
【算法竞赛】Kmp算法:两种方法解决字符串匹配问题
本文目录
例题地址
一. Kmp算法用来干什么的?
Kmp算法是用在字符串的匹配中的,假如现在给你字符串s和t长度分别是n和m,你需要判断t是否是s的子串如果是最普通的暴力枚举让t每一个字符都去匹配
不难看出时间复杂度最坏可以到达O(n*m) 的,但Kmp算法可以使得字符串的匹配的时间复杂度减少到O(n+m)
二. 相关概念认识
基础概念
现有一个字符串s=“bcbcbdbcbe”
前缀:从s的第一个字符开始到s的任意位置的字符串为其前缀 例如:bcbcbd
后缀:从s的最后一个字符开始到s的任意位置的字符串为其后缀 例如:bcbe
真前缀:和前缀一样,但是s的真后缀不能和s相等
真后缀:和后缀一样,但是s的真后缀不能和s相等
真公共前后缀(border):同时是s的真前缀和真后缀
最长真公共前后缀:一个字符串的最长的border
这上面几个概念一定要理解不然之后的内容很难看懂,特别是真公共前后缀(之后都叫它border)是Kmp算法的核心,同时后面还需要算最长真公共前缀后
//border演示
string s="ababa";
//此时s的border有:"a" "ab" "aba"
string s1="accbae";
//此时s1没有border
string s2="aaaaa";
//此时s2的border有:"a" "aa" "aaa" "aaaa"
进阶概念
现在你理解了border的含义之后,我们可以发现一个规律:border的border也是自己的border
假设下面图片代表的是一个任意的字符串s,它有一个长度为6的border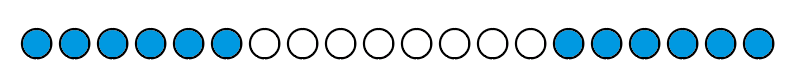 我们就可以知道两个蓝色的地方完全相等且border代表的字符串长度是6,假如现在这个长度为6的字符串也有自己的border
我们就可以知道两个蓝色的地方完全相等且border代表的字符串长度是6,假如现在这个长度为6的字符串也有自己的border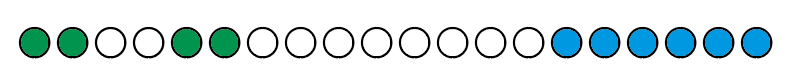
即这个绿色部分就是长度为6的字符串的border,由上面我们可以知道因为一开始的两个蓝色的字符串相等,所以它们自己有的border应该也是相等的即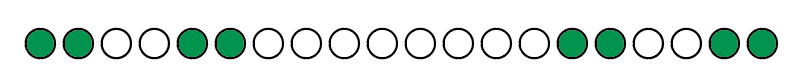
所以我们就可以看出来,这个绿色代表的字符串也是s的border长度为2,而且它又是蓝色代表字符串的border,所以我们就得出了结论:一个字符串的border的border也是它本身的border
三. 最长真公共前后缀数组(Kmp算法核心)
现在就是Kmp算法的最核心的地方,如果理解了这里那么Kmp算法也基本上没什么问题了
最长真公共前后缀数组含义
最长真公共前后缀数组pi[i]代表的含义:一个字符串s以第i位为结尾时的最长的真公共前后缀
例如:字符串s=" ababca";
小技巧:
我们为了写代码的时候方便会在字符串的最前面加上一个‘空格’这样字符串的有效字符就从下标为1开始了
此时它对应的数组pi[1]就等于0,因为字符串“a”只有一个字符肯定是没有border
pi[2]也是为0因为字符串“ab”没有border,pi[3]=1因为字符串“aba”中有一个长度为1的border“a”,所以以此类推就可以得出pi[4]=2…
推导pi数组一般规律
由前面我们知道了一个性质就是一个字符串的border的border也是这个字符串的border且因为数组是从前往后填的所以当我们填到i位置时前面[1,i-1]的pi都已经是知道的了那么此时,假设pi[i-1]=5
所以图中目标字符串标蓝色的地方就全部都是相等的,我们要找到i位置的最长的border就可以比较s[ i ](这里的字符串s是一个任意的字符串和上面的不同)是否等于s[5+1]也就是i-1位置的最长border的长度(我们用j来表示)的后一个位置,因为如果这两个位置相等的话那就是下图的情况
所以就可以得出pi[i]=j+1,那如果是不相等呢?![s[i]和s[j+1]不相等的情况](https://i-blog.csdnimg.cn/direct/4a658c3724774908b44276577d36cd4e.png)
这就用到了上面的性质我们可以去找j位置的border假如pi[j]等于2,就如下图的情况此时j位置的border为2,我们再把2赋值给j,所以此时还是比较s[ i ]是否等于s[j+1]
//如果一直匹配不上就通过性质一直往前找更小的border
while(j>0 && s[i]!=s[j+1]) j=pi[j];

如果相等的话那么pi[i]=j+1;不相等的话就继续找更小的border,当j等于0时还要再确定一次s[j+1]是否等于s[i],就是确保s[1]会等于s[i]的情况
为什么第一次匹配上字符算出来的就是i位置的最大border?
因为pi数组表示的是每个子串的最大的border,所以当填i位置时pi[i-1]放的就是i-1位置的最长border,如果i位置想要找border肯定是先看i-1位置的border,此时pi[i-1]放的就是i-1位置最长的border,直接匹配上了那肯定就是最大值,如果一开始没有匹配上就继续找i-1位置border的border去匹配字符,因为border的border位置放的也是最大border的长度,所以第一次匹配到字符时,算出来的就是最大值
代码实现
#include<iostream>
using namespace std;
const int N=1e6+10;
string s;
int pi[N]; //初始化全为0
void get_border()
{
int n = s.size();
s = ' ' + s;
pi[1] = 0; //第一个位置border肯定是0的
for(int i = 2; i <= n; i++)
{
int j = pi[i-1];
while(j > 0 && s[j+1] != s[i]) j = pi[j];
if(s[j+1] == s[i]) j++; //匹配上了的话i位置的最长border就是原先的j+1
pi[i] = j;
}
}
四. Kmp算法应用【Kmp算法模板】
前面我们已经说了Kmp算法主要是用来解决字符串匹配问题的,所以现在再回归到这个问题,给你一个主字符串s和模式串t,找出t在s中每次出现的位置
解法
1.将字符串t和字符串s拼接起来但是衔接处需要加上一个陌生字符(这里说的陌生字符指的是一定不会在s和t中出现的字符 例如‘#’),拼接顺序为:t->陌生字符->s
2.求这个拼接后的字符串的最长真公共前后缀数组,当发现某个位置的最长border刚好是t的长度时,但是此时不是t在s中出现的位置,具体见下图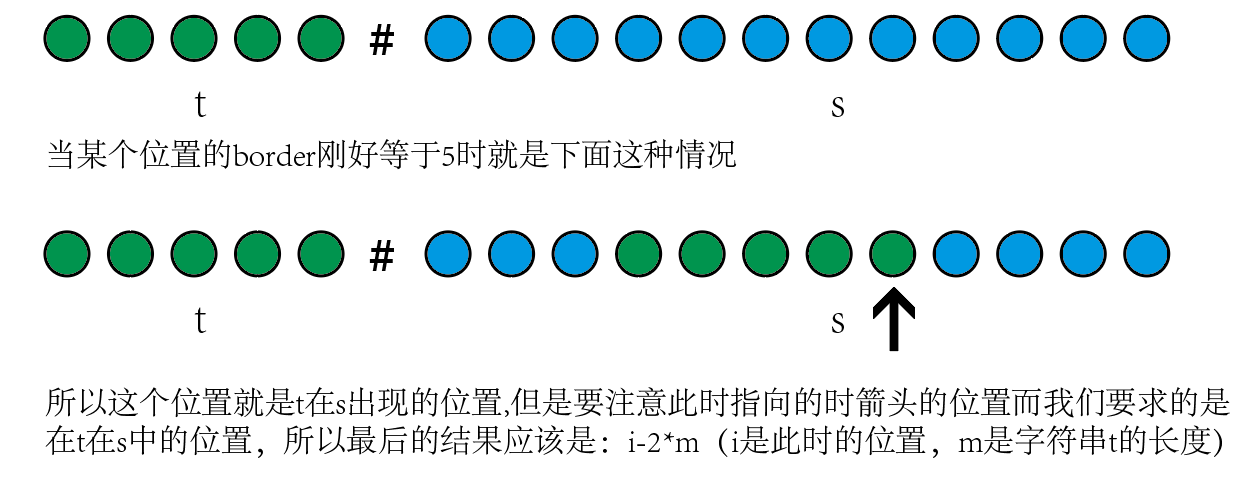
代码实现【Kmp算法模板】
#include<iostream>
using namespace std;
const int N = 2e6 + 10;
int pi[N];
int main()
{
string s, t;
cin >> s >> t;
string s = t + "#" + s;
int n = s.size();
s = ' ' + s;
//填表
for (int i = 2; i <= n; i++)
{
int j = pi[i - 1];
while (j > 0 && s[j + 1] != s[i]) j = pi[j];
if (s[j + 1] == s[i]) j++;
pi[i] = j;
}
//字串t的长度
int m = t.size();
for (int i = 1; i <= n; i++)
{
if (pi[i] == m) cout << i - 2 * m << endl;
}
return 0;
}
next数组版本
大部分的教材或者视频教程的kmp算法使用的都是next数组版本,看似两个是不一样的解法,其实这两个实现kmp算法的本质都是一样的,主要的核心都是找到最长的border
不过next数组的版本算的是模式串p的最长border,然后直接通过和主串s比较来匹配,下面给出代码
#include<iostream>
using namespace std;
const int N = 1e6 + 10;
int ne[N];
int n, m;
string s, t;
int main()
{
cin >> s >> t;
n = s.size();
m = t.size();
s = ' ' + s;
t = ' ' + t;
for (int i = 2; i <= m; i++)
{
int j = ne[i - 1];
while (j && t[j + 1] != t[i]) j = ne[j];
if (t[j + 1] == t[i]) j++;
ne[i] = j;
//cout << ne[i] << ' ' << endl;
}
for (int i = 1, j = 0; i <= n; i++)
{
while (j && s[i] != t[j + 1]) j = ne[j];
if (s[i] == t[j + 1]) j++;
if (j == m)
{
cout << i - m + 1 << endl;
}
}
for (int i = 1; i <= m; i++) cout << ne[i] << " ";
return 0;
}
五. 例题
题目链接:
P3375 【模板】KMP
题目描述
给出两个字符串 s 1 s_1 s1 和 s 2 s_2 s2,若 s 1 s_1 s1 的区间 [ l , r ] [l, r] [l,r] 子串与 s 2 s_2 s2 完全相同,则称 s 2 s_2 s2 在 s 1 s_1 s1 中出现了,其出现位置为 l l l。
现在请你求出 s 2 s_2 s2 在 s 1 s_1 s1 中所有出现的位置。
定义一个字符串 s s s 的 border 为 s s s 的一个非 s s s 本身的子串 t t t,满足 t t t 既是 s s s 的前缀,又是 s s s 的后缀。
对于 s 2 s_2 s2,你还需要求出对于其每个前缀 s ′ s' s′ 的最长 border t ′ t' t′ 的长度。
输入格式
第一行为一个字符串,即为 s 1 s_1 s1。
第二行为一个字符串,即为 s 2 s_2 s2。
输出格式
首先输出若干行,每行一个整数,按从小到大的顺序输出 s 2 s_2 s2 在 s 1 s_1 s1 中出现的位置。
最后一行输出 ∣ s 2 ∣ |s_2| ∣s2∣ 个整数,第 i i i 个整数表示 s 2 s_2 s2 的长度为 i i i 的前缀的最长 border 长度。
输入输出样例 #1
输入 #1
ABABABC
ABA
输出 #1
1
3
0 0 1
说明/提示
样例 1 解释
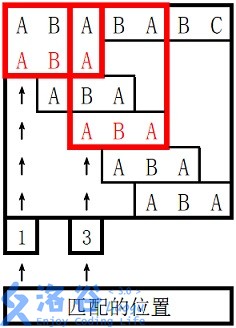 。
。
对于 s 2 s_2 s2 长度为 3 3 3 的前缀 ABA,字符串 A 既是其后缀也是其前缀,且是最长的,因此最长 border 长度为 1 1 1。
数据规模与约定
本题采用多测试点捆绑测试,共有 4 个子任务。
- Subtask 0(30 points): ∣ s 1 ∣ ≤ 15 |s_1| \leq 15 ∣s1∣≤15, ∣ s 2 ∣ ≤ 5 |s_2| \leq 5 ∣s2∣≤5。
- Subtask 1(40 points): ∣ s 1 ∣ ≤ 10 4 |s_1| \leq 10^4 ∣s1∣≤104, ∣ s 2 ∣ ≤ 10 2 |s_2| \leq 10^2 ∣s2∣≤102。
- Subtask 2(30 points):无特殊约定。
- Subtask 3(0 points):Hack。
对于全部的测试点,保证 1 ≤ ∣ s 1 ∣ , ∣ s 2 ∣ ≤ 10 6 1 \leq |s_1|,|s_2| \leq 10^6 1≤∣s1∣,∣s2∣≤106, s 1 , s 2 s_1, s_2 s1,s2 中均只含大写英文字母。
解法
其实这题就是一个Kmp的模板题,但是注意这里还多了一个要求,需要输出我们上面一直说的模式串t的每个位置的最长真公共前后缀数组,所以这题其实求出来拼接字符串的最长真公共前后缀数组也就是解出来了,所以其实最长真公共前后缀数组就是Kmp算法最大的核心
代码实现
题解代码就放在我的gitee仓库里面啦~
gitee仓库地址

一站式 AI 云服务平台
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)