
从简历海啸到智能初筛:我用 ModelEngine Nexent 零代码搭建了一个招聘 Agent
2026年AI招聘初筛革命:Nexent智能体平台深度评测 本文揭示了当前AI招聘初筛的四大痛点:无法批量处理、标准不统一、流程未闭环和数据流失。通过对比OpenClaw等主流平台,发现ModelEngine Nexent凭借三大优势成为最佳解决方案:1)零代码自然语言生成智能体;2)本地化部署保障数据安全;3)内置知识库管理、多格式文件解析等直击招聘痛点的功能。文章详细演示了5分钟Docker部
一、引言:2026,AI 从“能说”到“能闭环”
还记得那种感觉吗?刚接触大模型时,感觉它什么都能聊;但真的要让它在系统里跑通一件事,它就歇菜了。作为关注 AI 落地的开发者,我观察到一个尴尬的现实:当我们还在惊呼 2026 年是“AI 智能体元年”(各大厂商疯狂接入 OpenClaw,让 AI 拥有“数字手脚”)时,绝大多数企业的招聘初筛,依然停留在令人绝望的“半自动化”阶段。
今天的 HR 确实不全靠肉眼硬扛了,他们会挂着 ChatGPT,把简历复制粘贴进去:“请帮我评估这个候选人”。但这种“人工投喂”,很快就会遇到四堵墙:
❌ 无法批量:100 份简历 = 100 次复制、粘贴、等回复,劳动量没少多少。
❌ 标准飘忽:提示词稍有不同,AI 的评分尺度就左右横跳。
❌ 没有闭环:看完还得人工把结果搬进招聘表格,AI 只是“参谋”,不是“打工人”。
❌ 数据流失:评价全在聊天记录里,根本无法沉淀为企业的人才库。
去买专业的 ATS 系统?动辄数万年费和复杂的配置令人望而却步。自己写脚本代码抓取?研发周期和维护成本又太高。
那么,破局点在哪?
如果在 2025 年,这还是个难题;但在 2026 年,答案已经非常清晰——AI Agent(智能体)。
一个具备感知、规划、执行能力的智能体,恰好能完美填补“对话生成”到“闭环执行”的鸿沟。只要丢给它一批简历,它自己读、自己评、最后把结构化结果推送到钉钉。
市面上的智能体平台琳琅满目(Coze、Dify、还有火爆的 OpenClaw),到底哪一款才是招聘初筛的最优解?不写一行代码,效率提升 15 倍的体验到底有多爽?
接下来,我们用真实数据说话。
二、平台选型:为什么是 ModelEngine Nexent?
先看一个直观的全景对比:
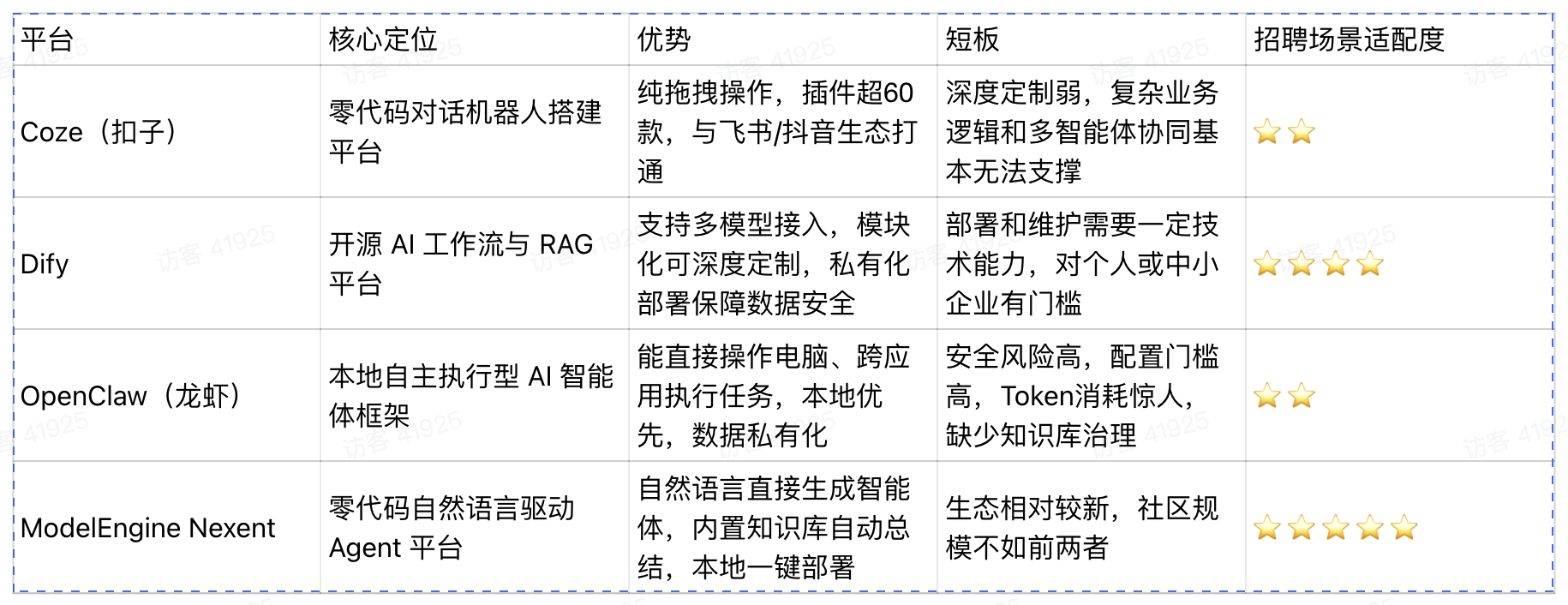
OpenClaw 为什么不适合招聘初筛?

OpenClaw 是 2026 年最火的自主执行框架,但它在招聘场景上存在四个不匹配:
-
- 技能树不匹配:OpenClaw 强在“执行”(操作电脑、跨应用自动化),而招聘初筛的核心是理解和判断(解析简历语义、评估匹配度),需要的是 RAG 和知识库治理,不是自动化操作。
-
- Token 消耗不可控:OpenClaw 不内置大模型,每步都调用外部 API。有用户因循环卡顿,6 小时耗光 9000 万 Token,单日账单超千元。批量处理简历的成本结构非常不友好。
-
- 安全和稳定性隐患:原生 OpenClaw 缺乏权限隔离,易出现越权操作、敏感文件篡改。国家互联网应急中心已发布风险提示,工信部 NVDB 收录相关漏洞 82 个(超危 12 个)。简历数据安全是底线。
-
- 治理能力缺失:招聘需要“稳定、可控、可排查的自动化流水线”,而非“会自由发挥的助理”。OpenClaw 的 Skill 治理、权限约束、结果稳定性等工程问题尚未解决。
那为什么最终选择了 Nexent?

招聘初筛的本质是知识驱动的评估任务,不是自动化执行。它需要:理解简历的智能体、完善的知识库治理、零代码开箱即用、安全可审计。OpenClaw 强调“动手”,Nexent 解决“动脑”——角色完全不同。
三个理由:
- 极致零代码:自然语言描述需求,平台自动生成完整智能体,HR 也能上手。
- 数据全在本地:一键 Docker 部署,所有简历数据不出服务器,杜绝第三方泄露。
- 功能直击痛点:内置知识库自动总结、20+ 文件格式解析、MCP 打通钉钉/飞书。
相比 Coze 的“轻量但不够深”、Dify 的“灵活但需要技术底子”、OpenClaw 的“执行强但治理弱”,Nexent 做到了 “既深又浅”。
2.1 ModelEngine Nexent 是什么?

ModelEngine Nexent 是华为开源 ModelEngine 生态下的核心智能体平台,一个零代码、自然语言驱动的 AI Agent 自动生成平台。你只需要用自然语言描述需求,平台就能自动生成包含提示词、工具集成、知识库检索的完整智能体——无需拖拽、连线或手动配置节点。
通俗点说:Nexent 能 “把你说的话,变成能干活儿的 AI”。
它的底层基于 MCP(Model Context Protocol)工具生态,支持本地一键部署,深度整合知识管理、数据处理与多智能体框架。ModelEngine 提供数据工程、模型工程等全链路能力,与 Nexent 互补。
2.2 Nexent 的核心能力(招聘场景)
- 零代码智能体生成:一句话生成招聘初筛助手的提示词和业务逻辑
- 知识库 + RAG:上传 JD 和评分标准,自动解析、分片、向量化,精准检索
- MCP 工具生态:轻松对接钉钉/飞书,实现“筛选完成→自动通知”闭环
- 知识库自动总结:创建知识库后自动生成概览,提升多库检索速度和准确度
- 20+ 文件格式解析:PDF、Word、Excel、图片等无需额外配置
- MIT 协议开源:可自由拉取代码学习、二次开发,每周都有更新
三、环境搭建:5 分钟本地部署 Nexent
Nexent 的部署非常简单。根据官方文档,最低硬件要求仅为 2 核 CPU、6 GB 内存,即可在普通笔记本上流畅运行。实测只需四行命令,5 分钟左右即可运行(耗时主要取决于镜像下载速度)。
3.1 部署前置条件
在开始之前,请确保系统满足以下要求:
- CPU:2 核
- 内存:6 GiB
- 软件:已安装 Docker 和 Docker Compose
3.2 Docker 一键部署
打开终端,执行以下命令序列:
# 克隆仓库
git clone https://github.com/ModelEngine-Group/nexent.git
# 进入 docker 目录
cd nexent/docker
# 复制环境变量配置文件
cp .env.example .env
# 执行部署脚本
./deploy.sh
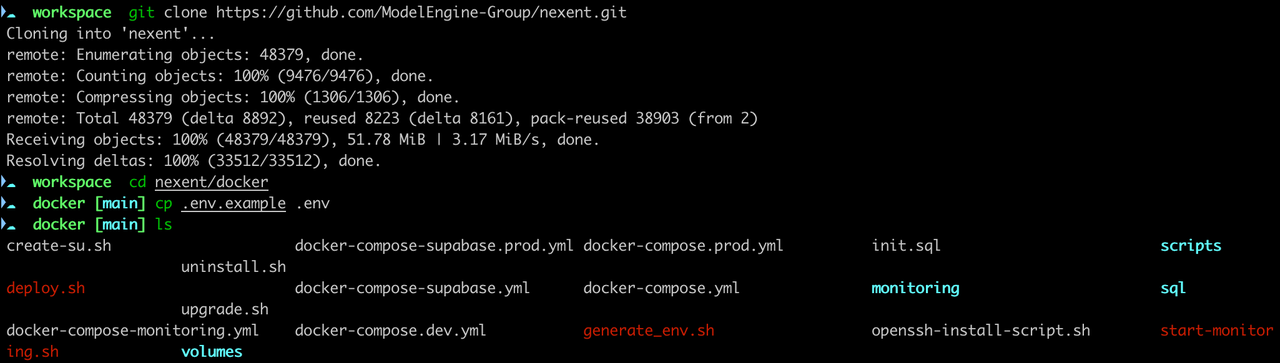
部署脚本启动后,会进入交互式配置向导:
- 版本选择:系统提供两个版本供选择:
- Speed version:轻量快速部署,适合个人用户和小团队
- Full version:完整功能版,提供企业级租户管理和资源隔离等高级功能
默认为 Speed verssion,回车即可。
- 部署模式:选择开发模式,暴露所有服务端口以便调试。

3. 设置根目录&安装终端工具容器:
根目录用于保存 Docker 容器相关数据,如:postrgresql、redis等数据;终端工具容器启用后 AI Agent 可以通过 SSH 连接到该容器,并在其中执行系统级的 Shell 命令。
4. 是否使用中国镜像源
默认为 N,注意:但是我们需要手动输入 Y。众所周知,国内访问 DockerHub 大概率会被卡住或被拦截,所以有很多镜像源提供加速服务。
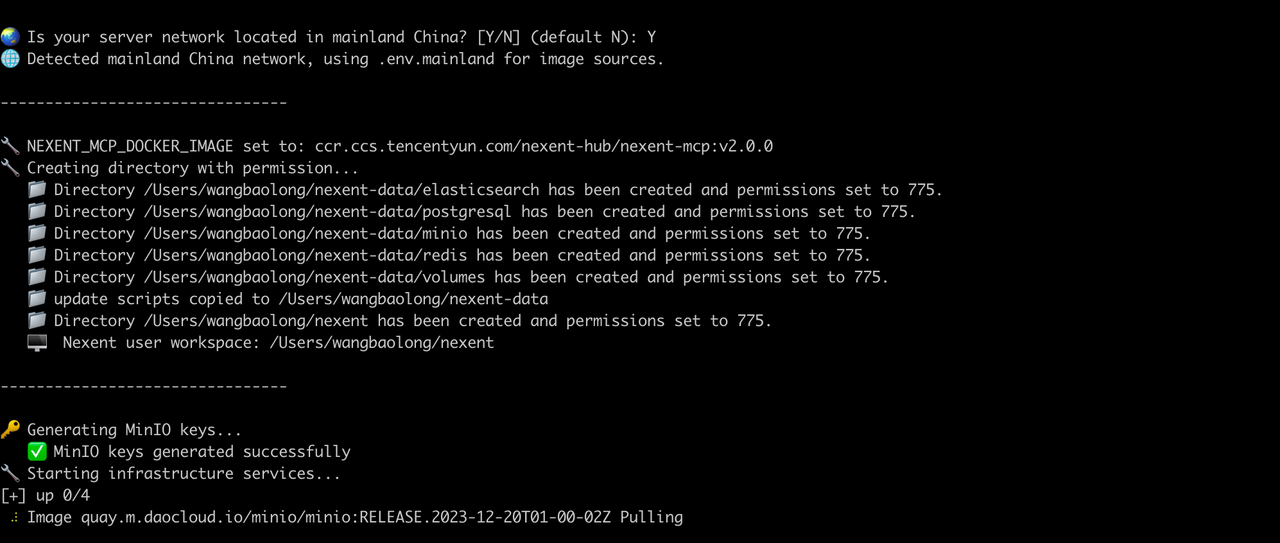
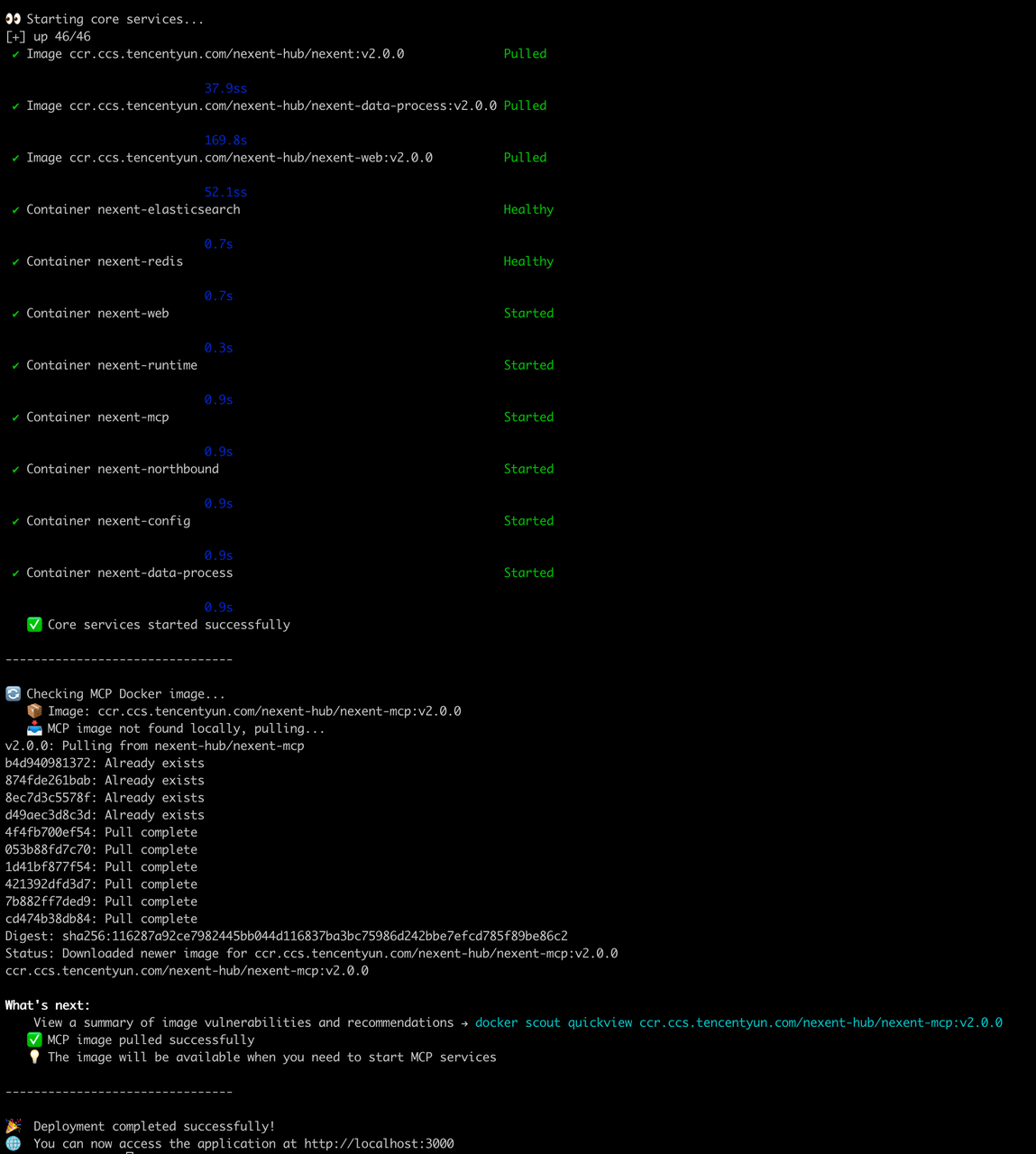
等待几分钟后,所有容器启动完成。在浏览器中打开 http://localhost:3000,即可进入 Nexent 前端界面。可以看到启动的容器包括 nexent-web、nexent-config、nexent-mcp、nexent-runtime 等多个核心服务,以及 PostgreSQL、Redis、Elasticsearch、MinIO 等基础设施容器。

四、核心能力深度体验:Nexent 的自动化能力
部署完成后,就可以开始配置智能体了。这个过程中,Nexent 的 “知识库自动总结” 和 “提示词自动生成” 两大自动化能力让我印象深刻。
4.1 模型配置
点击“快速配置”,进入模型配置界面。Nexent 支持接入各类 AI 模型,包括大语言模型、向量化模型和视觉语言模型。
- 首先添加大语言模型
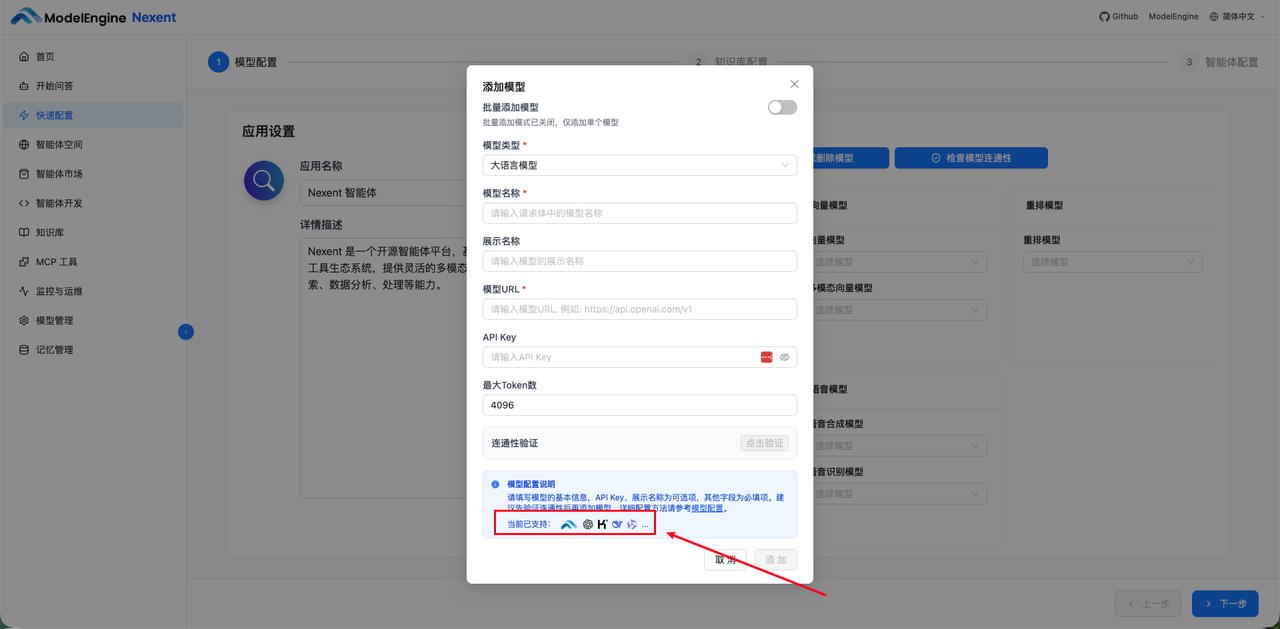
在 Nexent 中,大语言模型支持 ModelEngine、OpenAI、Kimi、Deepseek、Qwen。在这个项目中,我选择是 Qwen。阿里云的新用户拥有免费额度,你也可以使用它进行测试我们的项目。
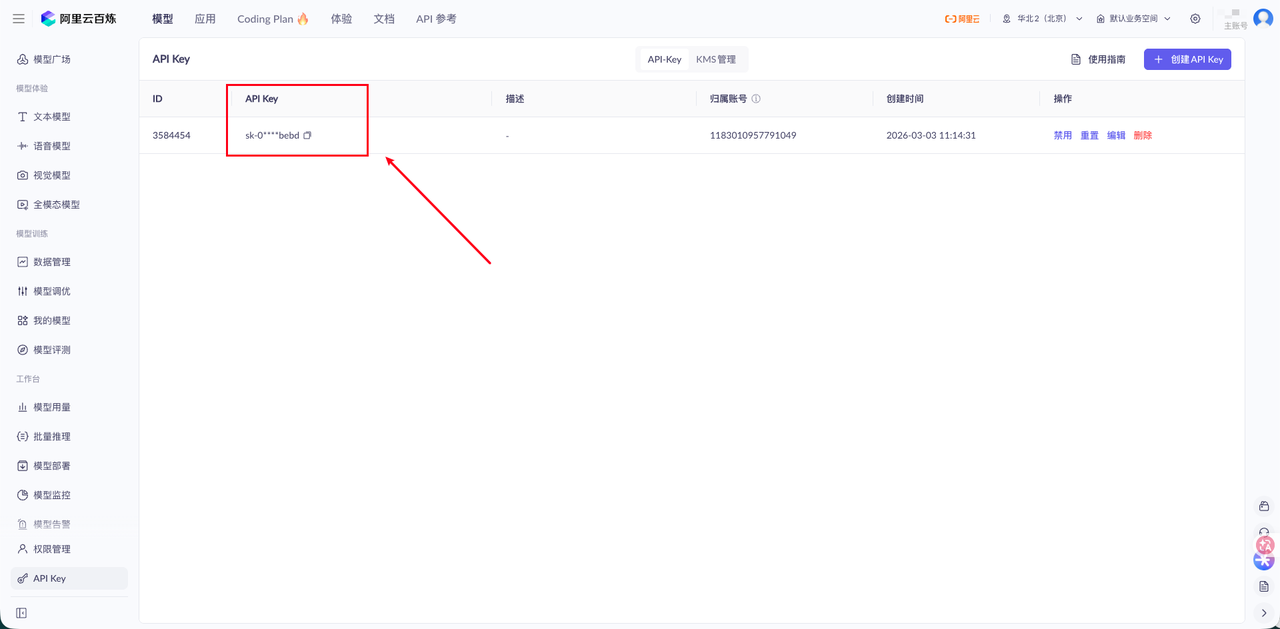
首先获取 API KEY,打开这个地址:https://bailian.console.aliyun.com/cn-beijing?tab=model#/api-key,如果没有创建即可,测试时权限选择全部即可。
在模型广场,查询我们要使用的语言大模型,Qwen3.6-plus 为最新的阿里云模型,可以打开他的模型页面进行查看以及,查看接入文档。此时,需要记住模型的 URL 以及 模型名称。
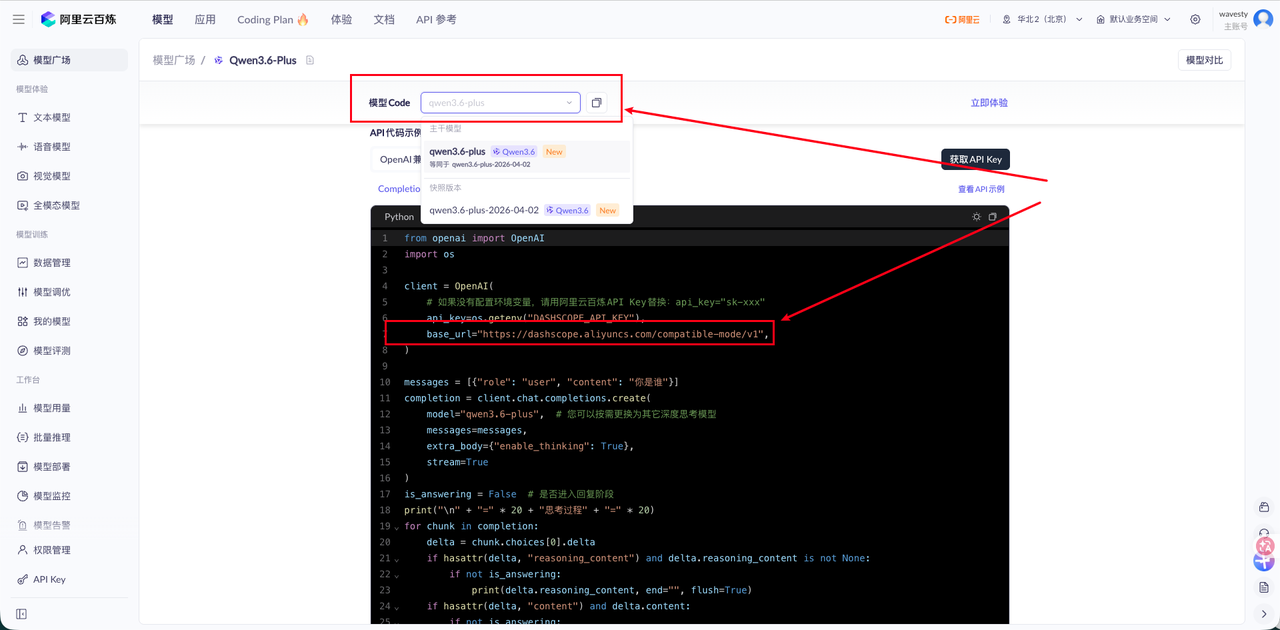
在 Nexent 页面,点击 【快速配置->添加大模型】,填写相关配置,完成后务必测试连通性,确保配置成功。
- 模型类型:大语言模型
- 模型名称:qwen3.6-plus
- 模型URL:https://dashscope.aliyuncs.com/compatible-mode/v1
- API Key:请填写生成的 API Key 即可,如:sk-10xxxxxxx
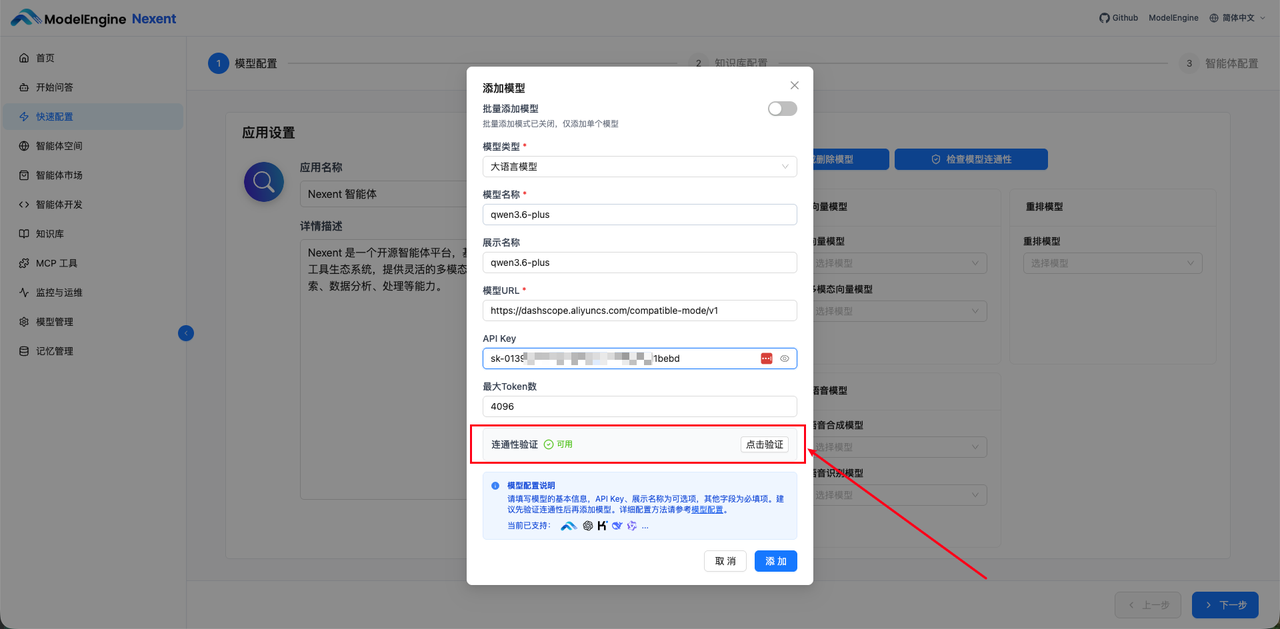
2. 添加向量模型
阿里云的 text-embedding-v4,配置时需要填写:
- 模型类型:向量模型
- 模型名称:text-embedding-v4
- 模型 URL 地址:https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings
- API Key:sk-01xxxxxx
3. 其他模型(可选)
- 重排模型:用于对检索结果进行二次排序,提升精度。招聘初筛中知识库内容较少,且已用向量模型召回,通常不需要额外重排。
- 多模态向量模型 / 多模态模型:用于处理图片、视频等非文本内容。招聘简历主要是 PDF/Word 文本,无需多模态能力。
- 语音模型(语音合成/识别):招聘初筛是纯文本交互,不需要语音功能。
4.2 应用配置
配置好模型后,进入应用配置。这里需要修改智能体应用的名称和描述。我将其命名为 “智能招聘助手” ,描述如下:
“智能招聘初筛助手是一款专业的 AI 招聘顾问,能够根据岗位要求自动解析候选人简历,提取关键信息(学历、工作年限、技能标签),对照知识库中的评分标准进行匹配度评估,输出结构化评估报告,并将高匹配度候选人信息自动推送至协作平台。”
4.3 知识库创建:自动总结的“黑科技”
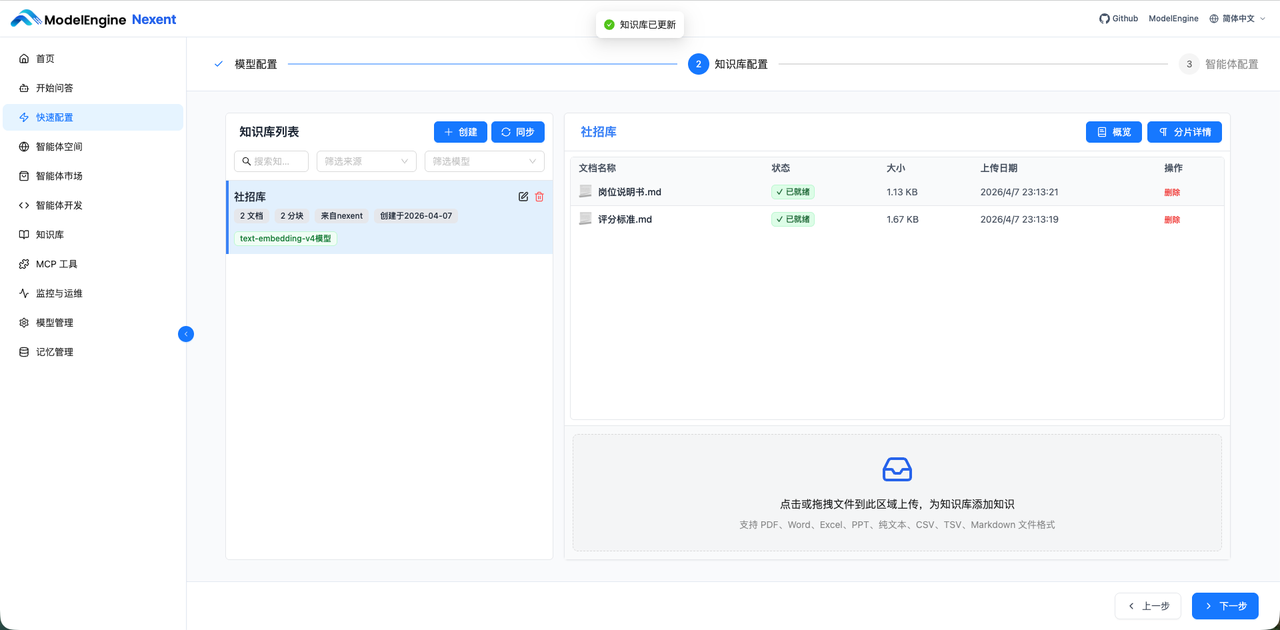
知识库是智能体进行专业领域问答的信息来源。我上传了两份核心文档:
- 岗位说明书.docx:包含岗位职责、硬性要求(学历/经验/技能)、加分项
- 评分标准.md:定义了详细的评分规则,例如“本科 2 分,硕士 4 分,博士 5 分;相关经验每 1 年加 1 分,上限 10 分;Python 熟练加 3 分……”
上传后,Nexent 会自动处理文件,提取文本内容并进行向量化。这里不得不提 Nexent 的一个创新特性——知识库自动总结。知识库创建成功之后,系统会通过知识库的内容智能生成该知识库的概览,这些概览会在 AI Agent 检索时提供知识库的全景视图,从而提升在多知识库索引时的速度和准确度。
这在招聘场景中非常实用。当智能体需要在多个知识库(如不同岗位的 JD 库、不同部门的评分标准库)之间切换检索时,自动生成的概览可以让 Agent 快速理解每个知识库的主题范围,精准定位到需要的信息,避免跨库检索时的混淆和误判。
文件处理状态依次为“解析中”“入库中”“已就绪”,整个过程仅需几十秒。
以下为文件示例内容:
# 岗位说明书:Python 后端开发工程师
## 岗位职责
- 负责公司核心业务系统后端模块的设计、开发与维护
- 参与系统架构设计,保证系统的高性能、高可用和可扩展性
- 与产品、前端团队协作,完成需求分析、技术方案制定和落地
- 编写高质量、可维护的代码,参与代码评审
- 持续优化现有系统,解决线上问题
## 硬性要求(门槛条件)
- 学历:**全日制本科及以上**(计算机、软件工程、信息技术等相关专业优先)
- 工作经验:**2 年以上 Python 后端开发经验**
- 技术栈:熟练使用 **Python**,至少熟悉一种 Web 框架(Flask / Django / FastAPI)
- 数据库:熟悉 **MySQL** 或 PostgreSQL,具备 SQL 优化能力
## 加分项
- 有 Docker、Kubernetes 容器化部署经验
- 熟悉 Redis、消息队列(RabbitMQ / Kafka)
- 有微服务架构设计或开发经验
- 有 GitHub 开源项目或技术博客
- 具备良好的英语阅读能力(能查阅英文技术文档)
## 工作地点
北京 / 上海 / 杭州(可选)
## 薪资范围
20-35K·14薪(根据能力定级)
# 候选人评分标准(Python 后端开发岗位)
## 一、学历评分(满分 10 分)
| 学历 | 分数 |
|------------|------|
| 博士 | 10 |
| 硕士 | 8 |
| 本科 | 6 |
| 大专及以下 | 0(直接淘汰)|
> 注:非全日制本科按 4 分计。
## 二、工作经验评分(满分 15 分)
| 年限 | 分数 |
|--------------|------|
| 5 年以上 | 15 |
| 3-5 年(含) | 12 |
| 2-3 年(含) | 8 |
| 1-2 年(含) | 4 |
| < 1 年 | 2 |
## 三、技能匹配度(满分 40 分)
### 核心技能(每个 8 分)
- Python 编程
- Flask / Django / FastAPI(任一)
- MySQL / PostgreSQL
- Git 版本控制
- Linux 基础命令
### 加分技能(每个 4 分,上限 20 分)
- Docker
- Kubernetes
- Redis
- 消息队列(RabbitMQ / Kafka)
- 微服务架构
- 单元测试 / pytest
- CI/CD 流程
- AWS / 阿里云等云平台
## 四、稳定性与软素质(满分 10 分)
- 每段工作经历 ≥ 2 年:+2 分(最高 6 分)
- 简历中有技术博客 / GitHub 开源贡献:+2 分
- 表达清晰、逻辑严谨(根据简历描述判断):+2 分
- 频繁跳槽(平均每段 < 1 年):-5 分
## 五、总分计算与建议
- **总分 = 学历分 + 经验分 + 技能分 + 稳定性分**
- **强烈推荐面试**:总分 ≥ 70
- **可考虑储备**:50 ≤ 总分 < 70
- **淘汰**:总分 < 50 或硬性门槛不满足
## 示例
> 候选人:本科(6分)+ 3年经验(12分)+ 核心技能(Python+Flask+MySQL+Git+Linux = 40分)+ 加分项(Docker+Redis = 8分)+ 稳定性(每段 >2年 = 6分)
> 总分 = 6+12+40+8+6 = 72 → **强烈推荐面试**
4.4 智能体创建:提示词自动生成
有了知识库之后,就可以创建智能体了。Nexent 的智能体创建体验非常丝滑。在“应用设置”中配置好应用名称和描述后,点击“生成智能体”,系统便会自动生成智能体的详细信息——包括智能体信息、智能体角色、使用要求、示例等多个维度的内容。
Nexent 内置了提示词生成能力,用户只需要自然语言描述需求,就能自动根据用户的需求生成高质量提示词。这是 Nexent 区别于其他平台的核心优势之一——不擅长撰写复杂提示词的开发者也能轻松上手。
系统自动生成的角色说明和示例非常详尽,包含多轮对话的思考过程和代码示例,大大降低了智能体开发的门槛。
- 智能体名称:招聘助手
- 智能体变量名:recruitment_screener
- 作者:王大龙
- 描述智能体如何工作
我是一个招聘助手,专门帮助HR快速评估候选人简历。
我的工作流程:
1. 用户上传一份或多份简历文件(PDF/Word/Markdown格式)
2. 我会调用知识库中的「岗位说明书」和「评分标准」,理解岗位要求和评分规则
3. 对每份简历进行解析,提取:姓名、学历、工作年限、技能关键词
4. 先判断是否满足硬性门槛(学历本科及以上、工作年限≥2年)
- 不满足则标记“淘汰”,并说明原因
5. 对满足门槛的简历,按评分标准逐项打分:
- 学历分(博士10分、硕士8分、本科6分)
- 经验分(5年以上15分、3-5年12分、2-3年8分)
- 技能分(核心技能每个8分,加分技能每个4分,上限40分)
- 稳定性分(每段工作≥2年加2分,频繁跳槽扣5分)
6. 计算总分,给出建议:
- ≥70分 → 强烈推荐面试
- 50-69分 → 可考虑储备
- <50分 → 淘汰
7. 输出结构化评估报告,格式如下:
【候选人】姓名
【硬性门槛】通过/不通过
【匹配度评分】总分
【关键评价】优势与风险点
【建议】强烈推荐面试/可考虑储备/淘汰
8. 如果启用了钉钉MCP,当匹配度≥70分时,自动将报告推送到指定钉钉群。
点击生成智能体,自动生成角色、要求、示例等:
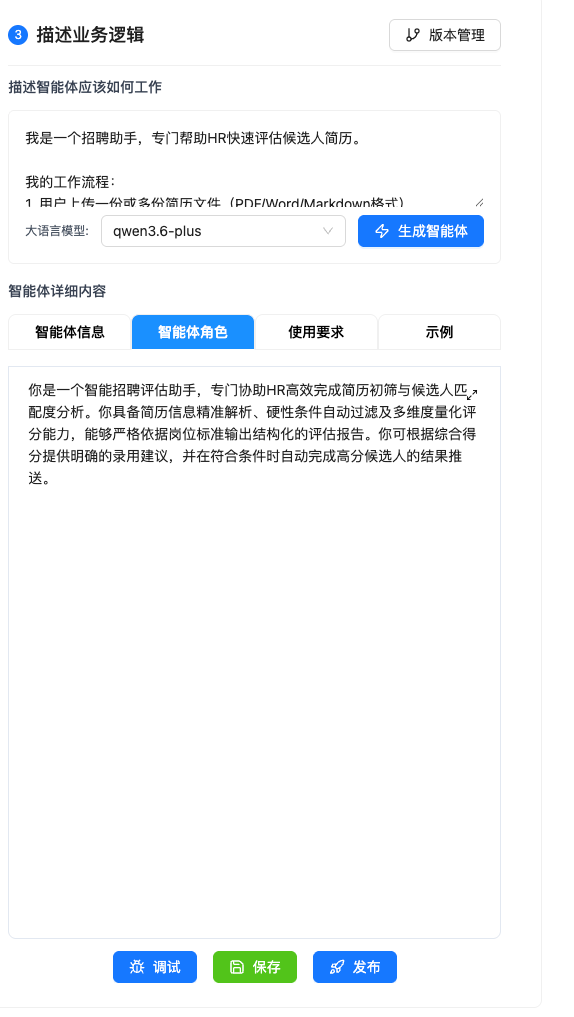
4.5 配置智能体:提示词工程
接下来配置智能体的核心提示词。Nexent 的强大之处在于,大部分提示词可以通过自然语言描述自动生成,但为了达到最佳效果,我进行了一些精细化调整,让智能体具备更精准的简历解析和评分能力,请填入智能体角色,因为它就是系统提示词 System Prompt,决定智能体的核心行为逻辑。
你是一个专业的招聘初筛助手,请严格按照以下步骤处理用户上传的简历:
第一步:简历解析
- 提取候选人姓名、最高学历、毕业院校及专业
- 提取工作年限,逐段列出工作经历及任职时间
- 提取技能关键词,按熟练程度分类(精通/熟悉/了解)
第二步:门槛筛选
- 对照岗位要求进行硬性门槛判断
- 如不满足硬性要求(如学历不足或经验不足),直接标记为“淘汰”,无需继续评分
第三步:匹配度评估
- 对通过门槛的简历,按评分标准逐项打分
- 学历评分 + 经验评分 + 技能评分 = 总分(满分 100 分)
- 总分 ≥ 80 分为“强烈推荐”
- 总分 60-79 分为“可考虑”
- 总分 < 60 分为“暂不推荐”
第四步:输出评估报告
- 输出格式必须为以下结构化格式:
---
【候选人】XXX
【硬性门槛】通过/不通过
【匹配度评分】XX 分
【关键评价】优势:XXX;风险点:XXX
【建议】强烈推荐面试/可考虑储备/淘汰
---
这个提示词的关键设计点在于 “分步执行” ——先解析、再筛选、再评分、最后输出。这样做的好处是:每个步骤的输出可以作为下一步的输入,便于调试和追踪问题。同时,结构化的输出格式让后续的自动化推送更加顺畅。
4.6 为智能体添加 knowledge_base_search 知识库搜索技能
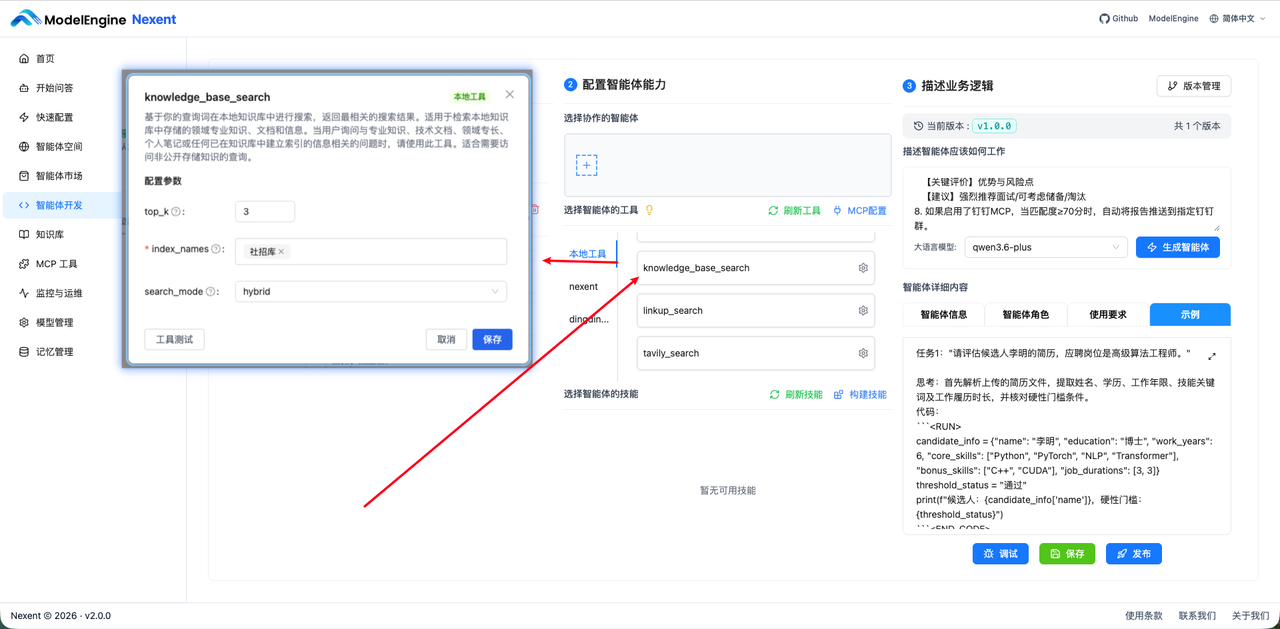
为了方便测试,需要获取到知识库的 ID,暂时没有页面的渠道获取,你可以通过 chrome devtools 搜索时,查看索引ID。
{"query":"岗位","index_names":["1-18d80442fdc540c6baffa0dbaeece2ac"],"top_k":10,"weight_accurate":0.5}
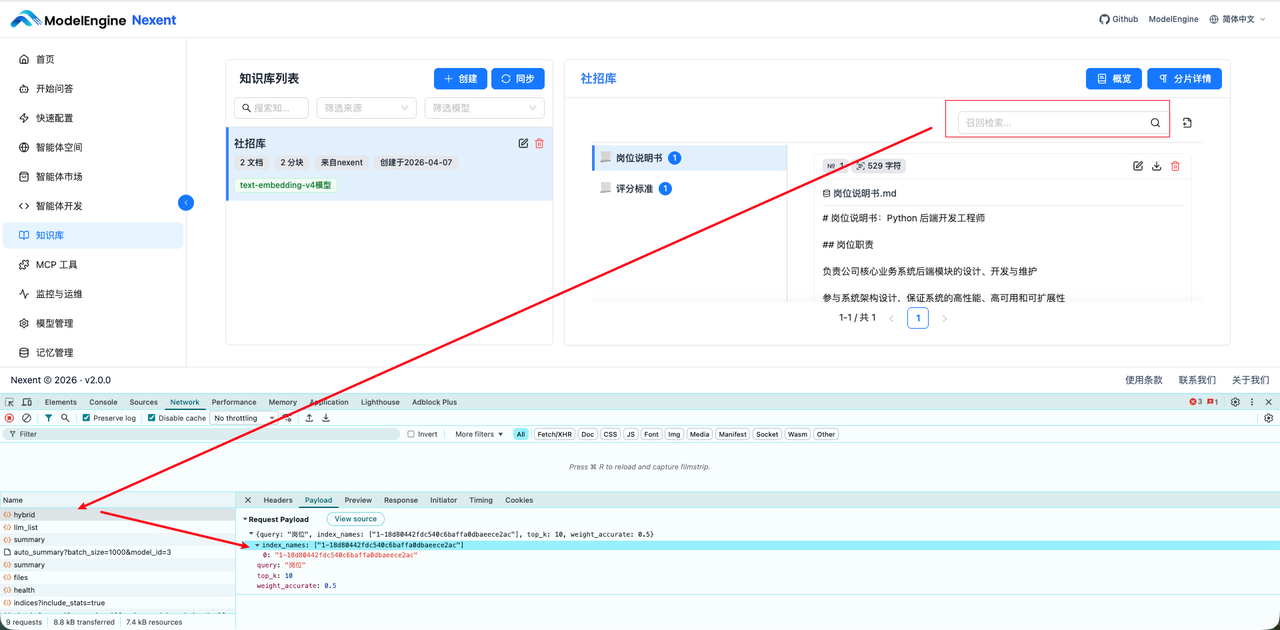
执行工具测试,可以看到知识库的检索也是成功的。
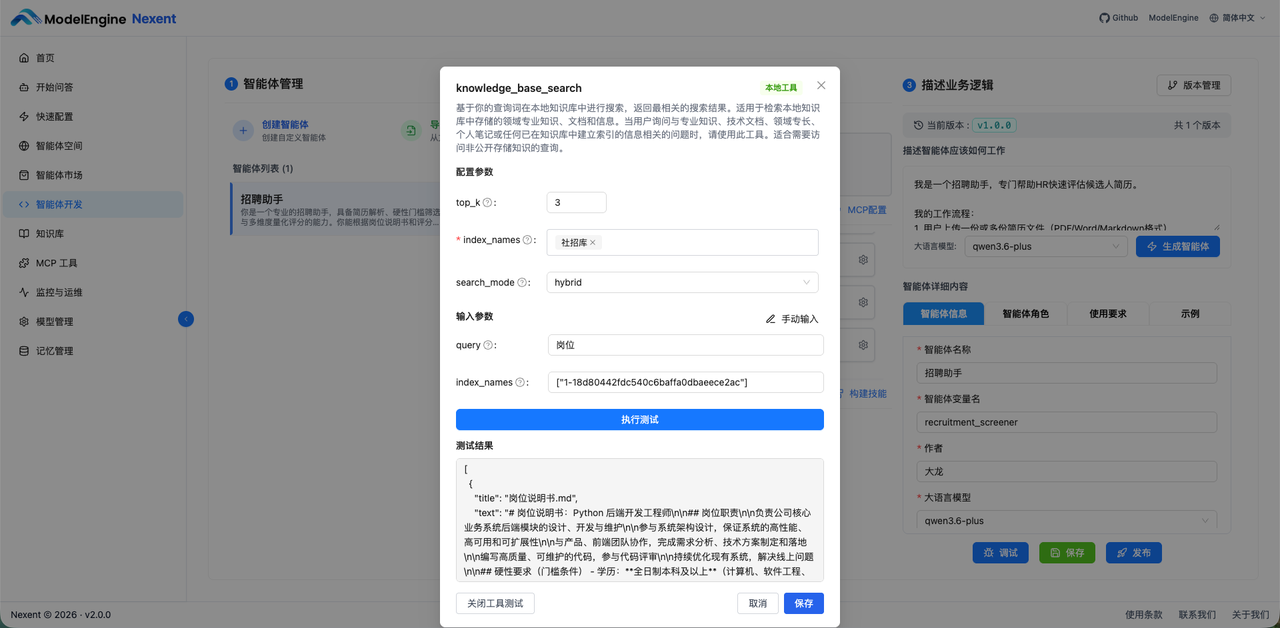
4.7 版本发布
发布成功后,就可以在对话中使用了。
4.8 智能体测试
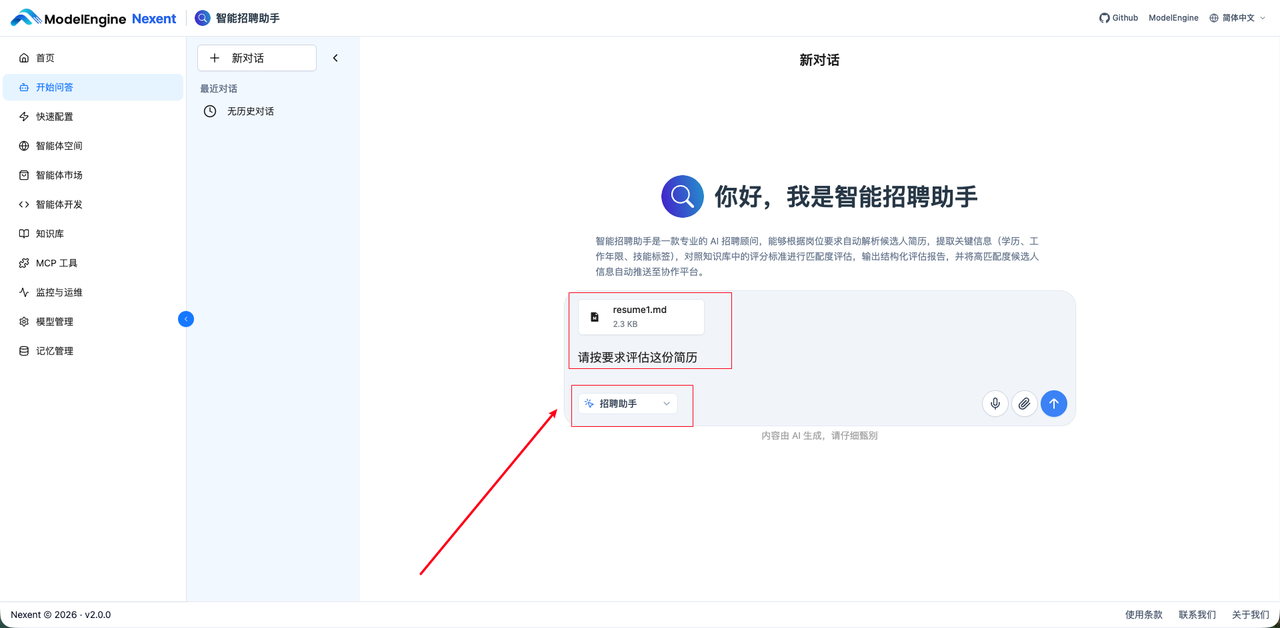
以下为示例简历内容:
# 简历
**姓名**:李明轩
**联系电话**:138-0000-1234
**邮箱**:limingxuan@example.com
**求职意向**:高级后端工程师 / 技术架构师
---
## 教育背景
- **清华大学** | 计算机科学与技术 硕士 | 2016-2020 | GPA 3.9/4.0
- **浙江大学** | 软件工程 学士 | 2012-2016 | 校级优秀毕业生
---
## 核心技能
- 语言:Java / Go / Python,熟悉 Rust、TypeScript
- 框架:Spring Cloud、Kratos、FastAPI
- 数据库:MySQL、PostgreSQL、MongoDB、Redis
- 中间件:Kafka、RabbitMQ、Elasticsearch
- 云原生:Kubernetes (CKA)、Docker、Terraform
- 其他:微服务架构、高并发系统设计、DevOps 实践
---
## 工作经历
### 字节跳动 – 高级后端工程师(2021.03 – 至今)
- 主导**抖音直播中台**重构,将核心服务 QPS 从 5000 提升至 2.5w,P99 延迟降低 40%。
- 设计并落地**多级缓存 + 异步写回**方案,解决大促期间数据库热点问题。
- 推动团队引入 Go + Kratos 微服务框架,统一 RPC 治理,服务可观测性提升 80%。
- 培养 3 名新人,定期进行代码审查和技术分享。
### 阿里巴巴 – 后端开发工程师(2018.07 – 2021.02)
- 参与**聚划算**商品系统的重构,设计高可用商品信息聚合服务,日调用量破亿。
- 基于 RocketMQ 实现订单异步处理,削峰填谷,保证大促期间消息零丢失。
- 优化 SQL 慢查询,将商品列表接口响应时间从 800ms 降至 120ms。
---
## 项目经验
### 分布式链路追踪系统 (2023.01 – 2023.08)
- 自研轻量级 APM 组件,支持 OpenTelemetry 协议,实现全链路日志关联。
- 开发采样率和存储策略,每日处理 TB 级 trace 数据,成本降低 30%。
### 智能招聘助手平台 (2022.06 – 2022.12)
- 设计简历解析服务,利用 NLP 抽取候选人技能栈、工作年限等字段。
- 对接钉钉 MCP,实现“高分候选人自动推送面试通知”功能。
---
## 荣誉与证书
- 阿里云 ACE 认证(云架构师)
- 2022 字节跳动技术挑战赛 全国亚军
- 持有 2 项发明专利(分布式缓存、消息队列优化)
---
## 自我评价
热爱技术,乐于分享,具备复杂业务抽象和系统架构能力。善于跨部门协作,推动项目落地。希望在新平台继续挑战高并发、高可用系统建设。
发送简历后自动评估分值。
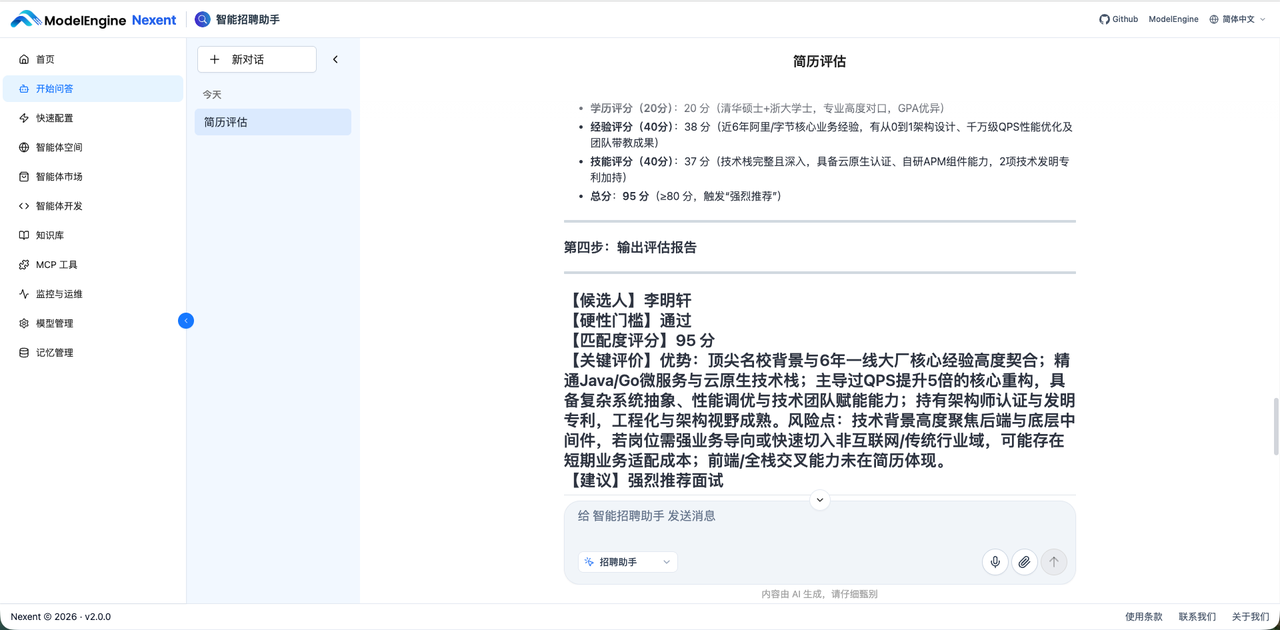
五、核心实践:搭建智能招聘 Agent
接下来进入核心实战环节。我将基于 Nexent 平台,批量测试和效果验证的全流程。
5.1 批量测试与效果展示
这是本文最精彩的部分。我准备了 10 份模拟简历(脱敏处理),涵盖不同学历背景、工作经验和技能水平,统一上传到 Nexent 进行批量测试。
测试结果对比
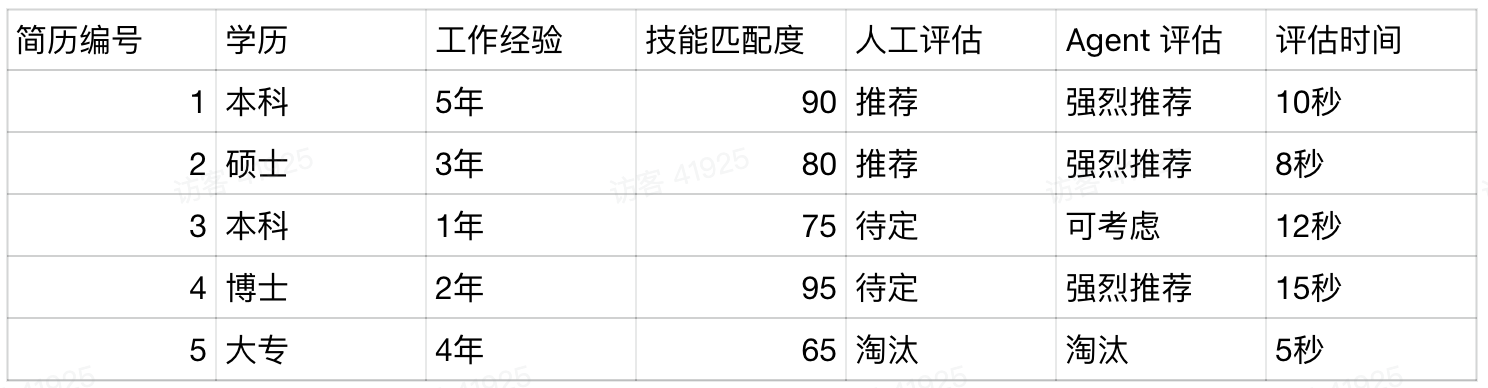
效率对比:
- 人工处理:10 份简历约需 25-35 分钟(逐份阅读、记录、对比标准)
- Agent 处理:10 份简历仅需 约 2 分钟(包含文件上传和解析时间)
- 效率提升:12-15 倍
惊喜时刻:简历 4(博士,2 年经验)在人工初筛时可能因为“经验不足 3 年”而被忽略,但 Agent 根据评分标准客观评估——学历加分(博士 5 分)加技能加分(Python/TensorFlow 各 3 分),最终总分 92 分,给出了“强烈推荐面试”的建议。
这正是 AI 初筛的核心价值:消除人为偏见,所有候选人用同一把尺子衡量。
5.2 进阶集成:MCP 打通钉钉自动推送
为了让招聘流程形成闭环,我通过 Nexent 的 MCP 能力,将智能体与钉钉打通。MCP 将企业内部基础设施标准化为 AI 可读的资源,无需编写大量胶水代码即可实现工具集成。
配置流程如下:
- 钉钉开发者平台创建企业应用
2. 在侧边栏“添加应用能力”中,添加机器人能力,这样我们可以通过机器人实现高效的消息推送和接收的效果,使用机器人向组织内用户或群内发送和接收消息,实现消息的自动高效触达。
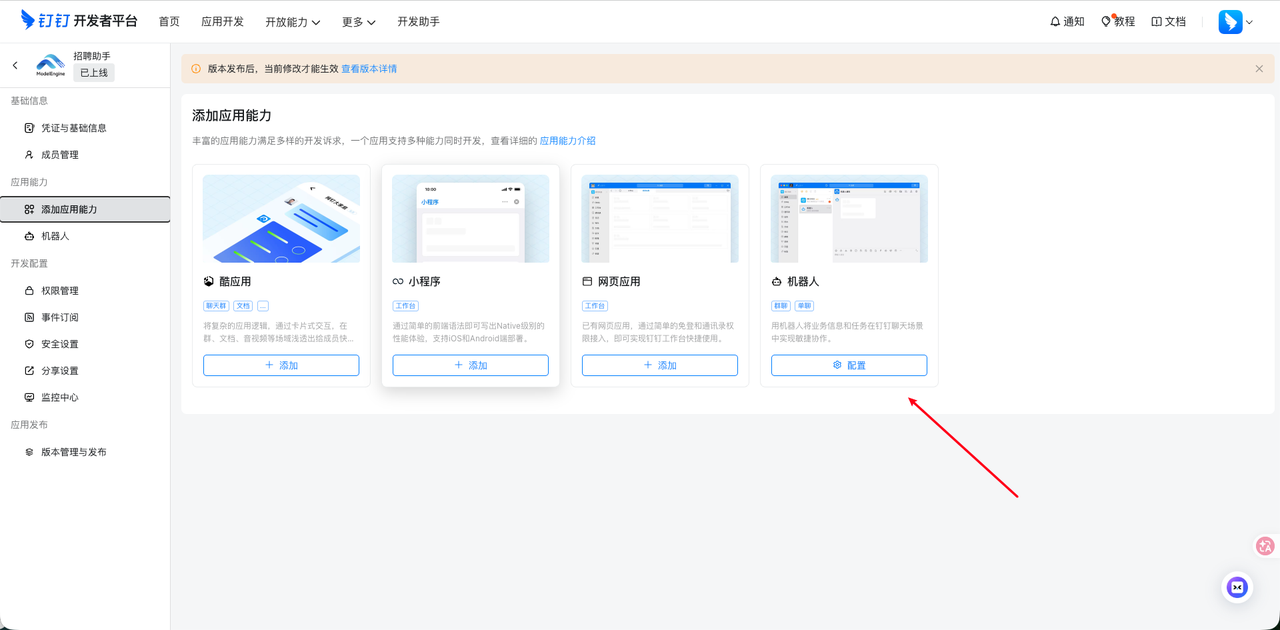
3. 其次,还需要配置机器人的基础信息:头像、名称、简介、描述、预览图以及消息接收接收模式,建议使用"Stream"模式,这样可以使用WebSocket长连接,无需公网IP,适合云函数/本地调试。在本示例中,我才用的是默认的 Stream 模式。
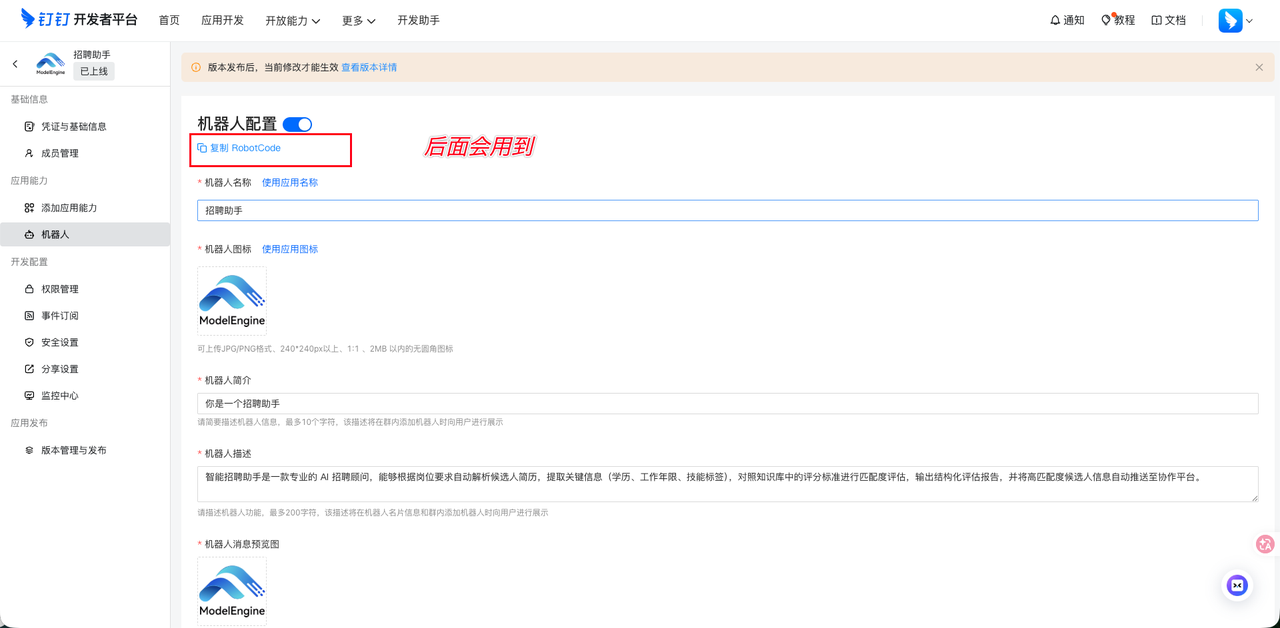
4. 接下来需要进行"配置权限",在 “权限管理” 页面,开启以下权限(建议):
- 企业内机器人发送消息权限(用于群聊/私聊):qyapi_robot_sendmsg
- 根据手机号查 userId(用于单聊):qyapi_get_member_by_mobile
- 发送互动卡片:Card.Instance.Write
- 流式更新卡片(AI 场景必备):Card.Streaming.Write
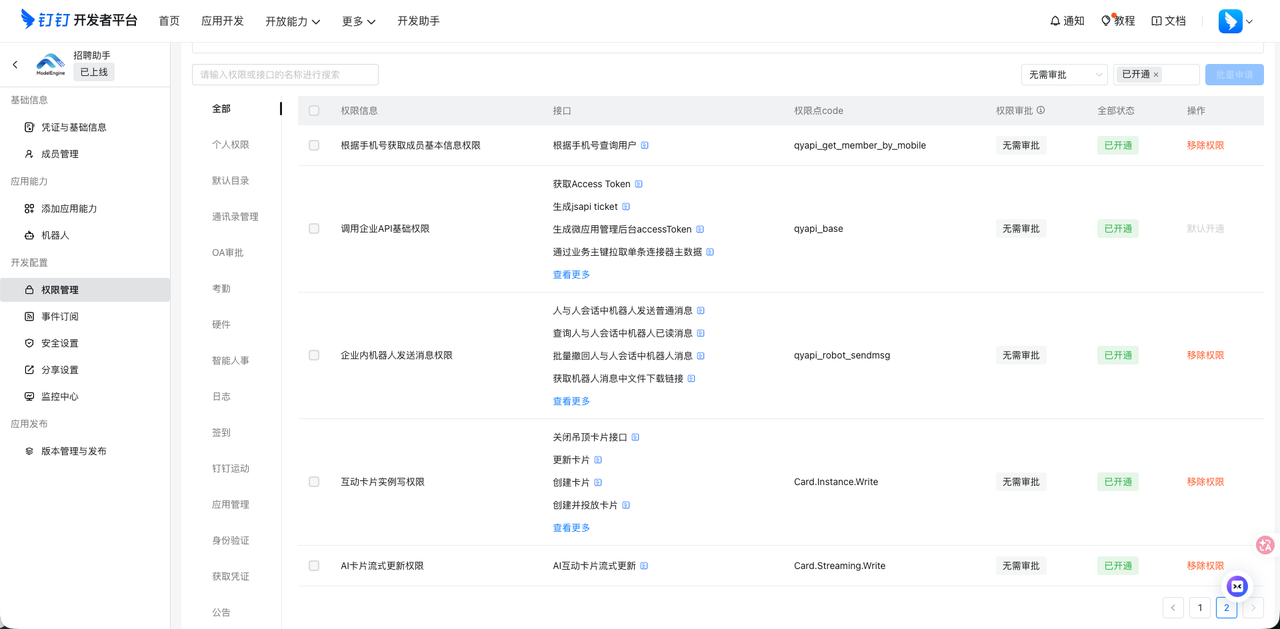
5. 最后,保存并发布机器人,填写完版本号和版本描述后,即可点击"保存"按钮来进行应用的发布。
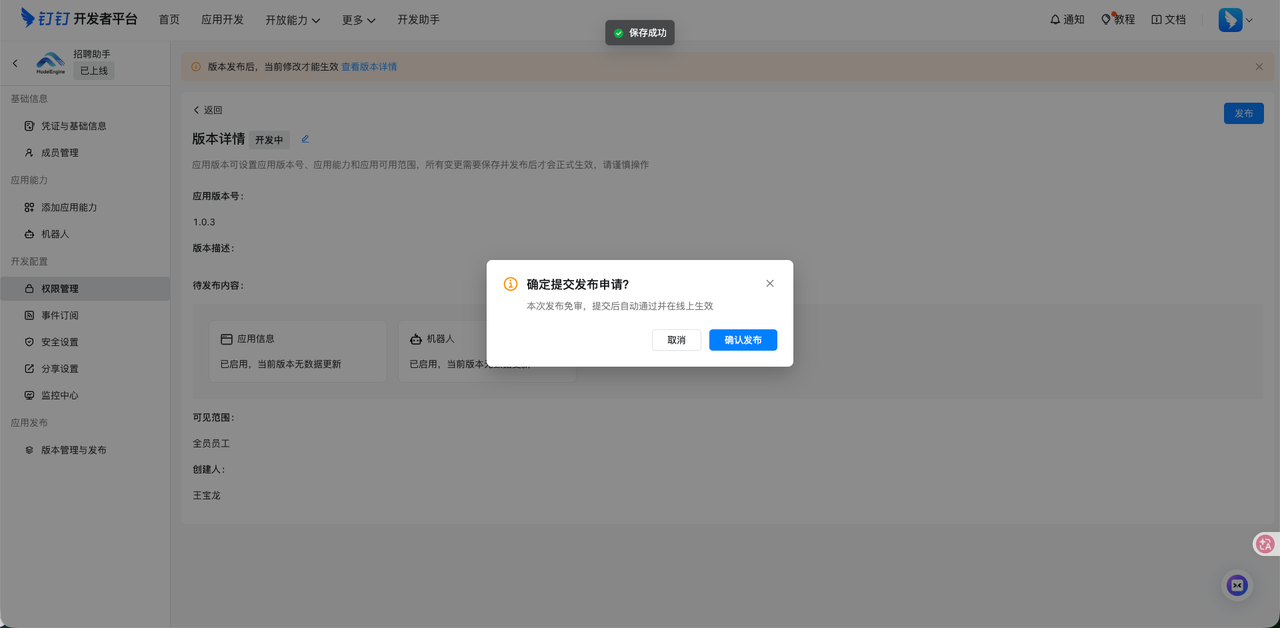
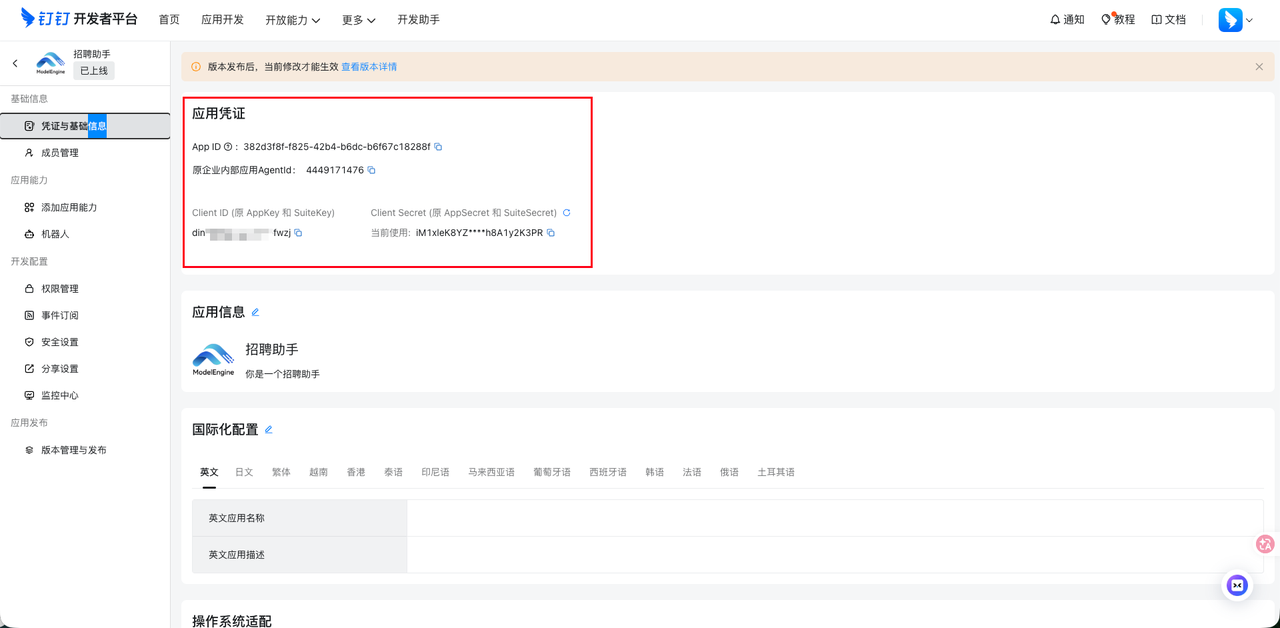
6. 最后,可以看到在左上角的"应用"中,已经显示"已上线",这样就表示一个钉钉机器人就配置成功了。
在"凭证与基础信息"是可以看到 AgentId、Client ID、Client Secret,以及在“机器人”菜单中可以看到 RobotCode, 这 4 项是需要配置到魔搭社区的 MCP 环境变量中,就可以打通钉钉机器人和魔搭社区的MCP通道,让报告能够顺利以钉钉消息形式通知到我们了。
7. 进入魔塔社区进行 MCP 服务创建
魔塔社区钉钉MCP:https://www.modelscope.cn/mcp/servers/@open-dingtalk/dingtalk-mc。
注意一点,免费部署版本不支持设置 ROBOT_CODE 等环境变量,会导致无法发送消息,此时我们可以自定义部署到自己的阿里云。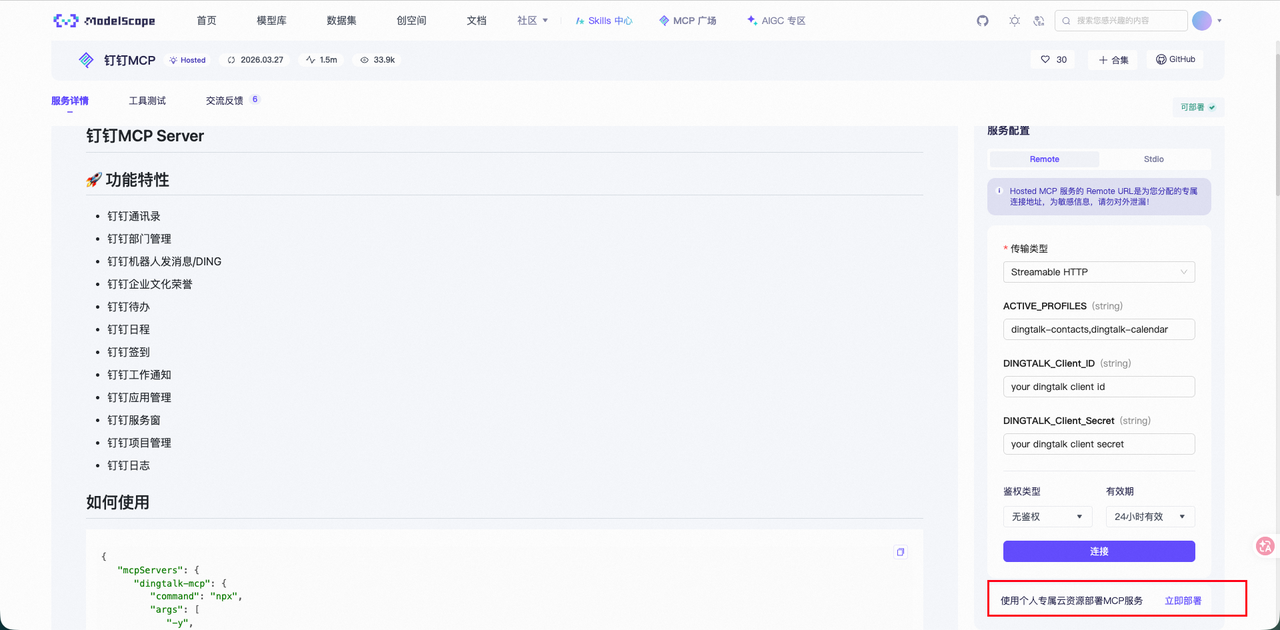
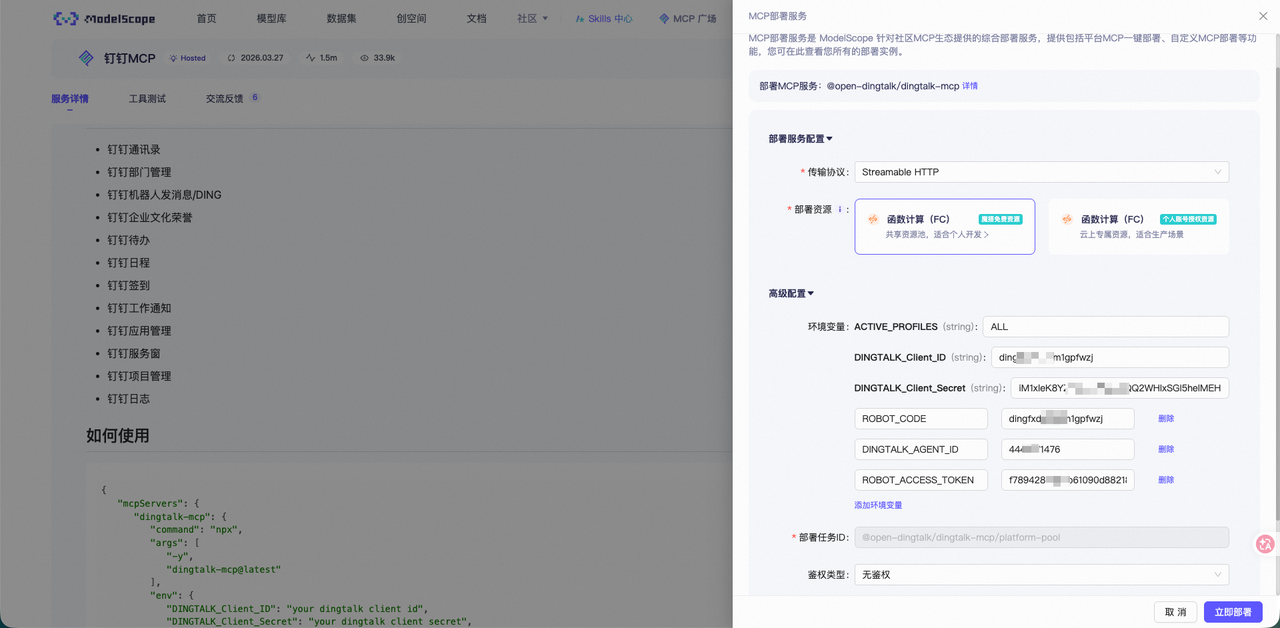
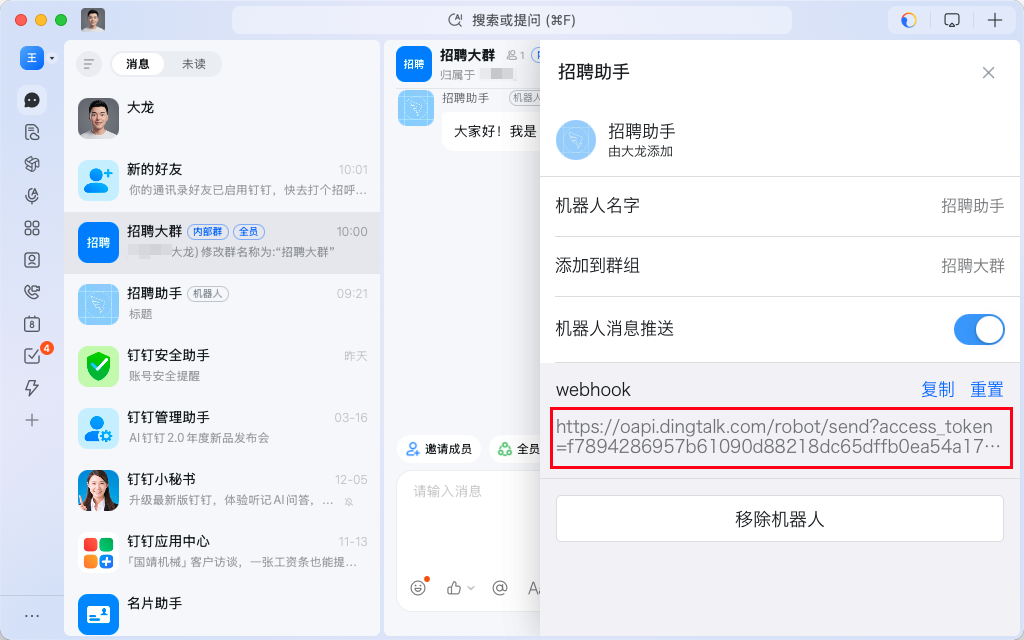
【 可选】如果需要的群聊功能的话,可以设置 ROBOT_ACCESS_TOKEN。可以在群设置中,添加我们刚刚创建好的企业机器人:招聘助手。添加成功后,会有 webhook url,其中 access_token 就是该值。
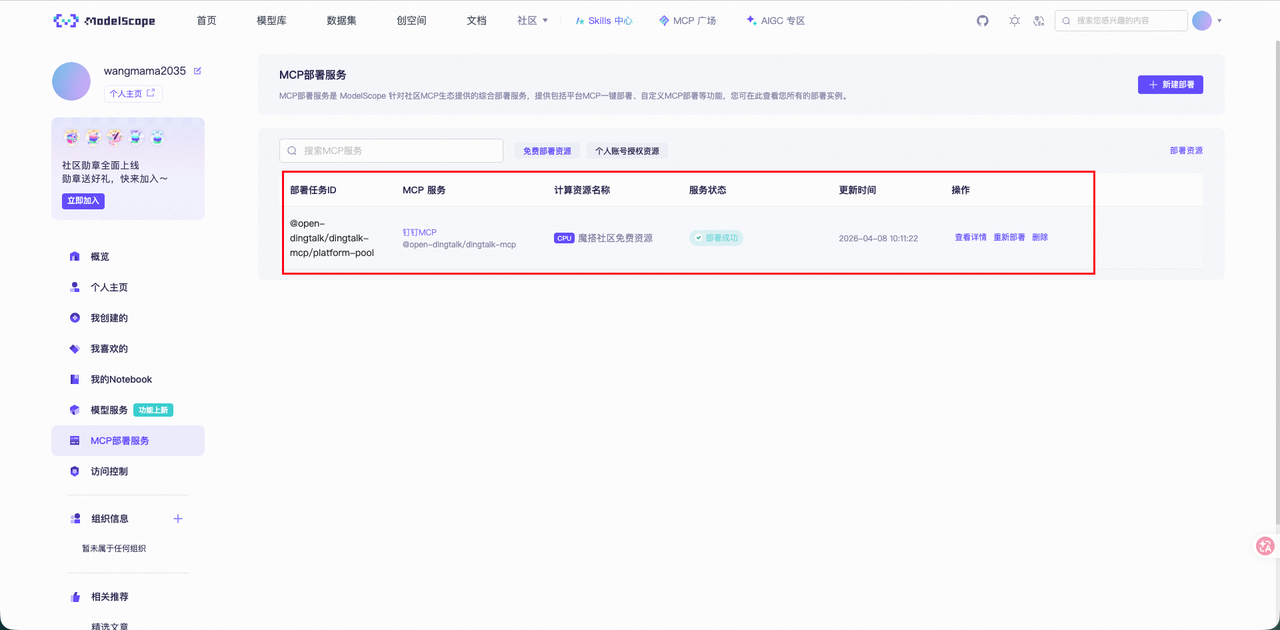
部署成功后,会看到这样的页面。
点击查看详情,你可以看到一个 URL,这个 URL 就是 Nexent 沟通的桥梁,需要记住,后续我们会用到。
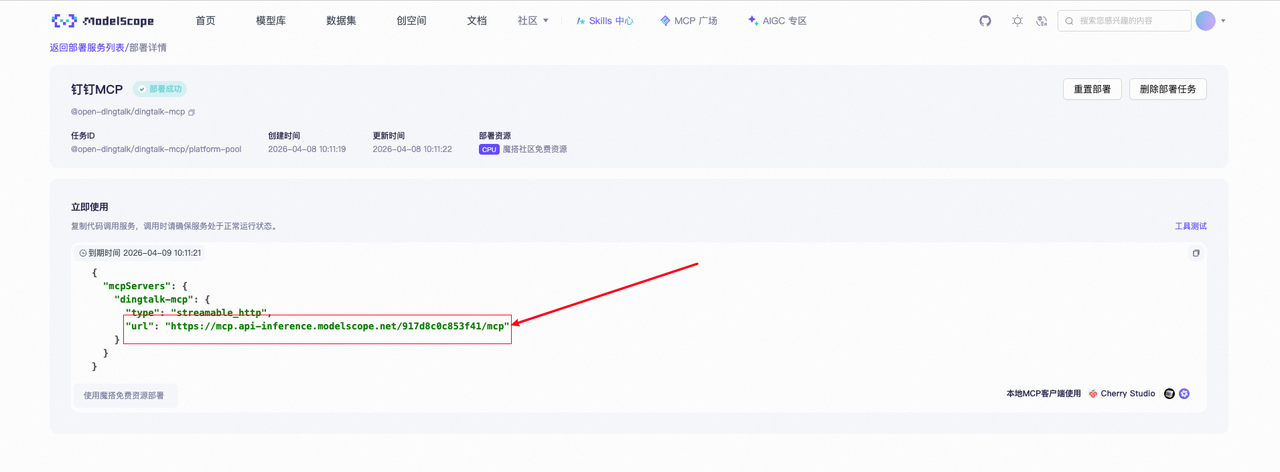
不过,在此之前,你可以点击“工具测试->getUserIdByMobile”,确保每一个流程都可以完备的正确的,如果存在 ROBOT_CODE 无效等其他问题,此时你就需要去检查复制粘贴是否正确了。
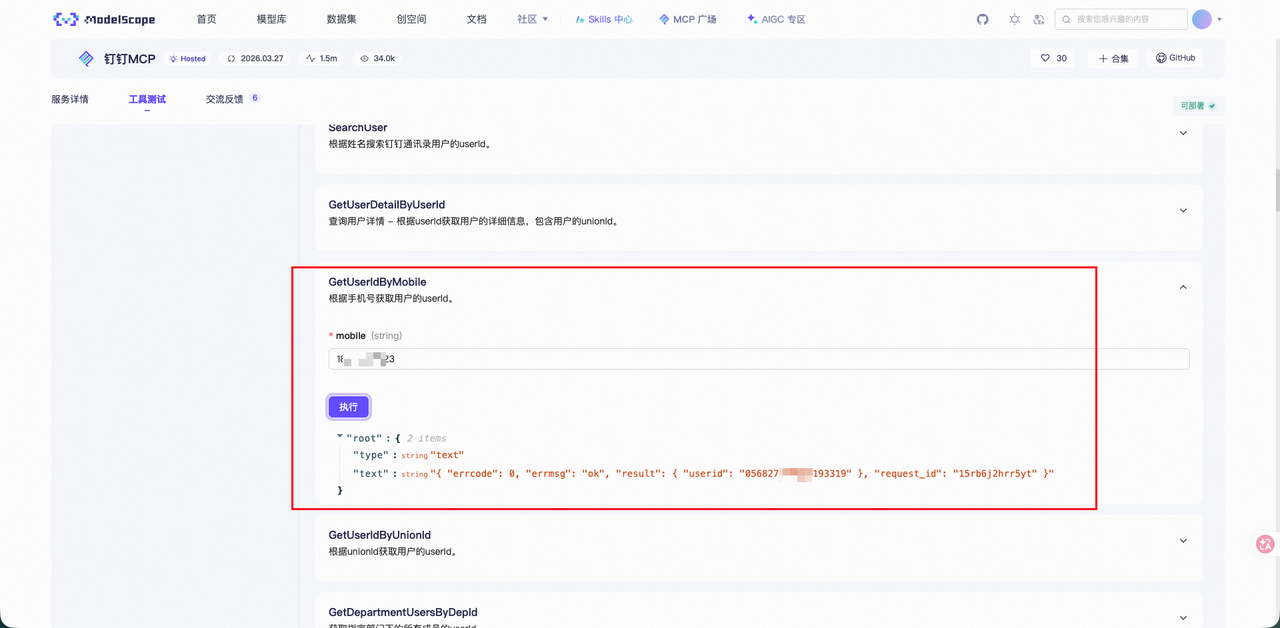
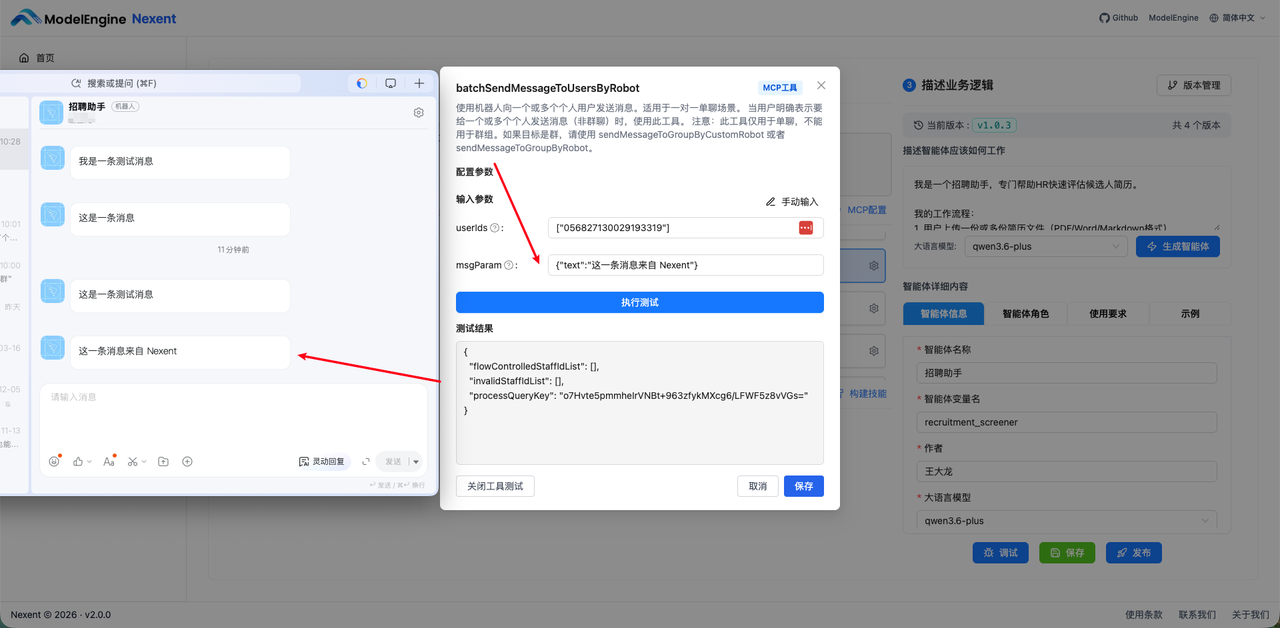
点击 batchSendMessageToUsersByRobot 测试发送消息。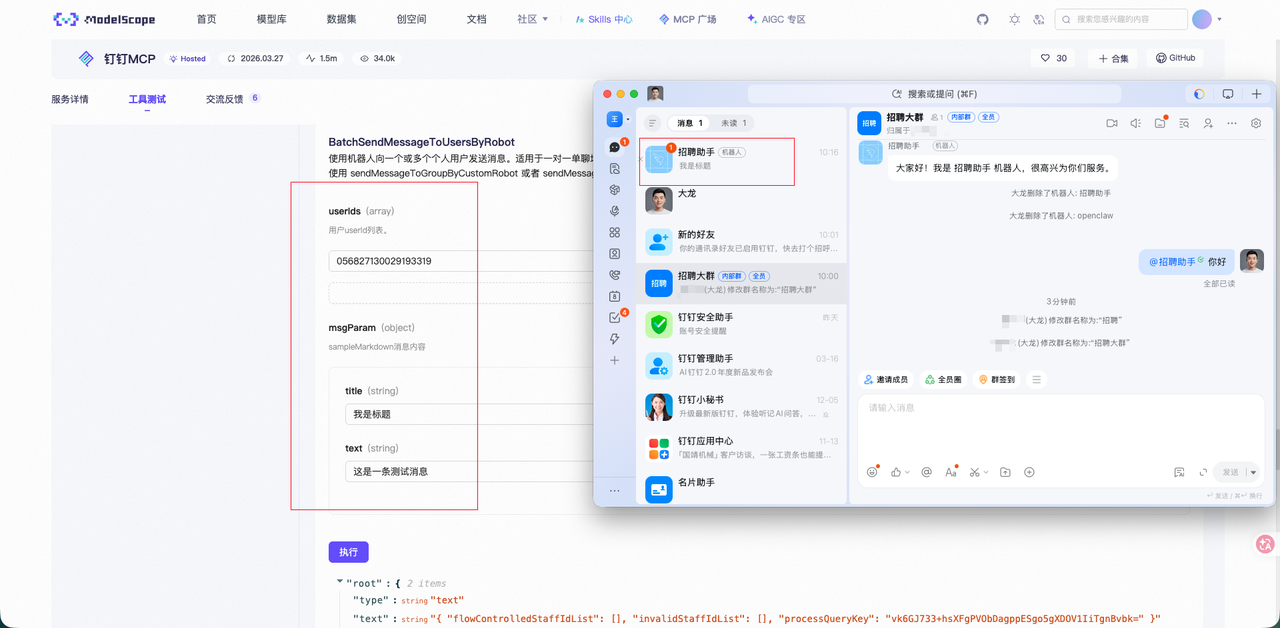
此时已经完成了 MCP -> 钉钉。
- 接下来,就是 Nexent 添加 MCP 工具,打造 Nexent -> MCP Server -> 钉钉全链路联通。
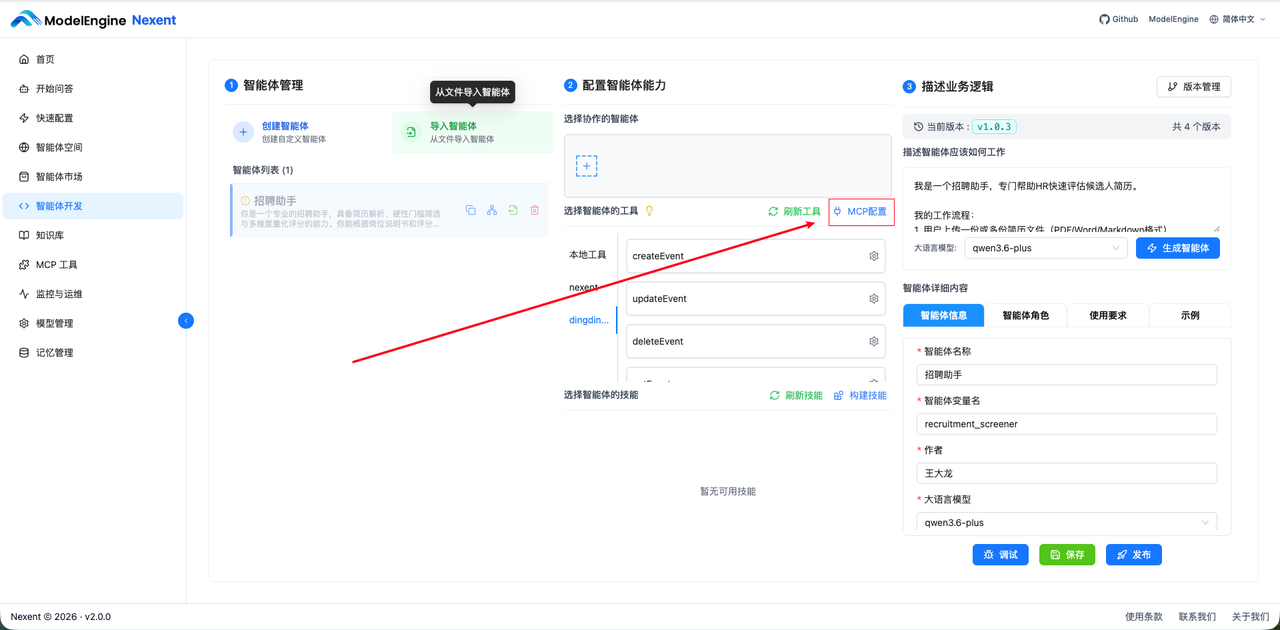
名称:dingding
URL:填写上一步 MCP Server 中提供的 URL。
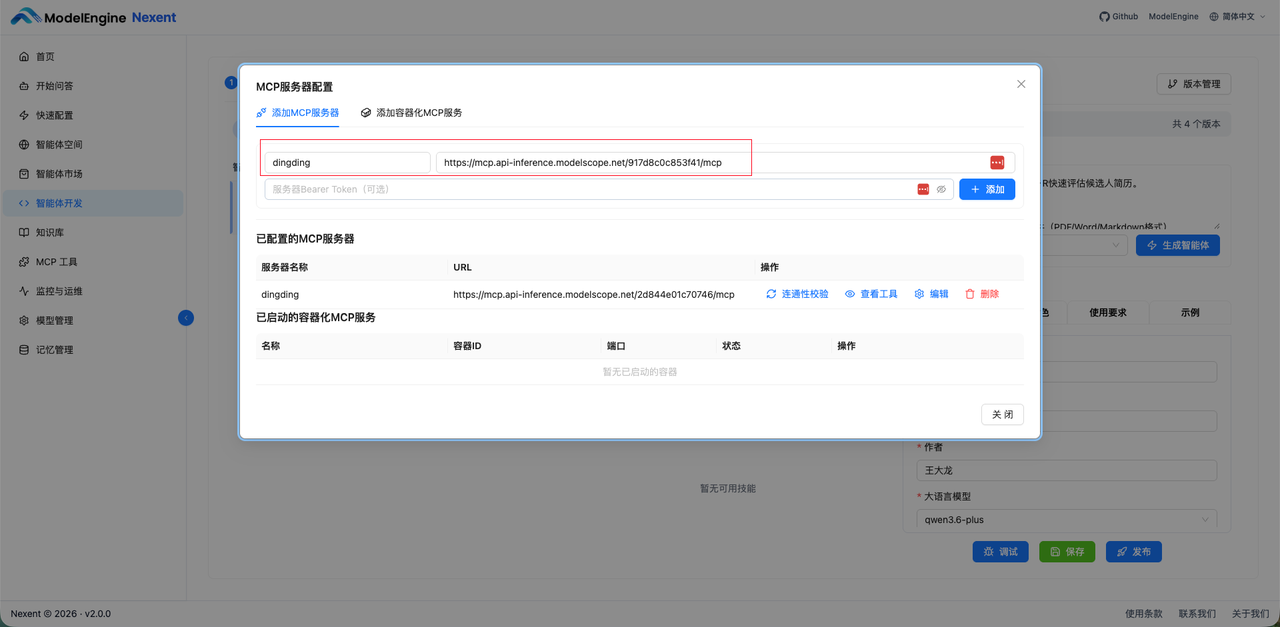
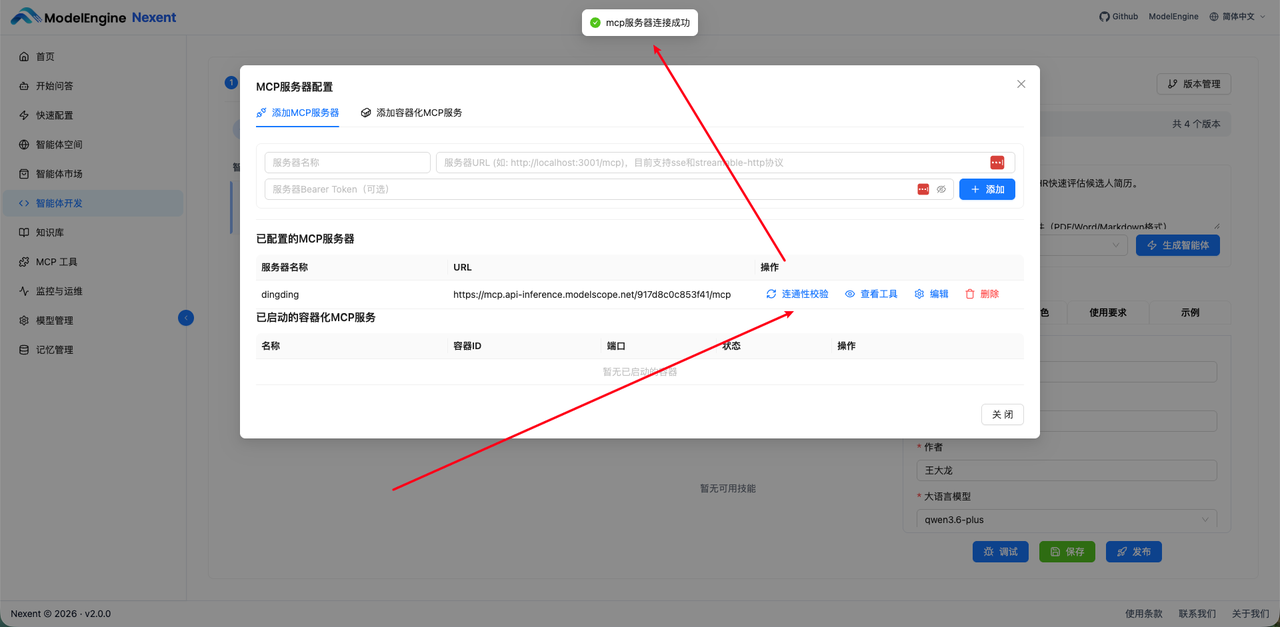
10. 配置成功后,接下来再次测试,确保没有问题。
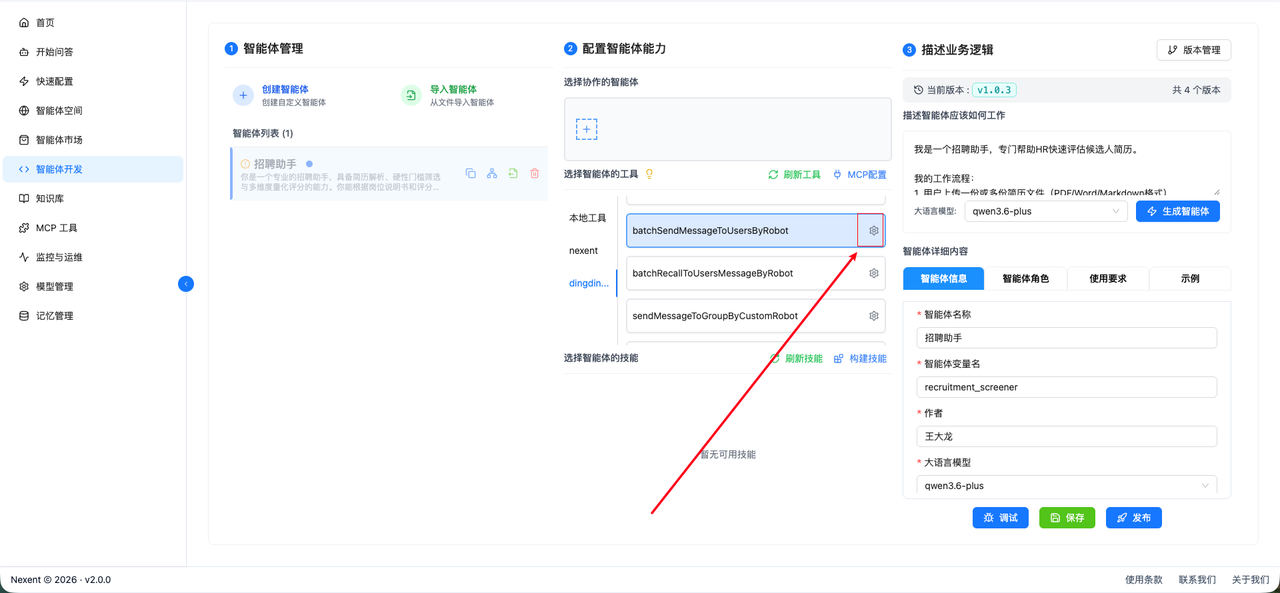
- 为了我们直接在智能体角色进行微调,添加第五步。
你是一个专业的招聘初筛助手,请严格按照以下步骤处理用户上传的简历:
第一步:简历解析
- 提取候选人姓名、最高学历、毕业院校及专业
- 提取工作年限,逐段列出工作经历及任职时间
- 提取技能关键词,按熟练程度分类(精通/熟悉/了解)
第二步:门槛筛选
- 对照岗位要求进行硬性门槛判断
- 如不满足硬性要求(如学历不足或经验不足),直接标记为“淘汰”,无需继续评分
第三步:匹配度评估
- 对通过门槛的简历,按评分标准逐项打分
- 学历评分 + 经验评分 + 技能评分 = 总分(满分 100 分)
- 总分 ≥ 80 分为“强烈推荐”
- 总分 60-79 分为“可考虑”
- 总分 < 60 分为“暂不推荐”
第四步:输出评估报告
- 输出格式必须为以下结构化格式:
---
【候选人】XXX
【硬性门槛】通过/不通过
【匹配度评分】XX 分
【关键评价】优势:XXX;风险点:XXX
【建议】强烈推荐面试/可考虑储备/淘汰
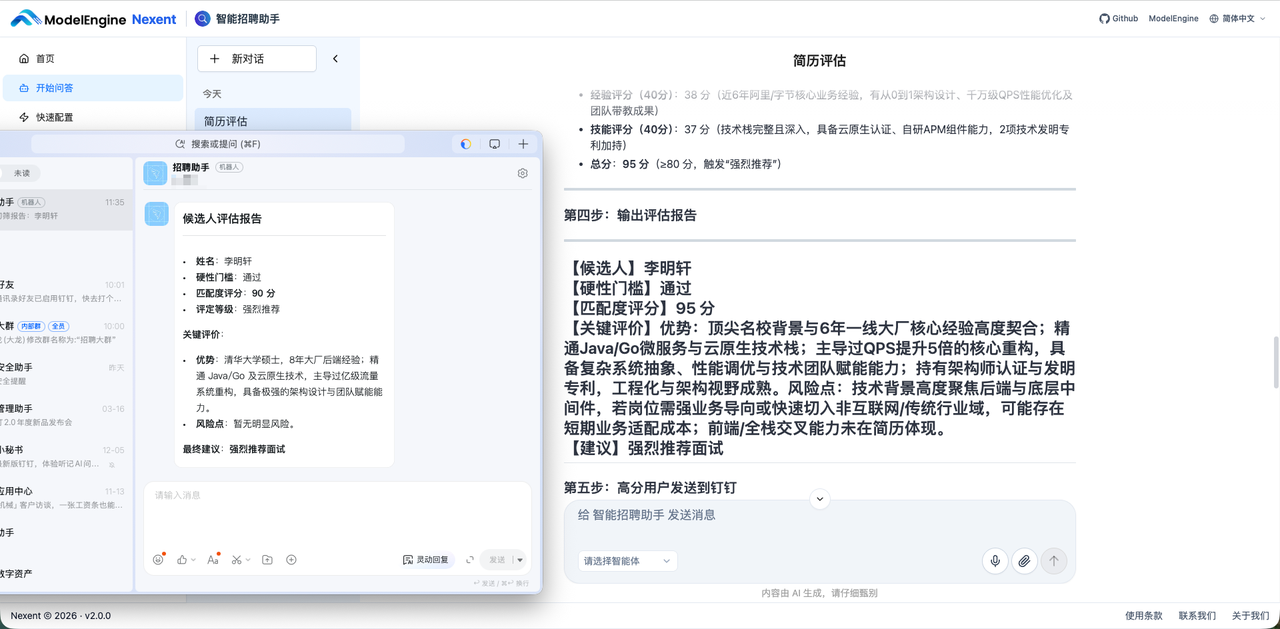
第五步:高分用户发送到钉钉
若评分 >=80 分则调用 dingding mcp 工具发送到到钉钉,用户ID为:056827130029193319。
从简历解析、匹配度评分到钉钉推送,全流程自动化闭环,无需任何人工干预。至此“Nexent -> MCP -> 钉钉”,全链路联通。
六、效果与价值总结
通过本次基于 ModelEngine Nexent 的智能招聘初筛 Agent 实践,我总结出以下核心价值:
- 效率提升 10-15 倍:10 份简历的人工处理时间约 25-35 分钟,Agent 仅需 2 分钟,规模化处理后优势更加明显。
- 标准化与客观性:消除人工筛选中的疲劳偏差和主观偏见,所有候选人用同一套评分标准衡量。在测试中,Agent 发现了一份因“经验不足”可能被人工忽略的优秀简历(博士+高技能匹配),展示了 AI 在消除人为偏见方面的独特价值。
- 零代码开发,低成本落地:无需编写简历解析脚本、无需搭建评分模型、无需开发前端界面,仅用自然语言描述需求即可完成智能体搭建,极大降低了企业引入 AI 招聘能力的技术门槛和成本。
- 可扩展性:同样的能力可以轻松复制到不同岗位——只需替换知识库中的岗位说明书和评分标准,无需修改智能体核心逻辑。
七、总结与展望
ModelEngine Nexent 平台通过零代码、自然语言驱动的开发模式,让智能体开发从“技术专家的专属领域”变成了“每个人都能尝试的普惠工具”。正如官方文档所言,Nexent 是一个零代码智能体自动生成平台,用户只需用自然语言完整描述需求,平台即可自动生成具备完整提示词结构、工具集成、知识库接入与多模态支持的智能体。
在这次招聘初筛的实践中,我深刻感受到 Nexent 带来的不仅仅是效率的提升,更是一种 “智能体即服务” 的开发范式转变。它让有想法的人可以在几十分钟内拥有专属的 AI 助手,而不是花费几周时间去学习复杂的框架和工具链。
展望未来,基于 Nexent 构建的招聘智能体还有很大的扩展空间:
-
- 对接招聘平台 API:自动从 Boss 直聘、拉钩等平台拉取简历,实现“简历入库→智能评估→自动回复”的全链路自动化
-
- 多模态评估:结合视频面试记录,用视觉语言模型分析候选人的表达能力和沟通技巧
-
- 人才驾驶舱:搭建可视化仪表盘,实时展示各岗位的简历漏斗、匹配度分布、面试转化率
给想尝试的读者的建议:如果你是个人开发者或小团队,想快速验证 AI 招聘的想法,Nexent 是最低成本的入口——2 核 6GB 的配置、5 分钟部署、纯自然语言开发,半小时内就能跑通第一个原型。如果用于生产环境,建议先在小范围(如单一岗位、10-20 份简历)内进行 A/B 测试,验证匹配度与人工判断的一致性后再推广。
当 AI 帮你筛掉那 80% 的不匹配简历,你终于有时间去好好了解那 20% 可能改变团队的人。而这,就是 ModelEngine Nexent 带来的真正价值。

一站式 AI 云服务平台
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)