
可视化搭建实战!学情多维画像挖掘与校园纪律管理数据分析教程(附超完整详细教程)
本次实验包含两个连贯的数据挖掘实验,依托助睿数智Uniplore零代码平台完成。第一部分为学生用户画像-考勤主题扩展标签构建,利用K-Means无监督聚类算法,以学生在校迟到、早退、请假、校服违规四类考勤行为数据为特征维度,对全体学生进行自动化人群分群,生成标准化学生考勤分类标签,完成原始数据表的标签扩充;第二部分为学生用户画像-考勤画像可视化分析。
#商业数据分析 #助睿数智 #可视化 #大数据分析
一、实验前言(实验背景)
1.1 实验目的
本次实验包含两个连贯的数据挖掘实验,依托助睿数智Uniplore零代码平台完成。
第一部分为学生用户画像-考勤主题扩展标签构建,利用K-Means无监督聚类算法,以学生在校迟到、早退、请假、校服违规四类考勤行为数据为特征维度,对全体学生进行自动化人群分群,生成标准化学生考勤分类标签,完成原始数据表的标签扩充;
第二部分为学生用户画像-考勤画像可视化分析,聚焦聚类结果中的纪律高危型学生群体,依托BI可视化工具做多维度数据剖析,从性别、年级、校区、班级角度挖掘高危人群分布规律与行为特征,为校园德育管理、班级管控、学生行为干预提供客观的数据依据。
通过本次完整实操流程,熟练掌握AI建模、ETL数据处理、BI可视化全套零代码平台操作,理解无监督聚类算法在人群分群业务中的实际用法,能够独立完成数据清洗、模型训练、图表制作、仪表盘搭建,具备基础的用户画像构建、数据解读与业务分析能力。
本次可视化处理的前置条件是上一次的转换工作流处理数据(教程:教育数据工作流分析
1.2 整体实验流程
第一阶段:进入AI建模平台新建空白工作流,连接数据库并加载原始考勤数据,筛选有效特征字段后完成数据预处理,配置K-Means聚类算法参数完成学生人群聚类,生成聚类结果数据表;随后进入BI可视化平台,制作散点分布图完成人群特征区分与标签定义;最后使用ETL数据集成工具为原始数据表新增扩展字段,将聚类分类标签批量回写至学生考勤主表,完善标签体系。
第二阶段:复用已经完成聚类标注的学生考勤主题标签表,在BI平台创建专项分析数据集,优先详细制作单张示例图表,明确制作流程,其余同类图表按照相同步骤复刻制作;整合全部可视化图表搭建综合分析仪表盘,完成仪表盘美化、发布与公开分享,实现考勤数据可视化成果共享。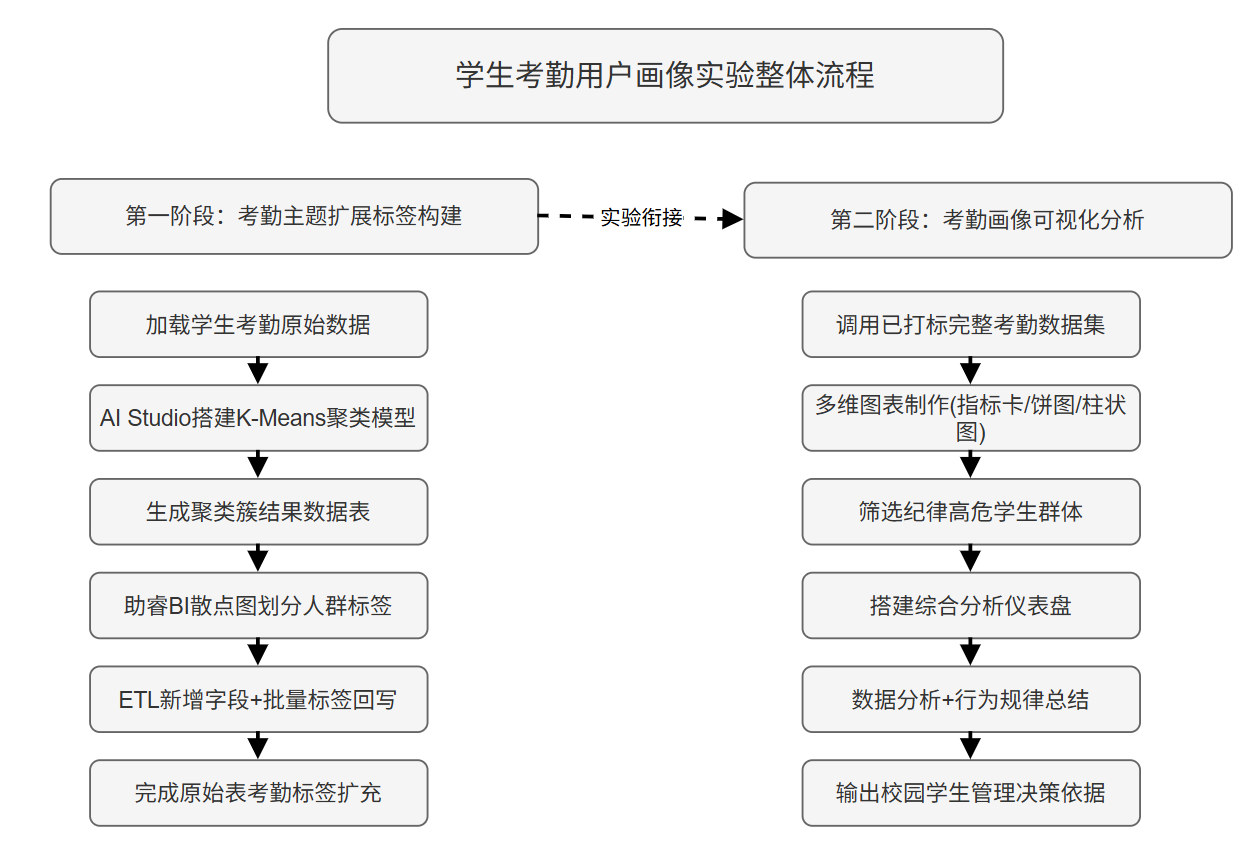
1.3 实验数据说明
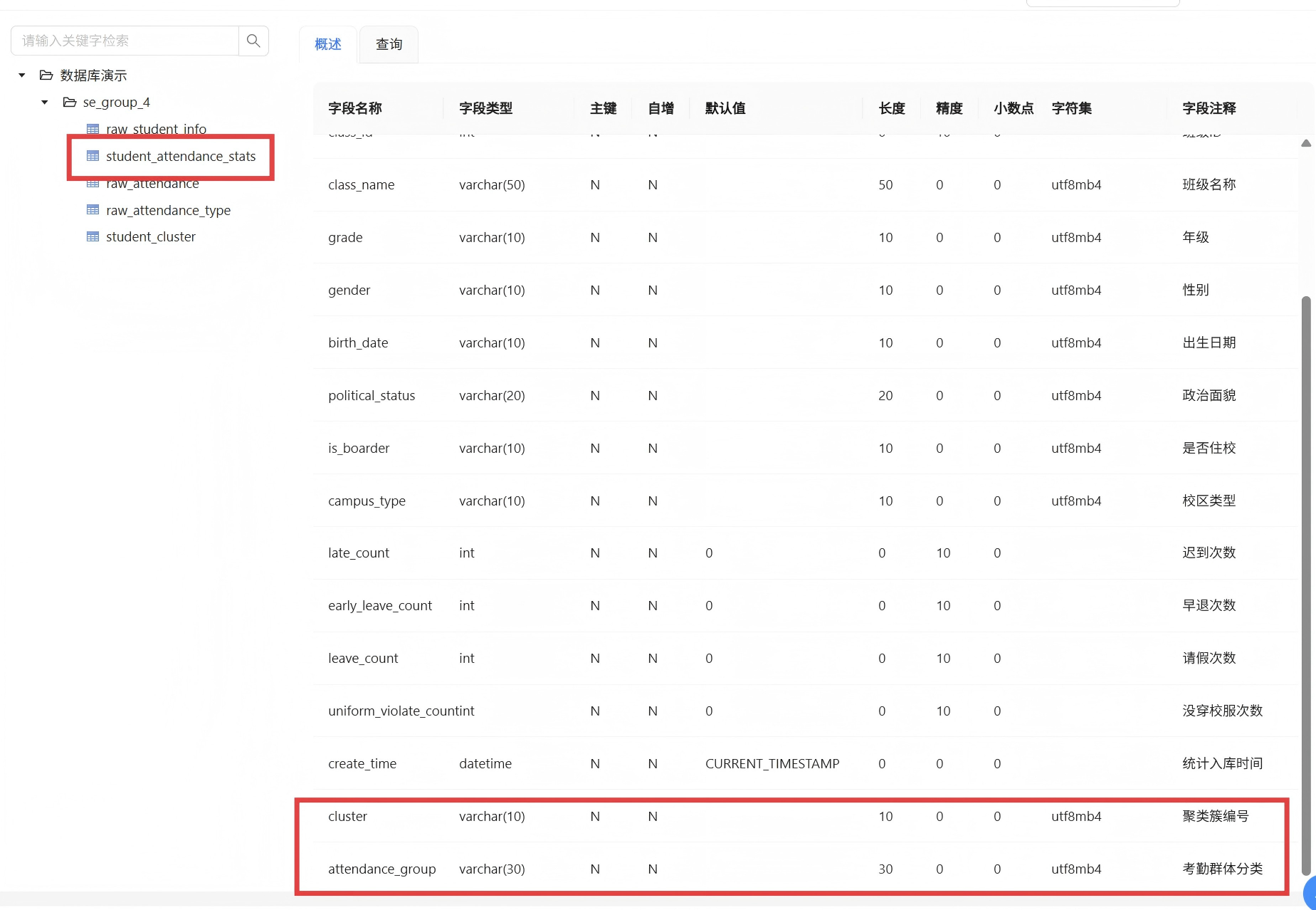
本次实验采用平台提供的学生考勤主题标签表,数据表涵盖学生基础个人信息、考勤违纪统计数据以及后期生成的聚类标签字段,完整支撑聚类建模与画像分析全流程,数据表结构如下表所示。
| 字段名 | 字段类型 | 字段说明 |
|---|---|---|
| id | int | 自增主键 |
| student_id | int | 学生ID |
| student_name | varchar(50) | 学生姓名 |
| class_id | int | 班级ID |
| class_name | varchar(50) | 班级名称 |
| grade | varchar(10) | 年级 |
| gender | varchar(10) | 性别 |
| late_count | int | 迟到次数 |
| early_leave_count | int | 早退次数 |
| leave_count | int | 请假次数 |
| uniform_violate_count | int | 校服违规次数 |
| create_time | datetime | 数据入库时间 |
| cluster | varchar(10) | 聚类簇编号 |
| attendance_group | varchar(30) | 考勤群体分类 |
二、学生用户画像 - 考勤主题扩展标签构建
2.1 AI平台聚类建模
2.1.1 新建AI工作流
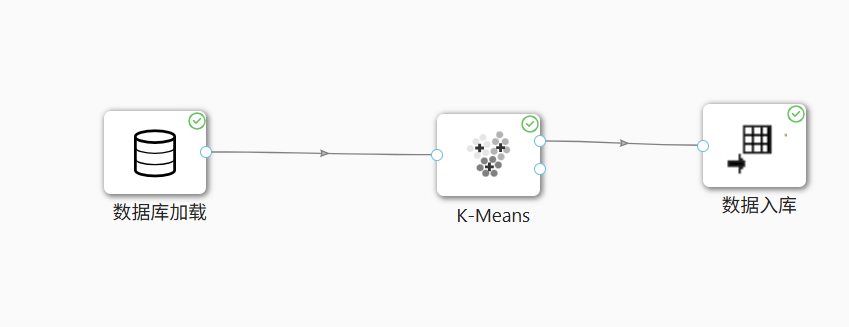
本次建模工作开始前,首先进入平台左侧菜单栏中的人工智能模块,打开AI Studio智能建模界面,在界面左上角点击新增按钮创建空白工作流,系统自动生成无组件空白画布,整个工作流界面由控件列表、功能菜单栏以及可视化编辑画布三部分组成,简洁的布局便于后续拖拽组件、连线搭建聚类流程。
2.1.2 数据库加载实验数据
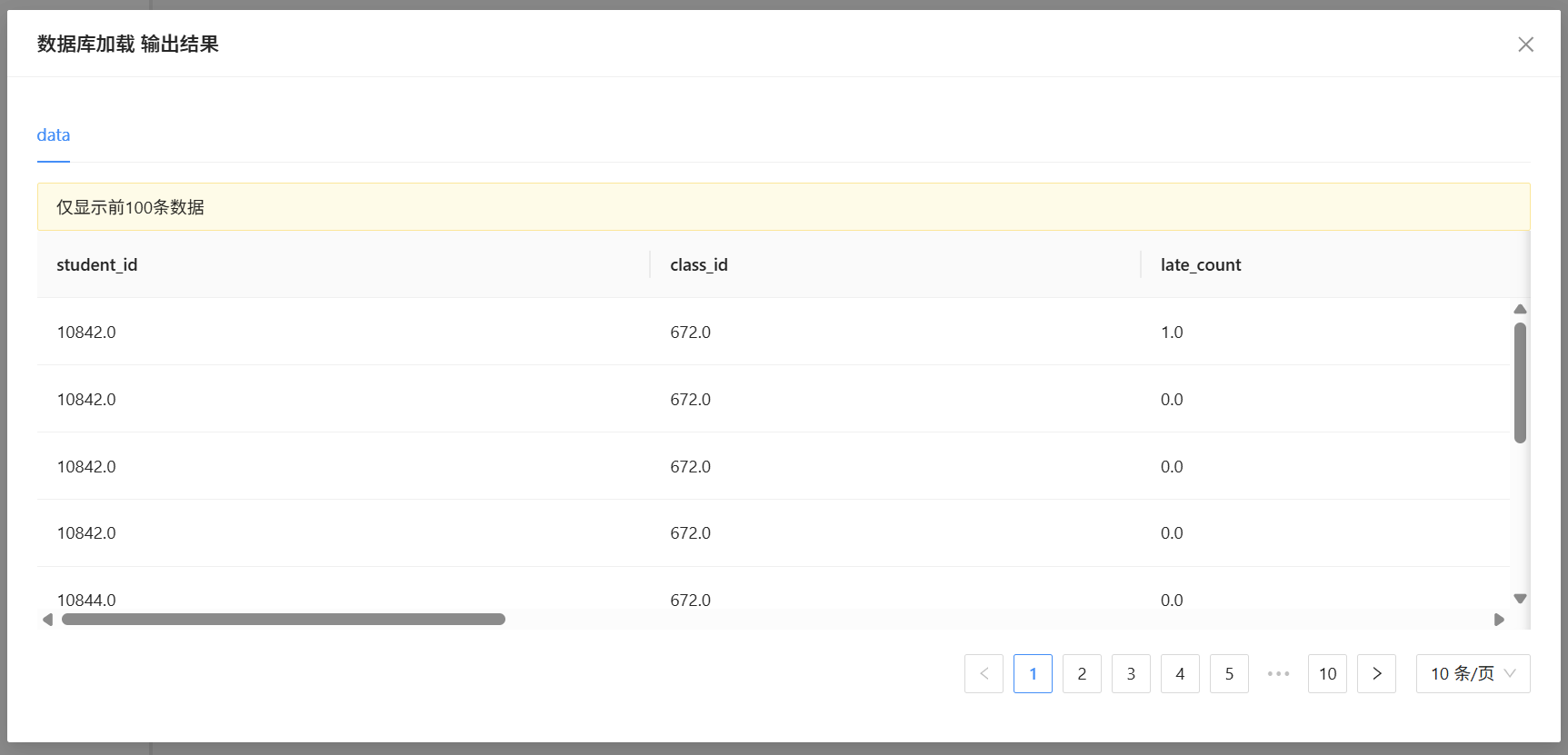
在左侧控件列表中检索数据库加载控件并将其拖拽至空白画布,双击控件进入配置页面,填写团队私有数据库账号、密码等连接信息并完成连通性测试,确认数据库连接无误后,选定student_attendance_stats数据表作为数据源。在字段配置页面中,保留学生ID、班级ID、迟到次数、早退次数、请假次数、校服违规次数六大核心字段,其余无关字段全部勾选跳过加载,同时规范字段数据类型,将学生编号类字段设置为分类类型,四项考勤违纪次数统一设置为数值类型,配置完成后右键点击运行控件,等待系统完成数据加载,加载结束后查看输出预览,校验字段格式与数据完整性,确保数据无缺失、无乱码。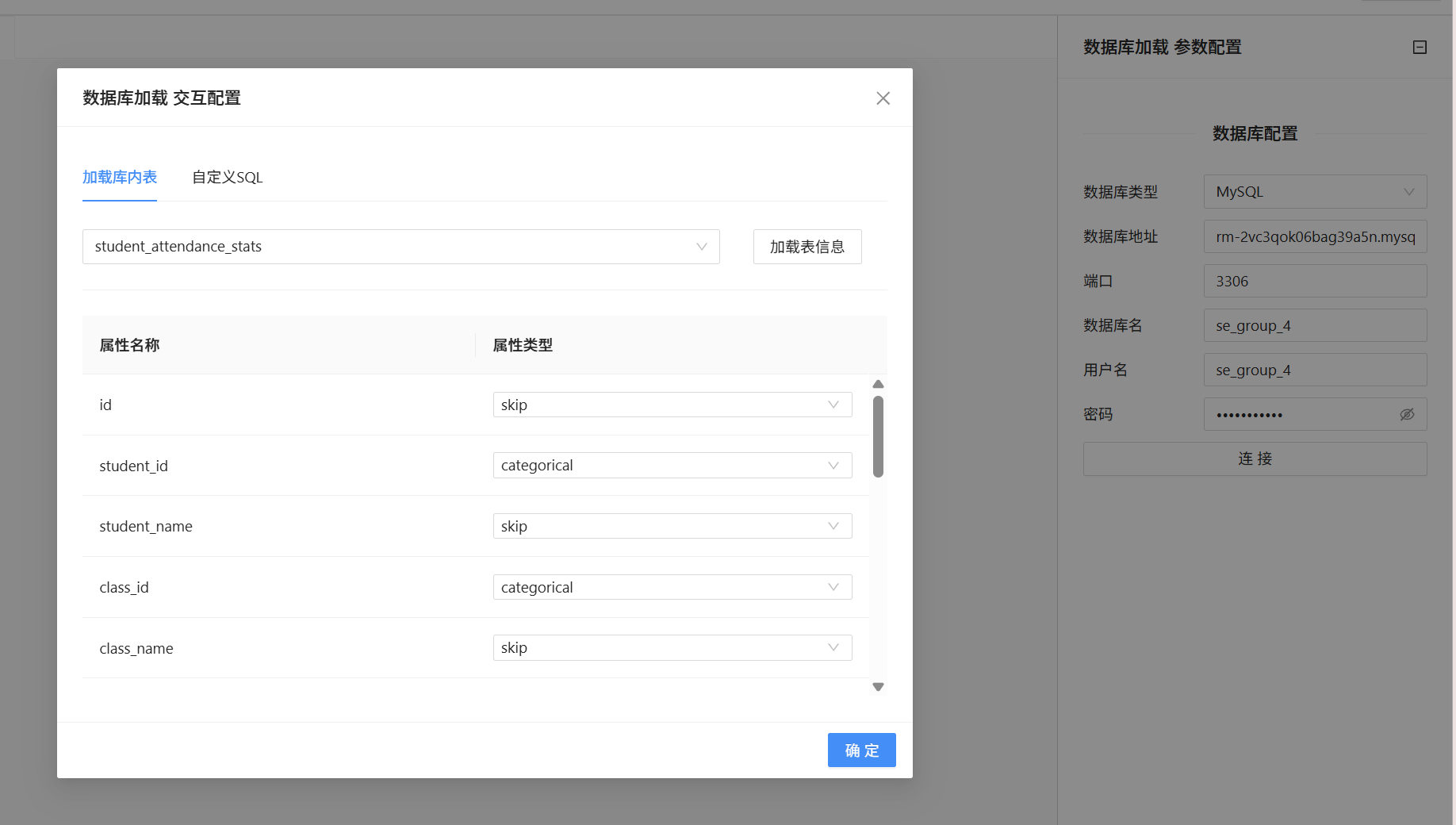
2.1.3 K-Means模型参数配置与运行
完成数据加载后,拖拽K-Means聚类算法组件至画布,使用连线工具将数据库加载组件的输出端口与聚类组件输入端口相连,保证数据正常流转。双击K-Means组件进入参数配置页面,结合业务需求将聚类簇数量固定设置为3类,其余迭代次数、距离算法等参数保持系统默认配置,无需手动修改。参数保存完成后右键运行聚类控件,系统自动完成数据迭代计算,算法运行结束后,每一条学生原始数据都会生成专属聚类编号,编号分为C1、C2、C3三类,用于区分不同考勤行为人群。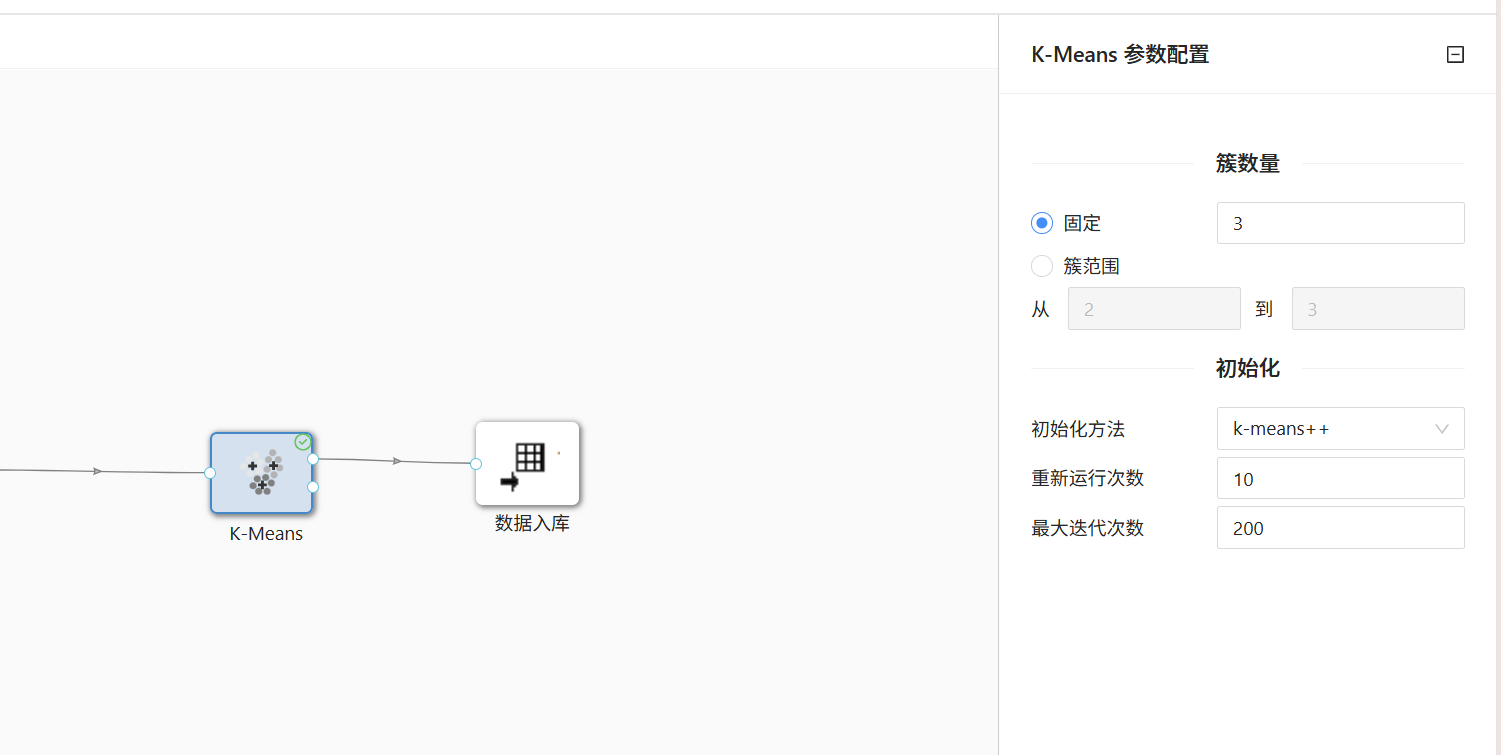
2.1.4 聚类结果入库保存
为持久化保存聚类计算结果,拖拽数据入库组件并连接K-Means算法输出端口,双击入库组件绑定团队私有数据库,在数据库内新建数据表并命名为student_cluster,用于存储带有聚类编号的学生明细数据。全部组件配置完毕后,一键运行整条工作流,等待流程执行结束,观察所有控件状态,全部控件显示绿色即为运行成功,聚类数据完整存入数据表。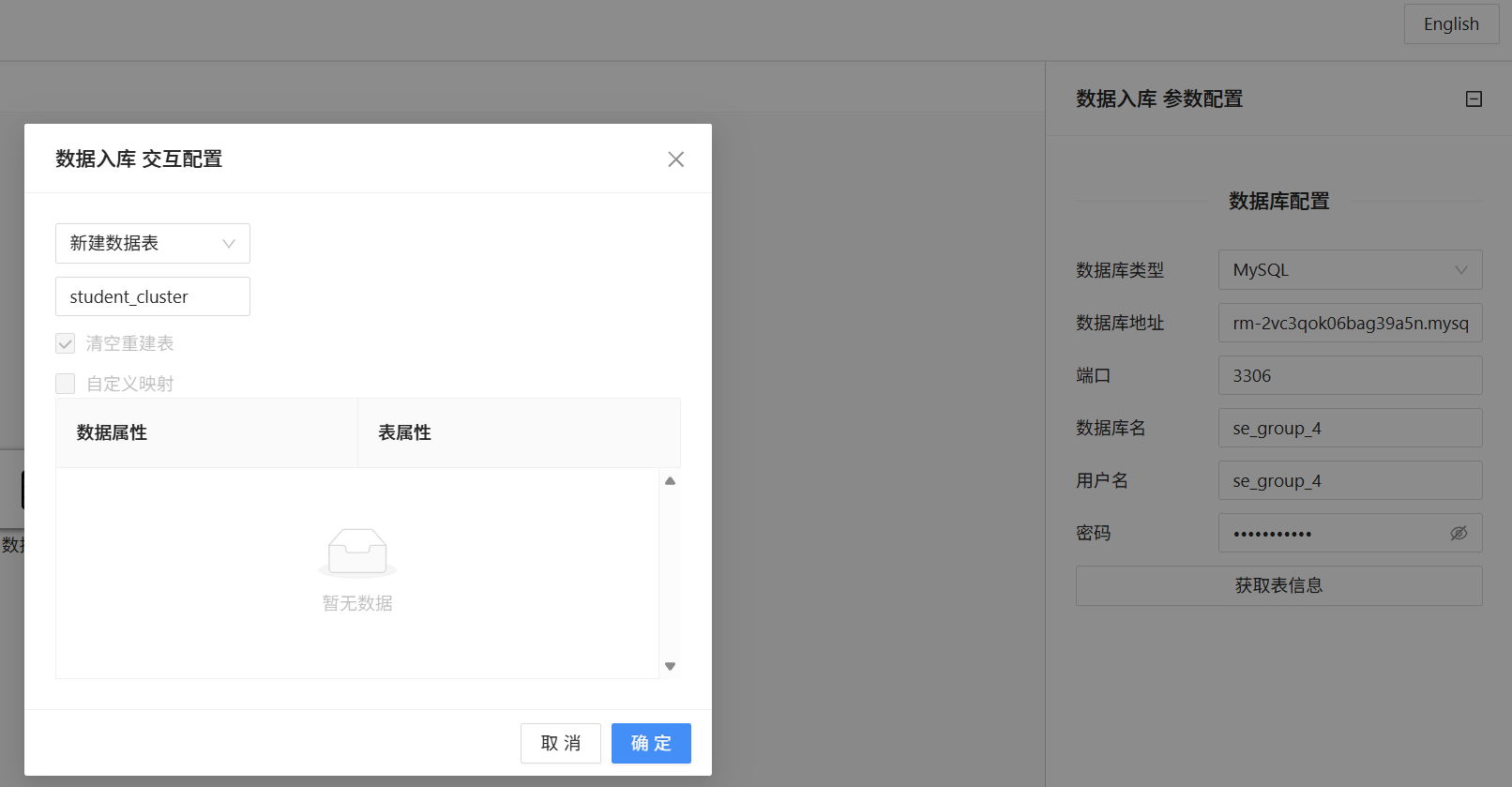
2.2 助睿BI聚类可视化分析
2.2.1 新建数据源连接
完成建模流程后,点击平台左侧导航栏进入助睿BI可视化平台,在数据源管理界面点击左上角新建连接,选择MySQL数据库连接类型,录入团队私有数据库配置信息,点击测试连接,提示连接成功后保存数据源,为后续可视化图表制作提供数据支撑。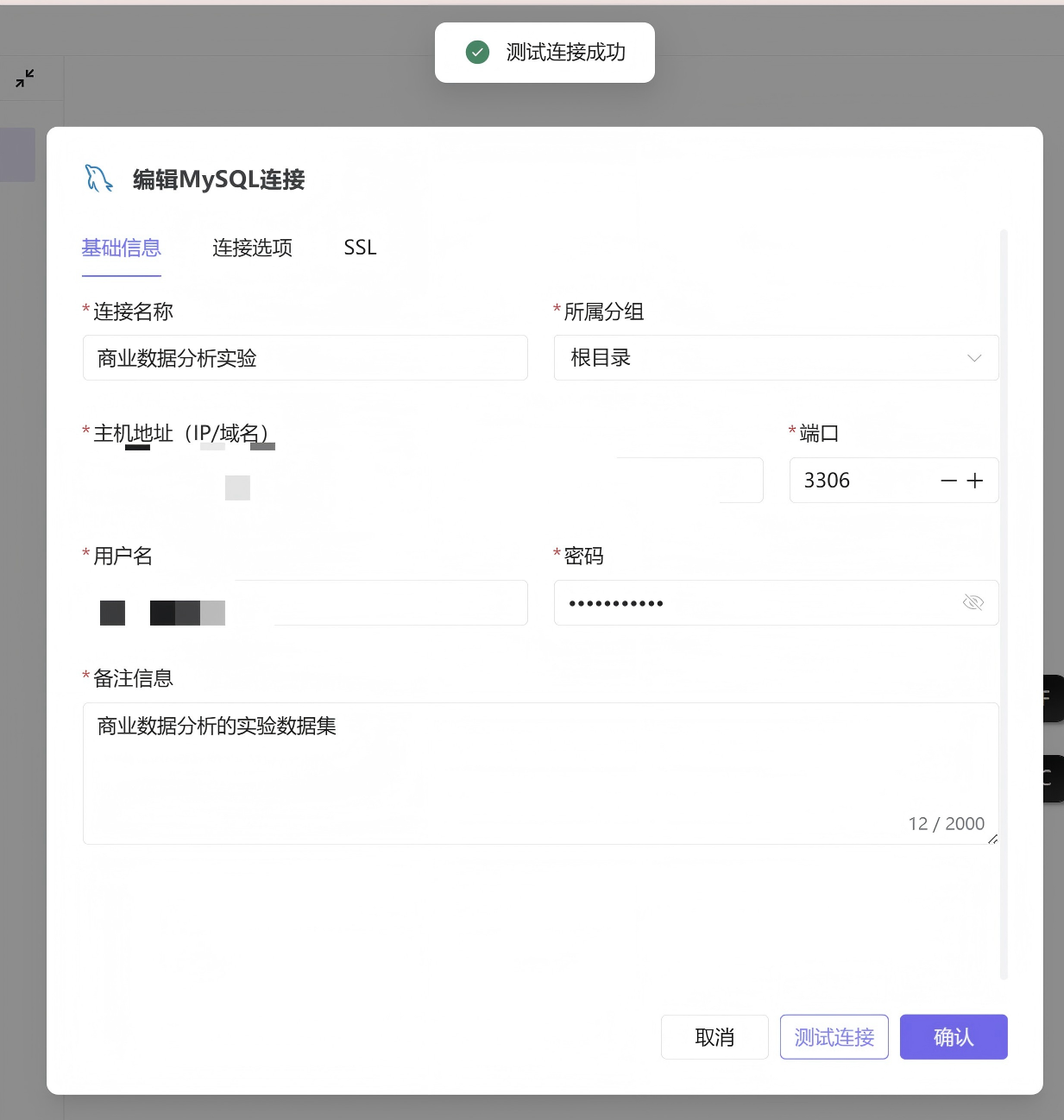
2.2.2 创建可视化数据集
进入数据集管理页面,新建自定义数据集,数据源选择已连通的团队数据库,数据目录选定labs文件夹,将刚刚生成的student_cluster聚类结果表拖拽至数据编辑画布。为提升可视化可读性,将数据表内英文字段统一修改为中文备注,确认字段无误后保存并发布数据集,使数据集能够被工作表正常调用。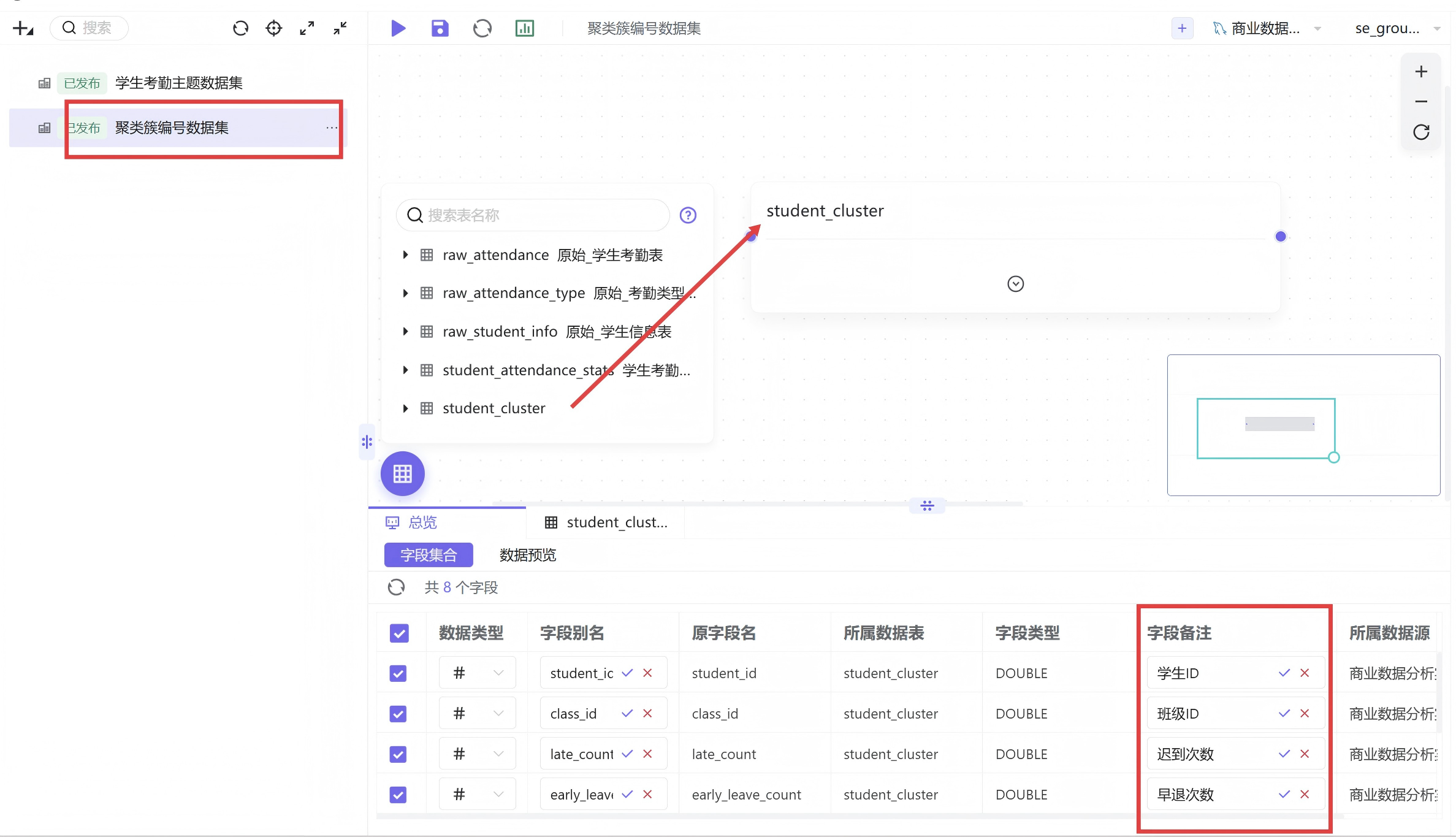
2.2.3 制作六张聚类散点工作表
为直观观察三类人群的考勤分布差异,本次实验需要制作六张两两组合的考勤指标散点图,为保证操作流程清晰、便于配图参考,本次以迟到-早退散点图作为详细示例步骤,其余五张图表复刻该操作流程制作,仅替换坐标轴指标。
-
示例图:迟到-早退散点图详细制作步骤
进入工作表模块并新建专属分组,在分组内新建空白工作表,图表类型选择探索器散点图;将迟到次数拖拽至X轴、早退次数拖拽至Y轴。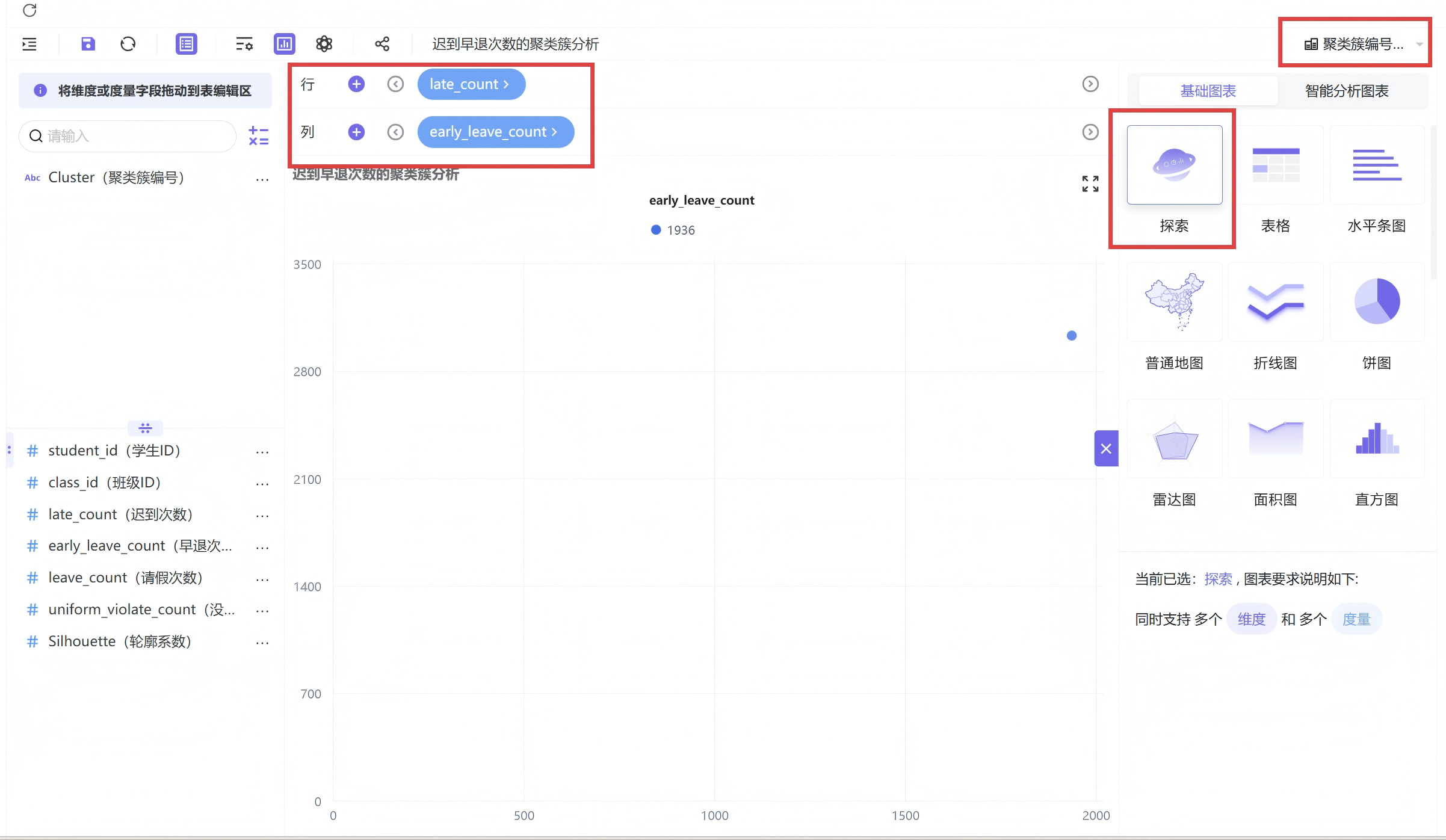
聚类簇编号绑定颜色维度,实现三类人群色彩区分,学生ID添加至信息展示栏,鼠标悬浮即可查看学生编号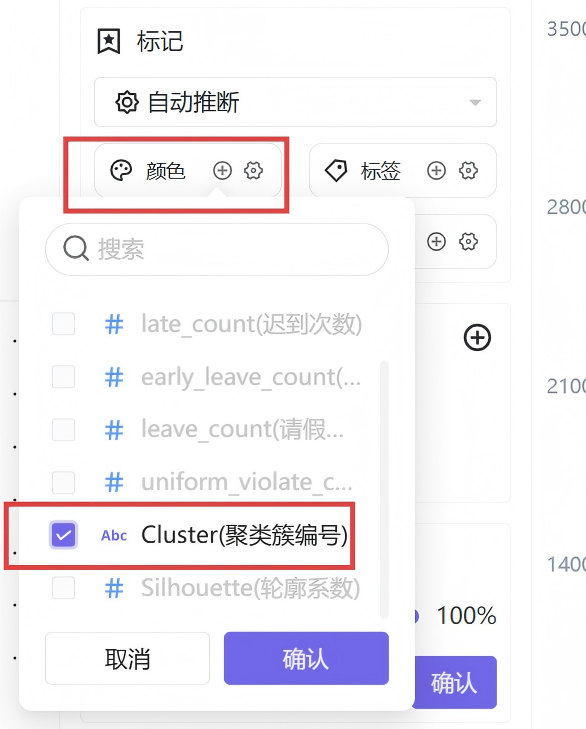
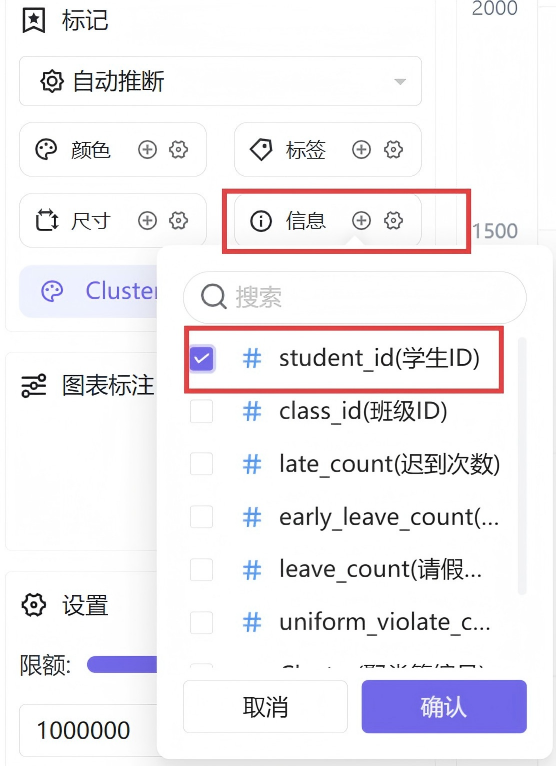
在图表设置中将数据展示限额调整为100%,保证全量数据无遗漏展示。
手动修改图表配色,拉大三类聚类人群颜色对比度,最后命名工作表并保存,完成单张散点图制作。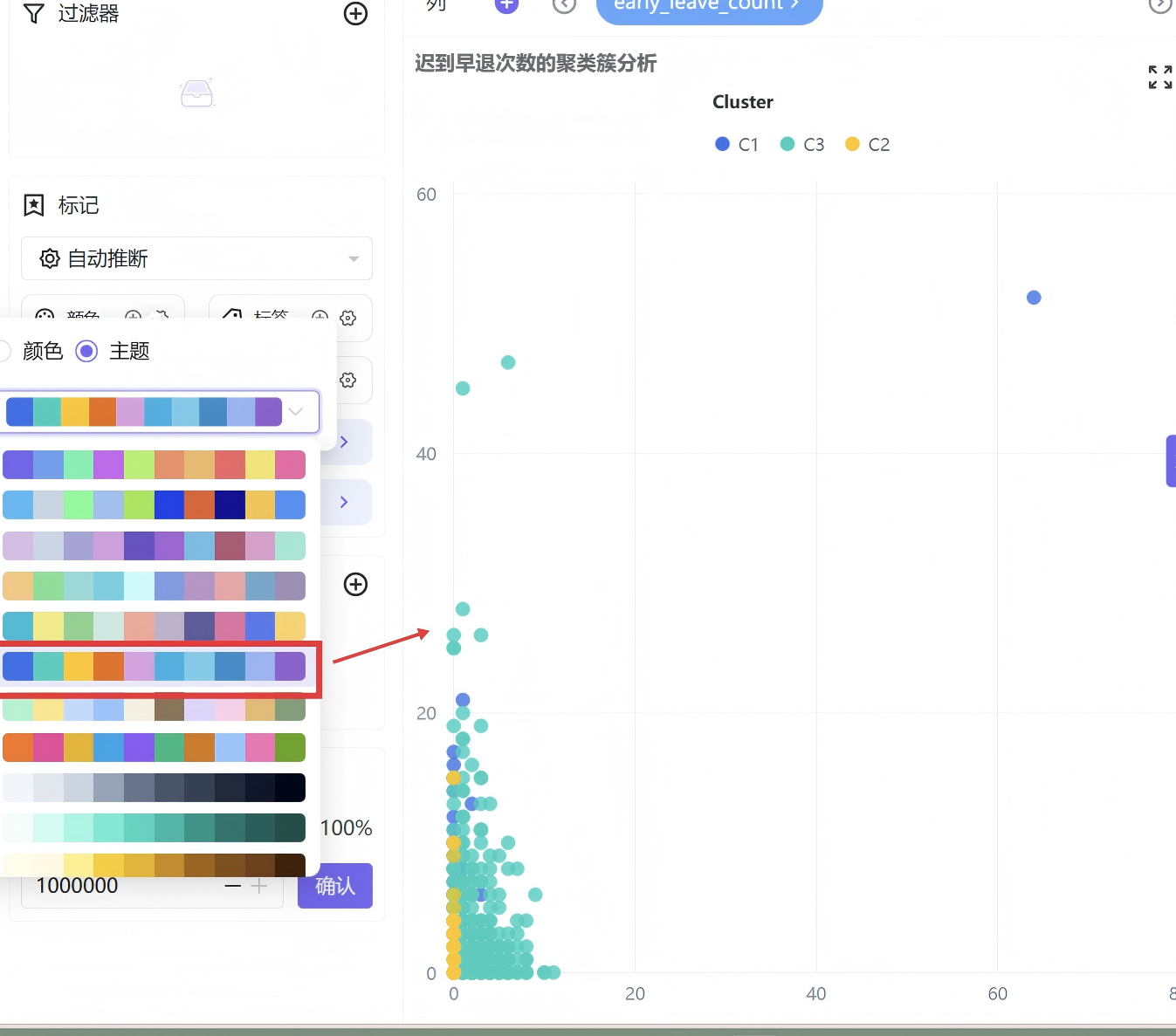
-
其余五张散点图简要制作说明
剩余迟到-请假、迟到-校服违规、早退-请假、早退-校服违规、请假-校服违规五张散点图,均沿用上述一模一样的制作流程,仅需要在坐标轴处替换对应的两项考勤指标,无需改动其他配置参数,依次保存图表并放入同一分组。
2.2.4 聚类分析仪表盘制作
为整合所有分析图表、实现一体化观测,新建仪表盘并命名为聚类簇分析,在画布中添加文本标题组件,设置文字加粗、居中放大,优化看板美观度。随后将六张散点分析图全部拖拽至仪表盘画布,手动调整图表大小、排版间距,完成布局优化后锁定组件位置,保存并发布仪表盘,实现聚类结果集中可视化展示。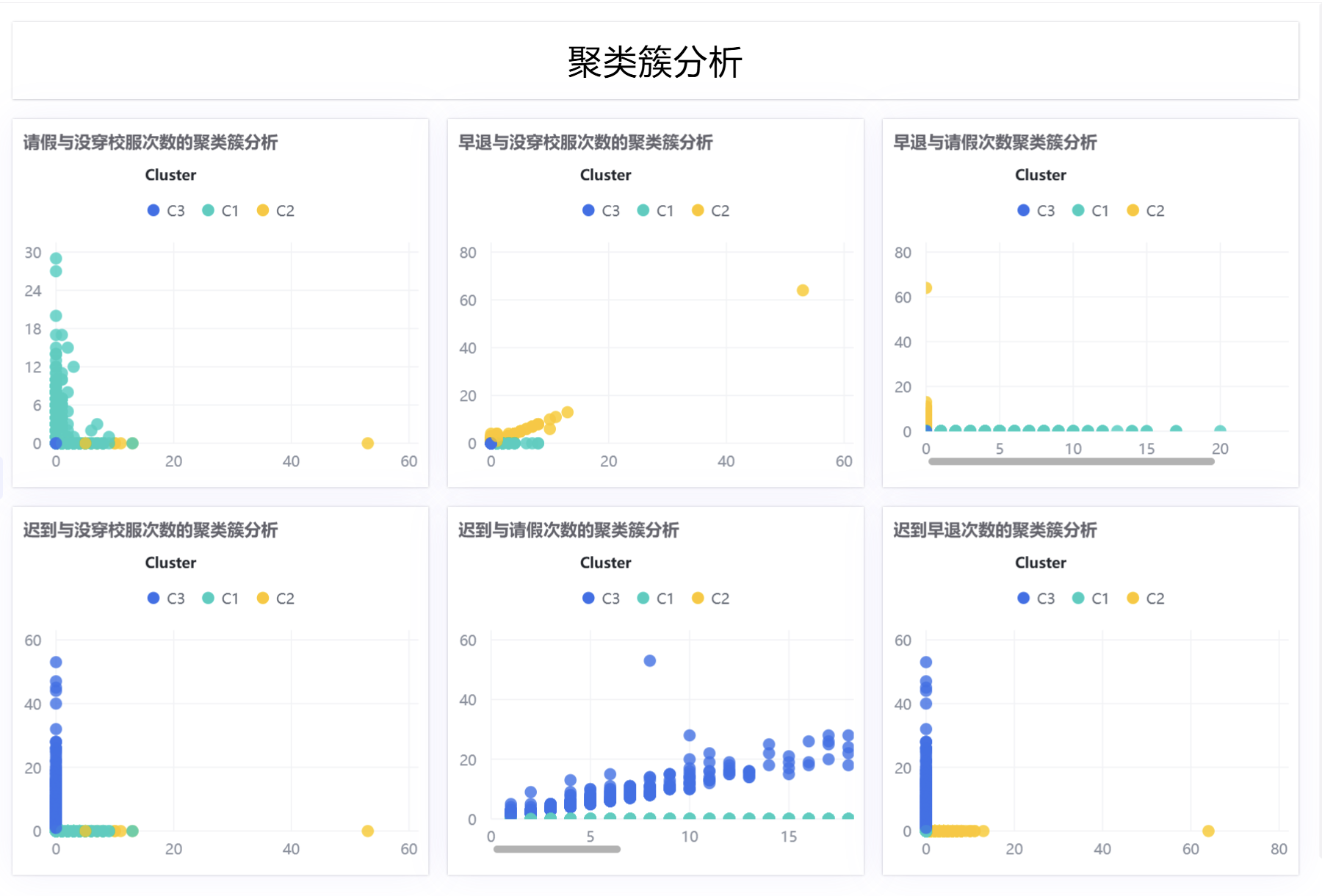
2.2.5 聚类人群业务划分
结合六张散点图的数据分布特征,依据违纪行为频次完成人群业务定义,结合聚类编号形成标准化人群标签,具体划分规则如下表所示。
| 聚类编号 | 人群分类 | 行为特征说明 |
|---|---|---|
| C1 | 自律模范型 | 各类考勤违规次数极低,出勤状态稳定 |
| C2 | 轻微波动型 | 无频繁迟到早退,偶发请假、校服违规行为 |
| C3 | 纪律高危型 | 迟到行为频繁,存在多项违纪叠加现象 |
2.3 ETL标签回写整合
主要流程如下: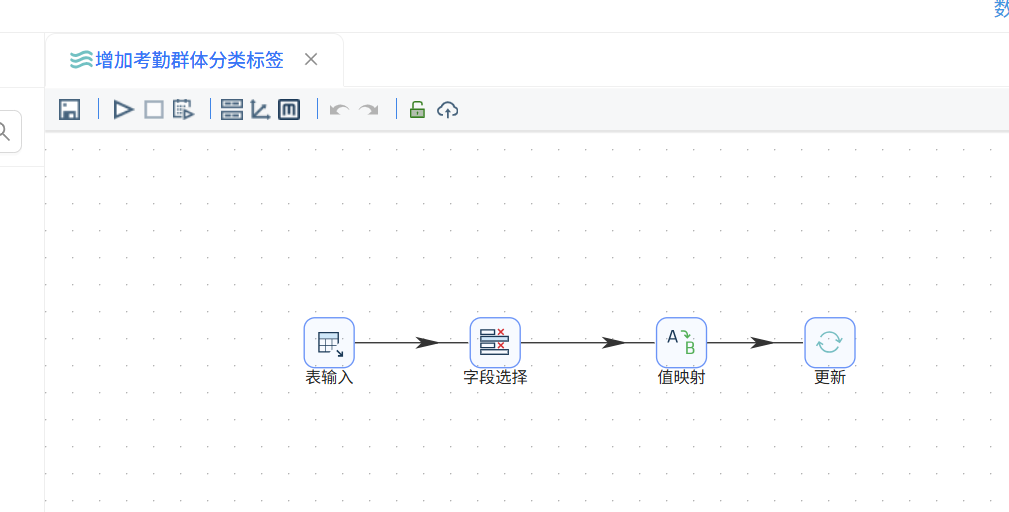
2.3.1 数据表新增扩展字段
为将聚类标签永久绑定至原始考勤数据,进入助睿ETL数据集成平台,创建全新数据转换流,拖拽SQL执行组件并输入数据表修改语句,为student_attendance_stats原始考勤表新增cluster聚类编号、attendance_group人群分类两个扩展字段,执行SQL脚本完成数据表结构修改,为后续标签写入预留字段空间。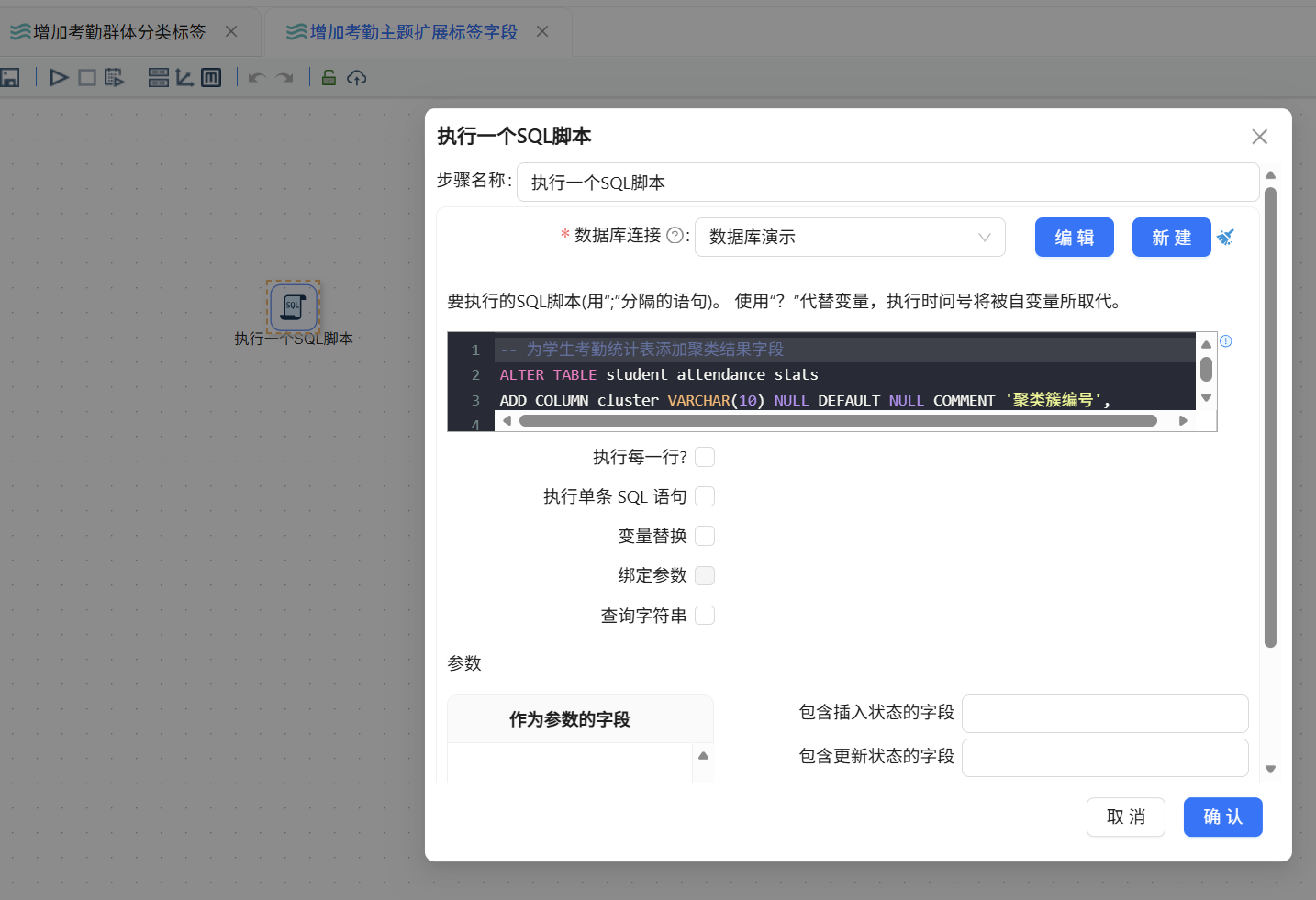
-- 为学生考勤统计表添加聚类结果字段
ALTER TABLE student_attendance_stats
ADD COLUMN cluster VARCHAR(10) NULL DEFAULT NULL COMMENT '聚类簇编号',
ADD COLUMN attendance_group VARCHAR(30) NULL DEFAULT NULL COMMENT '考勤群体分类';
2.3.2 读取聚类结果数据
新建一条独立转换流,拖拽表输入组件并绑定团队私有数据库,读取student_cluster聚类结果表内全部数据,为后续筛选、映射、更新操作提供数据源。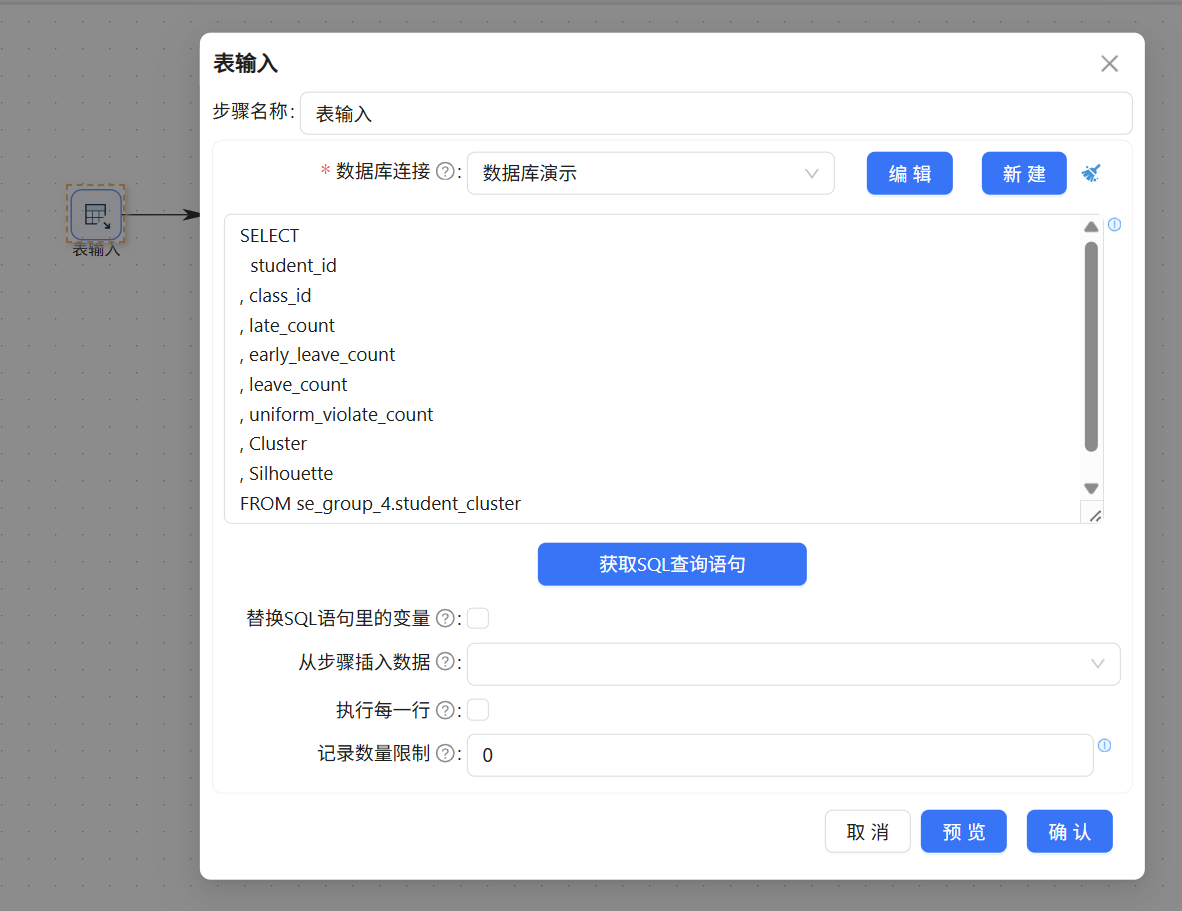
2.3.3 筛选有效字段
在转换流中添加字段选择组件,连接表输入端口,剔除多余冗余字段,仅保留学生ID与聚类编号两个核心字段,同时统一字段数据类型,将字段格式修改为Integer整型,保证与原始考勤表字段格式一致,避免数据更新报错。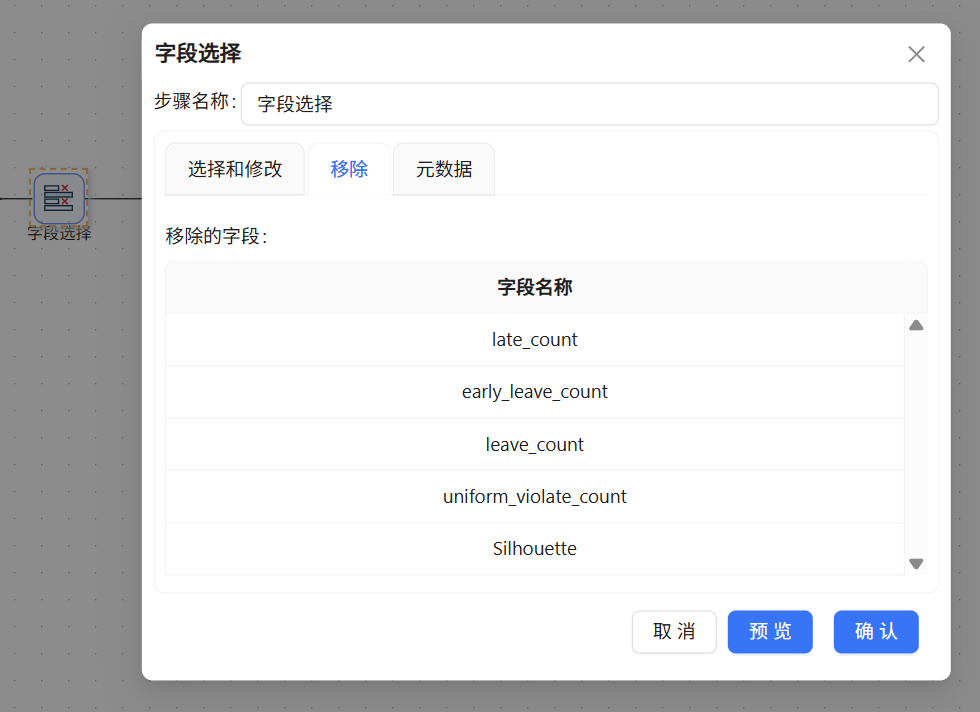
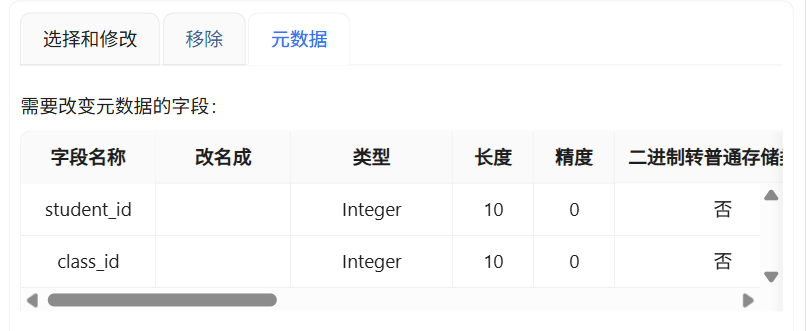
2.3.4 聚类编号中文映射
拖拽值映射组件,以聚类编号为映射依据,设置中英文标签转换规则,将机器生成的编码转化为通俗易懂的业务标签,其中C1映射为轻微波动型、C2映射为自律模范型、C3映射为纪律高危型,实现标签业务化转换。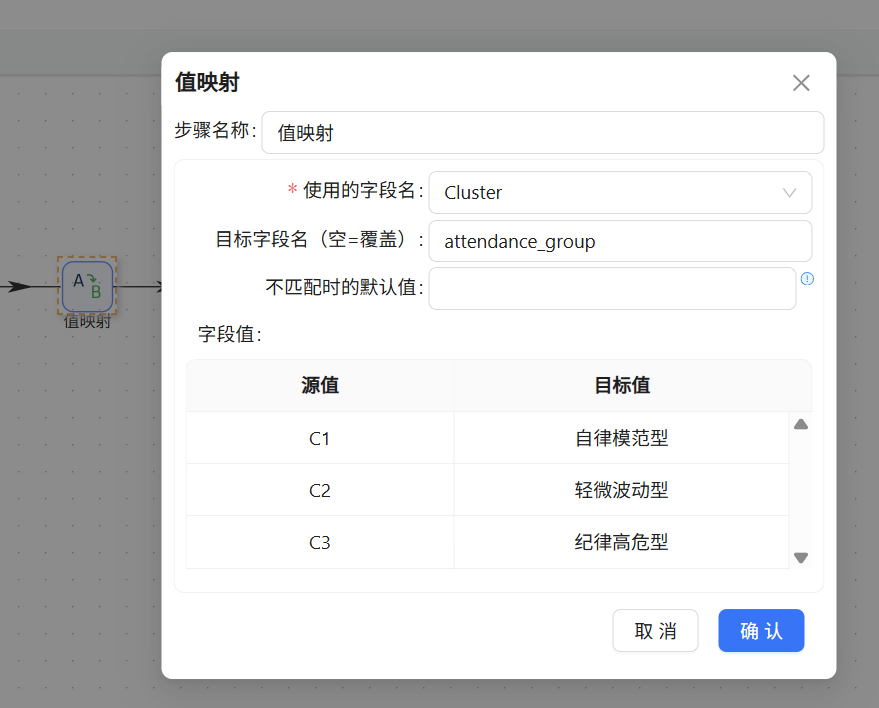
2.3.5 批量更新原始数据表
添加数据更新组件并绑定student_attendance_stats数据表,将学生ID设置为关联主键,保证学生数据一一对应,把聚类编号、中文人群分类批量写入提前新增的扩展字段中。全部配置完成后运行转换流,查看平台运行日志,确认数据更新语句执行成功,无报错、无异常数据。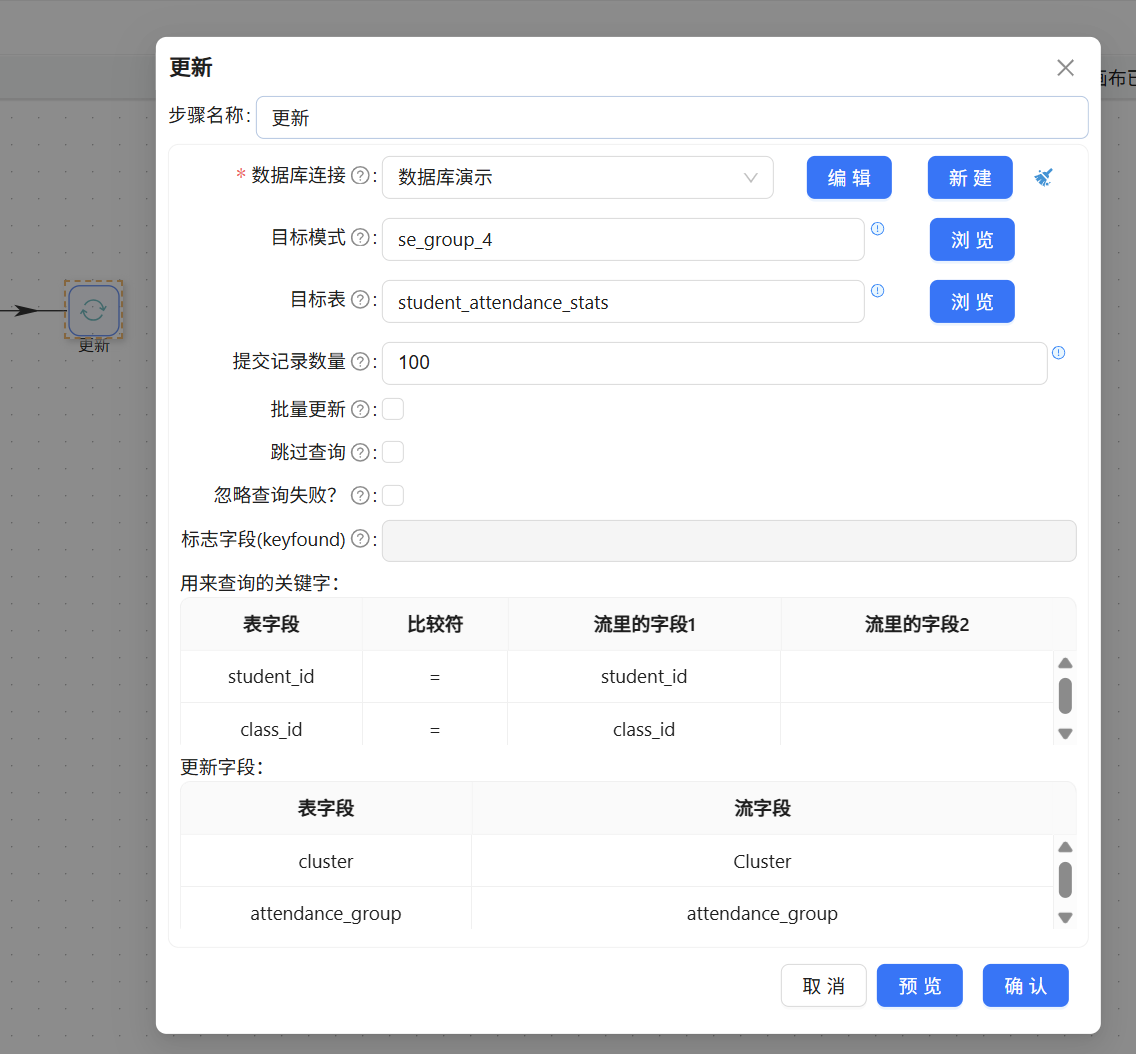
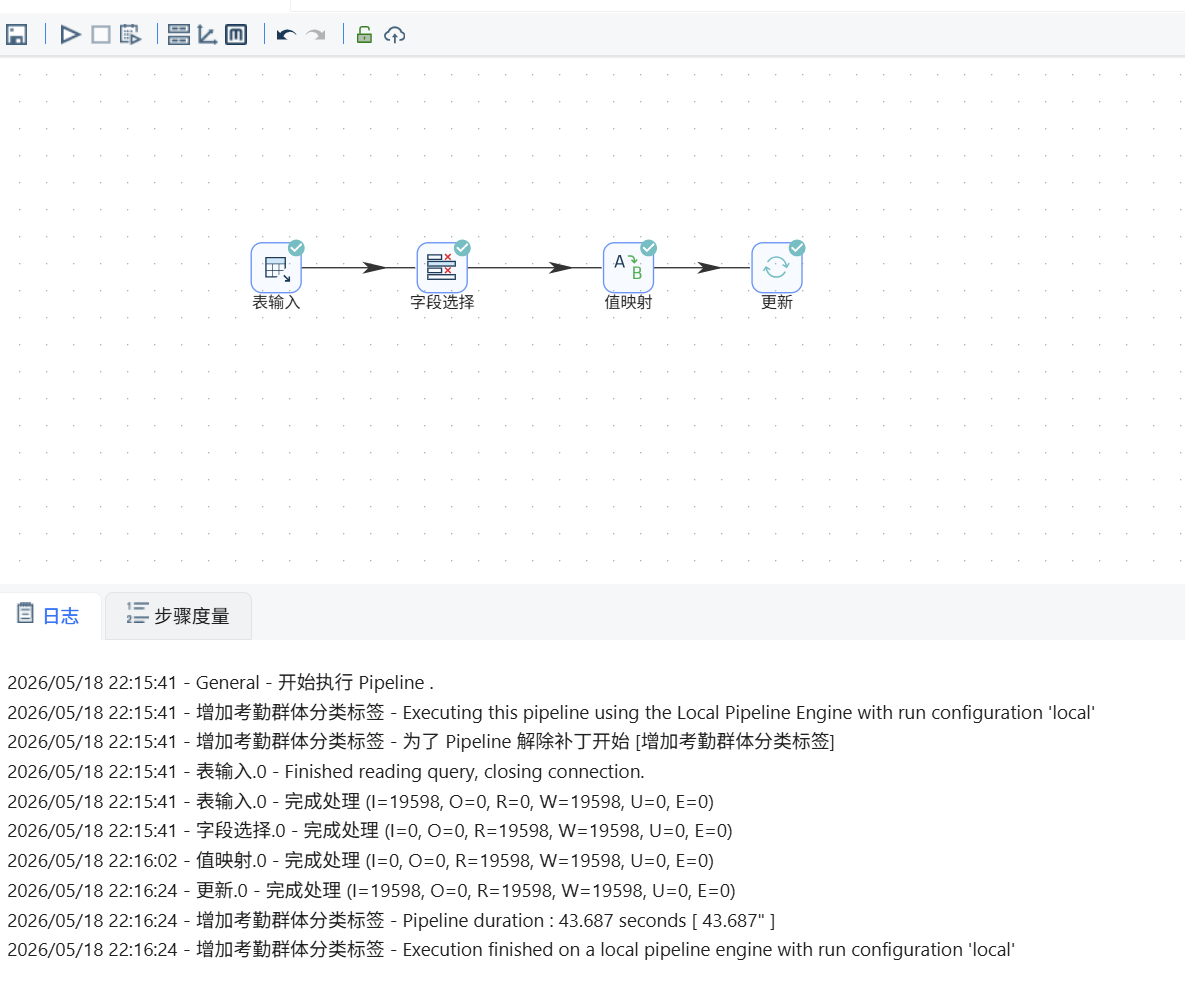
2.3.6 数据结果核验
数据更新结束后,手动刷新数据库元数据,重新打开原始考勤统计表,逐条抽查学生数据,核验每一位学生是否成功匹配聚类编号与考勤人群标签,确认标签回写完整、无缺失、无错乱,第一阶段实验流程全部结束。
三、学生用户画像 - 考勤画像可视化分析
3.1 数据源与数据集搭建
3.1.1 复用已有数据源
本阶段实验沿用第一阶段已经配置完成的团队私有数据库连接,无需重复新建数据源,直接复用连通接口,减少重复配置操作,提升实验效率。
3.1.2 新建分析数据集
在BI平台数据集页面新建空白数据集,在labs数据目录中选中已经完成标签标注的student_attendance_stats数据表,由于数据表前期已配置中文字段备注,本次无需手动修改字段名称,确认数据预览无误后保存并发布数据集,用于高危学生专项可视化分析。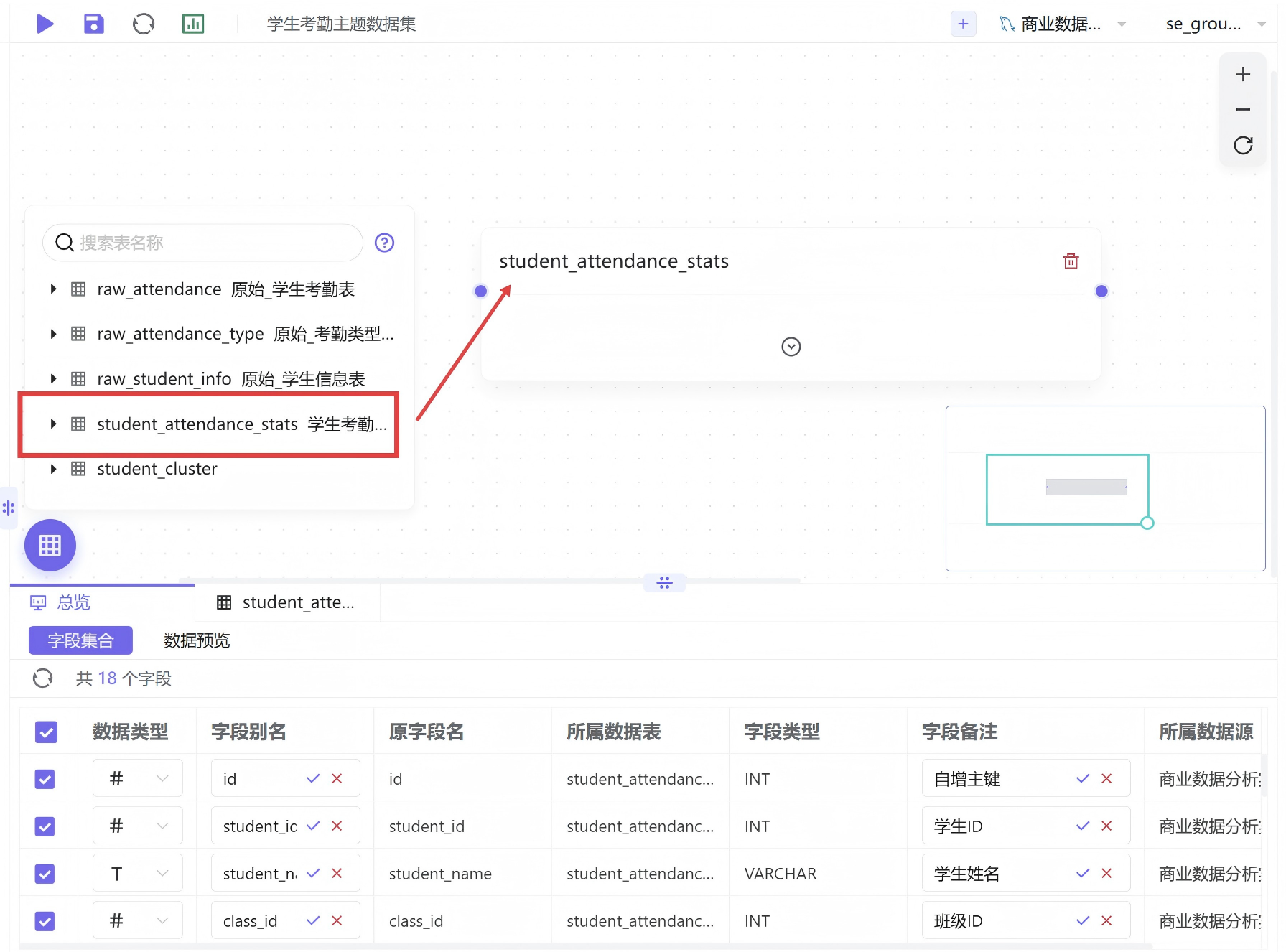
3.2 多维度可视化工作表制作
本章节围绕纪律高危型学生展开多维度分析,制作多种类型统计图表,为适配配图要求、简化重复操作,每一类图表选择一张作为详细示例制作步骤,同类其余图表简要说明制作逻辑,统一复刻操作即可,图表汇总说明如下:
| 图表类型 | 图表名称 | 分析用途 |
|---|---|---|
| 指标卡 | 高危人数统计卡片 | 展示高危群体总人数及性别分布人数 |
| 饼图 | 性别占比分析图 | 对比全校与高危人群性别结构差异 |
| 柱状图 | 年级分布统计图 | 分析高危学生年级聚集特征 |
| 柱状图 | 校区年级交叉图 | 区分新老校区高危人数分布 |
| 水平条形图 | 高危班级排名图 | 定位高危学生集中班级 |
3.2.1 指标卡制作(高危人数统计)
- 示例图:高危总人数指标卡详细制作步骤
新建工作表并选择指标卡图表类型,将学生ID字段拖拽至数据值维度,修改聚合方式为去重计数,保证学生人数统计不重复。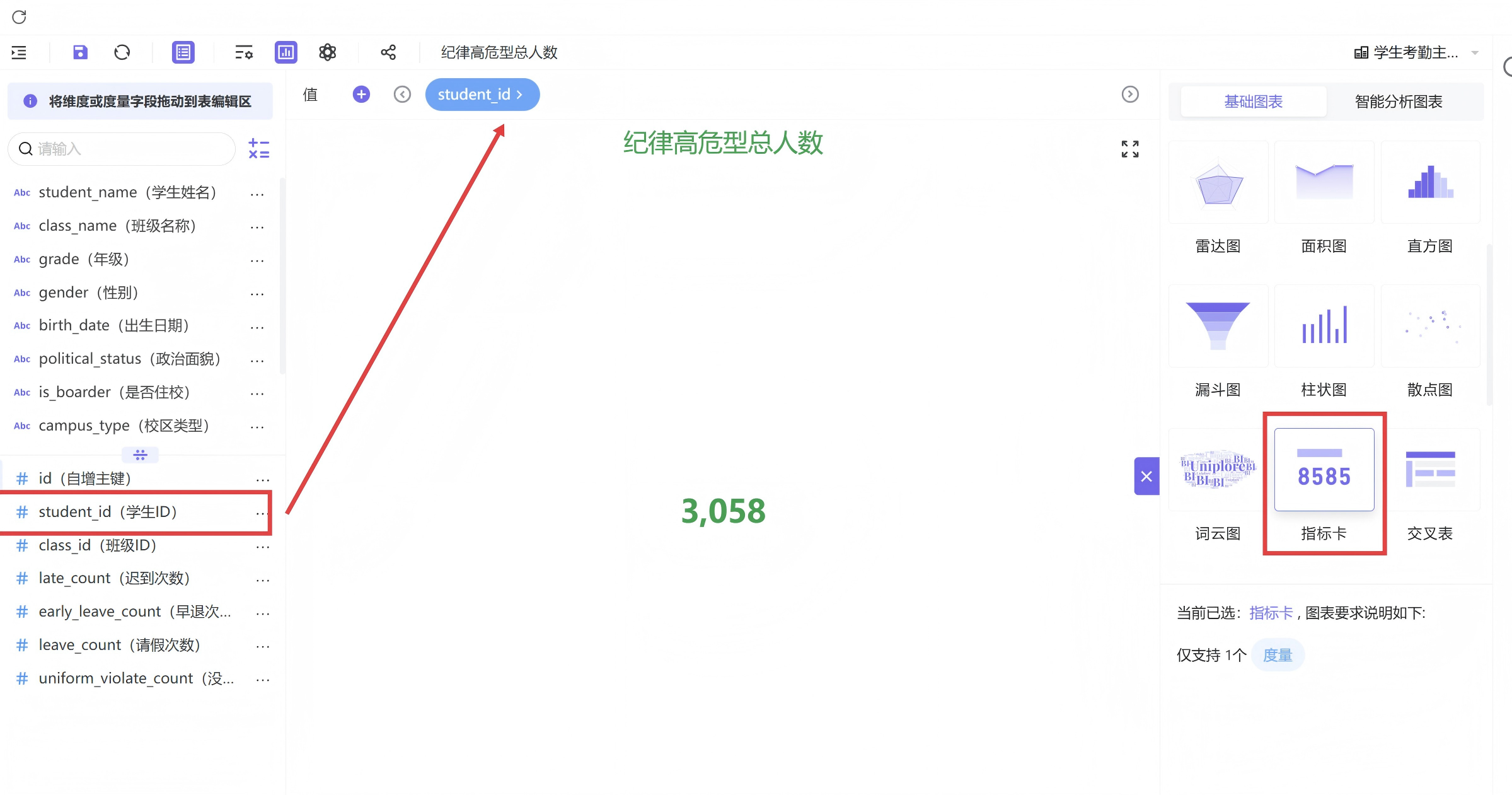
在过滤器中添加考勤群体分类字段,仅勾选纪律高危型人群,筛选出目标样本;进入样式设置页面,优化视觉观感,保存图表完成制作。
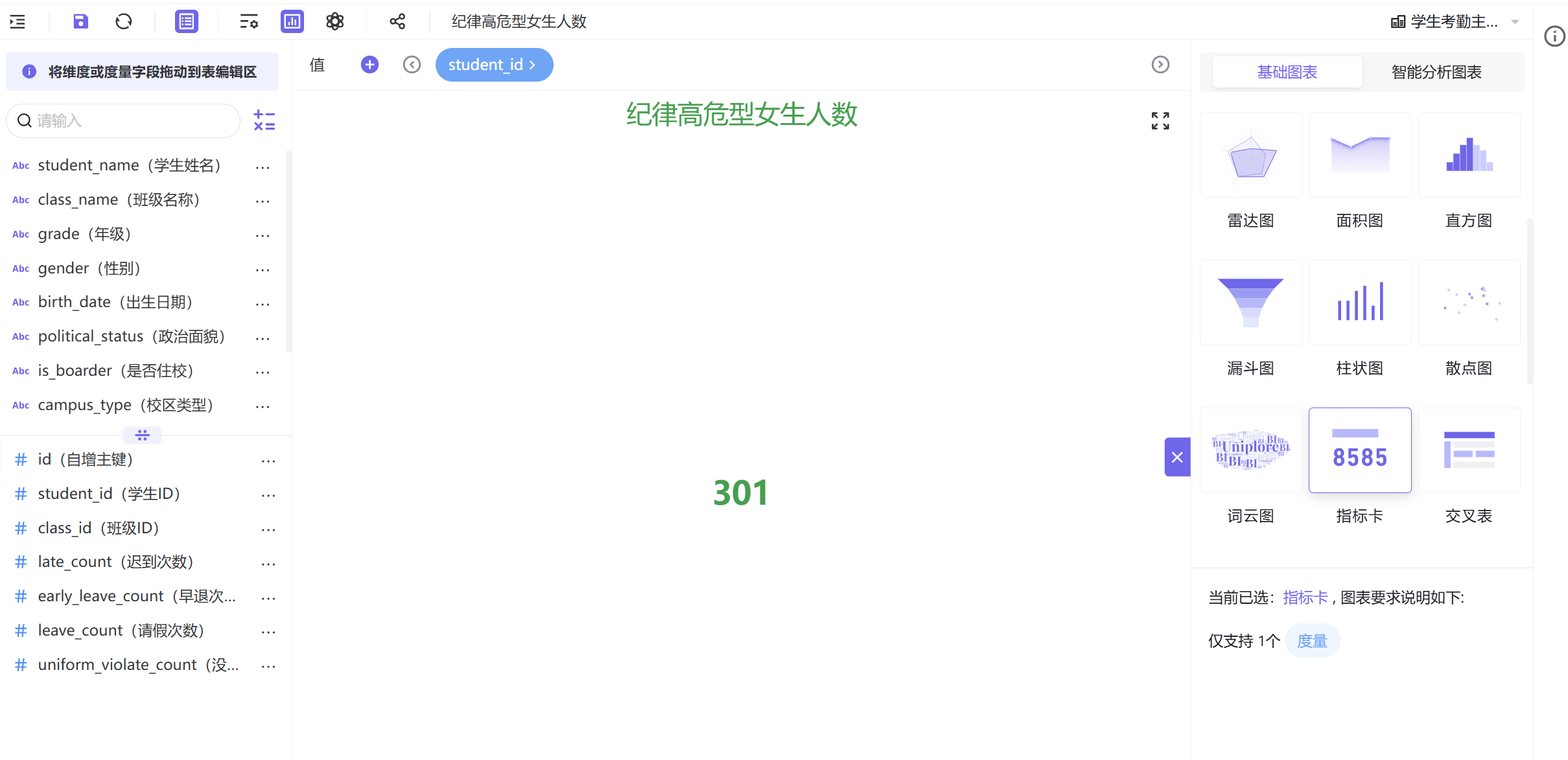
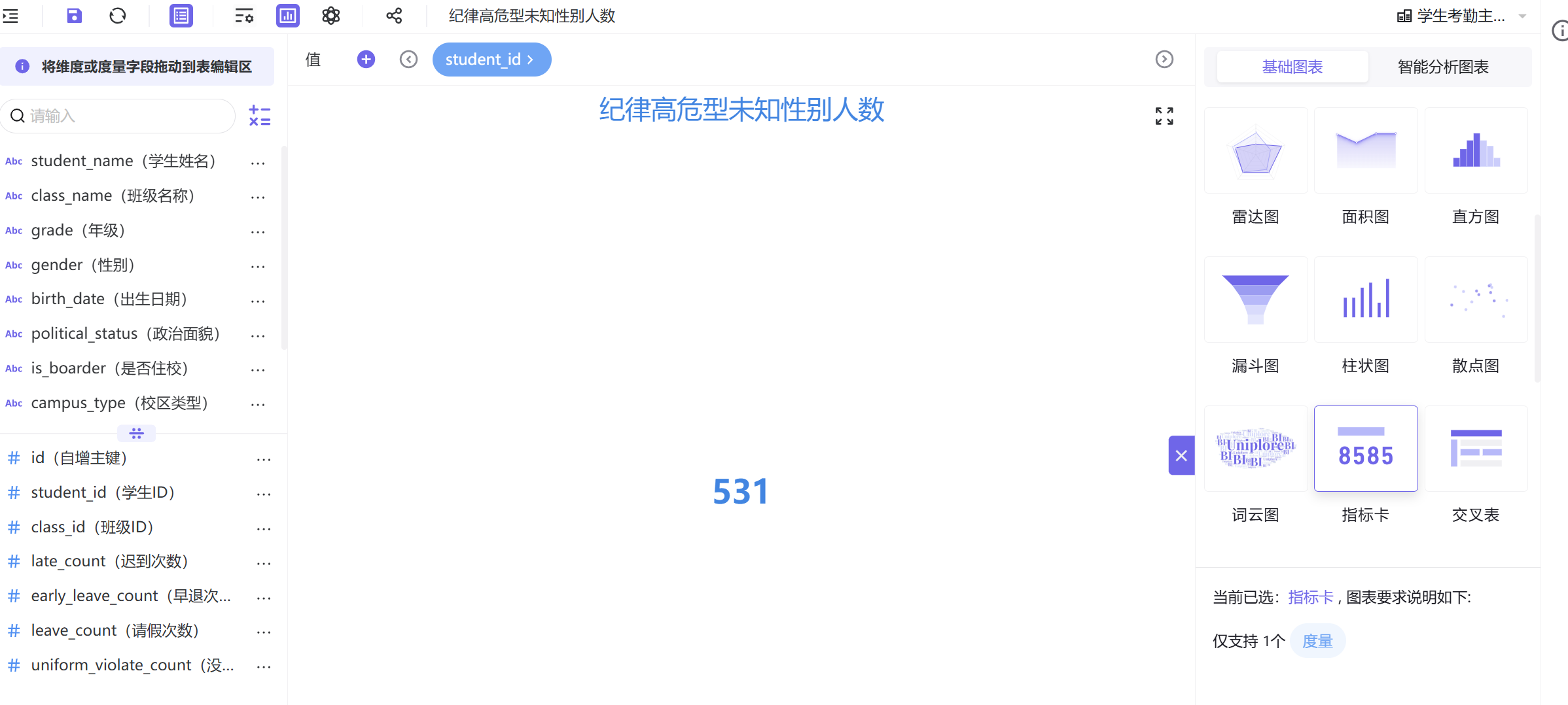
- 其余三张指标卡简要制作说明
男生人数、女生人数、未知性别人数指标卡,均复刻高危总人数指标卡制作流程,仅需在过滤器中叠加对应的性别筛选条件,样式格式保持统一即可。
3.2.2 性别占比饼图制作
- 示例图:高危学生性别占比饼图详细制作步骤
新建饼图工作表,以学生ID去重计数为统计指标,性别字段作为分类维度
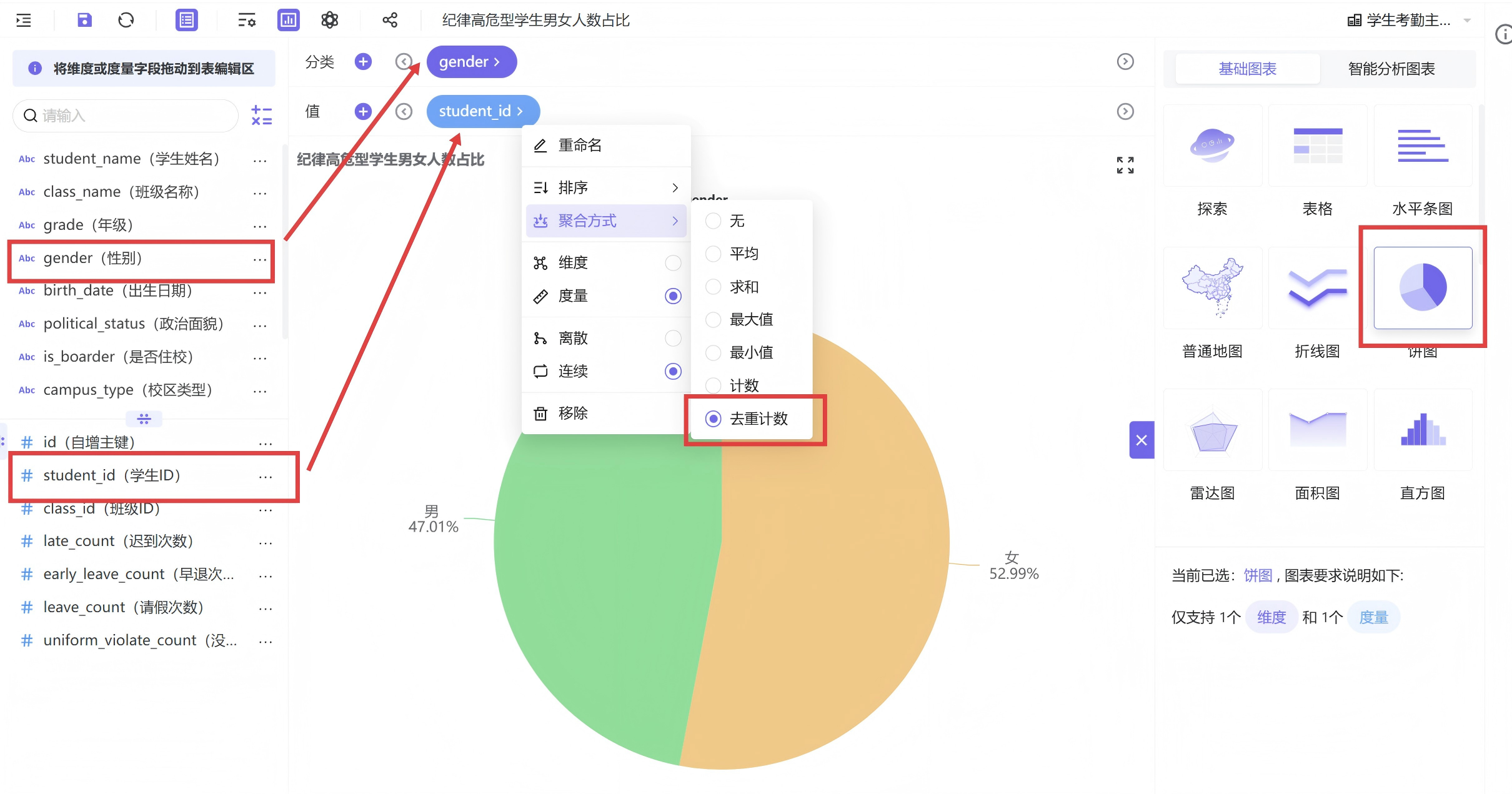
在过滤器中排除性别未知样本,同时勾选纪律高危型人群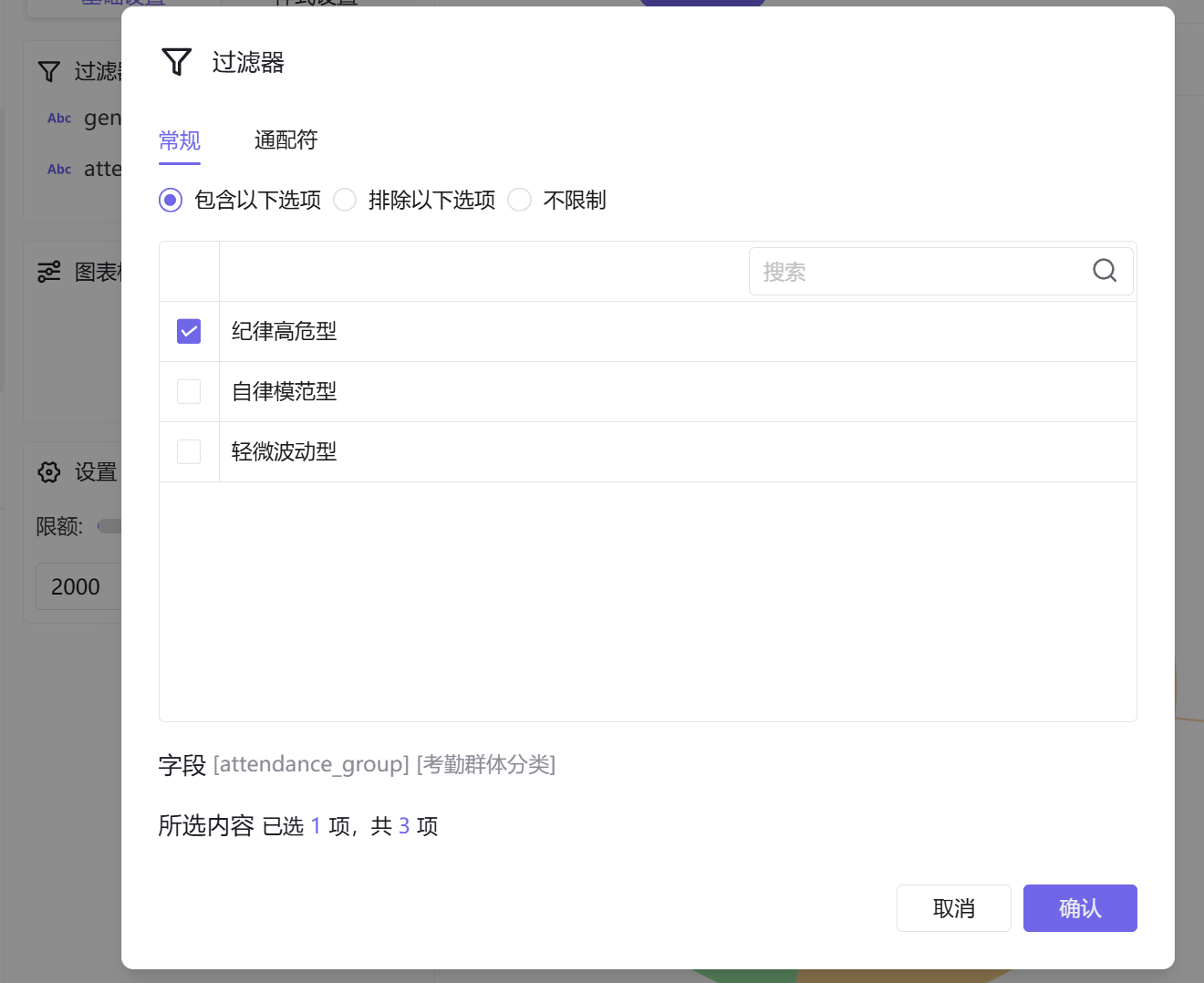
通过基础设置修改样式如下: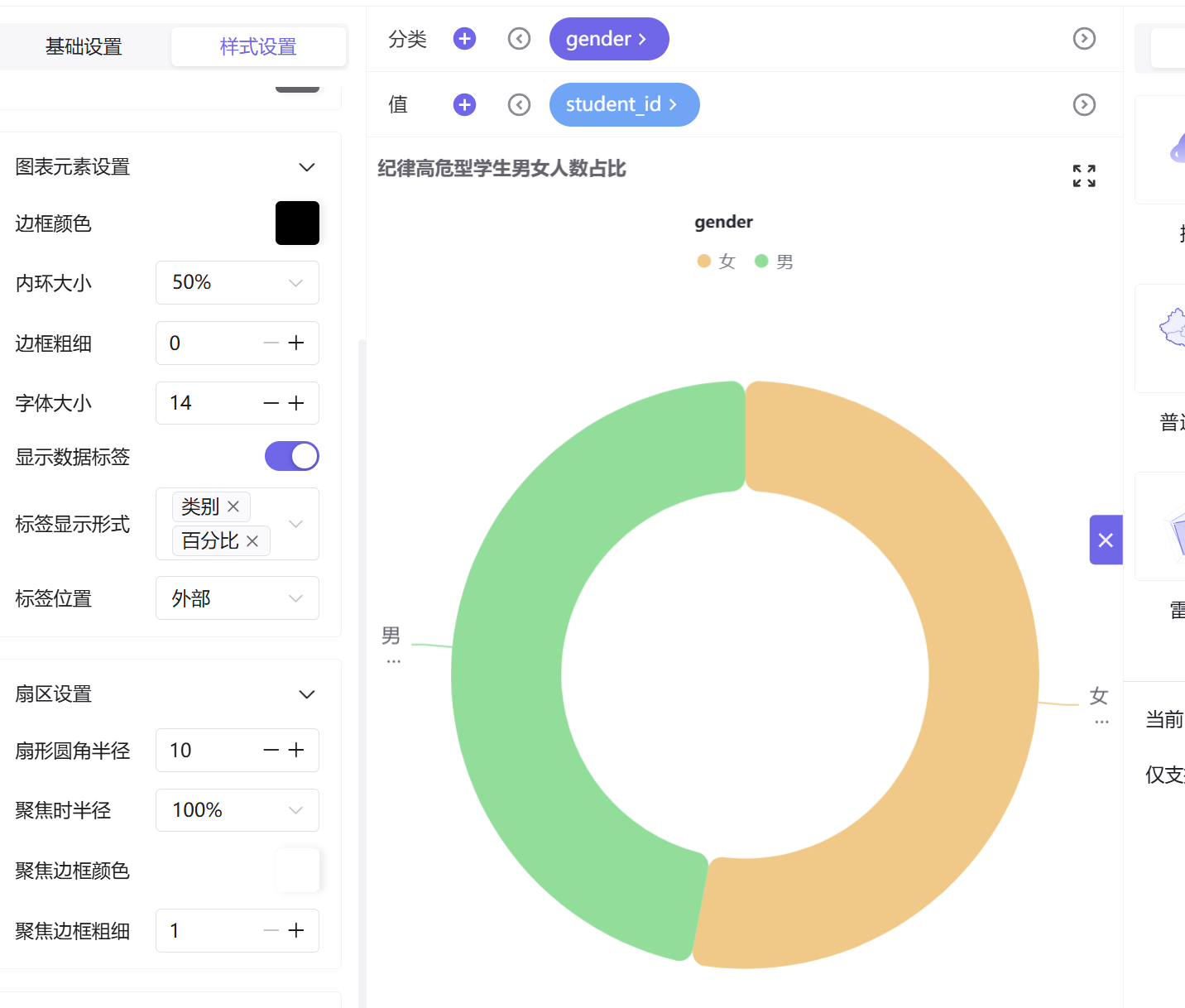
2. 对比饼图简要制作说明
全校学生性别占比饼图沿用相同配置,仅取消高危人群筛选,保留全部学生样本,用于前后数据对照分析。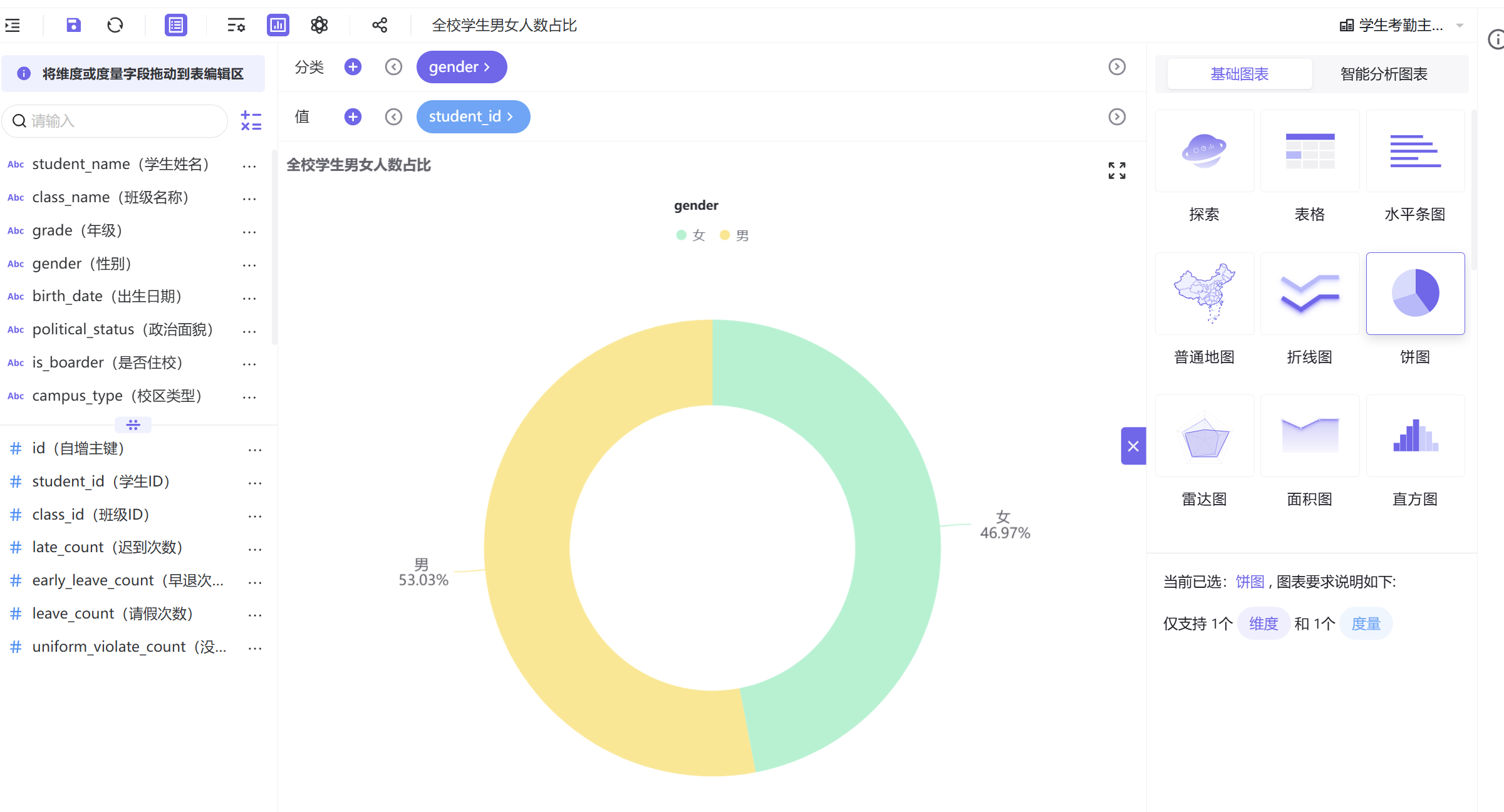
3.2.3 年级分布柱状图
新建柱状图工作表,将年级字段映射至X轴,学生人数映射至Y轴,筛选条件仅保留纪律高危型学生,生成年级分布统计图。为保持报告视觉统一,沿用前期图表配色方案,取消柱状边框线条,使图表简洁干净,直观观察不同年级高危学生数量差异。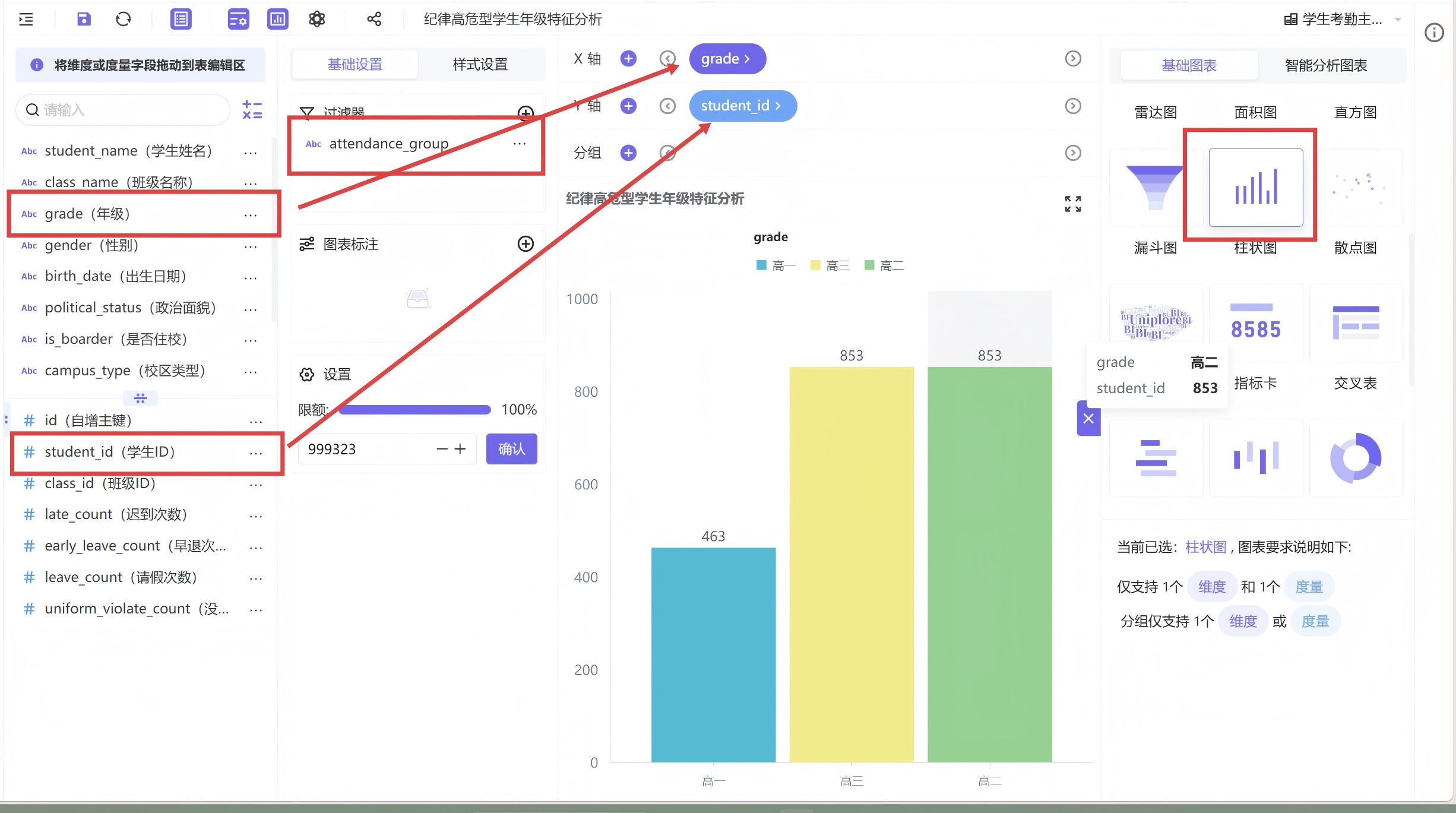
3.2. 4 不同校区类型各年级学生人数
在年纪分布柱状图基础上,添加校区类型作为分组维度数据,生成堆叠柱状图如下,可以清晰查看各个年级和校区的分布状况。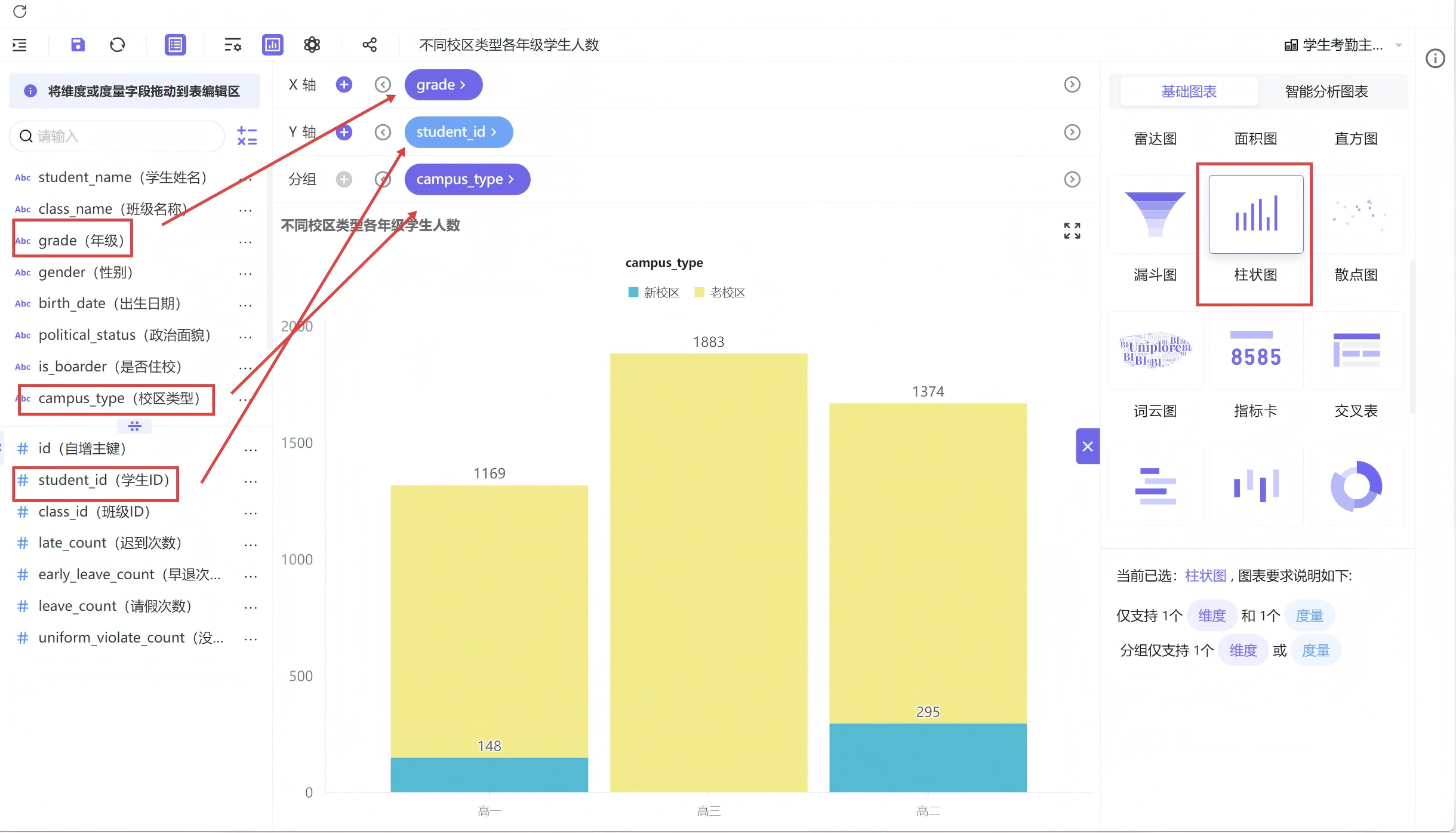
3.2.5 校区+年级高危数据交叉柱状图
在年级校区柱状图基础上,将校区类型字段添加至分组维度,生成堆叠柱状图,清晰区分新、老校区在各年级的高危学生人数。为判定校区差异是否由学生基数造成,额外制作全校校区年级人数分布图,无筛选条件展示全校学生分布,用于对照分析校区管理差异。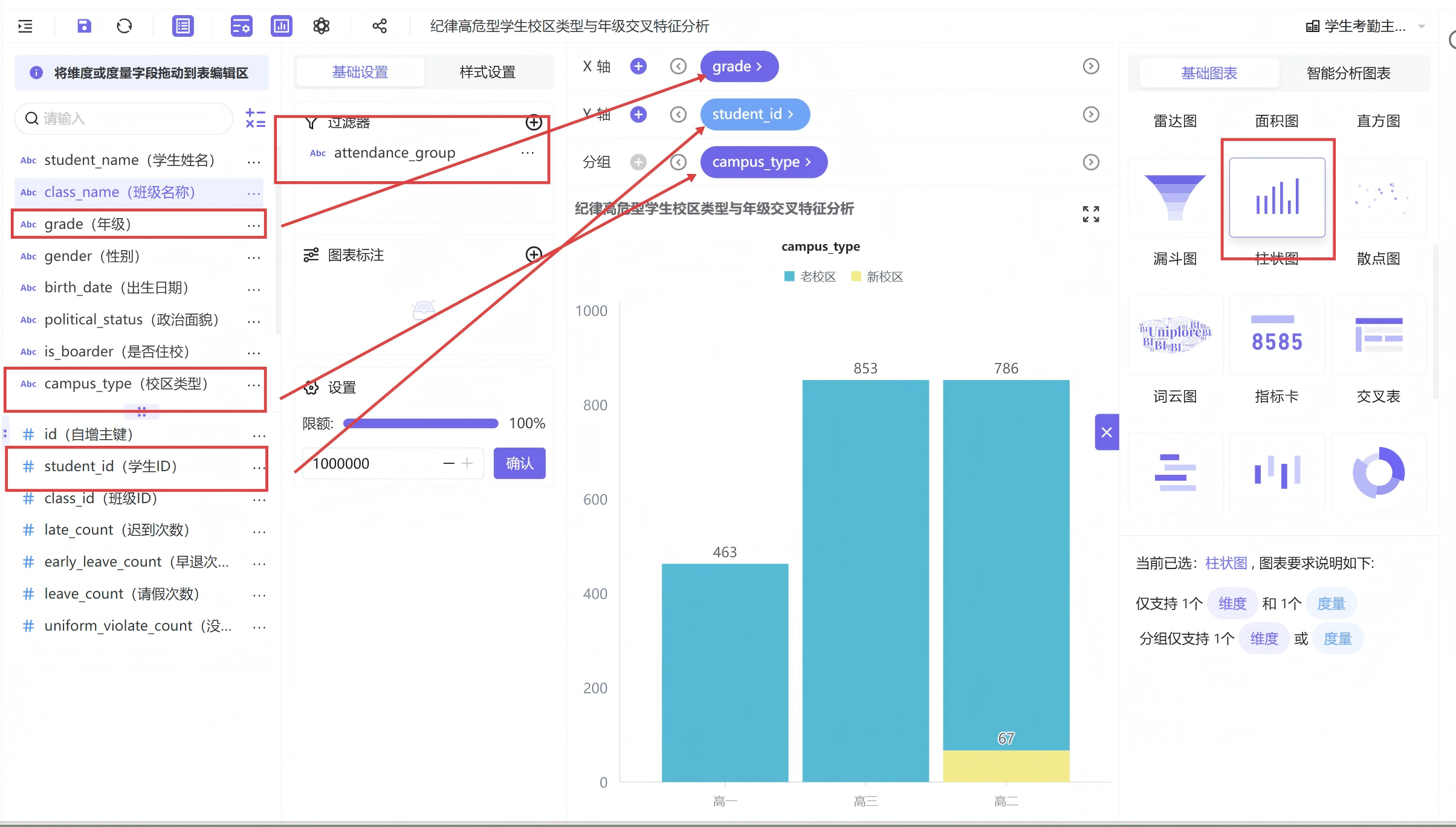
3.2.6 高危班级水平条形图
新建水平条形图,将班级名称放置于Y轴,学生人数放置于X轴,筛选纪律高危型人群,并且将数据按人数进行降序排序,高危人数最多的班级自动置顶展示,直观呈现高危学生聚集程度较高的班级,为班级针对性管控提供数据参考。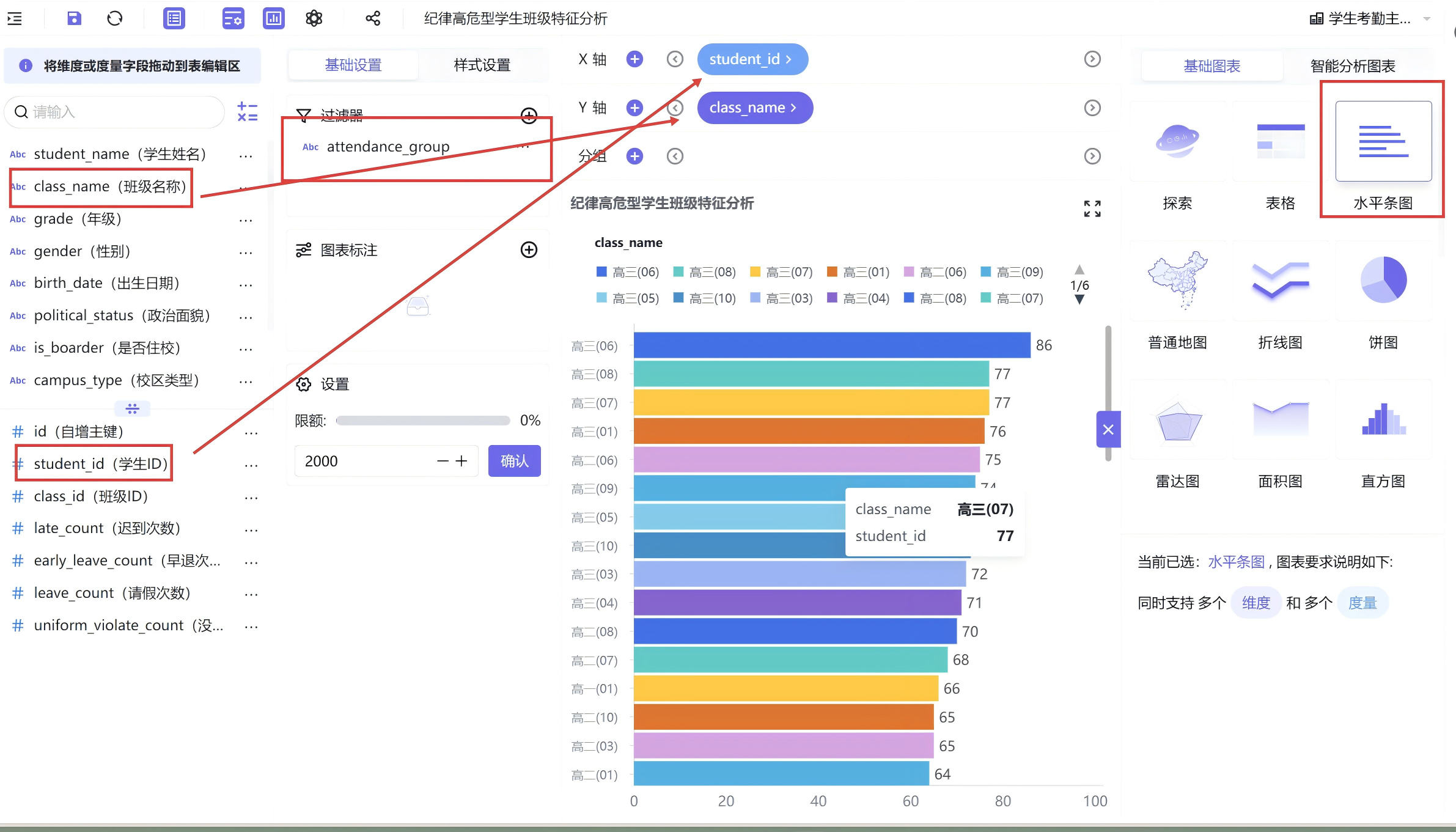
3.3 综合仪表盘搭建与发布
为整合全部分析成果,新建仪表盘并命名为纪律高危型学生用户画像分析,首先添加文本标题组件,设置加粗居中、大号字体,明确看板主题。随后将前期制作完成的四张指标卡、两张饼图、两张柱状图、一张条形图全部拖拽至画布,手动调整图表大小、间距与排版顺序,保证布局规整美观。同时新增文本注释组件,将各维度数据分析结论写入仪表盘,实现图表+文字一体化分析展示。全部设计完成后保存并公开发布仪表盘,系统自动生成公开分享链接,支持外部人员免登录查看。
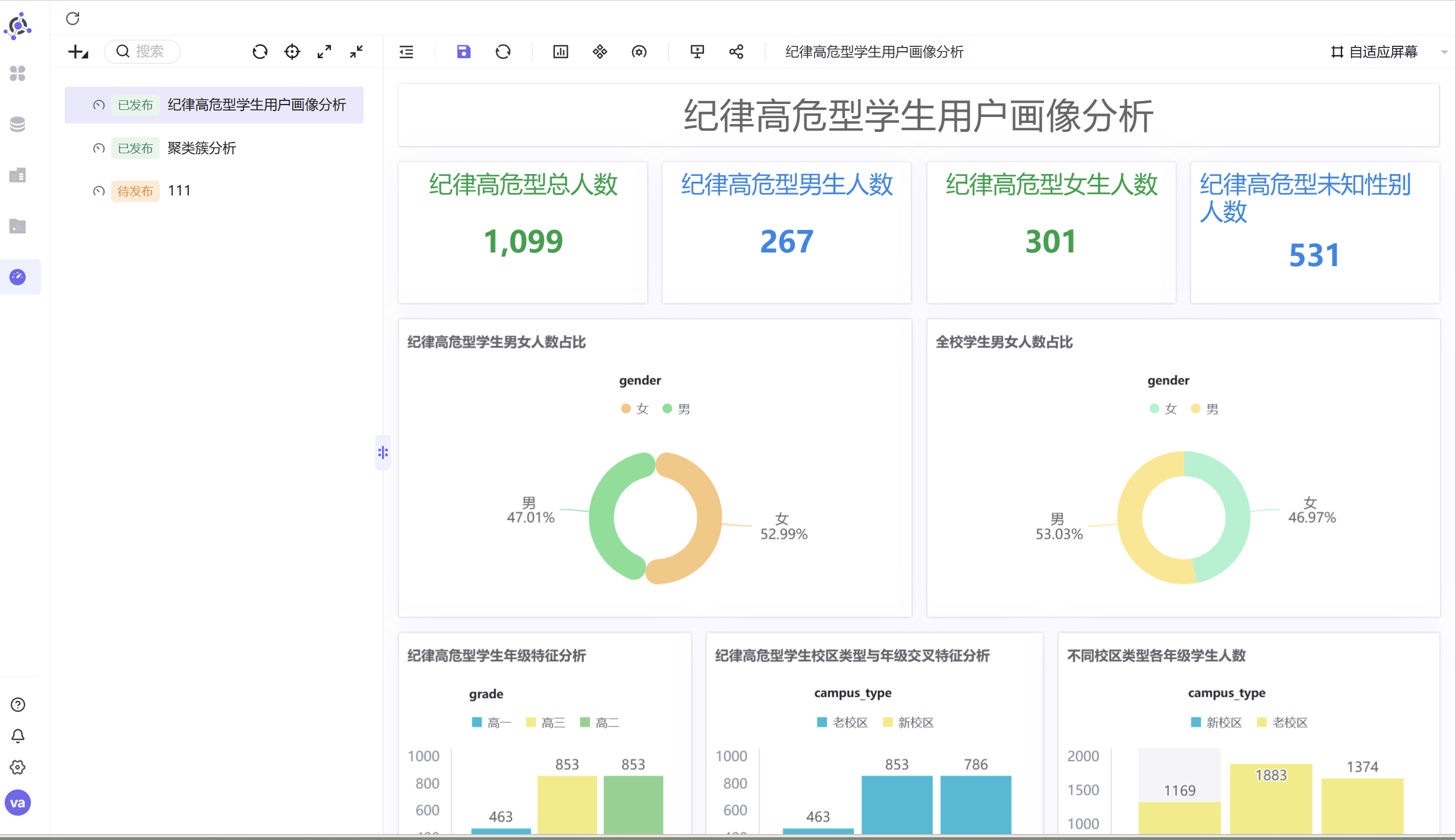
3.4 高危学生画像总结
综合多维度可视化分析结果,可完整归纳纪律高危型学生画像特征:该群体普遍存在多重违纪叠加现象,不良行为扩散影响较大;性别层面男生违纪概率明显高于女生,规则意识相对薄弱;年级层面高危学生人数随年级升高持续递增,高年级学生自律性下降;校区层面老校区为违纪高发区域,校区环境、通勤条件、管理模式存在优化空间;班级层面高危学生高度集中在少数管理薄弱、班风松散的班级。学校后续可针对性管控高年级、老校区及问题班级,重点加强男生纪律思想教育,实现精细化校园管理。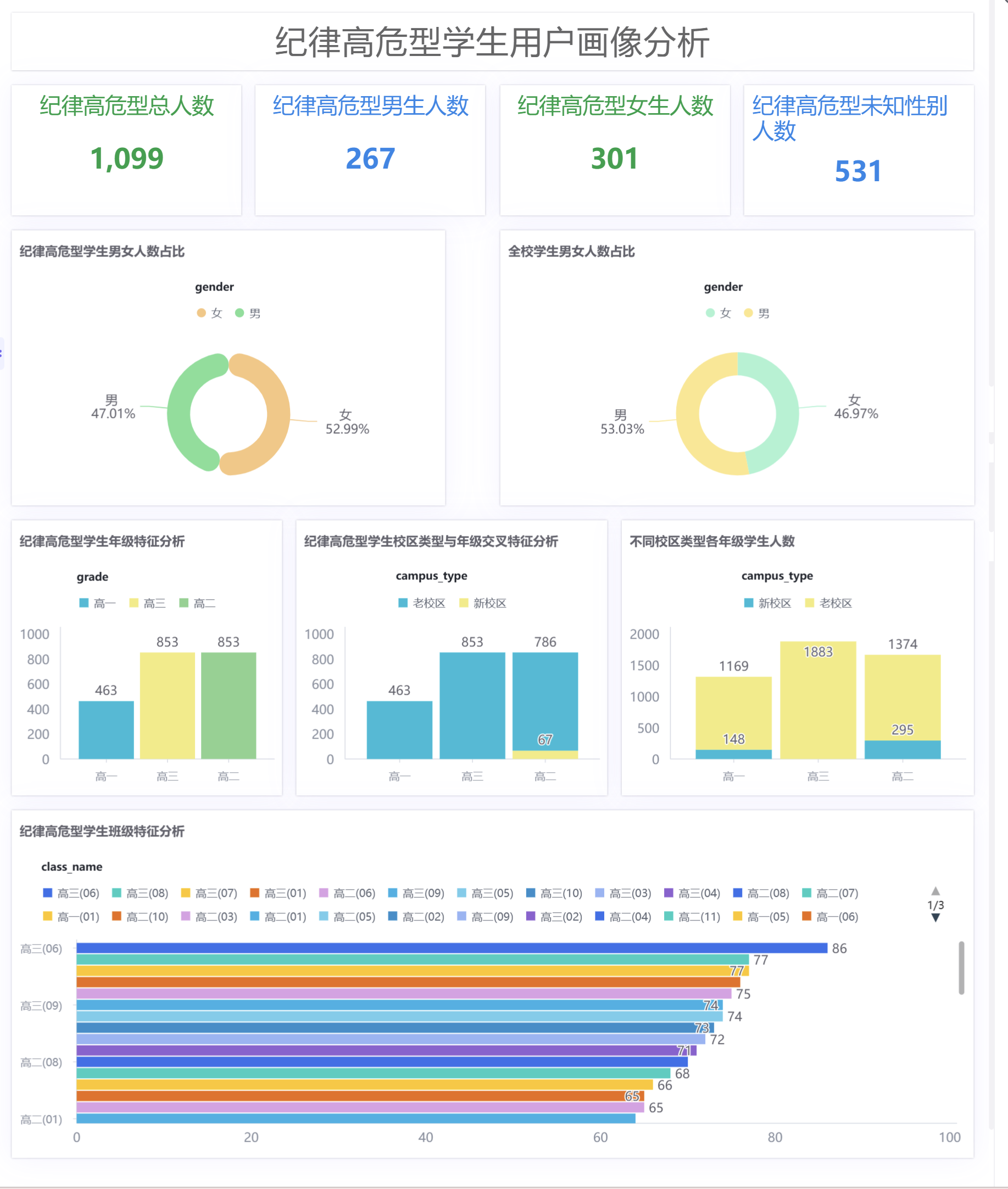
四、实验结果
本次实验第一阶段顺利完成K-Means聚类建模,依托四类考勤行为指标将全体学生划分为自律模范型、轻微波动型、纪律高危型三类群体,通过ETL工具成功将聚类标签回写至原始数据表,完善学生考勤标签体系;第二阶段基于标注数据完成多维度可视化分析,采用“一张详做、多张复刻”的方式制作十余张分析图表,从性别、年级、校区、班级四个角度剖析高危学生分布规律,搭建完成综合性可视化仪表盘并生成永久公开访问链接。本次实验聚类划分边界清晰、数据无异常偏差,可视化图表层次分明,数据分析结论贴合校园管理实际业务需求,实验成果完整有效。
五、问题与解决
在可视化制作过程中,平台默认数据展示限额较低,导致图表只能展示部分样本数据,无法呈现全量学生信息,通过将数据展示限额手动调整为100%,成功展示全部实验样本;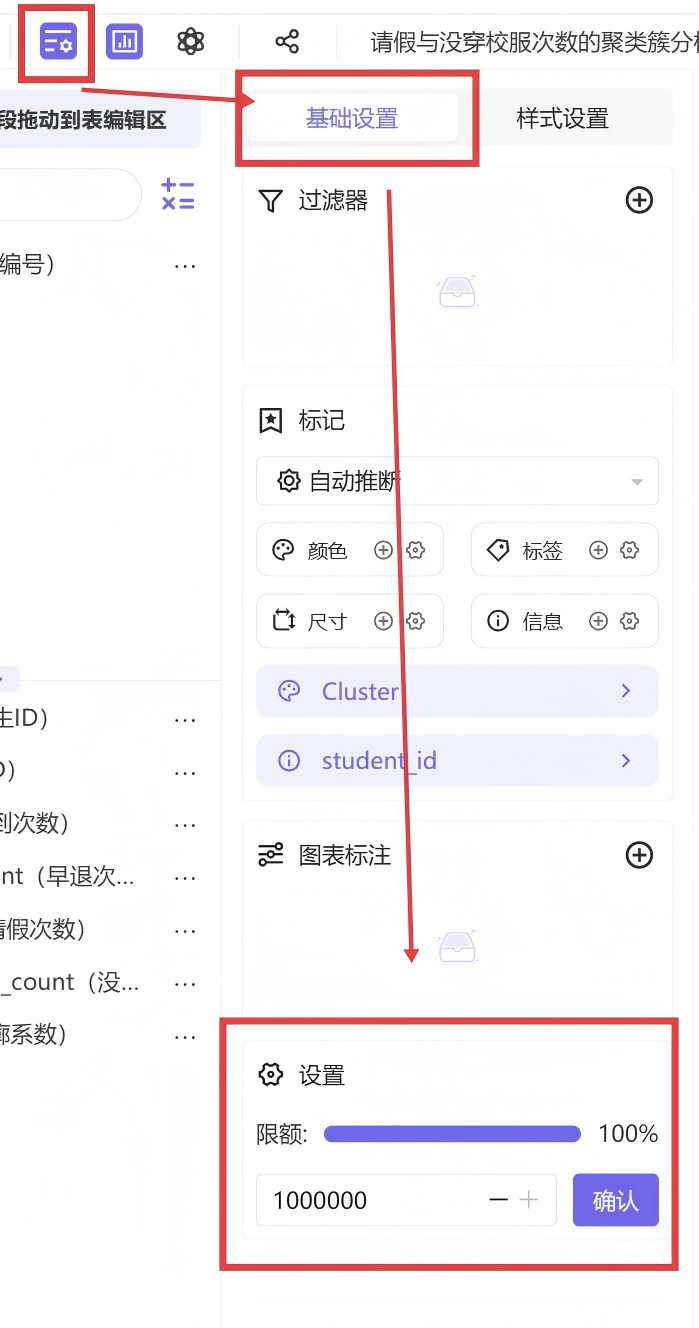
在ETL数据更新环节,因新旧数据表字段格式不统一,出现数据写入失败问题,重新刷新加载数据库元数据,统一字段数据格式后,顺利完成批量更新;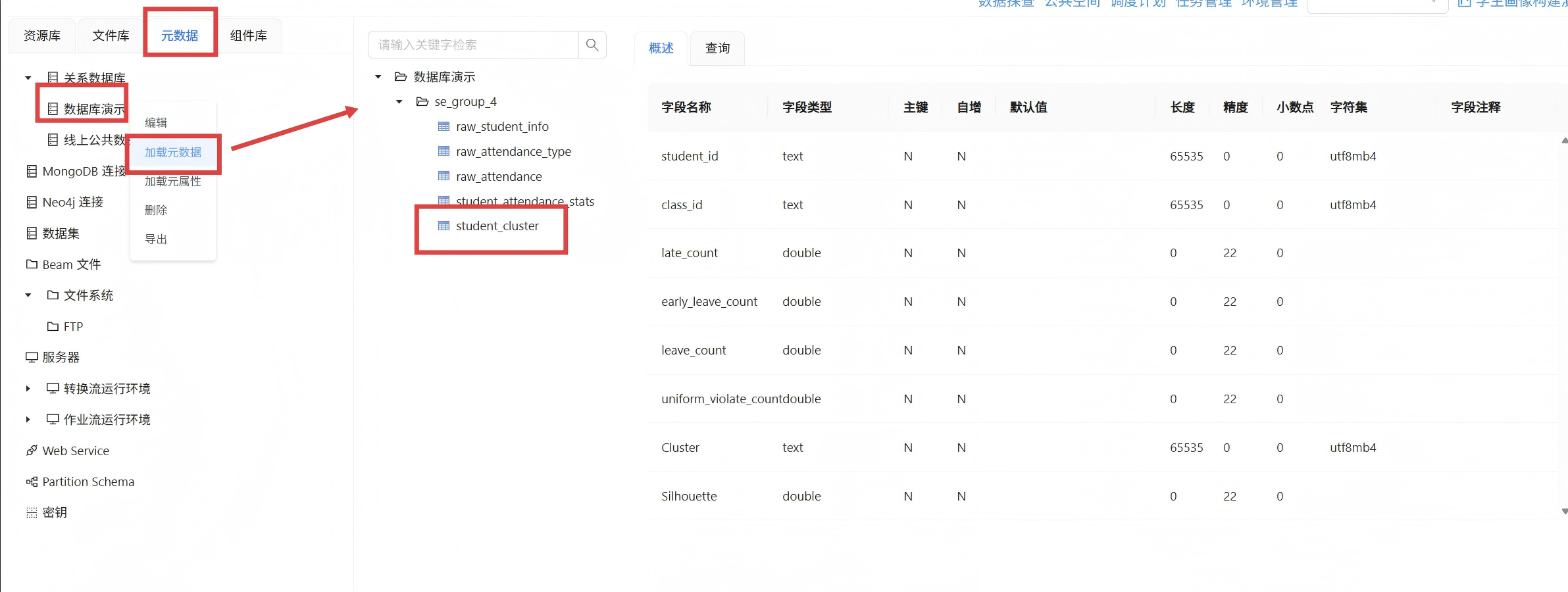
初始生成的聚类图表配色相近,人群区分辨识度较低,手动切换高对比配色模板,优化色彩搭配,提升图表可视化效果。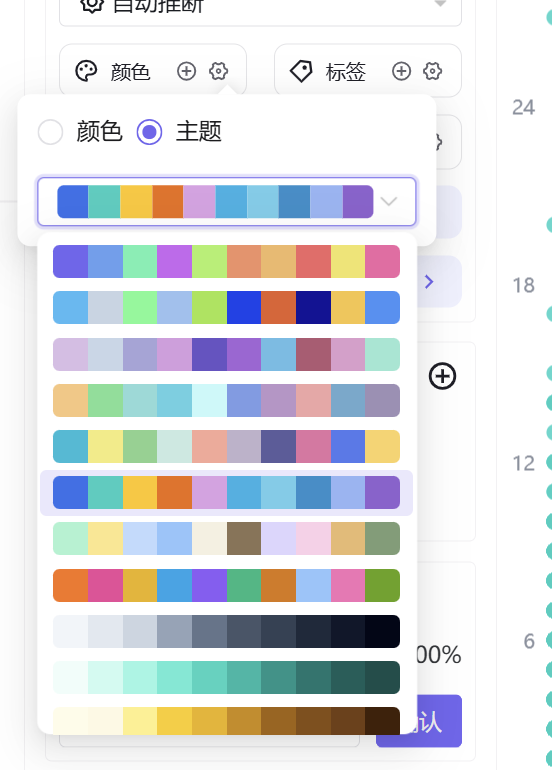
六、实验总结
本次实验连贯完成考勤标签构建与高危学生画像可视化分析两大模块,熟练掌握助睿平台AI建模、ETL数据处理、BI图表制作、仪表盘搭建等核心实操功能,深入理解K-Means无监督聚类算法在人群分群项目中的应用逻辑。实验过程中,采用示例详解+同类复刻的制作方式,简化重复操作、步骤清晰分明,完整复刻企业数据分析全流程,学会结合校园业务场景解读数据、归纳规律、提出管理建议,不仅强化了零代码平台操作能力,还培养了自身的数据思维与业务分析能力,为后续大数据可视化、用户画像挖掘类课程学习打下坚实基础
如果教程有帮助,请点赞收藏转发!
感谢 ^ - ^

一站式 AI 云服务平台
更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)