
基于 4sapi 构建零代码 AI 自动化工作流平台
首先定义工作流和执行记录的数据模型,使用 SQLAlchemy 进行数据库操作。python运行import os"""工作流模型"""definition = Column(JSON, nullable=False) # 工作流定义JSON"""工作流执行记录模型""""""节点执行记录模型"""# 创建数据库表定义工作流中支持的节点类型,包括开始节点、结束节点、AI 节点、HTTP 节点和条件
引言
2026 年,企业数字化转型已经进入深水区,自动化成为提升运营效率的核心抓手。从日常办公的邮件处理、文档生成,到业务流程的客户跟进、订单处理,再到研发环节的测试自动化、部署自动化,企业内部存在大量重复性、规则性的工作,这些工作不仅耗费大量人力,还容易出错。
传统的自动化解决方案如 RPA(机器人流程自动化)存在诸多局限性:
- 开发门槛高:需要专业的开发人员编写复杂的脚本,开发周期长,维护成本高;
- 灵活性差:只能处理固定规则的任务,无法应对复杂、多变的业务场景;
- 缺乏智能能力:不具备自然语言理解、逻辑推理、决策判断等 AI 能力;
- 集成困难:难以与企业现有的各种系统和工具无缝集成。
AI 自动化工作流平台结合了大模型的智能能力和工作流的编排能力,能够解决传统自动化方案的痛点。它允许用户通过可视化的方式编排工作流,利用大模型处理复杂的逻辑和决策,实现端到端的业务自动化。
本文将分享一套基于 4sapi 的零代码 AI 自动化工作流平台解决方案,详细介绍其架构设计、核心功能和实现方法,帮助企业快速构建自己的 AI 自动化工作流平台,实现业务流程的智能化和自动化。
一、AI 自动化工作流的核心需求
一套优秀的企业级 AI 自动化工作流平台需要满足以下核心需求:
1.1 零代码 / 低代码编排
- 提供可视化的拖拽式工作流编辑器,无需编写代码即可搭建自动化流程;
- 支持丰富的节点类型,包括触发节点、执行节点、条件节点、循环节点等;
- 允许用户自定义节点和组件,满足个性化的业务需求。
1.2 强大的 AI 能力
- 支持自然语言处理,能够理解用户的自然语言指令;
- 具备逻辑推理和决策判断能力,能够处理复杂的业务逻辑;
- 支持多模态内容处理,包括文本、图片、音频、视频等;
- 能够调用各种工具和 API,扩展平台的能力边界。
1.3 丰富的集成能力
- 支持与企业现有的各种系统集成,如 CRM、ERP、OA、数据库等;
- 提供丰富的预置连接器,能够快速连接主流的 SaaS 服务;
- 支持自定义 API 调用,能够集成任何提供 API 接口的服务。
1.4 企业级特性
- 支持多租户和权限管理,不同部门和用户只能访问自己的工作流;
- 提供完整的监控和日志功能,能够跟踪工作流的执行状态;
- 支持错误处理和重试机制,保证工作流的可靠执行;
- 具备高可用性和可扩展性,能够支持大规模的并发执行。
二、基于 4sapi 的工作流平台架构设计
4sapi 作为一个企业级的大模型 API 聚合平台,为 AI 自动化工作流平台提供了强大的 AI 能力支撑。基于 4sapi 的工作流平台采用分层架构设计,分为接入层、编排层、执行层和能力层。
2.1 整体架构图
plaintext
┌─────────────────────────────────────────────────────────────────────┐
│ 接入层 │
│ (Web控制台、移动端、API接口、第三方系统集成) │
└───────────────────────────────┬─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ 编排层 │
│ │
│ ┌─────────────┐ ┌─────────────────┐ ┌─────────────────────┐ │
│ │ 可视化编辑器│ │ 工作流模板库 │ │ 流程解析与校验 │ │
│ └─────────────┘ └─────────────────┘ └─────────────────────┘ │
└───────────────────────────────┬─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ 执行层 │
│ │
│ ┌─────────────┐ ┌─────────────────┐ ┌─────────────────────┐ │
│ │ 任务调度器 │ │ 节点执行引擎 │ │ 状态管理与持久化 │ │
│ └─────────────┘ └─────────────────┘ └─────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 错误处理与重试 │ │
│ └─────────────────┘ │
└───────────────────────────────┬─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ 能力层 │
│ │
│ ┌─────────────┐ ┌─────────────────┐ ┌─────────────────────┐ │
│ │ 4sapi AI能力│ │ 预置连接器 │ │ 自定义工具与API │ │
│ │ (文本/图像/ │ │ (邮件/钉钉/微信/│ │ │ │
│ │ 音频/视频) │ │ 数据库/云服务) │ │ │ │
│ └─────────────┘ └─────────────────┘ └─────────────────────┘ │
└─────────────────────────────────────────────────────────────────────┘
2.2 各层功能说明
- 接入层:提供多种接入方式,包括 Web 控制台、移动端 APP、API 接口和第三方系统集成,方便用户通过不同的方式使用平台。
- 编排层:提供可视化的工作流编排能力:
- 可视化编辑器:拖拽式的流程设计器,支持各种节点的添加、删除和连接;
- 工作流模板库:提供丰富的预置工作流模板,覆盖常见的业务场景;
- 流程解析与校验:对用户编排的工作流进行语法和逻辑校验,确保流程的正确性。
- 执行层:负责工作流的调度和执行:
- 任务调度器:根据触发条件自动调度工作流的执行,支持定时触发、事件触发、API 触发等多种触发方式;
- 节点执行引擎:执行工作流中的各个节点,调用相应的能力完成任务;
- 状态管理与持久化:记录工作流的执行状态和中间结果,支持断点续跑;
- 错误处理与重试:处理工作流执行过程中的错误,支持自动重试和人工干预。
- 能力层:提供工作流执行所需的各种能力:
- 4sapi AI 能力:通过 4sapi 平台调用各种大模型能力,包括文本生成、图像理解、语音识别等;
- 预置连接器:提供丰富的预置连接器,能够快速连接主流的 SaaS 服务和企业系统;
- 自定义工具与 API:支持用户添加自定义的工具和 API,扩展平台的能力。
2.3 4sapi 在工作流平台中的核心价值
- 统一 AI 能力接口:通过 4sapi 的统一接口,一次性接入所有主流大模型,无需分别对接不同厂商的 API,大幅降低开发和维护成本。
- 全模态能力支持:提供文本、图像、音频、视频等全模态的 AI 能力,满足各种复杂业务场景的需求。
- 企业级高可用:分布式多活架构,内置故障自动切换、限流降级和指数退避重试机制,保证工作流的稳定执行。
- 成本优化:上下文智能缓存、模型分级调度、批量处理优化等功能,可降低工作流运行成本 50% 以上。
- 快速迭代:4sapi 平台会实时更新最新的模型和能力,工作流平台无需任何修改即可使用最新的 AI 能力。
三、实战:AI 自动化工作流平台核心实现
下面我们将实现 AI 自动化工作流平台的核心功能,包括工作流定义、节点执行、流程调度和状态管理。
3.1 环境准备
bash
运行
pip install fastapi uvicorn python-dotenv openai pydantic sqlalchemy apscheduler requests
创建.env配置文件:
env
4SAPI_BASE_URL=https://4sapi.com/v1
4SAPI_API_KEY=你的4sapi API Key
DATABASE_URL=sqlite:///workflow.db
3.2 数据模型定义
首先定义工作流和执行记录的数据模型,使用 SQLAlchemy 进行数据库操作。
python
运行
import os
from dotenv import load_dotenv
from sqlalchemy import create_engine, Column, Integer, String, Text, DateTime, JSON, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship
from datetime import datetime
load_dotenv()
DATABASE_URL = os.getenv("DATABASE_URL")
engine = create_engine(DATABASE_URL, connect_args={"check_same_thread": False})
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
class Workflow(Base):
"""工作流模型"""
__tablename__ = "workflows"
id = Column(Integer, primary_key=True, index=True)
name = Column(String(100), nullable=False)
description = Column(Text)
definition = Column(JSON, nullable=False) # 工作流定义JSON
created_at = Column(DateTime, default=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
executions = relationship("WorkflowExecution", back_populates="workflow")
class WorkflowExecution(Base):
"""工作流执行记录模型"""
__tablename__ = "workflow_executions"
id = Column(Integer, primary_key=True, index=True)
workflow_id = Column(Integer, ForeignKey("workflows.id"))
status = Column(String(20), default="pending") # pending/running/completed/failed
input_data = Column(JSON)
output_data = Column(JSON)
error_message = Column(Text)
started_at = Column(DateTime, default=datetime.utcnow)
completed_at = Column(DateTime)
workflow = relationship("Workflow", back_populates="executions")
node_executions = relationship("NodeExecution", back_populates="execution")
class NodeExecution(Base):
"""节点执行记录模型"""
__tablename__ = "node_executions"
id = Column(Integer, primary_key=True, index=True)
execution_id = Column(Integer, ForeignKey("workflow_executions.id"))
node_id = Column(String(50), nullable=False)
node_type = Column(String(50), nullable=False)
status = Column(String(20), default="pending")
input_data = Column(JSON)
output_data = Column(JSON)
error_message = Column(Text)
started_at = Column(DateTime, default=datetime.utcnow)
completed_at = Column(DateTime)
execution = relationship("WorkflowExecution", back_populates="node_executions")
# 创建数据库表
Base.metadata.create_all(bind=engine)
3.3 节点类型定义
定义工作流中支持的节点类型,包括开始节点、结束节点、AI 节点、HTTP 节点和条件节点。
python
运行
from abc import ABC, abstractmethod
from openai import OpenAI
import requests
import json
load_dotenv()
client = OpenAI(
api_key=os.getenv("4SAPI_API_KEY"),
base_url=os.getenv("4SAPI_BASE_URL")
)
class BaseNode(ABC):
"""节点基类"""
def __init__(self, node_config: dict):
self.id = node_config["id"]
self.type = node_config["type"]
self.config = node_config.get("config", {})
@abstractmethod
def execute(self, input_data: dict) -> dict:
"""执行节点逻辑"""
pass
class StartNode(BaseNode):
"""开始节点"""
def execute(self, input_data: dict) -> dict:
return input_data
class EndNode(BaseNode):
"""结束节点"""
def execute(self, input_data: dict) -> dict:
return input_data
class AINode(BaseNode):
"""AI节点"""
def execute(self, input_data: dict) -> dict:
prompt_template = self.config.get("prompt", "")
model = self.config.get("model", "gpt-5.4-turbo")
temperature = self.config.get("temperature", 0.7)
# 替换模板中的变量
prompt = prompt_template.format(**input_data)
# 调用4sapi API
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
result = response.choices[0].message.content.strip()
return {
**input_data,
"ai_result": result
}
class HTTPNode(BaseNode):
"""HTTP请求节点"""
def execute(self, input_data: dict) -> dict:
url = self.config.get("url", "")
method = self.config.get("method", "GET").upper()
headers = self.config.get("headers", {})
body = self.config.get("body", {})
# 替换URL和body中的变量
url = url.format(**input_data)
if isinstance(body, dict):
body = {k: v.format(**input_data) if isinstance(v, str) else v for k, v in body.items()}
# 发送HTTP请求
if method == "GET":
response = requests.get(url, headers=headers, params=body)
elif method == "POST":
response = requests.post(url, headers=headers, json=body)
elif method == "PUT":
response = requests.put(url, headers=headers, json=body)
elif method == "DELETE":
response = requests.delete(url, headers=headers, json=body)
else:
raise ValueError(f"不支持的HTTP方法: {method}")
response.raise_for_status()
return {
**input_data,
"http_status": response.status_code,
"http_response": response.json() if response.headers.get("content-type", "").startswith("application/json") else response.text
}
class ConditionNode(BaseNode):
"""条件节点"""
def execute(self, input_data: dict) -> dict:
condition = self.config.get("condition", "")
# 简单的条件判断,支持基本的比较运算符
# 注意:生产环境中应使用更安全的表达式求值方式
try:
result = eval(condition, {}, input_data)
except Exception as e:
raise ValueError(f"条件表达式执行失败: {e}")
return {
**input_data,
"condition_result": bool(result)
}
# 节点类型映射
NODE_TYPE_MAP = {
"start": StartNode,
"end": EndNode,
"ai": AINode,
"http": HTTPNode,
"condition": ConditionNode
}
3.4 工作流执行引擎
实现工作流执行引擎,负责解析工作流定义,执行各个节点,并管理执行状态。
python
运行
class WorkflowEngine:
"""工作流执行引擎"""
def __init__(self, db_session):
self.db_session = db_session
def execute_workflow(self, workflow_id: int, input_data: dict = None) -> WorkflowExecution:
"""执行工作流"""
# 获取工作流定义
workflow = self.db_session.query(Workflow).filter(Workflow.id == workflow_id).first()
if not workflow:
raise ValueError(f"工作流不存在: {workflow_id}")
# 创建执行记录
execution = WorkflowExecution(
workflow_id=workflow_id,
status="running",
input_data=input_data or {}
)
self.db_session.add(execution)
self.db_session.commit()
try:
# 解析工作流定义
workflow_def = workflow.definition
nodes = workflow_def.get("nodes", [])
edges = workflow_def.get("edges", [])
# 构建节点映射和邻接表
node_map = {}
adjacency = {}
for node_config in nodes:
node_id = node_config["id"]
node_type = node_config["type"]
if node_type not in NODE_TYPE_MAP:
raise ValueError(f"不支持的节点类型: {node_type}")
node_map[node_id] = NODE_TYPE_MAP[node_type](node_config)
adjacency[node_id] = []
for edge in edges:
source = edge["source"]
target = edge["target"]
adjacency[source].append(target)
# 找到开始节点
start_node_id = None
for node_id, node in node_map.items():
if isinstance(node, StartNode):
start_node_id = node_id
break
if not start_node_id:
raise ValueError("工作流必须包含一个开始节点")
# 执行工作流
current_data = input_data or {}
current_node_id = start_node_id
visited = set()
while current_node_id:
if current_node_id in visited:
raise ValueError("检测到循环引用")
visited.add(current_node_id)
node = node_map[current_node_id]
# 创建节点执行记录
node_execution = NodeExecution(
execution_id=execution.id,
node_id=current_node_id,
node_type=node.type,
status="running",
input_data=current_data
)
self.db_session.add(node_execution)
self.db_session.commit()
try:
# 执行节点
result = node.execute(current_data)
# 更新节点执行记录
node_execution.status = "completed"
node_execution.output_data = result
node_execution.completed_at = datetime.utcnow()
self.db_session.commit()
current_data = result
# 找到下一个节点
next_nodes = adjacency.get(current_node_id, [])
# 处理条件节点
if isinstance(node, ConditionNode):
condition_result = result.get("condition_result", False)
# 条件节点的边应该有condition属性
filtered_next = []
for edge in edges:
if edge["source"] == current_node_id:
edge_condition = edge.get("condition", "true")
try:
if eval(edge_condition, {}, result):
filtered_next.append(edge["target"])
except:
pass
next_nodes = filtered_next
if not next_nodes:
# 没有下一个节点,结束执行
break
# 简单实现:只执行第一个下一个节点
current_node_id = next_nodes[0]
except Exception as e:
# 更新节点执行记录
node_execution.status = "failed"
node_execution.error_message = str(e)
node_execution.completed_at = datetime.utcnow()
self.db_session.commit()
# 更新工作流执行记录
execution.status = "failed"
execution.error_message = str(e)
execution.completed_at = datetime.utcnow()
self.db_session.commit()
raise e
# 更新工作流执行记录
execution.status = "completed"
execution.output_data = current_data
execution.completed_at = datetime.utcnow()
self.db_session.commit()
return execution
except Exception as e:
# 更新工作流执行记录
execution.status = "failed"
execution.error_message = str(e)
execution.completed_at = datetime.utcnow()
self.db_session.commit()
raise e
3.5 API 接口实现
提供 RESTful API 接口,用于管理工作流和执行工作流。
python
运行
from fastapi import FastAPI, Depends, HTTPException
from pydantic import BaseModel
from typing import Optional, Dict, Any, List
app = FastAPI(title="AI自动化工作流平台", version="1.0.0")
# 数据库依赖
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
# Pydantic模型
class WorkflowCreate(BaseModel):
name: str
description: Optional[str] = None
definition: Dict[str, Any]
class WorkflowUpdate(BaseModel):
name: Optional[str] = None
description: Optional[str] = None
definition: Optional[Dict[str, Any]] = None
class WorkflowExecuteRequest(BaseModel):
input_data: Optional[Dict[str, Any]] = None
# 工作流管理API
@app.post("/api/v1/workflows")
def create_workflow(workflow: WorkflowCreate, db = Depends(get_db)):
db_workflow = Workflow(
name=workflow.name,
description=workflow.description,
definition=workflow.definition
)
db.add(db_workflow)
db.commit()
db.refresh(db_workflow)
return db_workflow
@app.get("/api/v1/workflows")
def list_workflows(db = Depends(get_db)):
workflows = db.query(Workflow).all()
return workflows
@app.get("/api/v1/workflows/{workflow_id}")
def get_workflow(workflow_id: int, db = Depends(get_db)):
workflow = db.query(Workflow).filter(Workflow.id == workflow_id).first()
if not workflow:
raise HTTPException(status_code=404, detail="工作流不存在")
return workflow
@app.put("/api/v1/workflows/{workflow_id}")
def update_workflow(workflow_id: int, workflow_update: WorkflowUpdate, db = Depends(get_db)):
workflow = db.query(Workflow).filter(Workflow.id == workflow_id).first()
if not workflow:
raise HTTPException(status_code=404, detail="工作流不存在")
if workflow_update.name:
workflow.name = workflow_update.name
if workflow_update.description:
workflow.description = workflow_update.description
if workflow_update.definition:
workflow.definition = workflow_update.definition
workflow.updated_at = datetime.utcnow()
db.commit()
db.refresh(workflow)
return workflow
@app.delete("/api/v1/workflows/{workflow_id}")
def delete_workflow(workflow_id: int, db = Depends(get_db)):
workflow = db.query(Workflow).filter(Workflow.id == workflow_id).first()
if not workflow:
raise HTTPException(status_code=404, detail="工作流不存在")
db.delete(workflow)
db.commit()
return {"message": "工作流删除成功"}
# 工作流执行API
@app.post("/api/v1/workflows/{workflow_id}/execute")
def execute_workflow(workflow_id: int, request: WorkflowExecuteRequest, db = Depends(get_db)):
engine = WorkflowEngine(db)
try:
execution = engine.execute_workflow(workflow_id, request.input_data)
return execution
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/api/v1/executions")
def list_executions(workflow_id: Optional[int] = None, db = Depends(get_db)):
query = db.query(WorkflowExecution)
if workflow_id:
query = query.filter(WorkflowExecution.workflow_id == workflow_id)
executions = query.order_by(WorkflowExecution.started_at.desc()).all()
return executions
@app.get("/api/v1/executions/{execution_id}")
def get_execution(execution_id: int, db = Depends(get_db)):
execution = db.query(WorkflowExecution).filter(WorkflowExecution.id == execution_id).first()
if not execution:
raise HTTPException(status_code=404, detail="执行记录不存在")
return execution
@app.get("/api/v1/executions/{execution_id}/nodes")
def get_execution_nodes(execution_id: int, db = Depends(get_db)):
nodes = db.query(NodeExecution).filter(NodeExecution.execution_id == execution_id).order_by(NodeExecution.started_at).all()
return nodes
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
3.6 示例:创建并执行一个简单的工作流
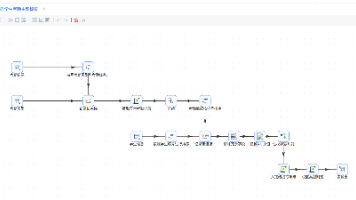
下面我们创建一个简单的工作流,实现 "用户输入产品名称→AI 生成营销文案→发送邮件通知" 的自动化流程。
python
运行
import requests
# API基础地址
BASE_URL = "http://localhost:8000/api/v1"
# 1. 创建工作流
workflow_def = {
"nodes": [
{
"id": "start",
"type": "start"
},
{
"id": "ai_copywriting",
"type": "ai",
"config": {
"prompt": "为产品'{product_name}'创作一篇吸引人的营销文案,适合在社交媒体发布。要求:标题吸引人,突出产品核心卖点,内容简洁有力,字数控制在200字以内。",
"model": "gpt-5.4-turbo",
"temperature": 0.7
}
},
{
"id": "send_email",
"type": "http",
"config": {
"url": "https://api.example.com/send-email",
"method": "POST",
"headers": {
"Content-Type": "application/json"
},
"body": {
"to": "marketing@example.com",
"subject": "新产品营销文案:{product_name}",
"body": "{ai_result}"
}
}
},
{
"id": "end",
"type": "end"
}
],
"edges": [
{
"source": "start",
"target": "ai_copywriting"
},
{
"source": "ai_copywriting",
"target": "send_email"
},
{
"source": "send_email",
"target": "end"
}
]
}
response = requests.post(f"{BASE_URL}/workflows", json={
"name": "营销文案自动生成与发送",
"description": "自动生成产品营销文案并发送邮件通知",
"definition": workflow_def
})
workflow_id = response.json()["id"]
print(f"创建工作流成功,ID: {workflow_id}")
# 2. 执行工作流
response = requests.post(f"{BASE_URL}/workflows/{workflow_id}/execute", json={
"input_data": {
"product_name": "智能保温杯"
}
})
execution_id = response.json()["id"]
print(f"执行工作流成功,执行ID: {execution_id}")
# 3. 获取执行结果
response = requests.get(f"{BASE_URL}/executions/{execution_id}")
result = response.json()
print(f"执行状态: {result['status']}")
if result["status"] == "completed":
print(f"生成的营销文案: {result['output_data']['ai_result']}")
四、生产级优化与最佳实践
4.1 性能优化
- 异步执行:将工作流执行改为异步方式,使用消息队列(如 RabbitMQ、Kafka)进行任务调度,避免 API 接口阻塞。
- 分布式执行:支持工作流的分布式执行,将不同的节点调度到不同的服务器上执行,提升系统的并发处理能力。
- 缓存机制:缓存常用的工作流定义和节点配置,减少数据库查询次数。
- 批量处理:支持批量执行工作流,提升处理效率。
4.2 可靠性优化
- 状态持久化:将工作流的执行状态和中间结果持久化到数据库,支持断点续跑和故障恢复。
- 错误处理与重试:为每个节点配置错误重试策略,支持指数退避重试和死信队列。
- 超时控制:为每个节点设置超时时间,避免节点长时间阻塞。
- 监控与告警:监控工作流的执行状态、成功率和响应时间,设置异常告警规则。
4.3 安全优化
- 身份认证与授权:实现基于 JWT 的身份认证和基于角色的访问控制(RBAC),确保只有授权用户才能访问和执行工作流。
- 数据加密:对工作流定义和执行数据中的敏感信息进行加密存储。
- API 安全:对 API 接口进行限流和防护,防止恶意攻击。
- 审计日志:记录所有用户的操作和工作流的执行情况,满足合规审计要求。
4.4 功能扩展
- 更多节点类型:增加更多的预置节点类型,如数据库节点、文件节点、定时节点等。
- 可视化编辑器:开发基于 Web 的可视化工作流编辑器,提供拖拽式的流程设计体验。
- 工作流模板库:提供丰富的预置工作流模板,覆盖常见的业务场景,用户可以直接使用或修改。
- 版本管理:支持工作流的版本管理,用户可以查看历史版本和回滚到任意版本。
五、企业落地收益
基于 4sapi 的 AI 自动化工作流平台能够为企业带来以下显著收益:
- 提升运营效率:将重复性、规则性的工作自动化,释放员工的时间和精力,让他们专注于更有价值的工作。
- 降低运营成本:减少人工成本和人为错误,降低业务流程的运营成本。
- 加快响应速度:自动化流程能够 7*24 小时不间断运行,大幅缩短业务处理时间。
- 提高业务灵活性:通过可视化的工作流编排,能够快速响应业务需求的变化,调整业务流程。
- 促进数字化转型:推动企业业务流程的数字化和智能化,提升企业的核心竞争力。
六、总结与展望
AI 自动化工作流是未来企业数字化转型的重要方向,它结合了大模型的智能能力和工作流的编排能力,能够实现端到端的业务自动化。基于 4sapi 的零代码 AI 自动化工作流平台解决方案,为企业提供了一套简单、高效、可扩展的自动化工具,帮助企业快速构建自己的自动化能力。
未来,随着大模型技术的不断发展,AI 自动化工作流将会变得更加智能和强大,能够处理更加复杂的业务场景。我们将继续优化这套平台,增加更多的功能和特性,帮助更多企业实现业务流程的智能化和自动化。

一站式 AI 云服务平台
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)