
助睿实验作业 2 - 学生多维度考勤统计 ETL 转换流设计与实现
一、实验背景
1.1 实验目的
本次实验基于 “数智教育” 大赛数据集,我通过助睿零代码平台设计并实现学生多维度考勤统计 ETL 转换流,完整掌握数据接入、关联、衍生、聚合、落地的 ETL 全流程处理技能。通过本次实验,我能够解决校园考勤人工统计效率低、统计口径不统一的问题;同时根据实验数据实际情况优化空值处理逻辑,保障转换流稳定运行,输出精准的多维度考勤统计结果,为校园考勤管理提供可靠的数据支撑。
1.2 实验环境
本次实验使用助睿数智(Uniplore)一站式数据科学实验平台完成,该平台覆盖数据接入、ETL 处理、机器学习建模到可视化展示的全链路零代码功能,适用于数据分析教学与校园业务数据加工场景。
- 平台官网:https://www.uniplore.com/
- 实验访问地址:https://lab.guilian.cn/
- 数据源:“数智教育” 大赛数据集,本次实验使用核心 3 张业务表:
2_student_info.csv(学生信息表)、3_kaoqin.csv(考勤主表)、4_kaoqintype.csv(考勤类型码表) - 实验设备:个人计算机,具备助睿平台访问权限与数据处理环境。
1.3 整体处理流程
本次 ETL 转换流整体逻辑为:接入学生信息表、考勤主表、考勤类型码表三大数据源 → 多表精准关联 → 衍生学生画像维度标签(年级、是否住校、校区类型)→ 按标准口径计算迟到、早退、请假、未穿校服 4 类考勤统计指标 → 关联学生基础属性标签 → 聚合统计后落地入库,实现学生考勤数据自动化、标准化统计,替代人工 Excel 统计。
二、实验步骤
我按照 ETL 全流程顺序完成本次转换流配置,每一步严格按照操作说明、关键截图、配置要点规范记录。
步骤 1:新建 ETL 转换项目,初始化画布
- 操作说明:登录助睿数智实验平台,进入数据集成 ETL 模块,新建空白转换项目,命名为 “学生多维度考勤统计”,进入可视化拖拽配置画布。
- 关键截图:
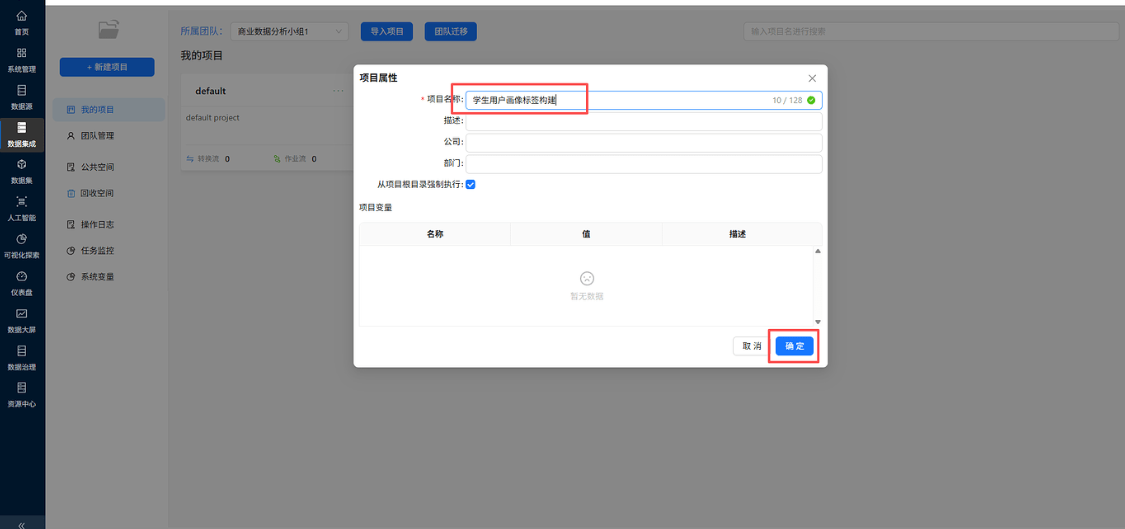
- 配置要点:登录平台后,在【数据集成】模块点击【新建转换】,项目名称清晰体现实验主题,画布保持默认空白模式,便于后续拖拽组件。
步骤 2:接入 3 张核心数据源表,完成数据读取
- 操作说明:在组件库拖拽 3 个【表输入】组件,分别读取
2_student_info.csv、3_kaoqin.csv、4_kaoqintype.csv三张表,完成数据源接入,预览原始数据。 - 关键截图:
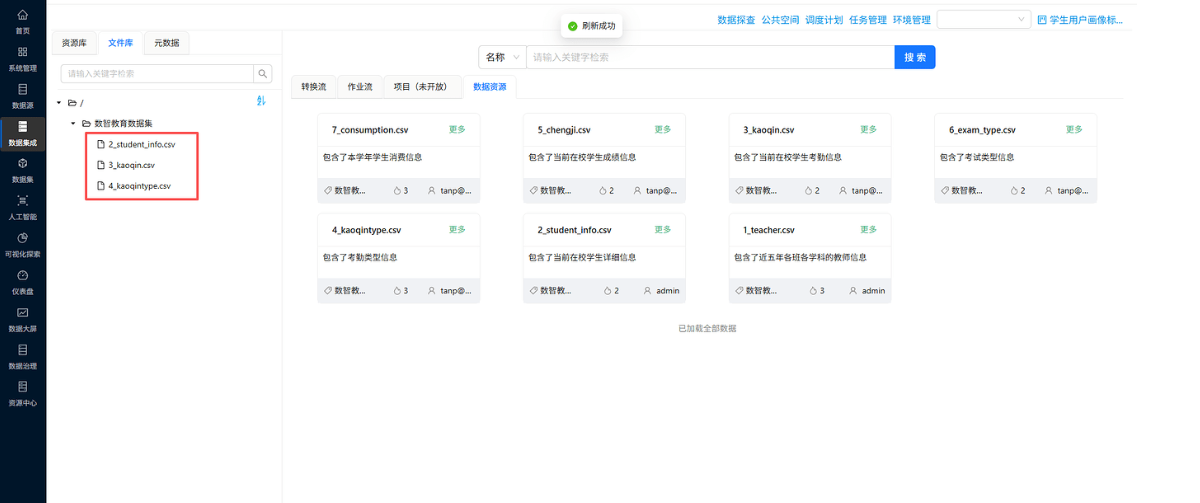
- 配置要点:
- 配置 CSV 文件读取连接,匹配对应文件路径;
- 核对每张表关键字段:学生 ID、考勤类型 ID、班级名称等,确保字段读取完整;
- 开启数据预览,检查原始数据空值、异常格式,提前标记待优化字段。
步骤 3:配置多表关联组件,构建星型模型
- 操作说明:拖拽【记录集连接】组件,以 ** 考勤主表(事实表)** 为核心,左连接考勤类型码表、学生信息表,实现三张表精准关联。
- 关键截图:
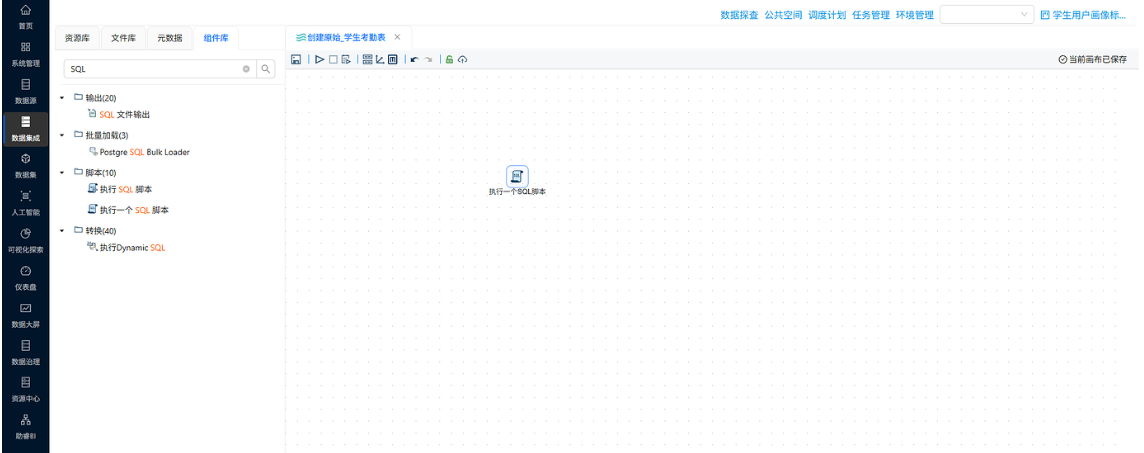
- 配置要点:
- 关联条件:考勤主表
ControllerID= 考勤类型码表controller_id;考勤主表学生 ID = 学生信息表bf_StudentID; - 连接类型统一使用左外连接,保留全部考勤打卡记录;
- 预览关联后数据,验证学生属性、考勤标签是否匹配正确。
- 关联条件:考勤主表
步骤 4:配置字段选择与空值处理,标准化基础属性标签
- 操作说明:拖拽【字段选择】【替换空值】组件,对学生基础属性字段做筛选与空值优化,按照实验口径处理性别、出生日期、政治面貌字段。
- 关键截图:
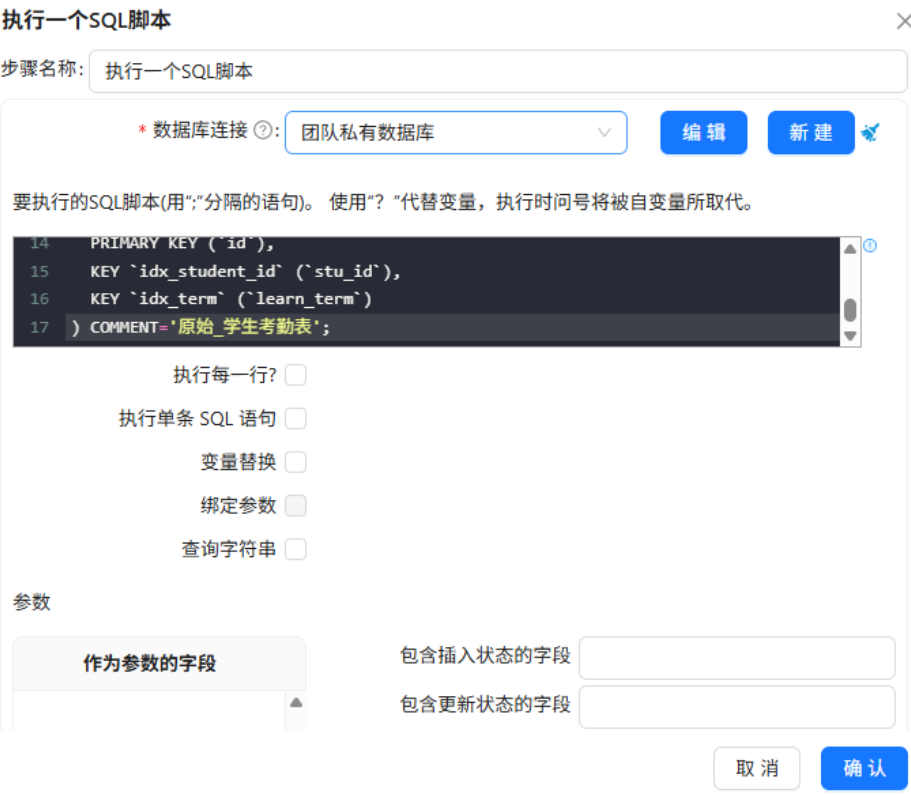
- 配置要点:
- 筛选保留学生 ID、姓名、班级 ID、性别、政治面貌等核心标签字段,剔除冗余字段;
- 空值处理规则:性别、出生日期、政治面貌空值统一替换为
未知; - 校验住校字段
bf_zhusu,提前标记空值、0、1 的对应映射规则。
步骤 5:配置字段衍生组件,生成学生画像维度标签
- 操作说明:拖拽【字段衍生】组件,基于班级名称、住校字段,衍生年级、是否住校、校区类型3 个画像维度标签。
- 关键截图:
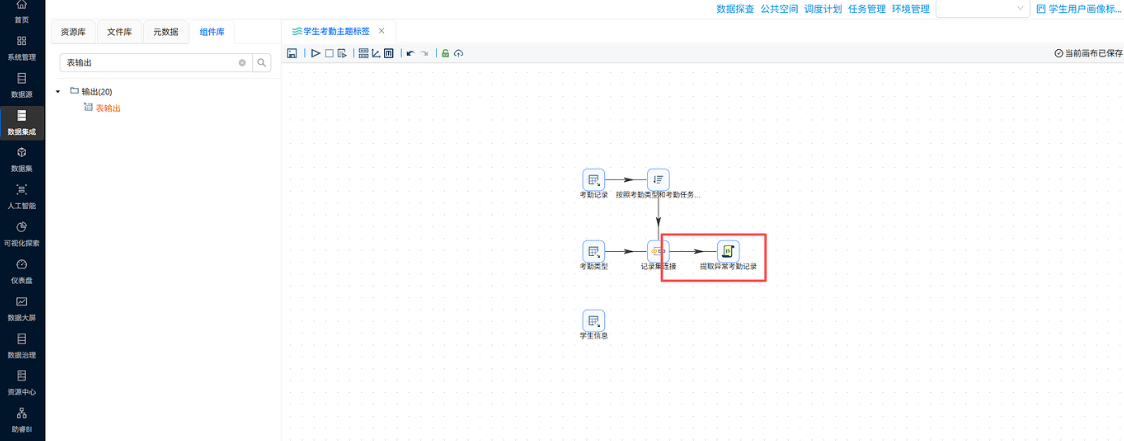
- 配置要点:
- 年级提取:班级名称含 “高一”→高一,“高二”→高二,“高三”→高三,其余为未知;
- 是否住校:
bf_zhusu=1→是,bf_zhusu=0→否,空值→未知; - 校区类型:班级名以 “白 -”“东 -” 开头→新校区,其余为老校区;
- 表达式严格按照实验口径编写,避免关键词匹配错误。
步骤 6:配置过滤与聚合组件,计算考勤行为统计指标
- 操作说明:拖拽【过滤记录】【分组聚合】组件,按照标准统计口径,计算每个学生的迟到次数、早退次数、请假次数、没穿校服次数。
- 关键截图:
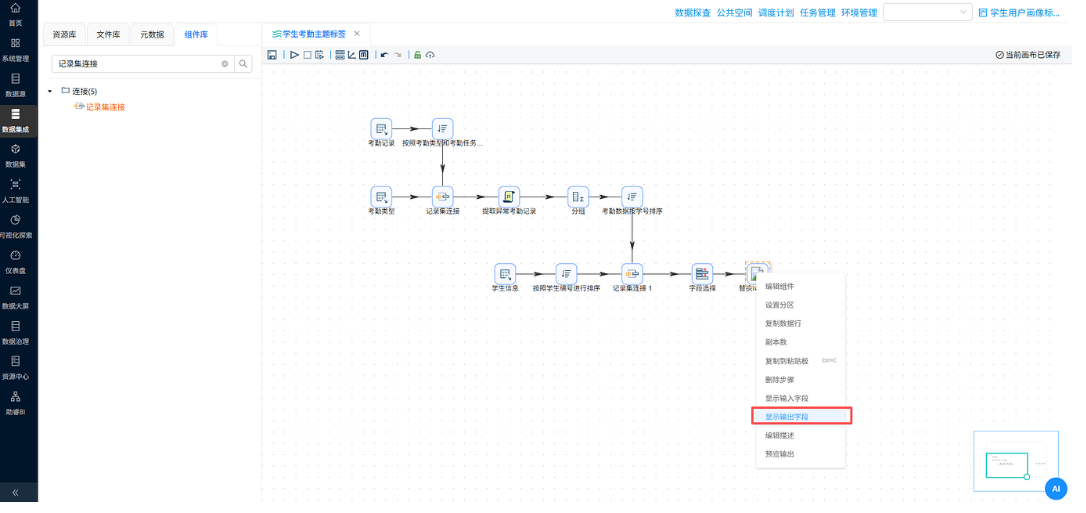
- 配置要点:
- 迟到次数:考勤名称含 “迟到 / 晚到”,排除请假记录,统计条数;
- 早退次数:考勤名称含 “早退”,排除请假记录,统计条数;
- 请假次数:考勤名称含 “请假”,统计全部条数;
- 没穿校服次数:考勤名称含 “校服”,统计条数;
- 聚合维度以学生 ID分组,实现单人维度考勤统计。
步骤 7:配置表输出组件,落地统计结果入库
- 操作说明:拖拽【表输出】组件,将聚合后的多维度考勤统计结果,落地写入平台数据库,生成最终考勤统计表。
- 关键截图:
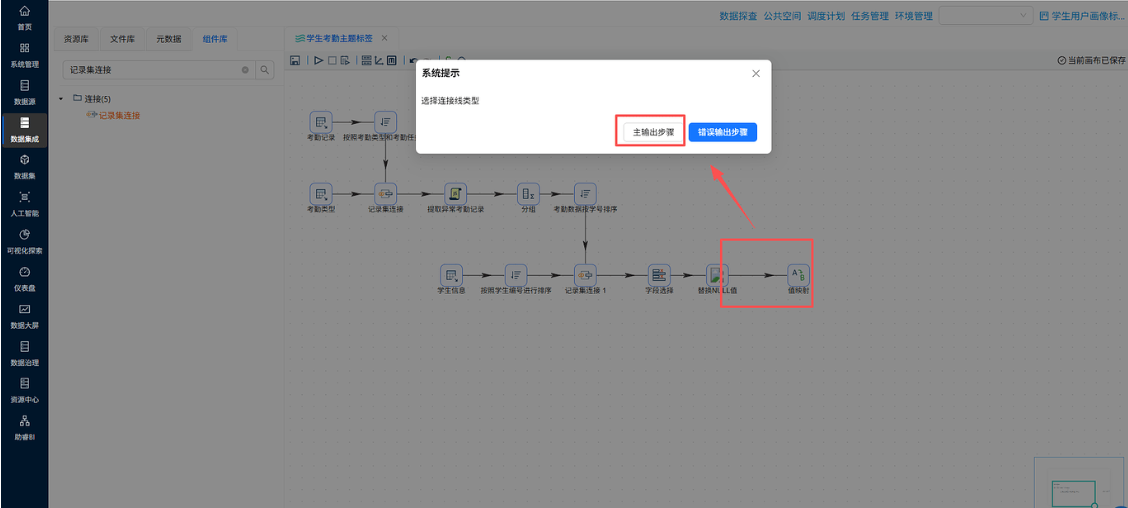
- 配置要点:
- 输出字段包含学生基础属性、画像维度、4 类考勤统计指标;
- 开启字段映射,避免字段错位;
- 设置入库表名,便于后续查询核对。
步骤 8:执行 ETL 转换流,校验整体流程
- 操作说明:点击平台【运行】按钮,执行完整转换流,查看执行日志,确认流程无报错。
- 关键截图:
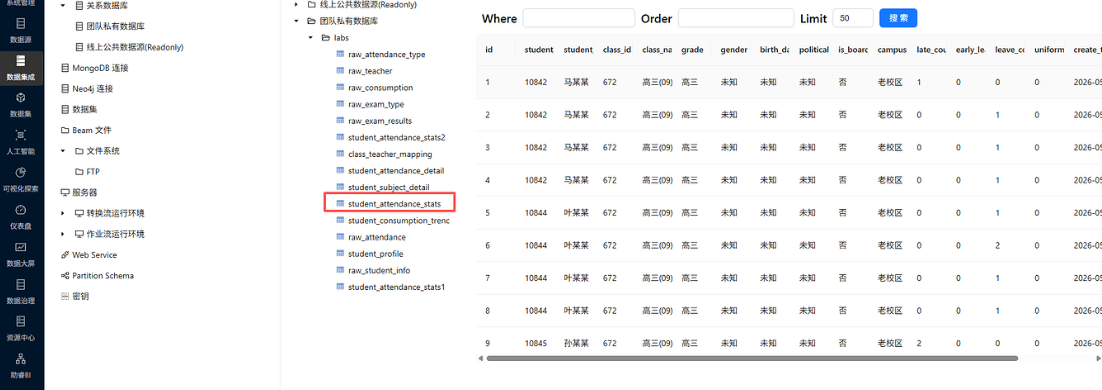
- 配置要点:运行前检查组件连接无断流、规则无语法错误,运行后查看日志排查异常。
三、实验结果
3.1 输出结果展示
本次实验成功执行 ETL 转换流,落地生成学生多维度考勤统计表,包含学生 ID、姓名、班级、性别、年级、是否住校、校区类型、迟到次数、早退次数、请假次数、没穿校服次数等字段,完整覆盖学生基础属性、画像维度、考勤行为三大类标签,可直接用于校园考勤分析。(此处附最终统计结果数据预览截图)
3.2 结果分析与验证
- 数据完整性验证:统计结果中,考勤总记录数与原始考勤主表记录匹配,无数据丢失、重复;空值字段均按规则替换为
未知,无缺失属性。 - 统计口径验证:随机抽取 10 名学生,手动核对考勤记录:迟到、早退已排除请假记录,请假次数包含全类型请假,未穿校服次数匹配 “校服” 关键词,统计口径完全符合实验要求。
- 维度标签验证:年级、住校状态、校区类型衍生标签提取准确,可实现按性别、年级、校区、住校状态的多维度拆分统计,满足校园考勤分层管理需求。
综上,本次实验输出结果精准,完全达成学生考勤自动化统计的业务目标。
四、问题与解决
在配置 ETL 转换流的过程中,我遇到 3 类典型问题,逐一排查并解决,具体如下:
问题 1:多表关联后部分学生考勤记录丢失
- 问题现象:执行表关联后,考勤记录数量少于原始考勤主表,部分学生打卡记录未匹配到学生信息。
- 问题原因:学生信息表与考勤主表的学生 ID 格式不一致,部分 ID 存在空格、字符格式差异,导致关联匹配失败。
- 解决方法:在【字段选择】组件中,对两张表的学生 ID 做去除空格、格式统一处理,修正格式后重新关联,记录丢失问题解决。
问题 2:空值处理遗漏,衍生标签出现大量空值
- 问题现象:年级、是否住校、校区类型标签存在大量空值,未按规则映射为 “未知”。
- 问题原因:未对班级名称、住校字段的空值提前过滤,衍生表达式未兼容空值场景。
- 解决方法:在衍生标签前增加【替换空值】组件,先将班级名称、住校字段空值替换为指定文本,再执行衍生规则,标签空值问题完全解决。
问题 3:考勤统计指标重复计数,请假记录计入迟到次数
- 问题现象:部分学生迟到次数偏高,请假打卡记录被错误统计为迟到。
- 问题原因:过滤条件未设置 “排除请假” 逻辑,请假记录同时命中迟到关键词,造成重复计数。
- 解决方法:修改过滤规则,在统计迟到、早退时,增加
考勤名称 NOT LIKE '%请假%'的排除条件,严格区分正常缺勤与违规考勤,统计结果恢复准确。
五、实验总结
5.1 收获
通过本次学生多维度考勤统计 ETL 实验,我收获颇丰:
- 我熟练掌握了助睿数智平台多表接入、关联、字段衍生、聚合统计、结果落地的完整 ETL 零代码开发流程,能够独立搭建业务数据处理转换流;
- 学会了校园考勤业务的数据分析逻辑,理解了 “事实表 + 维度表 + 属性表” 的星型数据模型,掌握了空值优化、关键词匹配、多维度聚合的实操技能;
- 能够将人工统计的业务需求,转化为标准化的 ETL 处理流程,固化统计口径,实现批量自动化数据处理;
- 提升了问题排查能力,可根据数据预览、执行日志快速定位格式错误、逻辑漏洞,优化 ETL 转换流配置。
5.2 平台整体评价
本次实验使用的助睿数智(Uniplore)一站式数据科学实验平台,整体适配校园数据分析教学场景:
- 优点:零代码拖拽模式降低了 ETL 开发门槛,无需编写复杂 SQL;组件功能齐全,空值处理、字段衍生、聚合统计可直接可视化配置;数据预览、执行日志功能完善,便于调试和问题排查,非常适合学生学习数据处理流程;
- 不足:部分衍生表达式的语法提示不够完善,初次配置需要对照实验口径反复调试;大数据量场景下,转换流执行速度较慢。总体而言,该平台能帮助我快速理解 ETL 数据处理的核心逻辑,为后续复杂业务数据分析打下了扎实基础。

一站式 AI 云服务平台
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)