
贵州某211实验样例——浏览器市场与用户画像分析-数据加工
本实验基于助睿平台对互联网用户行为日志进行数据加工与分析。实验首先通过Java代码组件解析半结构化日志文件,提取关键字段并转换为结构化数据表。随后针对浏览器类进程进行重点分析,包括用户覆盖率、使用时长统计以及时段活跃度分析。实验采用零代码方式完成数据清洗、聚合与关联,构建了browser_coverage(浏览器用户数与总时长)和browser_hourly(分时段活跃用户)两张核心数据表。通过助
#助睿平台#商业数据分析 #用户画像 #贵州某211 #零代码
因为内容过长,还会有第二部分在下一篇文章中。
一、实验目的以及使用环境
1、实验目的:
-
熟悉数据集构成与半结构化日志数据特点,掌握文本日志解析、字段拆分的实操方法
-
完成数据规整,将零散原始日志转化为标准结构化数据表
-
实现多维度数据聚合、字段衍生与跨表关联,搭建适配分析场景的指标体系
2、实验环境:
-
实验平台:助睿在线实验平台 https://lab.guilian.cn/
-
本次实验使用助睿数智(Uniplore)作为一站式数据科学平台。该平台覆盖从数据接入、ETL处理、机器学习建模到可视化展示的全链路零代码功能,适用于数据分析教学与企业数据加工场景。助睿数智官网为:https://www.uniplore.com/
二、数据说明
数据集含三个部分:
用户基本信息表:demographic.csv存储用户 ID、性别、年龄、职业、教育程度、收入等人口属性信息。
浏览器上网记录:日志中包含 URL、域名、访问时间等。
软件使用记录:日志中包含进程名、程序名、使用时长、窗口切换等。
数据总大小解压后约825MB,原始行为记录800 多万条,覆盖1000 名用户连续4 周的电脑使用行为(横跨 4 个月,每月抽取 1 周数据)。
第 1 周:2012-05-07 至 2012-05-13
第 2 周:2012-06-04 至 2012-06-10
第 3 周:2012-07-02 至 2012-07-08
第 4 周:2012-08-06 至 2012-08-12
数据文件结构:
-
behavior/ 文件夹:按日期归档,存放数万条 TXT 行为日志
-
demographic.csv:用户属性表
-
两个数据通过用户 ID(user_id) 唯一关联。
日志文件命名规则:
① 每个 TXT 文件 = 一个用户一次开机产生的行为日志文件名格式:用户ID_日期_开机时间.txt示例:0AB6BBBEDFF24EC8BAAC905F45AE314C_2012-05-07_21-22-38.txt
从文件名可直接解析出:
-
user_id:用户唯一标识
-
file_date:日志日期
-
file_start_time:开机时间
日志文件内部格式:
-
第 1 行:Last<=> 数字表示日志最后一条记录距离开机的秒数。
-
第 2 行:L_Start<=> 时间表示本次开机的绝对时间。
-
第 3 行及以后:行为记录(核心数据)
字段含义必须掌握:
|
字段名 |
类型 |
|
session_id |
String |
|
user_id |
String |
|
l_start |
String |
|
t |
String |
|
p |
String |
|
i |
String |
|
u |
String |
|
a |
String |
|
b |
String |
|
v |
String |
|
w |
String |
|
n |
String |
|
c |
String |
|
source_file |
String |
配置完成后点“确认”
3.2.6 字段选择:有效字段筛选与规整
右键“java 代码”组件点“预览输出字段”,可看到有很多字段是不需也不属于原始数据字段的,需移除
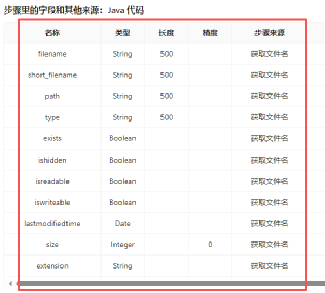
拖拽“字段选择”组件到画布,然后创建“Java 代码”组件到“字段选择”组件的连线,连接线类型选择“主输出步骤”
双击“字段选择”组件,点tab选项“移除”,然后在字段名称下方空白处右键点“获取字段”
选中上一步骤中的Java代码输出的字段后,右键点“删除选中的行”
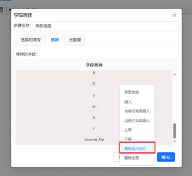
最后剩下多余的字段即可点“确认”
3.2.7 表输出:结构化数据表落地
之后,将已经转换为结构化的数据输出到数据库中,以便后续使用
拖拽“表输出”组件到画布,然后创建“字段选择”组件到“表输出”组件的连线,连接线类型选择“主输出步骤”
双击“表输出”组件,选择“团队私有数据库”连接
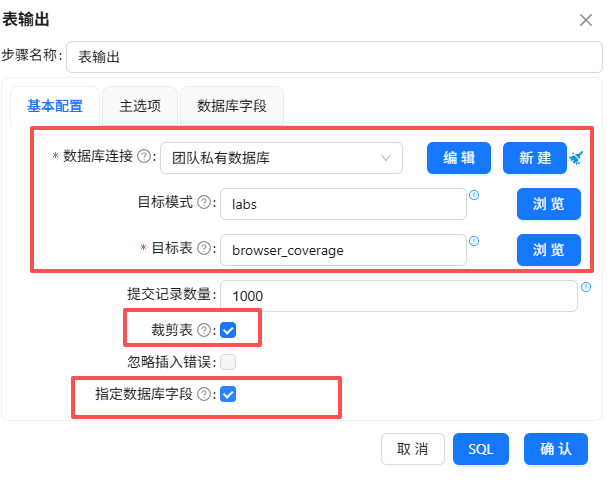
勾选“裁剪表”,这样表输出组件在插入数据前会清空原始表数据,避免重复插入
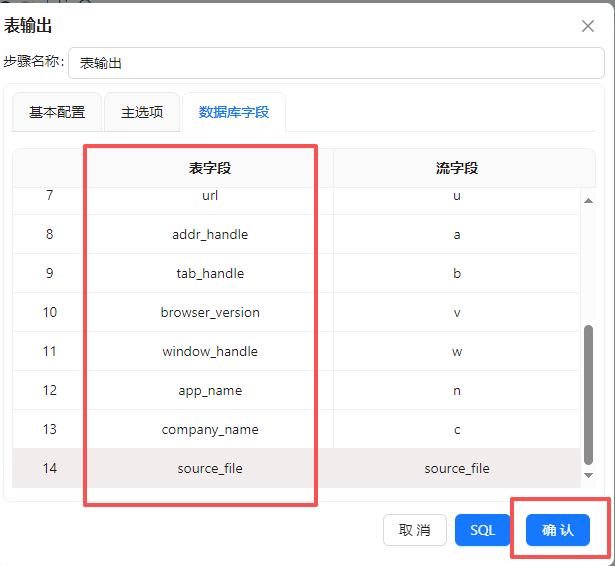
勾选指定数据库字段”,建立工作流字段与数据库表字段的映射关系。勾选后会激活“数据库字段”tab页,在数据库字段tab页,右键选择“获取字段”
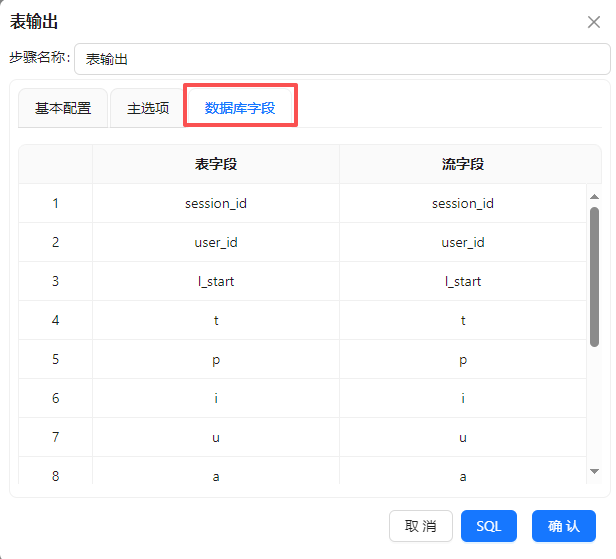
在3.2.3小节中创建的表字段与流字段是不一样的,双击表字段,在下拉框中选择正确的表字段
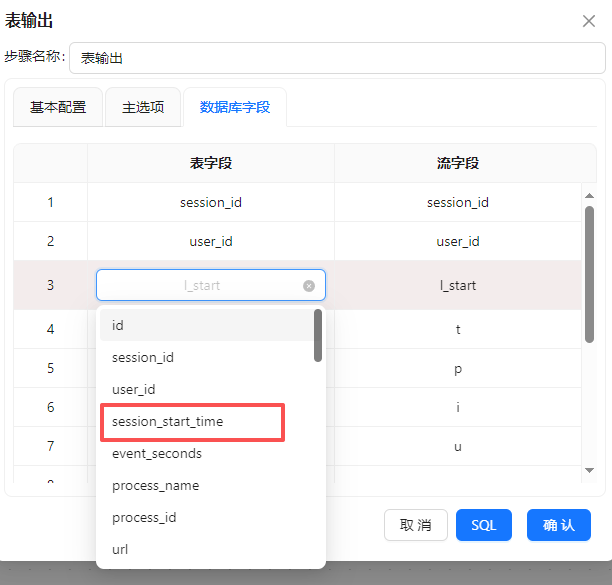
设置完成后点“确认”
3.2.8 执行转换流
执行转换流,点工具栏中的“执行”按钮
在弹出执行配置窗口中,选择默认配置,然后点“启动”按钮,启动工作流
查看日志,工作流执行后会打开日志页面,定期刷新工作流日志数据。
查看数据结果
打开“元数据”tab页,在“团队私有数据库”连接上右键选择“加载元数据”
然后进入数据探查页面,展开“团队私有数据库”
双击目标表“behavior_events”,在右侧页面选择“查询”tab标签
3.3 数据分析方向确定
得到 behavior_events 后,需决定分析什么。对 behavior_events 按进程名 process_name 统计使用人数,可以快速看出哪些程序覆盖的用户最广。这个统计的价值在于:它能帮从九百多万条杂乱记录中,迅速锁定最值得分析的候选对象。
3.3.1 创建进程统计表
新建转换工作流,然后命名为“创建进程统计表”,在该工作流中拖拽“执行一个SQL脚本”组件,通过执行SQL脚本来创建一个标签表。整个转换流如下所示:
配置说明:在组件中填写SQL脚本,选择目标数据库连接“团队私有数据库”,确保脚本执行权限;
SQL脚本如下:
-- 创建程序/软件统计表CREATE TABLE program_stats (
program_nameVARCHAR(255) NOT NULL,-- 程序/软件名称
user_countINT NOT NULL-- 使用用户数
);
其他参数使用默认选项,完成后组件配置如下:
由于数据量较大,为顺利运行转换流,点开“元数据”,双击“团队私有数据库”,勾选“使用结果流”
完成后运行转换流,运行过程会定时刷新组件状态,然后画布下面显示执行日志。
3.3.2 统计进程用户规模
每个进程得用户规模即用户数量 = 每个进程名称得用户ID计数
新建转换流“统计进程用户规模”,拖拽“表输入”组件到画布,数据库连接选择“团队私有数据库”,然后获取 behavior_events 得所有SQL查询语句
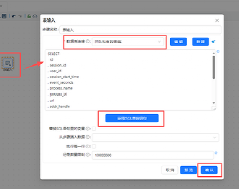
拖“字段选择”组件到画布,然后创建“表输入”组件到“字段选择”组件得连线,双击“字段选择”组件,点tab选项“移除”,然后再字段名称下方空白处右键点“获取字段”
统计每个进程得用户数量只需用到 user_id、process_name 两个字段,所以需移除其他字段
选中user_id、process_name 两个字段,右键点“删除选中的行”
删除后点“确认”
字段 process_name 可能存在空值,为避免后续操作错误,需将空值替换为“未知”。拖拽“替换NULL值”组件到画布,然后创建“字段选择”组件到“替换NULL值”组件的连线,连接线类型选中“主输出步骤”
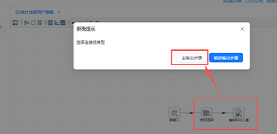
双击“替换NULL值”组件,勾选“选择字段”,在下方字段表格中插入一行,然后输入:
① 字段:process_name
② 值替换为:未知
③ 是否为空:否
分组聚合之前需对数据进行排序,否则分组计算结果可能出错。拖拽“排序字段”组件到画布,创建“替换NULL值”组件到“排序记录”组件的连线,连接线类型选中“主输出步骤”
双击“替换NULL值”组件,将数据按照“process_name”字段升序排序
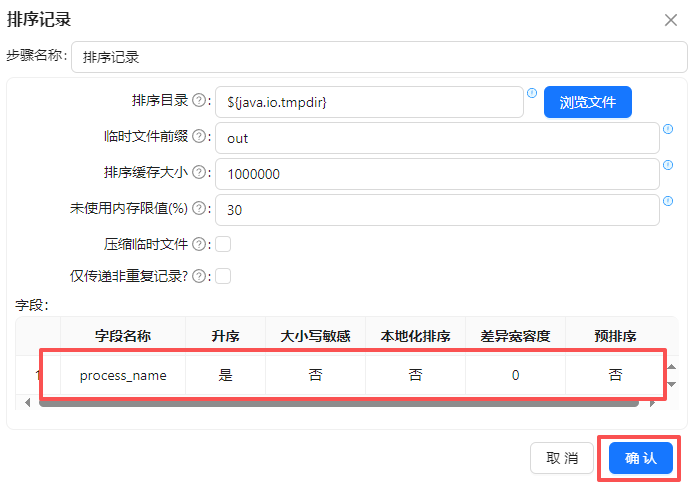
之后就可以对排序后的数据进行分组聚合统计,拖拽“分组”组件到画布,创建“排序记录”组件到“分组”组件的连线,

双击“分组”组件,在分组字段空白处获取字段后,仅保留“process_name”
在聚合表格空白处右键点“插入”
双击插入的空白行,名称输入“user_count”,subject选择“user_id”,类型选择“个数”,最后点“确认”
分组聚合后的数据需输出到3.3.1小节创建的统计表中,拖拽“表输出”组件,创建“分组”组件到“表输出”组件的连线
双击“表输出”组件,选择“团队私有数据库”连接,勾选“裁剪表”,这样表输出组件在插入数据前会清空原始表数据,避免重复插入
勾选“指定数据库字段”,建立工作流字段与数据库表字段的映射关系。勾选后会激活“数据库字段”tab页,在数据库字段tab页,右键选择“获取字段”
最后执行转换流即可
3.3.1 观察数据确定分析方向
为确定覆盖用户最广的进程/软件,使用助睿BI来观察数据
点平台左边菜单“助睿BI”,进入助睿BI首页
由于之前的实验已经创建团队私有数据库的数据源连接,本次实验无需再创建数据源连接,可直接创建数据集
点“数据集”菜单
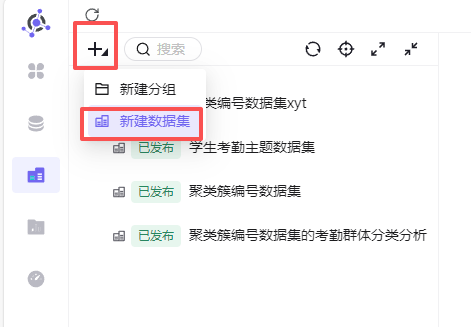
在数据集页面点“+” - “新建数据集”
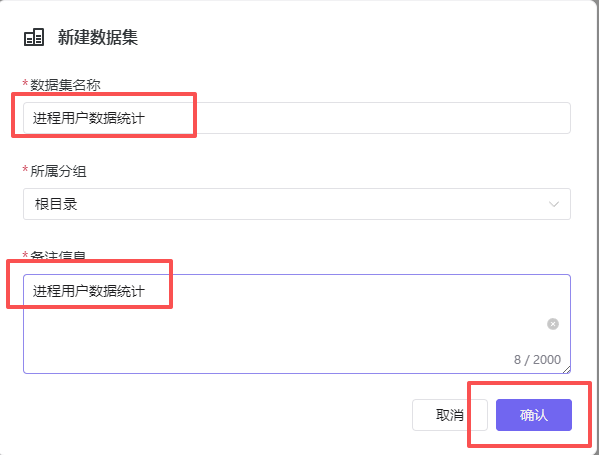
数据集名称和备注信息都输入“进程用户数据统计”,点“确认”
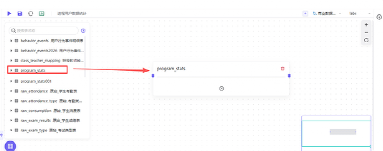
右上角数据源选择进程统计表 program_stats 所在的“商业数据分析” - “labs”

将 program_stats 拖拽至画布
可以看到 program_stats 的数据结果,为方便观察,可以将字段备注修改为中文
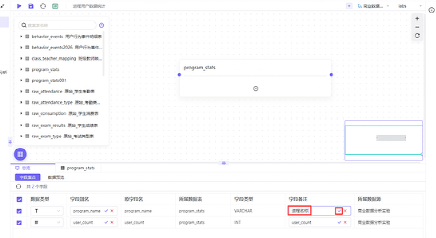
修改完成后点“保存”,保存然后发布数据集
点“工作表”
进入工作表页面后,点“+” - “新建工作表”
输入工作表名称和备注信息后点“确认”

数据集选择刚刚创建的数据集“进程用户数据统计”,图表类型选择“水平条图”
将字段“program_name”拖拽至Y轴,“user_count”拖拽至X轴,然后将“user_count”按照降序排序
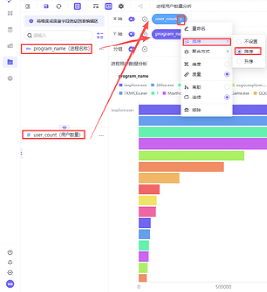
由以上内容得出,浏览器类进程(chrome.exe、360chrome.exe等)的用户数明显高于其他软件(如 QQ.exe、EXCEL.EXE、WINWORD.EXE)。这表明浏览器是覆盖面最广的应用,样本充足,同时浏览器记录包含 url,可进一步分析网站偏好。所以确定浏览器为分析对象。
3.4 分析方案设计与数据确定
根据 3.3 节的统计结果,发现浏览器类进程的用户覆盖率远高于其他软件,且浏览器记录包含 url 字段,可以挖掘用户网站偏好。将分析对象锁定为浏览器,然后围绕以下问题展开分析:
-
浏览器市场格局:哪些浏览器用户最多、使用时长最长?
-
用户画像:不同浏览器的用户在年龄、职业上有何差异?
-
使用习惯:用户集中在什么时段使用浏览器?
-
竞争迁移:用户是否会从一款浏览器切换到另一款?
-
流失预测:哪些用户可能停止使用 iexplore.exe 浏览器?
-
个性化推荐:根据用户的网站访问历史,可以推荐哪些网站?
为回答这些问题,可以预先设计一套可视化方案(将在下一实验完成)。下表列出每张图表对应的业务问题、所需数据字段以及最终输出的数据表名,后续数据加工将围绕它们展开。
|
<span style="font-family:宋体; <p>mso-ascii-font-family:Calibri;<br>font-variant:normal;<br>text-transform:none;<br>mso-ansi-language:EN-US;<br>mso-fareast-language:ZH-CN"><span leaf=" "="">输出表名 |
内容 |
粒度 |
|
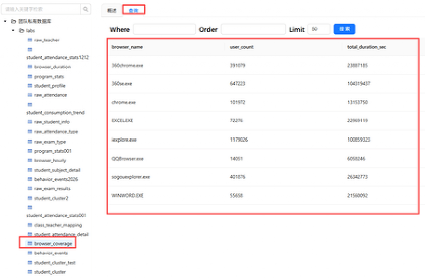
browser_coverage.csv |
每个浏览器的用户数、总使用时长 |
每个浏览器一行 |
|
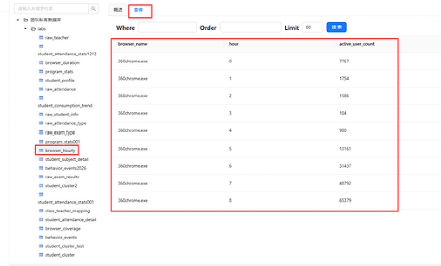
browser_hourly.csv |
每个浏览器按小时统计活跃用户数 |
浏览器 × 小时 |
|
browser_demographic.csv |
每个浏览器按年龄分段、职业的用户分布 |
浏览器 × 年龄组 × 职业 |
|
browser_retention.csv |
每个浏览器从第3周到第4周的留存率 |
每个浏览器一行 |
|
browser_migration.csv |
用户从第3周主用浏览器切换到第4周主用浏览器的迁移对及人数 |
源浏览器 → 目标浏览器 |
|
churn_features.csv |
每个用户前三周的 Chrome 行为特征及标签 |
每个用户一行 |
|
churn_probability.csv |
每个用户的流失概率(AI Studio 输出) |
每个用户一行 |
|
feature_importance.csv |
流失预测模型的特征重要性 |
每个特征一行 |
|
high_risk_users.csv |
流失概率最高的 20% 用户及其关键特征 |
每用户一行(约200行) |
本次实验先完成前2个数据的加工,首先需在团队私有数据库中先创建这2个数据表
创建两个转换流“创建浏览器的用户数总使用时长统计表”、“创建每个浏览器按小时统计活跃用户数统计表”
两个转换流都拖拽“执行一个SQL脚本”组件到画布,分别输入以下SQL:
创建浏览器的用户数总使用时长统计表的“执行一个SQL脚本”组件配置如下:
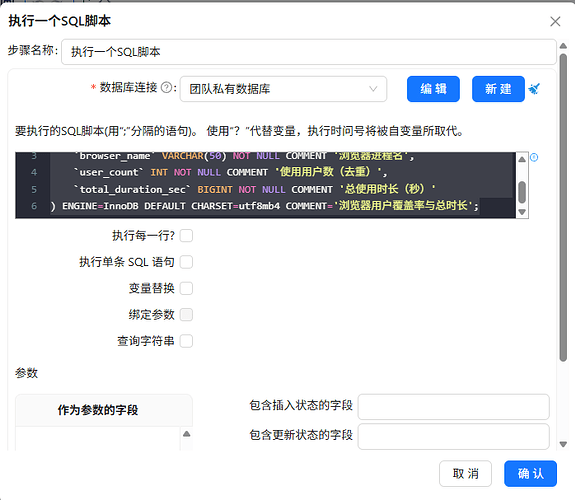
SQL:
CREATE TABLE `browser_coverage` (
`browser_name`VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
`user_count`INT NOT NULL COMMENT '使用用户数(去重)',
`total_duration_sec`BIGINT NOT NULL COMMENT '总使用时长(秒)'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器用户覆盖率与总时长';
创建每个浏览器按小时统计活跃用户数统计表的“执行一个SQL脚本”组件配置如下:
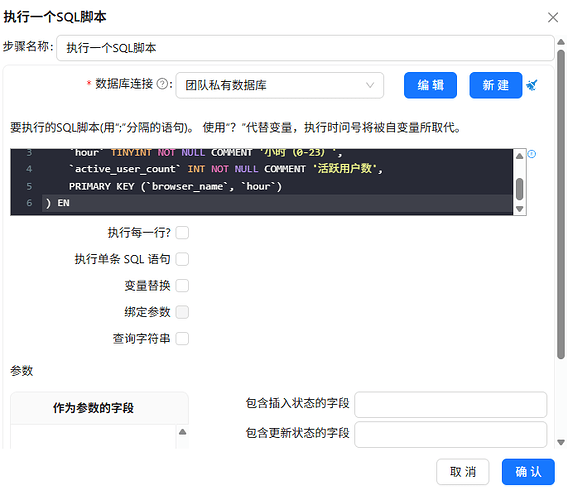
SQL
CREATE TABLE `browser_hourly` (
`browser_name`VARCHAR(50) NOT NULL COMMENT '浏览器进程名',
`hour`TINYINT NOT NULL COMMENT '小时(0-23)',
`active_user_count`INT NOT NULL COMMENT '活跃用户数',
PRIMARYKEY (`browser_name`, `hour`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器按小时活跃用户数';
最后分别执行两个转换流即可
3.5 数据清洗、聚合与关联加工
在3.1章节转换后得到明细结构化数据,单条记录仅反映单次电脑操作行为,无法直观体现用户整体使用习惯,因此开展清洗、聚合与关联加工,提炼核心统计指标,然后结合用户基础属性信息,形成具备分析价值的整合数据集。
解析完成的behavior_events行为明细表,同时引入demographic.csv用户人口属性数据表,依靠用户唯一编号完成两份数据联动处理。
注:包含全部数据的 behavior_events 行为明细表已经存放在线上公共数据库中,可以直接使用
新建转换流“互联网用户行为日志数据清洗抽取”
3.5.1 表输入:读取行为日志数据
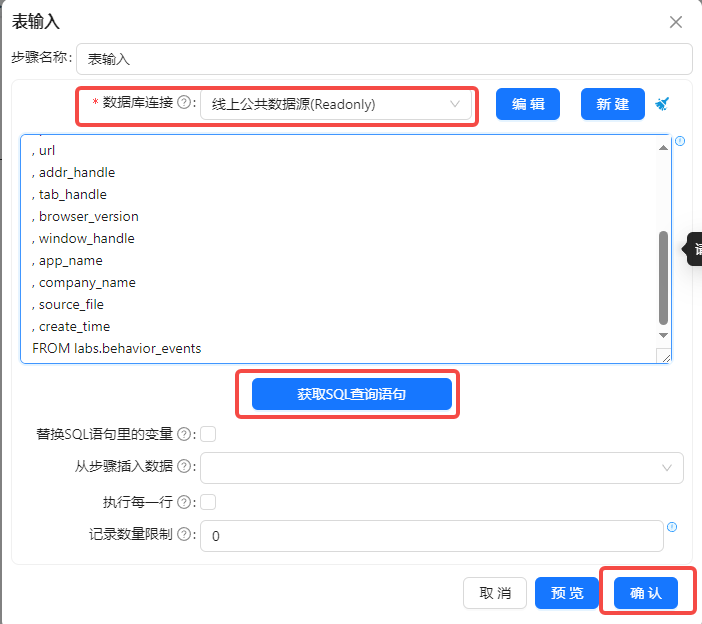
拖入“表输入”组件到画布
连接线上公共 数据源 (因为团队私有数据库中的数据只有20个数据,仅作教学,全部数据已存放在线上公共数据源中的 behavior_events 表中),获取 behavior_events 的所有SQL查询语句
3.5.2 字段选择:删除冗余字段
拖拽“字段选择”组件到画布,创建“表输入”组件到“字段选择”组件的连线
双击“字段选择”组件,点“移除”tab选项,在字段名称下方空白处右键点“获取字段”
选中 session_id, user_id, session_start_time, process_name, url, event_seconds 后删除选中的行,保留下来的字段就是要移除的字段,点“确认”
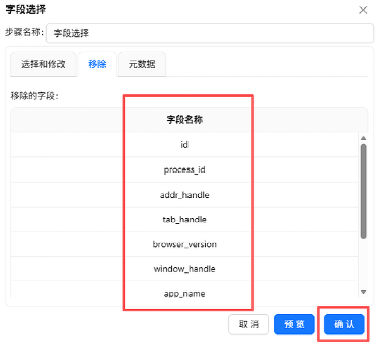
3.5.3 过滤记录:筛选进程为主要浏览器的数据
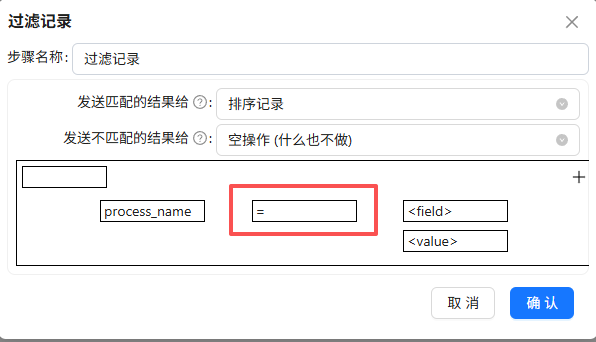
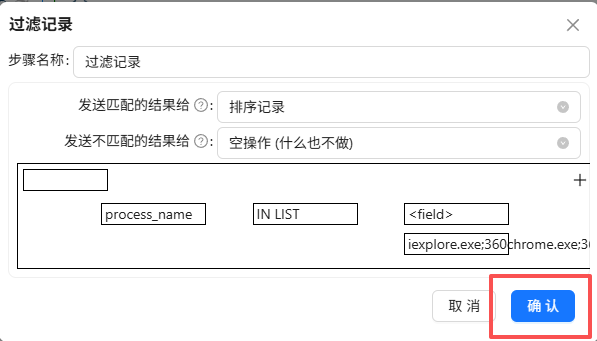
拖拽“过滤记录”组件到画布,创建“字段选择”组件到“过滤记录”组件的连线,连接线类型选择“主输出步骤”
双击“过滤记录”组件,可以看到需配置匹配和不匹配的结果的输出步骤
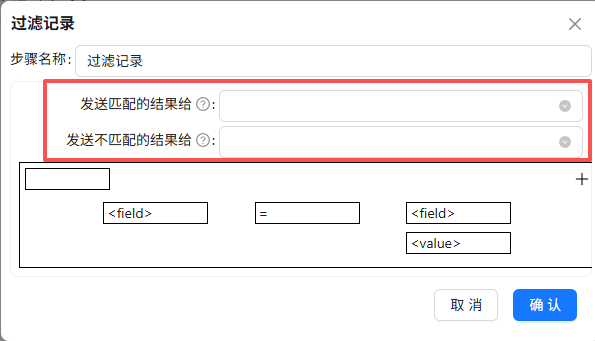
因此,先将后续的步骤的组件拖进来,拖拽“排序记录”组件到画布,创建“过滤记录”组件到“排序记录”组件的连线,连接线类型选择“True输出”
再拖一个“空操作 (什么也不做)”组件到画布,创建“过滤记录”组件到“空操作 (什么也不做)”组件的连线,连接线类型选择“False输出”
再次双击“过滤记录”组件,发送匹配的结果给“排序记录”,发送不匹配的结果给“空操作 (什么也不做)”
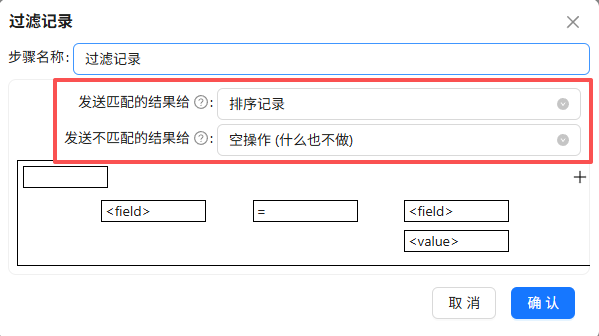
之后配置过滤条件,点第一个“field”,选择“process_name”,表示过滤条件为process_name的值
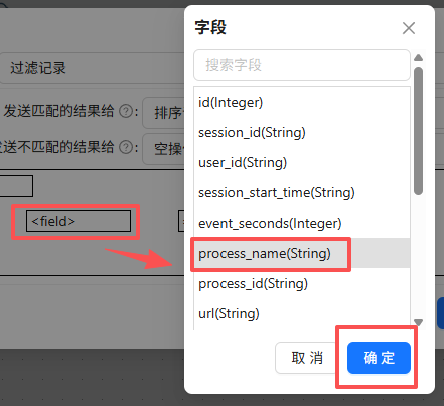
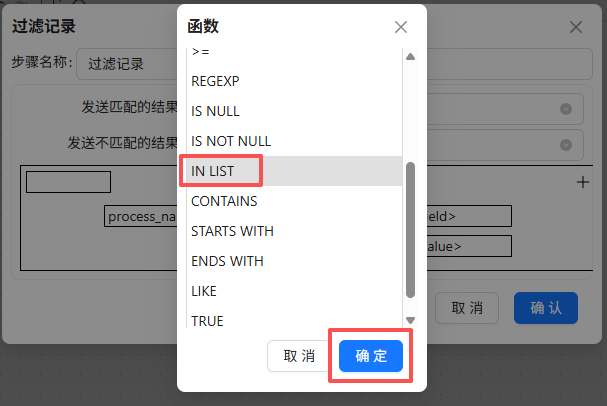
点函数符号,选择“IN LIST”
点“value”
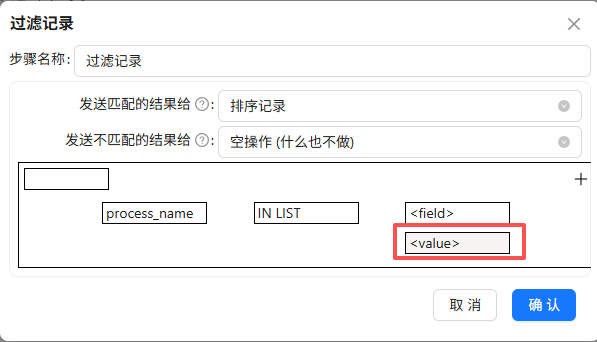
在弹出的窗口中,类型选择“String”,值为主要浏览器的进程名:“iexplore.exe;360chrome.exe;360se.exe;chrome.exe;sogouexplorer.exe;QQBrowser.exe”,表示process_name的值在其中的记录则为True,否则为False
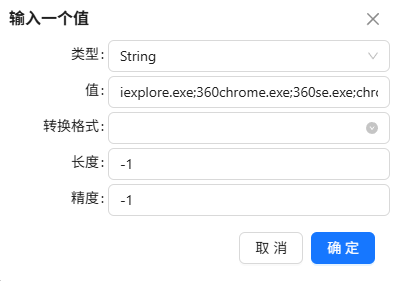
最后点“确认”
3.5.4 计算停留时长
原始日志只记录焦点切换的时刻,没有直接给出停留时长。但通过前后两条记录的 event_seconds 相减,就能算出用户在每个窗口上停留多久。这个时长是后续聚合(总使用时长)的基础数据。
这一步骤需用到3个组件:
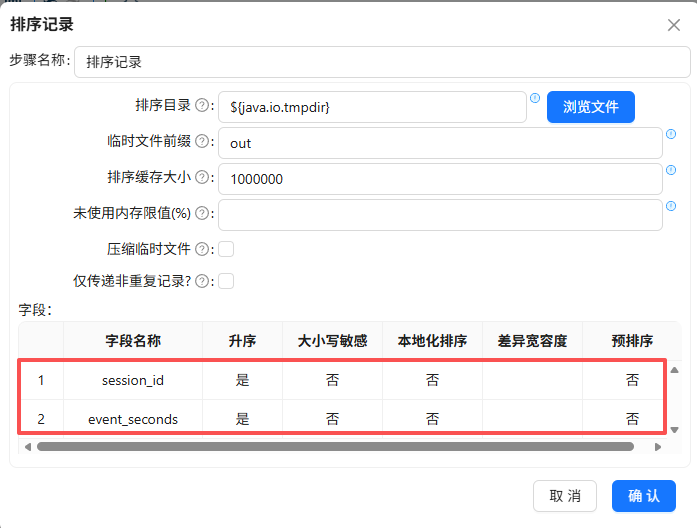
① 排序记录:按 session_id 和 event_seconds 升序排列,确保同一个会话内的行为按时间顺序处理
② 分析查询:获取同一会话内下一行的 event_seconds 值,存入新字段 next_event_seconds
③ 计算器:计算 next_event_seconds - event_seconds 得到停留时长 duration_sec
首先,“排序记录”组件在上一步骤已经拖入,双击“排序记录”组件,按 session_id 和 event_seconds 升序排列
拖拽“分析查询”组件到画布,创建“排序记录”组件到“分析查询”组件的连线,
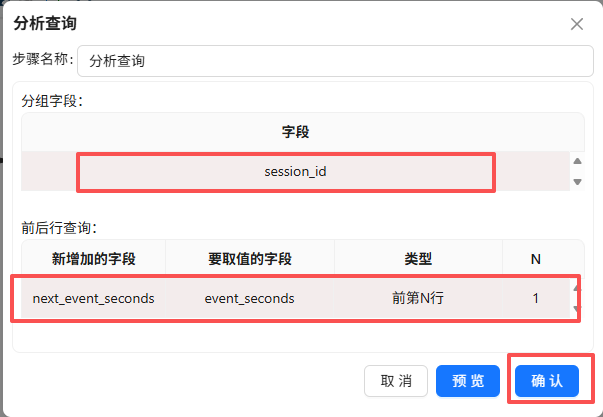
双击“分析查询”组件,分组字段为“session_id”,新增加的字段“next_event_seconds”,要取值的字段为“event_seconds”,类型“前第N行”,N为“1”,获取同一会话内下一行的 event_seconds 值,存入新字段 next_event_seconds
拖拽“计算器”组件到画布,创建“分析查询”组件到“计算器”组件的连线
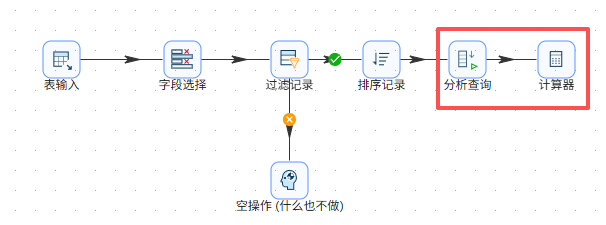
双击“计算器”组件,插入新字段行,新字段输入“duration_sec”,计算公式选择“A - B”,字段A选择“next_event_seconds”,字段B选择“event_seconds”,值类型为“Integer”
3.5.5 字段选择:保留必要字段
使用“字段选择”,只保留 user_id, process_name, session_start_time, url, duration_sec
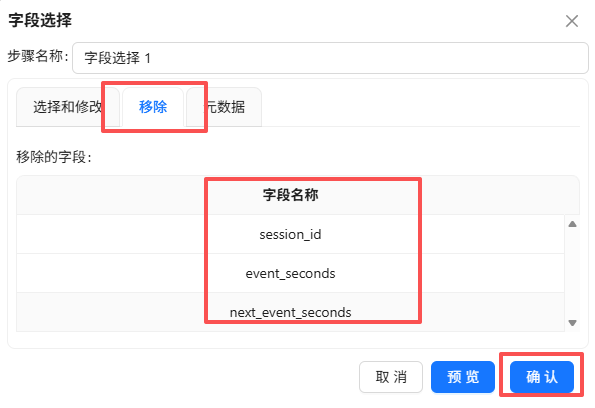
3.5.6 过滤记录:筛选停留时长>0的数据
使用“过滤记录”组件,过滤掉 duration_sec <= 0 的记录(最后一条记录没有下一条,时长无效,忽略)
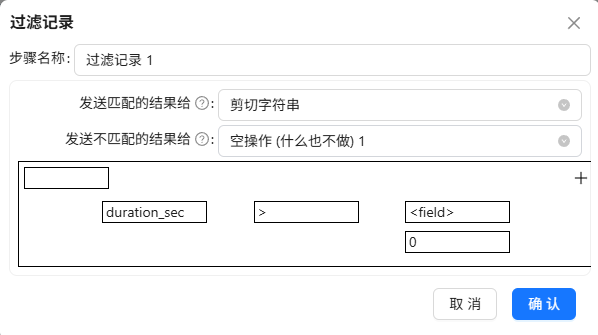
3.5.7 剪切字符串:提取日期
后续很多分析需按天、按时段聚合(比如每日使用时长、时段热力图)。提前提取好日期和小时,后续分组时直接使用,避免重复解析。
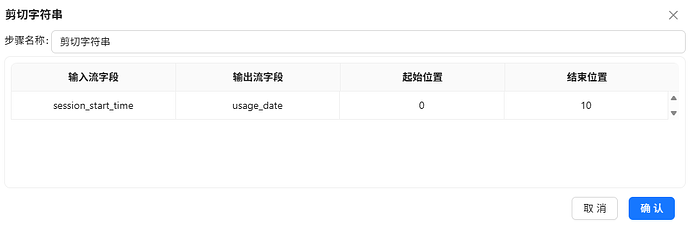
session_start_time 的格式为:yyyy-MM-dd HH:mm:ss,通过剪切字符串组件可以直接获取yyyy-MM-dd
拖拽剪切字符串组件到画布,创建过滤记录 1组件到拖拽剪切字符串组件的连线,连接线类型选择“Trur输出”,剪切字符串组件的配置如下:
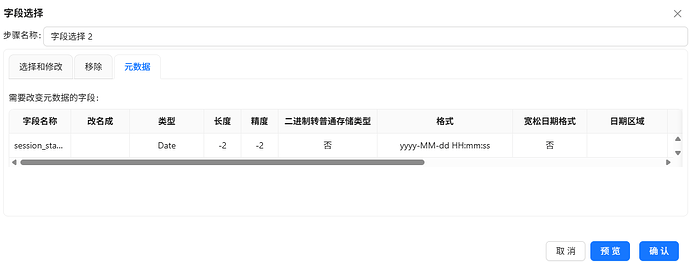
3.5.8 字段选择:设置日期格式
目前获取的数据中,session_start_time 的类型为String,为方便提前提取好小时,需将session_start_time 的类型设置为Date
拖拽字段选择组件到画布,创建剪切字符串组件到字符选择组件的连线,连接线类型选择“主输出步骤”,字段选择2组件的配置如下:
3.5.9 计算器:提取小时
通过计算器组件,可以提取 yyyy-MM-dd HH:mm:ss 中的HH,拖拽计算器组件到画布,创建字符选择组件到计算器组件的连线,连接线类型选择“主输出步骤”,计算器 1组件的配置如下:
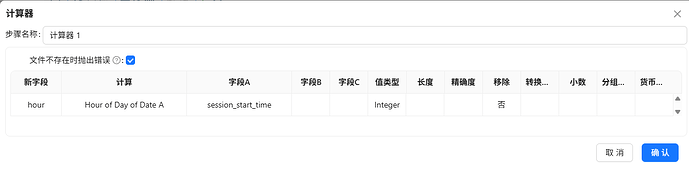
3.5.10 生成用户-日-浏览器-小时明细
原始数据是每条窗口切换记录,粒度太细。真正关心的是“每个用户每天每浏览器每小时用多久、启动几次”。这一步将数据压缩到合适的粒度,同时为后续所有统计表提供统一的基础数据。
之后就可以分组聚合组件来统计用户每天使用浏览器的时段数据,但在分组聚合前,先使用排序记录组件进行排序,避免分组聚合结果出错
拖拽排序记录组件到画布,创建“计算器 1”组件到“排序记录 1”组件的连线,排序记录 1组件的配置如下:
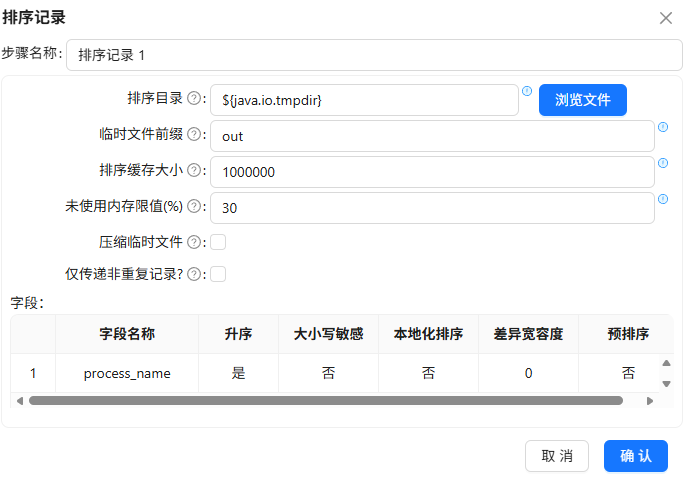
之后,拖拽分组组件,创建“排序记录 1”组件到分组组件的连线,分组组件的配置如下:
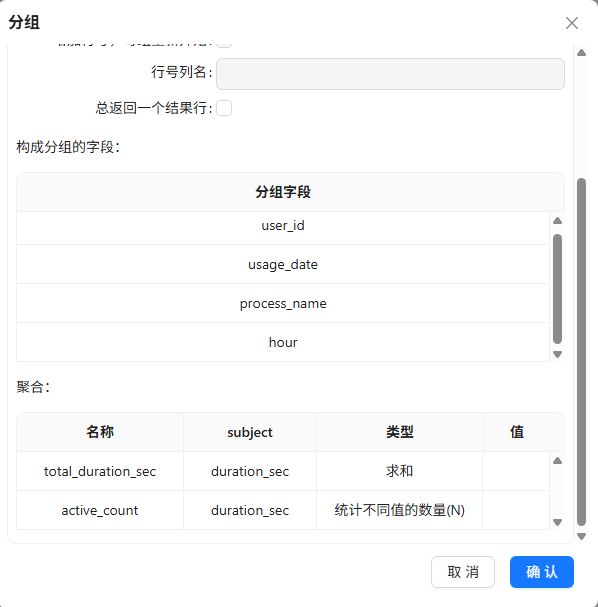
以上步骤获取的数据已经是比较合适颗粒度的数据,可以以此为基础,抽取不同维度的数据,以便用来实现后续的可视化分析
3.5.11 分支A:生成市场格局表
目标:统计每个浏览器的总用户数和总使用时长
这两个指标直接回答“哪种浏览器覆盖最广、用得最久”。去重计数能避免同一用户被重复计算,总时长反映真实使用强度。
拖拽分组组件到画布,创建“分组”组件到“分组 1”组件的连线
“分组 1”组件只按 process_name 分组
聚合:
① user_count = COUNT(DISTINCT user_id) (有多少不同用户使用过该浏览器)
② total_duration = SUM(total_duration_sec) (所有用户的累计使用时长)
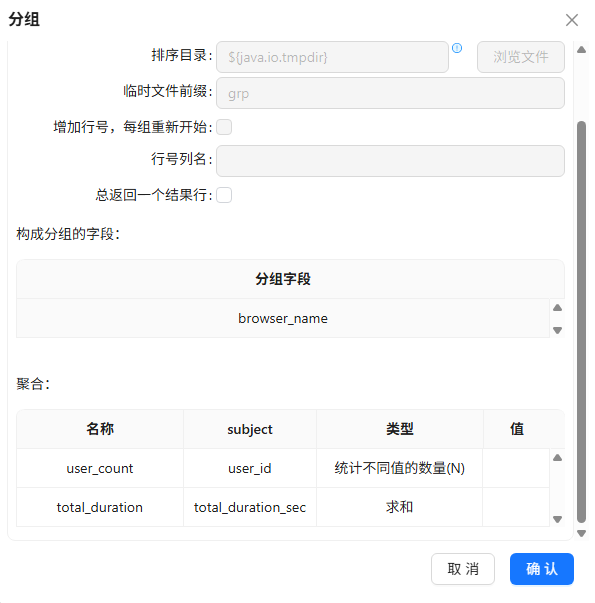
分组聚合的结果需落地数据库,拖拽“表输出”组件到画布,创建“分组 1”组件到“表输出 组件的连线”
表输出组的配置如下:
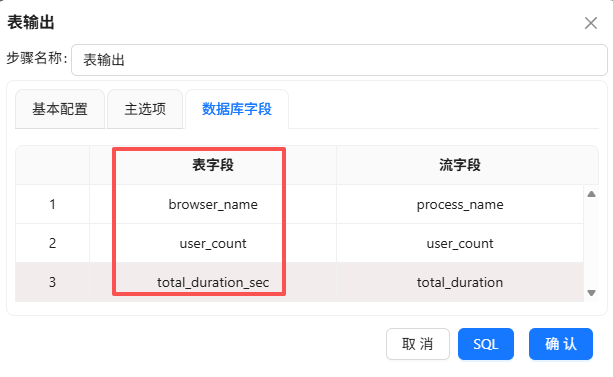
3.5.12 分支B:生成时段统计表
目标:统计每个浏览器在每个小时的使用情况,用于分析用户的时间段偏好
通过这张表可以绘制柱状图或折线图,展示不同浏览器的使用高峰时段。例如,白天工作时间 Chrome 使用量高,晚上娱乐时段 360 浏览器更活跃。按小时聚合已经足够,不需更细的粒度
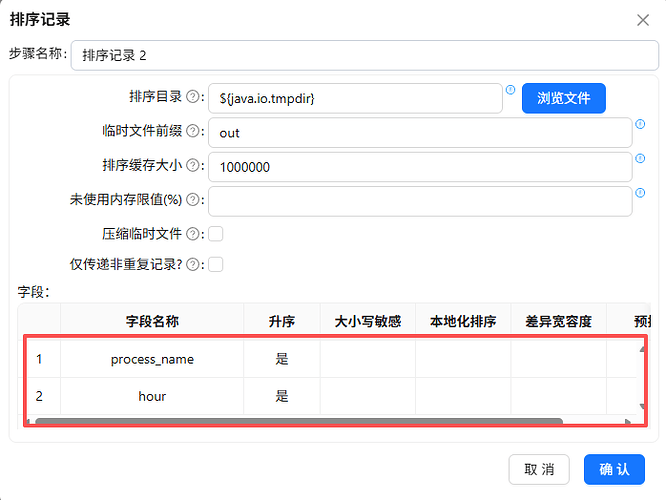
此分支的分组字段包含浏览器、小时,即process_name、hour,而前一个排序记录只对process_name排序,所以在这里需按照process_name、hour升序排序
拖拽“排序记录”组件到画布,创建“分组”组件到“排序记录 2”组件的连线,数据传输模式选择复制发送
“排序记录 2”组件的配置如下:
拖拽分组组件到画布,创建“排序记录 2”组件到“分组 2”组件的连线
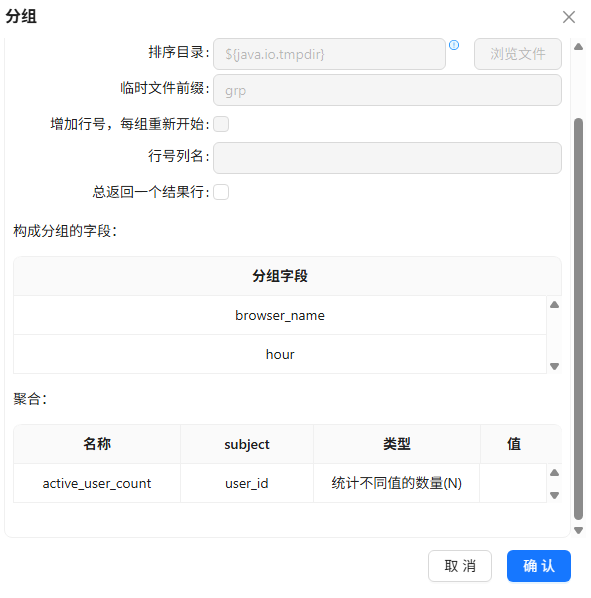
“分组 2”组件按 process_name、hour 分组
聚合:active_user_count =user_id个数
分组聚合的结果需落地数据库,拖拽“表输出”组件到画布,创建“分组 2”组件到“表输出 1组件的连线”
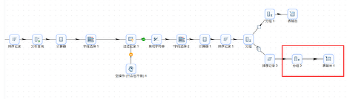
表输出组的配置如下:
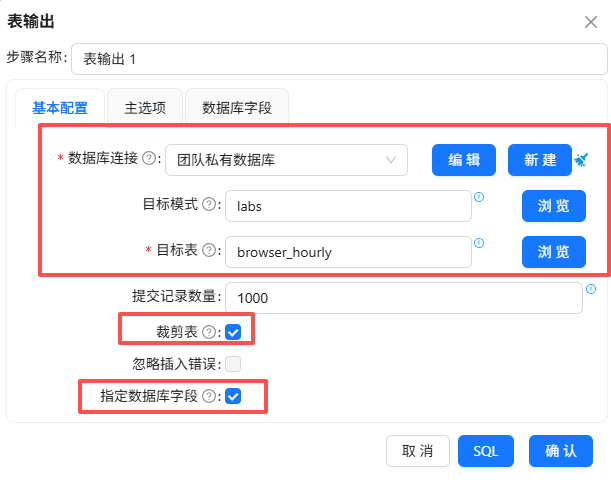
3.5.13 执行转换流
点运行按钮
3.5.14 查看结果
点“元数据”tab选项,右键团队私有数据,然后点“加载元数据”
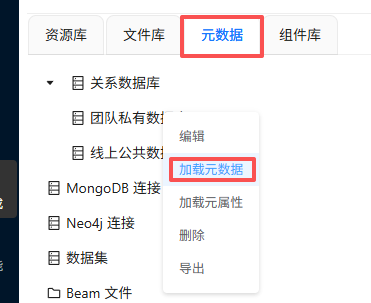
接着点“数据探查”,可以看到团队私有数据库目录

点 browser_coverage、browser_hourly 两个数据表,查询数据情况是否符合预期

一站式 AI 云服务平台
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)