
浏览器市场与用户画像分析-数据加工
半结构化日志解析:掌握基于Java代码组件的自定义格式日志拆分方法,包括文件名信息提取与日志体字段分割。零代码ETL组件串联:熟练运用字段选择、过滤记录、排序、分析查询、计算器、分组聚合、表输出等核心组件,理解组件间的数据流转逻辑。典型指标加工:实现了停留时长计算、日期小时维度衍生、多粒度分组去重等数据分析中的常见操作。数据质量治理:针对字段类型错误、时长负值、分组去重遗漏、配置路径异常等问题进行
1 背景与目标
本实验数据来源于首届中国互联网数据挖掘竞赛公开数据集:1000名用户连续4周的电脑操作日志,总规模约825MB,累计800余万条行为记录。日志采用半结构化格式,字段间以 [=] 分隔:
T<=>秒数[=]P<=>进程名[=]I<=>进程ID[=]U<=>URL[=]N<=>程序名[=]C<=>公司
文件名格式为 user_id_日期_开机时间.txt,可从中提取用户ID与会话起始时间。
实验目标是将批量原始日志加工为两张标准指标表:
- browser_coverage:各浏览器用户覆盖率与总使用时长
- browser_hourly:各浏览器分小时活跃用户数
全过程依托助睿零代码ETL平台(Uniplore),通过可视化组件配置完成,无手工编码环节。
2 数据源与加工流程
2.1 数据来源
| 数据源 | 说明 | 关键信息 |
|---|---|---|
| 行为日志TXT(20个文件) | 用户操作行为明细 | 文件名含user_id、日期、开机时间;日志体含T/P/U等字段 |
| demographic.csv | 用户人口属性 | user_id、性别、年龄、职业、收入 |
2.2 加工链路
日志文件采集 → 解析结构化 → 清洗过滤 → 时长/日期/小时衍生 → 维度聚合 → 结果入库
2.3 加工口径
| 规则项 | 说明 |
|---|---|
| 浏览器范围 | iexplore.exe、360chrome.exe、360se.exe、chrome.exe、sogouexplorer.exe、QQBrowser.exe |
| 停留时长 | 同一会话内相邻记录的 event_seconds 差值,剔除 ≤0 的无效记录 |
| 日期与小时 | 从 session_start_time(yyyy-MM-dd HH:mm:ss)截取 |
| 聚合粒度 | 浏览器级(browser_coverage)/ 浏览器×小时级(browser_hourly) |
3 实验操作过程
3.1 创建项目与数据导入
登录助睿平台ETL模块,新建项目"互联网用户行为日志数据加工"。
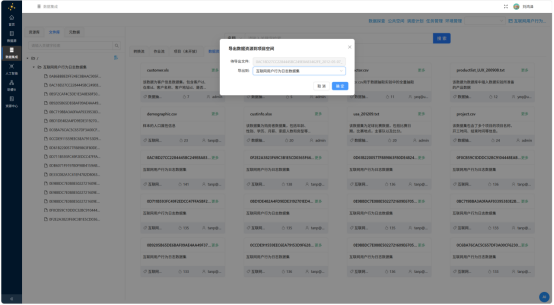
进入项目文件库,新建目录"互联网用户行为日志数据集",从公共空间依次导出20个实验日志文件至该目录。
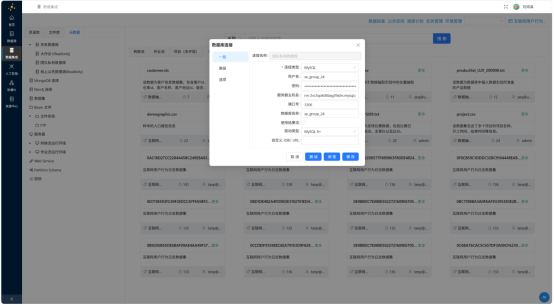
数据库连接复用团队已有私有数据库配置。
3.2 日志解析与结构化
3.2.1 创建行为事件明细表
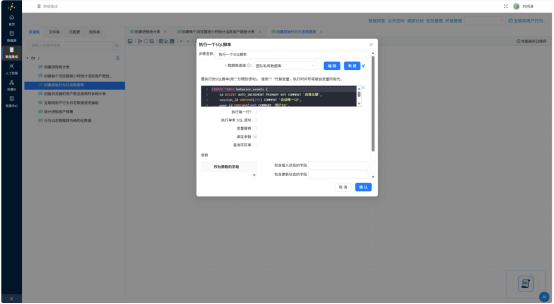
新建转换流,使用"执行一个SQL脚本"组件,在目标数据库创建 behavior_events 表:
CREATE TABLE behavior_events (
id BIGINT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键',
session_id VARCHAR(255) COMMENT '会话唯一ID',
user_id VARCHAR(100) COMMENT '用户ID',
session_start_time VARCHAR(50) COMMENT '会话开始时间',
event_seconds INT COMMENT '事件发生秒数',
process_name VARCHAR(255) COMMENT '进程名称',
process_id VARCHAR(100) COMMENT '进程ID',
url TEXT COMMENT '访问网址',
addr_handle VARCHAR(255) COMMENT '地址栏句柄',
tab_handle VARCHAR(255) COMMENT '标签页句柄',
browser_version VARCHAR(100) COMMENT '浏览器版本',
window_handle VARCHAR(255) COMMENT '窗口句柄',
app_name VARCHAR(255) COMMENT '程序名称',
company_name VARCHAR(255) COMMENT '开发公司',
source_file VARCHAR(255) COMMENT '原始日志文件名',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
INDEX idx_session_id (session_id),
INDEX idx_user_id (user_id)
) COMMENT '用户行为事件明细表';
选择目标数据库后执行该转换流。
3.2.2 日志解析管线
新建转换流"行为日志数据转为结构化数据",由四个组件串联构成:
- 获取文件名——指定日志存放目录,批量读取所有TXT文件路径
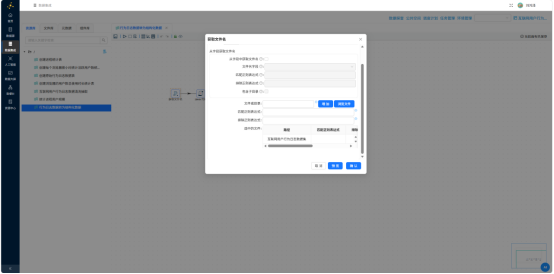
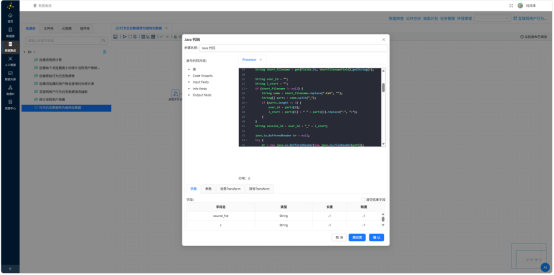
- Java代码——编写解析逻辑:从文件名拆分 user_id、日期、开机时间;从日志体按
[=]分隔符拆分 T、P、I、U、N、C 等字段
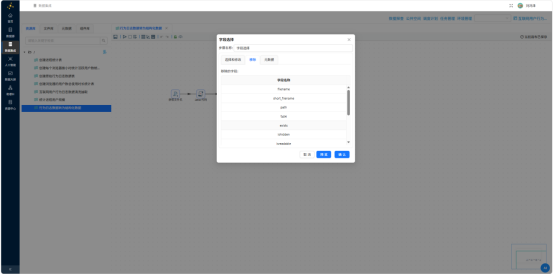
- 字段选择——移除解析产生的中间字段,仅保留核心输出列
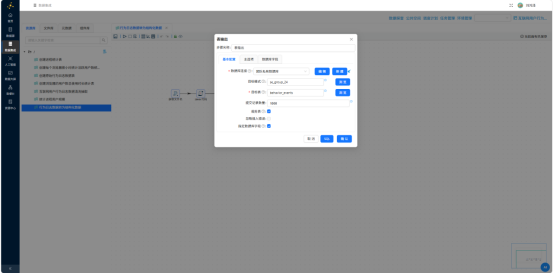
- 表输出——映射字段至
behavior_events表,勾选"裁剪表"
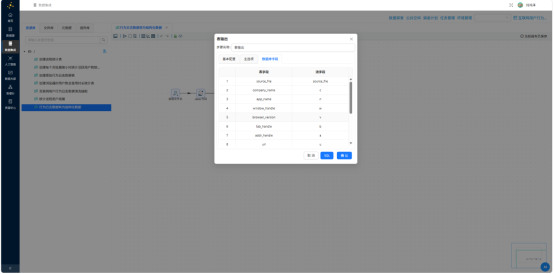
3.2.3 执行与验证
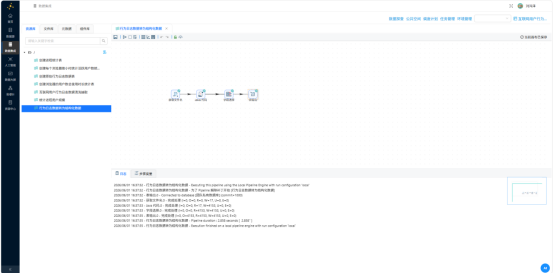
转换流配置完成后,点击工具栏"执行"并以默认配置启动,执行过程中通过日志页面查看进度。
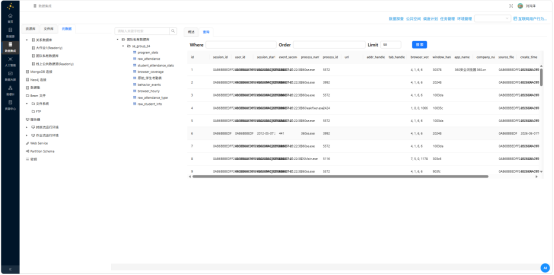
执行完毕后加载元数据,查询 behavior_events 表,确认数据量与字段均无误。
3.3 进程用户规模统计——确定分析方向
在聚焦浏览器分析之前,先对全体进程进行一次用户规模统计,以验证浏览器是否为正确的分析目标。
3.3.1 建表与聚合
新建转换流,使用SQL组件创建 program_stats 表:
CREATE TABLE program_stats (
program_name VARCHAR(255) NOT NULL,
user_count INT NOT NULL
);
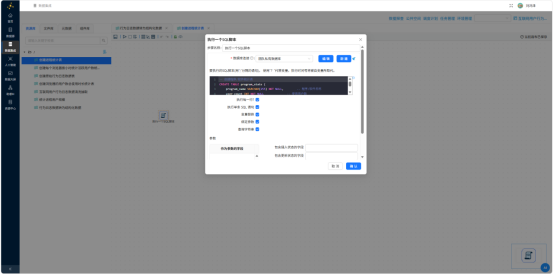
执行该转换流,通过日志页面查看进度。
再新建转换流"统计进程用户规模",组件链路如下:
表输入——读取 behavior_events 中的 user_id 与 process_name:
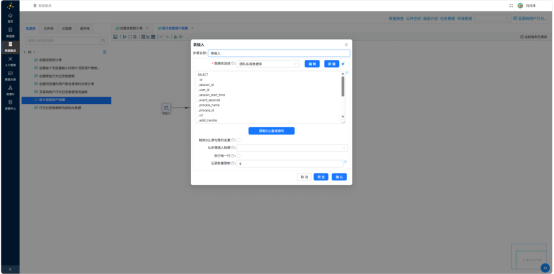
字段选择——仅保留 user_id、process_name:
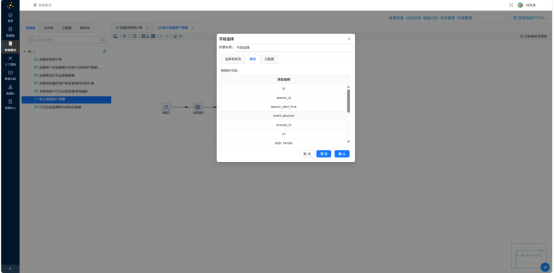
替换NULL值——process_name 为空时填充为"未知":
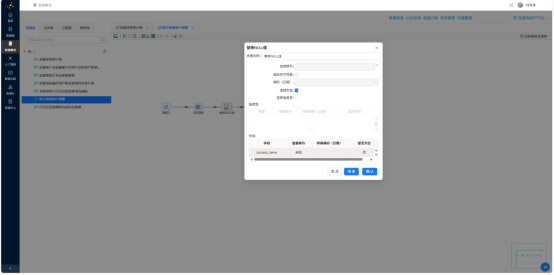
排序记录——按 process_name 排序:
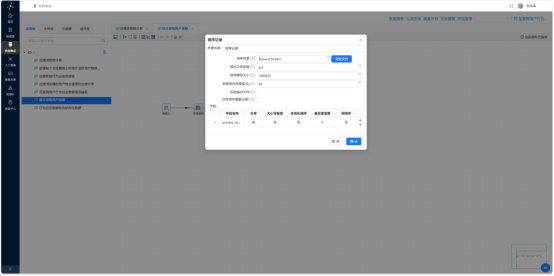
分组——按 process_name 分组,user_count = COUNT(user_id):
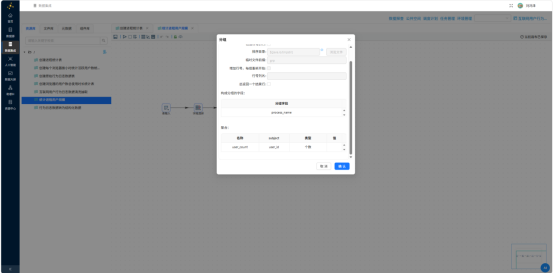
表输出——写入 program_stats:
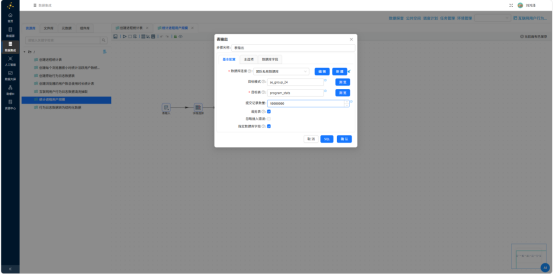
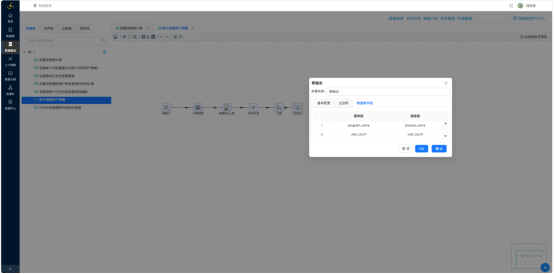
执行结果:
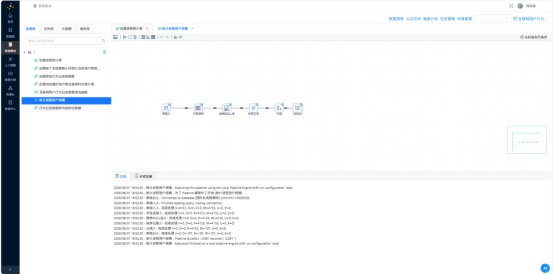
3.3.2 BI可视化验证
将 program_stats 表接入助睿BI模块,生成水平条图:Y轴 program_name,X轴 user_count(降序排列)。
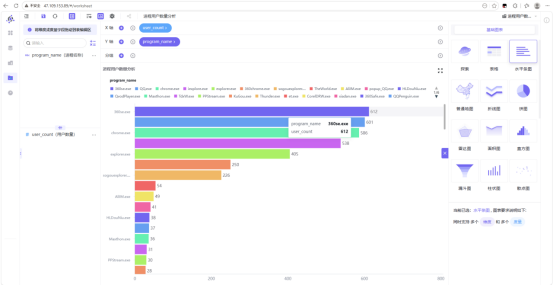
图表显示浏览器类进程用户数显著高于其他类别,确认浏览器为正确的分析方向。
3.4 创建目标结果表
在数据清洗与聚合之前,先建立两张目标表的结构。分别新建两个转换流,各配置一个SQL组件:
CREATE TABLE browser_coverage (
browser_name VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
user_count INT NOT NULL COMMENT '使用用户数(去重)',
total_duration_sec BIGINT NOT NULL COMMENT '总使用时长(秒)'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器用户覆盖率与总时长';
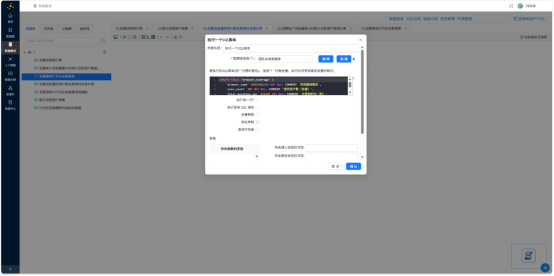
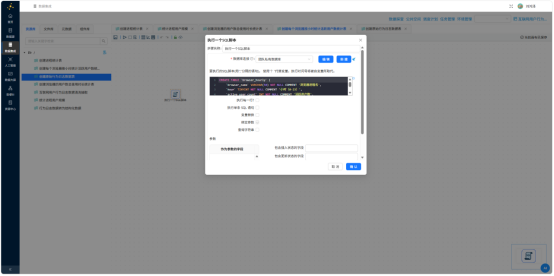
CREATE TABLE browser_hourly (
browser_name VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
hour TINYINT NOT NULL COMMENT '小时(0-23)',
active_user_count INT NOT NULL COMMENT '活跃用户数',
PRIMARY KEY (browser_name, hour)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器按小时活跃用户数';
分别执行两个转换流即完成建表。
3.5 核心加工:从明细数据到分析指标
本步骤是整个实验的核心环节。创建转换流"互联网用户行为日志数据清洗抽取",将原始明细逐层加工为两份统计指标表。
3.5.1 数据读取与字段筛选
使用"表输入"读取 behavior_events 全量数据,再通过"字段选择"仅保留6个核心字段:session_id、user_id、session_start_time、process_name、url、event_seconds。
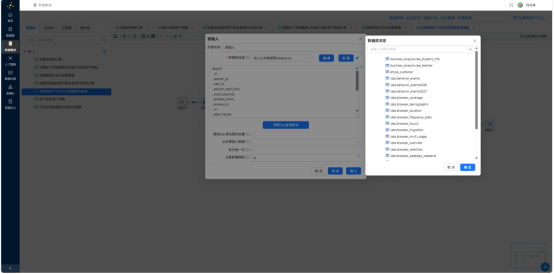
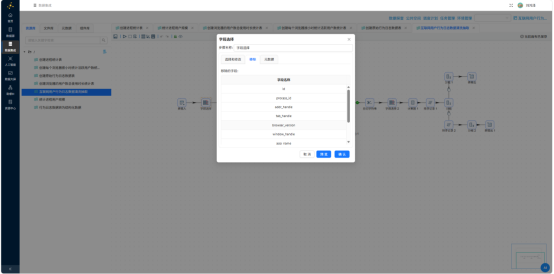
再用"过滤记录"组件,设置条件筛选6款目标浏览器进程:
process_name IN ('iexplore.exe','360chrome.exe','360se.exe','chrome.exe','sogouexplorer.exe','QQBrowser.exe')
经过此步,数据量大幅缩减,仅保留分析范围内的记录。
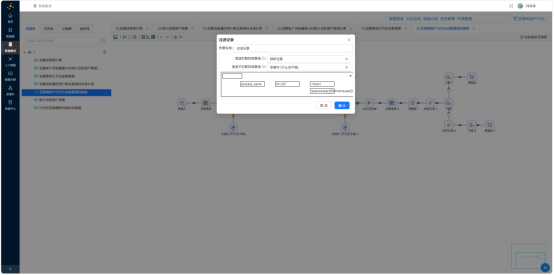
3.5.2 计算停留时长
停留时长定义为同一会话内相邻两条记录的 event_seconds 差值,分三步实现:
- 排序记录——按 session_id、event_seconds 排序
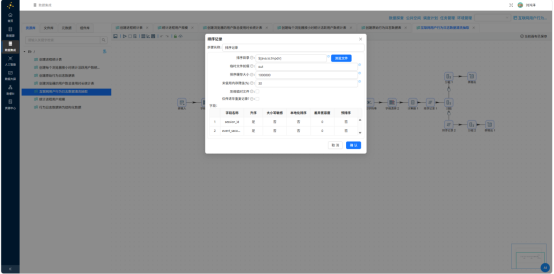
- 分析查询——取同一会话下一行的 event_seconds,记为 next_event_seconds
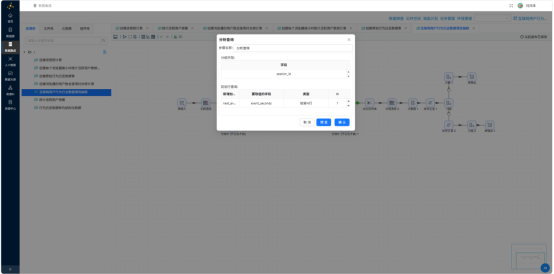
- 计算器——duration_sec = next_event_seconds - event_seconds
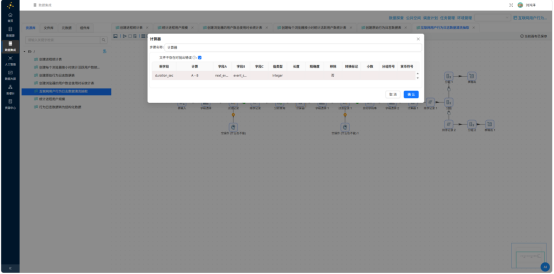
3.5.3 过滤无效数据
通过"字段选择"保留 user_id、process_name、session_start_time、url、duration_sec 五列,再用"过滤记录"剔除 duration_sec ≤ 0 的记录——此类记录主要是各会话的最后一条,因无下一条数据参照而无法计算有效时长。
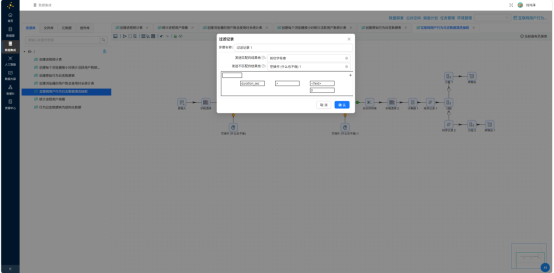
3.5.4 提取日期与小时维度
从 session_start_time 中分别提取日期和小时两个维度:
- 剪切字符串——截取前10位得到 event_date(yyyy-MM-dd)
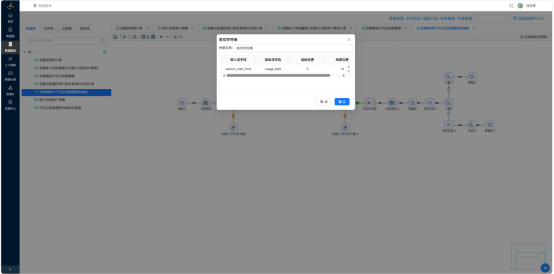
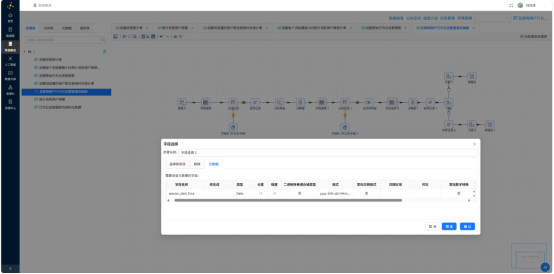
- 字段选择——将 session_start_time 转换为 Date 类型
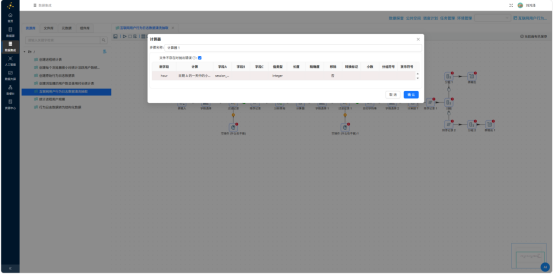
- 计算器——提取 event_hour
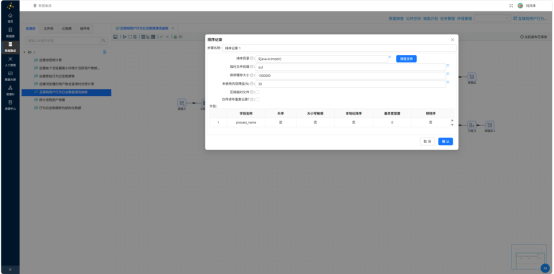
3.5.5 生成用户-日-浏览器-小时明细
按 user_id、process_name、event_date、event_hour 排序后进行分组聚合,得到标准化明细数据,后续所有汇总均以此作为统一数据源。
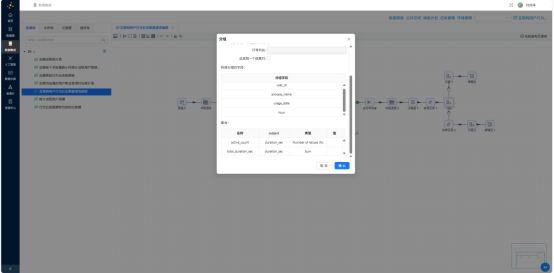
3.5.6 分支A:输出市场格局表
从明细数据引出第一条分支,按 process_name 分组聚合:
- user_count = COUNT(DISTINCT user_id)
- total_duration_sec = SUM(duration_sec)
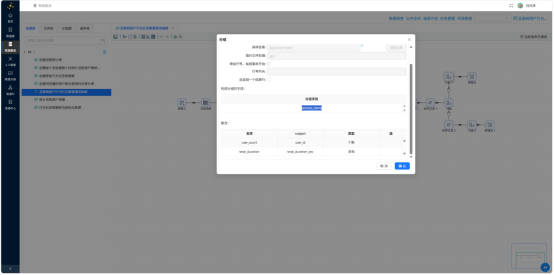
通过"表输出"写入 browser_coverage:
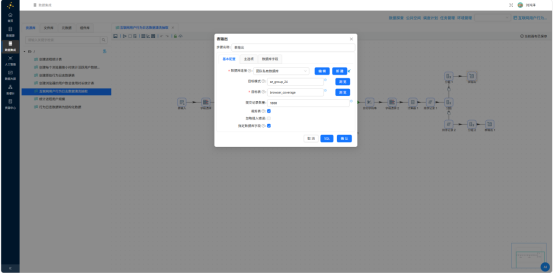
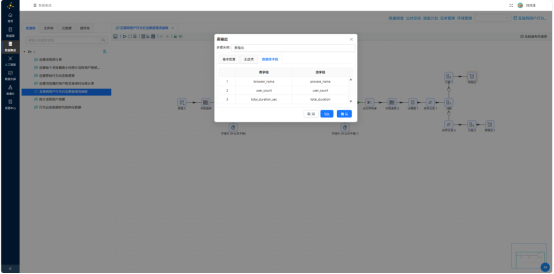
3.5.7 分支B:输出时段统计表
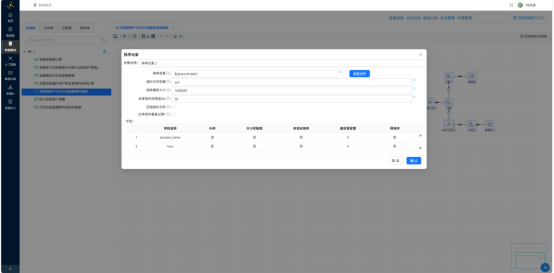
从明细数据引出第二条分支。先按 process_name + event_hour 排序:
再按 process_name + event_hour 分组,active_user_count = COUNT(DISTINCT user_id):
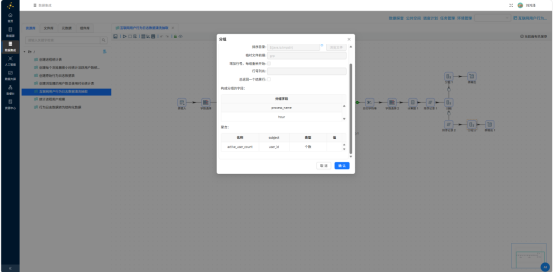
最后通过"表输出"写入 browser_hourly:
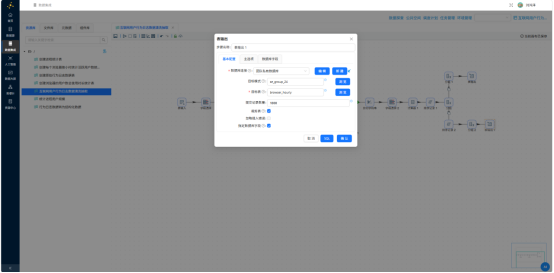
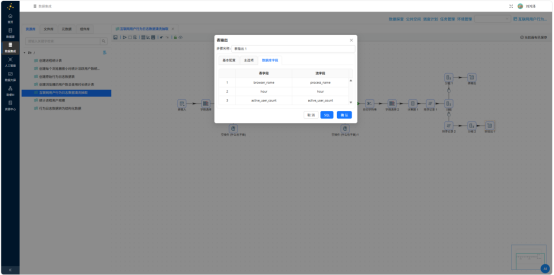
3.5.8 执行与验证
转换流整体配置完毕后,从表输入到两个表输出的完整链路即告贯通。执行转换流,加载元数据,分别查询 browser_coverage 与 browser_hourly:
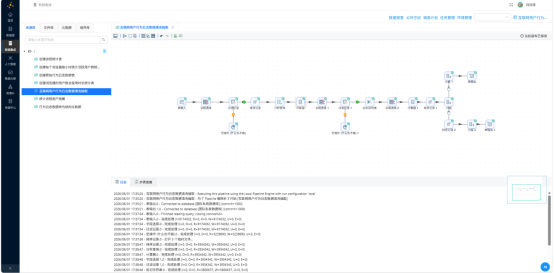
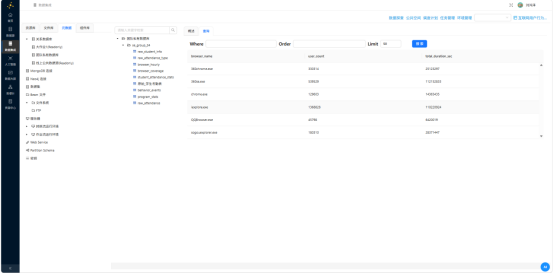
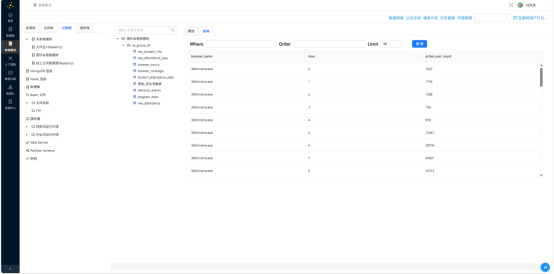
数据聚合结果符合预期,两表就绪。
4 结果验证
| 验证项 | 预期结果 | 实际结果 |
|---|---|---|
| 日志结构化 | 20个文件全量解析入behavior_events | 字段完整、数据量匹配 |
| 进程用户统计 | program_stats反映各进程用户规模 | 浏览器类进程用户数最高 |
| 浏览器筛选 | 仅保留6款目标浏览器记录 | 无其他进程数据混入 |
| 停留时长 | duration_sec > 0 | 无负值、无空值 |
| 日期小时衍生 | event_date / event_hour 格式正确 | 提取无误 |
| 市场格局统计 | browser_coverage含用户数与总时长 | 聚合结果正确 |
| 时段活跃统计 | browser_hourly含分小时活跃用户数 | 聚合结果正确 |
| 整体数据质量 | 无空值、无冗余、无错误数据 | 数据规范可用 |
5 常见问题记录
问题1:Java代码输出字段类型错误
现象:解析输出字段全部默认为String,导致后续数值计算失败。原因:Java代码组件未配置字段类型。处理方式:在Java组件中手动指定字段类型(如event_seconds设为Integer),重新执行转换流。
问题2:停留时长计算结果出现负值
现象:duration_sec存在负值。原因:每个会话最后一条记录无下一行参照,next_event_seconds为NULL,差值结果为负。处理方式:在过滤记录组件中设置条件 duration_sec > 0,剔除无效记录。
问题3:分组聚合后用户数重复计数
现象:同一用户被多次计入统计。原因:分组时计数方式未选去重。处理方式:分组组件中将count方式设为"个数(去重)",等价于 COUNT(DISTINCT user_id)。
问题4:日志导入后behavior_events表为空
现象:表内无数据写入。原因:Java代码未正确读取文件路径或分隔符配置有误。处理方式:核对获取文件名组件的目录路径与Java代码的分隔符,修正后重新执行。
6 总结
本实验完成了互联网用户行为日志从半结构化到结构化再到指标化的全链路ETL加工,覆盖以下能力:
- 半结构化日志解析:掌握基于Java代码组件的自定义格式日志拆分方法,包括文件名信息提取与日志体字段分割。
- 零代码ETL组件串联:熟练运用字段选择、过滤记录、排序、分析查询、计算器、分组聚合、表输出等核心组件,理解组件间的数据流转逻辑。
- 典型指标加工:实现了停留时长计算、日期小时维度衍生、多粒度分组去重等数据分析中的常见操作。
- 数据质量治理:针对字段类型错误、时长负值、分组去重遗漏、配置路径异常等问题进行了排查与修正。
最终产出的 browser_coverage 与 browser_hourly 两张标准表,可直接用于后续的市场份额分析、用户时段偏好分析及用户画像构建。

一站式 AI 云服务平台
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)