
零代码平台学生用户画像-考勤主题标签构建
助睿实验作业-学生多维度考勤统计一、实验说明1.1 实验目的本次实验基于“数智教育”大赛数据集,设计并实现一个学生多维度考勤统计的ETL转换流。主要目标包括:掌握助睿平台数据接入、关联、衍生、聚合、落地的全流程操作处理实际数据中的空值问题,确保转换流可正常运行输出多维度考勤统计结果,为校园考勤管理提供数据支撑1.2 实验环境实验平台:https://lab.guilian.cn/产品官网:http
助睿实验作业-学生多维度考勤统计
一、实验说明
1.1 实验目的
本次实验基于“数智教育”大赛数据集,设计并实现一个学生多维度考勤统计的ETL转换流。主要目标包括:
-
掌握助睿平台数据接入、关联、衍生、聚合、落地的全流程操作
-
处理实际数据中的空值问题,确保转换流可正常运行
-
输出多维度考勤统计结果,为校园考勤管理提供数据支撑
1.2 实验环境
-
实验平台:https://lab.guilian.cn/
-
产品官网:https://www.uniplore.com/
-
数据源:“数智教育”大赛数据集(7张核心业务表)
-
本次实验使用其中的3张表:考勤主表(3_kaoqin.csv)、考勤类型码表(4_kaoqintype.csv)、学生信息表(2_student_info.csv)
二、转换流整体设计
2.1 核心处理逻辑
我设计的转换流逻辑如下:
接入三大数据源 → 多表关联 → 标记考勤行为 → 聚合统计指标 → 关联基础属性 → 落地统计结果
2.2 组件功能规划
组件
作用
表输入(3个)
读取考勤记录、考勤类型、学生信息三张表
排序记录(多个)
为记录集连接准备有序数据
记录集连接(2次)
关联考勤记录与考勤类型、关联学生信息
JavaScript代码(3个)
衍生考勤行为标记、提取年级、判断校区类型
分组(2个)
按不同维度聚合统计异常次数
字段选择
移除冗余字段
替换NULL值
处理空值
值映射
住校状态编码映射为“是/否”
表输出
结果写入目标表
三、数据与标签口径
3.1 源数据结构
本次实验聚焦考勤主题,使用三张表形成星型模型:
表名
作用
关键字段
3_kaoqin.csv(考勤主表)
事实表,存储每日打卡记录
stu_id, cla_id, attendance_type_id, attendance_task_name
4_kaoqintype.csv(考勤类型码表)
维度表,提供标准化考勤名称
attendance_type_id, attendance_task_name
2_student_info.csv(学生信息表)
属性表,提供学生基础属性
stu_id, stu_sex, policy, bf_zhusu
3.2 标签字段及处理口径
基础属性字段:
字段
处理方式
学生ID、姓名、班级ID、班级名称
直接读取
性别、出生日期、政治面貌
空值替换为“未知”
衍生维度字段:
字段
衍生逻辑
年级
从班级名称提取(高一/高二/高三/未知)
是否住校
bf_zhusu=1→“是”,0→“否”,空值→“未知”
校区类型
班级名以“白-”或“东-”开头→新校区,否则→老校区
考勤行为指标(统计口径):
指标
统计逻辑
迟到次数
考勤事件包含“迟到”或“晚到”,且排除请假记录
早退次数
考勤事件包含“早退”,且排除请假记录
请假次数
考勤事件包含“请假”关键词
没穿校服次数
考勤事件包含“校服”关键词
四、实验步骤
4.1 创建项目与获取数据
-
新建项目,命名为“学生用户画像标签构建”
-
进入项目,在文件库中新建目录“数智教育数据集”
-
从公共空间导出 3_kaoqin.csv、4_kaoqintype.csv、2_student_info.csv 到该目录
-
在元数据中新建MySQL数据源(连接信息由助教提供),命名为“团队私有数据库”
4.2 导入数据到私有数据库
依次创建三个转换流,将CSV数据导入数据库:
转换流名称
目标表
关键配置
创建原始_学生考勤表
raw_attendance
执行SQL脚本建表 → CSV输入 → 表输出
创建原始_考勤类型表
raw_attendance_type
同上,注意列分隔符为TAB、编码GB2312
创建原始_学生信息表
raw_student_info
同上,需用字段选择组件固化 bf_zhusu、bf_qinshihao 为整数类型
4.3 创建目标标签表
新建转换流“创建学生考勤主题标签表”,使用“执行一个SQL脚本”组件创建结果表 student_attendance_stats,包含以下字段:student_id, student_name, class_id, class_name, grade, gender, birth_date, political_status, is_boarder, campus_type, late_count, early_leave_count, leave_count, uniform_violate_count。
4.4 学生考勤主题标签构建(核心转换流)
新建转换流“学生考勤主题标签”,按以下顺序配置组件:
步骤1:数据接入
-
拖入3个“表输入”组件,分别读取 raw_attendance、raw_attendance_type、raw_student_info 三张表
步骤2:关联考勤记录与考勤类型
-
添加“排序记录”组件,对考勤记录按 attendance_type_id 和 attendance_task_order_id 排序
-
添加“记录集连接”组件,左外连接考勤记录和考勤类型,连接字段为上述两字段
步骤3:生成考勤行为标记
-
添加“JavaScript代码”组件,输入脚本,通过关键词匹配生成四个标记字段:isLate、isEarly、isLeave、isNoUniform
步骤4:分组聚合
-
添加第一个“分组”组件,按 stu_id, stu_name, cla_id, cla_name 分组,对四个标记字段求和
步骤5:关联学生信息
-
添加两个“排序记录”组件(分别对学生信息和聚合后的考勤数据按 stu_id 排序)
-
添加第二个“记录集连接”组件,左外连接考勤统计结果与学生信息
步骤6:字段选择与空值处理
-
添加“字段选择”组件,移除冗余字段,保留核心字段
-
添加“替换NULL值”组件,将 stu_sex、born_date、policy、live_on_campus 的空值替换为“未知”
步骤7:基础属性标准化
-
添加“值映射”组件,将 live_on_campus 的 0→“否”、1→“是”
-
添加第二个“JavaScript代码”组件,从班级名提取年级(高一/高二/高三/未知)
-
添加第三个“JavaScript代码”组件,判断校区类型(班级名以“白-”或“东-”开头为新校区,否则为老校区)
步骤8:结果入库
-
添加“表输出”组件,目标表选择 student_attendance_stats,勾选“裁剪表”和“指定数据库字段”,建立字段映射关系
4.5 执行与验证
-
点击执行按钮运行转换流,在日志页面查看执行状态
-
在元数据中右键“团队私有数据库”选择“加载元数据”
-
双击 student_attendance_stats 表,切换到“查询”标签页,查看统计结果是否符合预期
五、实验结果
转换流执行成功后,student_attendance_stats 表中生成了每位学生的多维度考勤统计:
维度字段
指标字段
学生ID、姓名、班级、年级、性别、出生日期、政治面貌、是否住校、校区类型
迟到次数、早退次数、请假次数、没穿校服次数
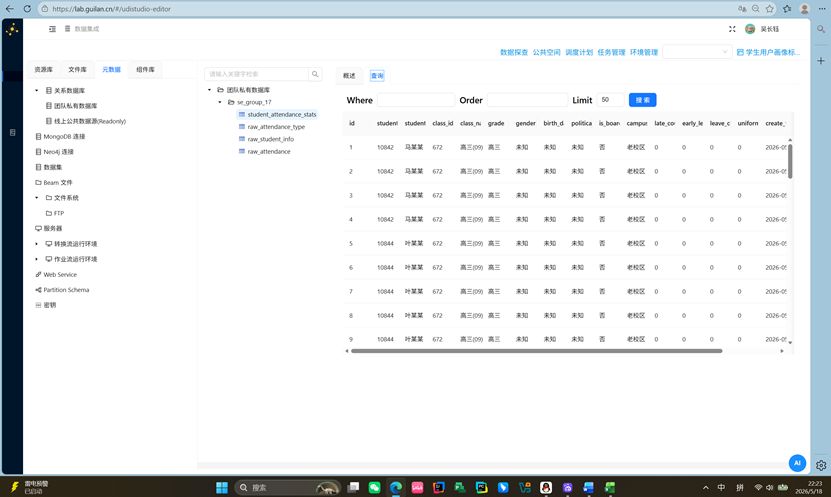
实验验证了空值处理和衍生逻辑的正确性,转换流可稳定运行。

一站式 AI 云服务平台
更多推荐

 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)