
爆肝整理!千万级用户行为日志清洗全流程实战(零代码ETL+Java解析+可视化,附踩坑指南)
爆肝整理!《千万级用户行为日志清洗全流程实战》来啦🔥。从Java硬核解析到高阶特征工程,再到BI大屏展现,全程无保留复盘!想要彻底告别脏数据治理噩梦的同学必看。文末附送800万原始数据集+完整 ETL 配置文件,直接抄作业,周末卷起来!🚀
大家好,做过数据挖掘的小伙伴肯定都有过这种绝望时刻:拿到手的数据不是漂漂亮亮的 Excel 表格,而是几万个零散的、没有任何表头的、充斥着奇奇怪怪分隔符的 TXT 文本! 面对几百兆甚至上 G 的半结构化日志,光是写 Python 脚本洗数据就能耗掉一整天,跑起来还动不动就内存溢出(OOM)。
今天,我要给大家安利一个“摸鱼神器”,带你实操一个硬核实验——如何基于零代码平台,通过纯“拖拉拽”的方式,将800万+条烂日志洗成干净清爽的结构化指标宽表! 全程干货,建议先 收藏 再看!🌟
🎯 第一部分:实验背景与挑战
1. 实验目的与任务
本次实战的核心就是解决“脏数据治理”与“指标体系构建”:
-
文本解析:攻克半结构化日志的解析与字段拆分。
-
数据规整:把零散的原始 TXT 日志转化为标准的 MySQL 结构化数据表。
-
多维聚合:实现按天、按小时、按软件层面的多维度数据聚合与跨表关联。
-
产出结果:搭建适配分析场景的指标体系,为后续的 BI 可视化和流失预测模型备好“弹药”。
2. 实验环境与神仙工具
-
实验平台:助睿数智(Uniplore)一站式数据科学实验平台。
-
平台主打一个:覆盖从数据接入、ETL 处理、机器学习到可视化的全链路 Agentic 零代码功能。(官网:https://www.uniplore.com/)
-
平台直达:https://lab.guilian.cn/
-
核心模块:助睿 ETL 数据集成平台、助睿 BI。
3. 数据集概况(真实竞赛数据)
数据来源于中国互联网数据挖掘竞赛,包含 1000 名用户连续 4 周的 800 万+ 条行为记录,总大小约 825MB。
-
demographic.csv:用户画像(年龄、职业、收入等)。
-
行为日志:散落在数万个 TXT 文件中,采用奇葩的 <=> 和 [=] 分隔符,无固定表头。(这正是我们要清洗的核心!)
4. 核心处理链路图解
为了让大家有个宏观概念,我先画了整个 ETL 处理的架构图。别看步骤多,用零代码工具连起来极其丝滑:
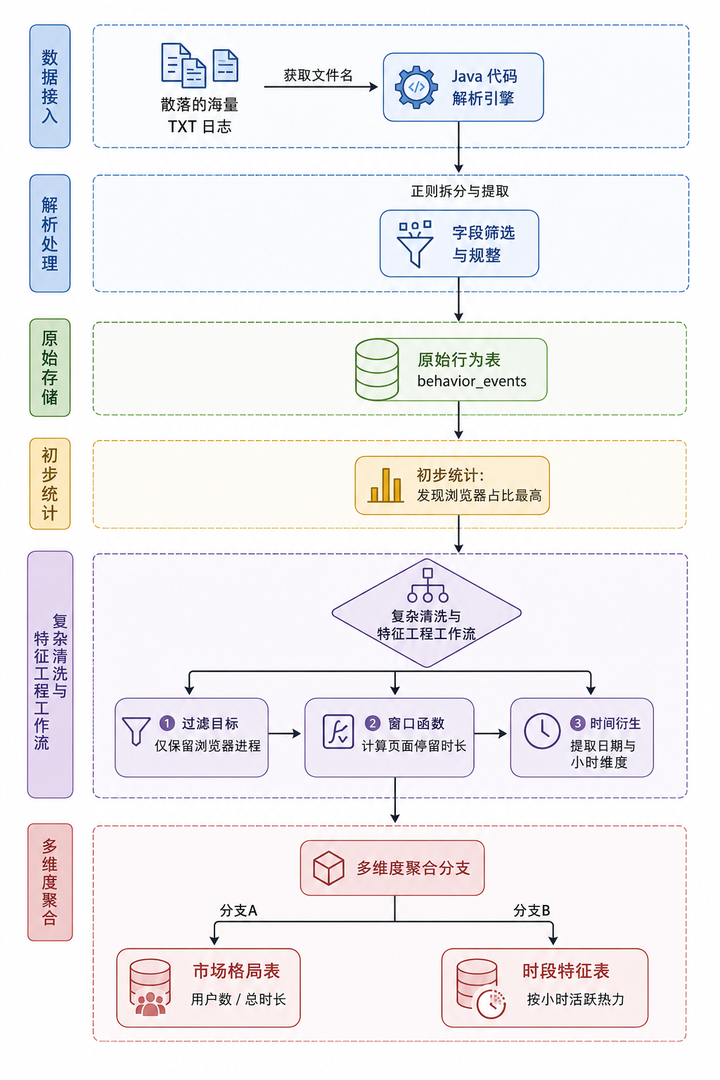
🚀 第二部分:保姆级实操步骤(手把手复现)
接下来进入正题,前方高能,请紧跟我的操作!
Step 1:创建项目与准备数据
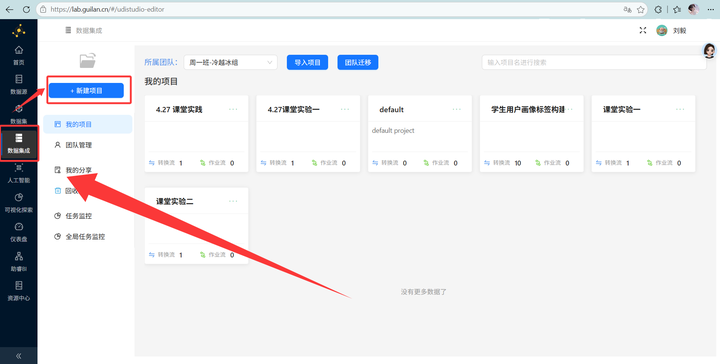
1.1 创建项目
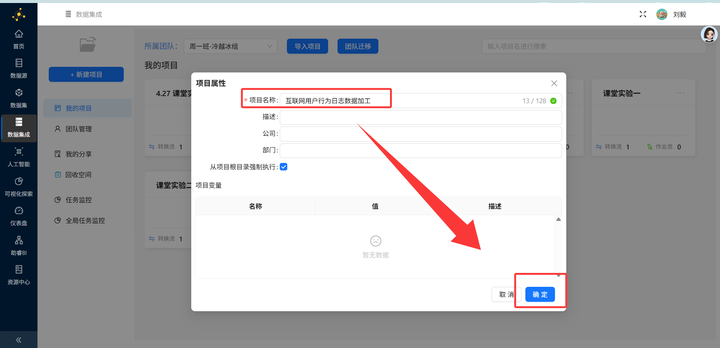
登录助睿在线实验平台,点击“新建项目”,霸气地填上项目名称“互联网用户行为日志数据加工”。
1.2 捞取日志数据
为了跑通流程,我们先拿 20 个 TXT 练练手。
-
在左侧“文件”库中,新建目录 互联网用户行为日志数据集。
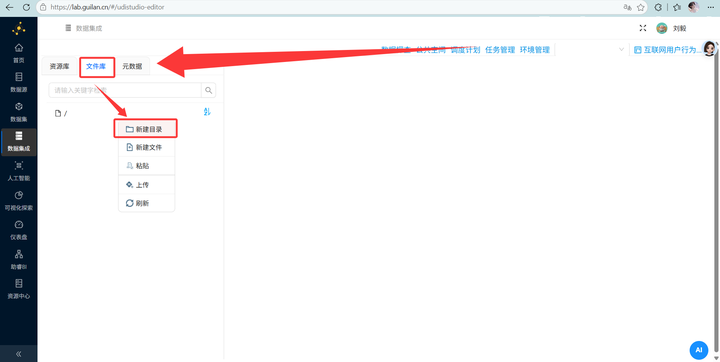
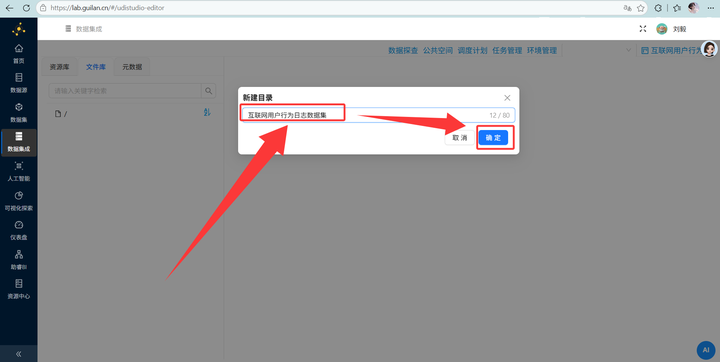
-
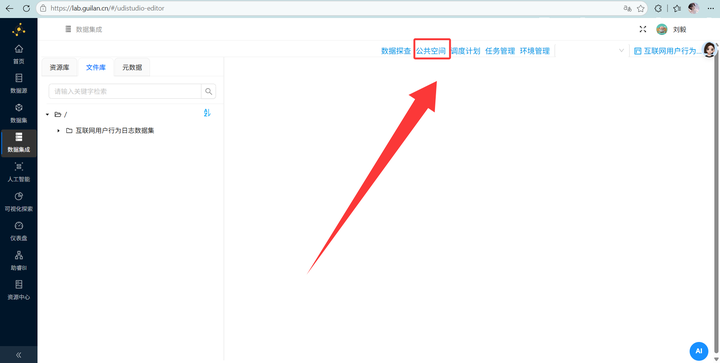
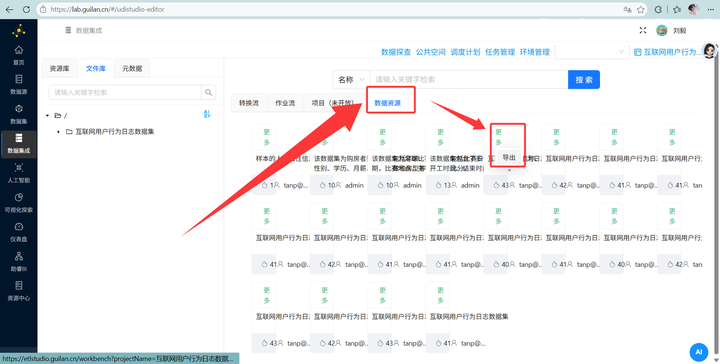
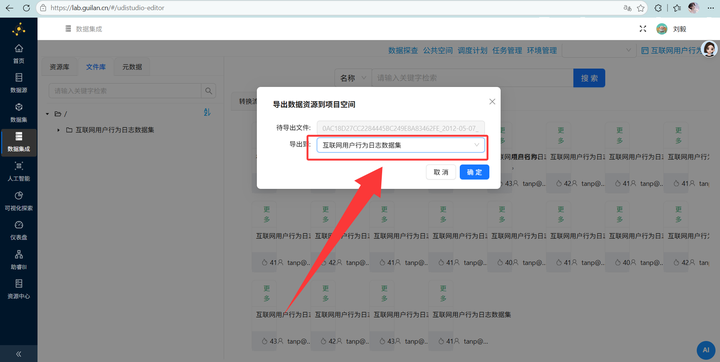
去“公共空间” -> “数据资源”,把这 20 个 TXT 文件全部“导出”到我们自己的目录下。
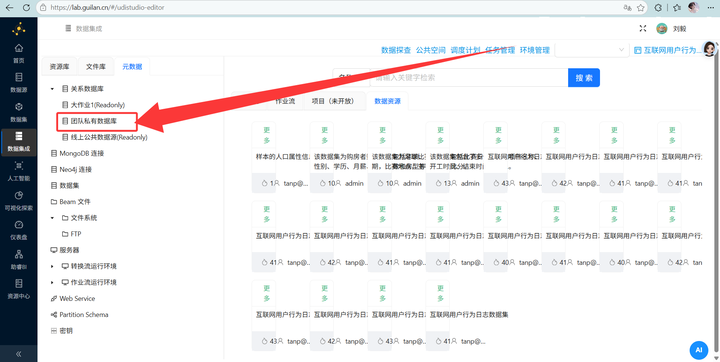
1.3 连接数据库
在“元数据”里配置好“团队私有数据库”(操作类似平时连 MySQL,一键搞定)。
Step 2:解析半结构化日志(从乱码到表)
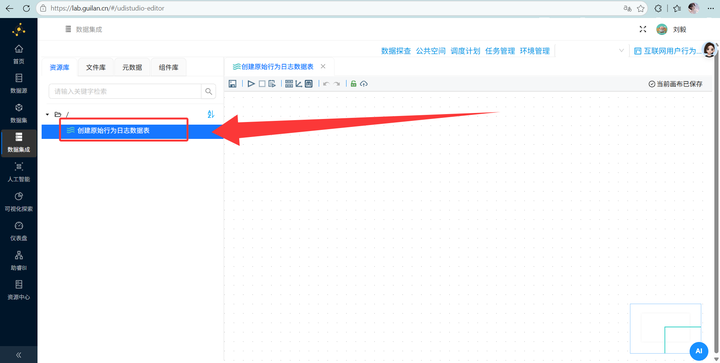
2.1 创建底层表
新建一个工作流“创建原始行为日志数据表”
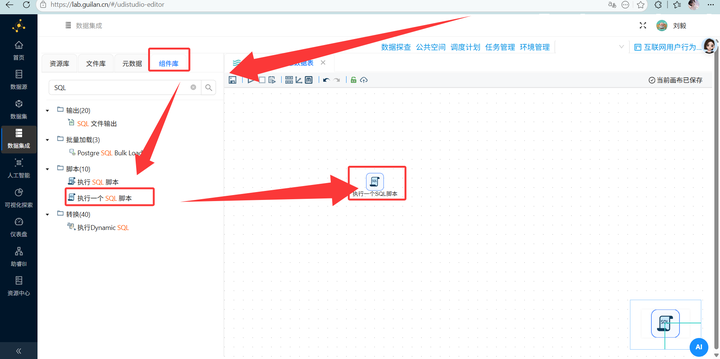
拖入 【执行一个SQL脚本】
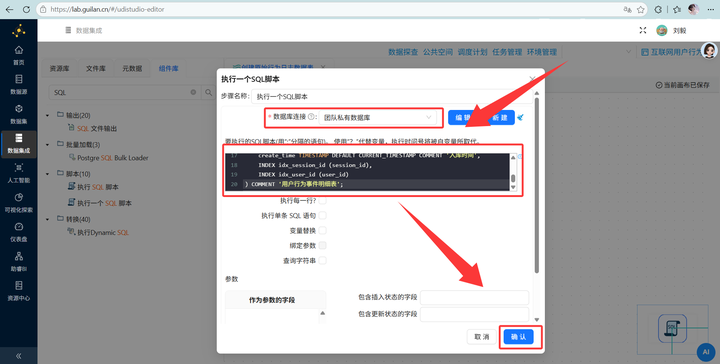
在私有数据库中执行建表语句,创建明细表 behavior_events(包含 session_id, user_id, 进程名, URL等字段)。SQL脚本如下:
CREATE TABLE behavior_events (
id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键',
session_id VARCHAR(255) COMMENT '会话唯一ID',
user_id VARCHAR(100) COMMENT '用户ID',
session_start_time VARCHAR(50) COMMENT '会话开始时间',
event_seconds INT COMMENT '事件发生秒数',
process_name VARCHAR(255) COMMENT '进程名称',
process_id VARCHAR(100) COMMENT '进程ID',
url TEXT COMMENT '访问网址',
addr_handle VARCHAR(255) COMMENT '地址栏句柄',
tab_handle VARCHAR(255) COMMENT '标签页句柄',
browser_version VARCHAR(100) COMMENT '浏览器版本',
window_handle VARCHAR(255) COMMENT '窗口句柄',
app_name VARCHAR(255) COMMENT '程序名称',
company_name VARCHAR(255) COMMENT '开发公司',
source_file VARCHAR(255) COMMENT '原始日志文件名',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
INDEX idx_session_id (session_id),
INDEX idx_user_id (user_id)
) COMMENT '用户行为事件明细表';
运行转换流:
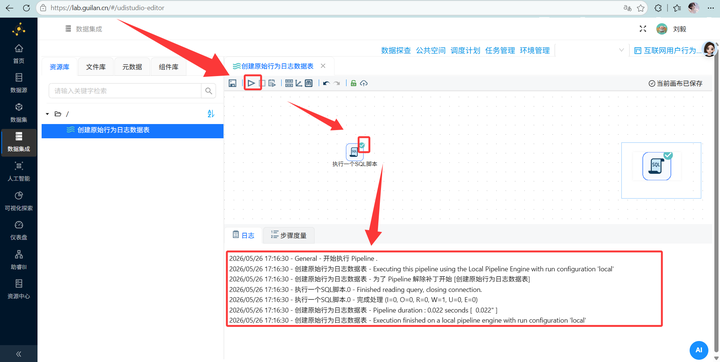
2.2 读取文件名列表
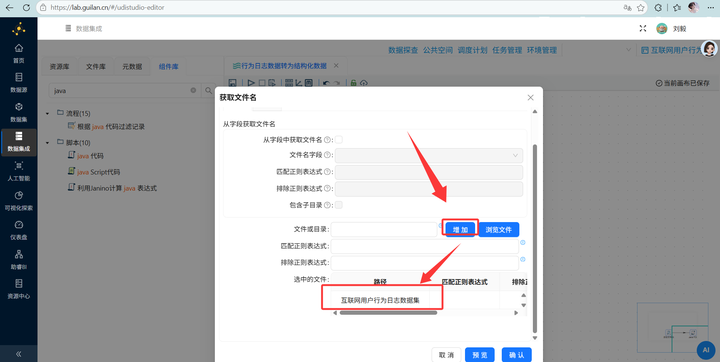
因为文件太多,咱们用批处理思路。新建工作流“行为日志数据转为结构化数据”拖入 【获取文件名】 组件,路径选择刚才建的 互联网用户行为日志数据集。
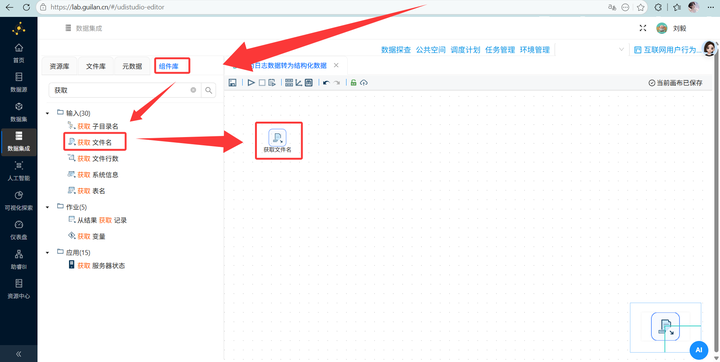
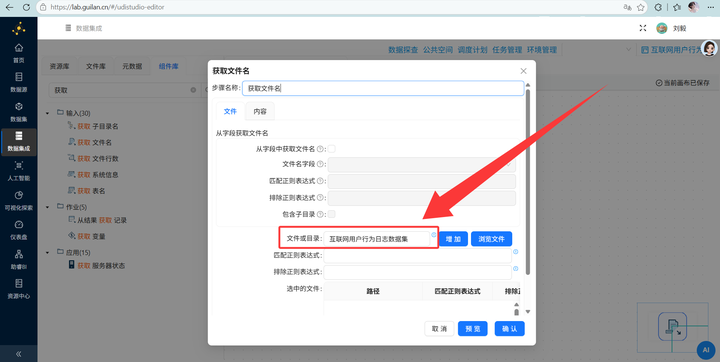
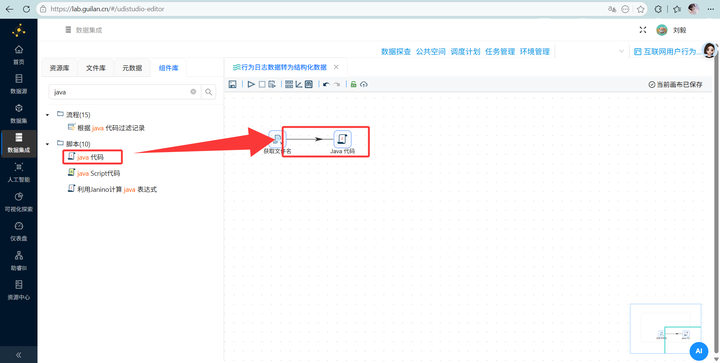
2.3 硬核 Java 解析(最关键一步!)
怎么处理恶心的 <=> 分隔符?拖入 【Java代码】 组件,连上一步。
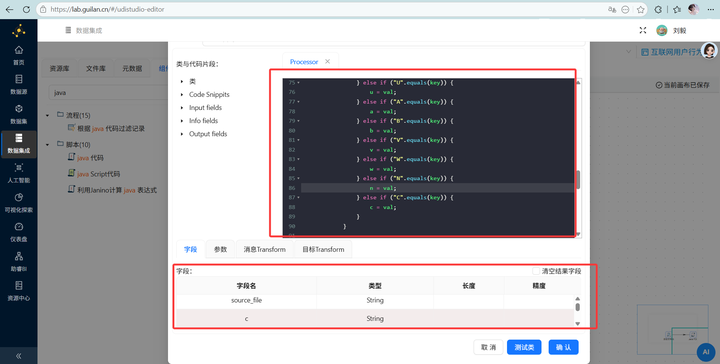
在这儿敲一段代码,跳过文件前两行,通过 kv.indexOf("<=>") 切割键值对:
// 全局变量定义
String pathField;
String shortFilenameField;
public boolean processRow() throws HopException {
if (first) {
pathField = "filename";
shortFilenameField = "short_filename";
first = false;
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
String path = get(Fields.In, pathField).getString(r);
String short_filename = get(Fields.In, shortFilenameField).getString(r);
String user_id = "";
String l_start = "";
if (short_filename != null) {
String name = short_filename.replace(".txt", "");
String[] parts = name.split("_");
if (parts.length >= 3) {
user_id = parts[0];
l_start = parts[1] + " " + parts[2].replace("-", ":");
}
}
String session_id = user_id + "_" + l_start;
java.io.BufferedReader br = null;
try {
br = new java.io.BufferedReader(new java.io.FileReader(path));
String line = "";
// 跳过前两行(Last和L_Start)
br.readLine();
br.readLine();
while ((line = br.readLine()) != null) {
if (line.trim().isEmpty()) {
continue;
}
// 解析键值对
String[] kvPairs = line.split("\\[=\\]");
String t = "";
String p = "";
String i = "";
String u = "";
String a = "";
String b = "";
String v = "";
String w = "";
String n = "";
String c = "";
for (String kv : kvPairs) {
int sepIdx = kv.indexOf("<=>");
if (sepIdx == -1) {
continue;
}
String key = kv.substring(0, sepIdx).trim();
String val = kv.substring(sepIdx + 3);
if ("T".equals(key)) {
t = val;
} else if ("P".equals(key)) {
p = val;
} else if ("I".equals(key)) {
i = val;
} else if ("U".equals(key)) {
u = val;
} else if ("A".equals(key)) {
a = val;
} else if ("B".equals(key)) {
b = val;
} else if ("V".equals(key)) {
v = val;
} else if ("W".equals(key)) {
w = val;
} else if ("N".equals(key)) {
n = val;
} else if ("C".equals(key)) {
c = val;
}
}
// 创建输出行
Object[] outRow = createOutputRow(r, data.outputRowMeta.size());
get(Fields.Out, "session_id").setValue(outRow, session_id);
get(Fields.Out, "user_id").setValue(outRow, user_id);
get(Fields.Out, "l_start").setValue(outRow, l_start);
get(Fields.Out, "t").setValue(outRow, t);
get(Fields.Out, "p").setValue(outRow, p);
get(Fields.Out, "i").setValue(outRow, i);
get(Fields.Out, "u").setValue(outRow, u);
get(Fields.Out, "a").setValue(outRow, a);
get(Fields.Out, "b").setValue(outRow, b);
get(Fields.Out, "v").setValue(outRow, v);
get(Fields.Out, "w").setValue(outRow, w);
get(Fields.Out, "n").setValue(outRow, n);
get(Fields.Out, "c").setValue(outRow, c);
get(Fields.Out, "source_file").setValue(outRow, short_filename);
putRow(data.outputRowMeta, outRow);
}
} catch (Exception e) {
logError(e.getMessage(), e);
} finally {
try {
if (br != null) {
br.close();
}
} catch (Exception e) {
// ignore
}
}
return true;
}在下方的字段插入:

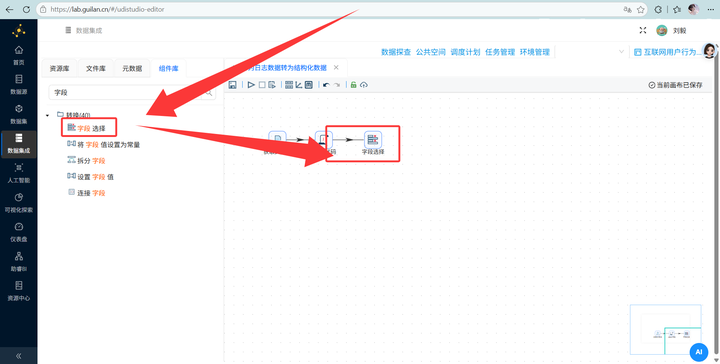
2.4 字段瘦身与入库
-
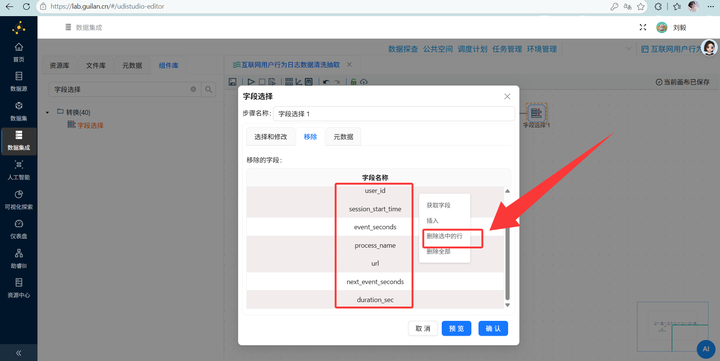
连上 【字段选择】 组件,选中上一步骤中的Java代码输出的字段后,右键点击“删除选中的行”
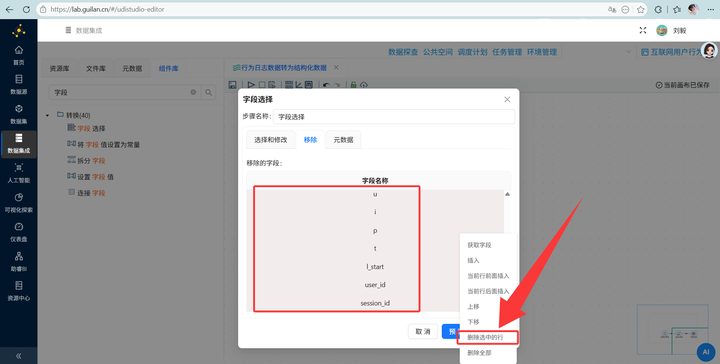
-
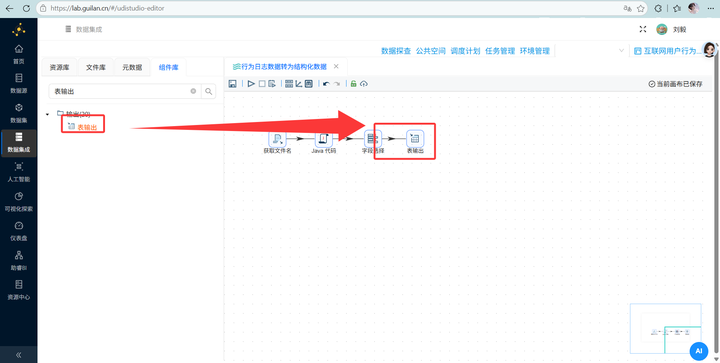
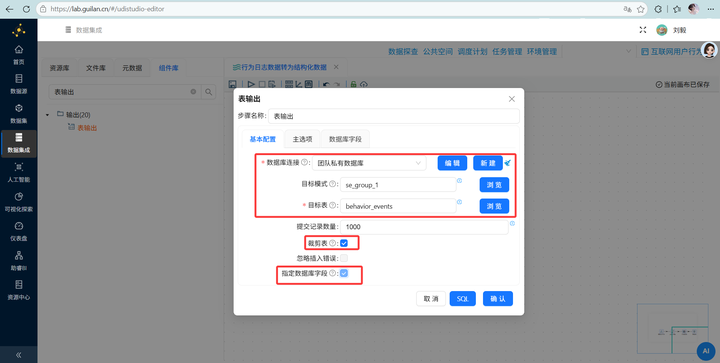
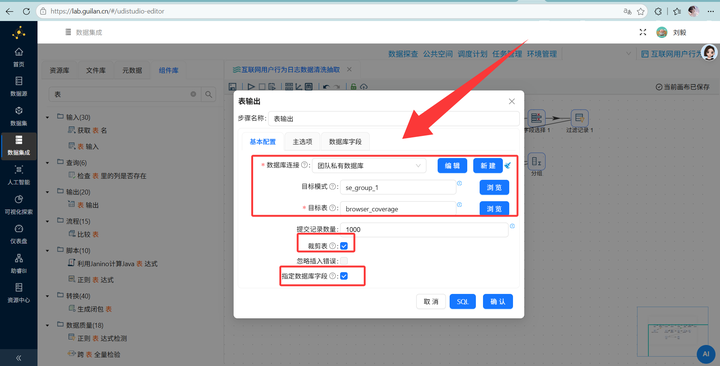
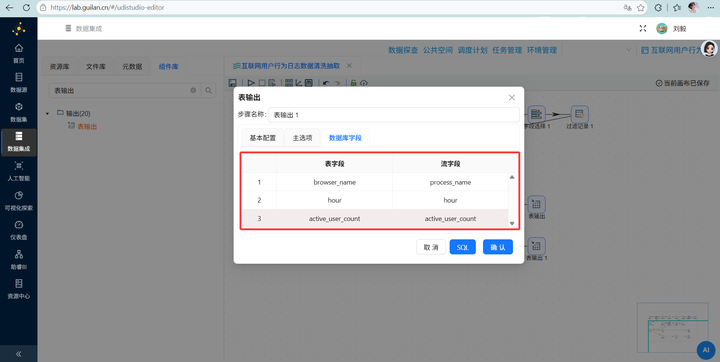
最后接上 【表输出】,目标表选 behavior_events,勾选“裁剪表”(防重复)
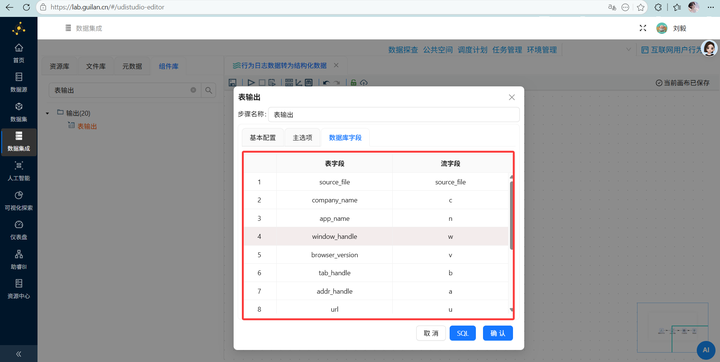
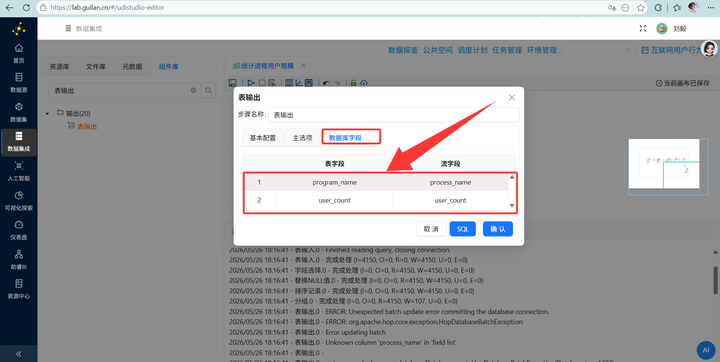
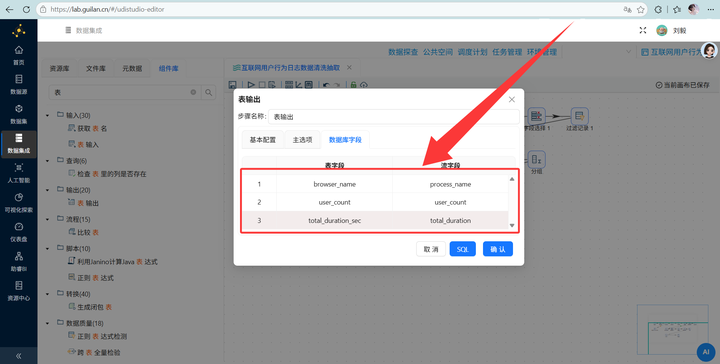
在“表输出”组件的“数据库字段”配置页中,需要将流字段与表字段进行如下一一映射:
点击“执行”!
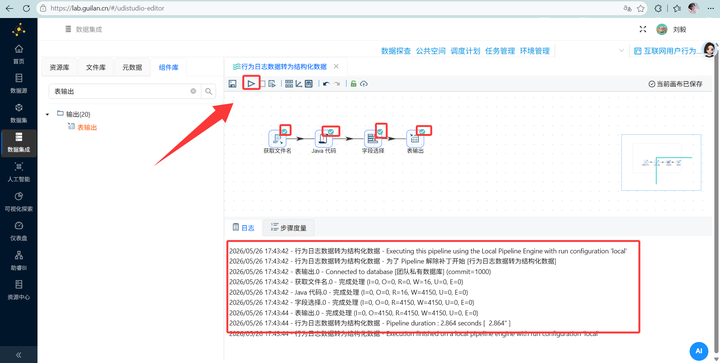
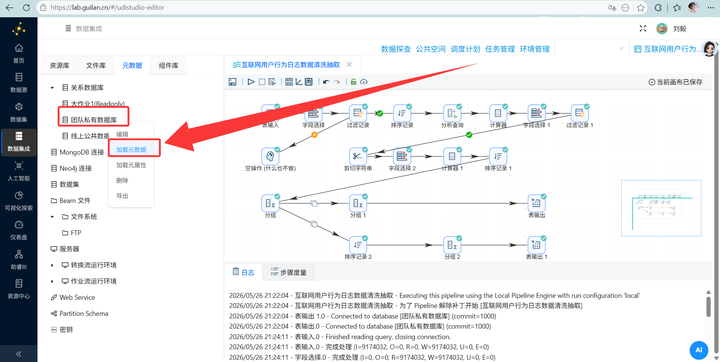
2.5 💡 探查一下
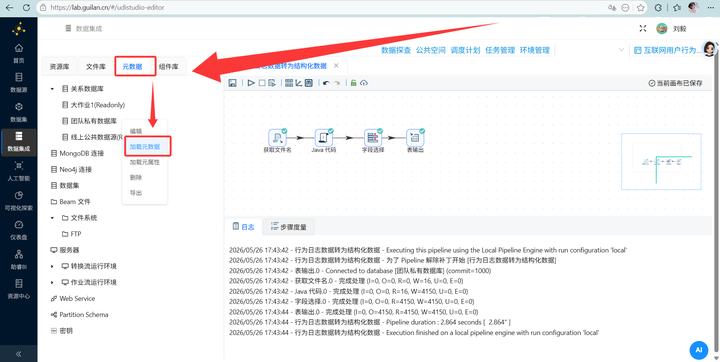
打开“元数据”tab页,在“团队私有数据库”连接上右键选择“加载元数据”
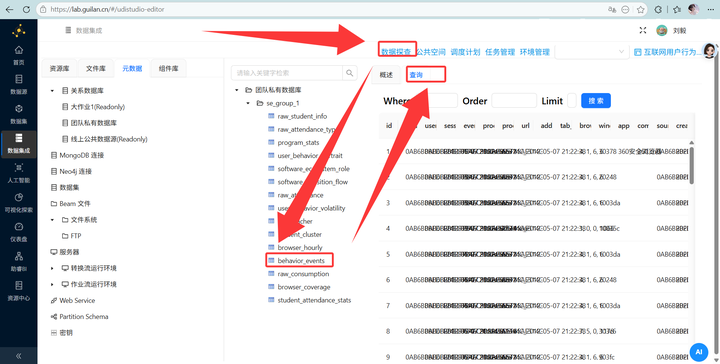
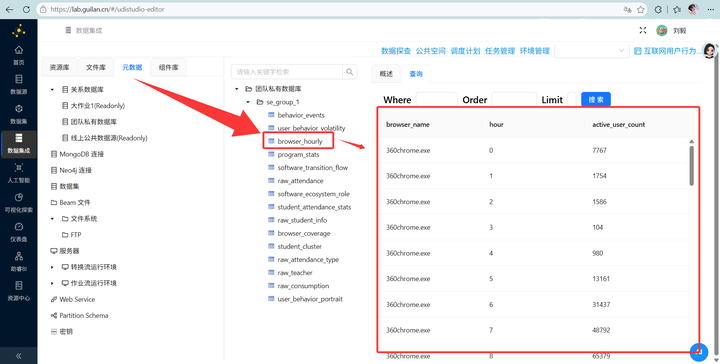
然后进入数据探查页面,展开“团队私有数据库”,双击目标表“behavior_events”,在右侧页面选择“查询”tab标签
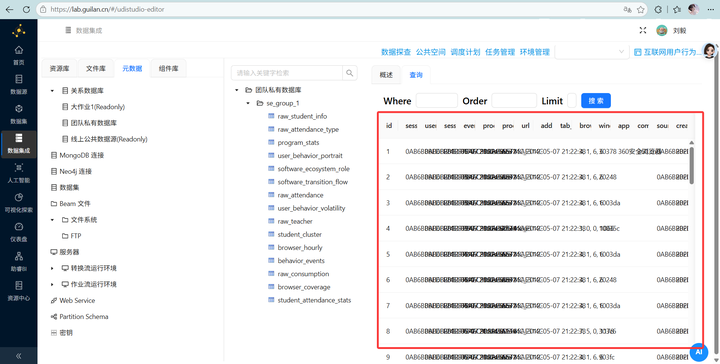
原本一团糟的 TXT,现在已经乖乖躺在数据库里,变成了结构化数据!
Step 3:业务探索(确认分析方向)
数据有了,九百多万条我们分析啥?最聪明的做法是:统计一下哪个软件用的人最多!
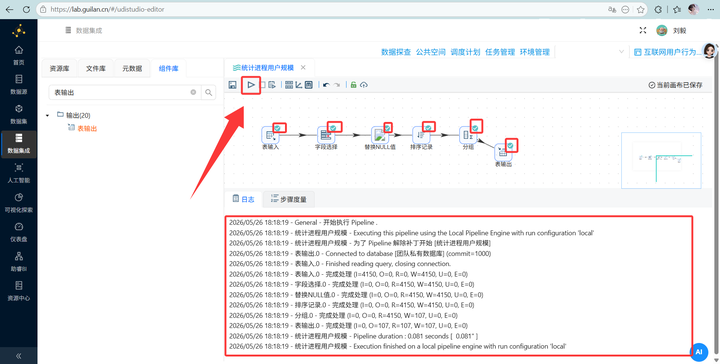
3.1 统计进程用户规模
我们需要明确逻辑:每个进程的用户数量 = 拥有该进程名称的去重用户 ID 计数。这一步的转换流非常清晰,我们一步步搭建:
-
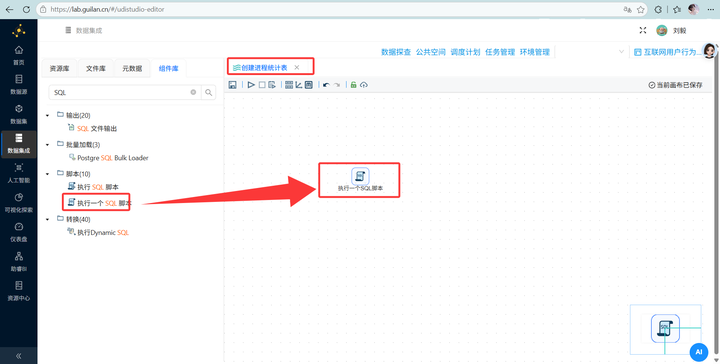
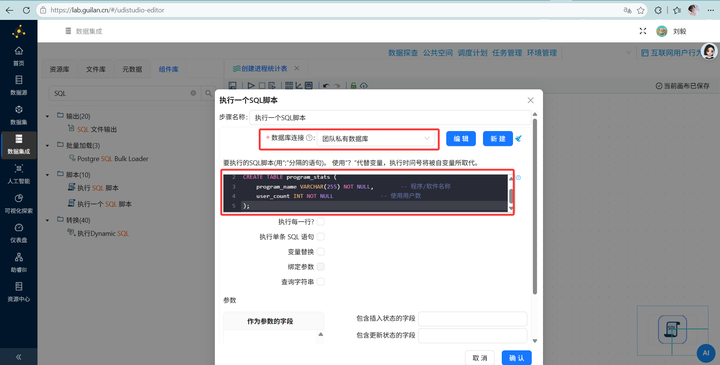
步骤一:创建承载结果的统计表 首先新建工作流“创建进程统计表”拖拽一个 【执行一个SQL脚本】 组件,在私有数据库中建一张表 program_stats,后续的统计结果会全存入这里。
CREATE TABLE program_stats (
program_name VARCHAR(255) NOT NULL, -- 程序/软件名称
user_count INT NOT NULL -- 使用用户数
);
-
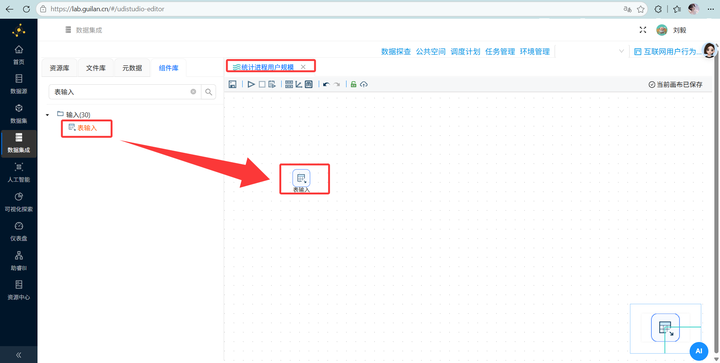
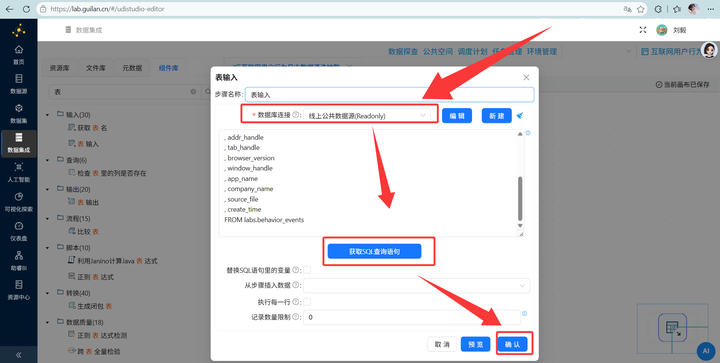
步骤二:读取行为明细数据 新建转换流“统计进程用户规模”,拖拽 【表输入】 组件到画布中,连接“团队私有数据库”,获取 behavior_events 表的所有 SQL 查询语句。
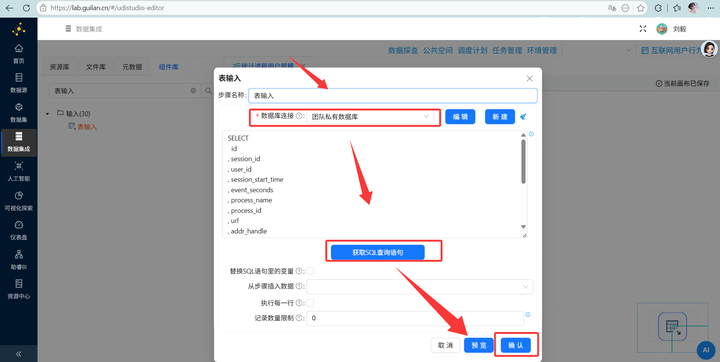
-
步骤三:精准字段瘦身 统计进程用户数,我们只需要用到 user_id 和 process_name 两个字段。拖拽 【字段选择】 组件连上表输入,双击进去后点击“移除”Tab 选项页,右键“获取字段”后,选中这两个字段并将它们删除,点击“确认”。
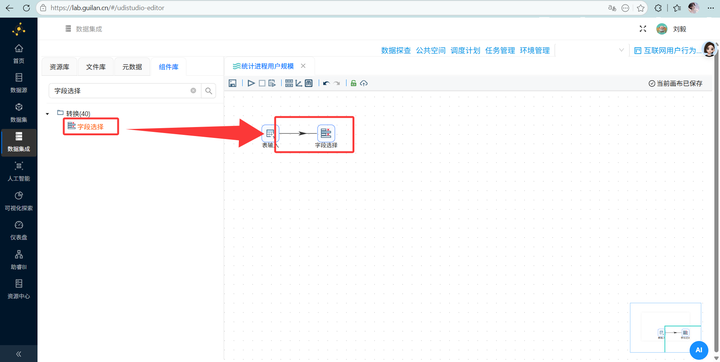
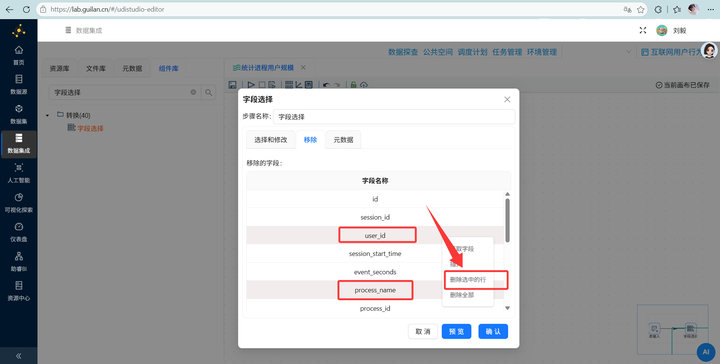
-
步骤四:处理烦人的空值(容错处理) 字段 process_name 难免存在空值,这会导致后续报错!拖拽 【替换NULL值】 组件。双击配置:勾选“选择字段”,在下方插入一行,字段选 process_name,值替换为填写“未知”。
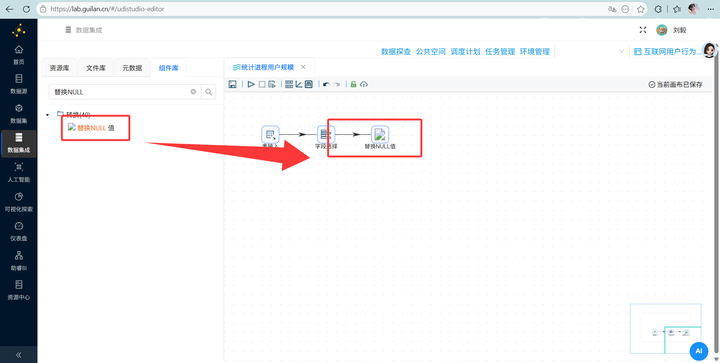
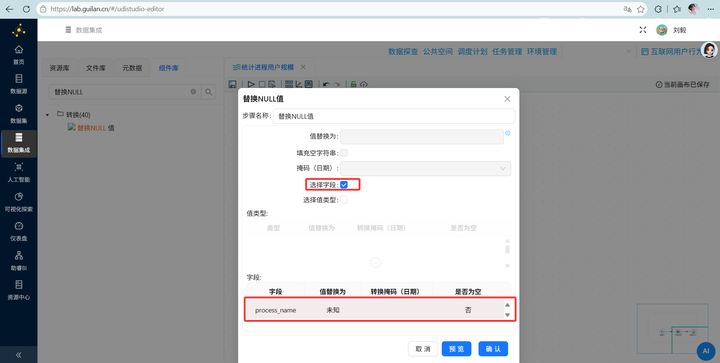
-
步骤五:分组前的必做项——强行排序 (敲黑板!新手最容易在这个地方掉坑)在零代码流中,如果不排序直接分组必定出错。拖拽 【排序记录】 组件并连上一步,双击进入,将数据严格按照 process_name 字段进行升序排列。
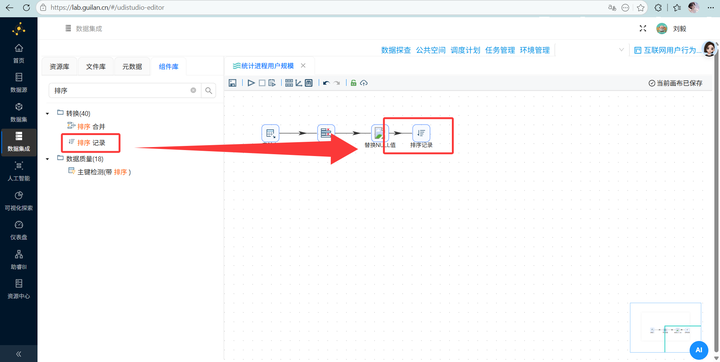
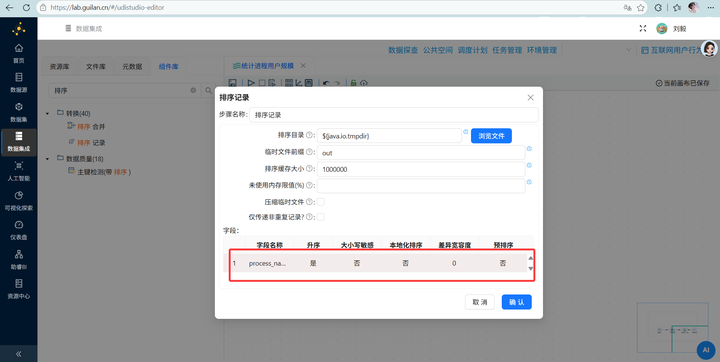
-
步骤六:核心统计——分组聚合 拖拽 【分组】 组件连上排序节点
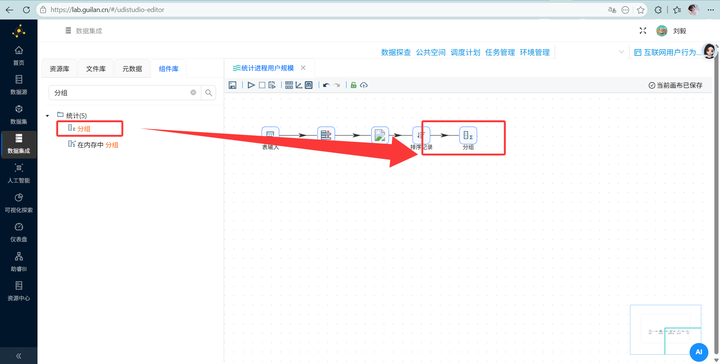
这里的配置分两步:
-
上半部分的分组字段:仅保留 process_name。
-
下半部分的聚合操作:右键插入一个新行,名称输入 user_count,Subject 选 user_id,类型一定要选择 个数。这就完成了按软件名称去统计使用人数!
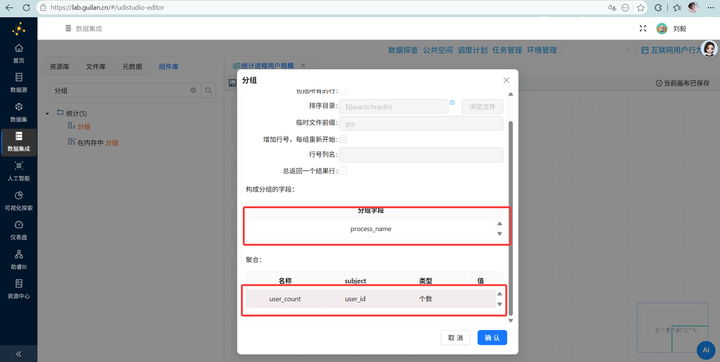
-
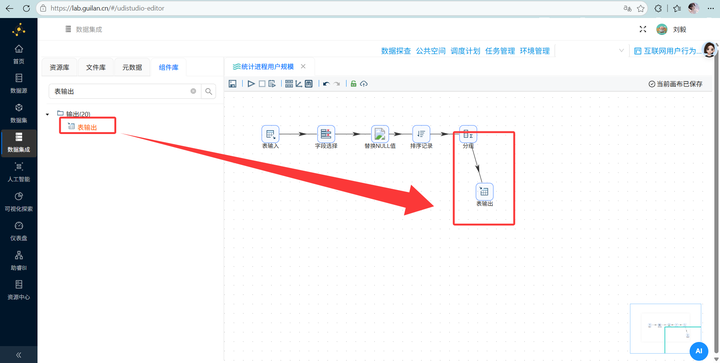
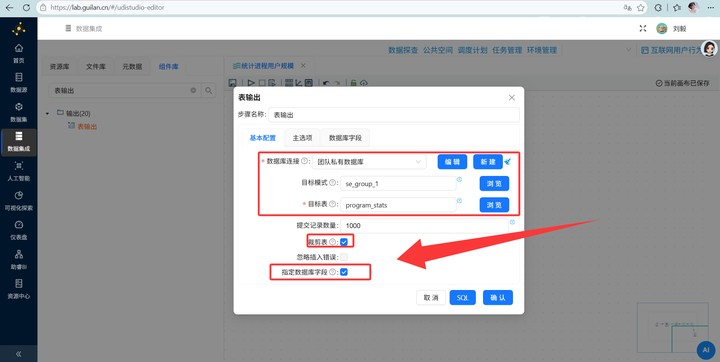
步骤七:结果入库 最后,拖拽 【表输出】 组件并连线。目标连接私有数据库里的 program_stats 表。一定要勾选“裁剪表”(防止重复插入数据),并在“指定数据库字段”处右键获取映射关系。
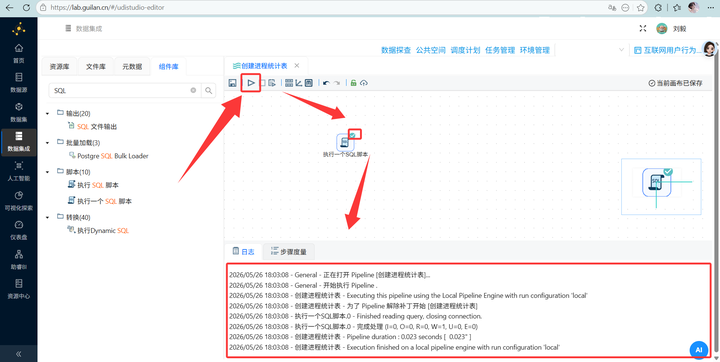
运行转换流:点击“启动”,一气呵成!
3.2 助睿 BI 可视化洞察 (让数据开口说话)
光看刚才算出的死板数据不够直观,我们需要让数据开口说话。这里我们无缝切换到左侧菜单的“助睿 BI”,开启零代码数据看板的制作!
-
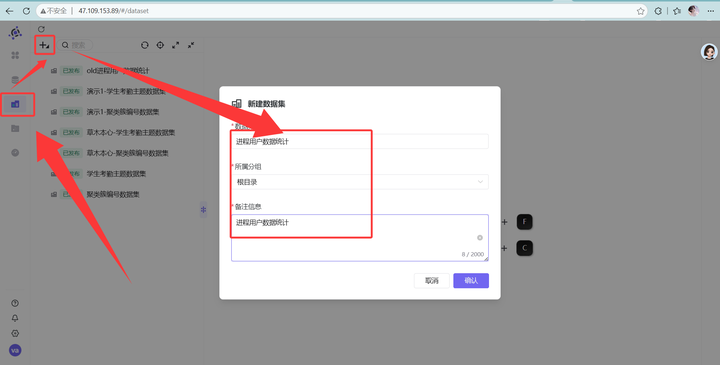
步骤一:新建数据集
-
在 BI 页面点击“数据集”菜单,点击左上角“+ 新建数据集”。在弹窗中,将名称和备注都填入“进程用户数据统计”,点击“确认”。
-
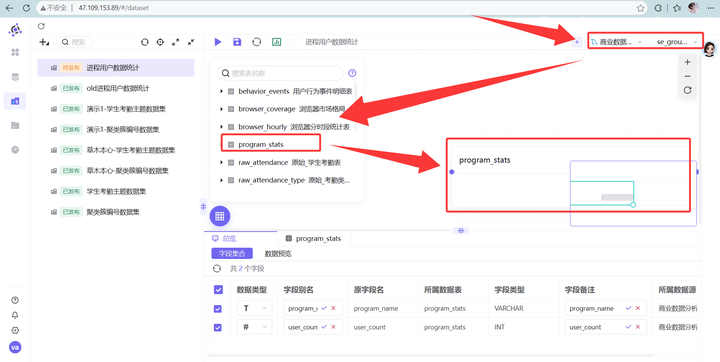
步骤二:引入并处理数据表
-
进入数据集配置页面,在右上角数据源处,找到刚才跑出结果的 program_stats 表(路径为“商业数据分析” -> “labs”),直接把它拖拽到中间的空白画布里。为了后续做图表看着舒服,我们可以双击下方的字段,顺手把字段备注改成对应的中文。修改完后,点击右上角“保存”并发布该数据集。
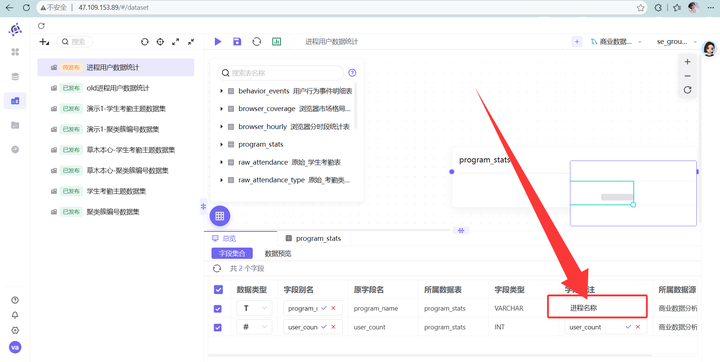
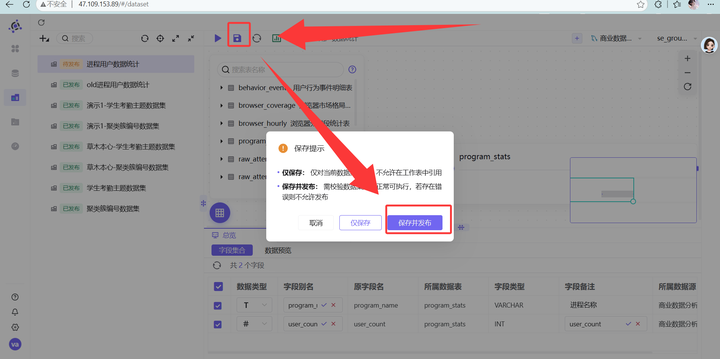
-
步骤三:创建可视化工作表
-
左侧菜单点击“工作表”,点击“+ 新建工作表”,填好工作表名称。接着进入图表编辑页,在左上角“选择数据集”下拉框里选中刚才建好的“进程用户数据统计”,然后在下方的图表类型里,果断选择 “水平条图”。
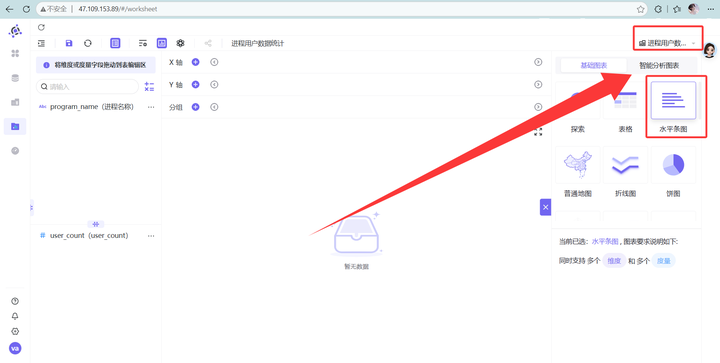
步骤四:拖拽生成图表
见证奇迹的时刻!将左侧列表中的 program_name 字段直接拖拽到 Y轴 的框中,再把 user_count 拖拽到 X轴 的框中。为了视觉效果更具冲击力,点击X轴中 user_count 的下拉设置,将其设置为降序排列。
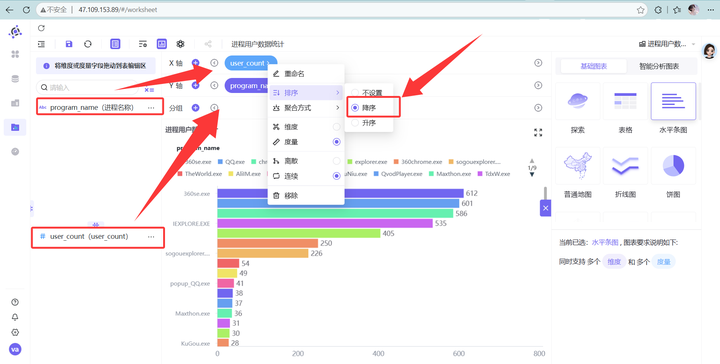
📊 结论出炉:
图表极其清晰地显示出,浏览器类进程(chrome.exe、360chrome.exe、sogouexplorer.exe、QQBrowser.exe 等)的用户数呈断层式碾压其它办公软件(如 Word、Excel)!由于浏览器天然会产生丰富的 URL 访问记录,分析潜力和价值极高。因此,我们敲定最终方向:全面围绕浏览器开展深挖探索!
Step 4:高阶特征工程(时长计算与多维特征衍生)
这里是整场实验的重头戏,我们将搭建一个极其优美的多分支复杂 ETL 流! 先创建两个转换流“创建浏览器的用户数总使用时长统计表”、“创建每个浏览器按小时统计活跃用户数统计表”,分别用 SQL 创建两张结果表:browser_coverage(覆盖率与总时长):
CREATE TABLE `browser_coverage` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
`user_count` INT NOT NULL COMMENT '使用用户数(去重)',
`total_duration_sec` BIGINT NOT NULL COMMENT '总使用时长(秒)'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器用户覆盖率与总时长';
browser_hourly(每小时活跃人数):
CREATE TABLE `browser_hourly` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
`hour` TINYINT NOT NULL COMMENT '小时(0-23)',
`active_user_count` INT NOT NULL COMMENT '活跃用户数',
PRIMARY KEY (`browser_name`, `hour`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器按小时活跃用户数';
深呼吸,看懂下面这个“神仙”数据清洗工作流:
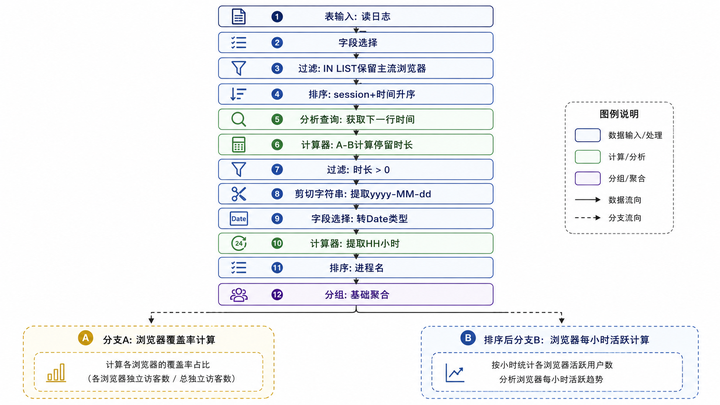
我们一步一步来盘,这里的每一步组件配置都极其精妙,千万别漏看:
-
4.1 读取全量行为日志
-
新建转换流“互联网用户行为日志数据清洗抽取”,拖拽 【表输入】 组件到画布。
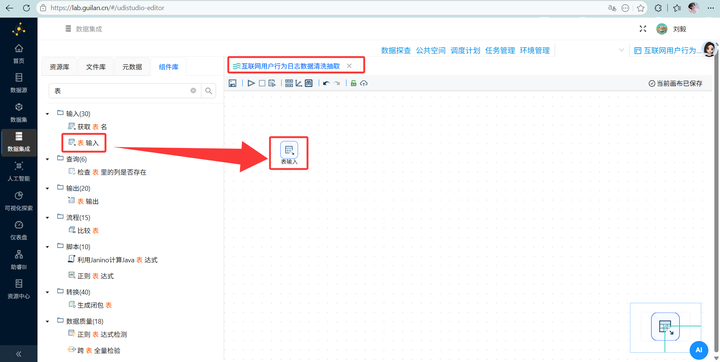
为了分析全貌,这次我们直接连接线上公共数据源,获取 behavior_events 表的所有 SQL 查询语句。
-
4.2 精准瘦身
-
剔除冗余字段 拖拽 【字段选择】 连线上一步。
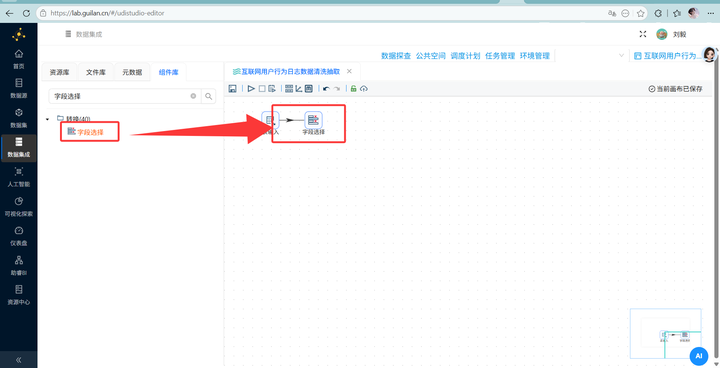
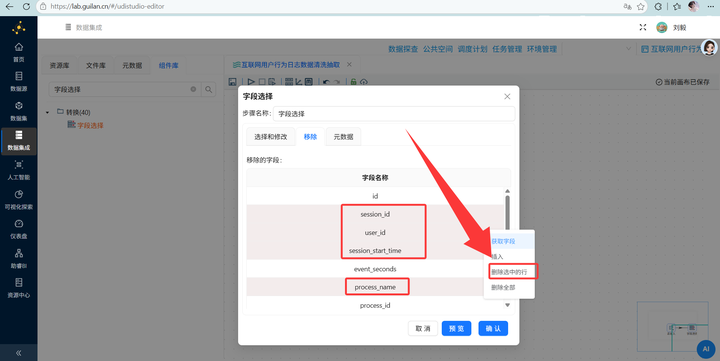
在“移除”Tab页里,获取所有字段。然后我们选中 session_id, user_id, session_start_time, process_name, url, event_seconds 这几个核心字段并“删除选中的行”——注意!这里的逻辑是“把不需要移除的拿走”,留在列表里的才是会被删掉的废弃字段!
-
4.3 过滤大招
-
锁定目标浏览器进程 只分析浏览器怎么做?拖入 【过滤记录】 组件连线。
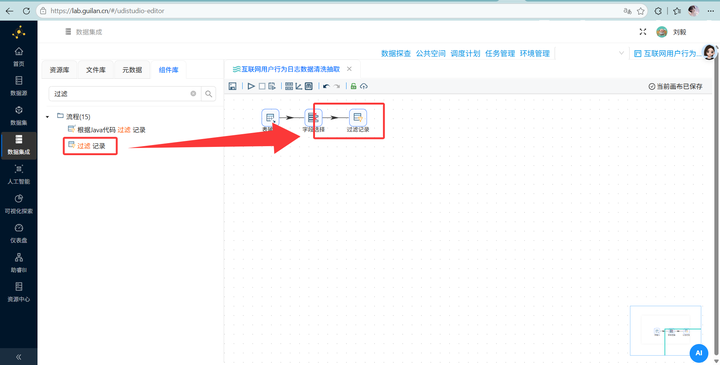
再拖入【排序记录】,连接线类型选择“True输出”、【空操作 (什么也不做)】,连接线类型选择“False输出”
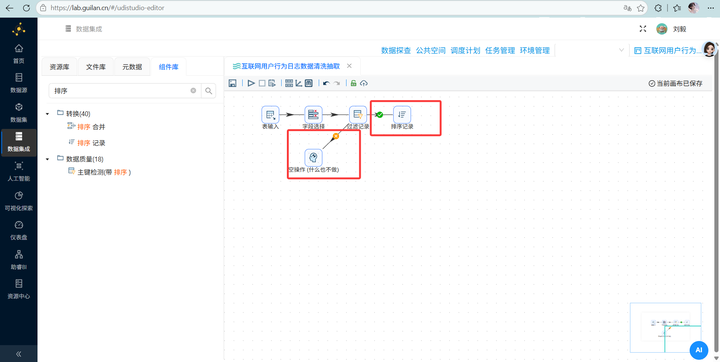
划重点:双击配置:发送匹配的结果给“排序记录”,发送不匹配的结果给“空操作 (什么也不做)”。点击 field 选择 process_name,函数符号选 IN LIST,值填入我们发现的几大主流浏览器和软件集合(iexplore.exe;360chrome.exe;360se.exe;chrome.exe;sogouexplorer.exe;EXCEL.EXE;WINWORD.EXE;AlilM.exe;QQBrowser.exe)。
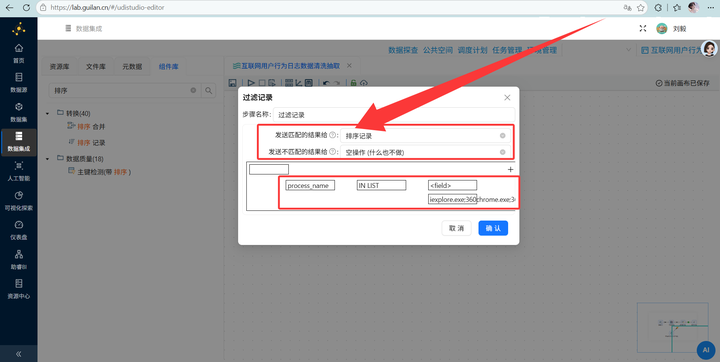
4.4 封神操作
利用窗口函数计算停留时长 日志里只有事件发生时间,没有“停留时长”,怎么办?这就是体现 ETL 功底的地方了!
-
先双击 【排序记录】,按 session_id 和 event_seconds 升序排列(确保同一个会话内按时间排序)。
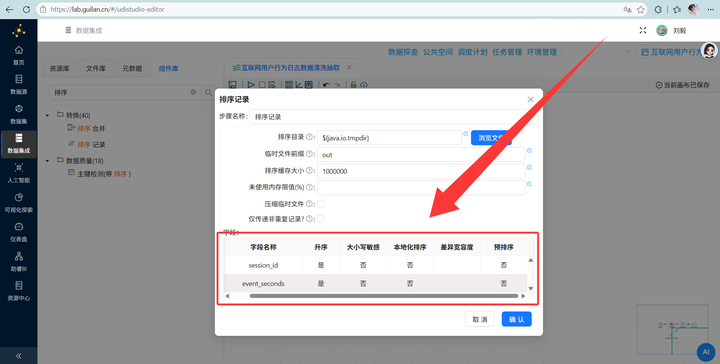
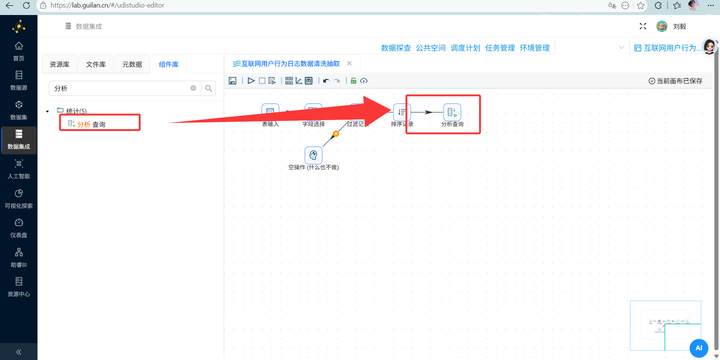
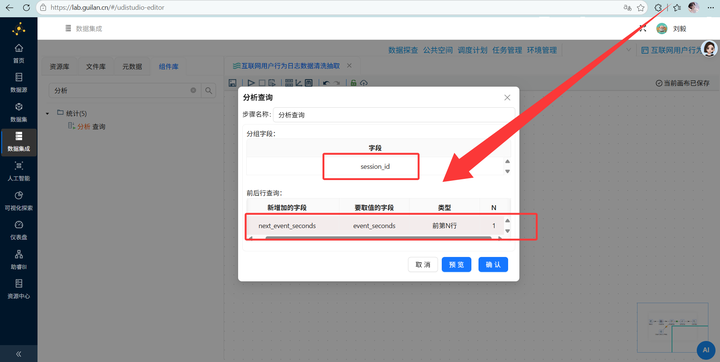
2. 接着拖入 【分析查询】(这就相当于 SQL 的 LEAD 窗口函数),分组字段选 session_id。设置新字段名为 next_event_seconds,要取值的字段选 event_seconds,类型选“前第1行”。这就把下一条记录的时间抓过来了!
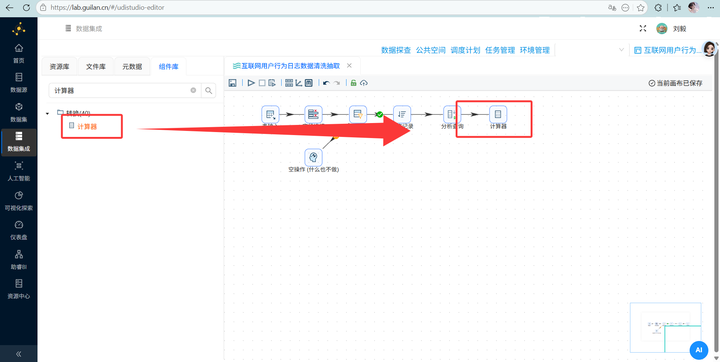
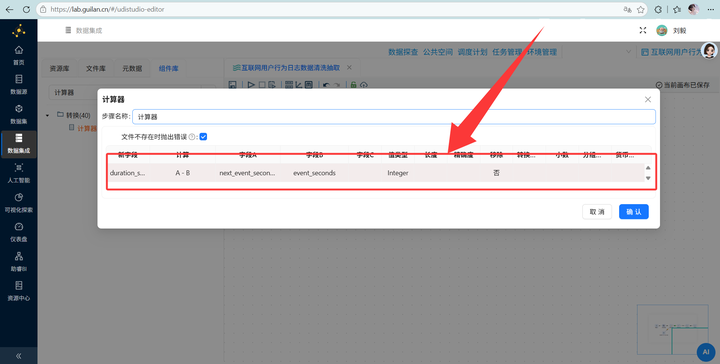
3. 最后连上 【计算器】,新建字段 duration_sec,计算公式选 A - B,字段 A 选刚抓来的 next_event_seconds,字段 B 选原本的 event_seconds,值类型选 Integer。完美算出停留时长!
-
4.5 再次清洗与废数据过滤
-
经过上一步,又产生了一些过渡字段。我们再接一个 【字段选择】,这次老老实实只保留 user_id, process_name, session_start_time, url, duration_sec 这 5 个真核心。
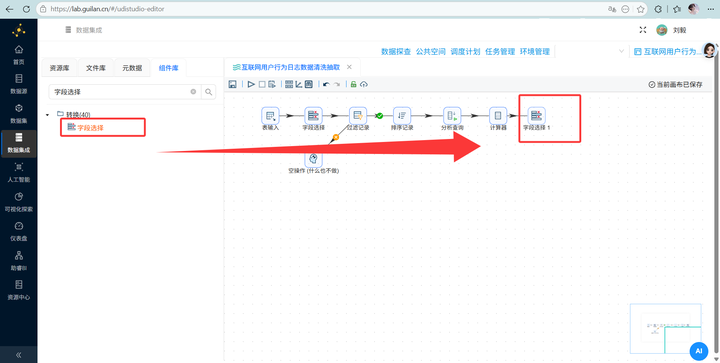
同时接上一个 【过滤记录】,条件设为 duration_sec > 0。因为会话的最后一条记录没有“下一条”,时长可能是负数或无效,必须过滤掉。
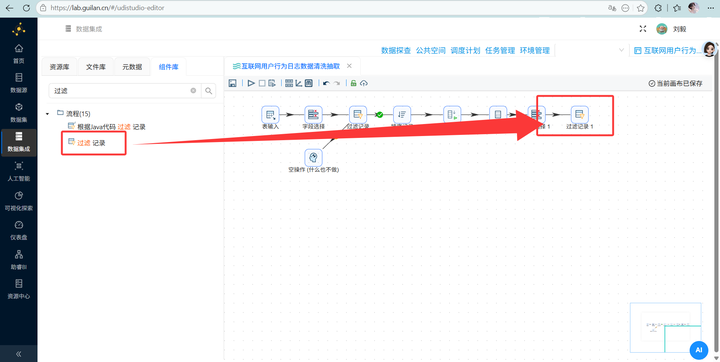
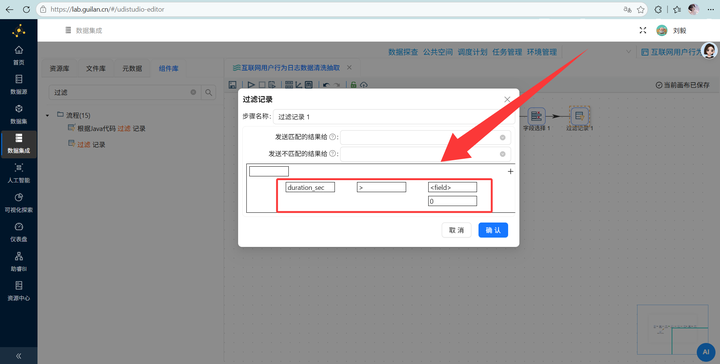
-
4.6 优雅地榨干时间维度
-
时间戳是 yyyy-MM-dd HH:mm:ss,我们得把它拆开,方便后续画日历图和小时热力图。
-
连上 【剪切字符串】 组件,从 session_start_time 里把前面的年月日切出来。
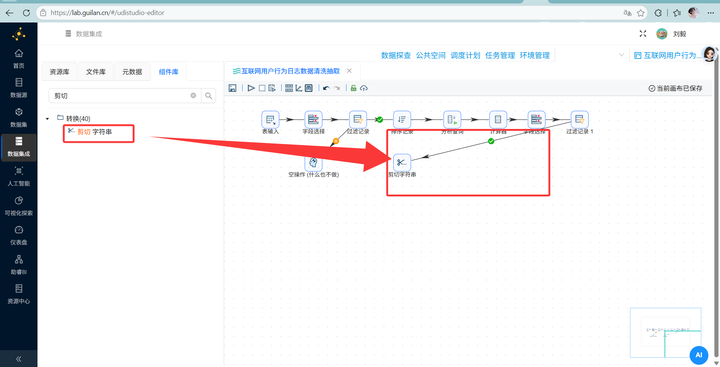
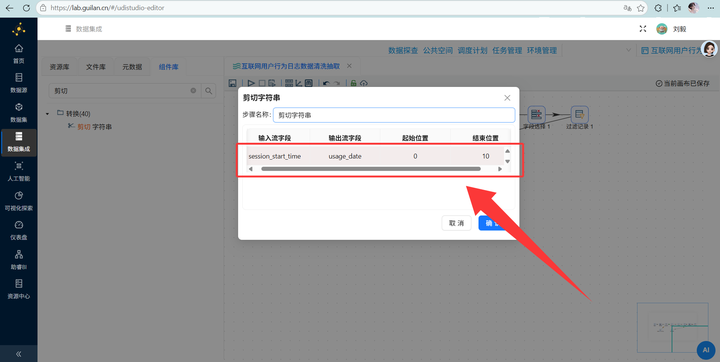
2. 连上 【字段选择】 组件,强行把刚刚的字符串时间改成 Date 日期格式。
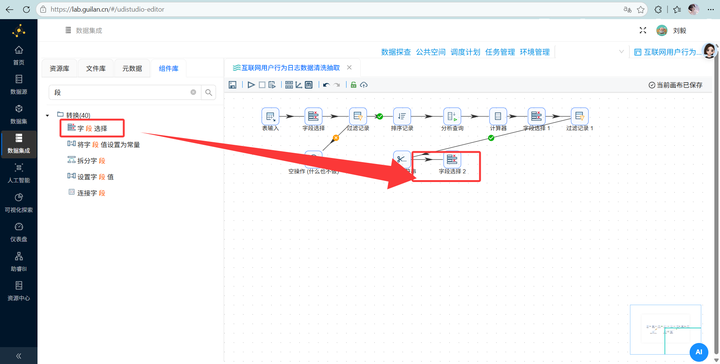
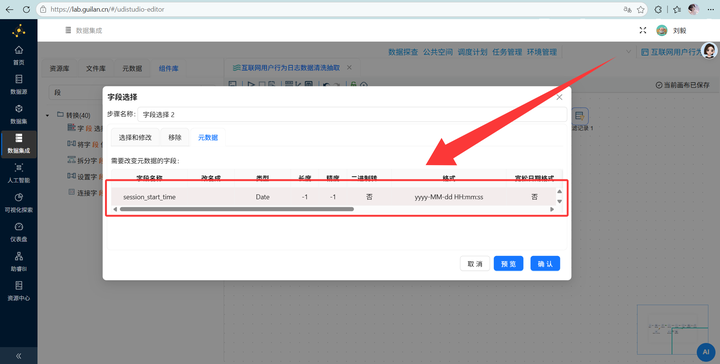
3. 连上 【计算器】 组件,直接提取出 HH(小时),存为备用。
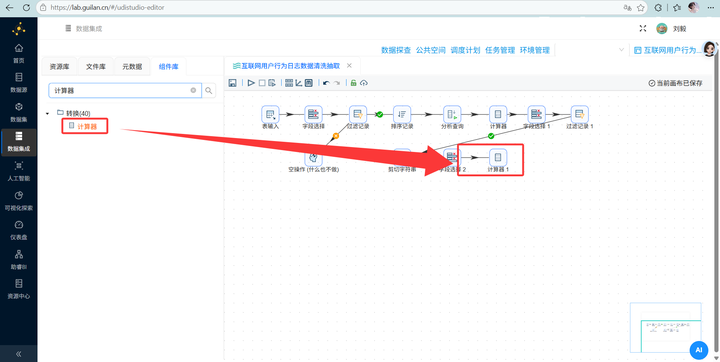
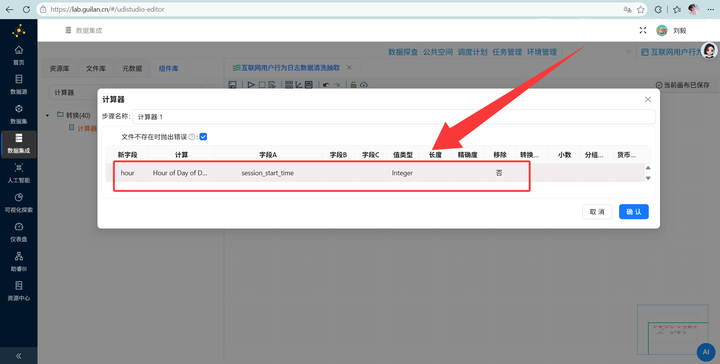
-
4.7 基础粒度打底压缩
-
原始数据太碎了,每次窗口切换就是一条记录。我们先来一次聚合,接上 【排序记录】,按 process_name 排序
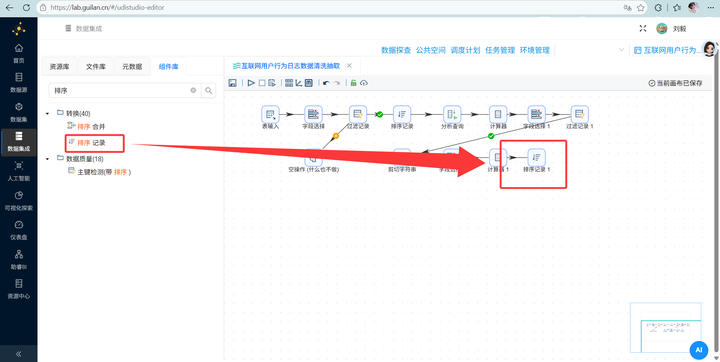
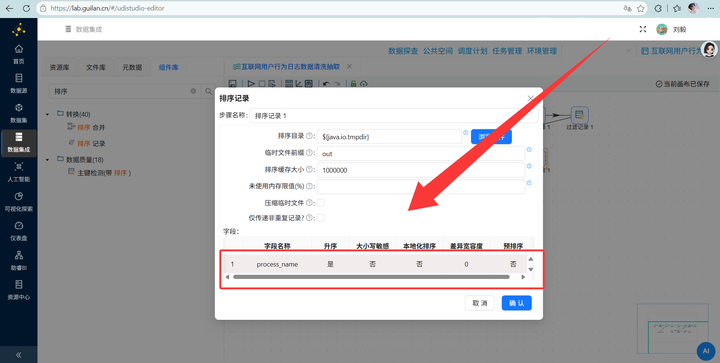
再接上 【分组】 组件,将数据压缩成“用户-日-浏览器-小时”的标准明细,为后面的双分支分流打好地基。
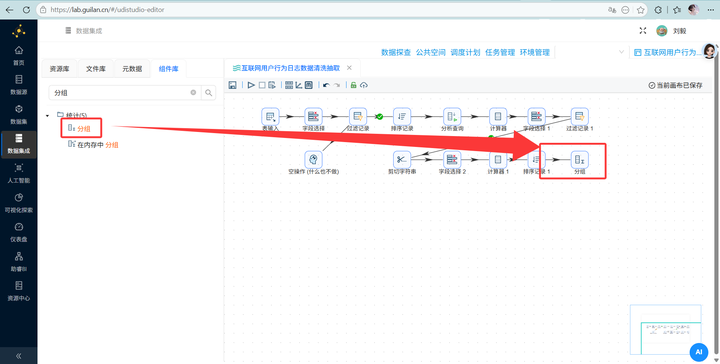
-
4.8分支 A
-
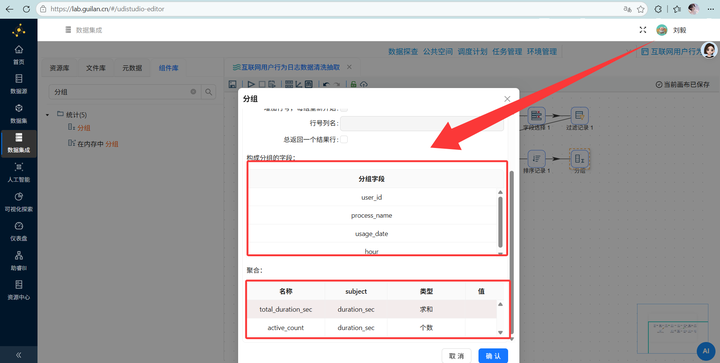
生成市场格局表(覆盖率) 从上一步的分组引出第一根线,连到一个新的 【分组】 组件(分支 A)。 这里只按 process_name 分组,聚合里配置两项:user_count 选个数(算出用户覆盖),total_duration 选求和 SUM(算出累计黏性时长)。
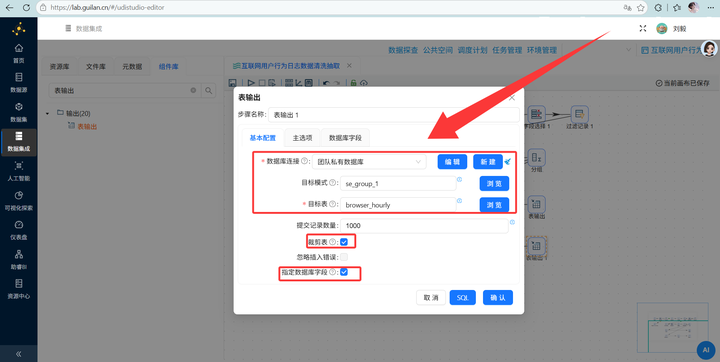
最后,连上 【表输出】,果断写入我们最开始建好的 browser_coverage 表。
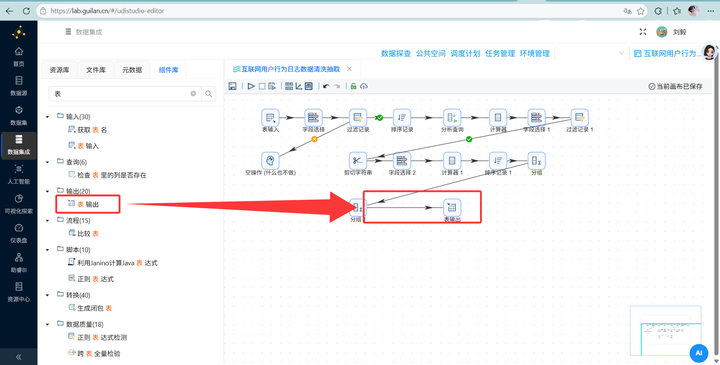
-
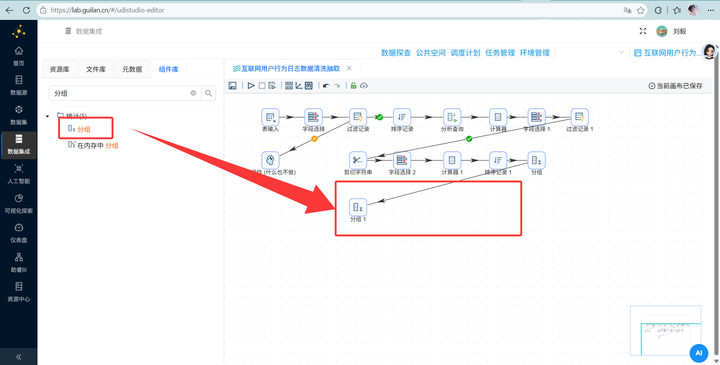
4.9 分支 B
-
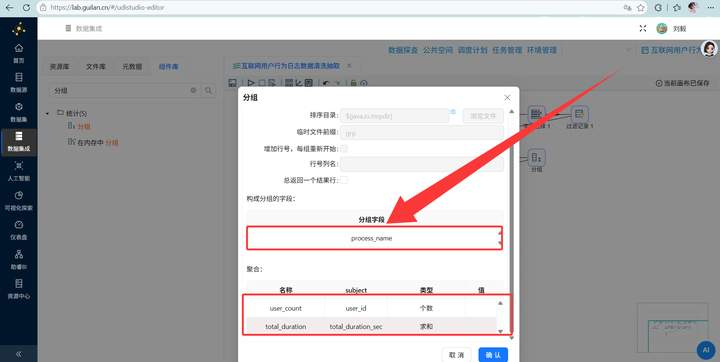
生成时段统计表(小时热力图) 从打底的 4.5.10 步骤拉出第二根线,注意,这里必须先连一个【排序记录】,严格按 process_name 和 hour 两个字段升序排序!
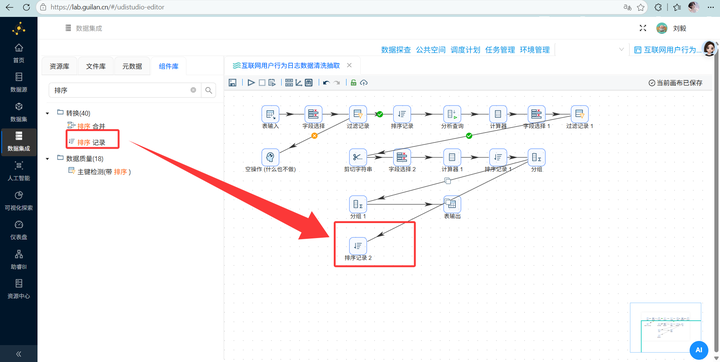
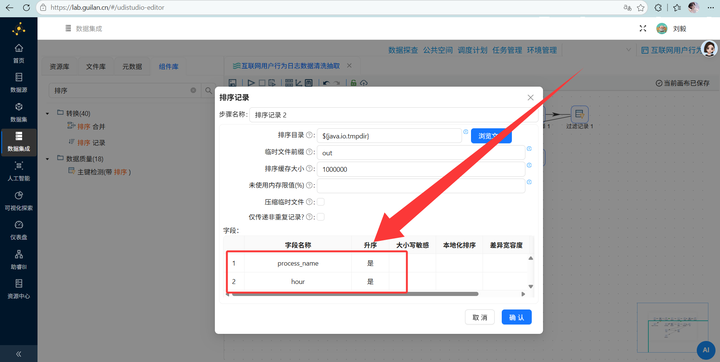
然后连上 【分组】 组件,同样按这两个字段分组,聚合计算 active_user_count(用户 ID 的个数)。
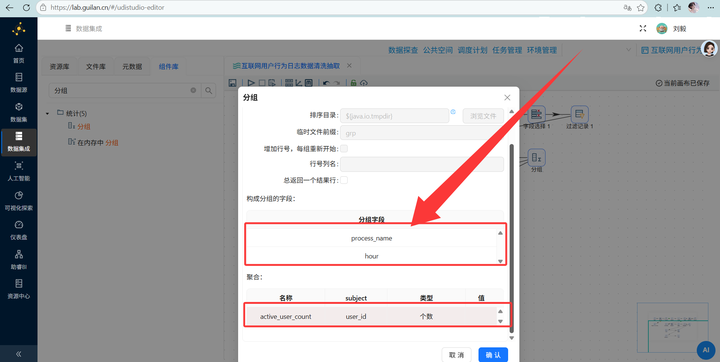
最后连上 【表输出】,数据稳稳落入 browser_hourly 表。
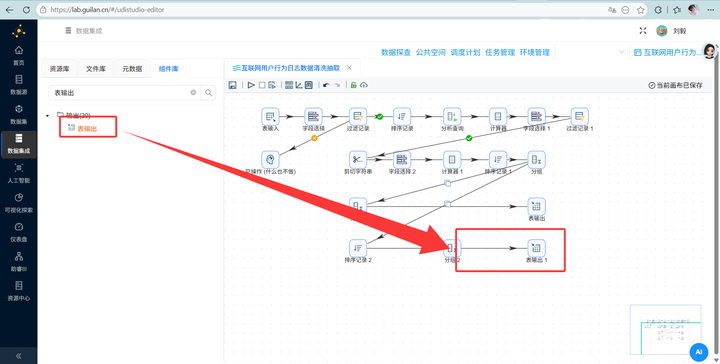
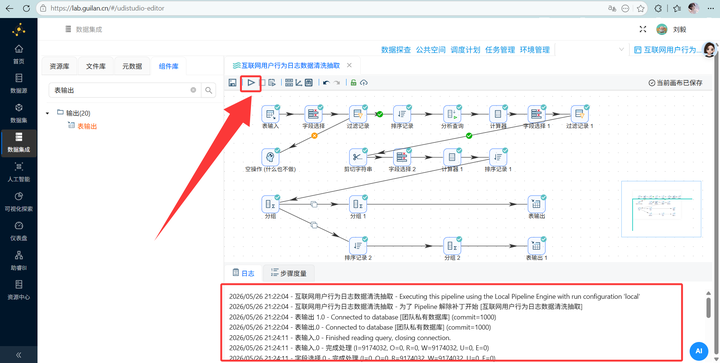
一键点击【启动】! 看着海量数据在两条优美的分支里疯狂流转,绝对是强迫症患者的福音!
🏆 第三部分:实验结果验收
功夫不负有心人,来到“数据探查”模块,验收我们的战利品:
-
脱胎换骨的明细表:原本犹如乱码的半结构化文本,已经被抽丝剥茧,整整齐齐地躺在 behavior_events 表中,成了标准的分析底表。
-
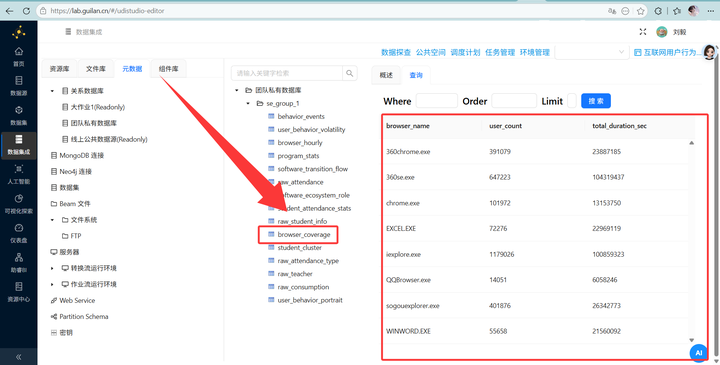
市场格局报表(browser_coverage):清清楚楚地展示了哪款浏览器拥有压倒性的用户基数和使用总时长。
-
用户作息报表(browser_hourly):产出了“浏览器-小时-活跃人数”的黄金维度,直接拿去画趋势折线图,用户的摸鱼时段一览无余!
🛑 第四部分:避坑指南(全网独家血泪经验)
在跑这条千万级数据流的过程中,我可是真金白银地踩过几个大坑!为了大家不走弯路、不熬夜掉头发,特地总结出这份“避雷手册”,做实验前一定要反复默读:
🔥 坑位 1:分组聚合后数据量反而暴增?结果极其离谱!
-
案发现场:很多人受传统 SQL 毒害太深,以为要分组算人数,直接拖一个“分组”组件就万事大吉了。结果跑出来的数据完全对不上,几百万的数据变成了几千万!
-
致命原因:在流式 ETL 引擎中,数据是像水流一样通过节点的。如果流入“分组”组件的数据是乱序的,底层引擎遇到相同的值一旦断开,就会“自作聪明”地重新开一个新组,导致数据被无限撕裂切割!
-
抢救大招:无排序,不分组!这是零代码平台的铁律! 凡是用到【分组】组件的地方,它的上游必须死死绑定一个【排序记录】组件,并且严格按照你要分组的字段进行升序排好,药到病除!
🔥 坑位 2:算出来的“网页停留时长”居然有几万个小时?甚至还是负数!
-
案发现场:兴冲冲地做完“下一条记录减上一条记录”的计算,结果一看表,某个用户在一个网页上停留了 -800 秒,另一个用户停留了 3 年?
-
致命原因:这其实是窗口函数的典型“跨服聊天”灾难。如果在使用【分析查询】提取下一行数据时没有做好边界隔断,A 用户的最后一次操作时间,就会去无情地减掉紧挨着他的 B 用户的第一次操作时间。
-
抢救大招:在【分析查询】组件的配置里,一定要将 session_id(会话ID)老老实实地设置为分组字段,把计算严格框死在每一次单独的开机行为里!同时,在结尾务必挂一个【过滤记录】组件,把 时长 <= 0 的废数据一刀切掉,保证逻辑无懈可击。
🔥 坑位 3:空值(NULL)不处理,整条流原地爆炸!
-
案发现场:数据流跑到一半突然报错停止,翻看底层日志,全是一片刺眼的红字:NullPointerException。
-
致命原因:真实的业务数据比你想的脏一百倍!很多记录的 process_name 或者时间戳根本就是空的。如果带着这些“定时炸弹”直接进入分组或计算器组件,系统不仅无法进行聚合匹配,还会直接引发宕机。
-
抢救大招:永远对原始数据保持敬畏!在进行任何高阶处理前,务必习惯性地串联一个【替换NULL值】组件。将文本空值替换为“未知”,将数字空值替换为“0”,这才是高级数据分析师的自我修养!
💡 第五部分:实验总结与心得分享
跑完这一趟数据清洗链路,看着屏幕上规整清爽的宽表和优美的 BI 可视化大屏,我只想大喊一句:助睿零代码平台真的太香了!!!
回顾整个实验过程,感触颇深:
-
底层技能的全面洗礼(从语法奴隶到逻辑大师) 以前洗数据,80% 的时间都在和 Python 语法较劲、在 StackOverflow 上查报错。这次实验让我彻底弄懂了半结构化日志的解析底层套路,并且第一次如此直观地理解了“窗口函数(分析查询)计算时间差”这种高级特征工程玩法。当工具门槛被抹平后,我发现自己终于有精力去思考真正的业务分析逻辑了。
-
生产力效率的降维打击(告别脱发,拥抱准点下班) 如果你手写过 Pandas 处理千万级数据的合并与清洗,你一定懂那种“跑一次要等十分钟,错了一个标点符号全部推翻重来”的痛苦。而在助睿 ETL 平台这种“拖拉拽”的环境里,“所见即所得”让 debug 变成了极其轻松的点选。复杂的聚合和多分支流转在画布上一目了然,效率简直是坐火箭攀升。
-
生态闭环的极致体验(丝滑到不可思议) 过去我们做数据分析,清洗在 Python,存储在 MySQL,做表又要导到 Tableau,中间来回折腾数据接口极其痛苦。而助睿数智(Uniplore)真正做到了生态大闭环!上游刚才用 ETL 节点洗出来的温热数据,下游无需任何代码配置,立刻就能在助睿 BI 模块里拖拽成极具视觉冲击力的图表。这种一气呵成的成就感,真的是谁用谁知道!
最后想说,数据清洗绝不是纯粹的苦力活,找对了工具和方法,它就是一场享受创造过程的艺术! 如果你也是深陷数据泥潭的分析师、或者是正在头疼不知道如何处理毕设数据的同学,强烈建议去亲自体验一下这套流程!
🎉 觉得这篇保姆级教程对你有帮助的话,千万别忘了【点赞】、【在看】和【收藏】哦!你们的支持是我持续输出干货的最大动力!
💬 在处理海量数据时你踩过哪些离谱的坑?对于零代码 ETL 还有什么疑问?欢迎在评论区留言,我们一起交流探讨~ 👇

一站式 AI 云服务平台
更多推荐


 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)