
Java开发者AI转型第十三课!知识库终局方案:Spring AI Vector Store架构演进与ETL全链路入库实战
本文结合 Spring AI 详解向量数据库核心价值,剖析传统数据库向量检索短板。讲解 VectorStore 统一接口设计,完成 SimpleVectorStore 本地内存向量库搭建、JSON 持久化,串联文档解析、文本切分、向量化入库的 ETL 全链路实战。同时演示 Docker 部署 Redis Stack,零代码无缝切换企业级向量库,助力 Java 开发者快速落地私有化 RAG 知识库。
大家好,我是直奔標杆!专注Java开发者AI转型实战分享,和大家一起从零基础吃透Spring AI,少走弯路、直奔技术标杆~
欢迎来到《Spring AI 零基础到实战》专栏第十三课,也是我们RAG全链路实战的关键一环!
在上一节(Java开发者AI转型第十二课!吃透Embeddings向量化:让Java代码读懂文本语义)中,我们一起解锁了AI时代的“文本转码术”——Embedding向量化,成功将普通文本转换成了计算机能理解的高维浮点数矩阵。
但实操过的朋友都懂,新问题随之而来:传统关系型数据库根本“扛不住”这种高维向量!
如果硬把这些浮点数数组塞进MySQL的VARCHAR或JSON字段,后续用户提问时,需要全表扫描所有向量、逐个计算余弦相似度(向量夹角),这种操作不仅效率极低,在实际项目中完全不可落地。
为了解决向量的高效相似度检索难题,AI时代的专属新基建——向量数据库(Vector Database)应运而生,而这也是我们今天的核心主题。
本节课,我们就来打通RAG的最后一公里——L(Load,加载数据入库),借助Spring AI的优雅接口抽象,将前两节课提取、切分好的文档,完整写入向量数据库,彻底完成ETL全链路的知识准备工作,为后续的语义检索打下坚实基础!
本节学习目标(一起打卡进阶)
-
认知升级:搞懂传统关系型数据库在AI检索场景的短板,明确向量数据库的不可替代性,避免踩选型坑;
-
架构吃透:掌握Spring AI VectorStore接口的抽象设计精髓,理解其如何屏蔽底层存储差异;
-
实战落地:上手本地开发利器SimpleVectorStore,实现内存级极速入库与JSON文件持久化,快速验证功能;
-
生产适配:串联ETL全链路代码,演示如何零业务代码修改,热切换到企业级Redis向量数据库,适配生产环境。
VectorStore抽象艺术:Spring AI的“数据库无关”设计
作为Java开发者,我们早就习惯了Spring Data JPA、MyBatis的“屏蔽底层”特性——不用关心底层是MySQL、Oracle还是SQL Server,一套代码适配多种数据库。
Spring AI完美继承了这种设计哲学,推出了VectorStore统一接口,让我们彻底摆脱向量数据库的底层差异束缚:今天用本地内存做Demo测试,明天切换到Redis、Milvus等企业级向量库,一行业务代码都不用改!
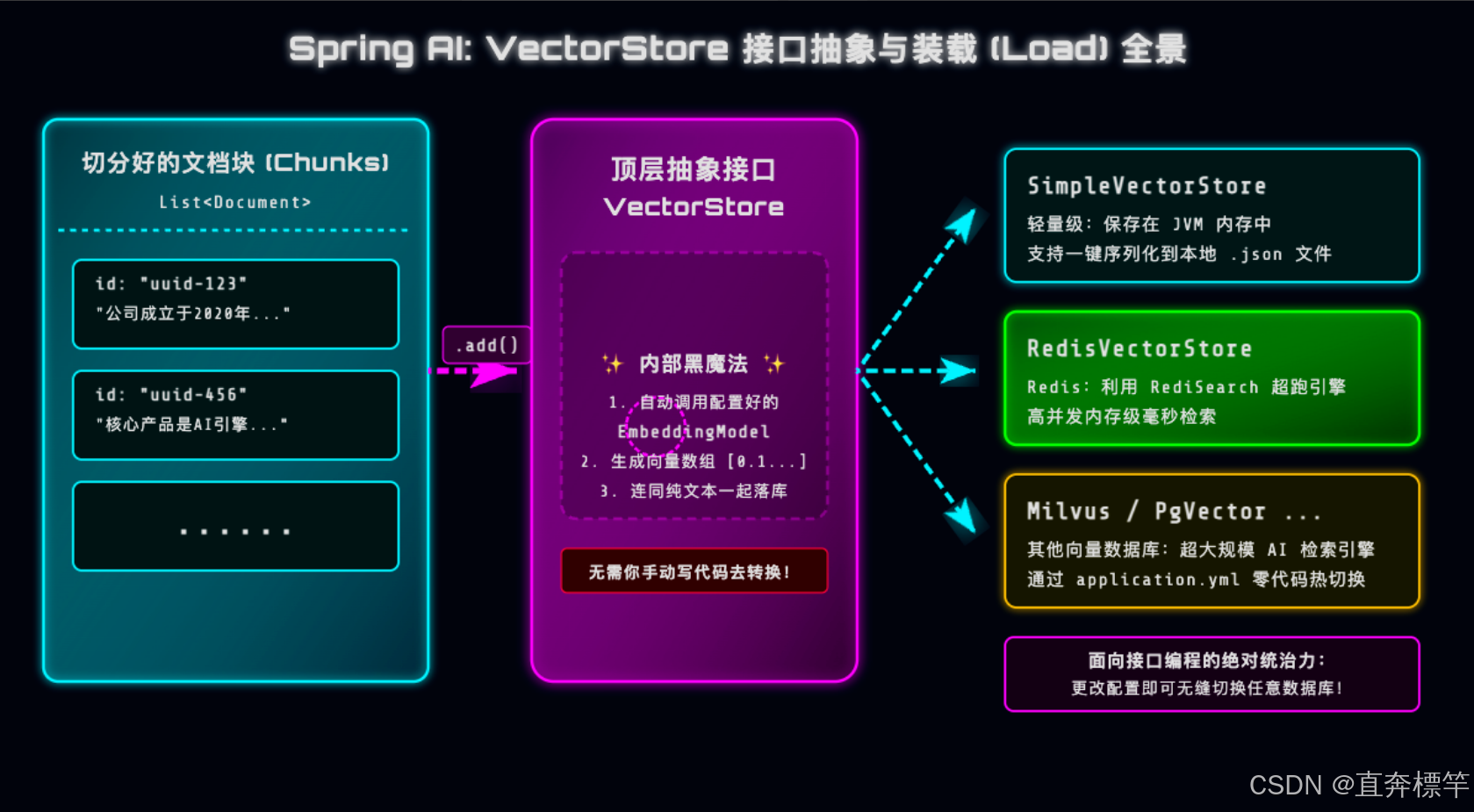
这里和大家分享一个核心知识点(避坑重点):在Spring AI中,我们完全不需要在业务代码中显式调用EmbeddingModel!只需将切分好的List<Document>丢给VectorStore.add()方法,框架内部会自动拦截文档、调用Embedding模型生成向量,再将向量与原始文本、元数据一起落库,极大简化了开发流程。
简单来说,VectorStore就相当于AI知识库的“专属书架”,负责统一管理向量数据的存储与检索,而底层具体用哪种“书架”(向量数据库),我们完全可以灵活切换。
本地实战:SimpleVectorStore快速上手(新手友好)
对于我们开发者来说,本地调试时,专门部署Milvus这类分布式向量数据库太繁琐,Spring AI贴心提供了开箱即用的本地向量存储——SimpleVectorStore,完美适配本地开发、快速验证场景。
它的核心优势的是:数据存于内存,读写速度极快;同时支持将整个向量库序列化为本地JSON文件,下次服务器重启时直接反序列化加载,避免重复计算Token、重复向量化,大大提升调试效率。
话不多说,直接上实操步骤(代码可直接复制,注释已补全,新手也能看懂):
1. 引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-vector-store</artifactId>
</dependency>2. 注册SimpleVectorStore Bean(核心配置)
/**
* 账号:直奔標杆
* 专注Java AI转型实战,分享可落地的技术方案
*/
// 当spring.ai.vectorstore.type未配置或值为simple时,启用该配置
@ConditionalOnProperty(
name = {"spring.ai.vectorstore.type"},
havingValue = "simple",
matchIfMissing = true
)
@Configuration
public class VectorStoreConfig {
// 重点:VectorStore必须依赖EmbeddingModel,框架会自动调用它完成文本向量化
@Bean
public SimpleVectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore vectorStore = SimpleVectorStore.builder(embeddingModel).build();
// 优化点:启动时自动加载本地已保存的向量库,避免重复工作
File vectorStoreFile = new File("local_vector_store.json");
if (vectorStoreFile.exists()) {
vectorStore.load(vectorStoreFile);
System.out.println(" [System] 从本地JSON文件成功加载向量数据库,无需重复向量化!");
}
return vectorStore;
}
}全链路实战:串联ETL,实现文档自动入库
结合前面第10课(文档解析)、第11课(文本切分)的内容,我们来串联完整的ETL管道,实现“读取PDF→文本切分→向量化→入库”全自动化,模拟企业私有知识库的真实入库流程。
以下代码可直接运行,我会标注关键步骤和注意事项,大家可以跟着实操,遇到问题欢迎在评论区交流~
/**
* 账号:直奔標杆
* ETL全链路实战:文档提取→切分→向量化→入库
*/
public class TestStore {
// 读取classpath下的PDF文档(可替换为自己的文档路径)
@Value("classpath:/docs/alibaba-java-guide.pdf")
private Resource pdfResource;
// 注入VectorStore(自动适配SimpleVectorStore,后续切换Redis无需修改此处)
@Autowired
private VectorStore vectorStore;
@Test
void simpleStoreTest() {
// ---------------- 1. E (Extract) - 提取:读取PDF文档 ----------------
System.out.println("--- 1. 执行ETL-E (Extract) 读取PDF文档 ---");
PagePdfDocumentReader reader = new PagePdfDocumentReader(pdfResource);
List<Document> rawDocuments = reader.get();
System.out.println("成功读取PDF,总页数:" + rawDocuments.size());
// ---------------- 2. T (Transform) - 转换:文本切分 ----------------
System.out.println("--- 2. 执行ETL-T (Transform) 文本Token切分 ---");
// 切分参数优化:chunkSize=800,overlap=350,避免语义割裂(新手建议参考这个参数)
TokenTextSplitter splitter = new TokenTextSplitter(800, 350, 5, 10000, true);
List<Document> chunkedDocuments = splitter.apply(rawDocuments);
System.out.println("文本切分完成,共得到 " + chunkedDocuments.size() + " 个文本块");
// ---------------- 3. L (Load) - 加载:向量化并入库 ----------------
System.out.println("--- 3. 执行ETL-L (Load) 向量化并入库 ---");
// 核心代码:Spring AI自动拦截文档,调用EmbeddingModel生成向量,再写入数据库
vectorStore.add(chunkedDocuments);
// 关键:SimpleVectorStore手动持久化,防止断电丢失数据
if (vectorStore instanceof SimpleVectorStore simpleStore) {
File vectorStoreFile = new File("local_vector_store.json");
simpleStore.save(vectorStoreFile);
System.out.println("向量数据已持久化到本地JSON文件,路径:" + vectorStoreFile.getAbsolutePath());
}
}
}运行结果与说明
运行测试方法后,控制台会输出如下日志(大家可对照自己的运行结果排查问题):
--- 1. 执行ETL-E (Extract) 读取PDF文档 ---
成功读取PDF,总页数:3
--- 2. 执行ETL-T (Transform) 文本Token切分 ---
文本切分完成,共得到 6 个文本块
--- 3. 执行ETL-L (Load) 向量化并入库 ---
.....Calling EmbeddingModel for document id = 5231761f-b1c4-4812-8aff-3a9b74021690
向量数据已持久化到本地JSON文件,路径:xxx/local_vector_store.json运行结束后,会在项目根目录生成local_vector_store.json文件,里面包含了每个文本块的原始文本、向量数据、元数据(文件名、页码、切分索引等),示例如下(简化版):
{
"59acb5f7-f8d2-4bcf-b10d-68b22859fec7" : {
"text" : "是尽可能少踩坑,杜绝踩重复的坑,切实提升质量意识。.....",
"embedding" : [ 0.03476889, 0.013548773, 0.02090146, ....],
"id" : "59acb5f7-f8d2-4bcf-b10d-68b22859fec7",
"metadata" : {
"file_name" : "alibaba-java-guide.pdf",
"chunk_index" : 1,
"page_number" : 1,
"parent_document_id" : "5b2369b6-81b0-4d0f-a5fd-5f5c8e9853a3",
"total_chunks" : 2
}
}
}源码解析(关键理解点)
很多朋友会好奇,Spring AI是如何自动完成向量化并入库的?这里给大家拆解核心调用链路,不用深入源码,理解这个逻辑即可:
// 核心调用链路: VectorStore#add → AbstractObservationVectorStore.doAdd
// Spring一贯风格:doXxx方法定义抽象逻辑,子类(如SimpleVectorStore)实现具体业务
public void doAdd(List<Document> documents) {
//... 省略无关逻辑
// 1. 调用EmbeddingModel,将单个文档转为向量
float[] embedding = this.embeddingModel.embed(document);
// 2. 封装存储对象,包含文档ID、文本、元数据、向量
SimpleVectorStoreContent storeContent = new SimpleVectorStoreContent(document.getId(), document.getText(), document.getMetadata(), embedding);
// 3. 写入内存存储(SimpleVectorStore的核心逻辑)
this.store.put(document.getId(), storeContent);
//...
}生产演进:零代码切换到Redis向量数据库
SimpleVectorStore适合本地调试,但生产环境中,面对超大文件、高并发语义检索(带Metadata条件过滤),就必须切换到企业级向量数据库。
这里给大家推荐Redis向量库(最易落地,很多项目已在用Redis,无需额外新增基础设施)——Redis Stack(带RediSearch模块),它不仅是K-V缓存,更是具备内存级极速检索能力的向量数据库,适配生产场景需求。
重点来了:借助Spring AI的VectorStore抽象,我们只需2步配置,就能零业务代码修改,实现从SimpleVectorStore到Redis的切换!
第一步:替换依赖(pom.xml)
移除或保留spring-ai-vector-store依赖(Redis依赖会自动关联),新增Spring官方Redis Vector Store Starter:
<!-- Redis向量库,依赖spring-ai-vector-store,无需重复引入 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-store-spring-boot-starter</artifactId>
</dependency>第二步:部署Redis Stack并配置(application.yml)
首先部署带向量搜索插件的Redis(Redis Stack),推荐用Docker快速部署(命令可直接复制):
# 拉取Redis Stack镜像(带RediSearch模块,支持向量存储)
docker pull redis/redis-stack:latest
# 启动容器,映射端口,设置密码和持久化
docker run -itd \
--restart always \
--name redis-stack \
-p 6379:6379 \
-p 8001:8001 \
-e REDIS_ARGS="--requirepass 123456 --appendonly yes" \
-v 本地目录/docker-data/redis/conf:/usr/local/etc/redis \
-v 本地目录/docker-data/redis/data:/data \
redis/redis-stack:latest部署完成后,在application.yml中配置Redis连接和向量索引参数:
spring:
data:
redis:
host: localhost # 替换为你的Redis地址(生产环境填云端地址)
port: 6379
password: 123456 # 对应上面启动命令中的密码
ai:
vectorstore:
type: redis # 指定使用Redis向量库,替代默认的simple
redis:
index-name: spring-ai-document-index # 自动创建的索引名称
prefix: "document:" # Redis Key前缀,便于区分向量数据
initialize-schema: true # 开启自动建表和索引初始化,无需手动操作配置完成后,再次调用vectorStore.add()方法,数据会自动写入Redis向量库,业务代码完全不用修改!这就是Spring AI抽象设计的魅力,极大降低了生产环境的适配成本。
总结:ETL全链路打通,知识库地基筑牢!
到这里,我们用四节课的时间,彻底打通了RAG架构中最底层、最繁琐的ETL全链路:从物理文件(PDF等)提取文本,到切分成分割合理、语义完整的文本块,再到通过Embedding向量化,最终存入向量数据库,每一步都落地实操,没有多余的理论堆砌。
回顾一下核心收获:我们不仅掌握了VectorStore的抽象设计和SimpleVectorStore的本地实战,还实现了零代码切换到Redis向量库,完成了从本地调试到生产适配的全流程。现在,我们的AI已经拥有了一个私有化的“超级知识库”,为后续的语义检索、智能问答做好了充分准备。
最后和大家说一句:AI转型不用慌,跟着直奔標杆一步一步实操,每节课吃透一个核心知识点,慢慢就能从零基础成长为能落地AI项目的Java开发者~
下节预告(重点关注!)
知识存进向量库了,下一步就是“取”——如何从海量向量中,精准检索出与用户问题最相关的内容?
比如用户提问:“公司最新的离职赔偿 N+1 是怎么算的?”,我们如何将这个问题向量化,在向量数据库中“大海捞针”,快速召回最相关的3个法律条文段落?
下一节课(第十四课):《Java开发者AI转型第十四课!大海捞针实战:向量数据库召回与相似度检索全解析》,我们将解锁VectorStore的核心方法similaritySearch(),完成RAG架构的最后一块核心拼图,不见不散!
往期回顾(串联学习,效果更佳)
-
Java开发者AI转型第十课!化繁为简!Spring AI 全能文档解析器 (Document Readers) 与元数据提取实操
-
Java开发者AI转型第十一课!文本切分避坑指南:Spring AI 智能分块与Overlap语义防割裂实战
-
Java开发者AI转型第十二课!吃透Embeddings向量化:让Java代码读懂文本语义
欢迎大家在评论区留言交流实操中遇到的问题,也可以点赞收藏,后续反复回顾!一起加油,直奔技术标杆~

一站式 AI 云服务平台
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)