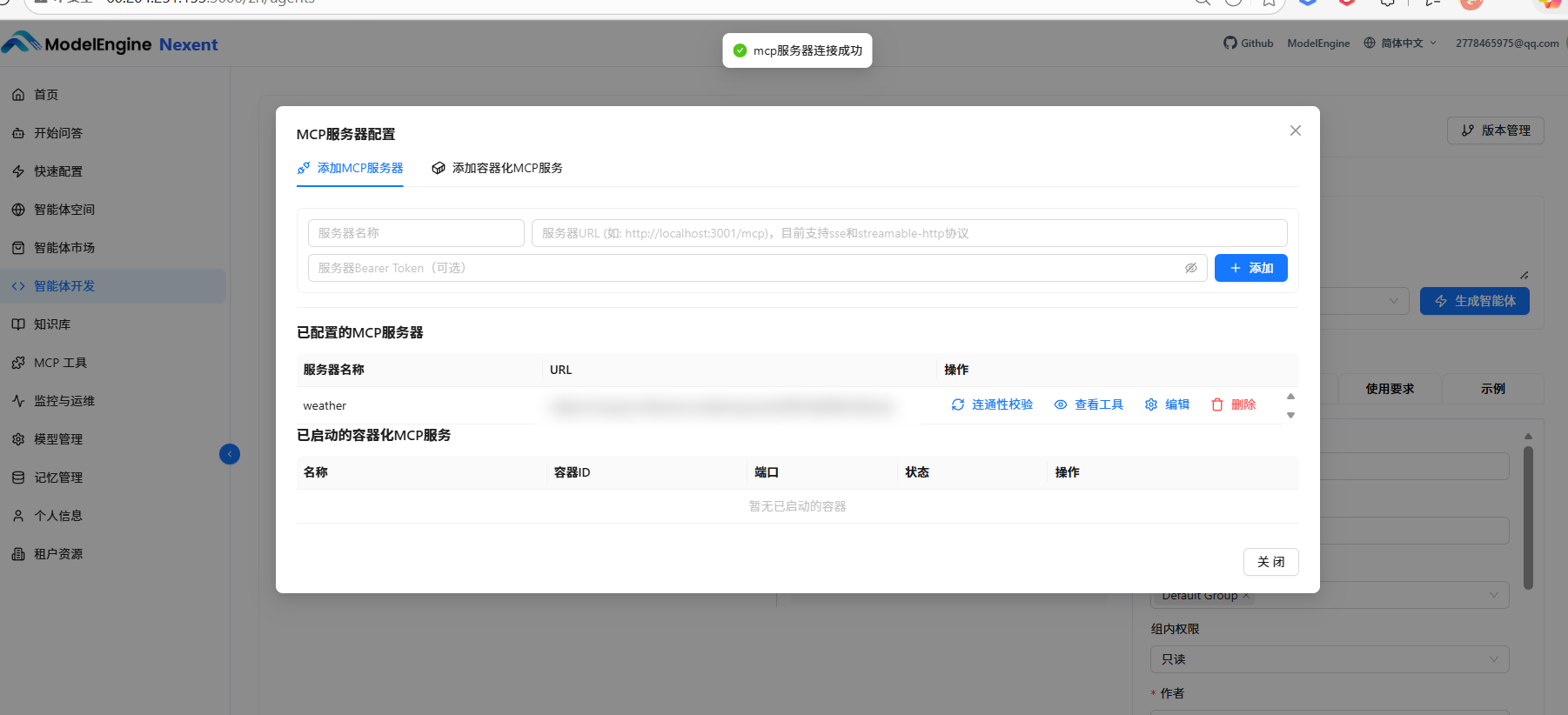
⚠️ 踩坑:服务器名称只能用英文字母和数字,不能有下划线。
5.2 方式二:自己开发 MCP 服务
我开发了一个简单的"健身记录" MCP 服务,可以记录用户的训练数据。用 Python 编写后启动,在 Nexent 中配置 Stdio 传输类型。这是最灵活的方式,可以根据需求定制工具。
from mcp.server import Server
from mcp.server.stdio import stdio_server
from mcp.types import Tool, TextContent
import json
from datetime import datetime
# 创建服务器
server = Server("fitness-record")
# 存储健身记录(简单的内存存储)
fitness_records = []
@server.list_tools()
async def list_tools():
"""列出所有可用工具"""
return [
Tool(
name="record_workout",
description="记录一次健身训练",
inputSchema={
"type": "object",
"properties": {
"exercise": {
"type": "string",
"description": "运动名称,如:深蹲、俯卧撑、跑步"
},
"sets": {
"type": "integer",
"description": "组数"
},
"reps": {
"type": "integer",
"description": "每组次数"
},
"duration": {
"type": "string",
"description": "时长,如:30分钟"
},
"notes": {
"type": "string",
"description": "备注"
}
},
"required": ["exercise"]
}
),
Tool(
name="get_records",
description="获取健身记录",
inputSchema={
"type": "object",
"properties": {
"date": {
"type": "string",
"description": "日期筛选,格式:YYYY-MM-DD,不填则返回全部"
}
}
}
),
Tool(
name="get_summary",
description="获取健身统计摘要",
inputSchema={
"type": "object",
"properties": {}
}
)
]
@server.call_tool()
async def call_tool(name: str, arguments: dict):
"""执行工具"""
if name == "record_workout":
# 记录健身数据
record = {
"date": datetime.now().strftime("%Y-%m-%d"),
"time": datetime.now().strftime("%H:%M:%S"),
"exercise": arguments.get("exercise"),
"sets": arguments.get("sets", 0),
"reps": arguments.get("reps", 0),
"duration": arguments.get("duration", ""),
"notes": arguments.get("notes", "")
}
fitness_records.append(record)
result = f"✅ 记录成功!\n"
result += f"运动:{record['exercise']}\n"
if record['sets']:
result += f"组数:{record['sets']}组\n"
if record['reps']:
result += f"次数:{record['reps']}次/组\n"
if record['duration']:
result += f"时长:{record['duration']}\n"
result += f"时间:{record['date']} {record['time']}"
return [TextContent(type="text", text=result)]
elif name == "get_records":
# 获取记录
date_filter = arguments.get("date", "")
if date_filter:
filtered = [r for r in fitness_records if r["date"] == date_filter]
records = filtered
else:
records = fitness_records
if not records:
return [TextContent(type="text", text="暂无健身记录")]
result = "📋 健身记录:\n\n"
for r in records:
result += f"【{r['date']} {r['time']}】\n"
result += f"运动:{r['exercise']}\n"
if r['sets']:
result += f"组数:{r['sets']}组 × {r['reps']}次\n"
if r['duration']:
result += f"时长:{r['duration']}\n"
result += "\n"
return [TextContent(type="text", text=result)]
elif name == "get_summary":
# 统计摘要
if not fitness_records:
return [TextContent(type="text", text="暂无健身记录,开始你的第一次训练吧!")]
total_count = len(fitness_records)
exercises = {}
for r in fitness_records:
ex = r["exercise"]
exercises[ex] = exercises.get(ex, 0) + 1
result = f"📊 健身统计摘要\n\n"
result += f"总训练次数:{total_count}次\n\n"
result += f"各运动统计:\n"
for ex, count in exercises.items():
result += f"• {ex}:{count}次\n"
return [TextContent(type="text", text=result)]
return [TextContent(type="text", text="未知工具")]
async def main():
"""启动服务器"""
async with stdio_server() as (read_stream, write_stream):
await server.run(
read_stream,
write_stream,
server.create_initialization_options()
)
if __name__ == "__main__":
import asyncio
asyncio.run(main())六、智能体开发:从描述到发布
6.1 创建与配置
点击"新建智能体",命名为"智能健身助手"。配置界面包括:
- 基础设置:名称、描述
- 模型选择:选择对话模型
- 工具选择:从 MCP 工具中选择
- 知识库关联:选择知识库
- 助手协作:选择其他智能体协作
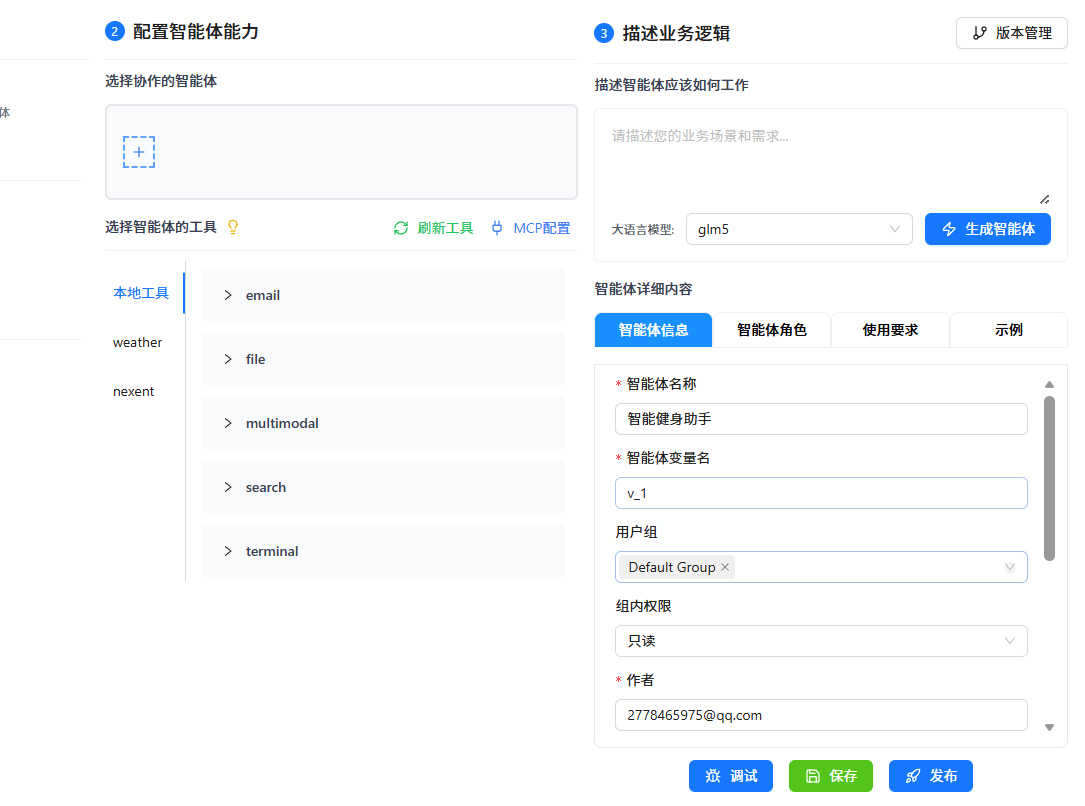
这里我们选择qwen3.5-plus进行自动生成,提示词如下!
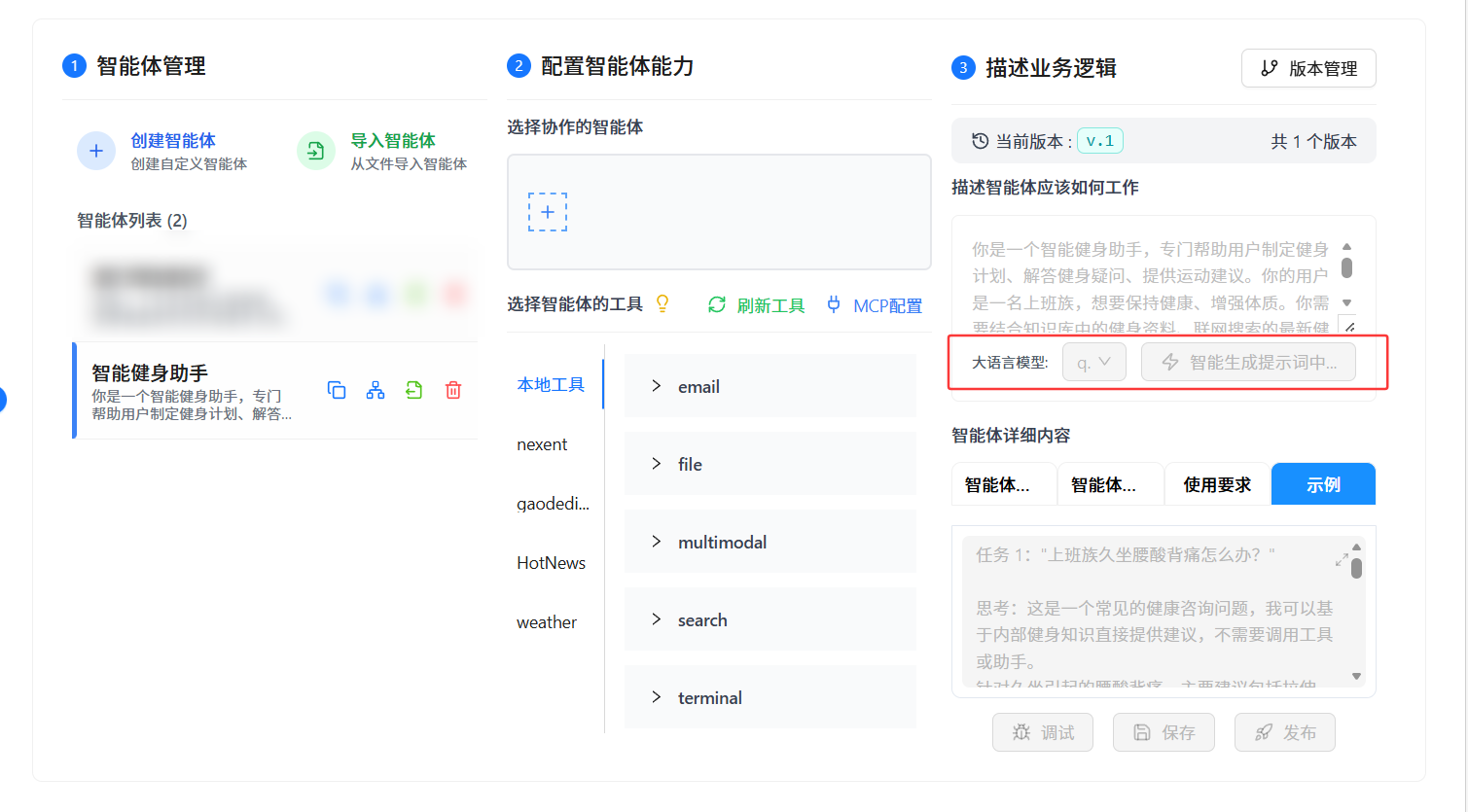
6.2 自动生成提示词
在描述框里写:
你是一个智能健身助手,专门帮助用户制定健身计划、解答健身疑问、提供运动建议。你的用户是一名上班族,想要保持健康、增强体质。你需要结合知识库中的健身资料、联网搜索的最新健身资讯,为用户提供个性化的健身建议。回复要简洁、专业、易于理解。
点"生成智能体",大约 8 秒后生成了完整的提示词结构。
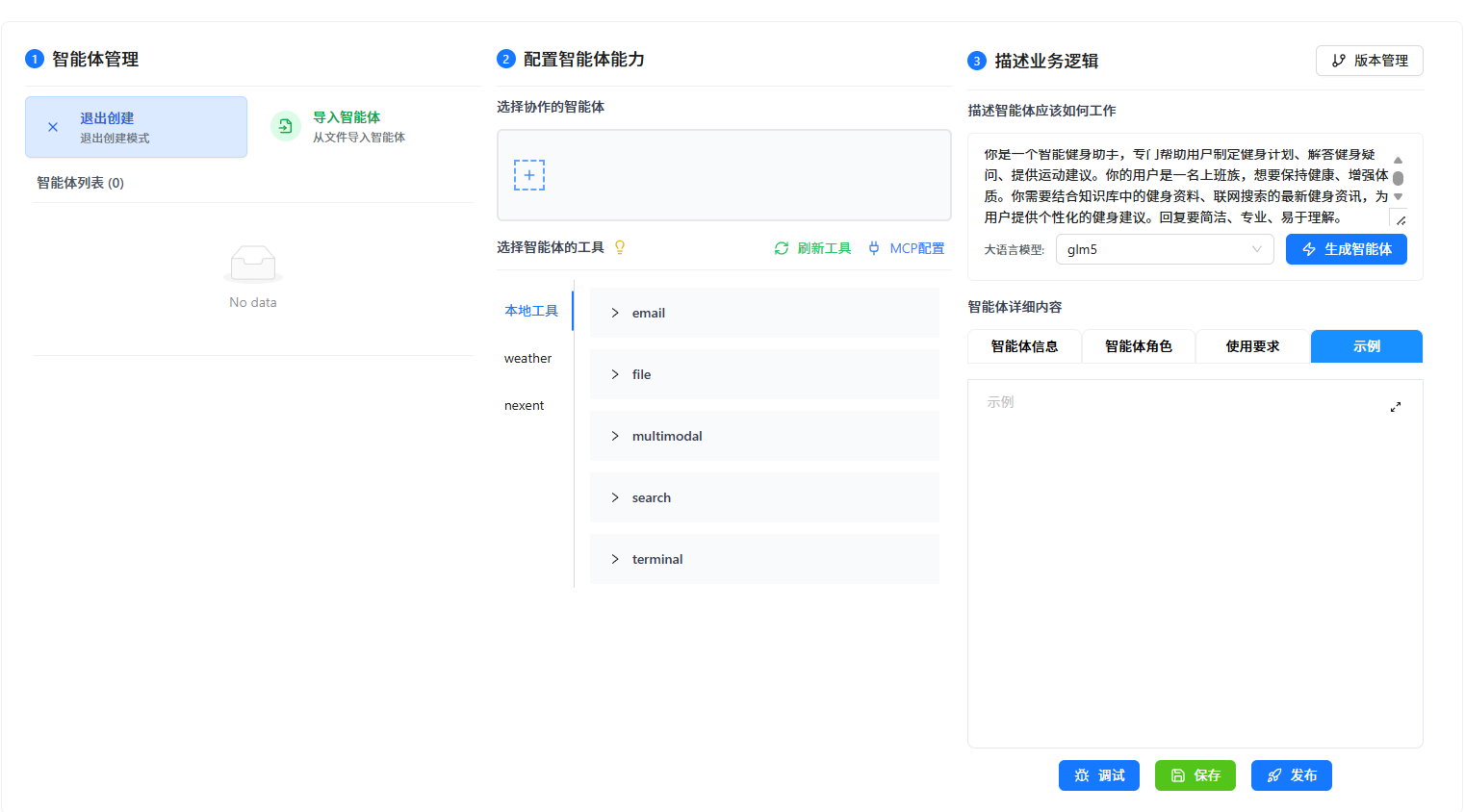
6.4 手动修改提示词
自动生成的提示词我做了三处修改:
- 工具调用顺序:优先检索知识库,再联网补充
- 输出格式:添加具体的分节规则,每个回答要有"动作要领"和"注意事项"
- 拒答逻辑:明确只回答健身相关问题
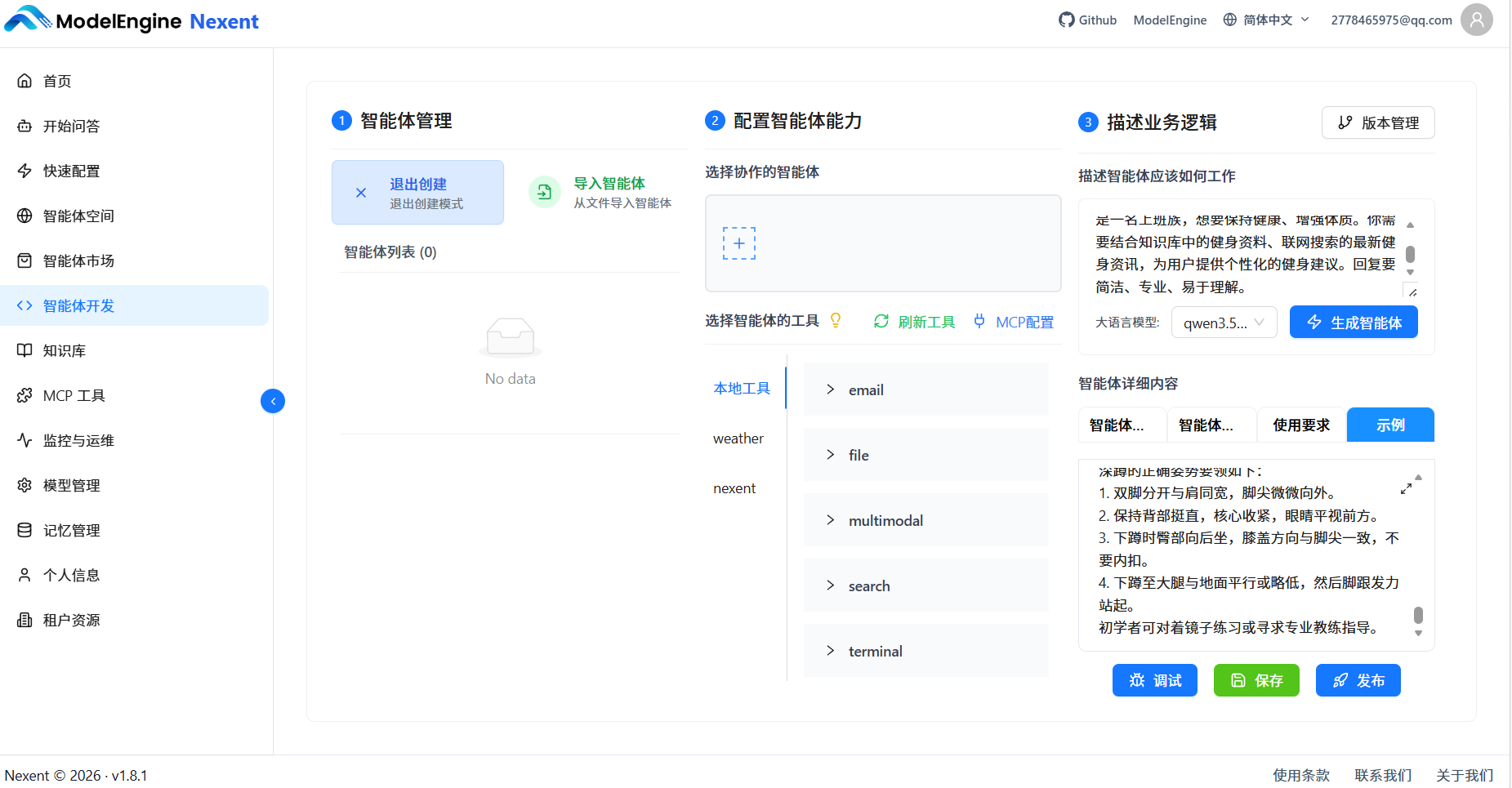
七、调试与测试
7.1 知识库检索测试
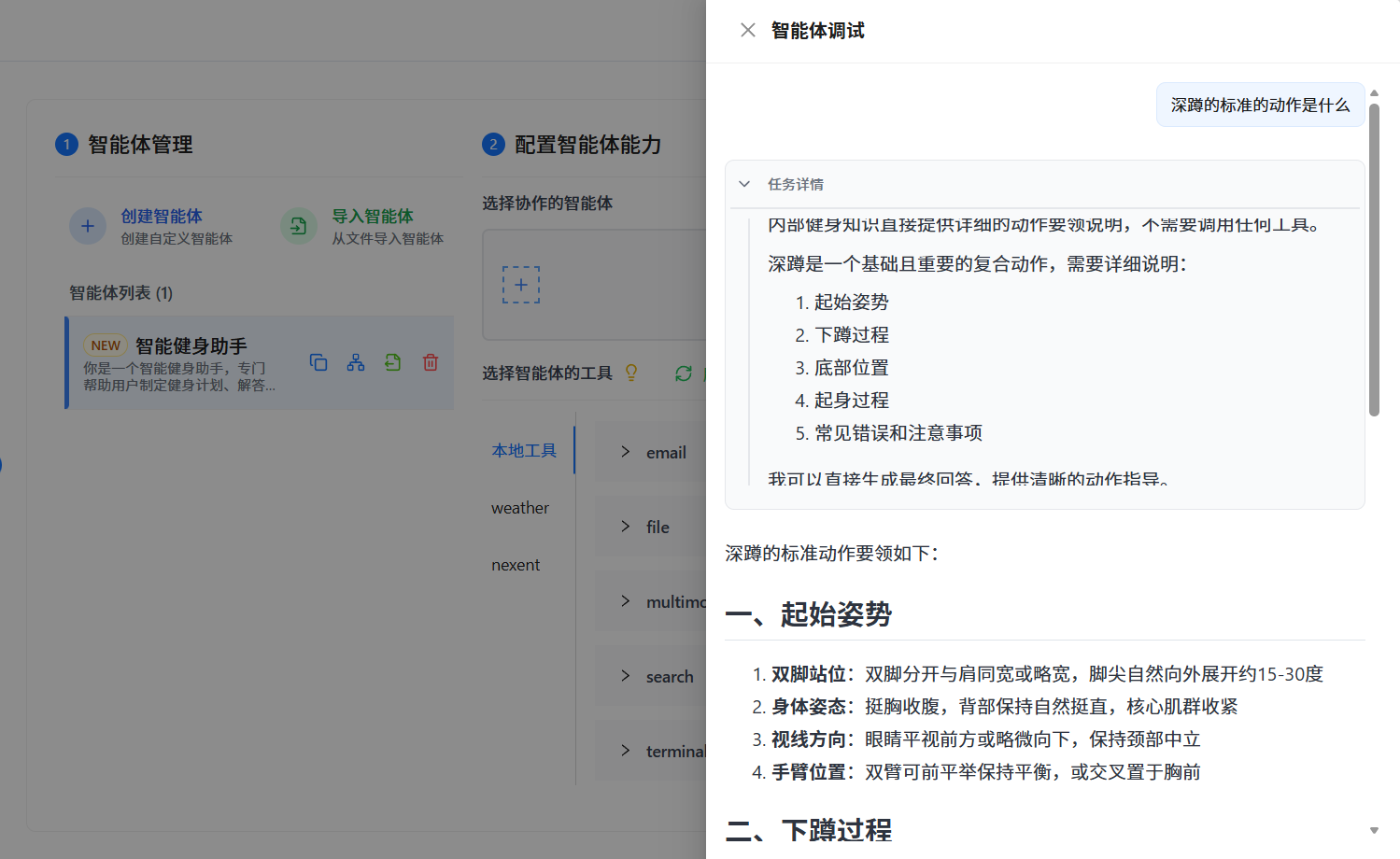
问:"深蹲的标准动作是什么?"
智能体正确调用了知识库检索,返回了详细的动作要领和注意事项。
7.2 工具调用测试
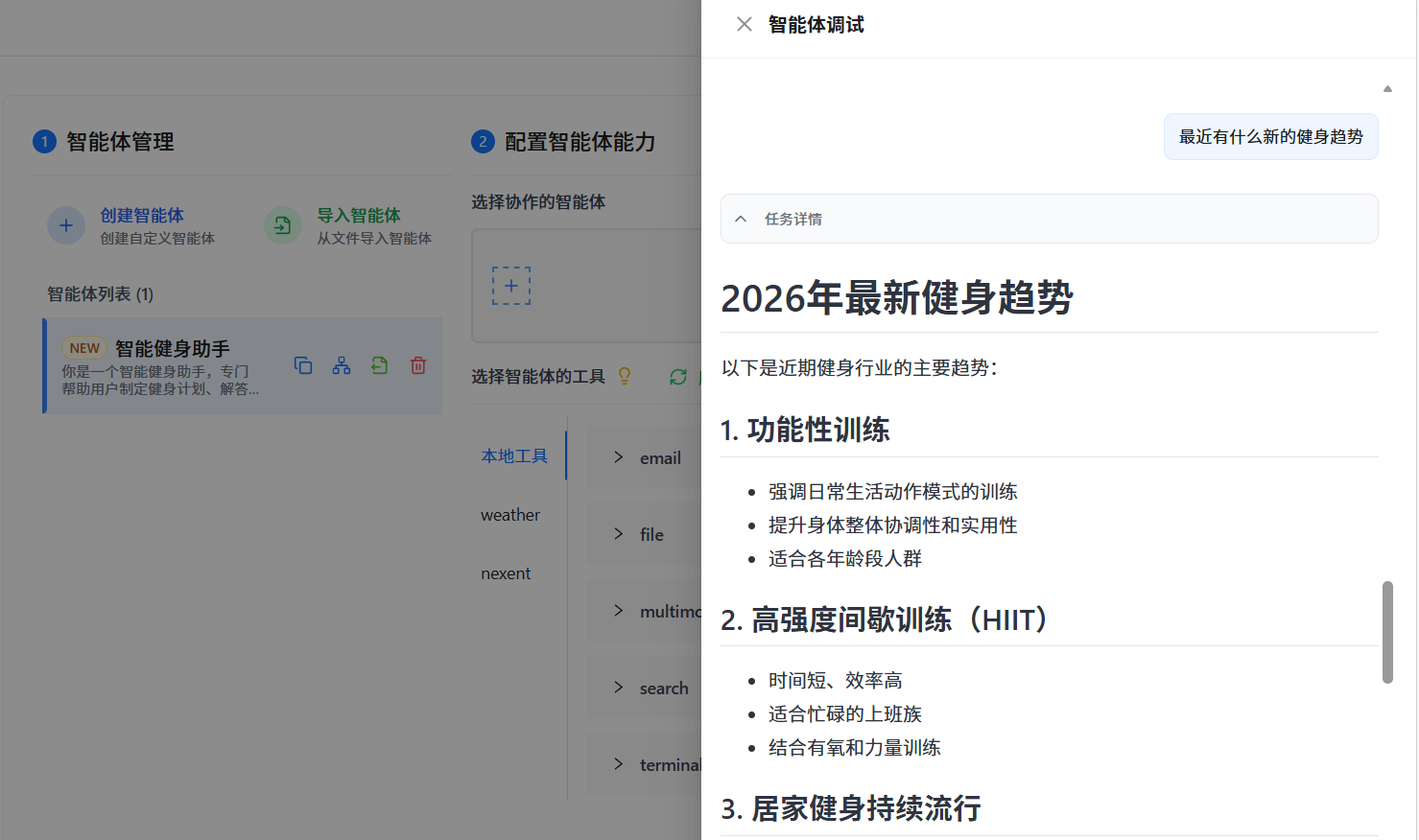
问:"最近有什么新的健身趋势?"
智能体调用联网搜索工具,返回了最新的健身资讯。
7.3 综合测试
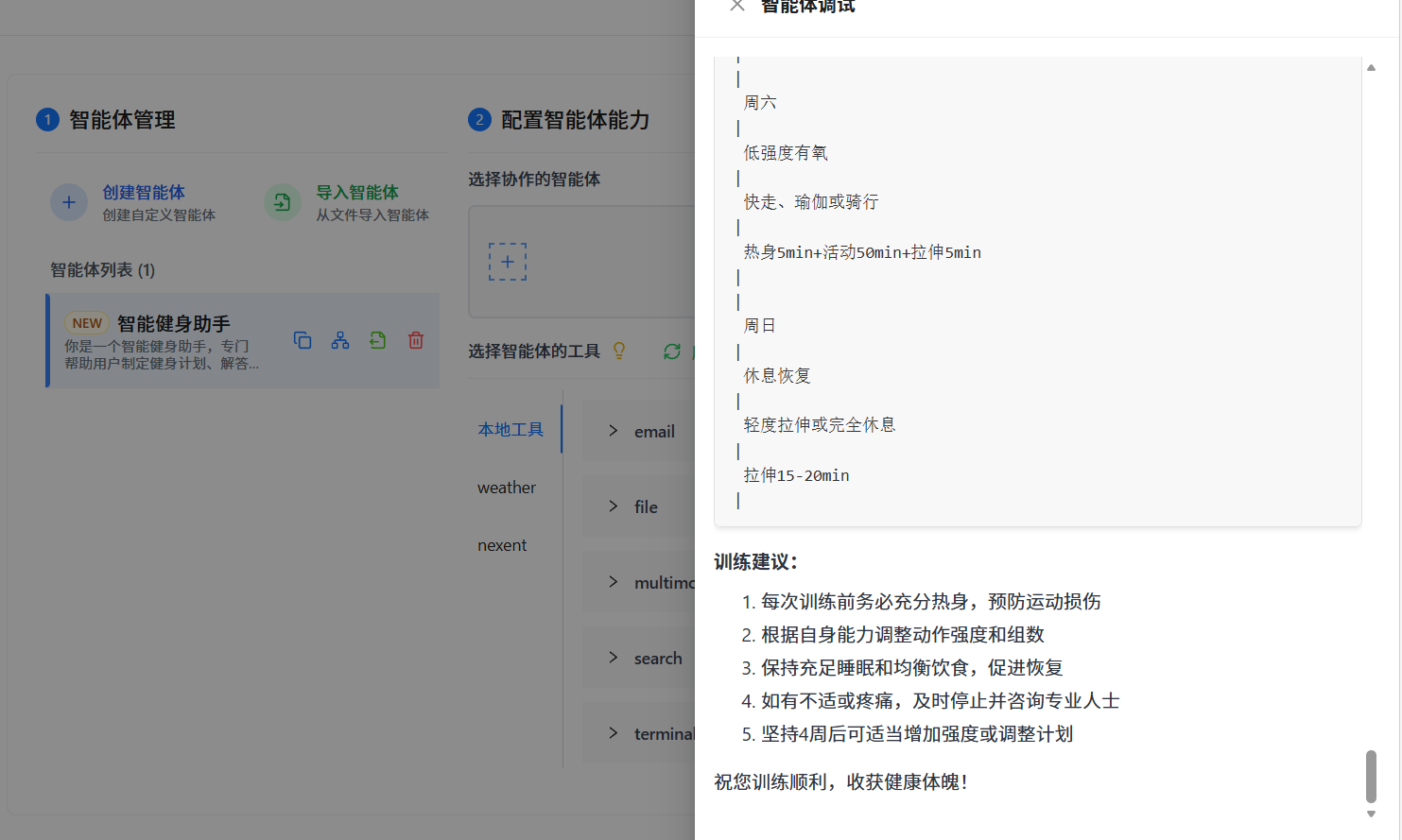
问:"帮我制定一个一周健身计划,我每天有1小时时间"
智能体综合调用多个工具和知识库,生成了一份详细的周计划。
八、发布与使用效果
调试完成后点击"发布",智能体出现在"智能体空间"里。
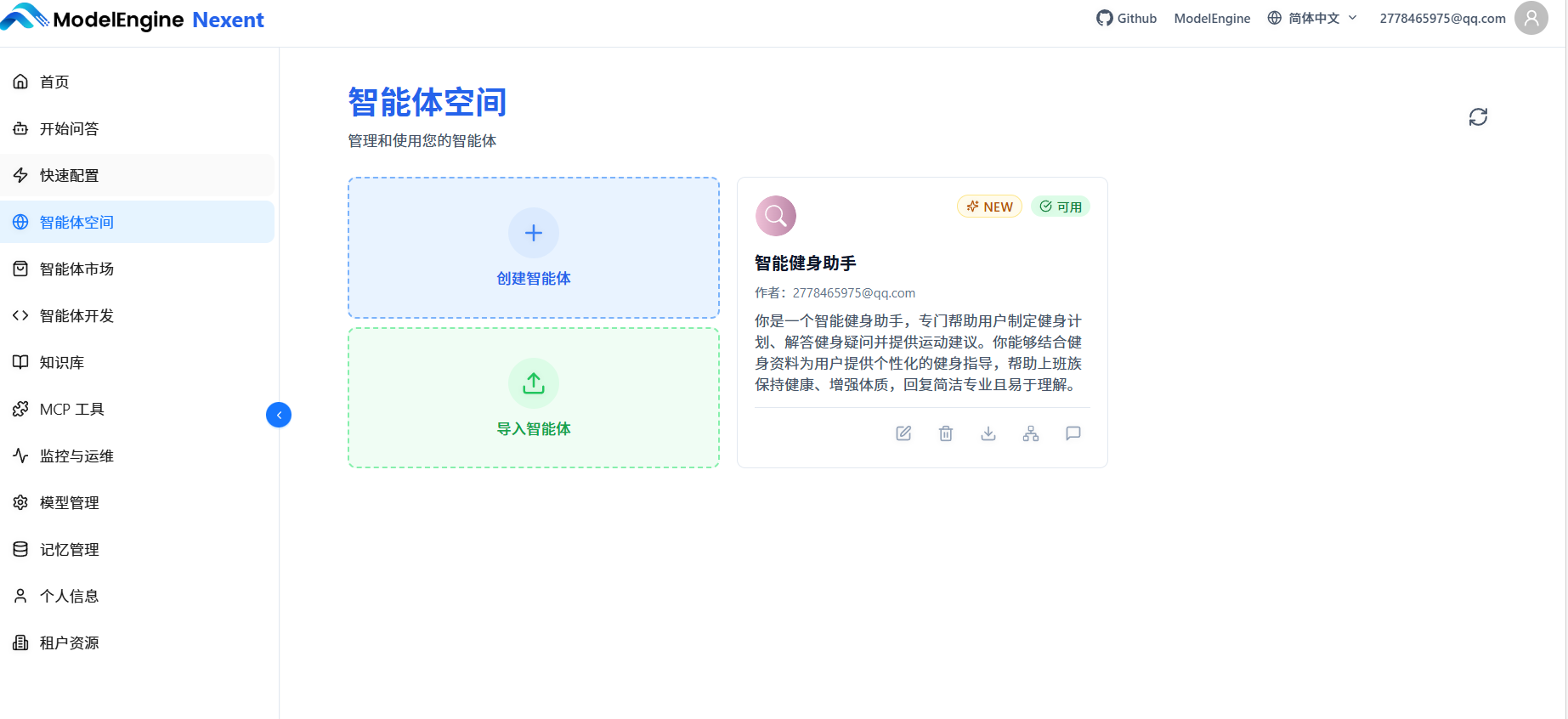
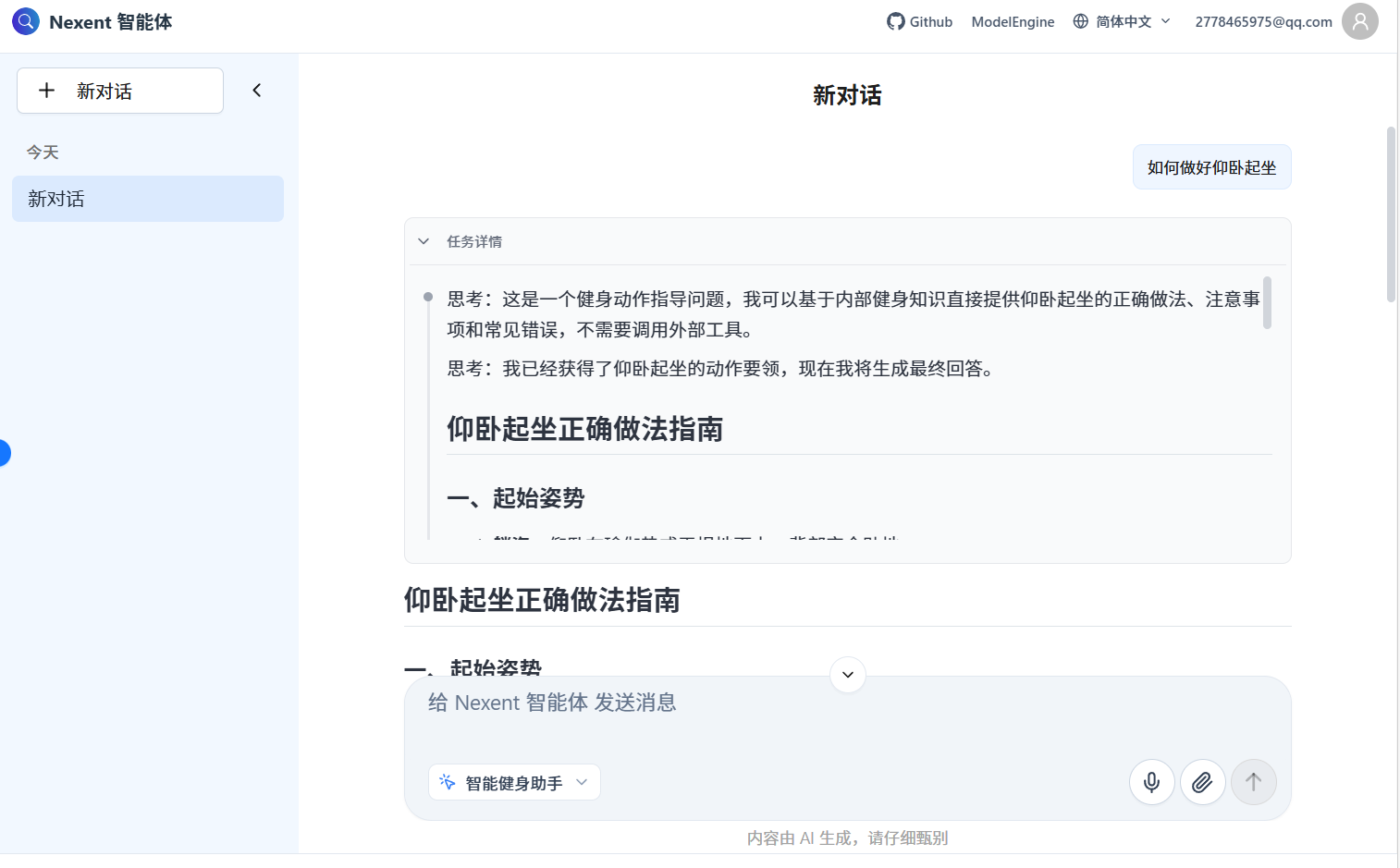
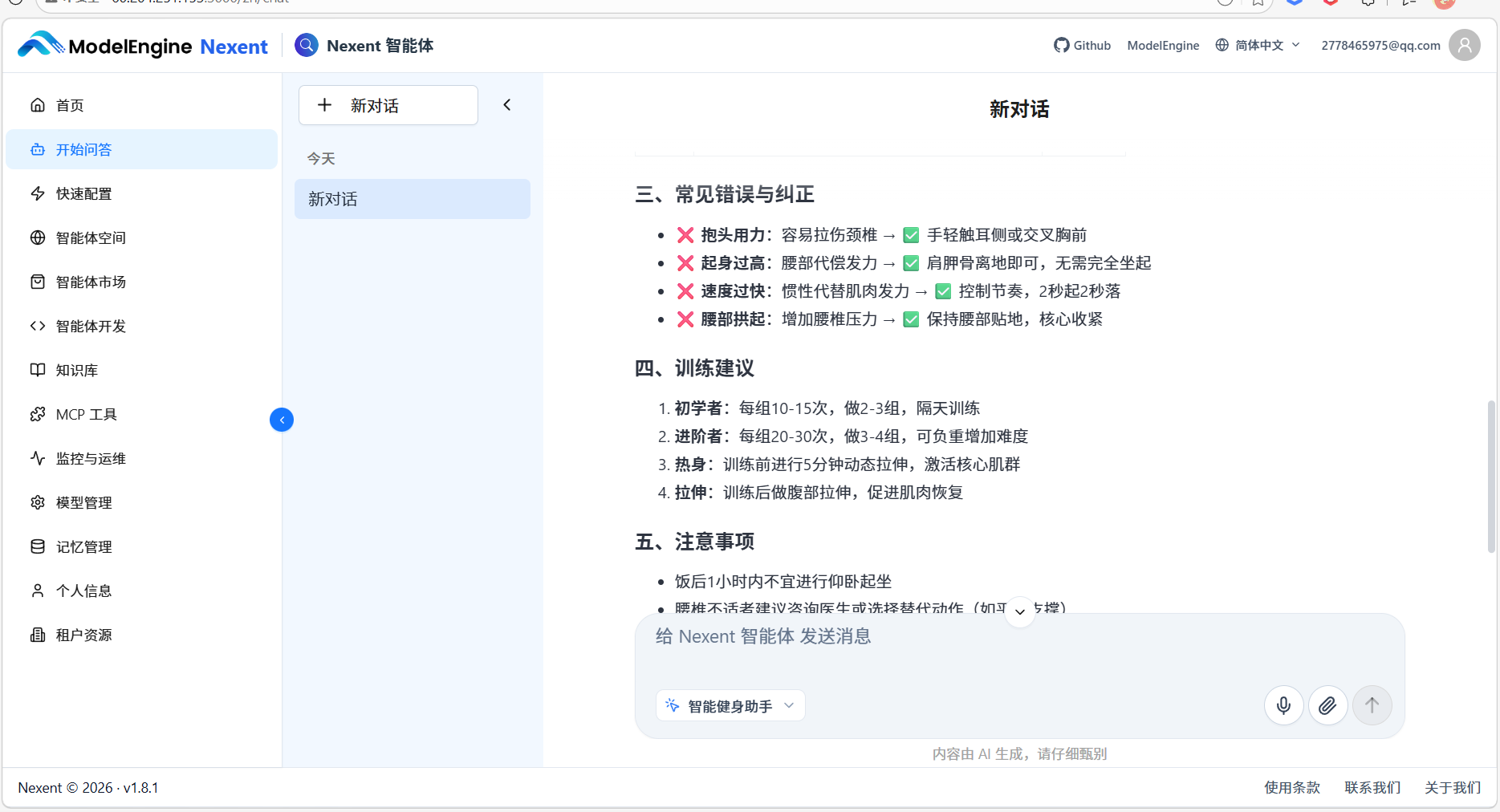
实际使用中,我问了几个问题,智能体都能准确回答,并标注信息来源。特别是综合性的问题,能同时调用知识库和外部工具,效果超出预期。
九、总结
这个周末构建的"智能健身助手",现在已成为我日常健身的好帮手。它帮我整合了碎片化的健身知识,解答我的疑问,还能根据我的情况制定训练计划。
Nexent 给我的感觉是一个成熟度高、对普通用户友好的平台。它把构建智能体的复杂过程简化成了搭积木,让想法到落地的距离变得很短。
如果你也在寻找一款能让知识"活起来"的工具,不妨试试 Nexent。花一个周末搭建一个自己的智能体,或许你也会对未来的生活方式有新的想象。

一站式 AI 云服务平台
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)