
考研复习Day 15 | 数据结构与算法 --串
一、串的定义和实现
1.1 串的定义
串(String):由零个或多个字符组成的有限序列,通常记为:
S = 'a₁ a₂ … aₙ' (n ≥ 0)
| 术语 | 说明 |
|---|---|
| S | 串名 |
| 单引号内的序列 | 串的值 |
| n | 串的长度 |
| 空串 | n=0,用∅表示 |
| 空格串 | 由一个或多个空格字符组成,不是空串 |
| 子串 | 串中任意多个连续字符组成的子序列 |
| 主串 | 包含子串的串 |
| 位置 | 字符在串中的序号;子串位置以其第一个字符的位置标识 |
| 串相等 | 两个串长度相等,且对应位置字符完全相同 |
串与线性表的区别:
串的数据对象被限定为字符集
线性表的基本操作以单个元素为单位
串的基本操作以子串为单位
1.2 串的基本操作
| 操作 | 描述 |
|---|---|
StrAssign(&T, chars) |
赋值操作,将串T赋值为chars |
StrCopy(&T, S) |
复制操作,将串S复制给T |
StrEmpty(S) |
判空操作 |
StrCompare(S, T) |
比较操作:S>T返回>0;S=T返回0;S<T返回<0 |
StrLength(S) |
求串长 |
SubString(&Sub, S, pos, len) |
求子串,用Sub返回S中从pos起长度为len的子串 |
Concat(&T, S1, S2) |
串联接,用T返回S1+S2 |
Index(S, T) |
定位操作,返回T在S中首次出现的位置 |
ClearString(&S) |
清空操作 |
DestroyString(&S) |
销毁操作 |
最小操作子集:
StrAssign、StrCompare、StrLength、Concat、SubString这五种操作无法通过其他串操作实现,其余串操作均可基于它们实现。
1.3 串的存储结构
1. 定长顺序存储表示
#define MAXLEN 255
typedef struct {
char ch[MAXLEN]; // 每个分量存储一个字符
int length; // 串的实际长度
} SString;注意:串的实际长度不得超过MAXLEN,超出部分会被截断。
串长的两种表示方式:
-
用独立的整型变量
length显式记录 -
在串值末尾添加结束标记符
'\0'(串长为隐含值,需遍历计算)
2. 堆分配存储表示
typedef struct {
char *ch; // 按串长分配存储区,ch指向串的基地址
int length; // 串的长度
} HString;特点:存储空间在程序运行过程中动态申请获得,通过
malloc()分配,free()释放。
3. 块链存储表示
每个链表结点可存放一个或多个字符,每个结点称为一个块。
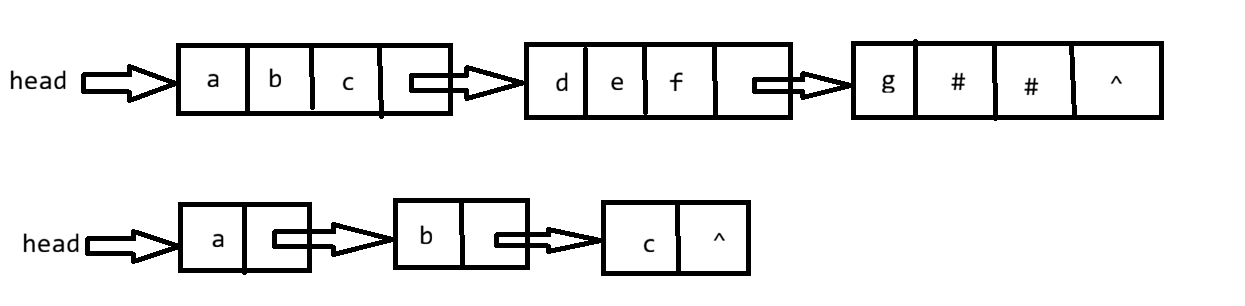
| 块大小 | 特点 |
|---|---|
| 块大小为1 | 每个结点存1个字符(链式存储的极端形式) |
| 块大小>1 | 每个结点存多个字符,最后一块用#补齐 |
二、串的模式匹配
2.1 简单的模式匹配算法
模式匹配:在主串中查找与模式串完全相同的子串,并返回其首次出现的位置。
int Index(SString S, SString T) {
int i = 1, j = 1;
while (i <= S.length && j <= T.length) {
if (S.ch[i] == T.ch[j]) {
++i; ++j; // 继续比较后继字符
} else {
i = i - j + 2; // 主串指针后退
j = 1; // 模式串指针重置
}
}
if (j > T.length)
return i - T.length; // 匹配成功
else
return 0; // 匹配失败
}算法思想:
-
从主串S的第一个字符开始,与模式串T的首字符比较
-
若相等,继续比较后续字符
-
若不相等,主串比较起点后移一位,模式串从头开始
-
重复直到匹配成功或遍历完主串
时间复杂度:
-
最坏情况:O(n×m)
-
例如:主串
'000...001'(45个0),模式串'000...01'(6个0后跟1),比较次数约40×7=280次
2.2 KMP算法
KMP算法的核心思想:利用已匹配成功的部分信息,主串指针不回溯,仅模式串指针j调整,从而提高效率。
1. 前缀、后缀和部分匹配值
| 概念 | 定义 |
|---|---|
| 前缀 | 除最后一个字符外,字符串的所有头部子串 |
| 后缀 | 除第一个字符外,字符串的所有尾部子串 |
| 部分匹配值(PM) | 字符串的前缀和后缀的最长相等前后缀长度 |
示例:以'ababa'为例
| 子串 | 前缀集合 | 后缀集合 | 交集 | PM值 |
|---|---|---|---|---|
'a' |
∅ | ∅ | ∅ | 0 |
'ab' |
{a} | {b} | ∅ | 0 |
'aba' |
{a, ab} | {a, ba} | {a} | 1 |
'abab' |
{a, ab, aba} | {b, ab, bab} | {ab} | 2 |
'ababa' |
{a, ab, aba, abab} | {a, ba, aba, baba} | {a, aba} | 3 |
2. PM表的作用
以主串'ababcabcacbab',模式串'abcac'为例:
| 编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 模式串 | a | b | c | a | c |
| PM | 0 | 0 | 0 | 1 | 0 |
右滑位数公式:
右滑位数 = 已匹配字符数 - 对应的部分匹配值
匹配过程:
-
第一趟:第3位失配,已匹配2个字符
'ab',PM=0 → 右滑2位(2-PM [2]=2) -
第二趟:第5位失配,已匹配4个字符
'abca',PM=1 → 右滑3位(4-PM [4]=3) -
第三趟:全部匹配成功
核心价值:PM表指导模式串在失配后的最优右移距离,主串指针始终不回溯。
3. next数组的手算方法
next[j]的含义:当模式串的第j个字符失配时,下一轮应从模式串的第next[j]个字符开始与主串当前位置比较。
推导关系:
右滑位数 = j - 1 - PM[j-1]
next[j] = j - 右滑位数 = PM[j-1] + 1
next数组求法:将PM表右移一位,再整体加1。
| 编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 模式串 | a | b | c | a | c |
| PM | 0 | 0 | 0 | 1 | 0 |
| 右移一位 | 0 | 0 | 0 | 0 | 1 |
| next | 0+1=1 | 0+1=1 | 0+1=1 | 0+1=1 | 1+1=2 |
固定规则:
-
next[1] = 0(模式串首字符失配,主串和模式串同步右移一位) -
next[2] = 1(第二个字符失配,模式串下次从第1个字符开始比较)
4. next数组的推理公式
设next[j] = k,则模式串前k-1个字符与后k-1个字符相等:
![]()
递推关系:
-
若
p_k = p_j,则next[j+1] = k+1 = next[j] + 1 -
若
p_k ≠ p_j,则继续向前找更小的k' = next[k],直到找到匹配或k'=0
5. KMP算法的实现
int Index_KMP(SString S, SString T, int next[]) {
int i = 1, j = 1;
while (i <= S.length && j <= T.length) {
if (j == 0 || S.ch[i] == T.ch[j]) {
++i; ++j; // 继续比较后继字符
} else {
j = next[j]; // 模式串向右滑动
}
}
if (j > T.length)
return i - T.length; // 匹配成功
else
return 0; // 匹配失败
}注意:当
j=0时,表示模式串首字符失配,将主串指针和模式串指针同时加1。
时间复杂度:O(n+m)
2.3 KMP算法的进一步优化(nextval数组)
问题:当
p_j = p_{next[j]}时,回退后仍然会用相同的字符去匹配,必然再次失配,造成不必要的比较。
解决方案:将next[j]修正为next[next[j]],直到p_j ≠ p_k或k=0,修正后的数组称为nextval数组。
示例:模式串'aaaab'
| 编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 模式串 | a | a | a | a | b |
| next | 0 | 1 | 2 | 3 | 4 |
| nextval | 0 | 0 | 0 | 0 | 4 |
计算规则:
nextval[1] = 0若
p_j = p_{next[j]},则nextval[j] = nextval[next[j]]否则,
nextval[j] = next[j]
三、思考
3.1 小小的思考
1. 串 ≈ 文本处理的基本单位
你在Word里搜索一个词,搜索引擎里输入关键词,本质上都是串的模式匹配。
2. KMP算法 ≈ 查找时的“记忆”能力
一部分人查字典时,如果发现当前页没有要找的字,会翻到下一页从头找(简单匹配)。而有的人人会记住“这一页末尾的偏旁是什么”,然后直接跳到可能的位置(KMP)。
3. next数组 ≈ 失配时的“备忘录”
每次匹配失败后,不是完全从头开始,而是根据备忘录(next数组)告诉“可以从哪里继续”。
3.2 关于“KMP人生哲学”
今天学习的时候偶然看见了一句话,大致是:一个人走多远不是看你在顺境中走多快,而是看在逆境中能不能更快的找到原本的自己,这不正是KMP的核心哲学思想,也是人生的哲学吗?
“一个人走多远不是看你在顺境中走多快”。
-
KMP中:匹配顺利时(顺境),大家都很快,暴力匹配也一样快。单纯的“快”不是优势。
-
人生中:顺风顺水时,谁都能走几步。这并不能区分人与人的差距。
“而是看在逆境中能不能更快的找到原本的自己”
-
KMP中:“逆境”就是发生失配(不匹配)的瞬间。 这时,暴力匹配会慌乱地回到起点,一切归零。而KMP会冷静地利用已经匹配成功的信息(前缀和后缀),快速回溯到“原本的自己”——也就是那个最长的、已经匹配好的前缀位置,从而避免从零开始。
-
人生中:当遇到挫折、失败(逆境),你是彻底否定自己,从零开始(暴力匹配),还是能冷静复盘,利用过去的经验和积累(已匹配的信息),快速找到自己真正的定位和价值,重新站起来?
“这不正是KMP吗,即使前面匹配再快,一旦出现不匹配的情况,那就看是谁更快的找到原本自己该匹配的情况”
-
KMP中:这正是
next数组干的事。它告诉你:“别慌,你不需要回到起点。你之前走过的路没有白费,从这里继续就好。” -
人生中:这才是真正的智慧。不是不跌倒,而是跌倒后,能最快地找到自己的节奏和方向,而不是每次都推倒重来。
KMP的两个灵魂:
-
不回溯(不沉溺于过去):主指针
i不回退,意味着不被过去的失败拖累,继续向前看。 -
智能回退(找到原本的自己):模式串指针
j根据next数组回退,意味着从过去的经验(已匹配的前缀)中,找到东山再起的最佳位置,而不是彻底否定自己。
暴力匹配的人生观是:“错了?那就全部推倒,重头再来。”
KMP的人生观是:“错了?没关系。看看之前做对了什么,从这里继续。”
你,是哪一个呢?
注:以上内容参考 2027年数据结构考研复习指导 王道论坛 组编,其中有一些个人想法,如有任何错误或不妥,欢迎各位大佬指出,如果各位有一些有意思的想法,也可以和我交流一下~感谢!
四、明日计划
树与二叉树(上):(二叉)树的概念、二叉树的遍历、线索二叉树

一站式 AI 云服务平台
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)