
基于K-Means聚类的学生考勤行为分群及高危群体画像分析
本文基于助睿数智(Uniplore)平台,完成了从学生考勤行为 K-Means 聚类建模到高危群体专项画像分析的全流程实践。实验以学生迟到、早退、请假、校服违规次数为核心指标,通过零代码 K-Means 聚类算法将学生划分为自律模范型、轻微波动型、纪律高危型三类群体;借助助睿 BI 平台制作多维度可视化图表,为聚类结果赋予业务含义;最终通过 ETL 流程将分类标签回写至原始数据表,并对纪律高危型学
目录
实验一:基于K-Means聚类的学生考勤行为分群实验
1 实验说明
1.1 实验目的
基于已完成的学生考勤主题标签表(student_attendance_stats),使用 K-Means 聚类算法对学生考勤行为进行自动分群。通过迟到、早退、请假、校服违规次数等核心指标,识别不同类型的考勤群体,生成可解释的考勤画像,为校园学生管理、行为分析提供精准数据支撑。
1.2 实验环境
本次实验依托助睿数智(Uniplore)在线实验平台完成,平台访问地址:https://lab.guilan.cn/,产品官网:https://www.uniplore.com/。
助睿数智(Uniplore)是AI驱动的一站式数据科学平台,覆盖从数据接入、ETL处理、机器学习建模到可视化展示的全链路零代码功能,无需深厚编程基础即可完成数据分析与建模工作。本次实验核心环境配置如下:
-
功能平台:数据集成平台(助睿 ETL)、人工智能平台(助睿 AI)、助睿BI 数据可视化探索平台
-
数据库:MySQL
-
前置数据:学生考勤主题标签表(student_attendance_stats)
2 实验数据
2.1 数据构成
本次实验使用标准化处理后的学生考勤主题标签表,数据集整合了学生基础信息与全量考勤次数统计结果,无冗余脏数据、字段规范,能够为K-Means聚类建模提供干净、可靠的标准化特征数据。
2.2 字段说明
数据表包含学生基础属性、考勤行为统计、数据入库时间三大类字段,具体详情如下:
|
名称 |
说明 |
类型 |
|---|---|---|
|
id |
自增主键 |
连续(整数) |
|
student_id |
学生 ID |
连续(整数) |
|
student_name |
学生姓名 |
文本 |
|
class_id |
班级 ID |
连续(整数) |
|
class_name |
班级名称 |
文本 |
|
grade |
年级 |
文本 / 分类 |
|
gender |
性别 |
二分类 |
|
birth_date |
出生日期 |
文本 / 日期 |
|
political_status |
政治面貌 |
文本 / 分类 |
|
is_boarder |
是否住校 |
二分类 |
|
campus_type |
校区类型 |
文本 / 分类 |
|
late_count |
迟到次数 |
连续(整数) |
|
early_leave_count |
早退次数 |
连续(整数) |
|
leave_count |
请假次数 |
连续(整数) |
|
uniform_violate_count |
没穿校服次数 |
连续(整数) |
|
create_time |
统计入库时间 |
日期时间 |
2.3 建模思路
结合数据特征与校园考勤业务场景,本次K-Means聚类建模思路清晰、针对性强,全程贴合业务需求,保证模型结果稳定、可解释,具体思路如下:
1. 特征维度精简有效:本次数据维度适中,无需复杂降维操作。基于考勤业务逻辑,筛选迟到、早退、请假、校服违规四类核心行为指标用于建模,各维度独立对应一类考勤特征,变量间相关性低、无冗余干扰,可有效避免模型过拟合、结果难以解释的问题。
2. 数据类型高度适配算法:建模所用的考勤次数指标均为非负整数连续变量,完全契合K-Means聚类算法的数据输入要求,无需进行哑变量编码、二值化等特殊数据转换,大幅简化预处理流程,同时保障聚类结果的稳定性与准确性。
3. 区分建模与画像变量:学生性别、年级、住校状态、校区类型等基础离散属性不参与聚类建模,仅用于后续群体画像解读、特征归因,确保聚类结果纯粹聚焦学生考勤行为本身,提升分群的专业性与贴合度。
3 实验步骤
本次建模依托平台AI Studio人工智能模块完成,该模块为零代码拖拽式建模工具,内置100+数据挖掘算法组件,无需编程即可实现数据加载、预处理、模型训练、结果输出全流程操作,适配零基础数据分析场景。
3.1 AI Studio 聚类建模
3.1.1 新建工作流
搭建独立工作流,为数据加载、聚类建模、结果保存提供专属运行编辑空间,步骤如下:
1. 登录助睿数智实验平台,点击左侧菜单栏「人工智能」,进入AI Studio用户操作空间;
2. 点击页面「+」按钮,选择「新建工作流」,创建空白建模工作流;
3. AI Studio操作页面分为三大核心区域:左侧功能菜单栏、中间算法控件列表、右侧画布编辑区,后续所有建模操作均在此完成。
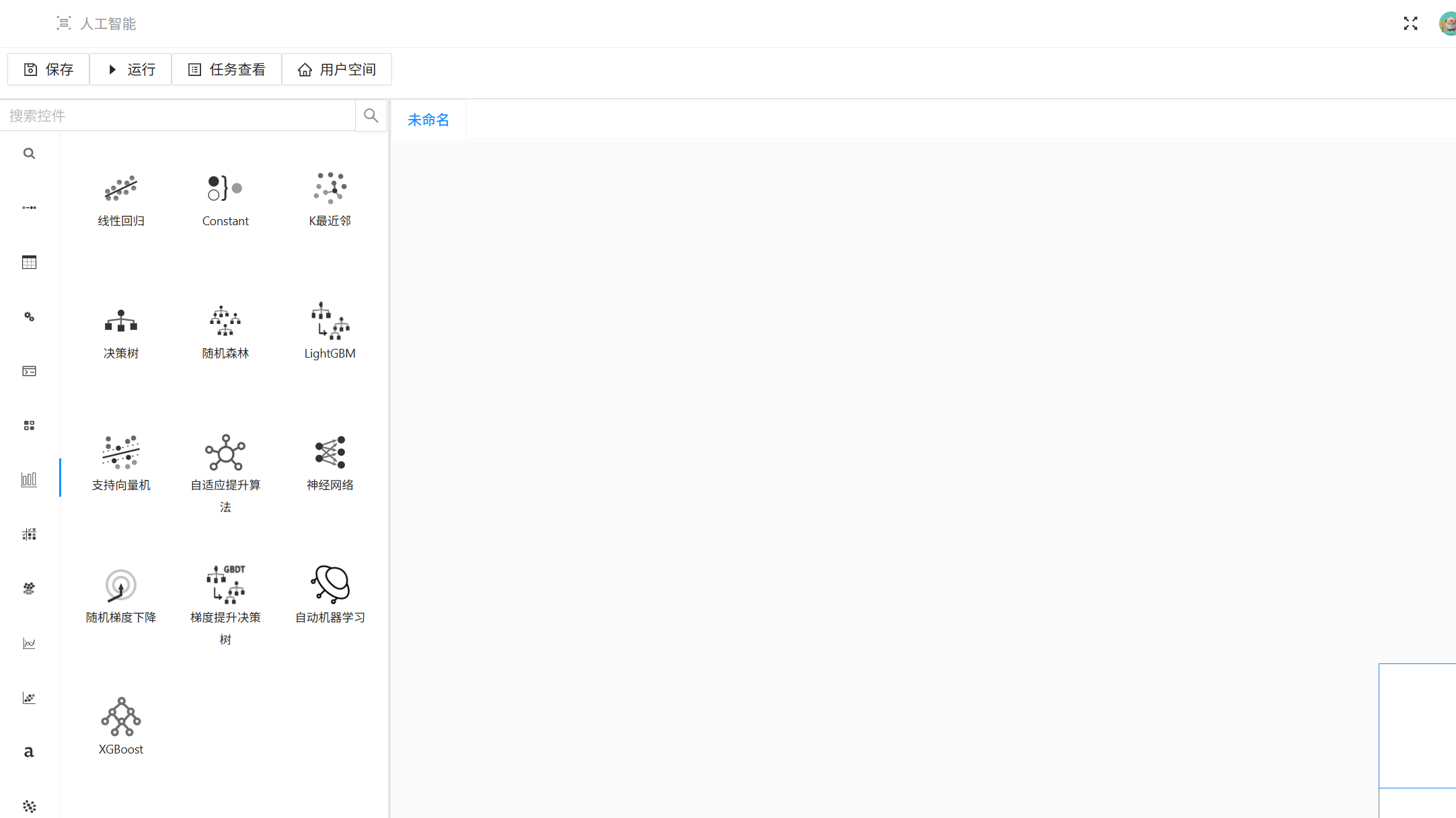
3.1.2 数据导入
加载实验专属数据表,筛选建模所需核心字段,过滤冗余无效数据:
1. 在控件列表搜索「数据库加载」控件,拖拽至右侧空白画布;
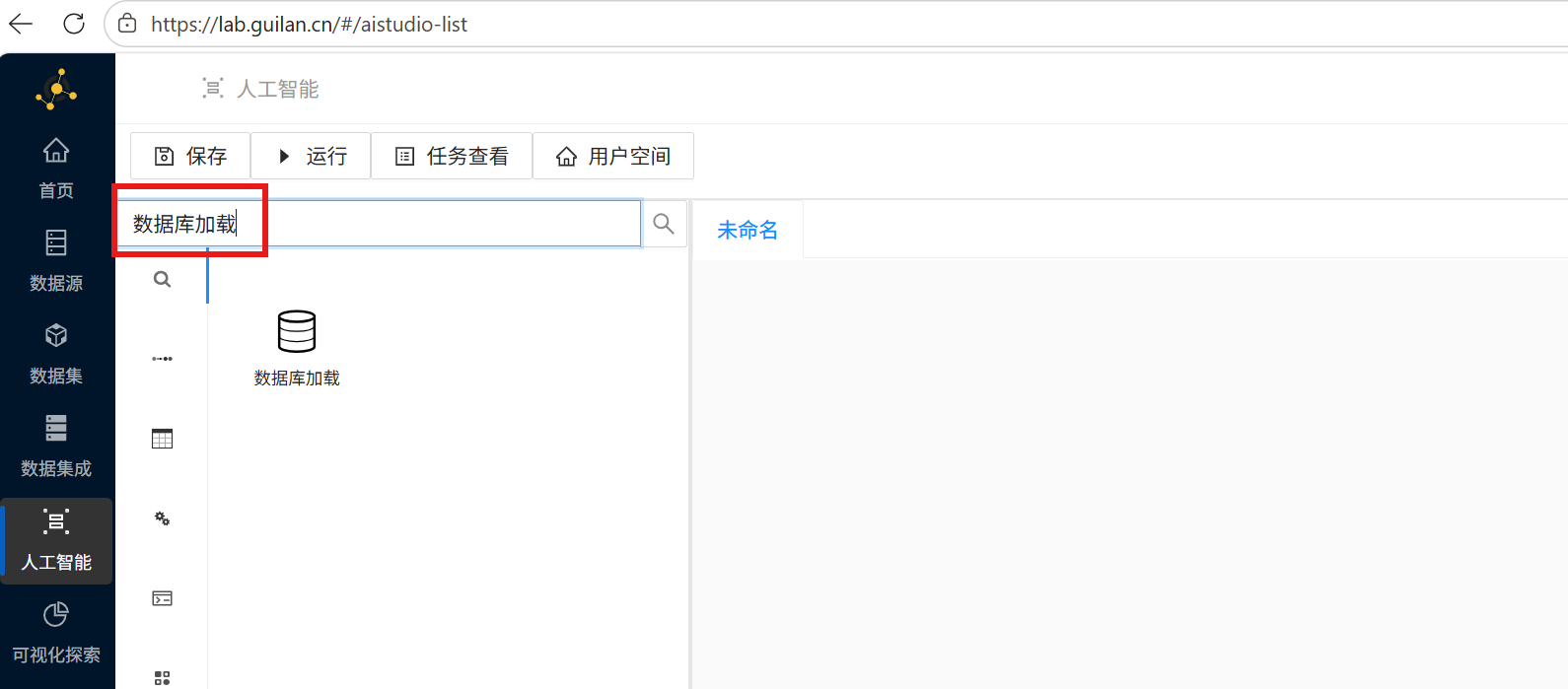
2. 双击控件,在右侧参数配置窗口填写团队私有数据库信息,点击「连接」打通数据库链路;
3. 在数据表下拉选项中,选中实验前置数据「student_attendance_stats」,自动加载表结构与字段信息;
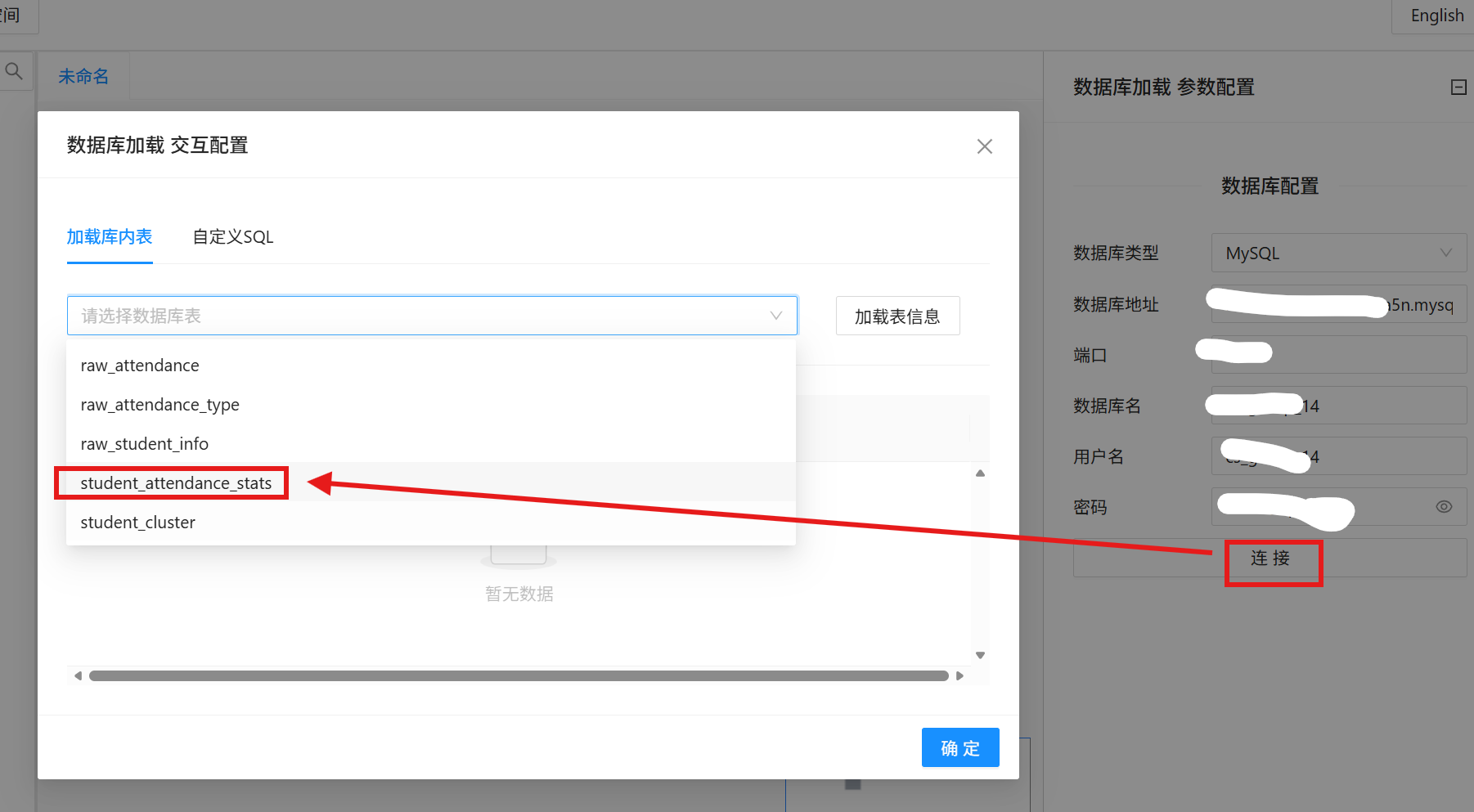
4. 按需筛选字段,仅保留student_id、class_id、late_count、early_leave_count、leave_count、uniform_violate_count,其余字段统一设置为skip(跳过),字段属性配置标准如下:
|
属性名称 |
属性类型 |
属性名称 |
属性类型 |
|---|---|---|---|
|
id |
skip |
political_status |
skip |
|
student_id |
categorical |
is_boarder |
skip |
|
student_name |
skip |
campus_type |
skip |
|
class_id |
categorical |
late_count |
numeric |
|
class_name |
skip |
early_leave_count |
numeric |
|
grade |
skip |
leave_count |
numeric |
|
gender |
skip |
uniform_violate_count |
numeric |
|
birth_date |
skip |
create_time |
skip |
5. 字段配置完成后点击「确定」,右键点击「数据库加载」控件,选择「运行该控件」;
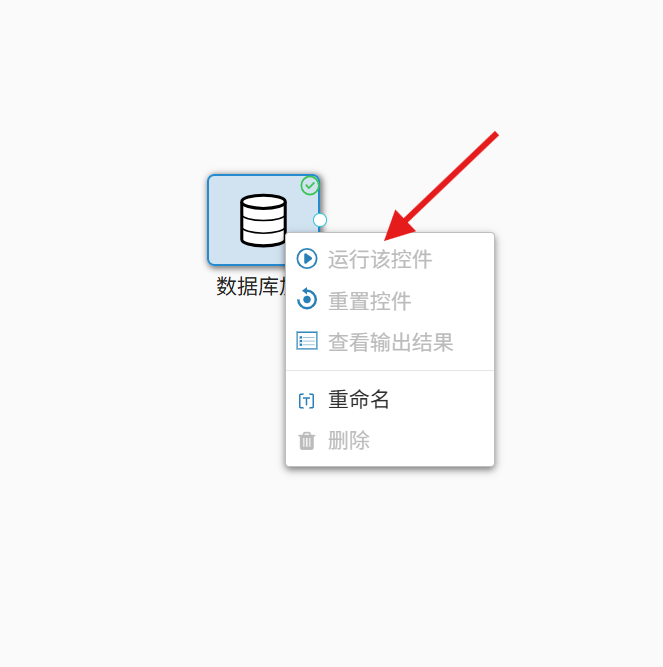
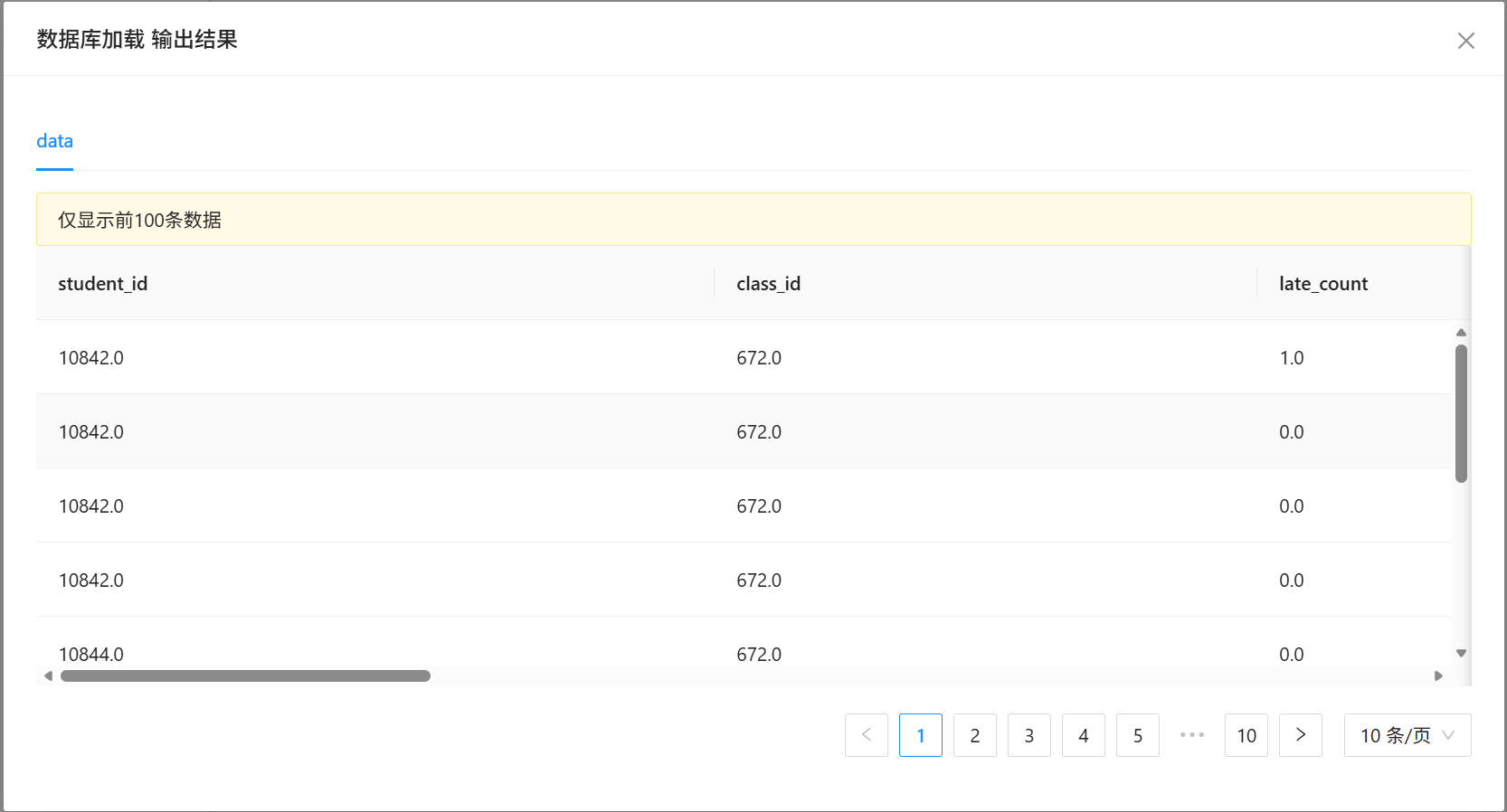
6. 控件运行成功后,右键选择「查看输出结果」,预览清洗后的数据集,确认数据无误后进入建模环节。
3.1.3 K-Means 聚类建模
基于清洗后的考勤特征数据,搭建K-Means聚类模型,完成学生考勤行为自动分群:
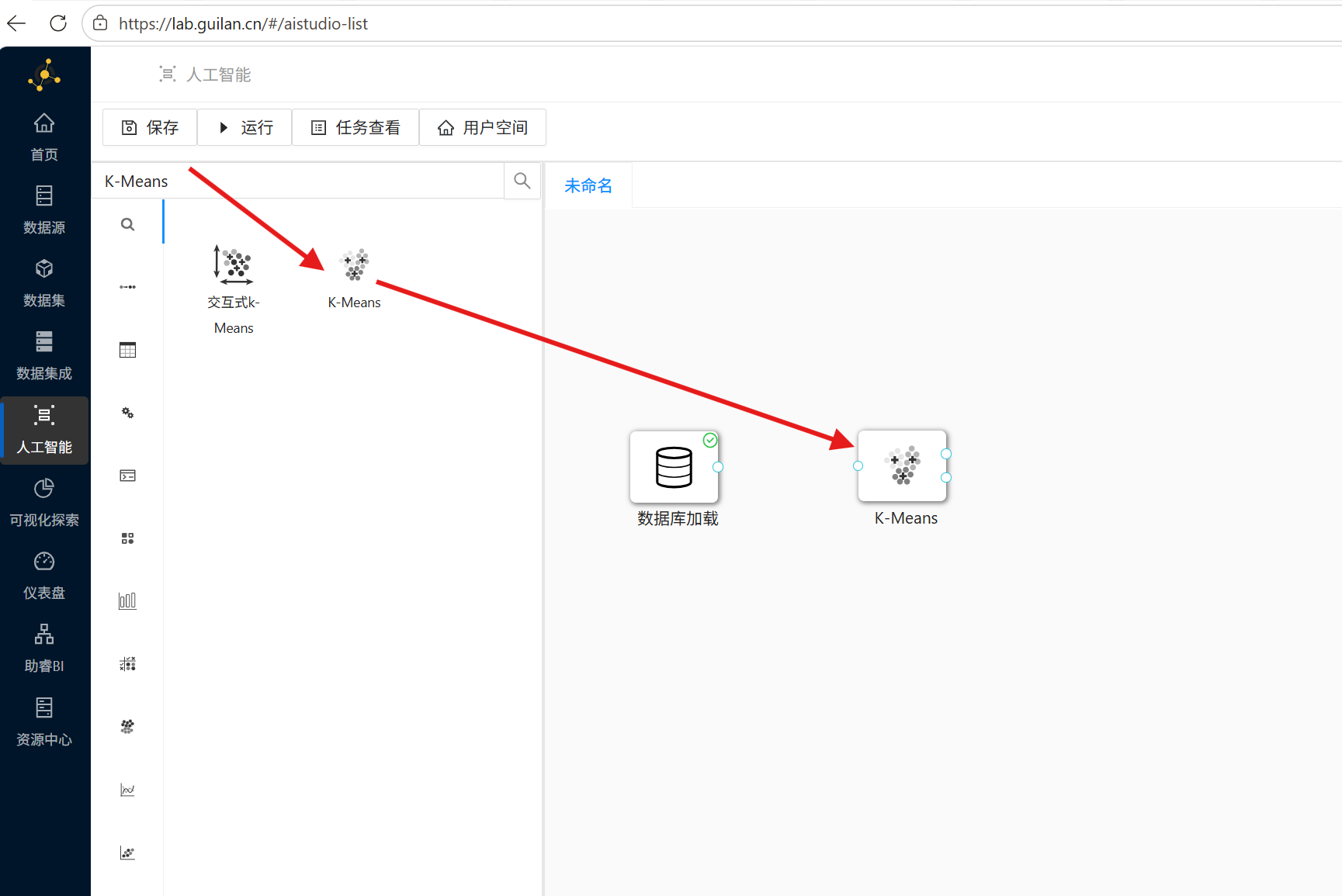
1. 在控件列表拖拽「K-Means」组件至画布,绘制「数据库加载」组件到「K-Means」组件的连线,打通数据传输链路;
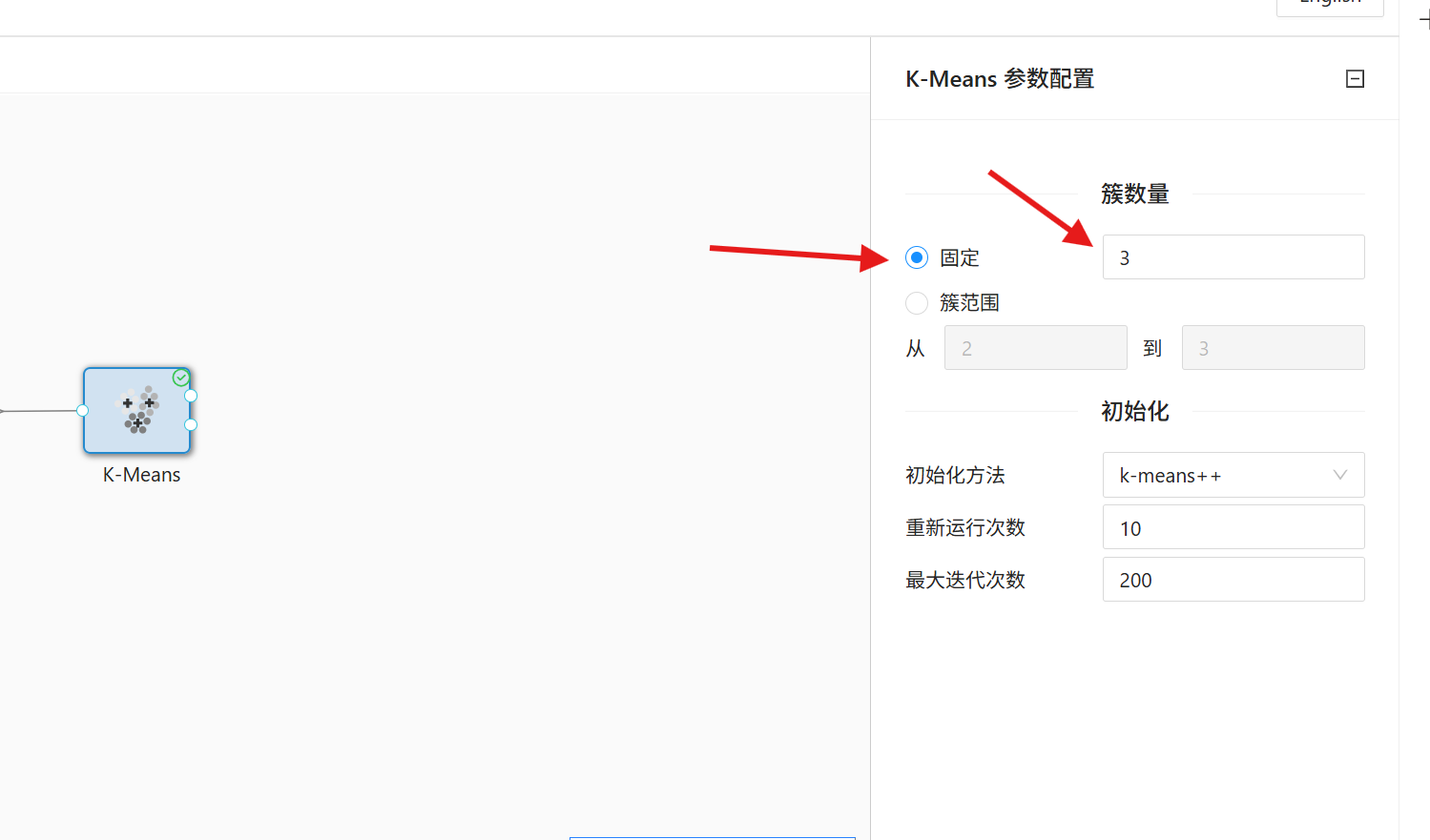
2. 双击「K-Means」组件进入参数配置界面,设置簇数量为固定3个,其余参数保持系统默认;
3. 右键点击K-Means组件,选择「运行该控件」,等待模型自动训练完成;
4. 运行结束后右键查看输出结果,系统自动为每位学生匹配聚类簇标签(C1/C2/C3),完成初步机器自动分群。
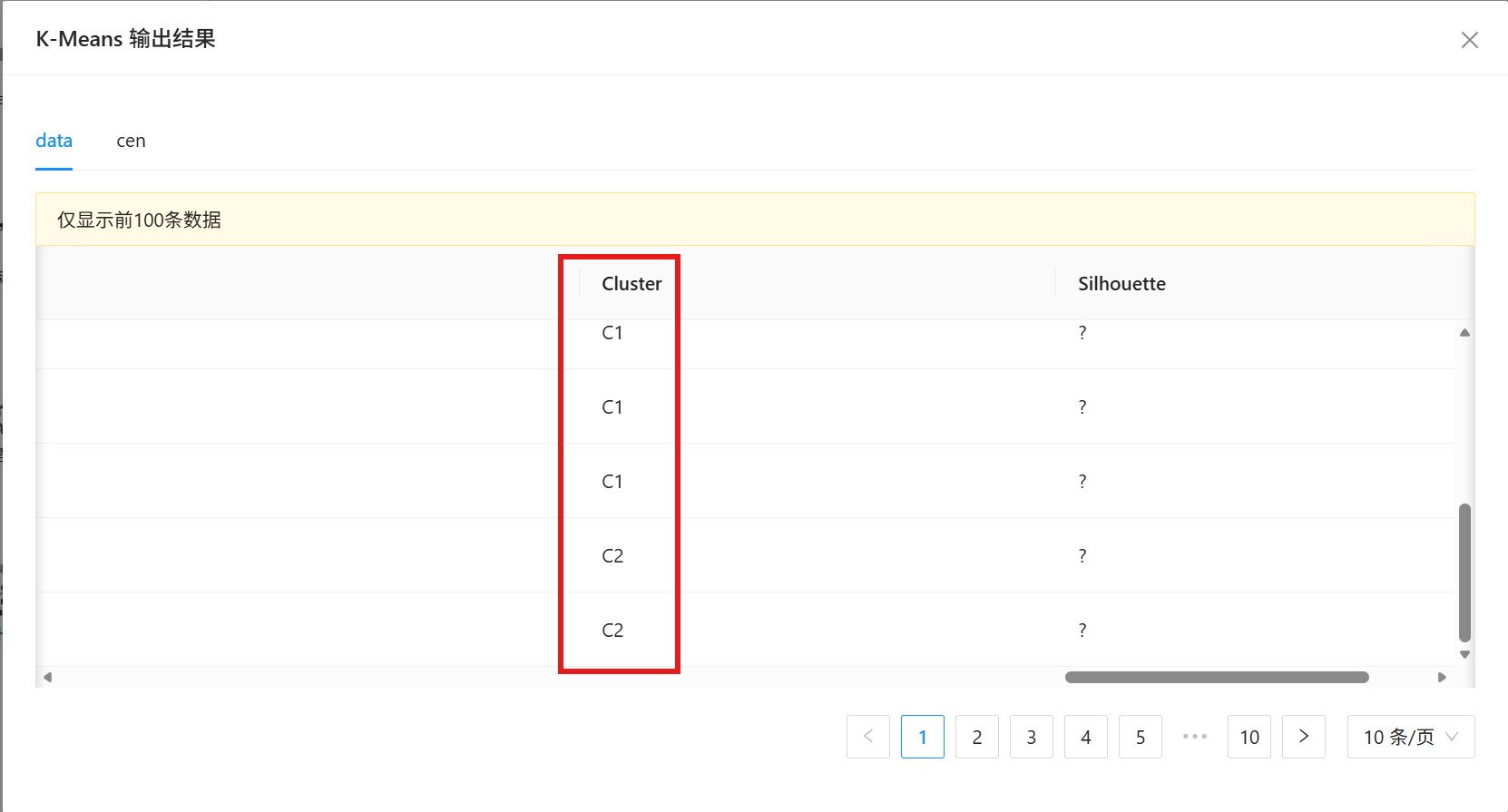
3.1.4 结果输出与保存
将聚类建模结果持久化存入数据库,生成专属结果表,为后续可视化分析、数据回写提供数据源支撑:
1. 拖拽「数据入库」组件至画布,绘制「K-Means」组件到「数据入库」组件的连线;
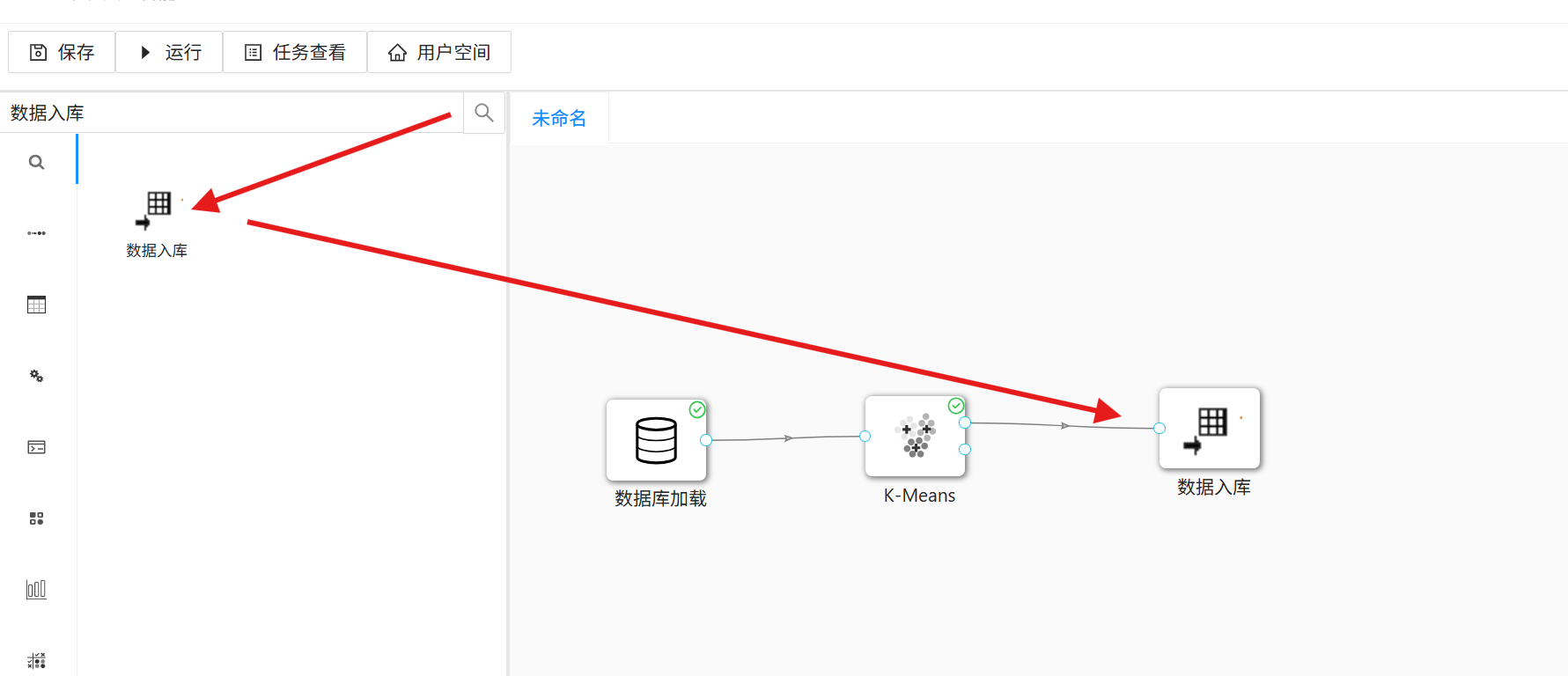
2. 双击「数据入库」组件,填写团队私有数据库配置参数,点击「获取表信息」;
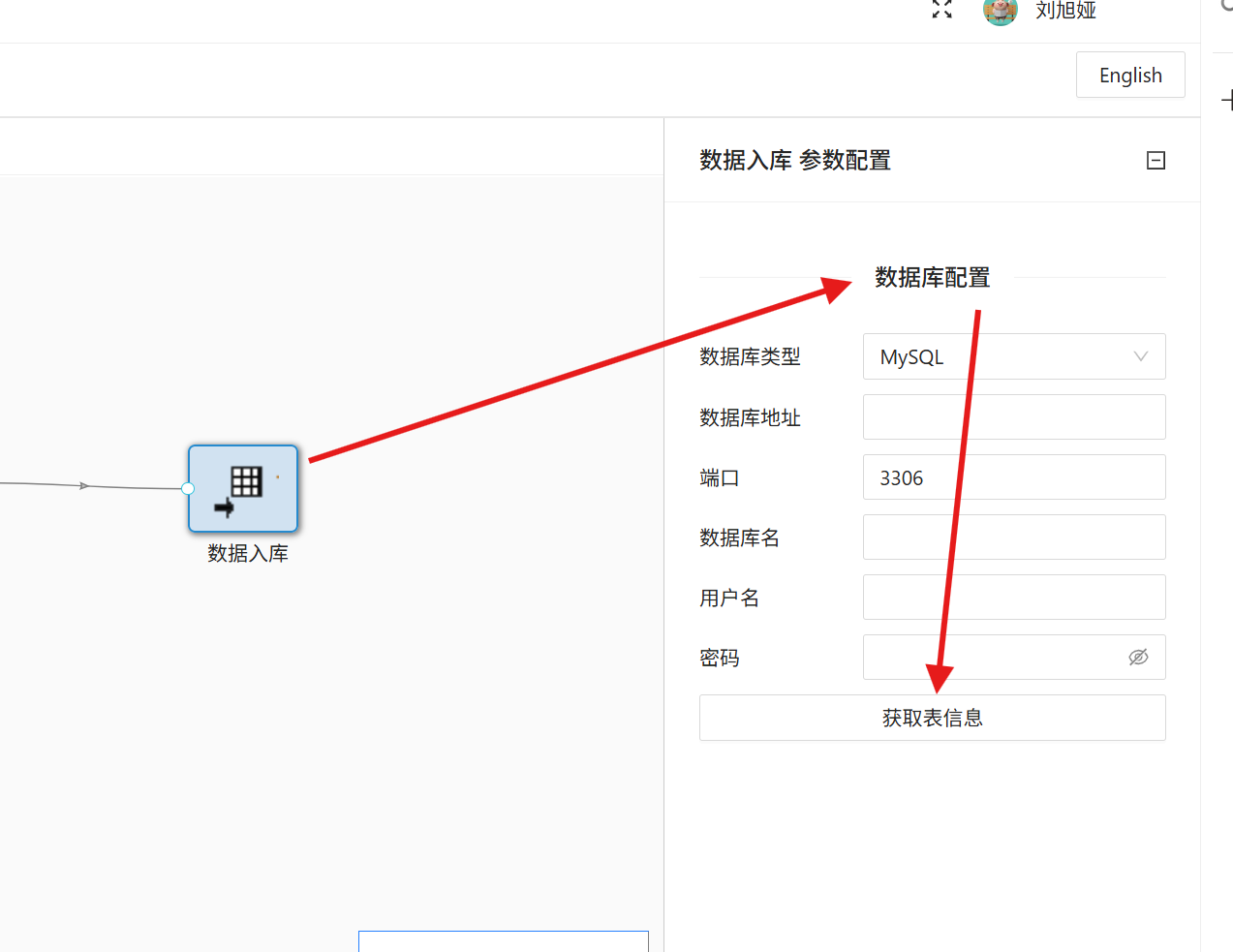
3. 在弹窗中选择「新建数据表」,将数据表命名为「student_cluster」,点击「确定」;
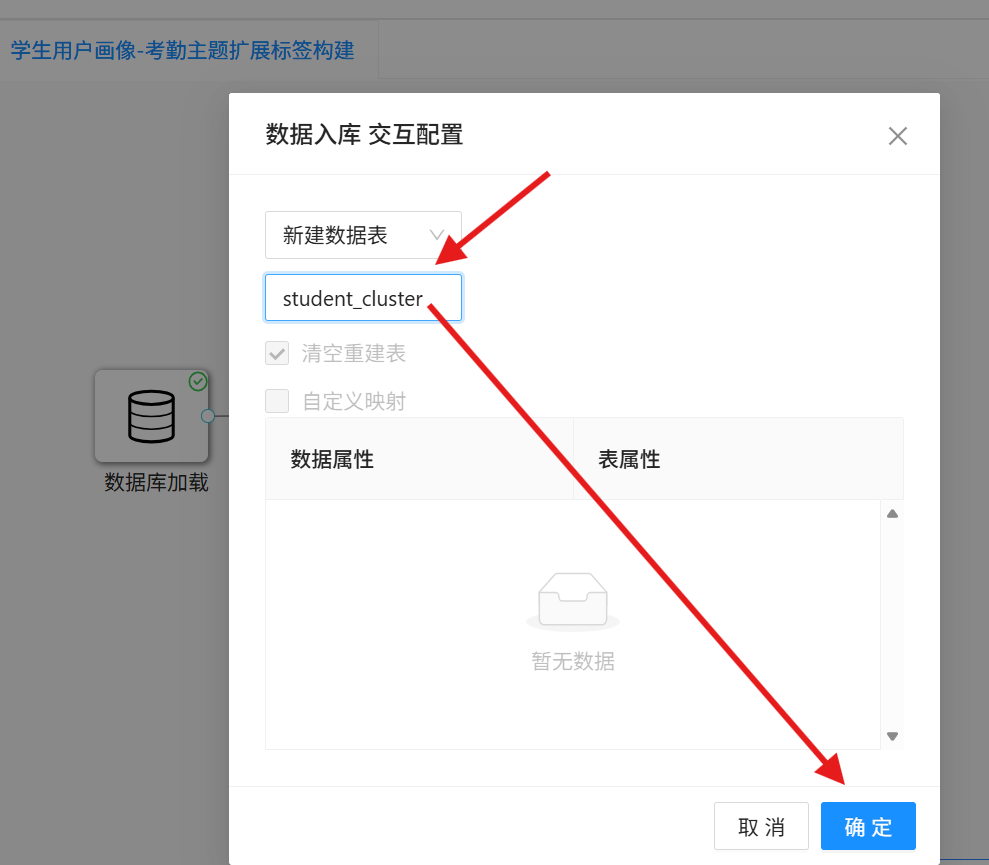
4. 点击画布顶部运行按钮,执行完整工作流,所有控件显示运行成功即代表聚类结果保存完成。
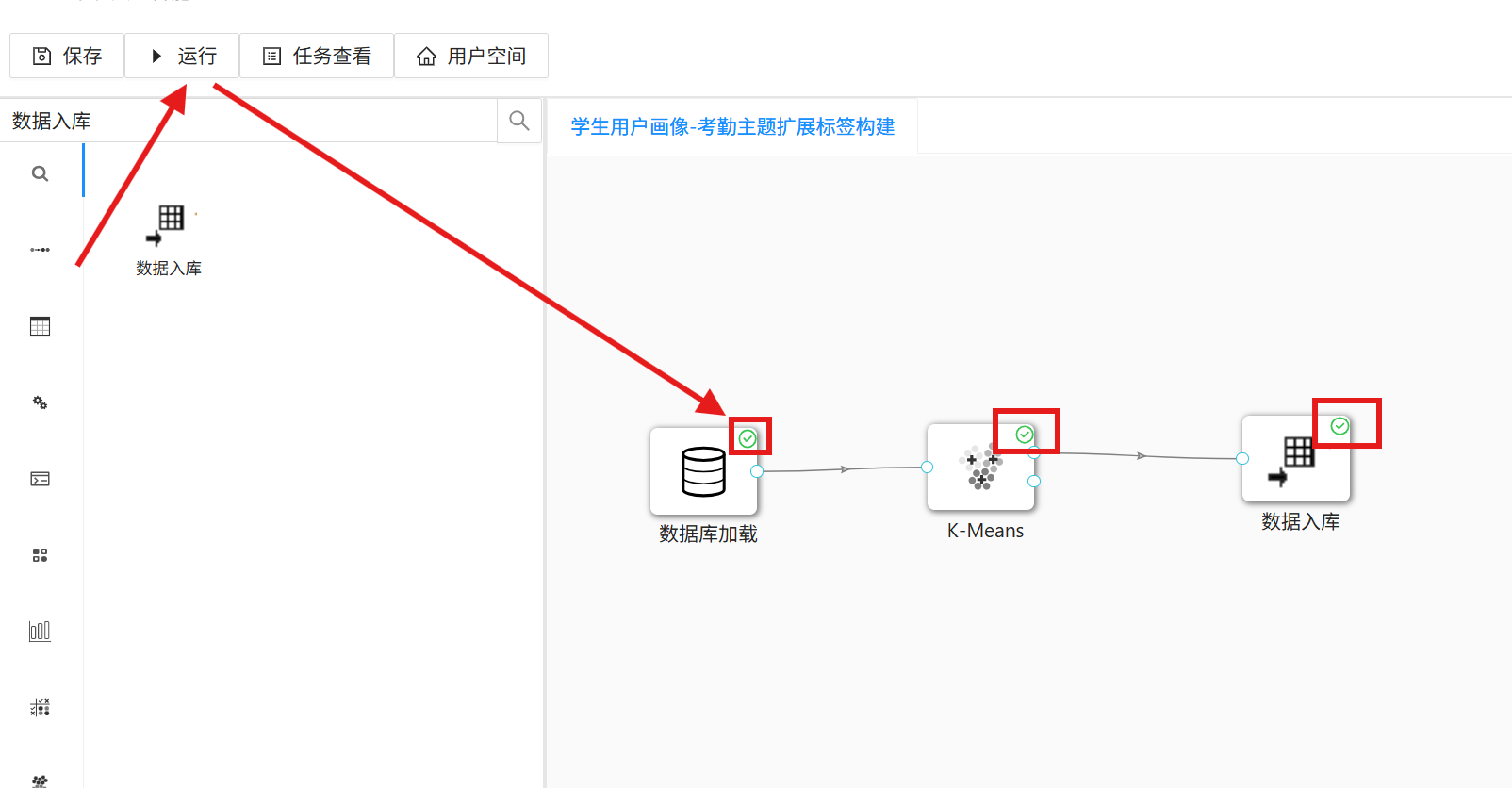
3.2 分析聚类簇编号对应的考勤群体分类
模型输出的C1、C2、C3仅为机器编号,无业务语义,需通过助睿BI可视化平台做多维度交叉分析,将机器编号转化为可落地的学生考勤群体画像。
3.2.1 连接数据源
将聚类结果数据表接入助睿BI平台,搭建可视化分析数据源:
1. 返回实验平台首页,点击左侧菜单栏「助睿BI」,进入数据可视化探索平台;
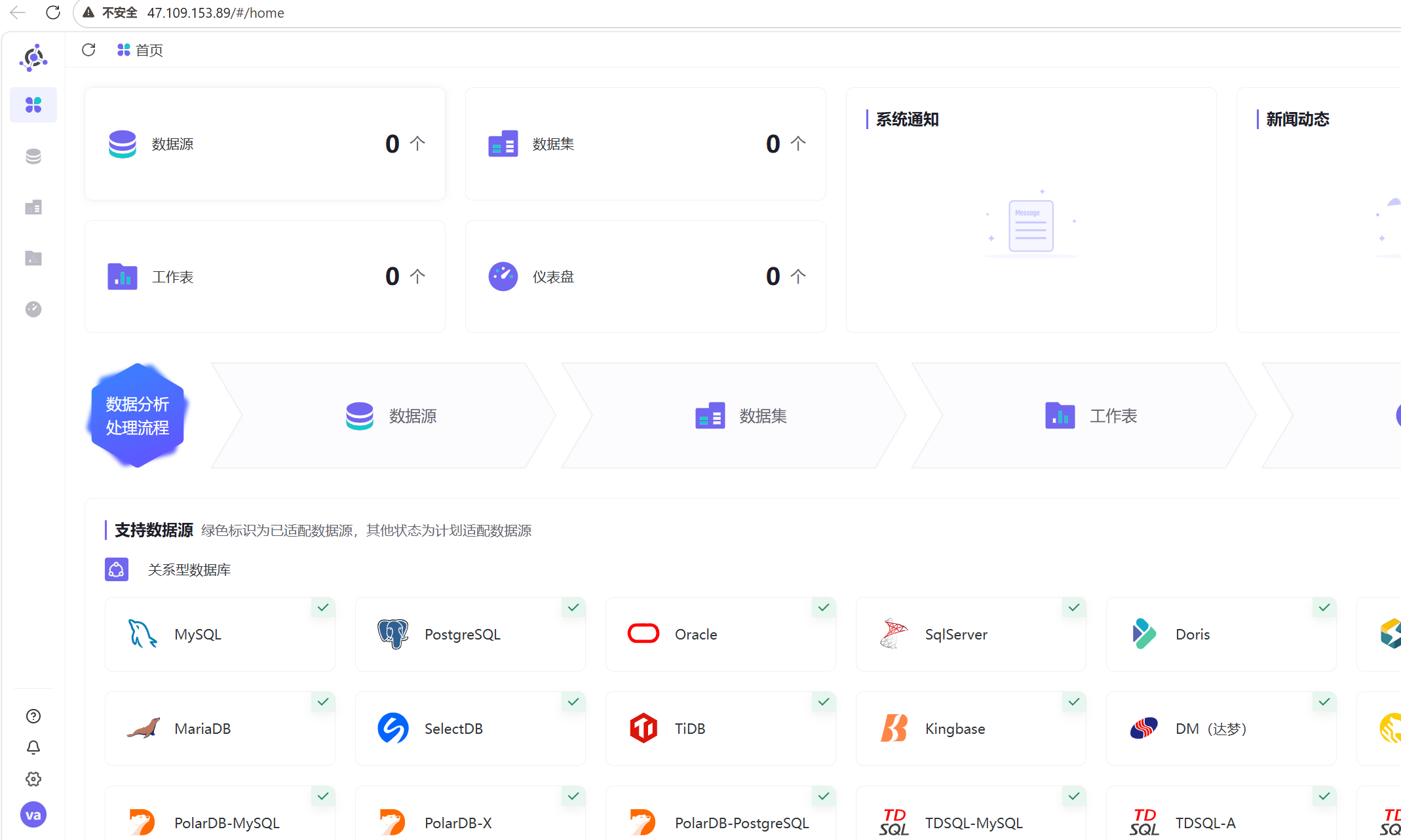
2. 点击左侧「数据源」模块,点击左上角「+」-「新建连接」,选择数据库类型为「MySQL」;
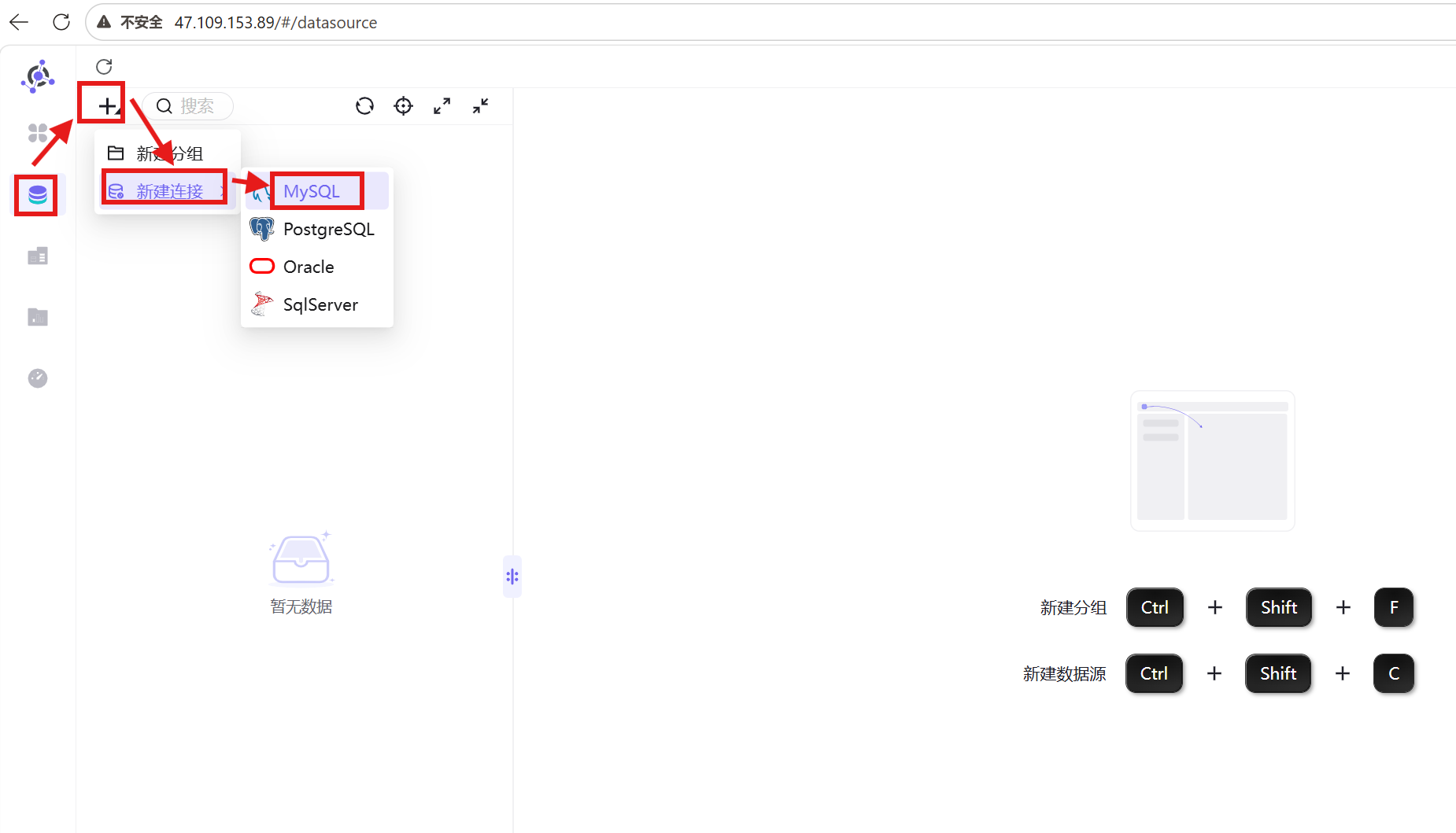
3. 填写团队Uniplore实验平台私有数据库账号信息,点击「测试连接」,显示连接成功后点击「确认」;
4. 打开新建的数据库目录,预览student_cluster数据表,确认数据源接入正常。
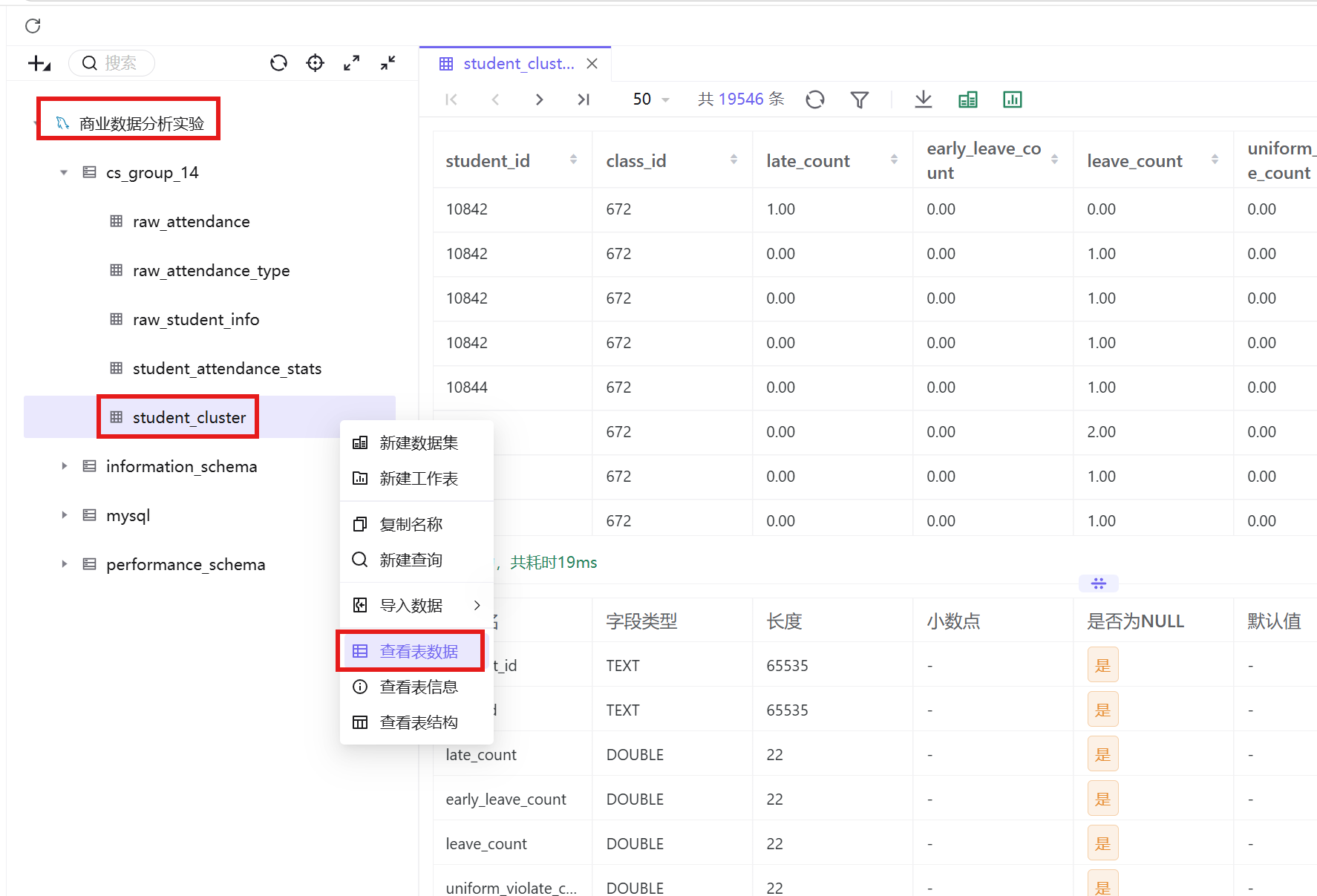
3.2.2 构建数据集
基于接入的数据源创建专属分析数据集,统一字段释义,为可视化图表制作铺垫:
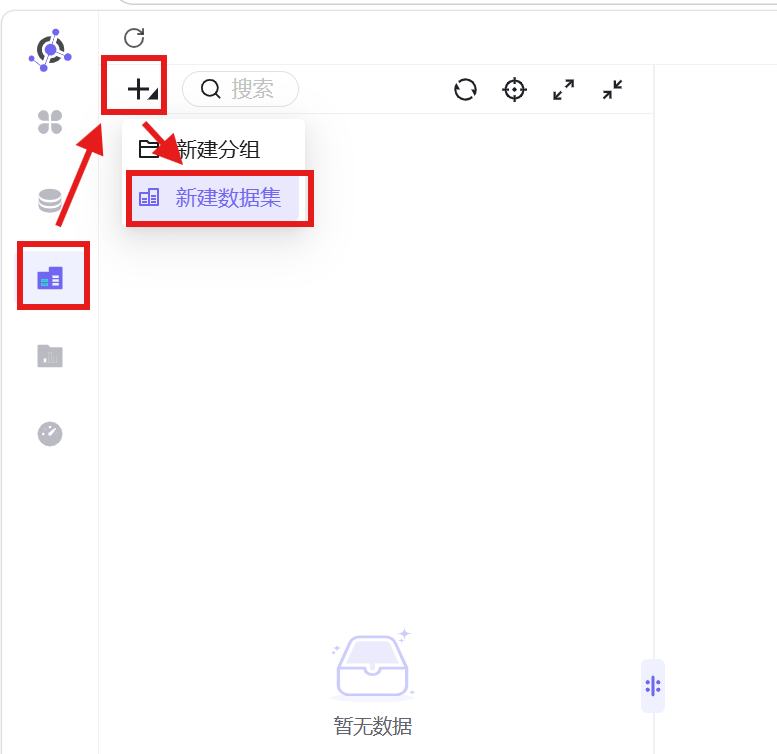
1. 点击左侧「数据集」模块,点击左上角「+」-「新建数据集」,填写名称、分组及备注信息后确认创建;
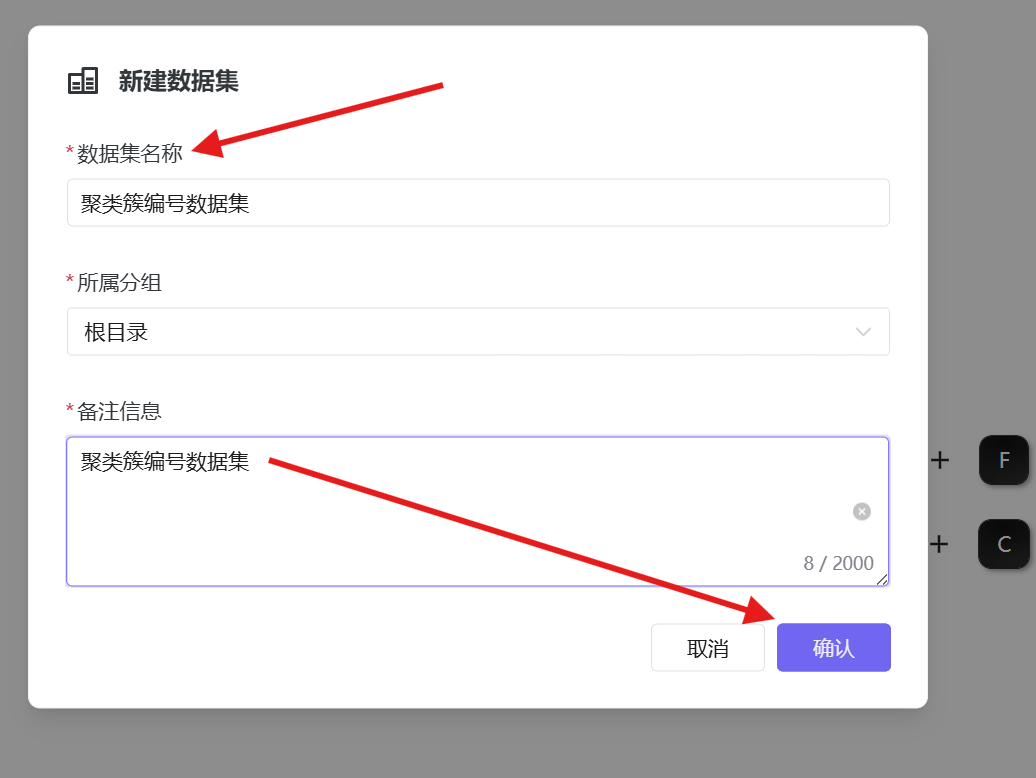
2. 关闭平台新手提醒,数据源选择「商业数据分析实验」,目录选择「自己的数据库名」;
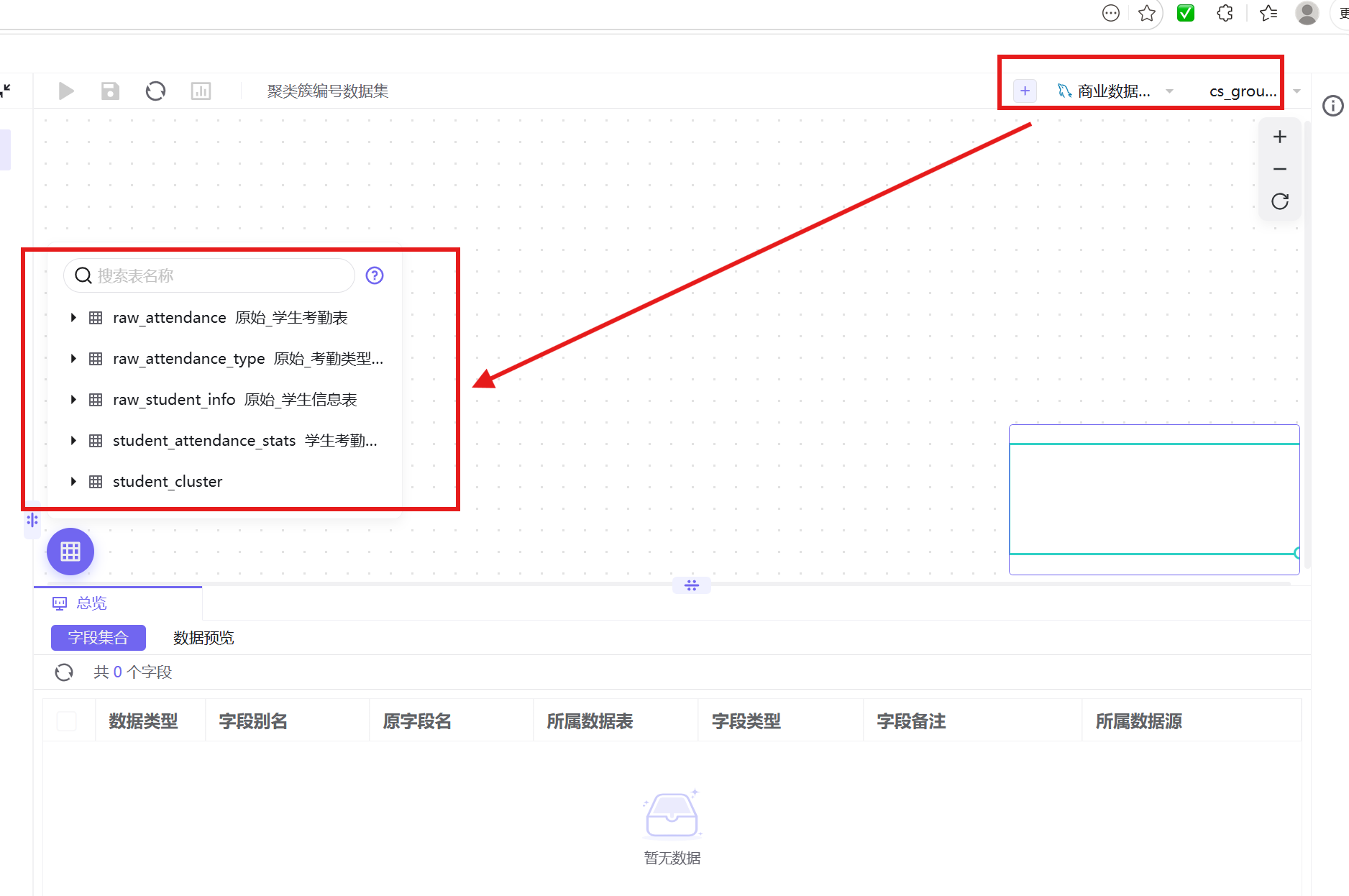
3. 将student_cluster数据表拖拽至画布编辑区;
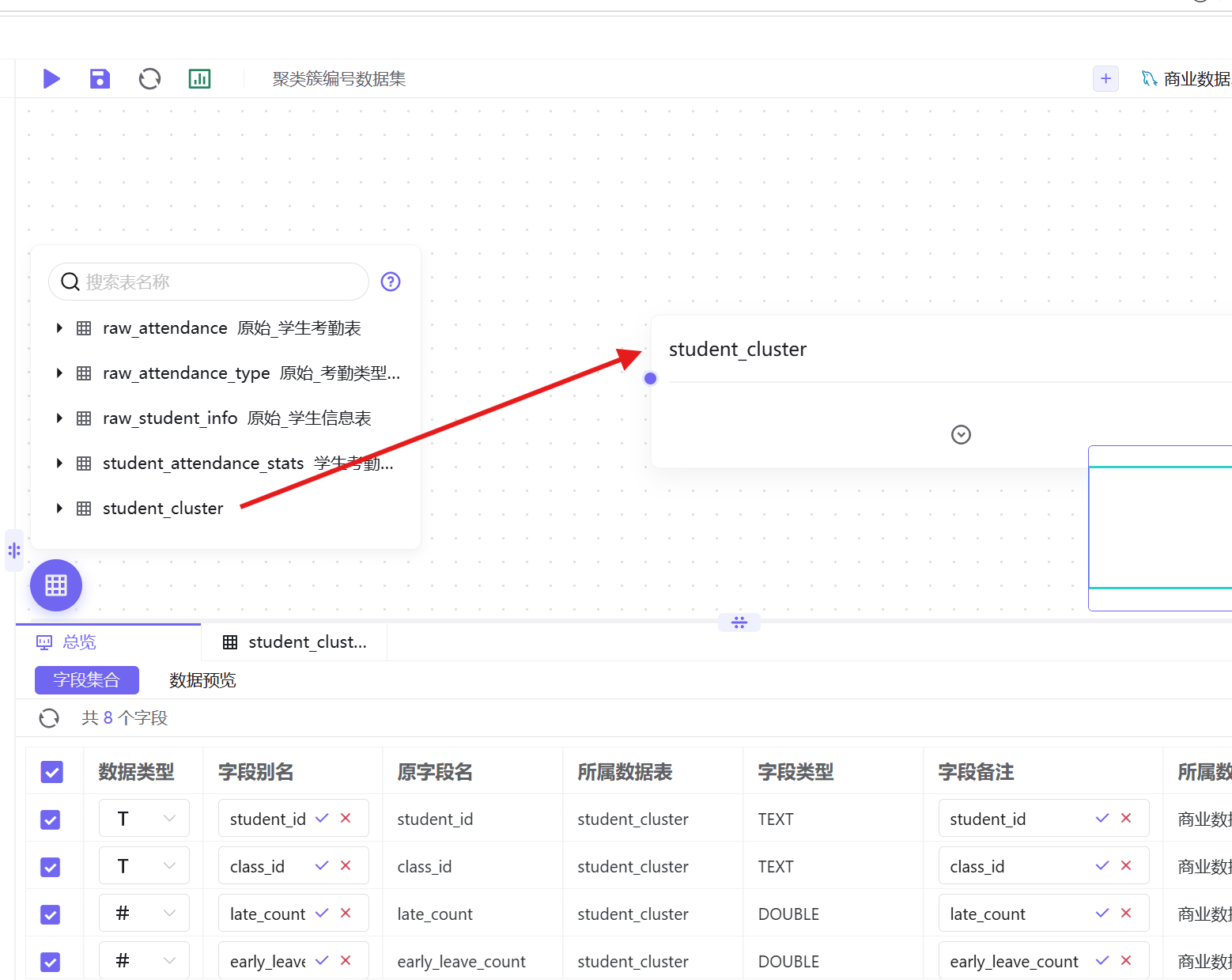
4. 统一修改字段中文备注,提升图表可读性,字段对应关系如下:
|
原字段名 |
字段备注 |
|---|---|
|
student_id |
学生ID |
|
class_id |
班级ID |
|
late_count |
迟到次数 |
|
early_leave_count |
早退次数 |
|
leave_count |
请假次数 |
|
uniform_violate_count |
没穿校服次数 |
|
Cluster |
聚类簇编号 |
|
Silhouette |
轮廓系数 |
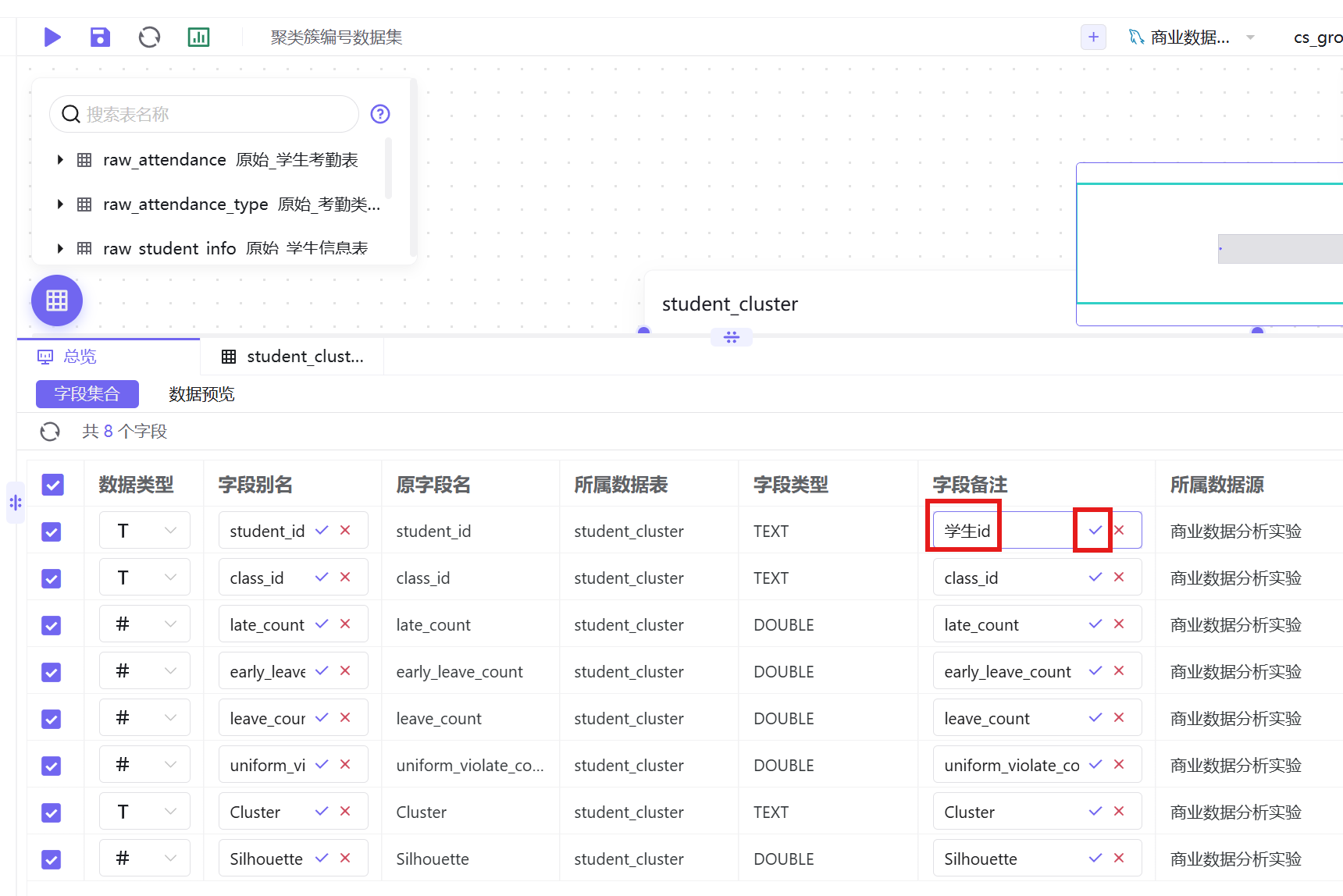
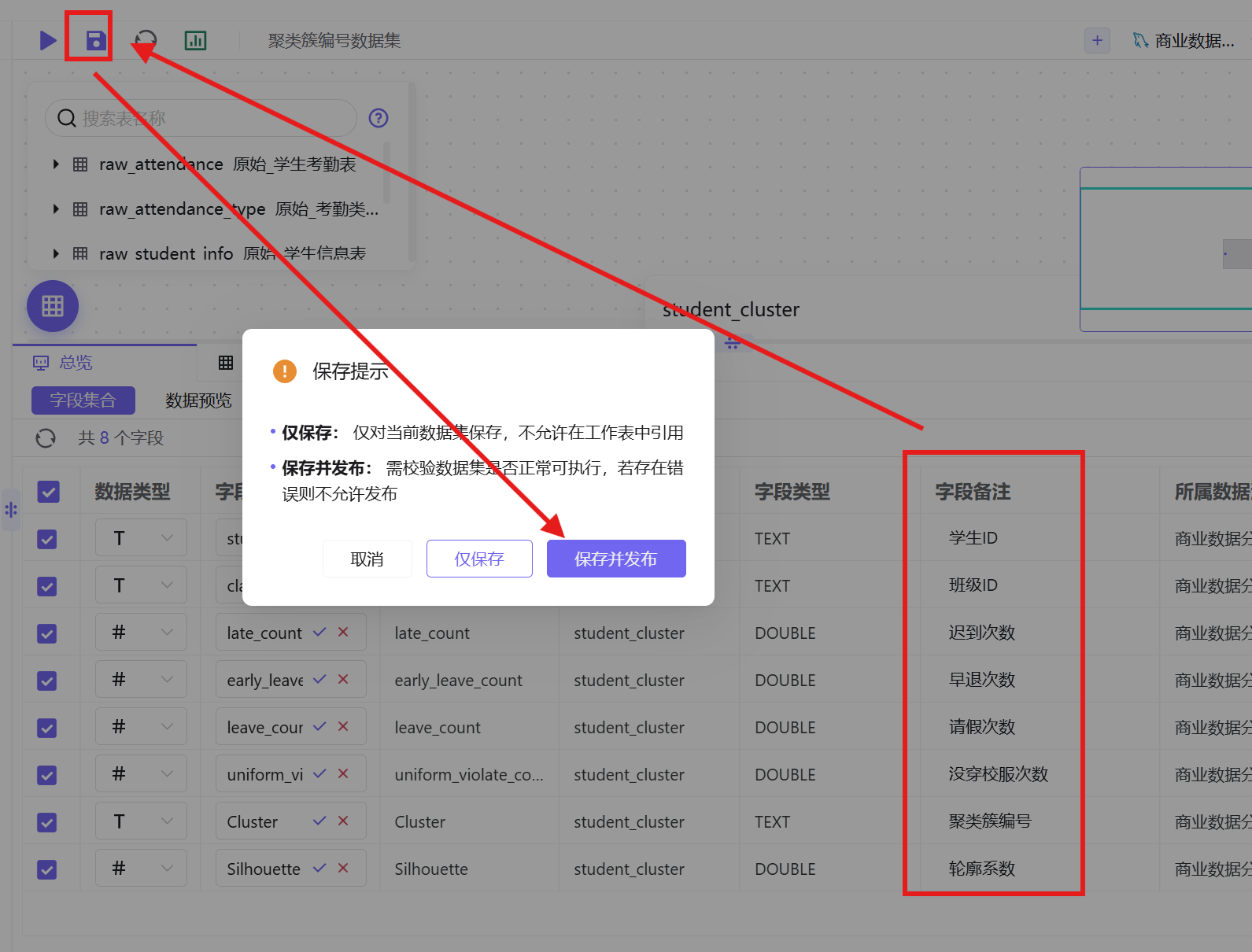
5. 字段修改完成后,点击画布左上角「保存」-「保存并发布」,完成数据集创建发布。
3.2.3 制作工作表
通过多维度指标交叉分析,制作散点图工作表,直观呈现不同聚类簇的考勤行为分布特征:
1. 点击左侧「工作表」模块,新建专属分组用于存放本次分析工作表;
2. 在分组内新建工作表,命名为「迟到早退次数的聚类簇分析」,数据集选择已发布的聚类数据集,图表类型选择「探索器」;
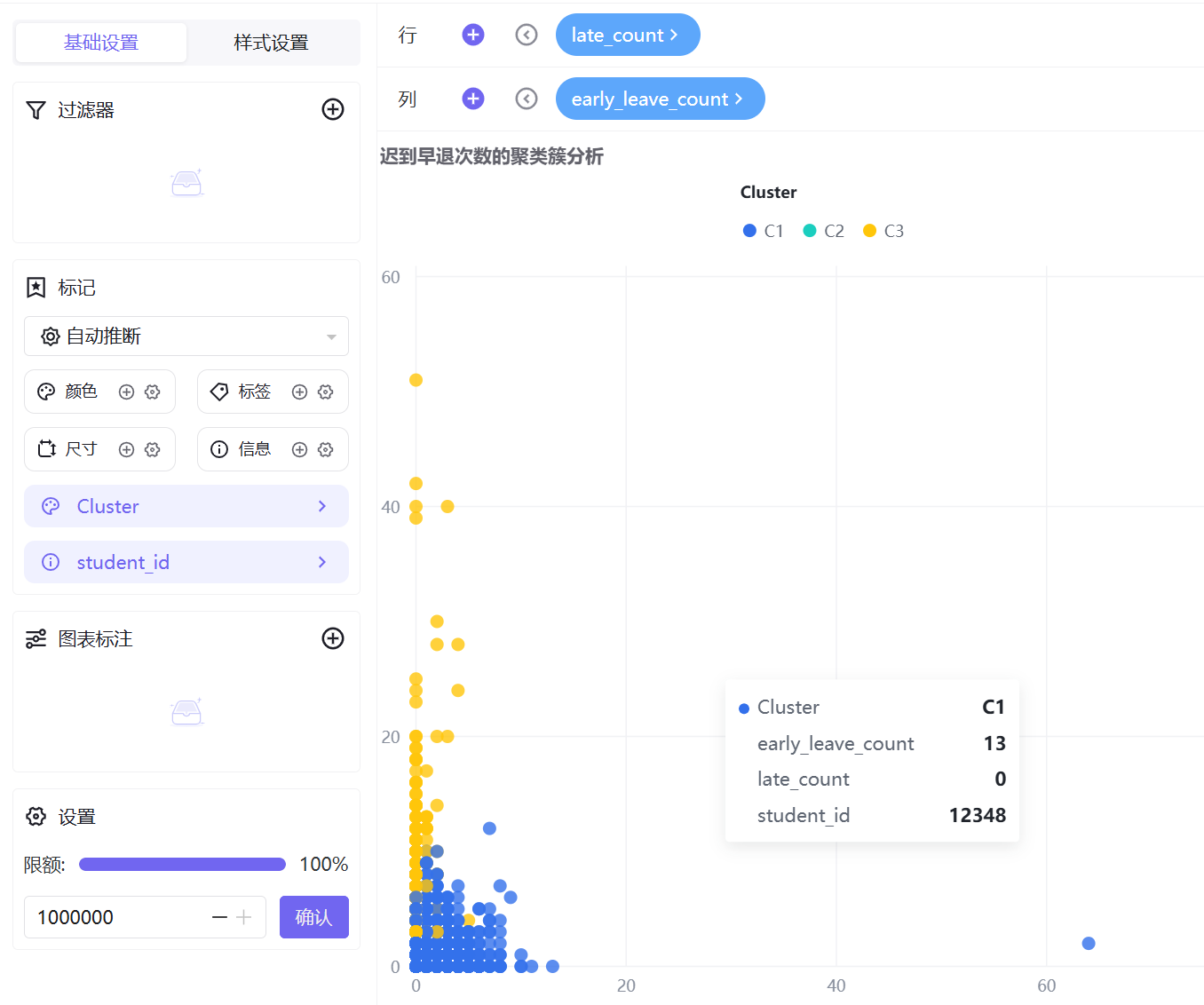
3. 字段配置:X轴放置「迟到次数」,Y轴放置「早退次数」;
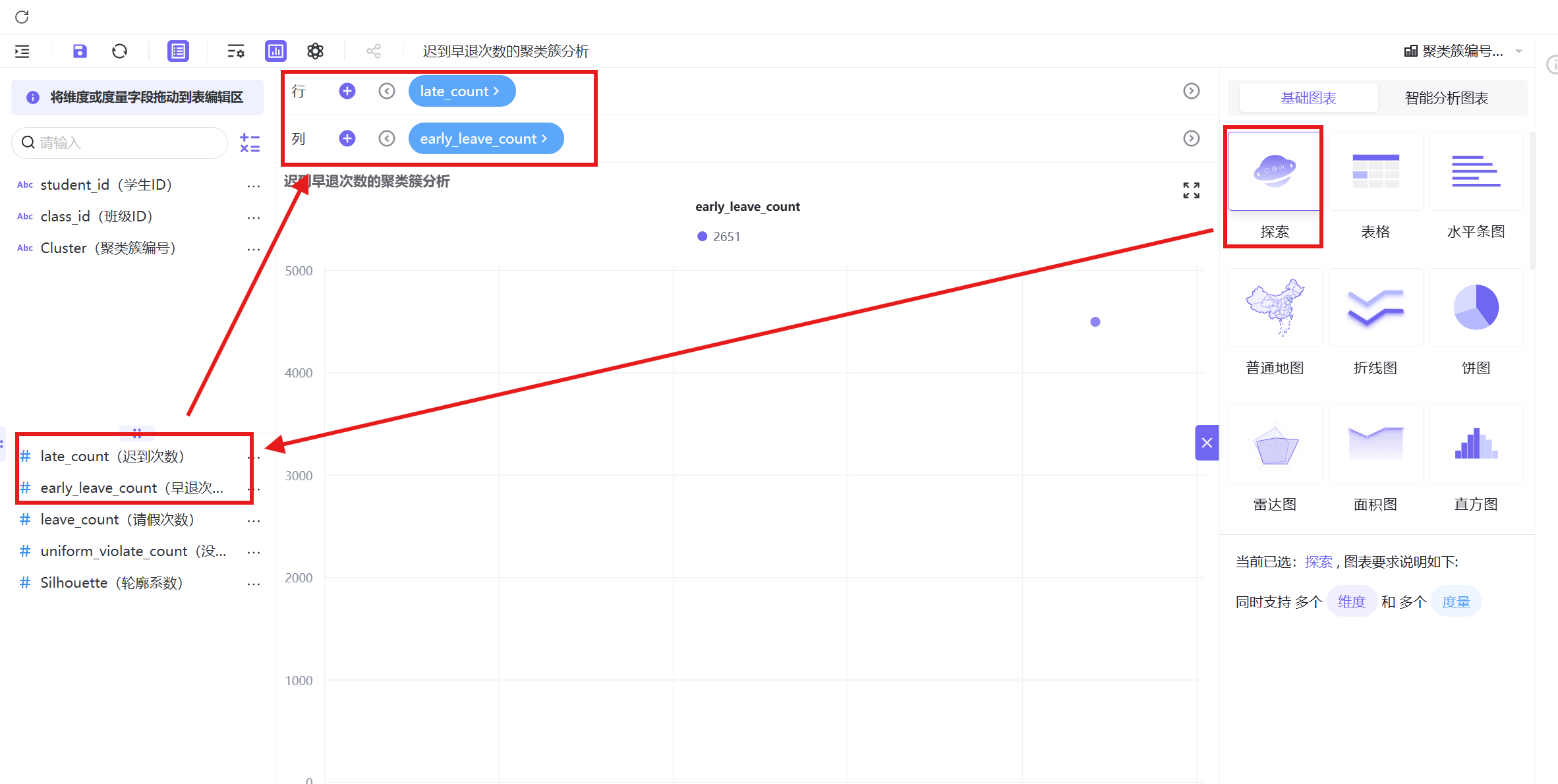
4. 图形设置:颜色维度添加「聚类簇编号」,信息维度添加「学生ID」并设置为维度属性;
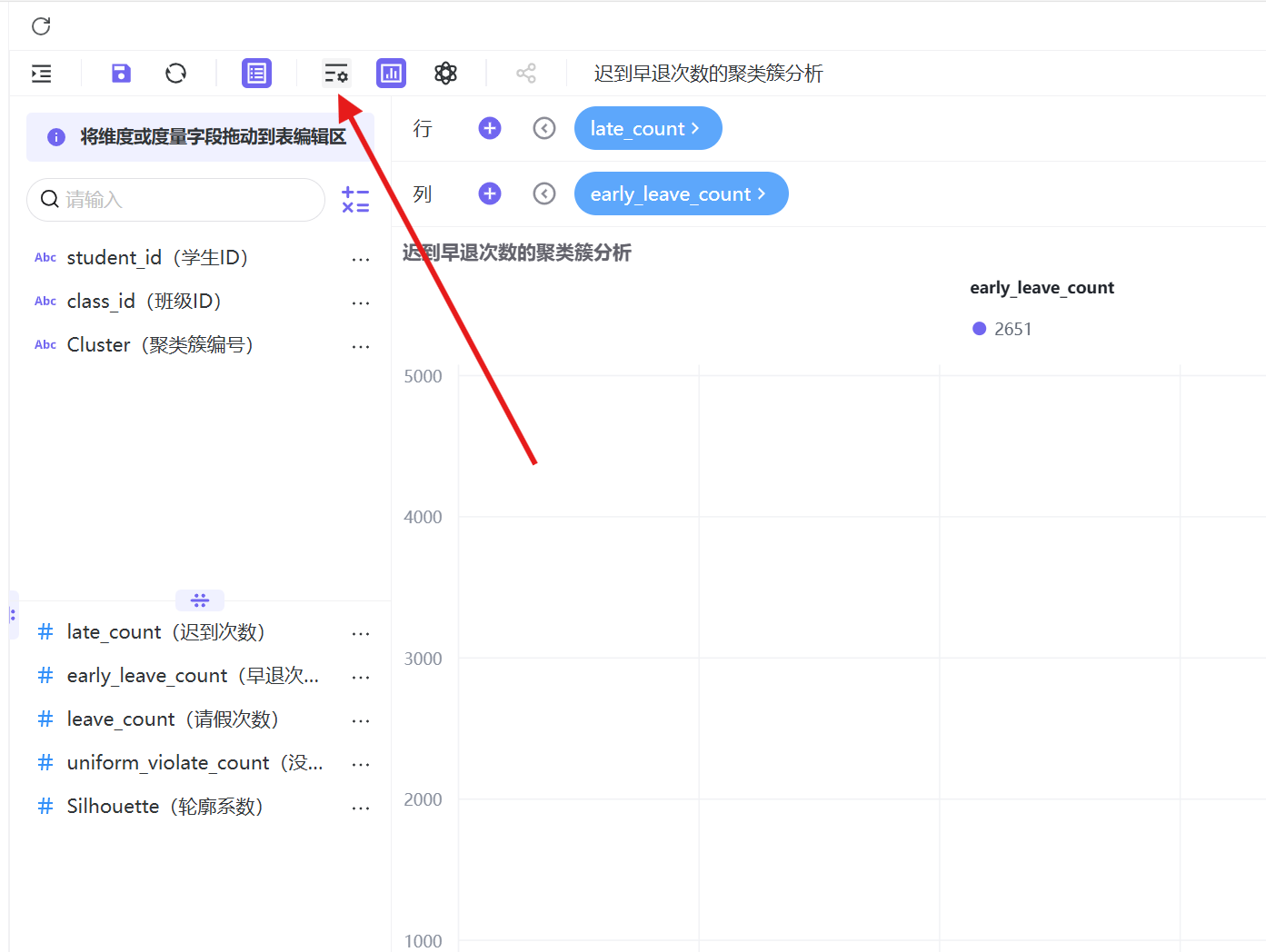
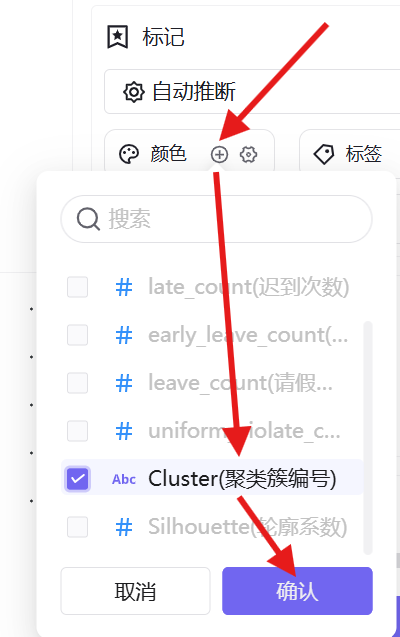
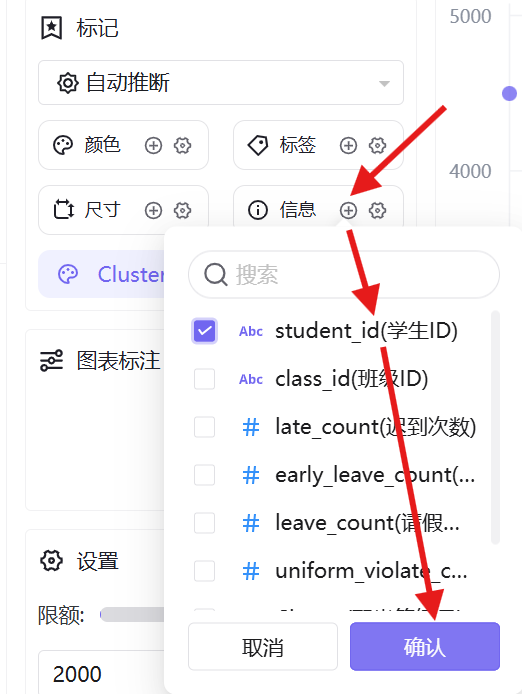
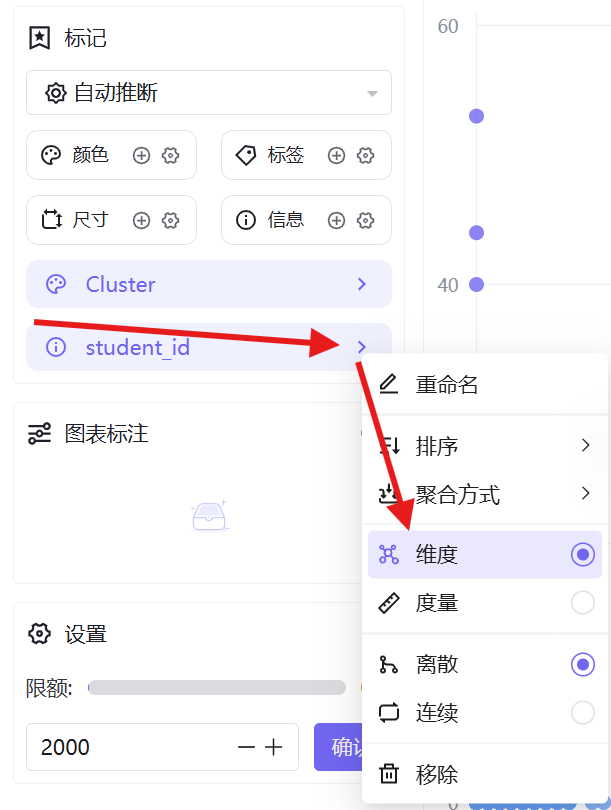
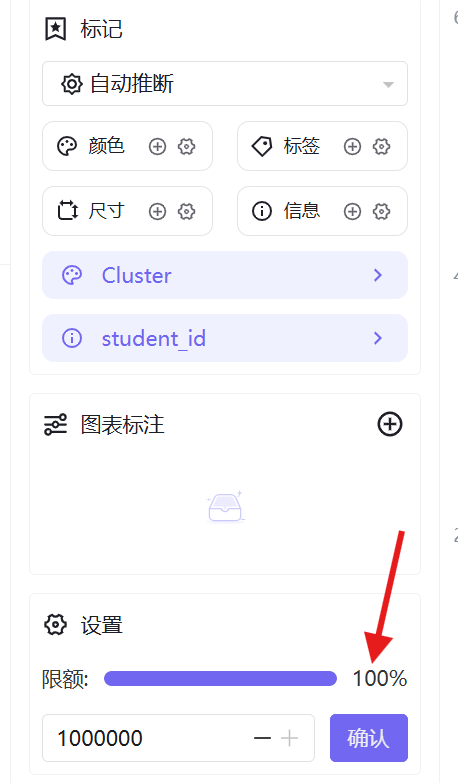
5. 将数据展示限额设置为100%,完整展示全量数据,切换高对比主题色区分簇类,保存并发布工作表;
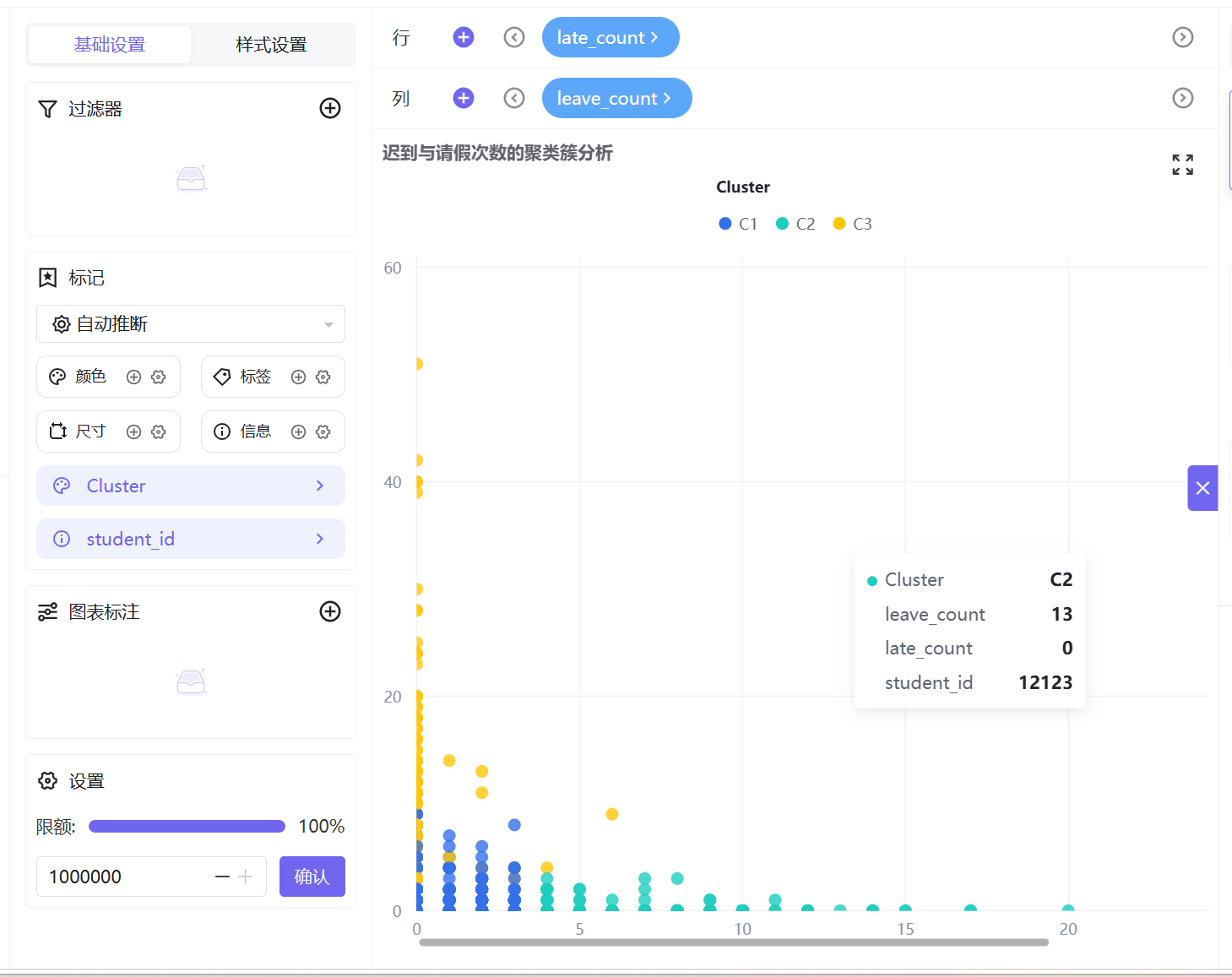
6. 按照相同操作逻辑,依次制作5组交叉分析工作表:迟到与请假次数、迟到与没穿校服次数、早退与请假次数、早退与没穿校服次数、请假与没穿校服次数的聚类簇分析。
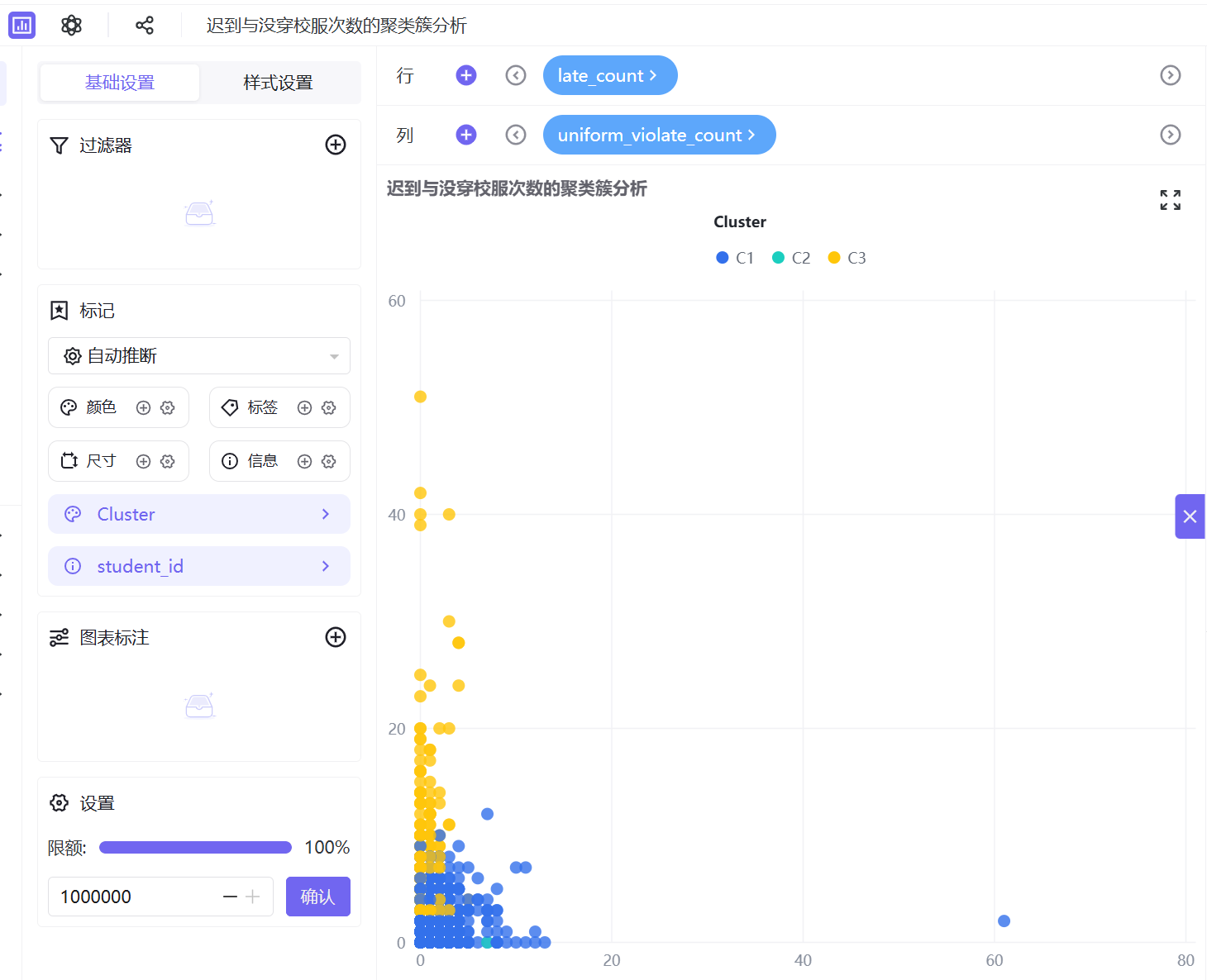
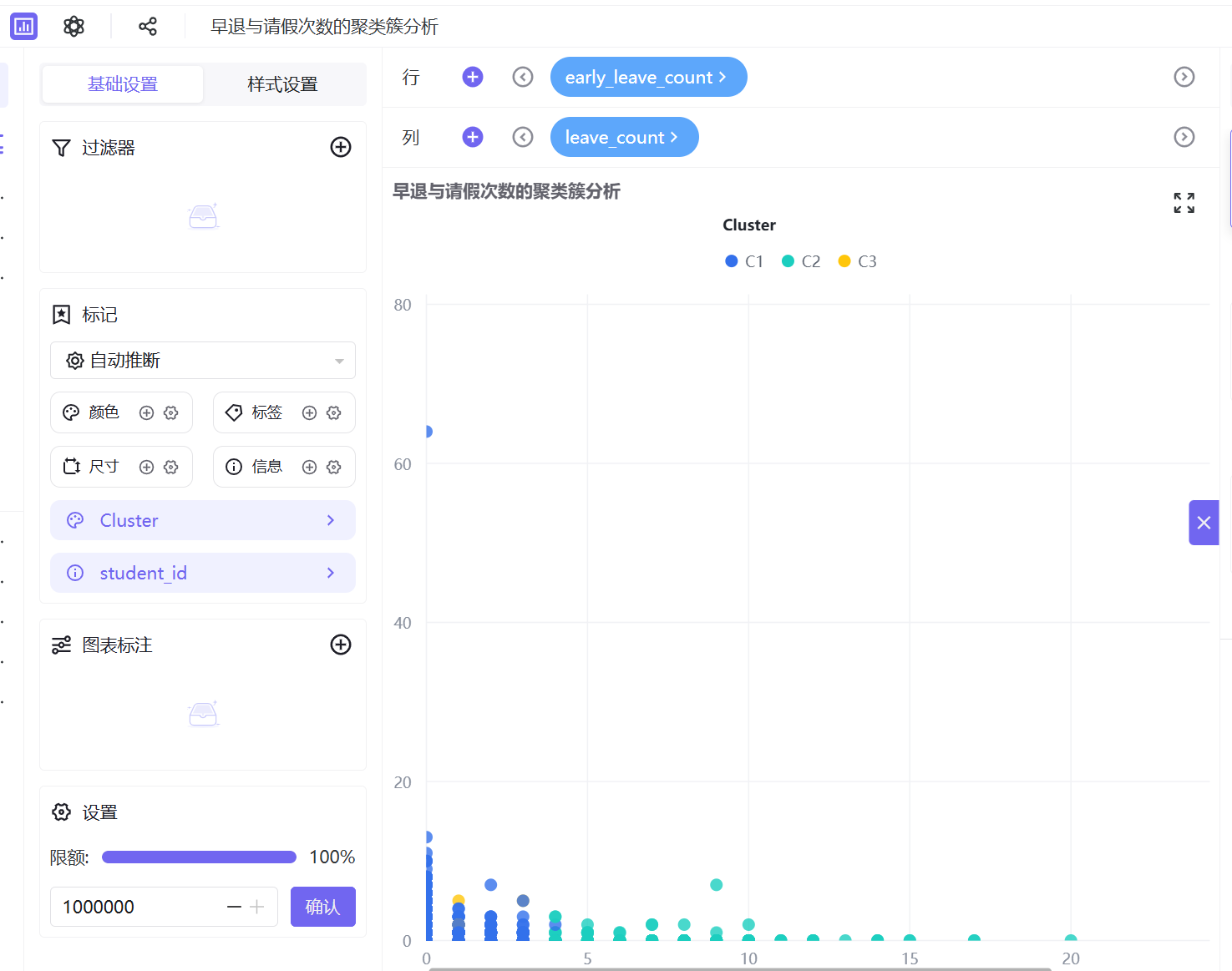
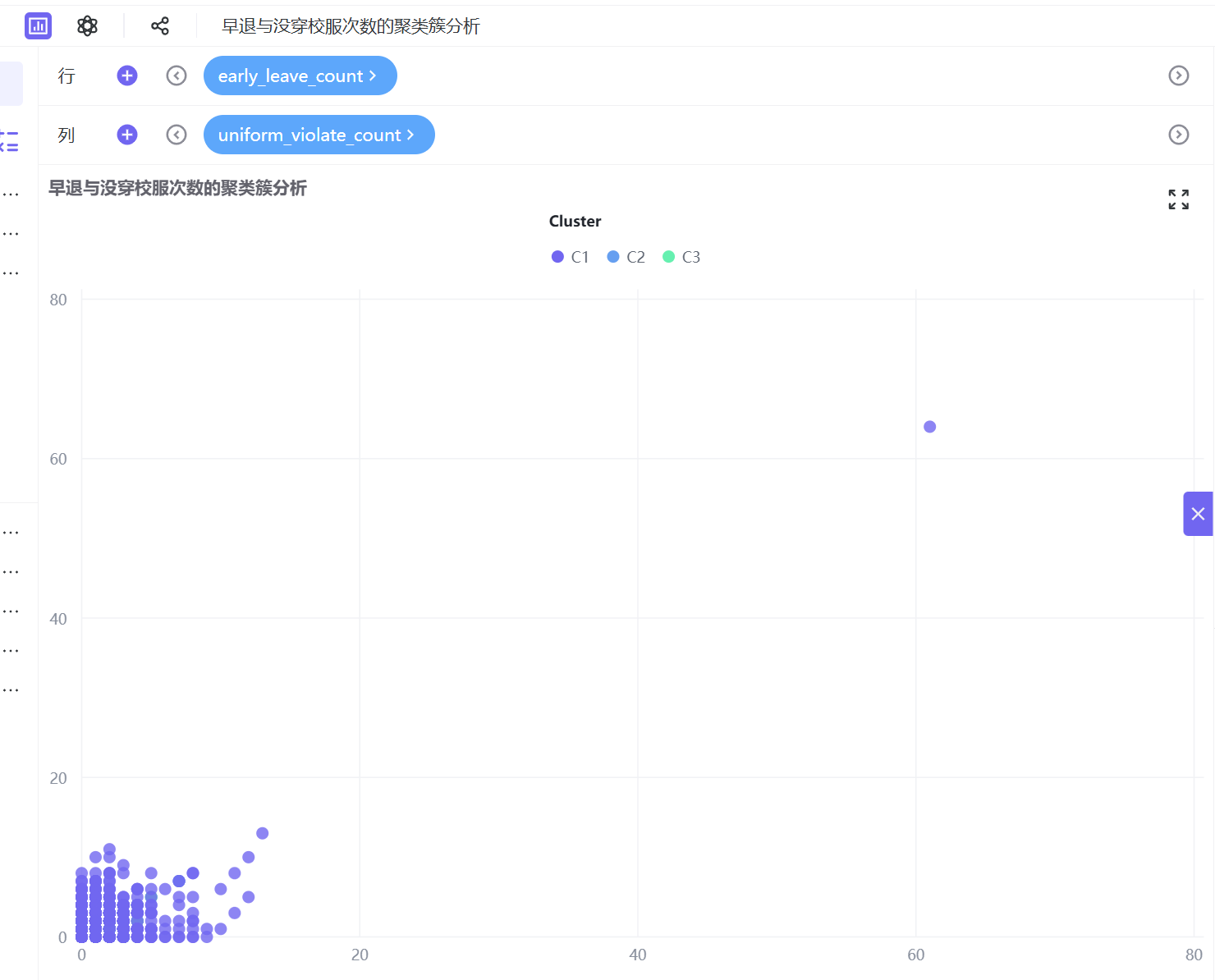
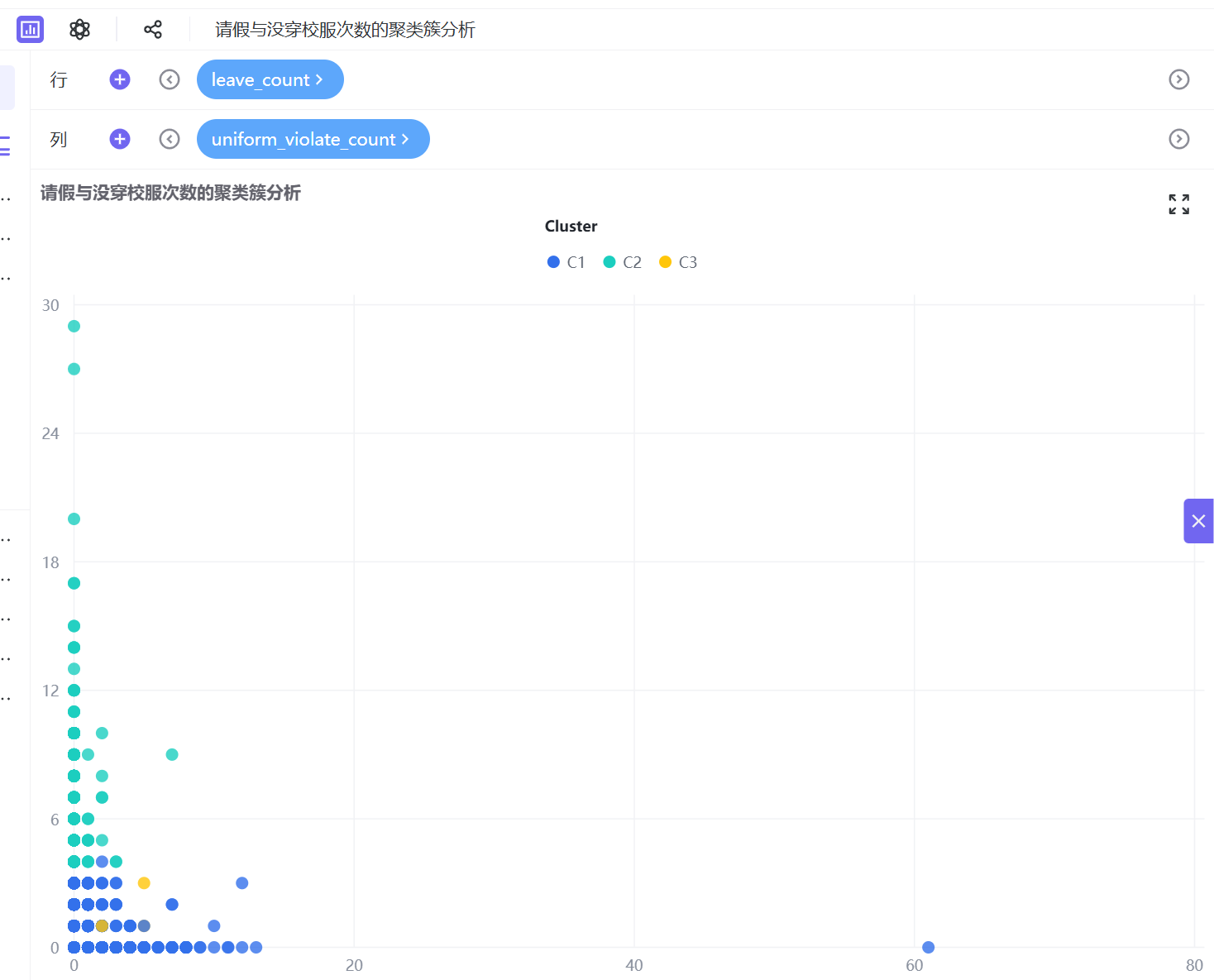
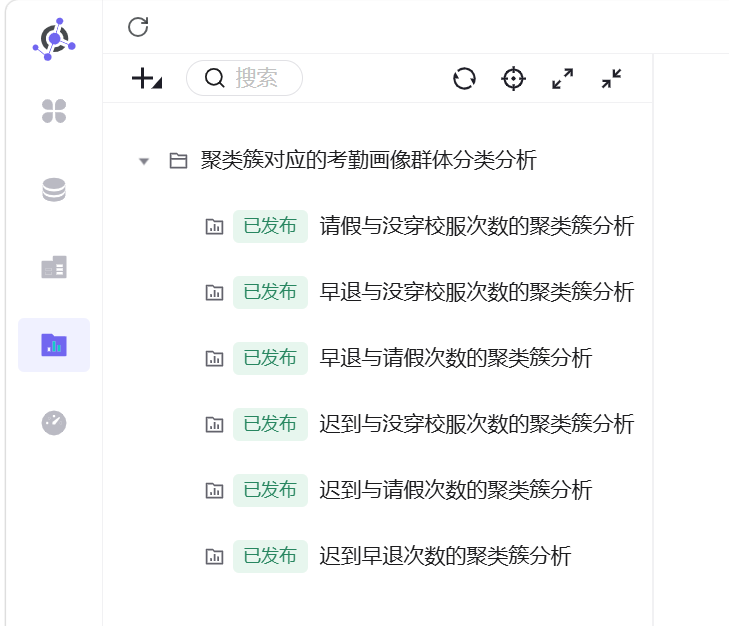
3.2.4 搭建仪表盘
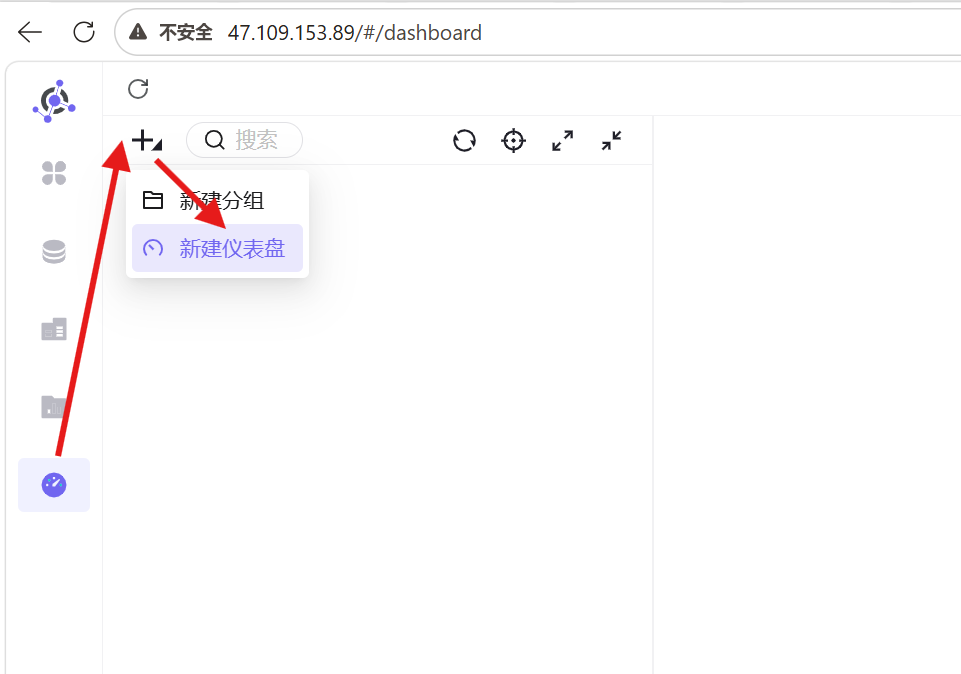
整合所有分析工作表,搭建统一可视化仪表盘,实现聚类结果集中展示:
1. 点击左侧「仪表盘」模块,新建仪表盘并命名为「聚类簇分析」;
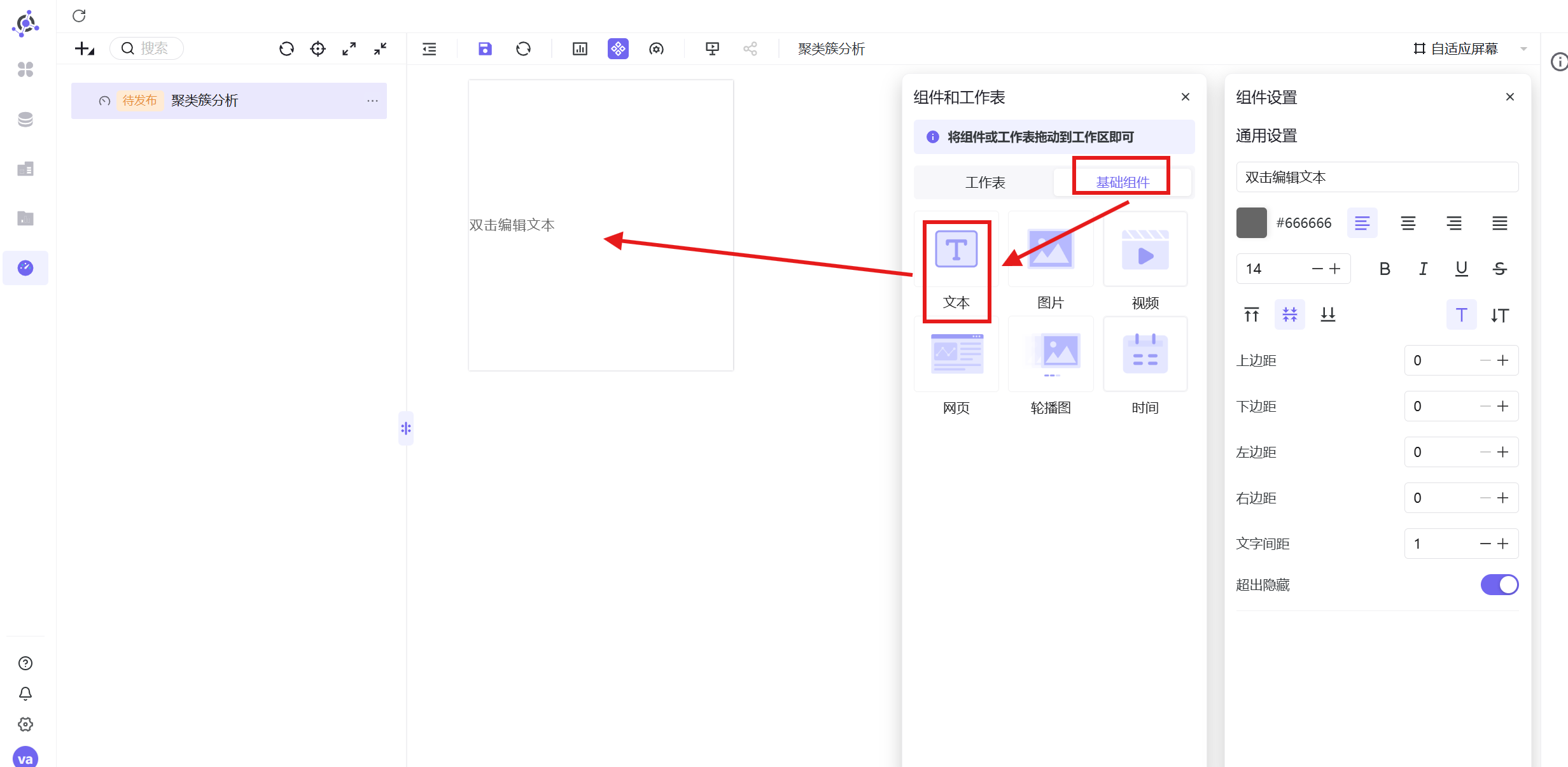
2. 拖拽文本组件至画布,设置标题为「聚类簇分析」,调整字体大小、颜色、居中加粗并固定位置;
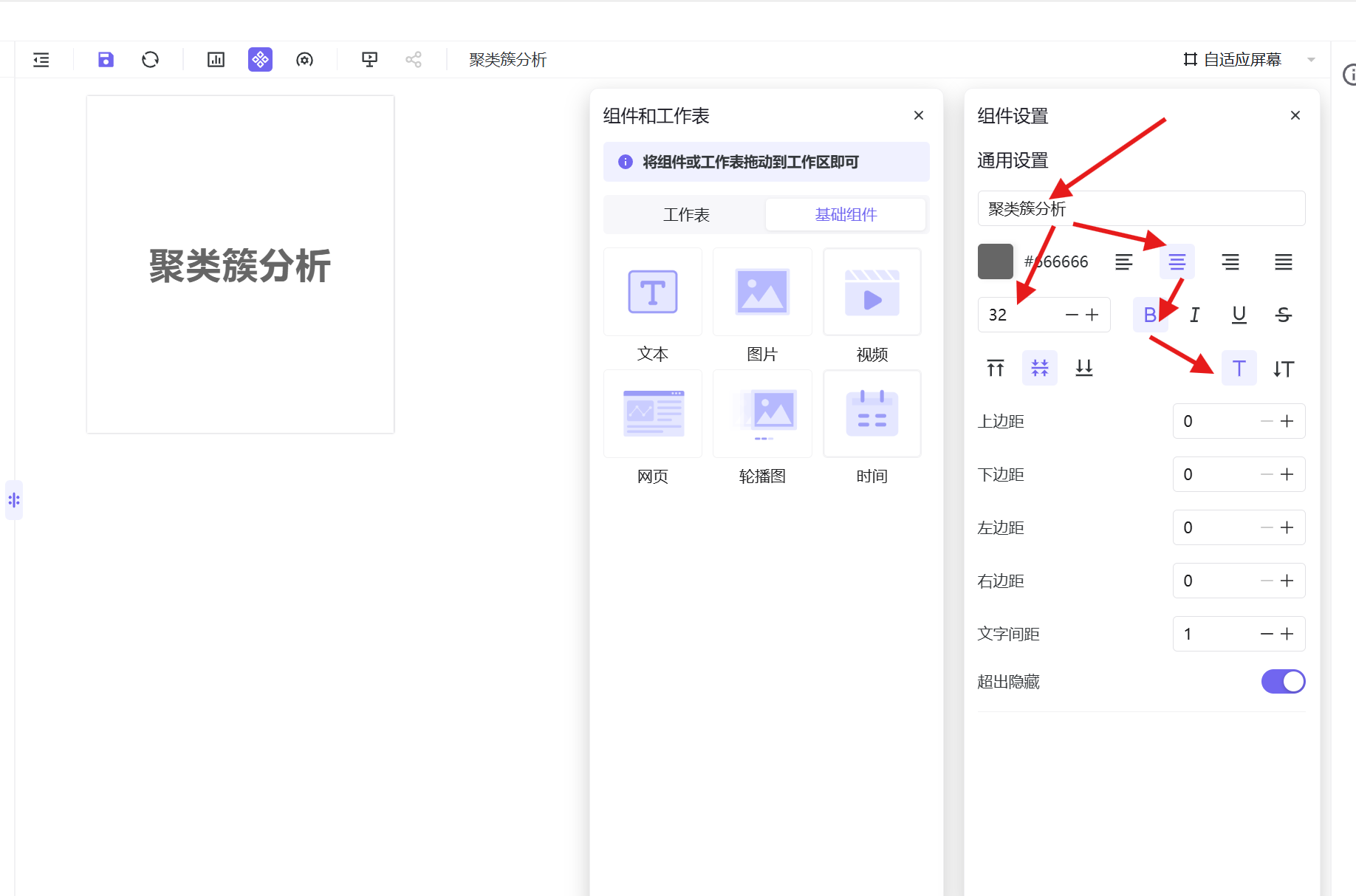
3. 将6组已制作完成的交叉分析工作表全部拖拽至仪表盘画布;
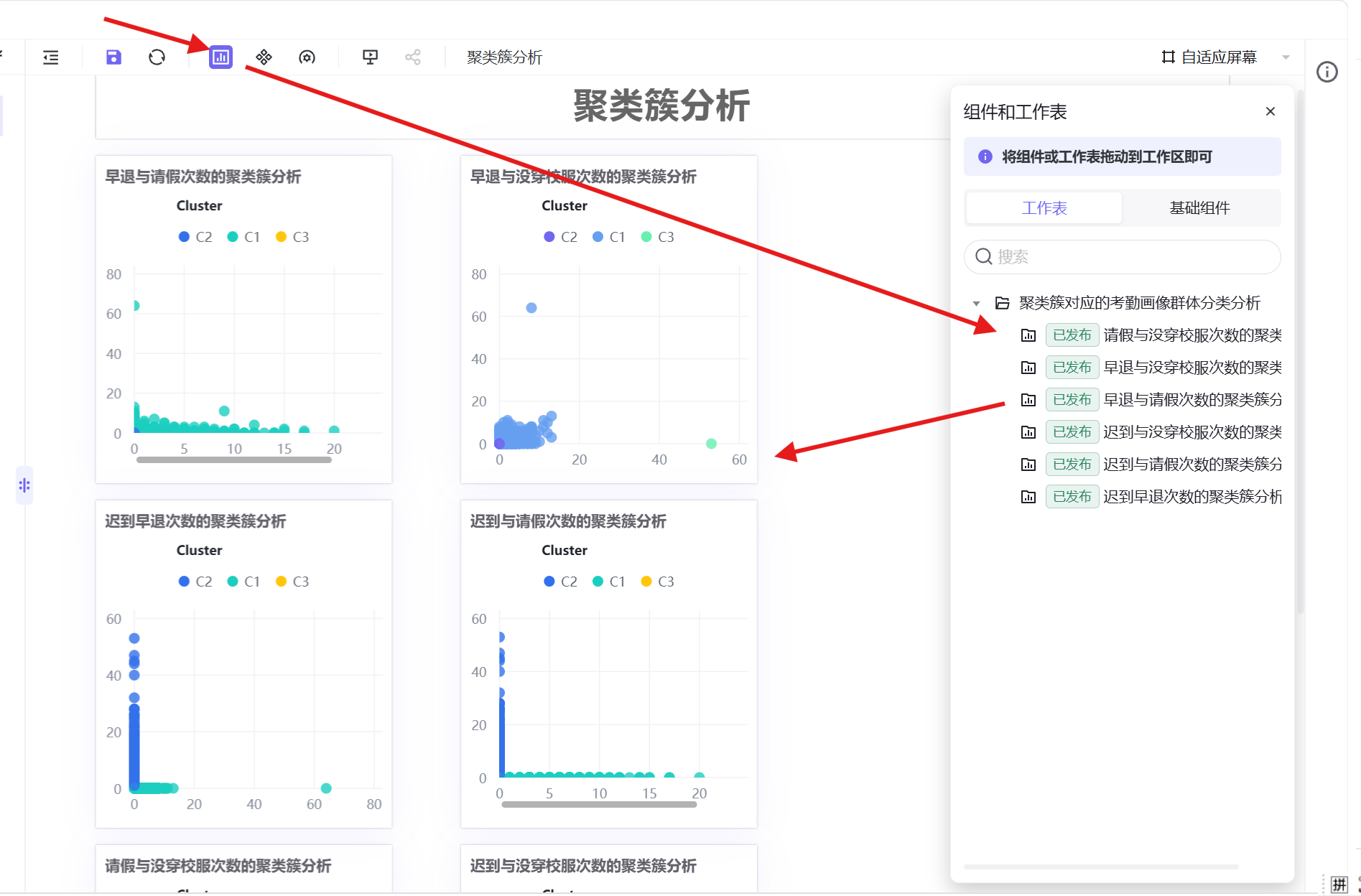
4. 手动调整各图表大小与布局,保证页面整洁美观,调整完成后保存并发布仪表盘。
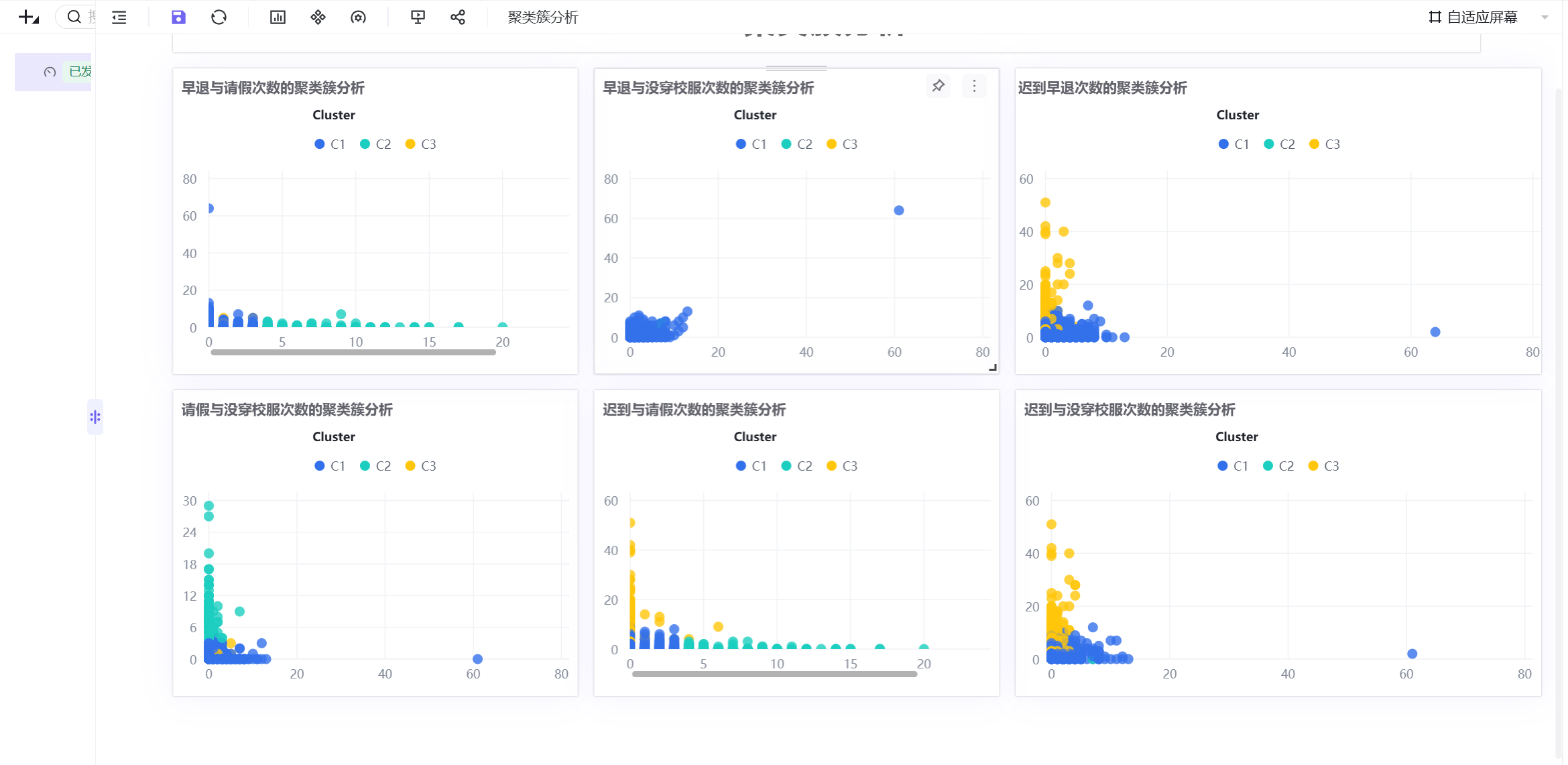
3.2.5 聚类群体画像解读
结合6组多维散点图分布特征,为三类聚类簇赋予业务含义,完成机器编号到学生考勤画像的转化,精准划分三类学生群体:
C1(蓝色,自律模范型):所有考勤指标组合中,数据点高度集中在低频次区间,无离群值。学生出勤稳定、纪律意识强,几乎无迟到、早退、请假、校服违规等考勤异常行为,是校园考勤正面典型。
C2(青色,轻微波动型):数据整体处于低违纪区间,分布略松散,仅存在少量轻微校服违规、请假行为,无高频迟到早退记录。学生整体纪律可控,仅存在偶发考勤波动,属于日常轻微提醒群体。
C3(黄色,纪律高危型):数据呈现显著离群特征,高频迟到行为突出,同时伴随不同程度早退、请假、校服违规行为,是唯一存在多维度违纪叠加的群体,考勤问题突出,为校园重点管理对象。
群体分类汇总表如下:
|
聚类簇编号 |
颜色 |
群体分类名称 |
核心特征 |
|---|---|---|---|
|
C1 |
蓝色 |
自律模范型 |
全维度异常次数均极低,出勤表现稳定,纪律意识强 |
|
C2 |
青色 |
轻微波动型 |
迟到早退次数低,偶发校服违规或请假,整体纪律可控 |
|
C3 |
黄色 |
纪律高危型 |
全维度异常次数均偏高,高频违纪行为叠加,存在极端离群记录 |
3.3 将映射结果加入学生考勤主题标签表
为实现考勤群体标签持久化应用,将聚类簇编号、中文群体分类标签回写至原始学生考勤主题标签表,完善数据集维度,为后续专项分析铺垫数据基础。
3.3.1 新增扩展字段
原始数据表无聚类分类相关字段,需手动新增字段用于存储聚类结果:
1. 进入往期实验创建的ETL项目,新建转换流并命名为「增加考勤主题扩展标签字段」;
2. 拖拽「执行一个SQL脚本」组件至画布,双击配置数据库连接为团队私有数据库;
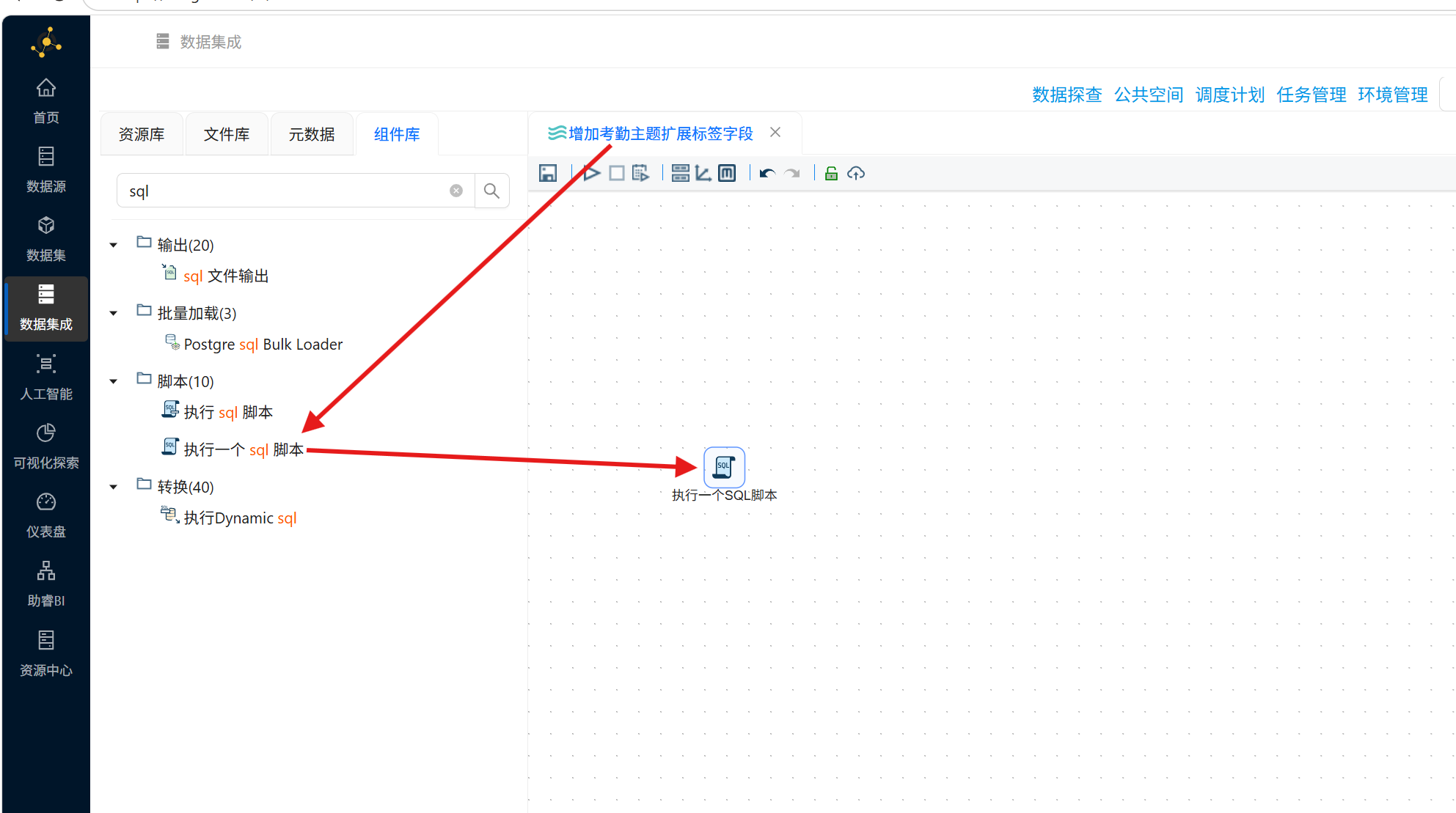
3. 输入以下SQL语句,为数据表新增聚类相关字段:
-- 为学生考勤统计表添加聚类结果字段 ALTER TABLE student_attendance_stats ADD COLUMN cluster VARCHAR(10) NULL DEFAULT NULL COMMENT '聚类簇编号', ADD COLUMN attendance_group VARCHAR(30) NULL DEFAULT NULL COMMENT '考勤群体分类';
4. 保存配置并运行转换流,完成数据表字段新增。
3.3.2 聚类簇编号数据获取
读取AI Studio建模生成的聚类结果表数据,为后续数据更新做准备:
1. 新建转换流,命名为「增加考勤群体分类标签」;
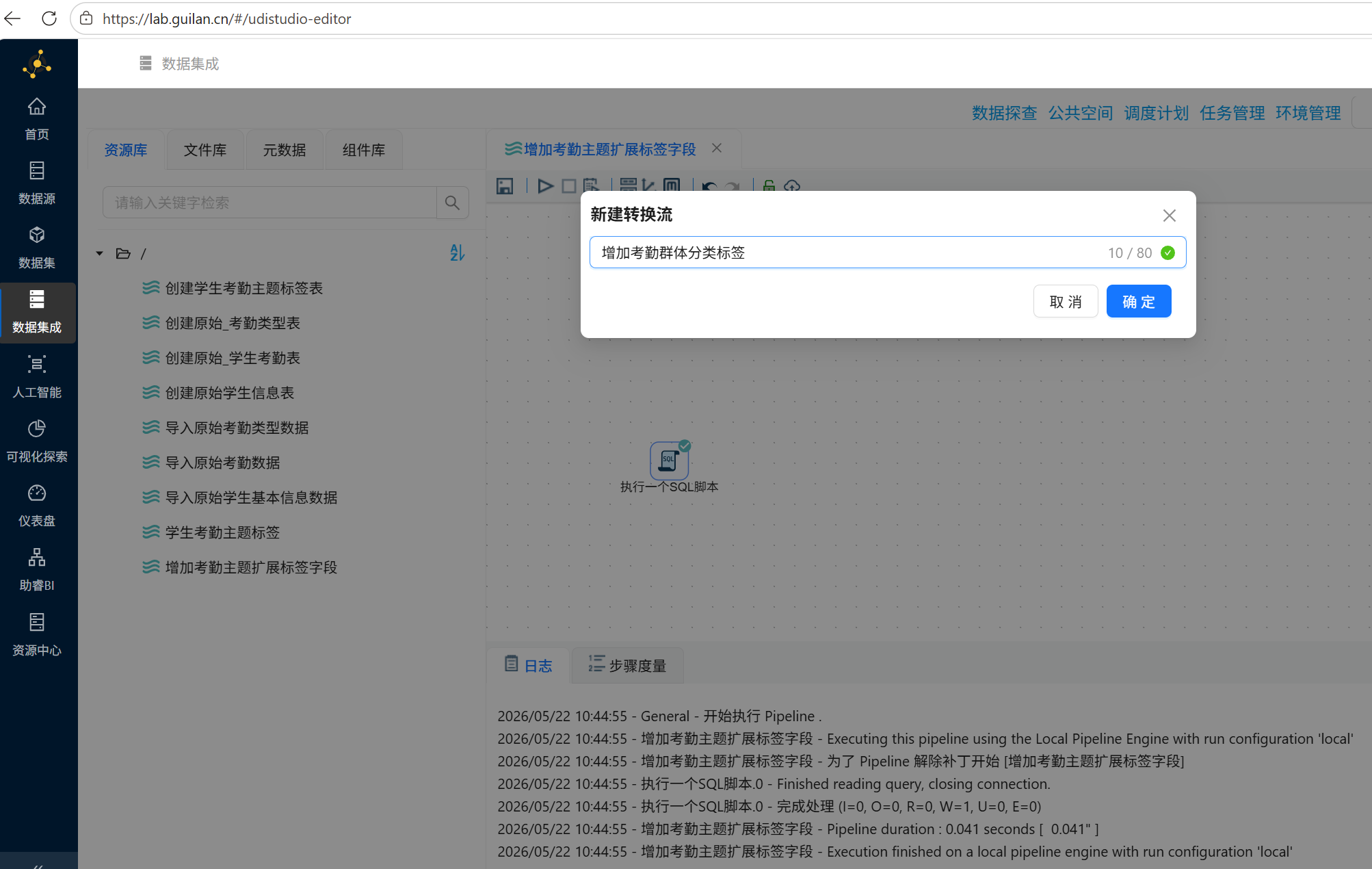
2. 拖拽「表输入」组件至画布,双击组件,从团队私有数据库中读取student_cluster数据表全部数据。
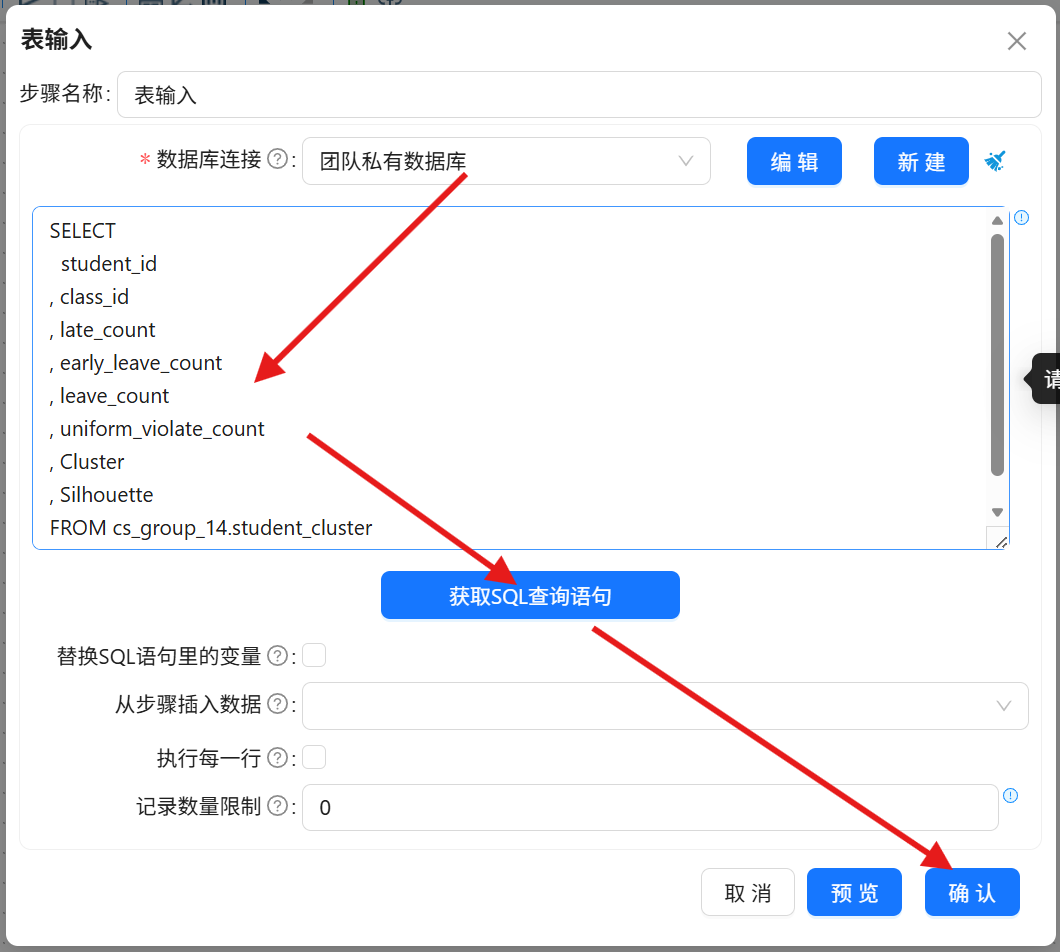
3.3.3 字段选择
精简数据字段,保证数据更新精准有效:
1. 拖拽「字段选择」组件至画布,建立「表输入」到「字段选择」的连线;
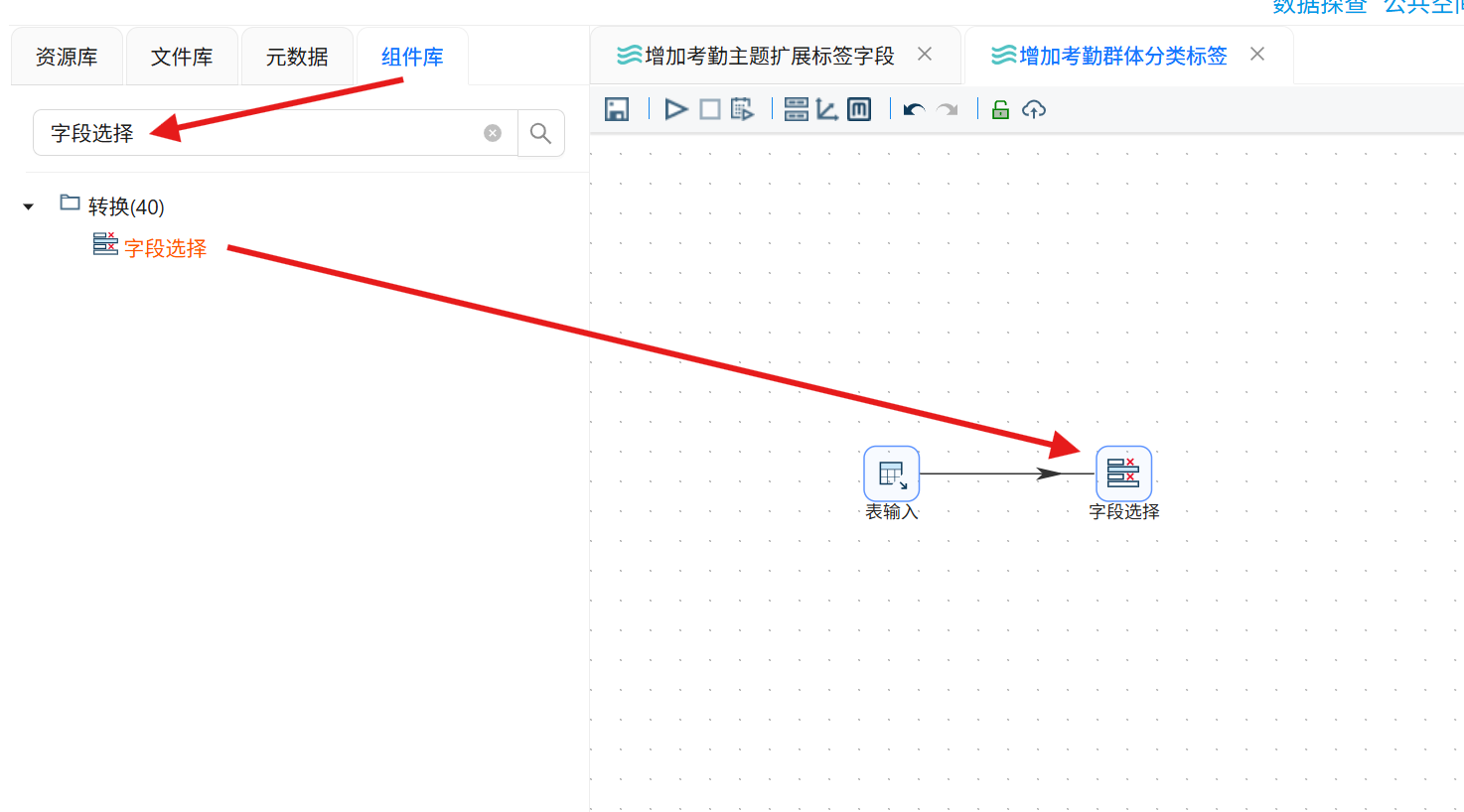
2. 双击组件,获取数据表所有字段,删除除student_id、Cluster外的全部冗余字段;
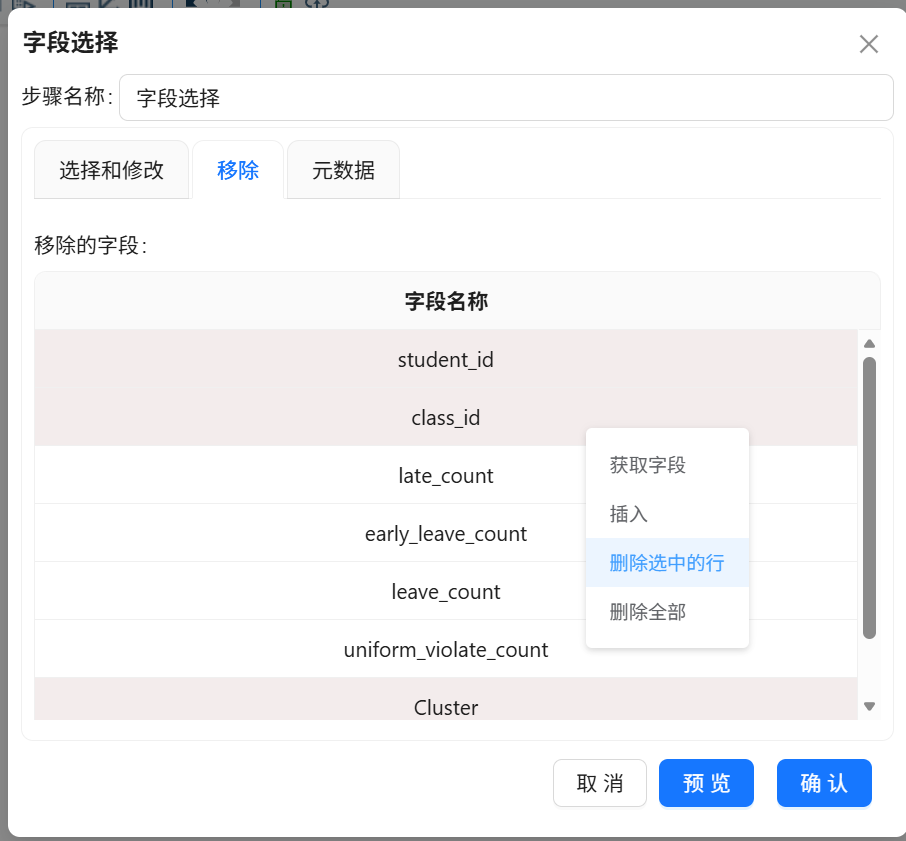
3. 进入元数据配置界面,将student_id字段类型修改为Integer,与原始数据表字段类型保持一致,避免数据更新异常,保存配置。
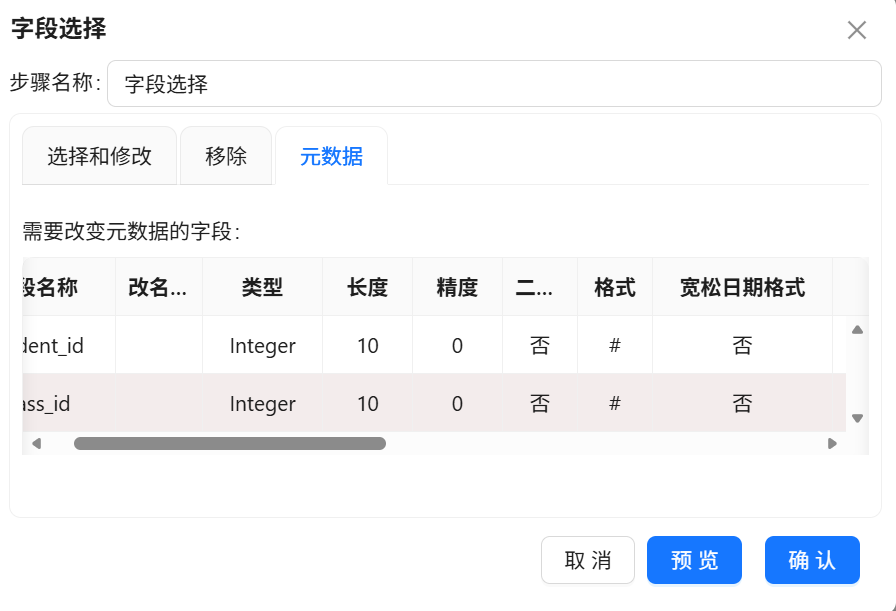
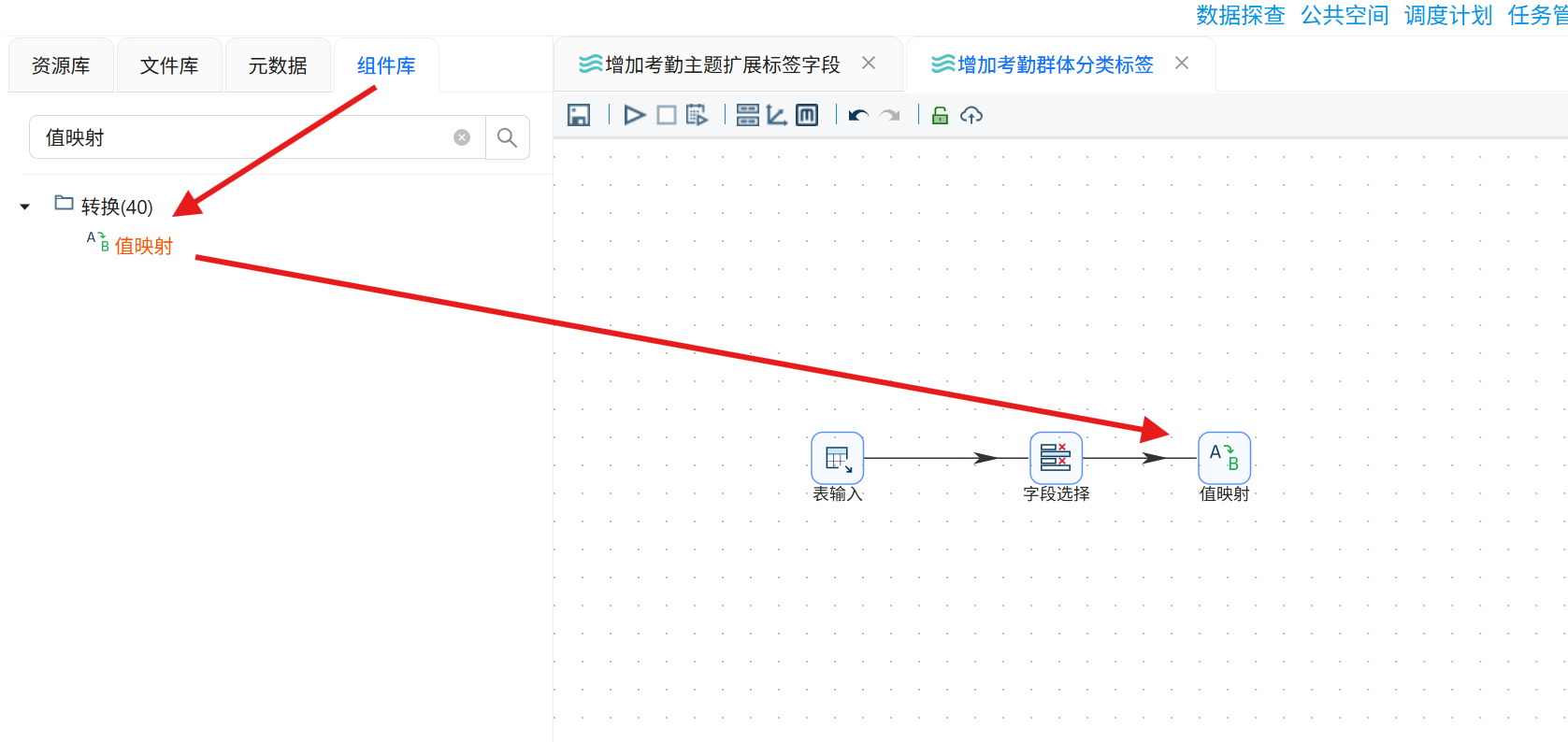
3.3.4 聚类簇编号映射
将机器聚类编号转换为中文业务标签,提升数据可读性:
1. 拖拽「值映射」组件至画布,连接字段选择组件主输出端口;
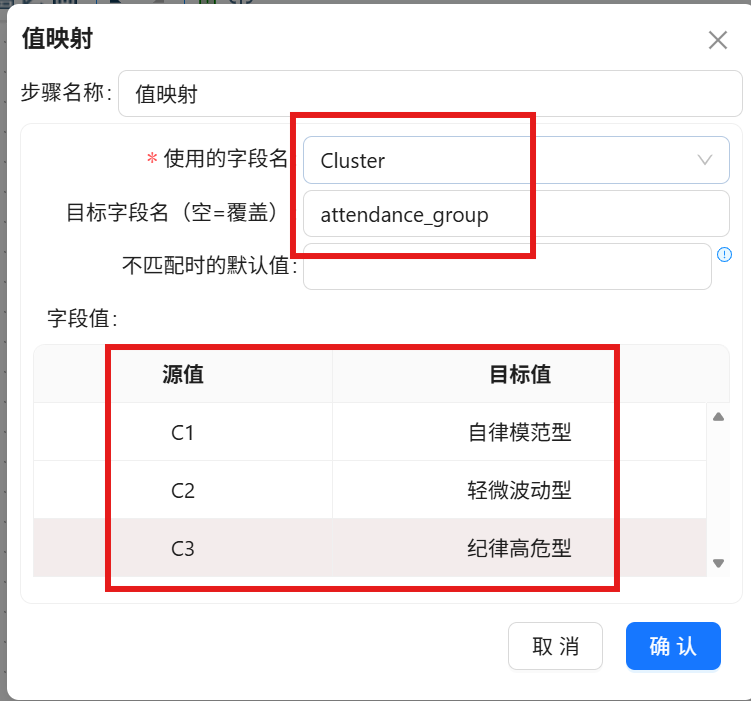
2. 双击组件,设置映射源字段为「Cluster」,新增目标字段「attendance_group」;
3. 新增三组映射规则:源值C1对应「轻微波动型」、C2对应「自律模范型」、C3对应「纪律高危型」,保存配置。
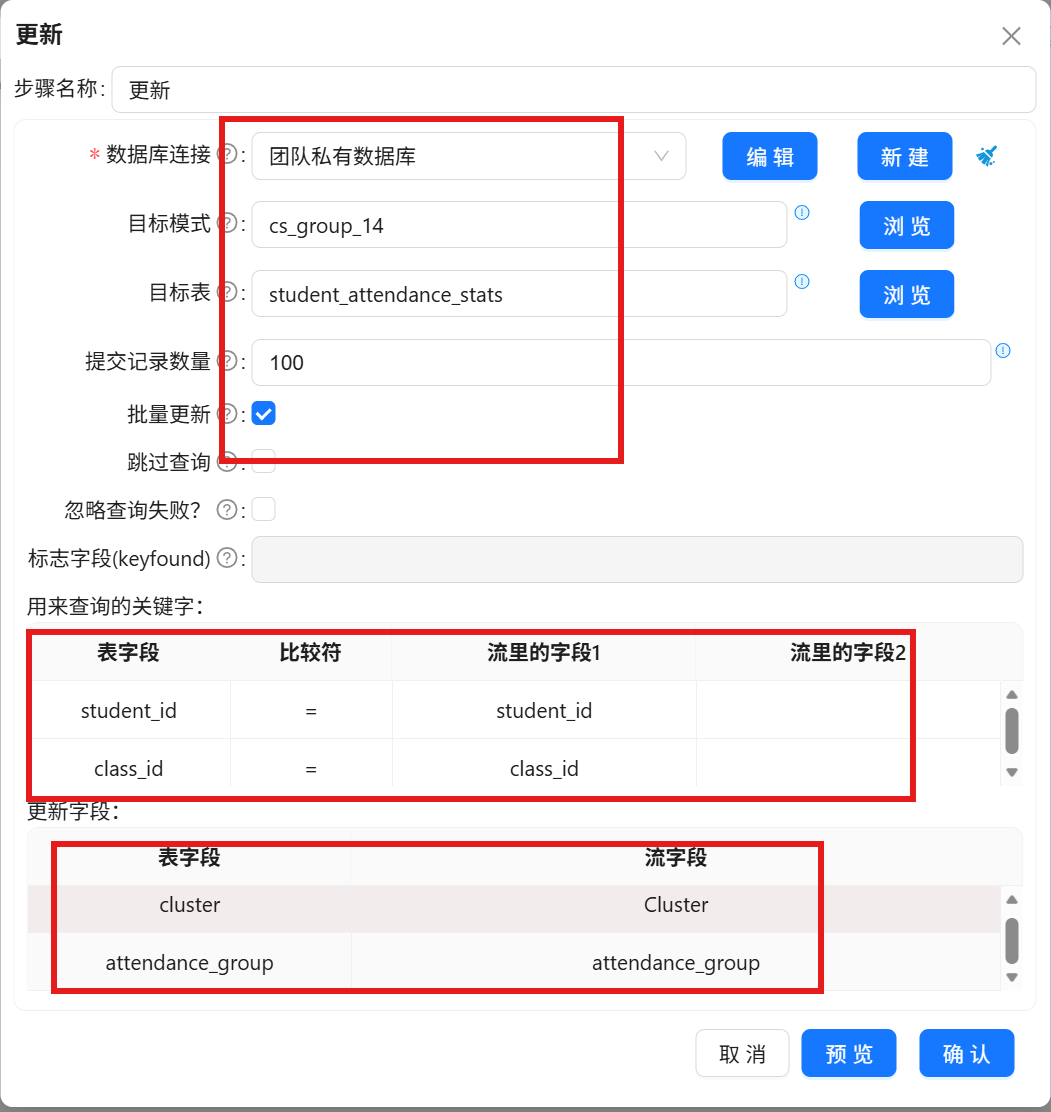
3.3.5 更新学生考勤主题标签
将映射后的中文标签与聚类编号批量更新至原始考勤数据表:
1. 拖拽「更新」组件至画布,连接值映射组件输出端口;
2. 双击更新组件,数据库连接选择团队私有数据库,目标模式选择labs,目标表选中student_attendance_stats;
3. 配置更新规则:以student_id为唯一关联关键字,将流数据中的cluster、attendance_group字段值,批量更新至目标数据表对应字段中。
3.3.6 运行转换流
点击画布运行按钮,执行完整数据更新转换流,等待所有组件运行成功。
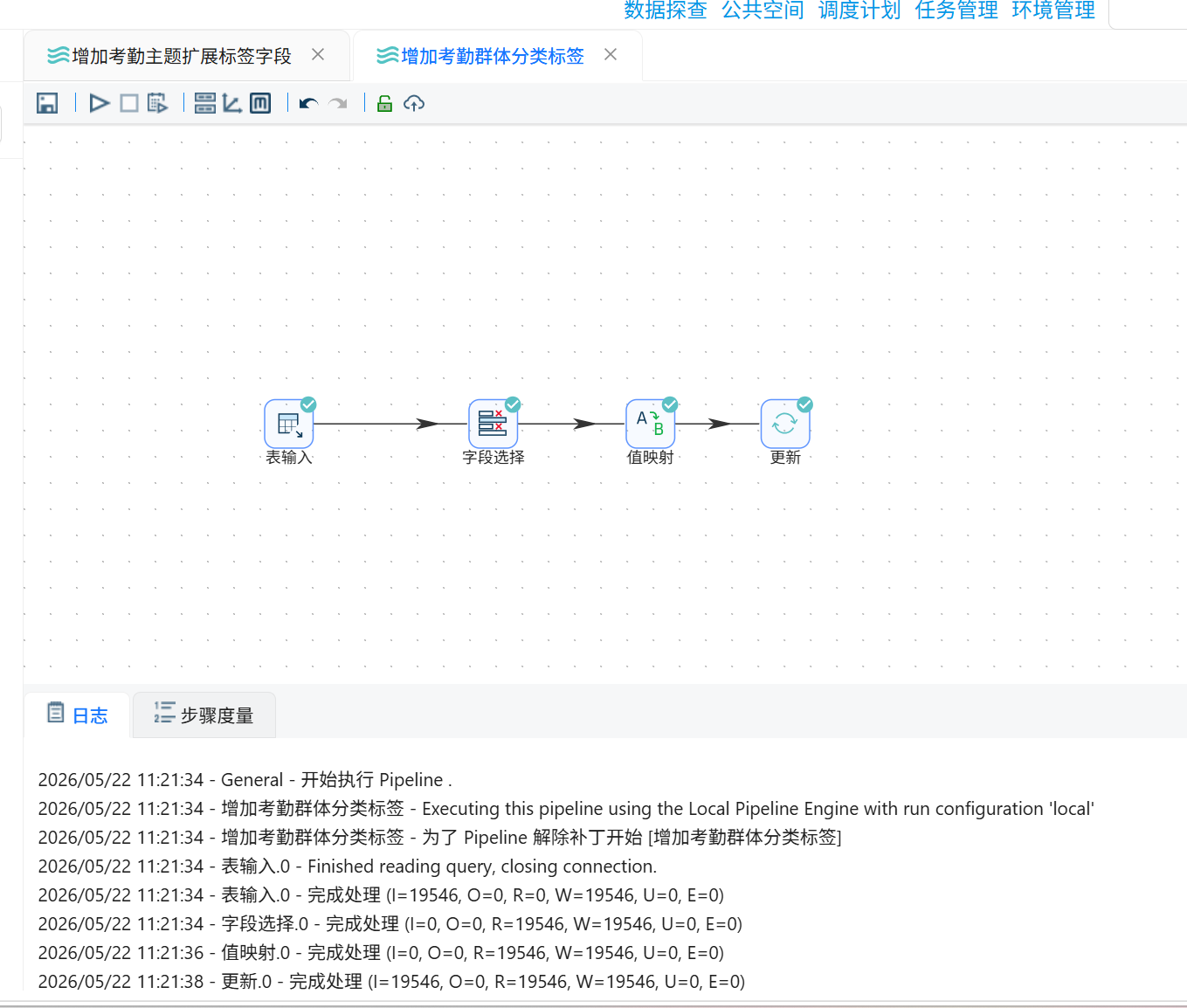
3.3.7 查看结果
1. 切换至元数据界面,右键团队私有数据库,点击「加载元数据」;
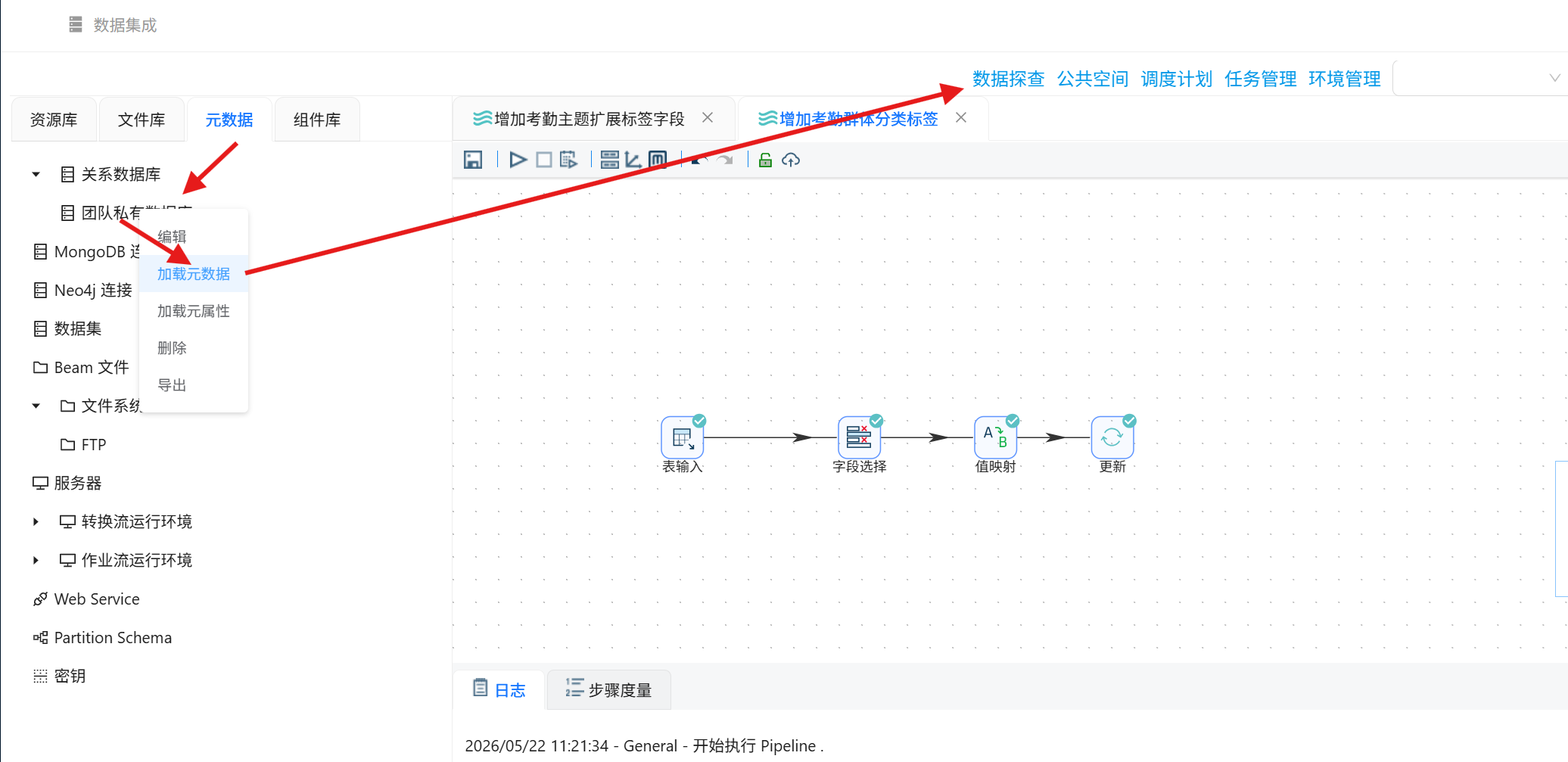
2. 进入数据探查界面,打开student_attendance_stats数据表;
3. 查询表数据,可确认cluster、attendance_group字段已成功更新,数据回写完成。、
4 实验总结
本次实验依托助睿数智Uniplore零代码数据分析平台,基于学生考勤核心行为数据,通过K-Means聚类算法实现学生考勤行为自动分群。实验精准筛选四类考勤核心指标建模,保障了聚类结果的稳定性与业务可解释性。借助助睿BI可视化工具,完成机器聚类编号的语义转化,精准划分出自律模范型、轻微波动型、纪律高危型三类学生考勤群体。最终通过ETL数据处理流程完成分类标签回写,完善考勤主题标签体系,为校园学生精细化管理、违纪行为精准干预、个性化德育教育提供了坚实的数据支撑。
实验二:纪律高危型学生考勤行为专项画像分析
1 实验说明
1.1 实验目的
基于实验一已完成K-Means聚类标注的学生考勤主题标签表,聚焦纪律高危型核心群体开展专项画像分析。该群体具备高频违纪、多维度考勤异常叠加的典型特征,是校园考勤管理中风险最高、不良影响最大的学生群体。通过多维度拆解该群体的性别、年级、校区、班级分布特征,挖掘违纪行为规律,定位高危高发群体与区域,为学校开展精准干预、重点整治、精细化校园管理提供数据支撑。
1.2 实验环境
1. 实验工具:助睿数智(Uniplore)在线实验平台(https://lab.guilan.cn/)
2. 核心功能:助睿BI数据可视化探索平台、MySQL数据库
3. 核心数据源:student_attendance_stats 学生考勤主题标签表(含聚类分类标签)
4. 实验设备:可正常访问助睿平台、具备数据库连接权限的计算机设备
2 实验数据
2.1 数据结构
本次实验沿用实验一更新后的student_attendance_stats学生考勤主题标签表,在原始基础上新增聚类簇编号、考勤群体分类两个扩展字段,完整数据表结构如下:
|
字段名 |
字段类型 |
|---|---|
|
id |
int |
|
student_id |
int |
|
student_name |
varchar(50) |
|
class_id |
int |
|
class_name |
varchar(50) |
|
grade |
varchar(10) |
|
gender |
varchar(10) |
|
birth_date |
varchar(10) |
|
political_status |
varchar(20) |
|
is_boarder |
varchar(10) |
|
campus_type |
varchar(10) |
|
late_count |
int |
|
early_leave_count |
int |
|
leave_count |
int |
|
uniform_violate_count |
int |
|
create_time |
datetime |
|
cluster |
varchar(10) |
|
attendance_group |
varchar(30) |
2.2 样例数据
本次实验核心分析对象为纪律高危型学生,选取部分典型样例数据如下,可直观体现该群体高频违纪特征:
|
id |
student_id |
student_name |
class_id |
class_name |
grade |
gender |
birth_date |
political_status |
is_boarder |
campus_type |
late_count |
early_leave_count |
leave_count |
uniform_violate_count |
create_time |
cluster |
attendance_group |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
1 |
10842 |
马某某 |
672 |
高三(09) |
高三 |
未知 |
未知 |
未知 |
否 |
老校区 |
1 |
0 |
3 |
0 |
2026/5/14 16:00 |
C3 |
纪律高危型 |
|
2 |
10844 |
叶某某 |
672 |
高三(09) |
高三 |
未知 |
未知 |
未知 |
否 |
老校区 |
0 |
0 |
5 |
0 |
2026/5/14 16:00 |
C3 |
纪律高危型 |
|
3 |
10845 |
孙某某 |
672 |
高三(09) |
高三 |
未知 |
未知 |
未知 |
否 |
老校区 |
3 |
0 |
0 |
0 |
2026/5/14 16:00 |
C3 |
纪律高危型 |
3 实验步骤
3.1 进入助睿BI平台
登录助睿数智在线实验平台,点击左侧菜单栏「助睿BI」,进入数据可视化探索平台首页,查看账户数据资源与数据分析功能模块,准备开展专项画像分析。
3.2 连接数据源
本次实验沿用实验一已配置完成的团队私有数据库数据源,无需重复新建连接,可直接调用student_attendance_stats数据表开展多维度画像分析。
3.3 构建数据集
基于更新后的学生考勤标签表,新建专属分析数据集,为高危群体画像分析提供数据支撑:
1. 点击助睿BI左侧「数据集」模块,点击左上角「+」-「新建数据集」,填写数据集名称、所属分组及备注信息,确认创建;
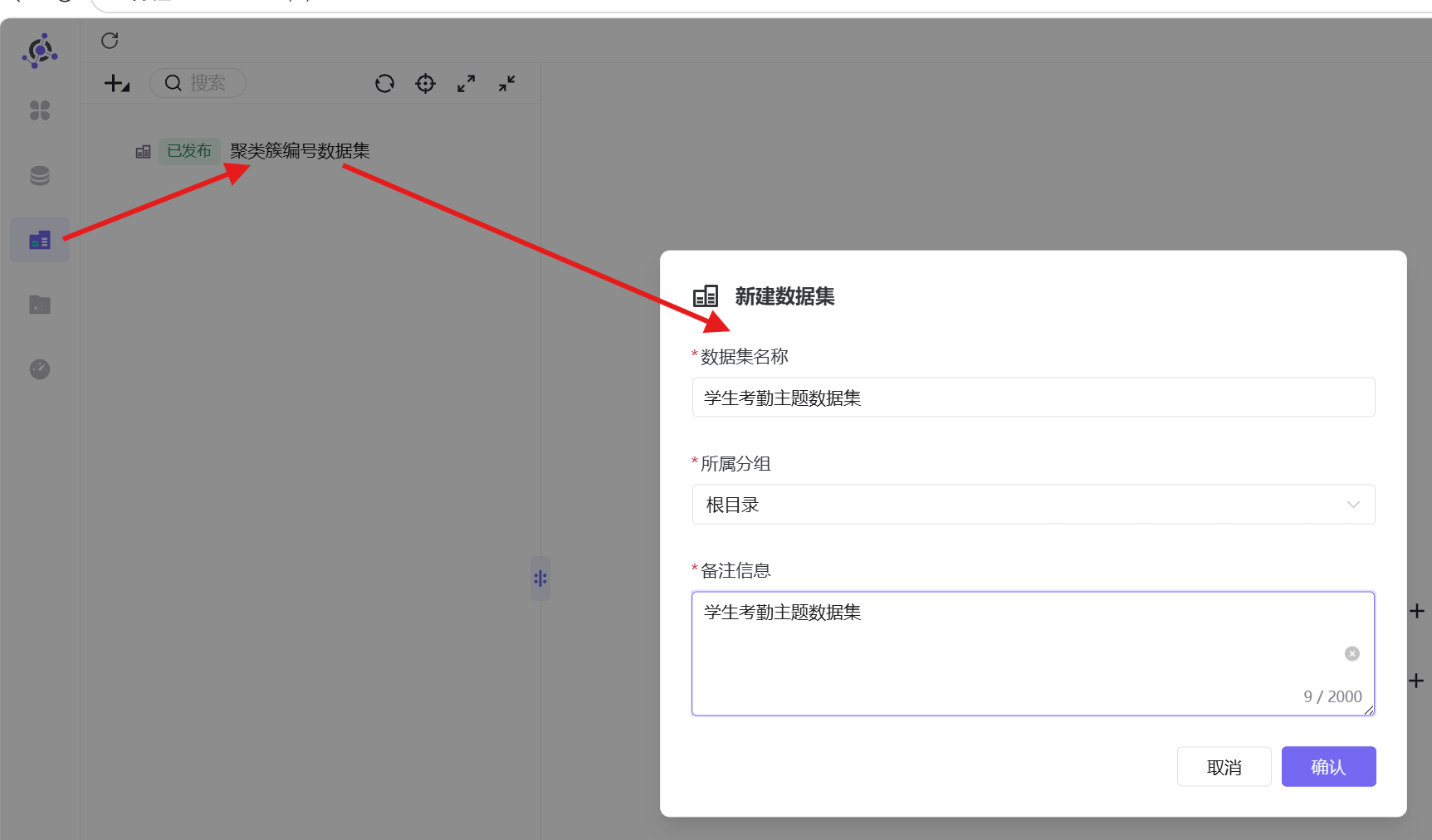
2. 关闭平台新手提醒,数据源选择「商业数据分析实验」,目录选择「自己的数据库名」;
3. 将student_attendance_stats数据表拖拽至画布编辑区,校验表结构与数据完整性;
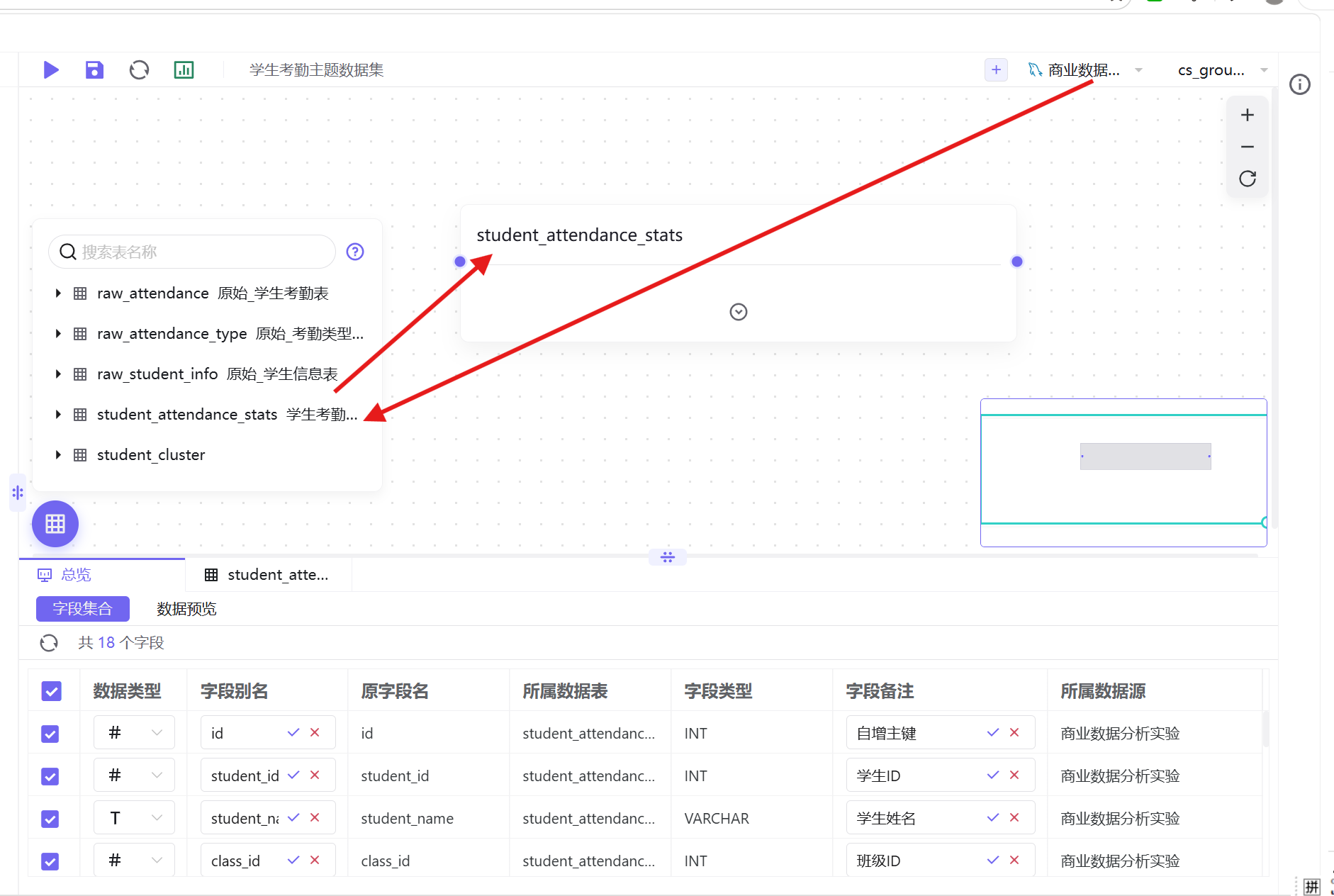
4. 数据表已内置完整中文字段备注,无需二次修改,直接点击「保存」-「保存并发布」,完成数据集发布。
3.4 制作可视化分析工作表
3.4.1 整体概况指标卡制作
通过指标卡组件直观展示纪律高危型学生整体规模及性别分布概况,快速把控群体整体特征。
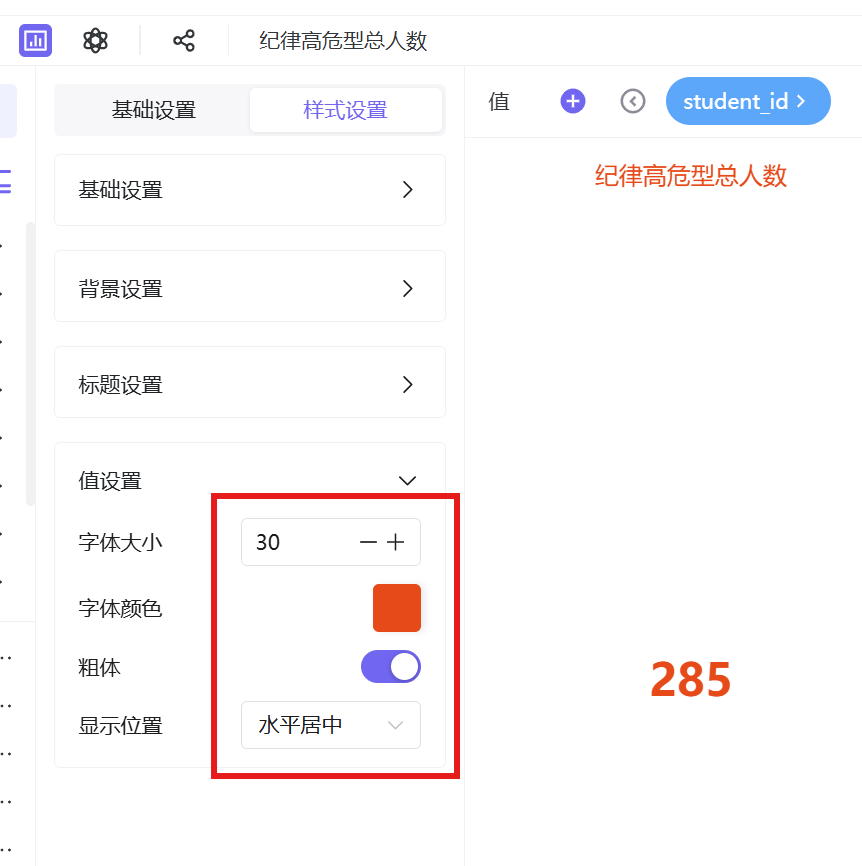
3.4.1.1 纪律高危型总人数
1. 新建专属工作表分组,在分组内新建工作表,命名为「纪律高危型人数」;
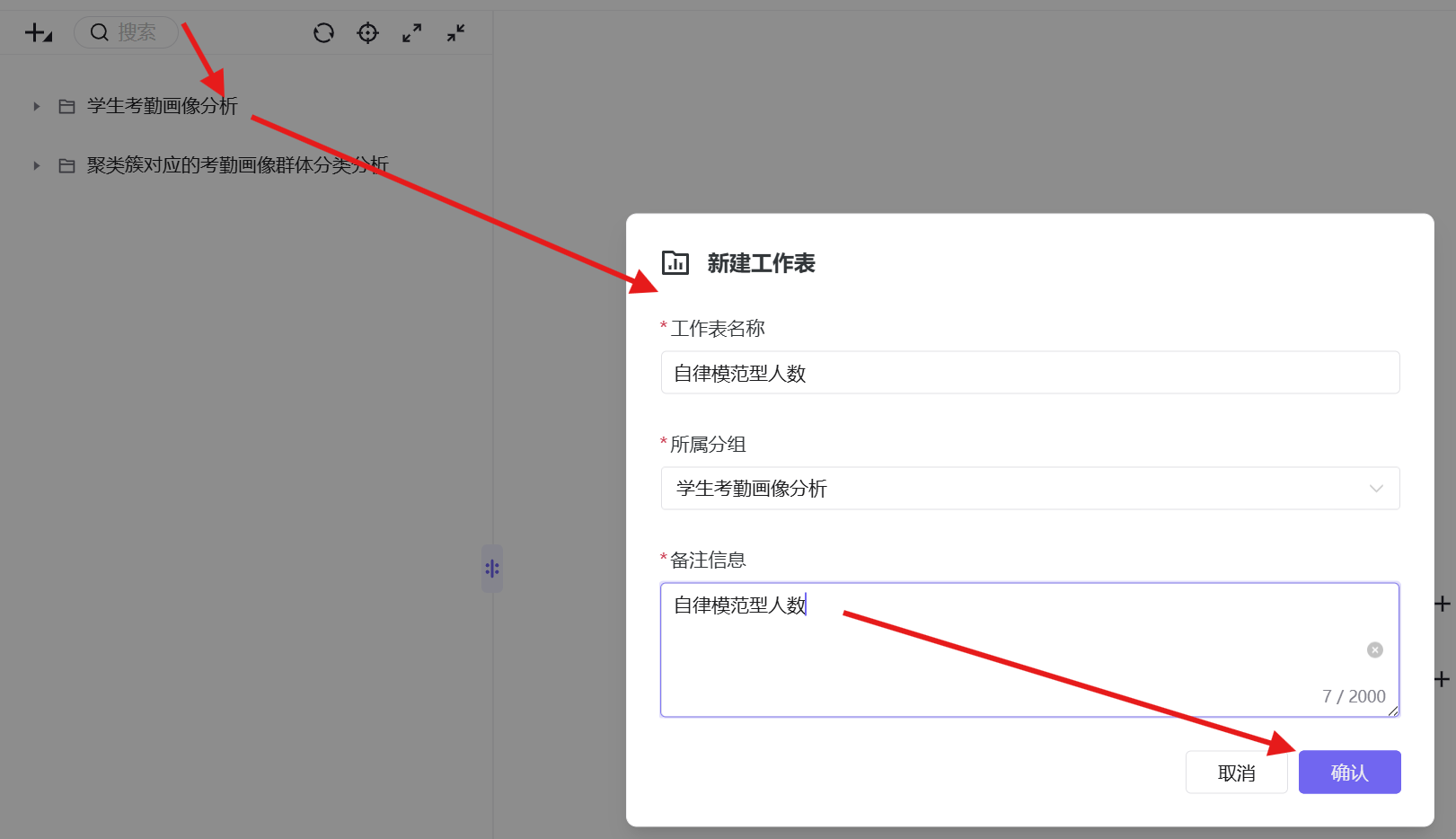
2. 数据集选择已发布的学生考勤主题数据集,图表类型选择「指标卡」;
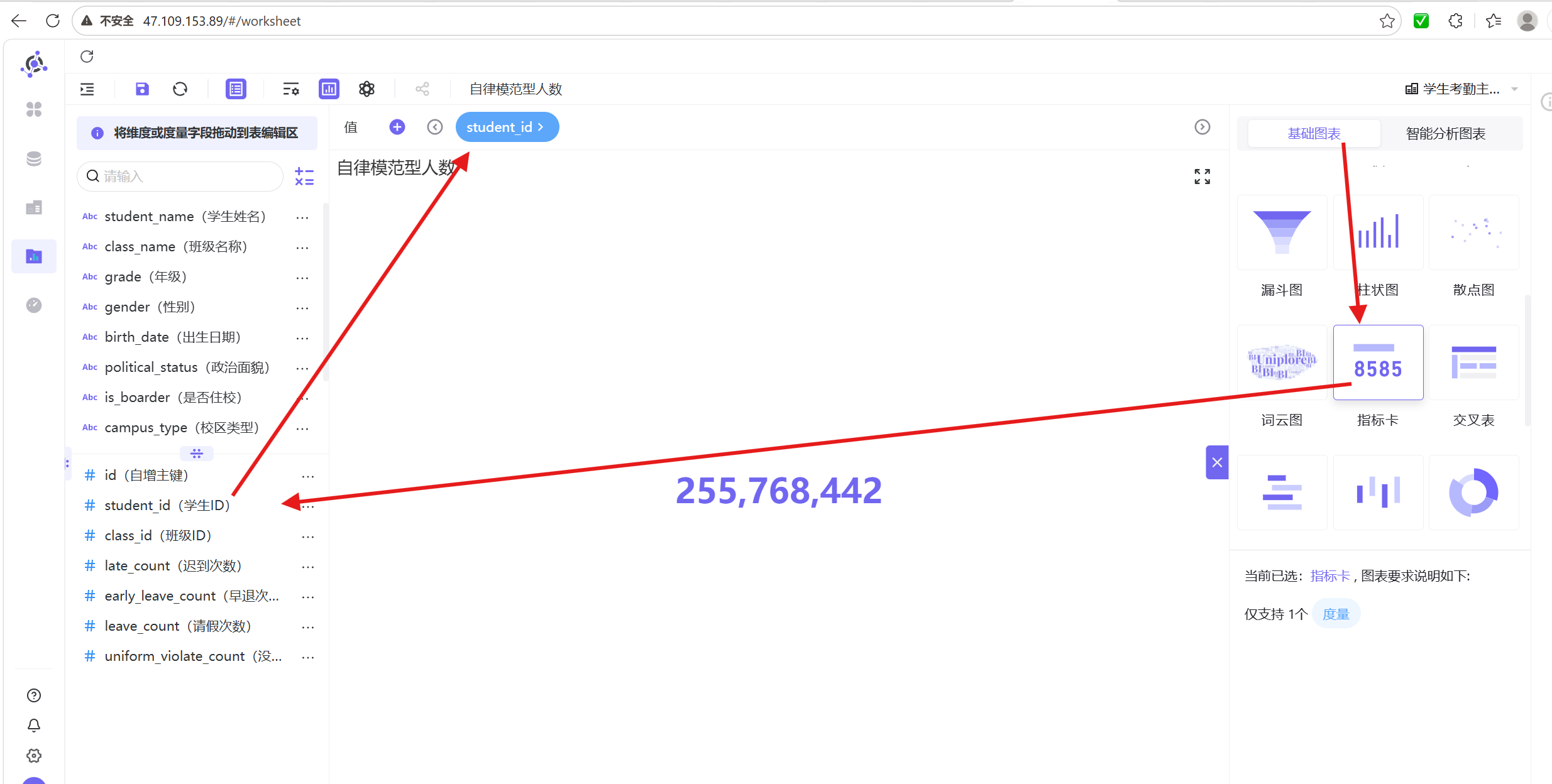
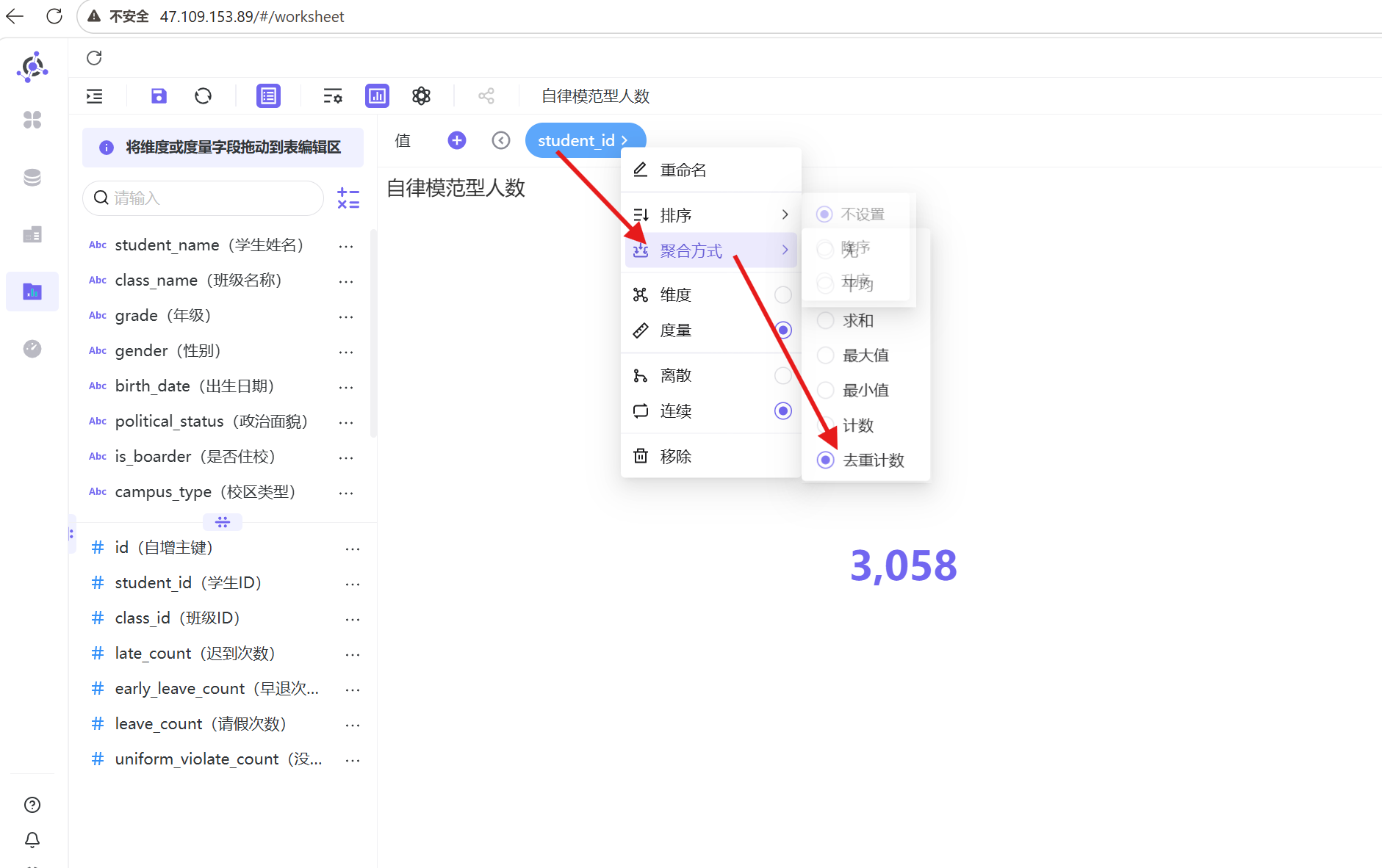
3. 将「学生ID」字段拖拽至值维度,修改聚合方式为「去重计数」,确保人数统计精准无重复;
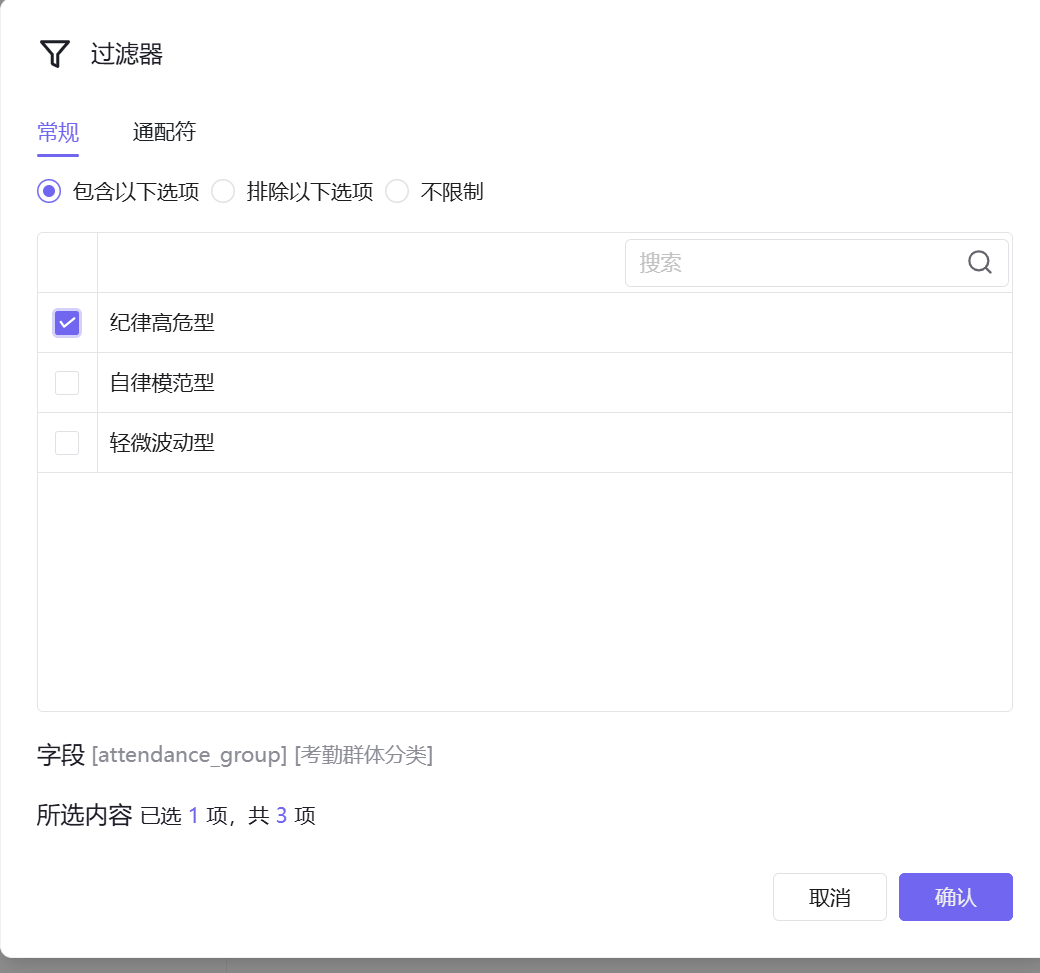
4. 添加过滤器,筛选规则设置为「考勤群体分类=纪律高危型」;
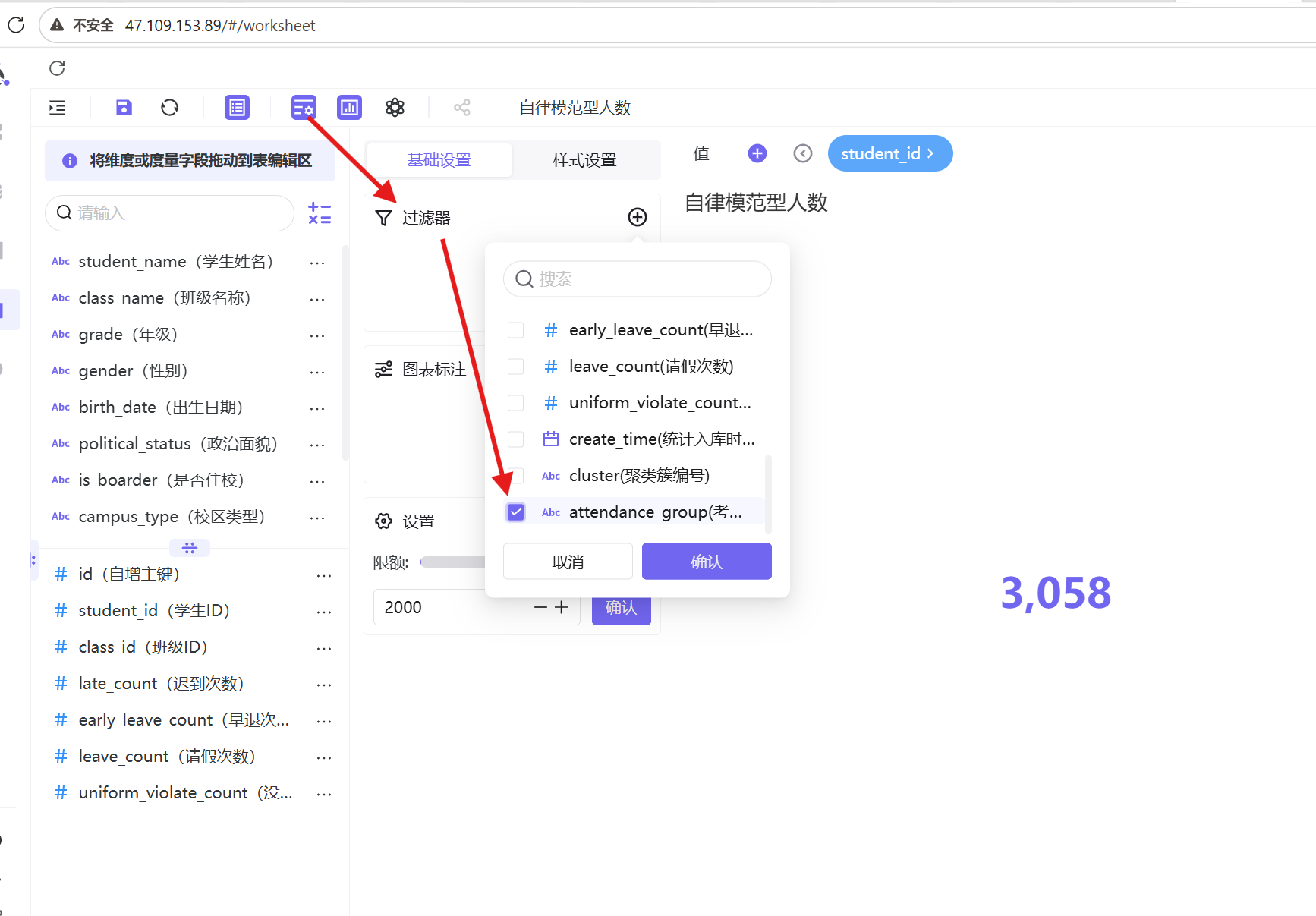
5. 样式优化:边距16,标题16号红色居中,数值30号红色加粗居中;
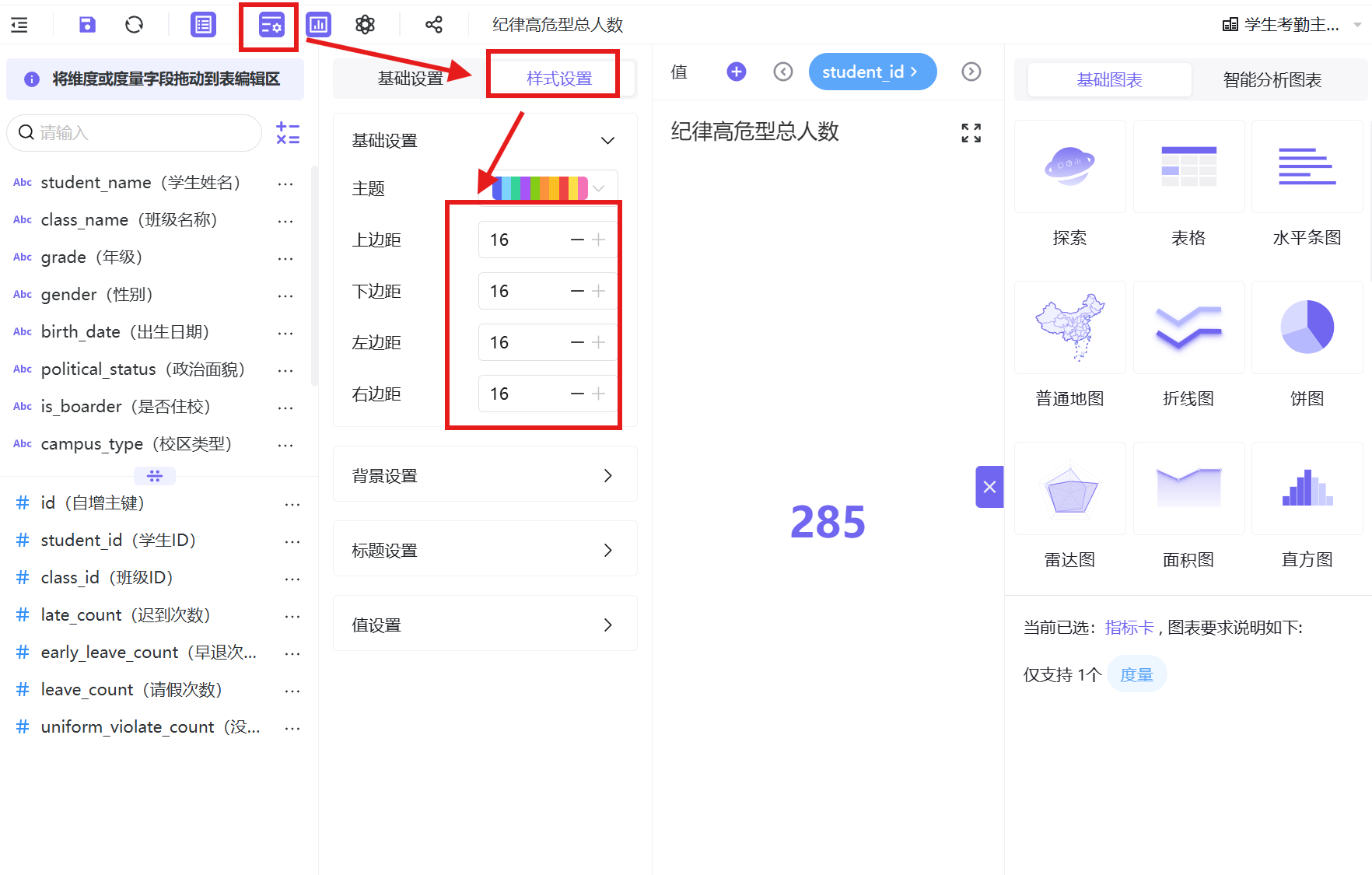
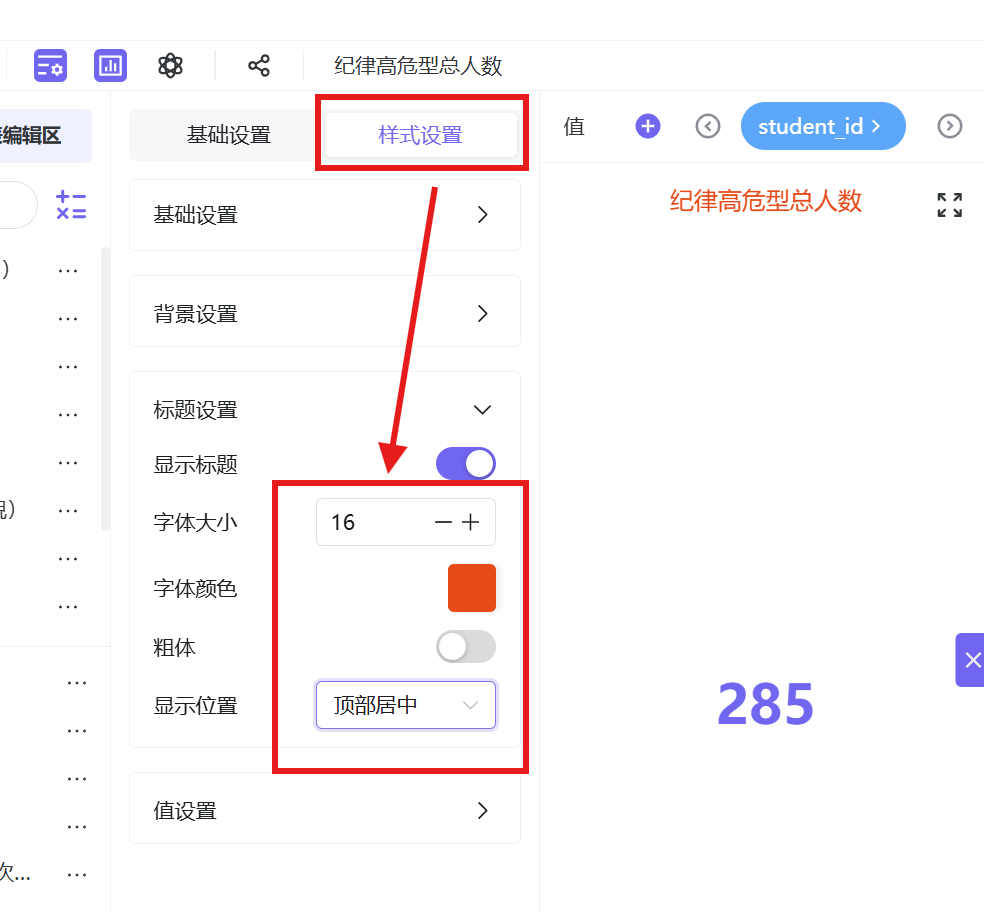
6. 保存并发布工作表,完成高危总人数指标卡制作。
3.4.1.2 纪律高危型男/女/未知性别人数
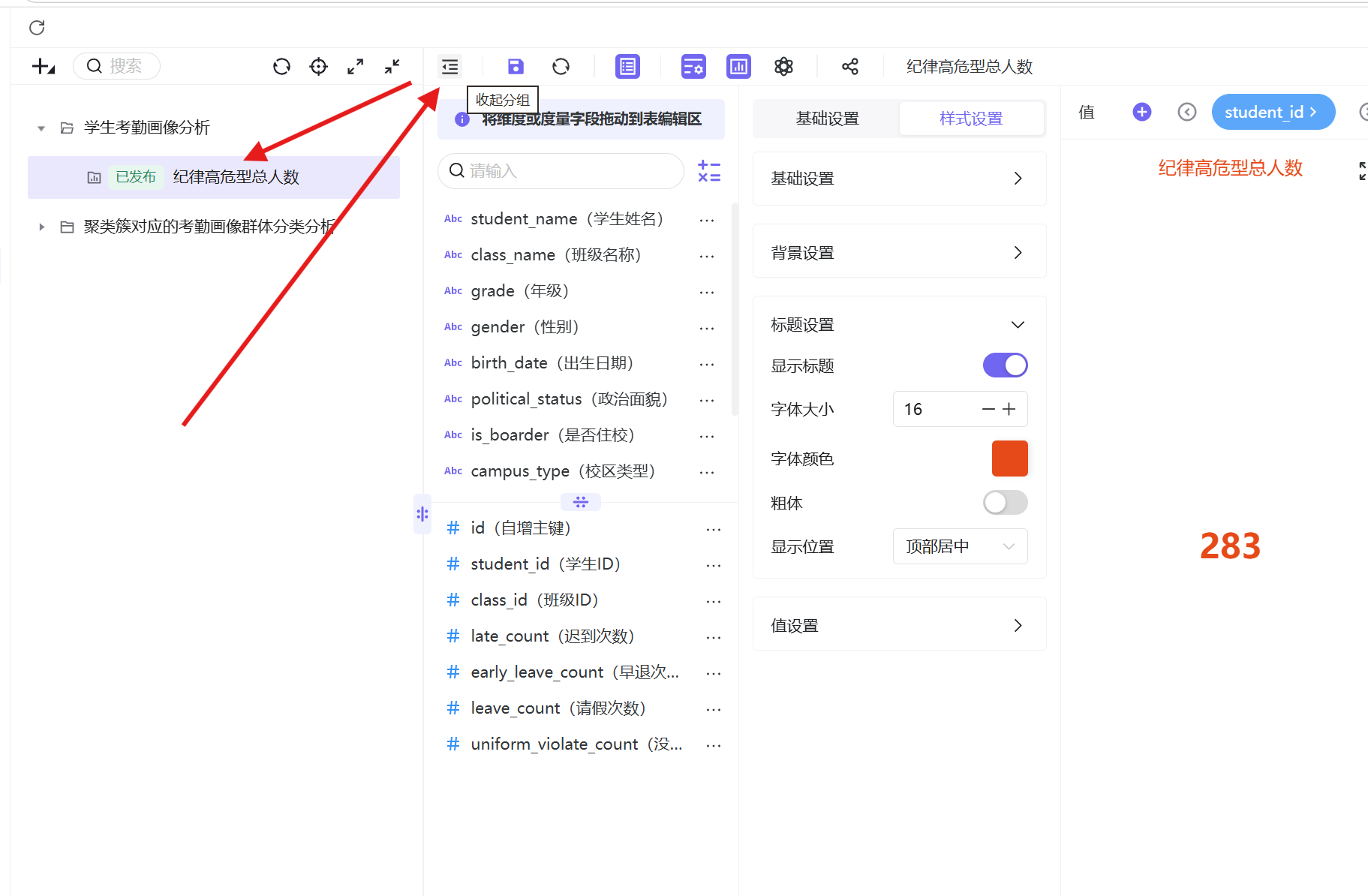
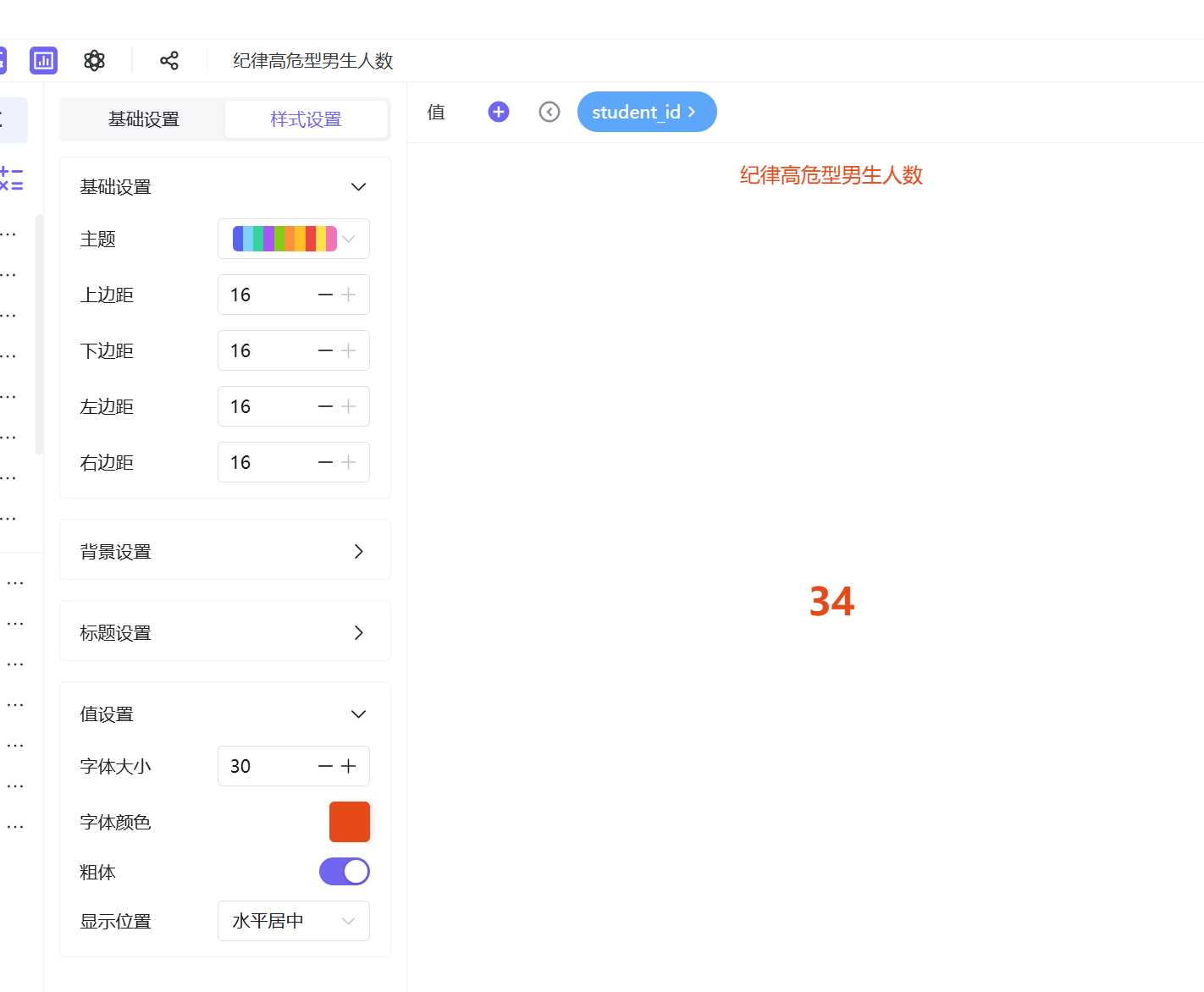
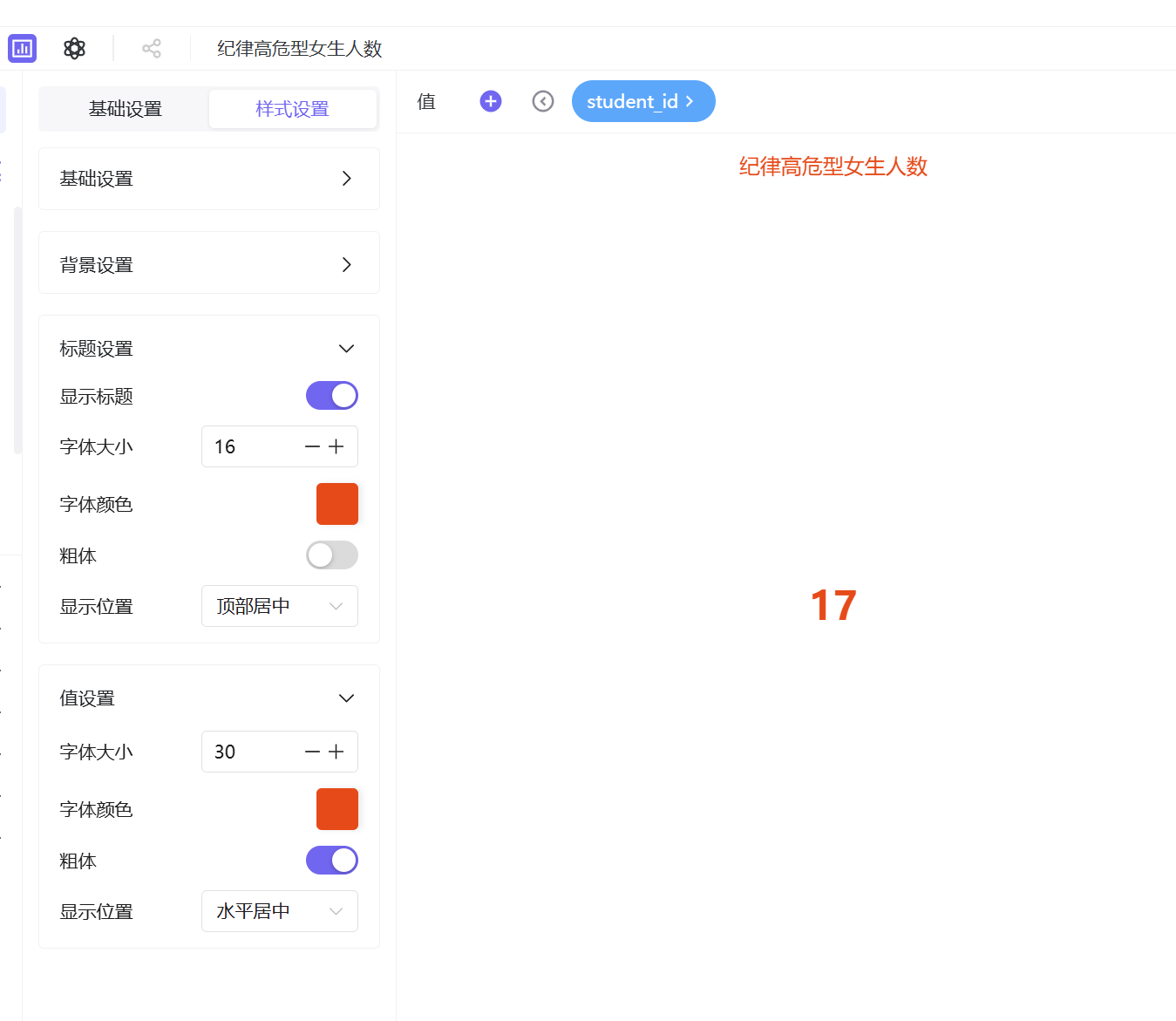
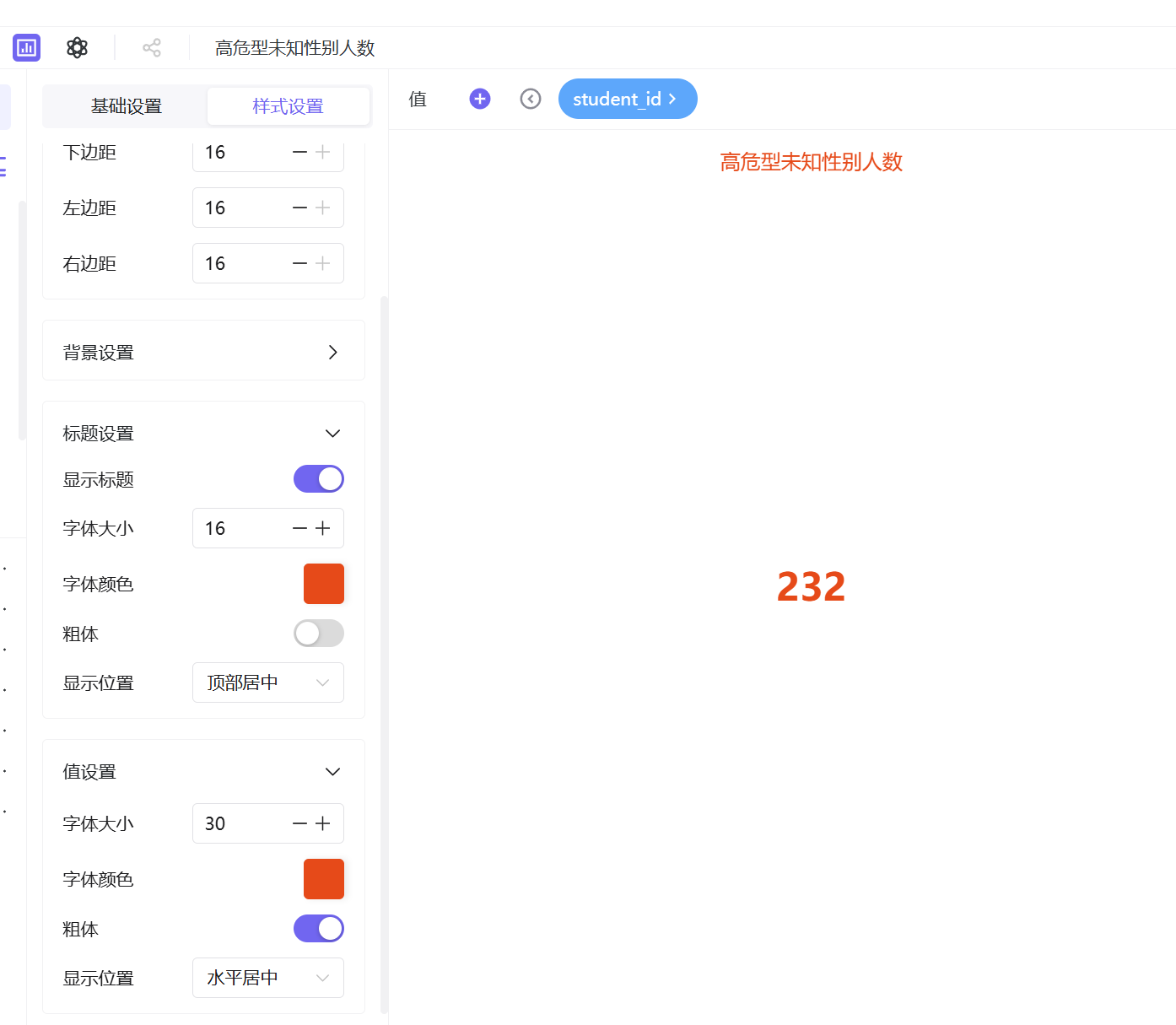
参考高危总人数制作步骤,分别新建「纪律高危型男生人数」「纪律高危型女生人数」「高危型未知性别人数」三张工作表,在高危群体筛选基础上,新增对应性别字段筛选,统一优化样式后保存发布。
3.4.1.3 整体指标分析
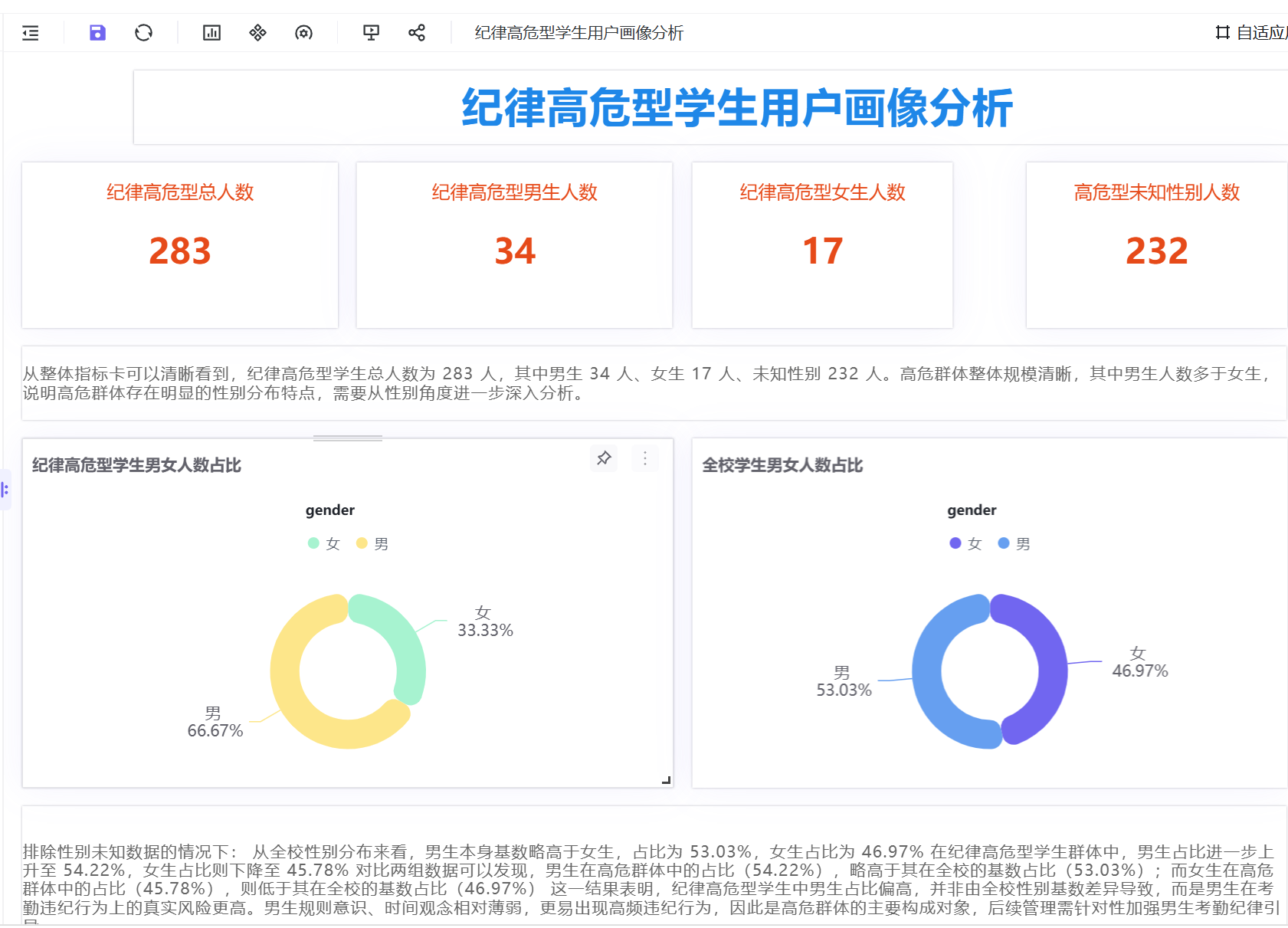
指标卡数据统计结果:纪律高危型学生总人数为283人,其中男生34人、女生17人、未知性别232人。高危群体整体规模可控,但性别分布差异显著,男生高危人数明显多于女生,存在突出的性别分布特征,需进一步深度分析。
3.4.2 纪律高危型学生性别特征分析
通过双层饼图对比高危群体与全校学生性别占比,排除基数干扰,精准判断性别与考勤高危行为的关联性。
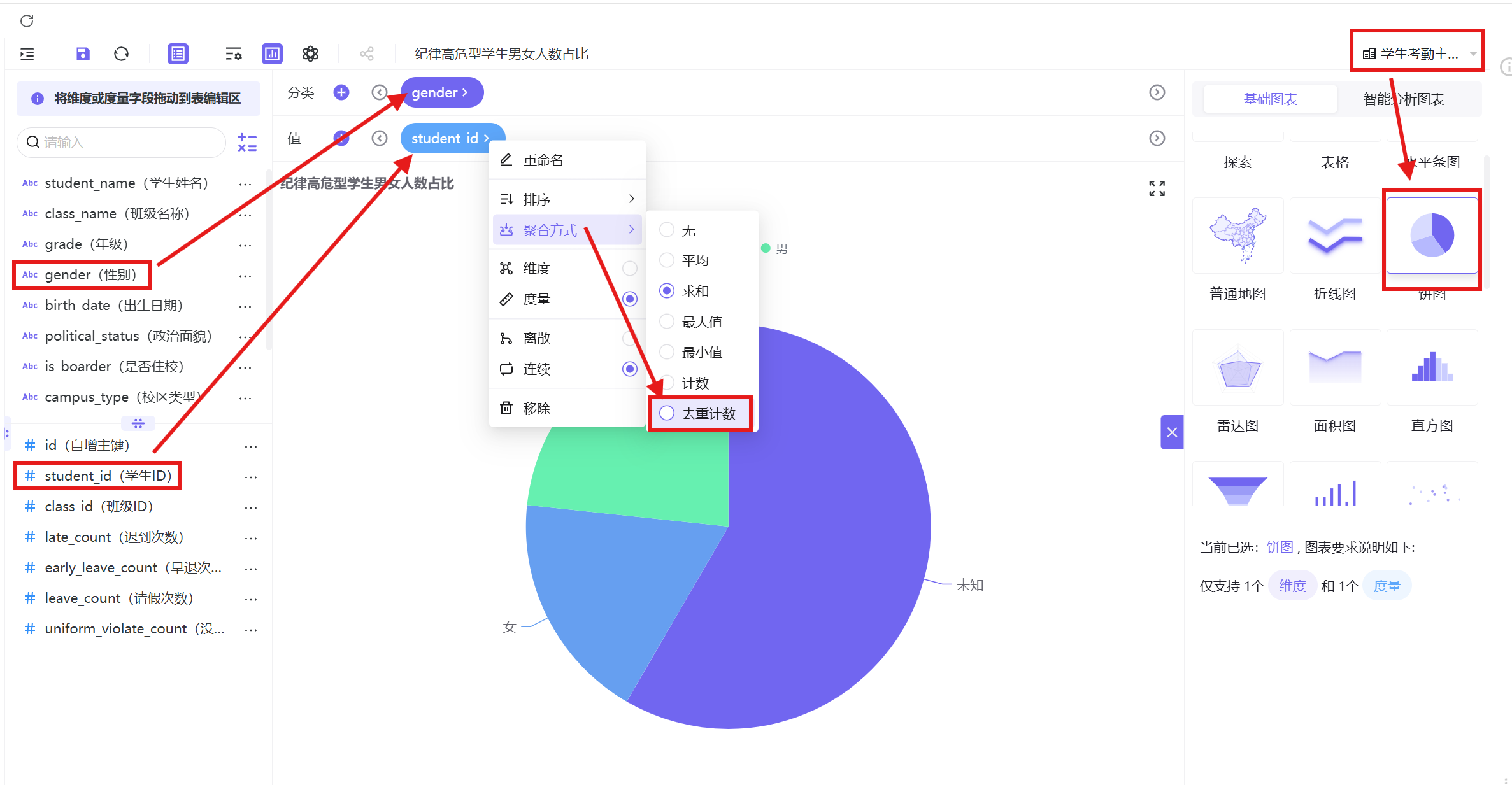
3.4.2.1 纪律高危型学生男女人数占比
1. 新建工作表「纪律高危型学生男女人数占比」,图表类型选择饼图;
2. 字段配置:值维度为学生ID(去重计数),分类维度为性别;
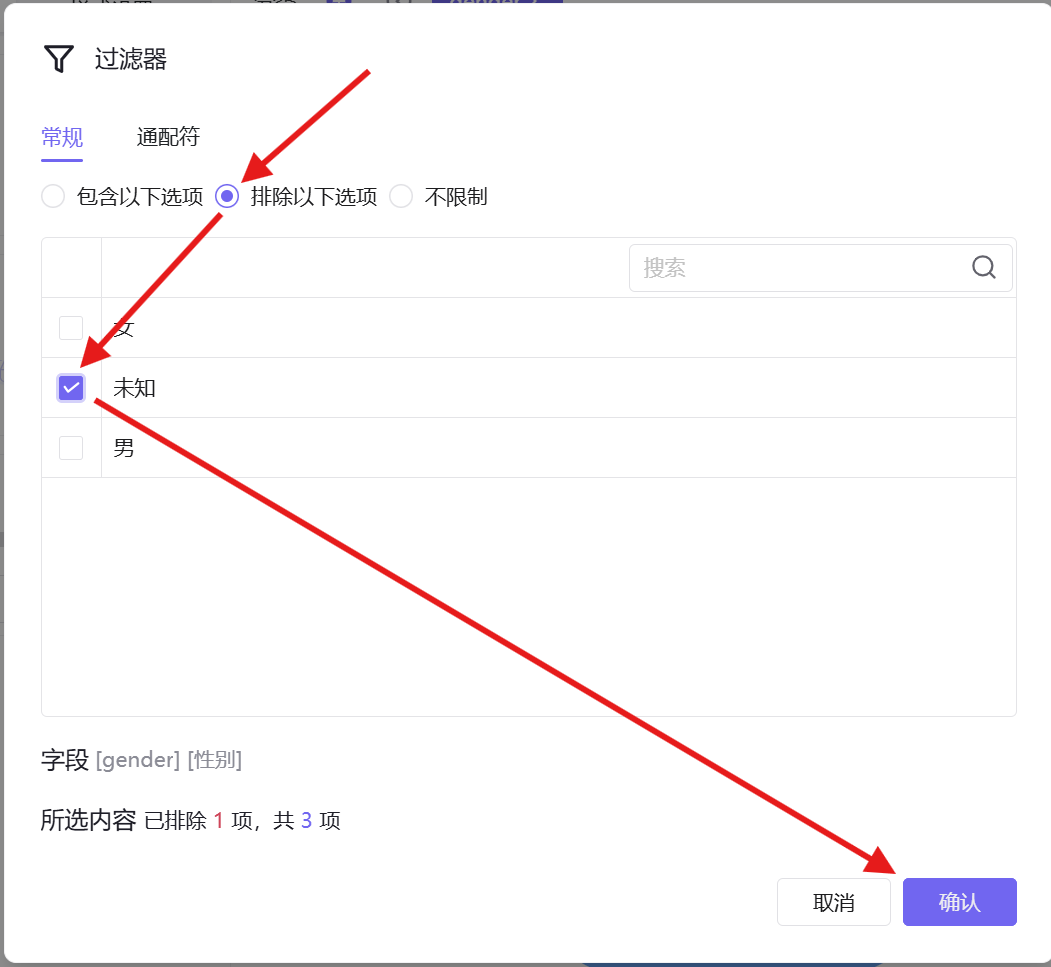
3. 过滤器配置:排除性别「未知」数据,仅保留男女样本,同时筛选考勤群体为纪律高危型;
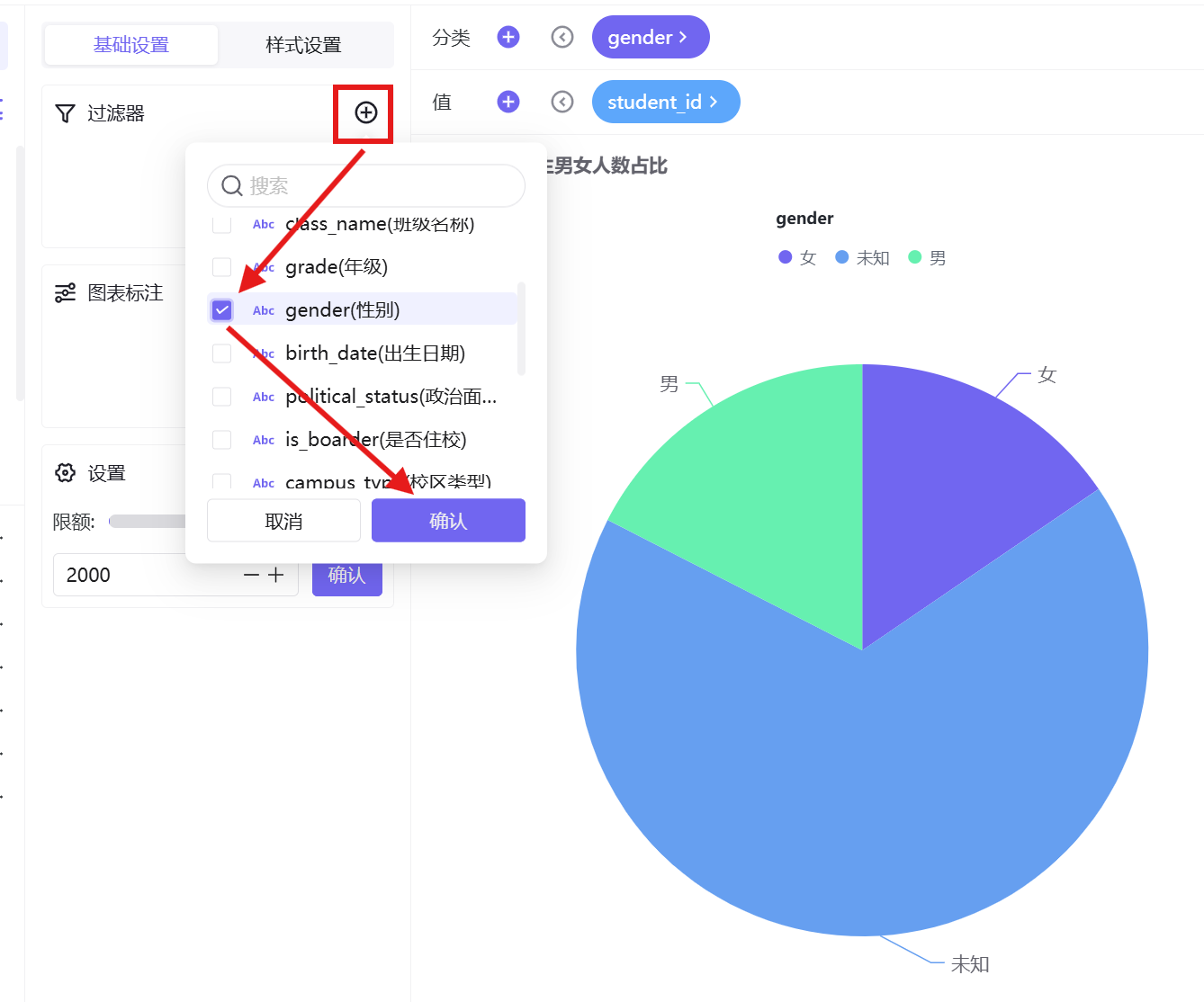
4. 样式优化:开启百分比标签显示,内环大小50%、扇形圆角半径10,自定义高对比主题色;
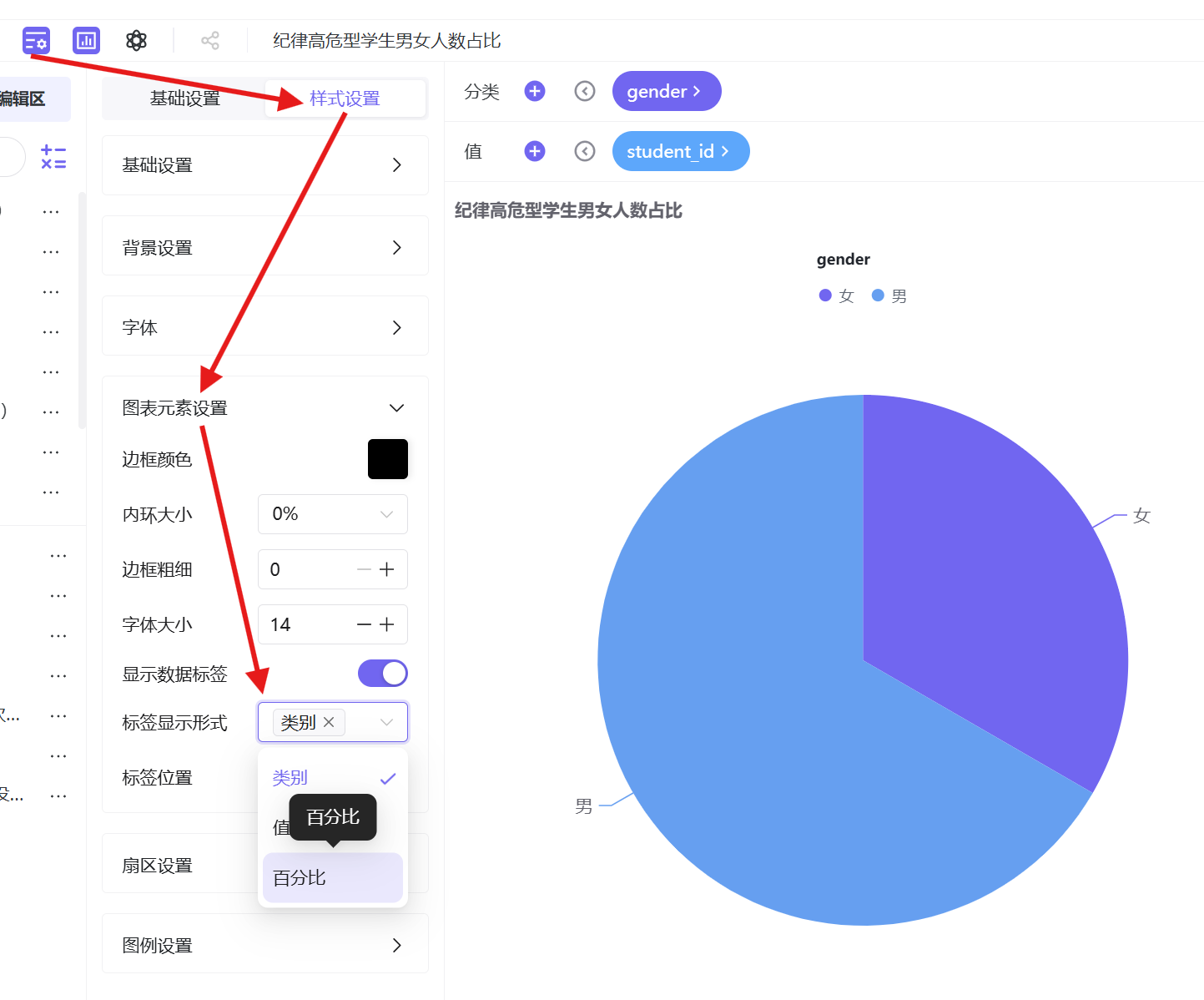
5. 保存并发布工作表。
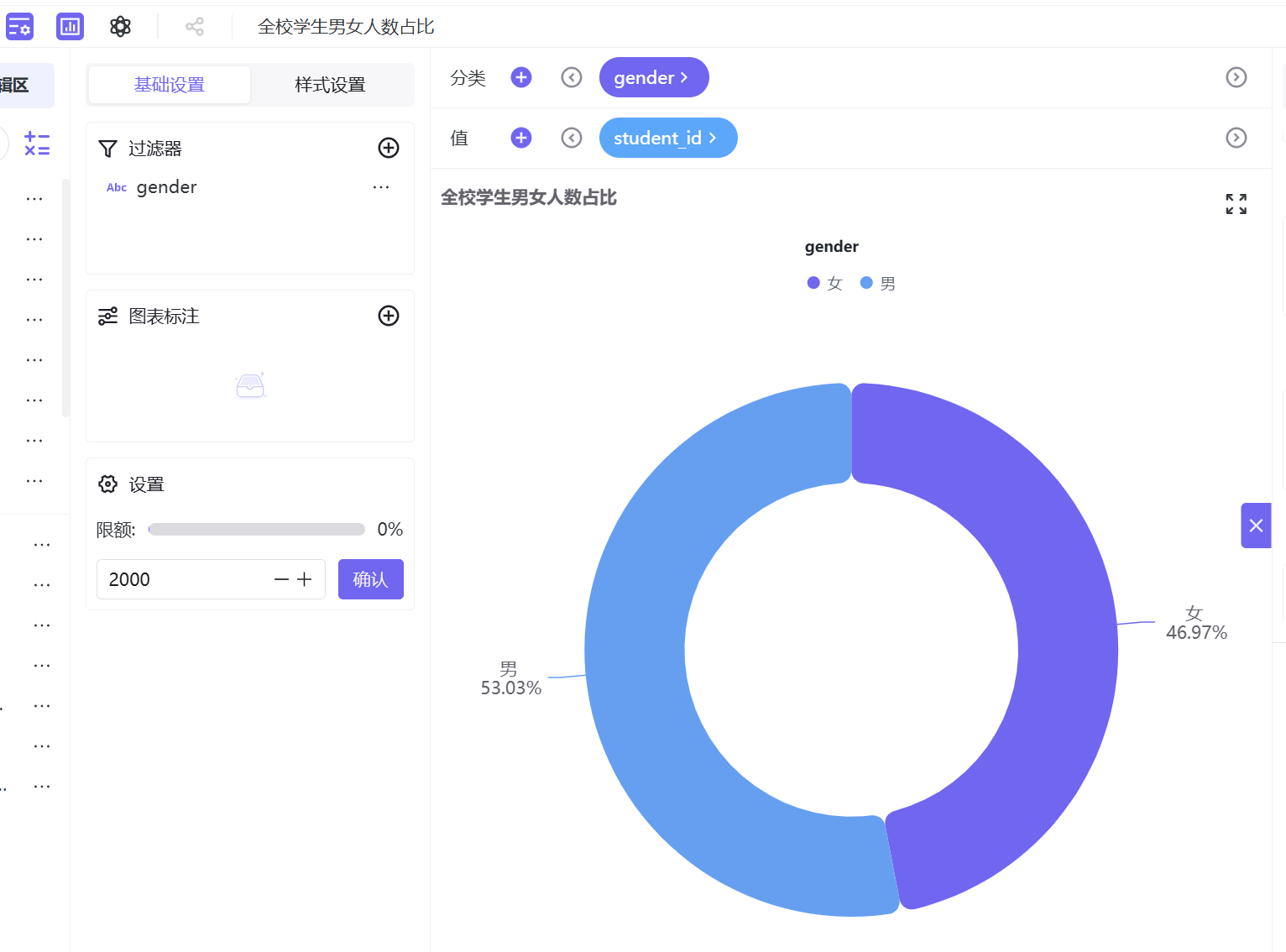
3.4.2.2 全校学生男女人数占比
新建工作表「全校学生男女人数占比」,制作逻辑与高危群体性别占比饼图一致,仅过滤未知性别数据,不筛选考勤群体,作为全校基数对比参考。
3.4.2.3 性别特征分析结论
排除未知性别样本后,全校学生性别分布:男生占比53.03%、女生占比46.97%;纪律高危型群体性别分布:男生占比54.22%、女生占比45.78%。
数据对比可见,男生在高危群体中的占比高于全校基数占比,女生则低于全校基数占比。该差异并非由全校性别基数导致,而是真实行为差异,说明男生规则意识、时间观念相对薄弱,更易出现考勤违纪行为,是高危群体的核心构成对象。
3.4.3 纪律高危型学生年级特征分析
通过柱状图分析高危学生年级分布规律,定位考勤高危行为高发年级:
1. 新建工作表「纪律高危型学生年级特征分析」,图表类型选择柱状图;
2. 字段配置:X轴为年级,Y轴为学生ID(去重计数);
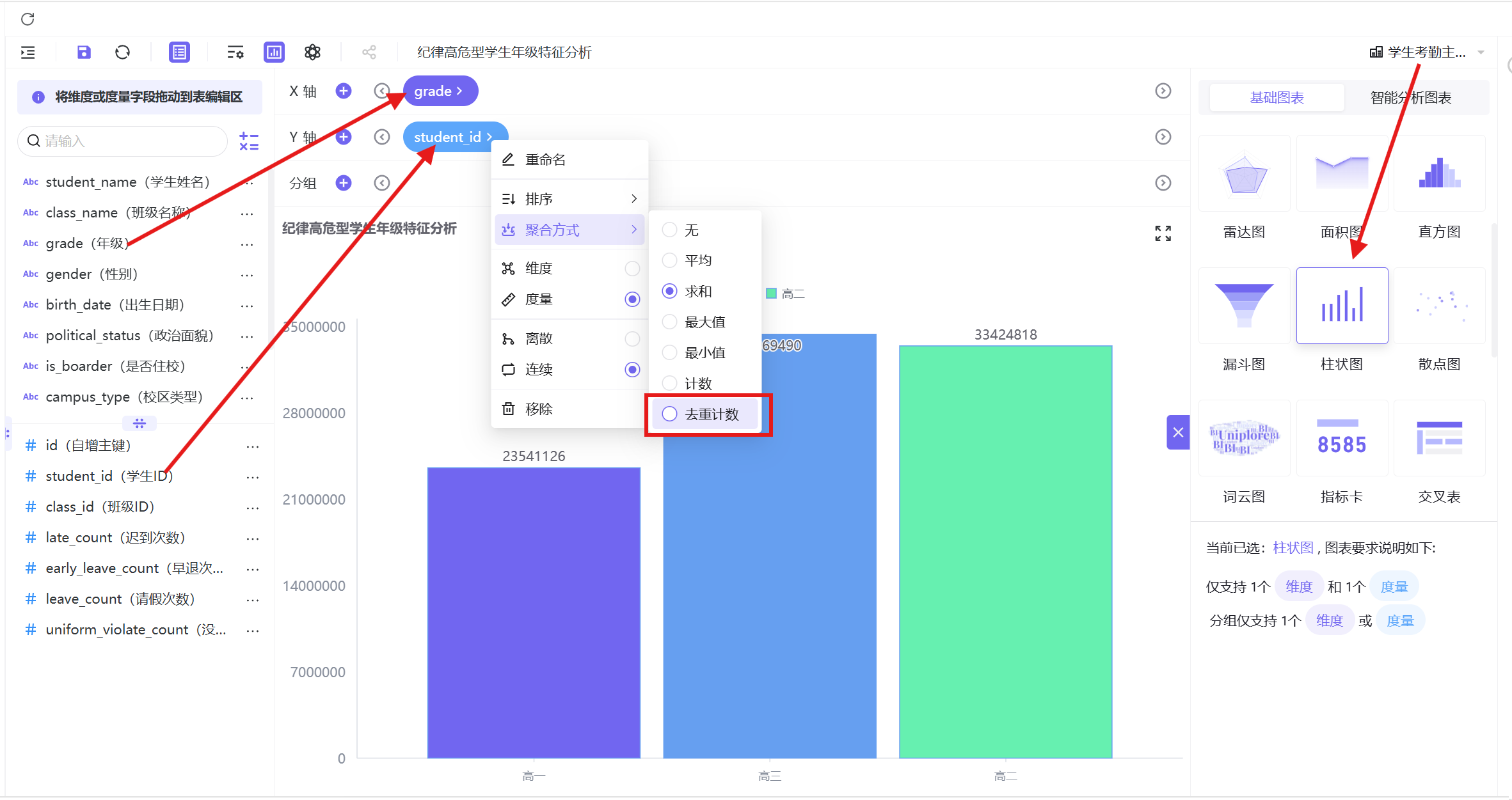
3. 过滤器筛选「考勤群体分类=纪律高危型」;
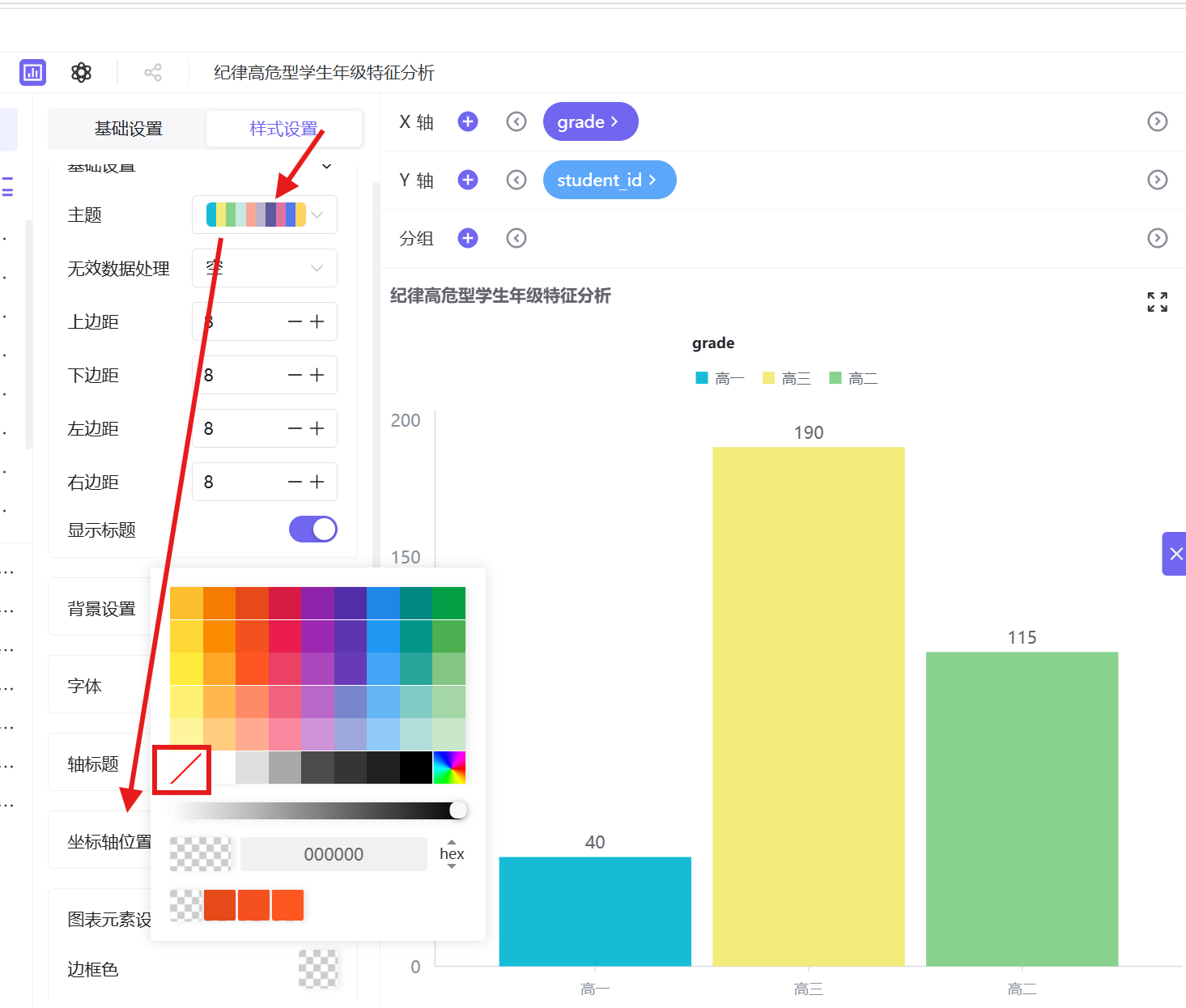
4. 统一图表主题色、取消边框,优化视觉效果后保存发布。
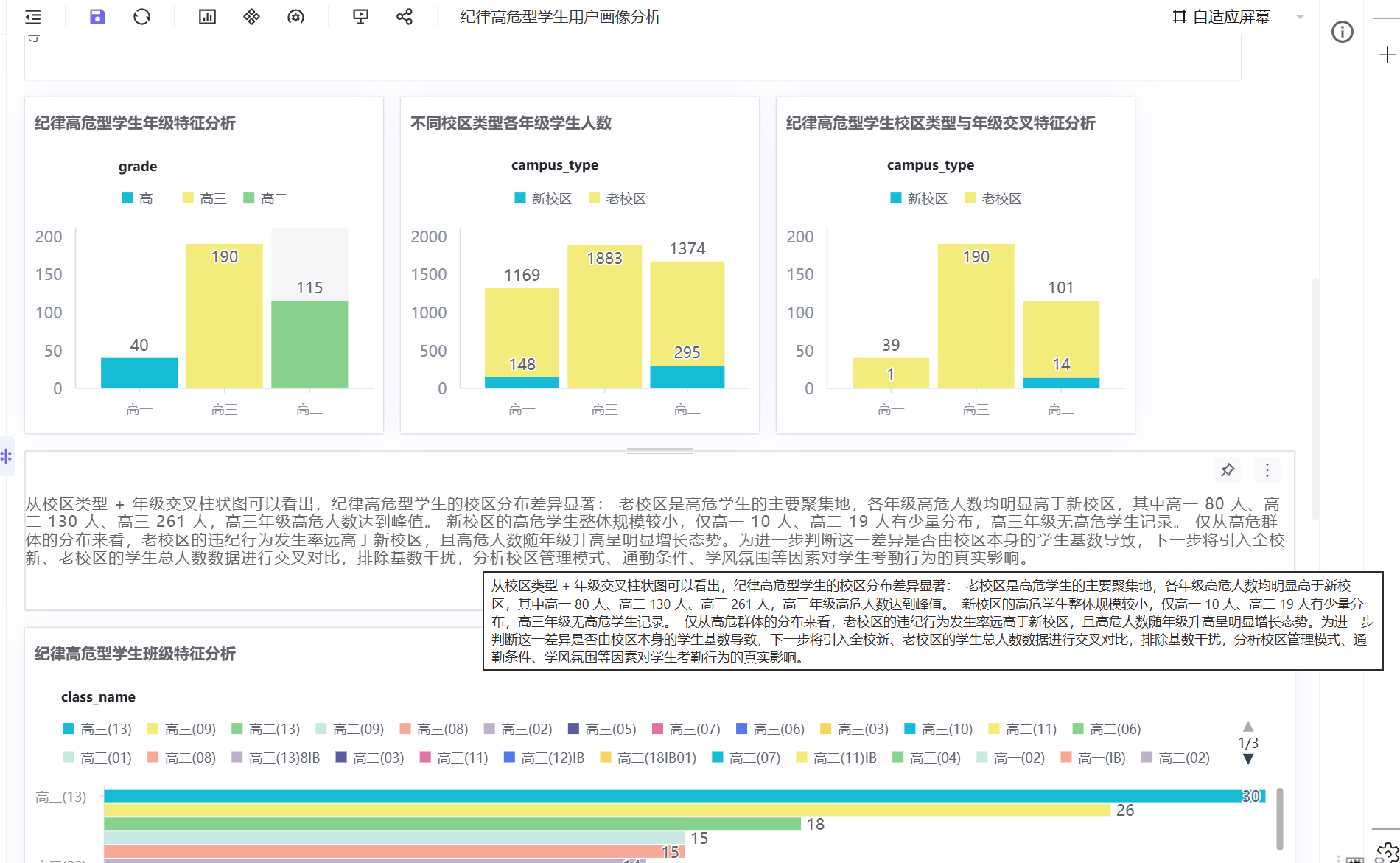
分析结论:纪律高危型学生年级分布差异显著,高三年级高危人数最多,高一、高二年级人数相对较少。核心原因为高三学生升学备考压力大、在校自主空间广、课程安排灵活,对考勤纪律重视度降低,导致考勤异常行为频发。
3.4.4 纪律高危型学生校区+年级交叉特征分析
通过交叉柱状图,挖掘不同校区、不同年级高危学生的分布差异,精准定位高危高发区域:
1. 新建工作表「纪律高危型学生校区类型与年级交叉特征分析」,在年级柱状图基础上,新增「校区类型」为分组维度;
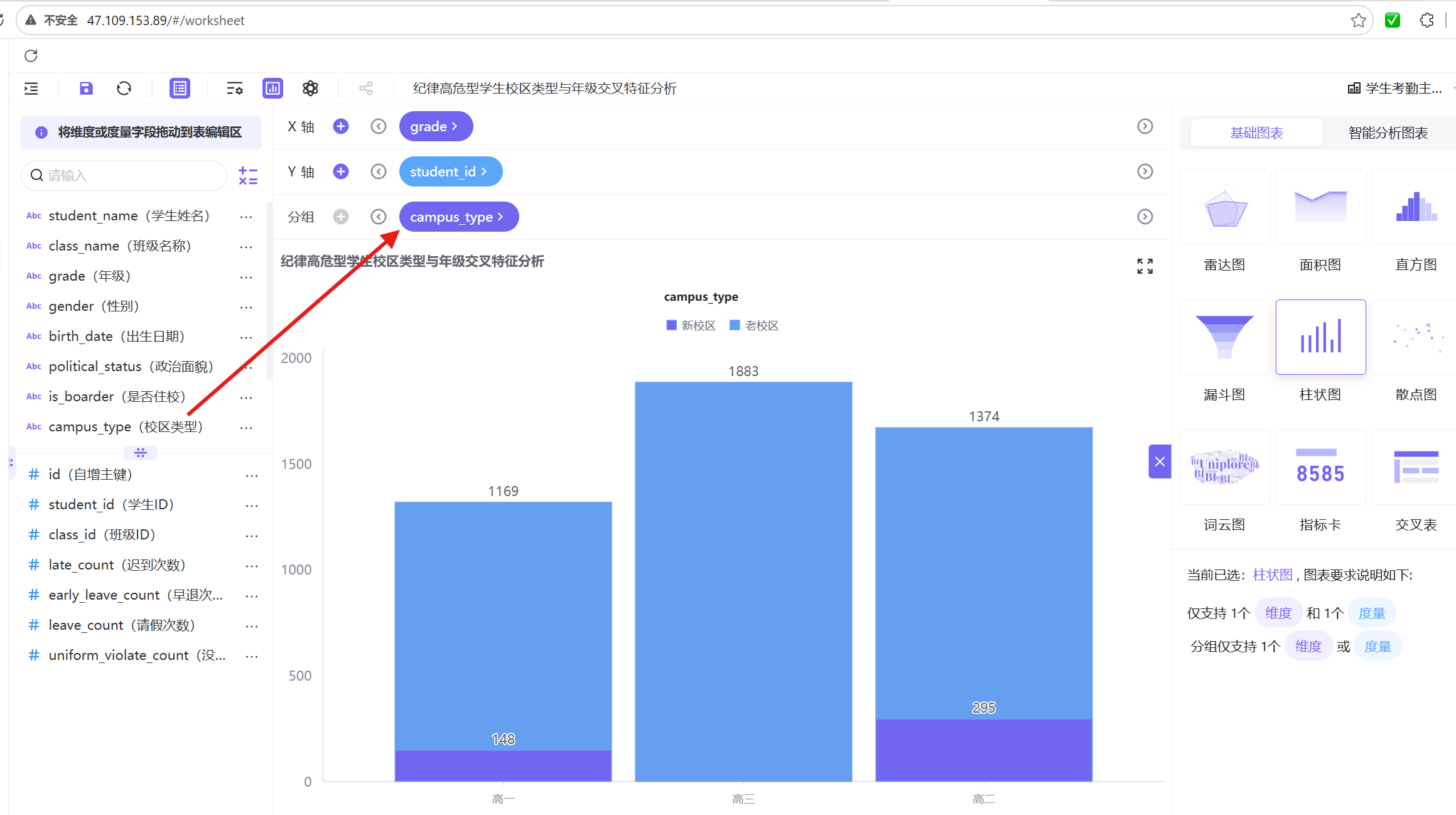
2. 筛选纪律高危型群体,统一图表样式后保存发布。
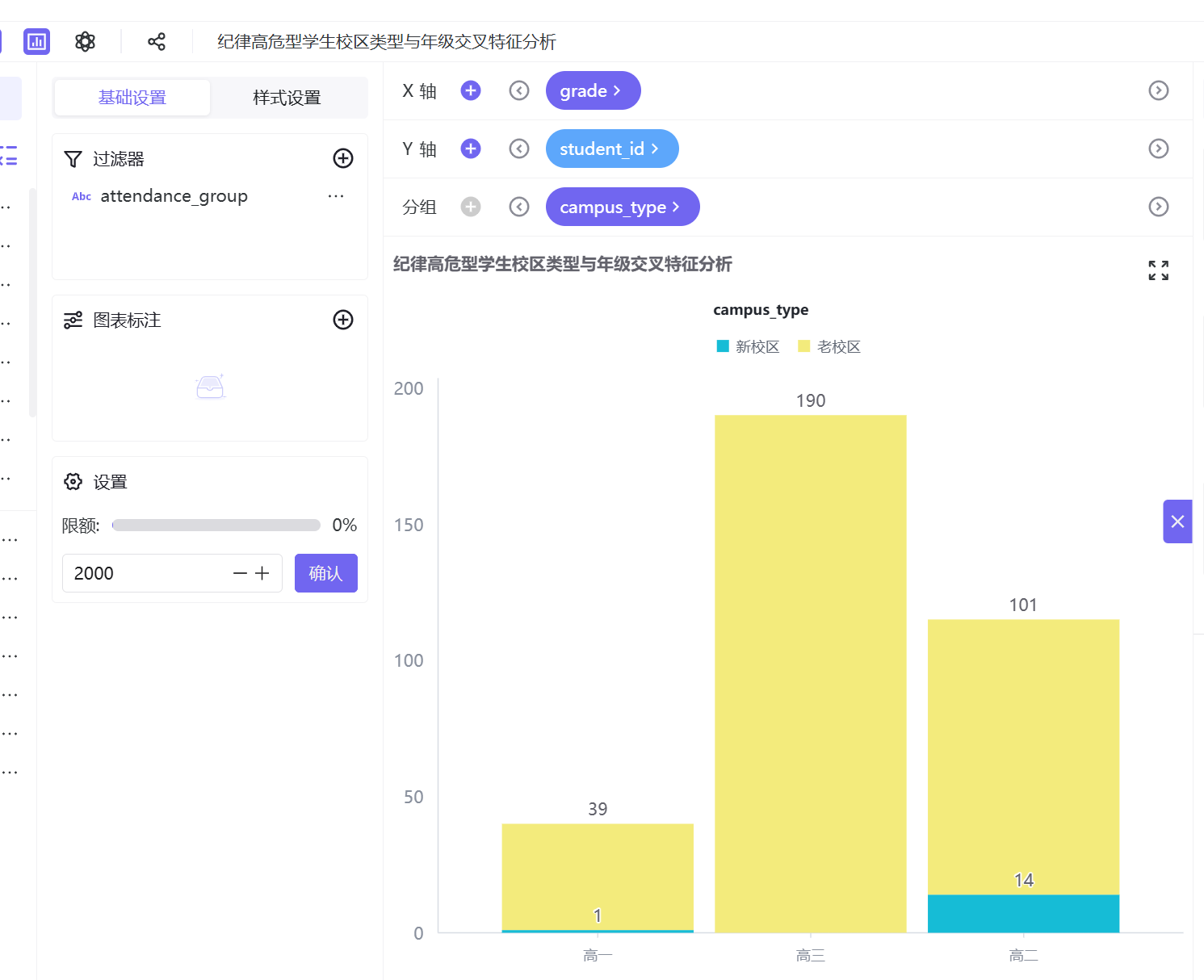
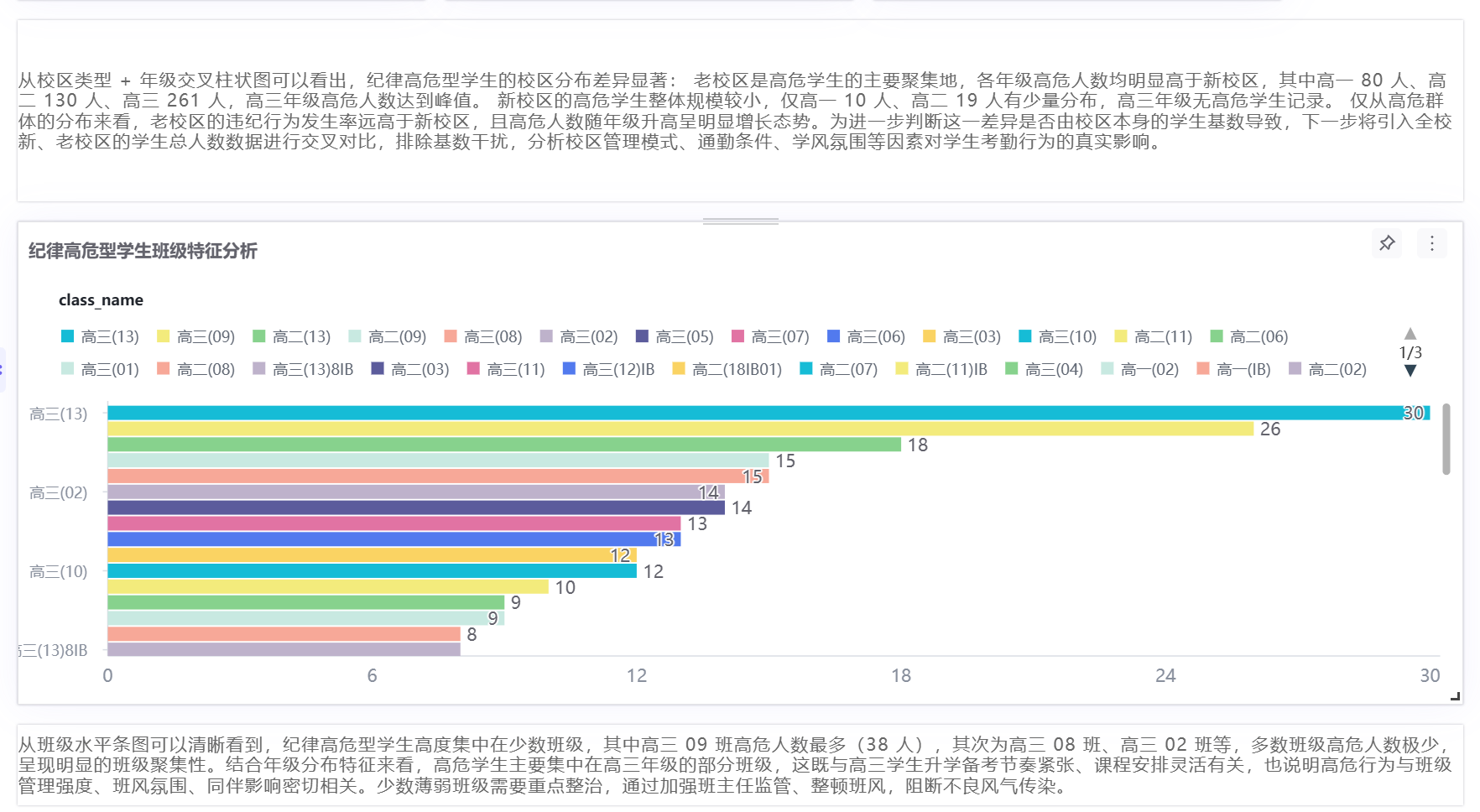
分析结论:老校区为高危学生主要聚集地,各年级高危人数均远超新校区,具体分布为高一80人、高二130人、高三261人,高三年级达到峰值;新校区高危人数极少,仅高一10人、高二19人,高三无高危学生记录。整体来看,老校区考勤违纪风险远高于新校区。
3.4.5 全校校区年级基数对比分析
新建工作表「不同校区类型各年级学生人数」,制作无筛选条件的校区-年级分布柱状图,用于基数校验,排除学生基数对分析结果的干扰。
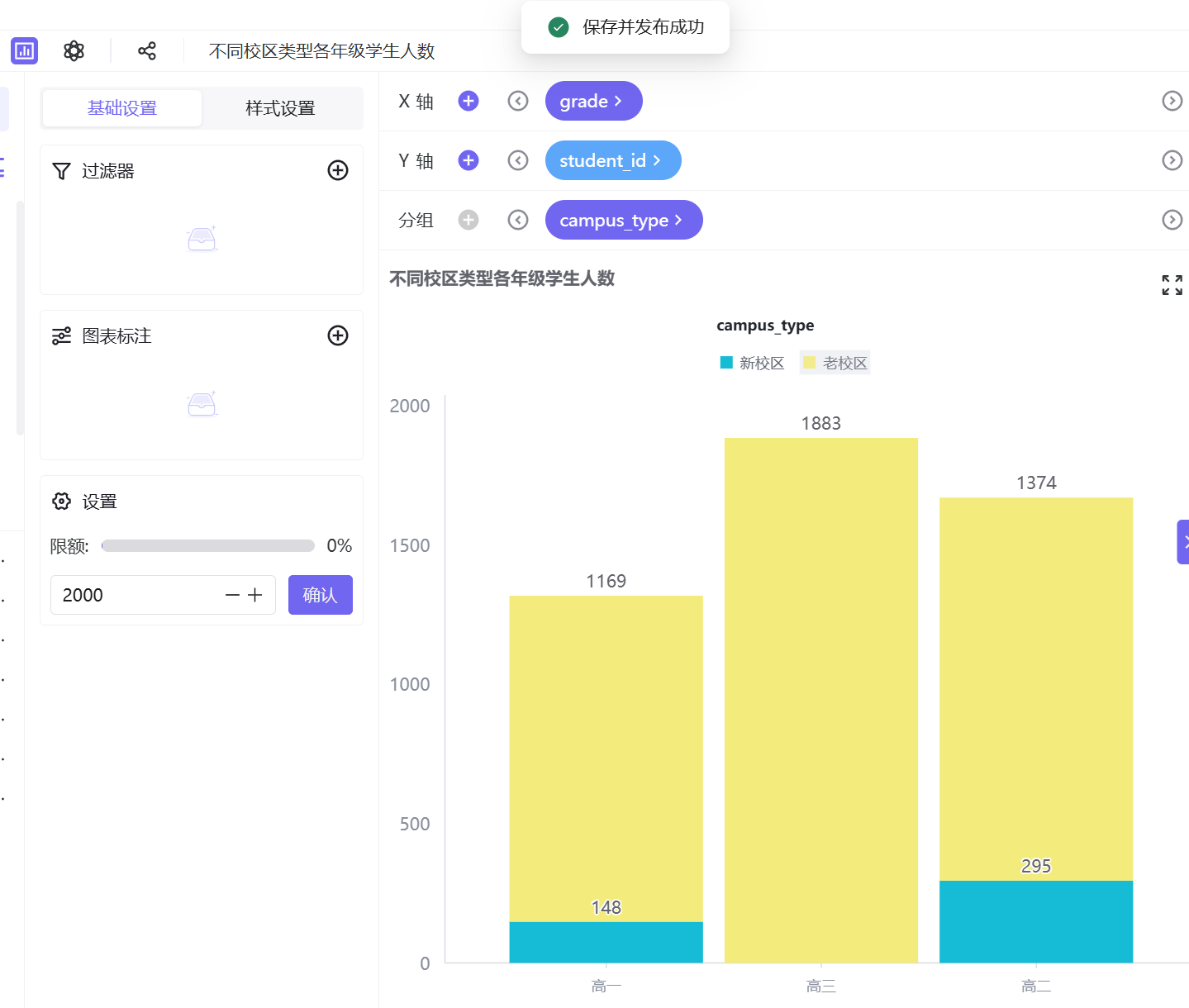
分析结论:全校数据显示,老校区高一1021人、高二1079人、高三1883人,新校区高一148人、高二295人、高三无学生。结合高危分布可知,高三老校区是绝对高危高发区,新校区整体学风、管理效果更优,违纪风险可控,校区管理模式、通勤条件、学风氛围是造成两类校区违纪差异的核心因素。
3.4.6 纪律高危型学生班级特征分析
通过水平条形图分析高危学生班级分布,定位高危学生集中的薄弱班级,完整操作步骤如下:
- 新建工作表「纪律高危型学生班级特征分析」,数据集选择已发布的学生考勤主题数据集,图表类型选择「水平条图」;
- 字段配置:Y 轴拖拽「班级名称(class_name)」字段,X 轴拖拽「学生 ID(student_id)」字段,将「学生 ID」的聚合方式设置为「去重计数」,确保统计的是每个班级的高危学生人数,无重复统计;
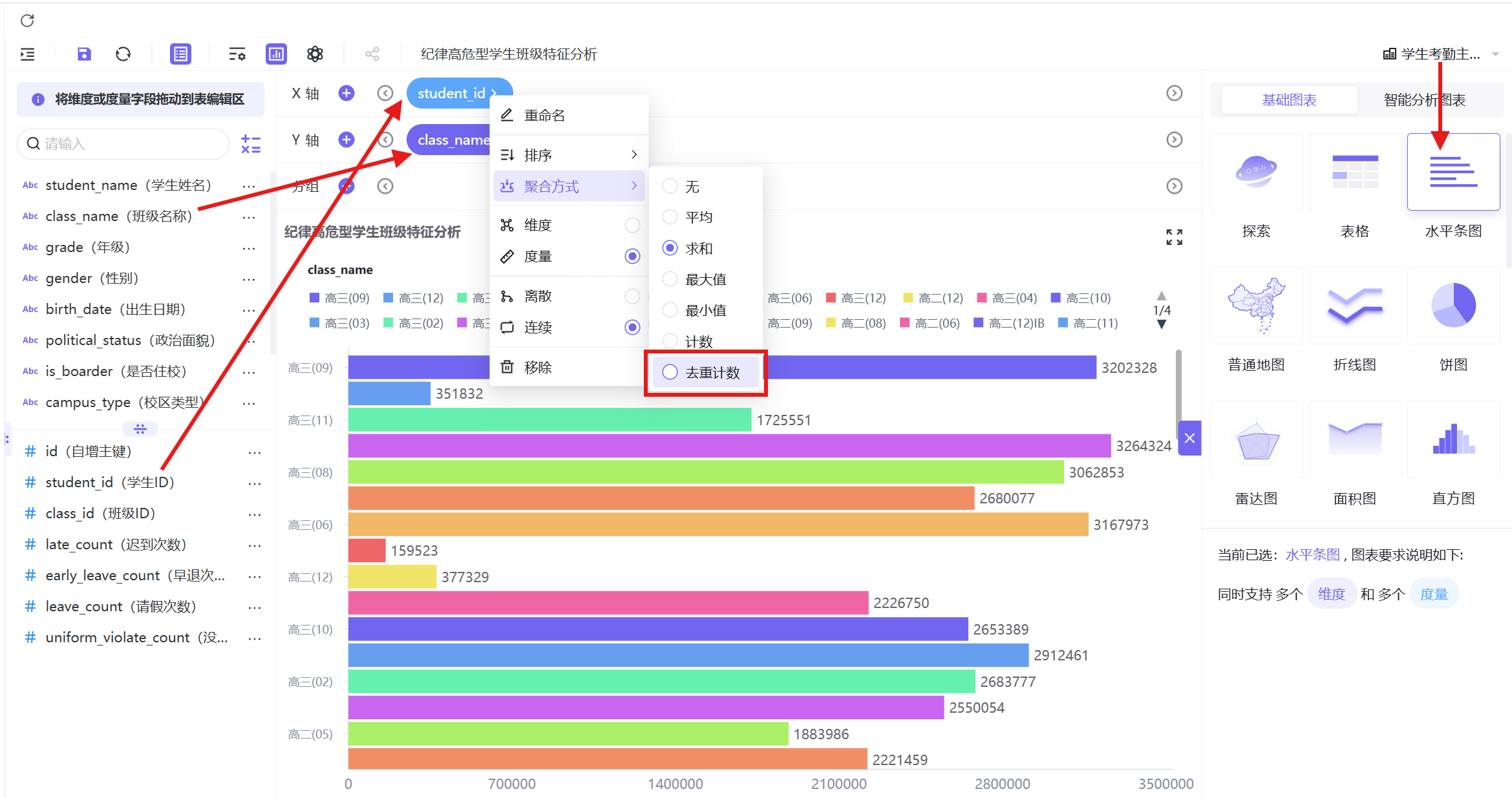
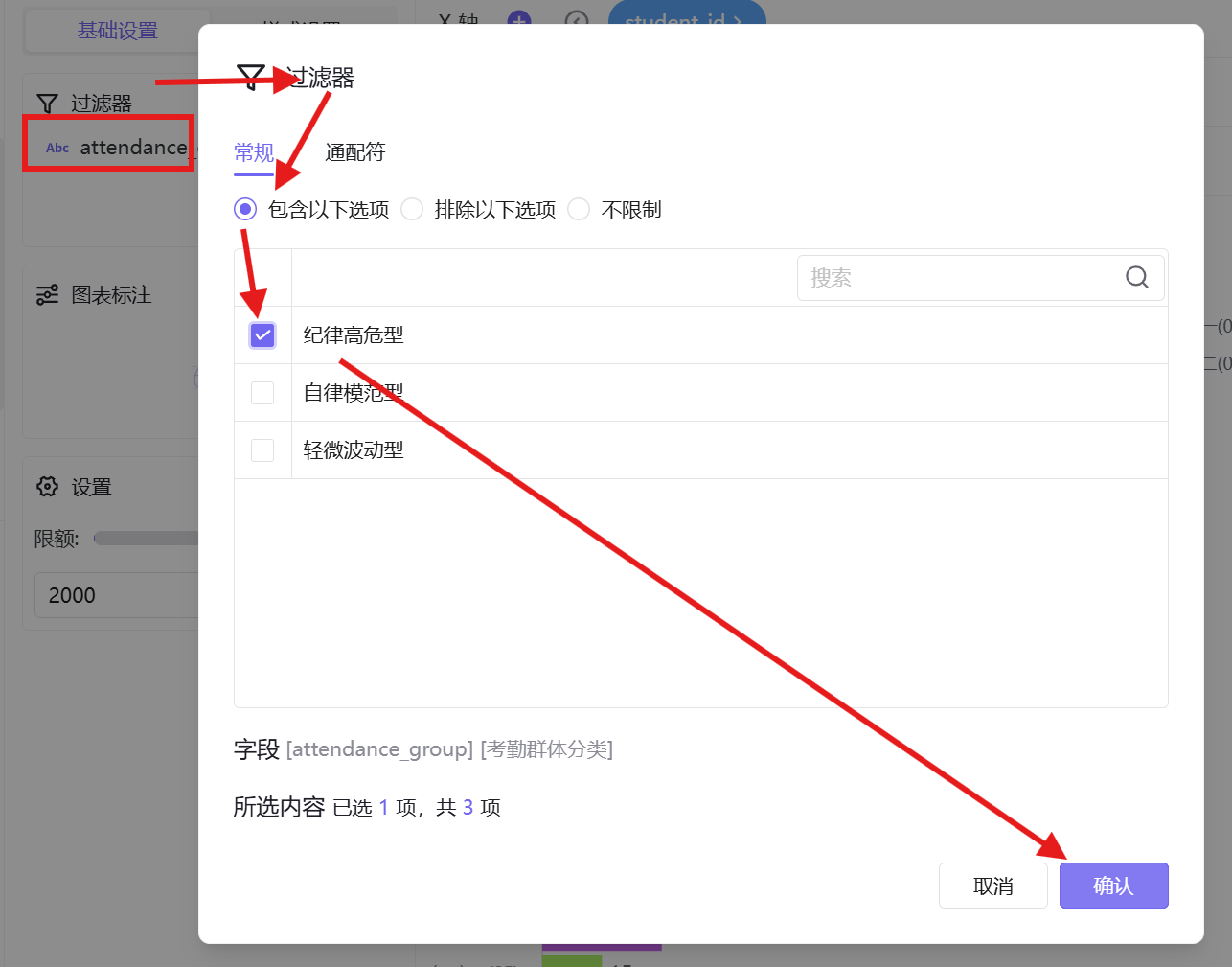
- 过滤器配置:点击图形设置按钮,在过滤器中添加「考勤群体分类(attendance_group)」字段,编辑筛选规则为「包含以下选项」,勾选「纪律高危型」,点击确认完成筛选;
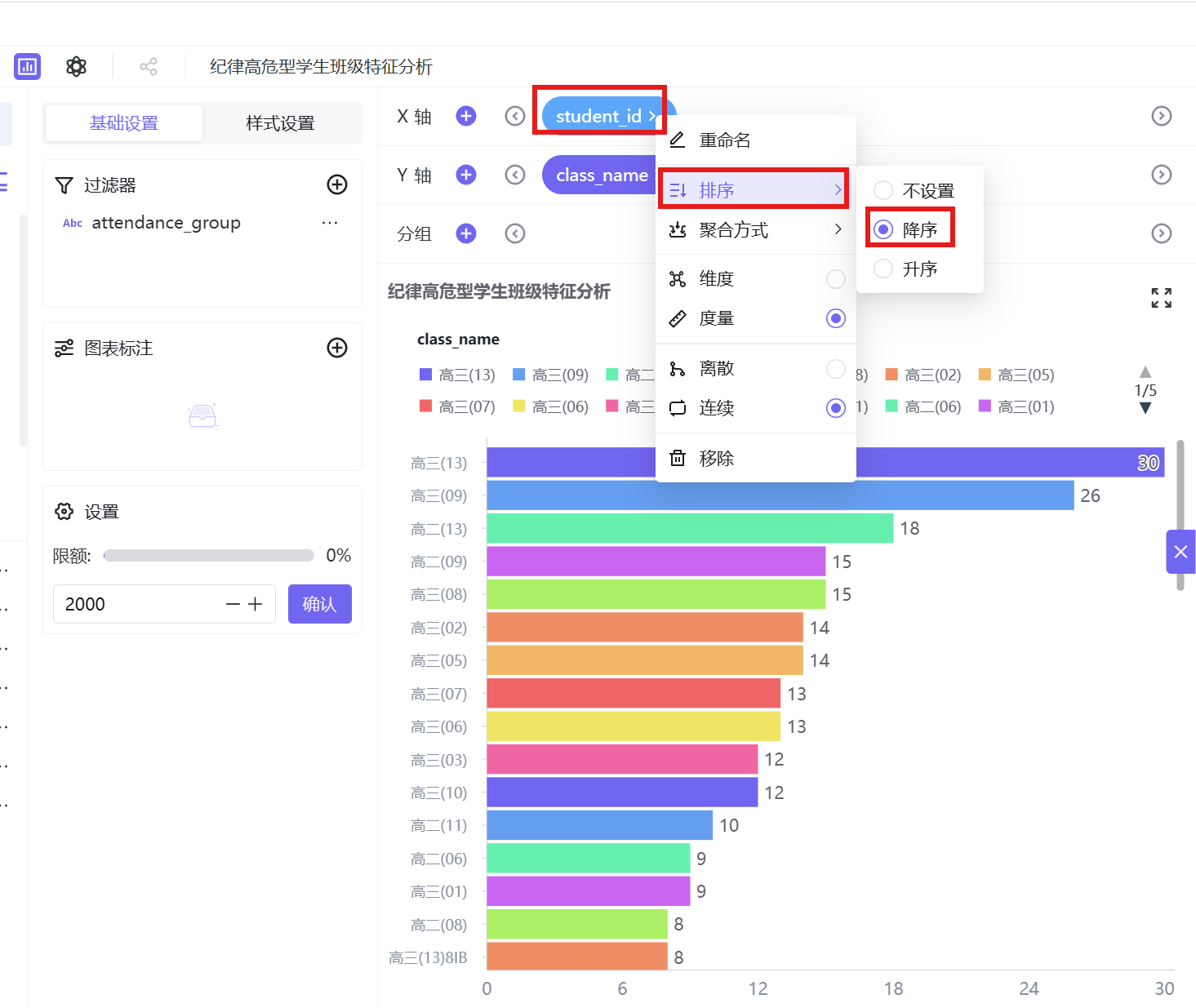
- 排序设置:为了更直观地定位高危学生集中的班级,点击 X 轴「学生 ID」字段的排序按钮,选择「降序」排列,让高危人数最多的班级排在图表最上方;
- 样式优化:点击样式设置,将图表主题色设置为与前文分析图表统一的主题色,取消图表边框,调整 Y 轴班级名称的显示间距,保证长班级名称完整展示;
- 完成配置后,点击「保存」-「保存并发布」,完成班级特征分析工作表的制作。
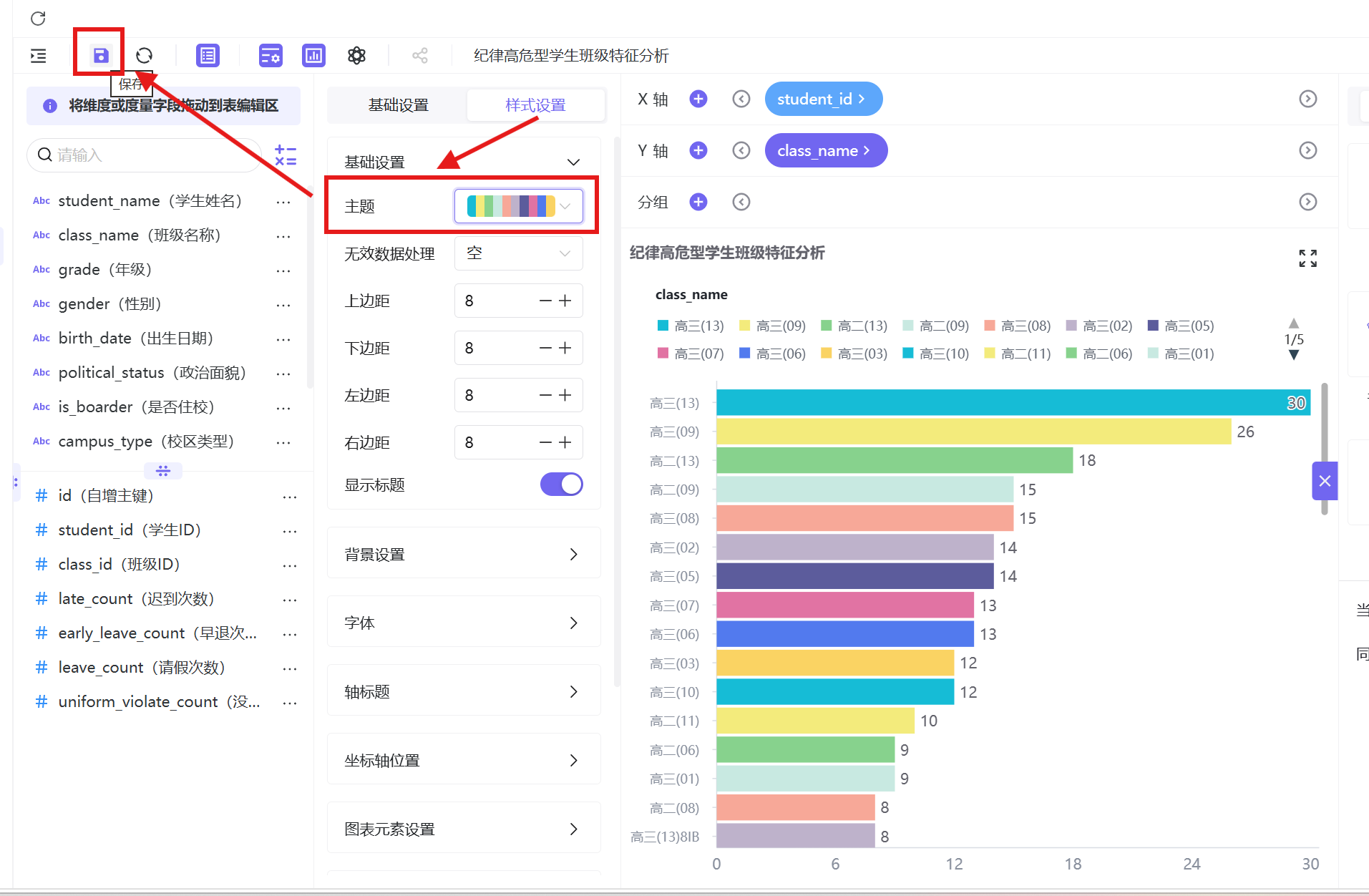
分析结论:从班级水平条图可以清晰看到,纪律高危型学生高度集中在少数班级,其中高三 09 班高危人数最多(38 人),其次为高三 08 班、高三 02 班等,多数班级高危人数极少,呈现明显的班级聚集性。结合年级分布特征来看,高危学生主要集中在高三年级的部分班级,这既与高三学生升学备考节奏紧张、课程安排灵活有关,也说明高危行为与班级管理强度、班风氛围、同伴影响密切相关。少数薄弱班级需要重点整治,通过加强班主任监管、整顿班风,阻断不良风气传染。
3.5 搭建综合仪表盘
将所有高危群体分析工作表整合为统一可视化仪表盘,实现全维度分析结果集中展示、一键分享,完整操作步骤如下:
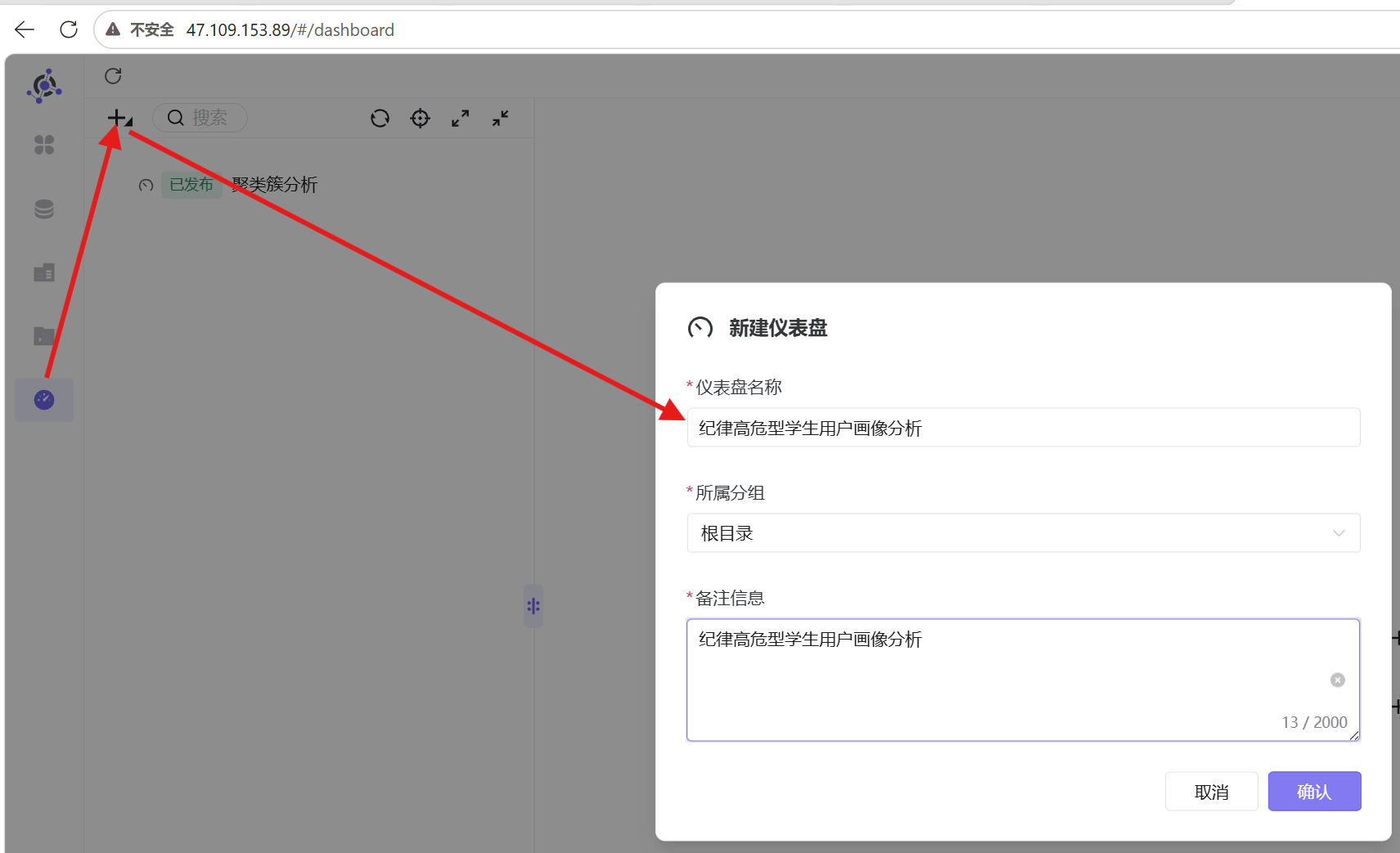
- 点击助睿 BI 左侧菜单栏中的「仪表盘」模块,进入仪表盘管理页面;
- 点击左上角「+」-「新建仪表盘」,在弹窗中输入仪表盘名称「纪律高危型学生用户画像分析」,填写备注信息后点击「确认」;
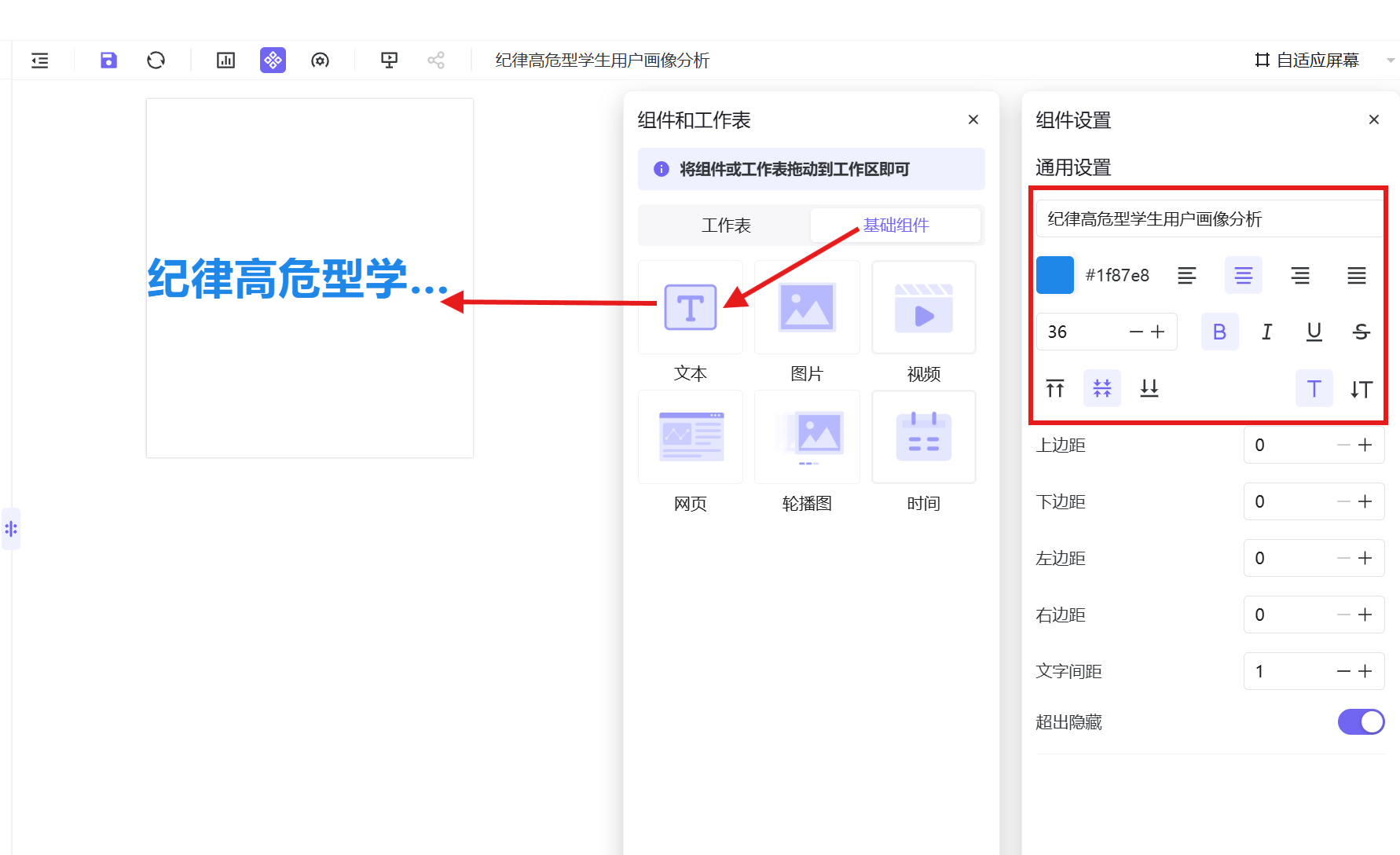
- 在右侧组件与工作表区域,点击「基础组件」,拖拽一个文本组件到画布中;
- 编辑文本组件内容为「纪律高危型学生用户画像分析」,设置字体颜色、字体大小、加粗、居中格式,调整组件大小至适配画布顶部,关闭组件编辑窗口;
- 点击右侧「工作表」组件显示按钮,切换到工作表列表,将 3.4 节中制作的所有分析工作表(高危总人数、性别占比、年级分布、校区年级交叉、班级分布等)全部拖拽至仪表盘画布中;
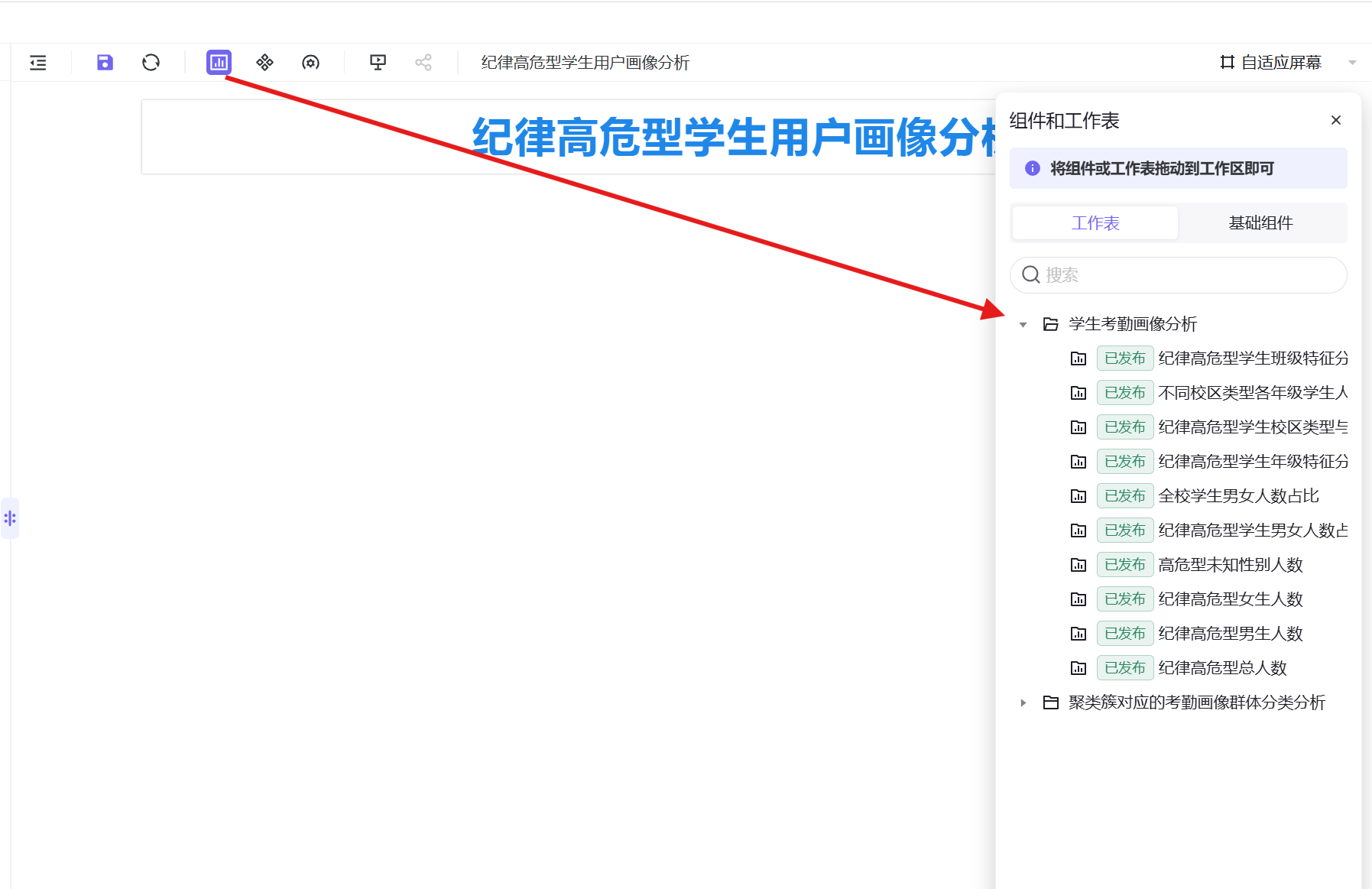
- 拖入完毕后,使用鼠标拖动调整各图表的位置、大小,优化整体布局,保证页面整洁、逻辑清晰;同时可通过文本组件将各维度的分析结论添加到对应图表旁,形成完整的分析看板,文本组件可通过关闭「超出隐藏」开关实现长文本换行展示;
- 布局与内容设计完毕后,点击画布顶部「发布」按钮,保存并发布仪表盘;
- 发布成功后,点击「预览」可全屏查看仪表盘效果,点击「分享」可选择不同分享方式,将分析看板分享给其他人员查看,复制分享链接后,其他人员即可通过链接直接访问仪表盘。
4 纪律高危型学生画像分析总结

4.1 整体概况
纪律高危型学生存在高频迟到、早退、请假及校服违规行为,多维度违纪叠加,是校园考勤管理中最需重点关注的群体。该群体人数占比虽可控,但行为影响大,易引发不良风气传染,需开展专项治理与精准干预。
4.2 核心特征
- 性别特征:男生为高危群体主体,占比显著高于女生,是高危行为的主要发生对象,核心原因与男生规则意识薄弱、时间观念不足、自我约束能力相对较弱相关。
- 年级特征:高度集中于高年级,随年级升高,高危学生占比明显上升。高年级学生学业压力大、自主空间广、备考心态浮躁,对考勤纪律的重视度显著下降,是违纪行为高发的核心群体。
- 校区特征:在不同校区呈现明显分布差异,高危学生高度集中在老校区,新校区风险极低。该差异与校区通勤条件、管理模式、学风氛围密切相关,老校区学生通勤成本更高、管理半径更大,更易出现考勤违纪行为。
- 班级特征:存在明显的班级聚集性,高危学生集中在少数管理薄弱、班风涣散的班级,与班级管理强度、班主任监管力度、同伴效应直接相关,不良风气在班级内的传染效应显著。
4.3 管理建议
- 重点关注高年级男生群体:针对性开展考勤纪律教育与时间管理培训,强化规则意识,通过主题班会、一对一谈心等方式,引导男生树立正确的纪律观念,减少违纪行为发生。
- 加强老校区高年级管理:针对老校区优化通勤管理、强化考勤监督机制,通过家校联动、错峰上下学等方式,降低学生通勤违纪风险;同时营造严谨的学风氛围,提升高年级学生的纪律自觉性。
- 整治高危学生集中班级:加强班主任监管力度,建立班级考勤责任制,对高危人数集中的班级开展专项班风整顿,通过班级公约、小组互助等方式,阻断不良风气的传染。
- 建立高危学生专项台账:对纪律高危型学生一对一建档,跟踪记录考勤行为变化,联合家长开展家校联动教育,制定个性化的行为矫正方案,定期跟进干预效果,防止违纪行为固化升级。
5 问题与解决
我整理了实验过程中高频出现的典型问题,每个问题都按「现象 - 原因 - 解决方法」的结构写好了:
问题 1:K-Means 聚类结果散点图不显示全量数据
- 问题现象:在助睿 BI 制作散点图时,系统默认只显示前 2000 条数据,导致部分学生数据点未在图表中展示,聚类簇分布不完整。
- 问题原因:平台默认对大数据集设置了 2000 条的显示限额,目的是优化图表加载性能,但本次学生考勤数据集样本量超过该阈值,导致数据截断。
- 解决方法:在工作表的「图形设置」面板中,找到「数据限额」选项,将默认值修改为100%,确保所有数据点完整展示;同时切换高对比度主题色,避免不同簇类的颜色在大量数据点中出现混淆。
问题 2:聚类结果回写 ETL 转换流执行失败
- 问题现象:在助睿 ETL 中运行「更新」组件时,报错提示
字段类型不匹配,导致聚类簇编号和考勤群体分类无法回写到 student_attendance_stats 表中。 - 问题原因:student_attendance_stats 表中 student_id 字段为
INT类型,而 student_cluster 表中 student_id 字段为VARCHAR类型,字段类型不一致,导致更新时无法匹配关键字。 - 解决方法:在 ETL 流程的「字段选择」组件中,进入「元数据」配置页,手动将 student_id 字段类型修改为
Integer,与目标表字段类型保持一致,重新运行转换流,数据更新成功。
问题 3:助睿 BI 仪表盘工作表显示不全
- 问题现象:发布仪表盘后,部分工作表图表在预览时显示不全,出现截断或空白区域。
- 问题原因:工作表拖拽至仪表盘后,图表大小未适配画布尺寸,或工作表的筛选条件与仪表盘的全局设置冲突。
- 解决方法:重新调整仪表盘布局,将工作表图表按逻辑顺序排列,手动拖拽调整每个图表的大小;同时检查每个工作表的筛选器是否存在冲突,确保所有工作表的筛选条件独立生效,调整后重新发布仪表盘。
问题 4:聚类群体画像解读困难
- 问题现象:K-Means 输出的 C1/C2/C3 仅为机器编号,无法直接对应考勤群体的业务含义,难以解释不同簇类的行为差异。
- 问题原因:仅通过单一指标无法区分聚类簇特征,缺乏多维度交叉对比分析,无法捕捉学生在迟到、早退、请假、校服违规等多个维度的行为模式。
- 解决方法:制作 6 组两两指标交叉散点图,将迟到次数与早退、请假、校服违规次数分别组合分析,通过数据点的分布特征对比,为每个簇类赋予业务标签,形成可解释的学生画像。
6 实验总结
收获
- 掌握了 K-Means 聚类的业务落地流程:从数据筛选、参数配置、模型训练到结果解读,完整掌握了基于助睿数智平台的零代码聚类建模方法,理解了无监督学习在学生行为分群场景的应用逻辑。
- 提升了数据可视化与业务解读能力:学会了使用助睿 BI 制作散点图、饼图、柱状图、水平条图等多维度图表,掌握了通过图表对比分析挖掘数据背后业务规律的方法,实现了从机器结果到业务画像的转化。
- 熟悉了数据集成与数据治理流程:通过 ETL 平台完成了数据表字段新增、数据映射、批量更新等操作,理解了数据清洗、字段类型统一、数据回写在数据分析流程中的重要性。
- 建立了校园考勤管理的数据分析思维:通过高危群体专项画像分析,学会了从性别、年级、校区、班级多维度拆解群体特征,形成了从数据指标到管理建议的闭环分析思路。
对平台的整体评价
助睿数智(Uniplore)平台作为一站式数据科学平台,本次实验中表现出了显著的易用性与专业性:
- 零代码建模门槛低:无需复杂编程基础,拖拽式操作即可完成机器学习建模与可视化分析,非常适合数据分析入门学习;
- 全链路功能完善:从数据集成、ETL 处理、AI 建模到 BI 可视化,平台覆盖了数据分析全流程,各模块间数据互通顺畅,无需额外工具;
- 可视化能力强大:助睿 BI 平台支持多种图表类型,仪表盘制作与分享功能便捷,能够快速将分析结果转化为可落地的管理看板;
- 不足与优化建议:部分功能(如字段筛选、数据限额)的默认设置对新手不够友好,建议增加更详细的新手引导;同时 ETL 组件的报错提示可以更具体,方便快速定位问题。
总体而言,助睿数智平台能够高效支撑校园考勤数据分析这类实战场景,是数据分析入门与实践的优质工具。

一站式 AI 云服务平台
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)