
浏览器市场行为分析大屏全流程(数据加工+静态布局+蓝图数据接入,基于助睿数智平台)
数据加工:使用助睿ETL的“表输入”、“分组”、“值映射”、“JavaScript代码”、“记录集连接”等组件,高效完成多张聚合表的加工,理解了数据仓库“分层加工”的思想。大屏布局设计:从业务问题出发,设计合理的图表选型和布局,利用成组、背景图片、标题装饰等提升大屏美观度。蓝图编辑器:理解了数据源、触发器、动作、并行数据处理等核心概念,能够为不同图表配置SQL查询,并通过数据处理节点灵活转换数据格
标签:#助睿数智 #商业数据分析 #数据大屏 #ETL #浏览器分析
实验背景
实验目的
本次实验基于一份包含1000名用户、800余万条浏览器行为记录的原始数据,完成从数据加工、大屏静态布局到动态数据接入的完整可视化分析流程。通过本实验,我希望掌握:
-
使用助睿ETL平台进行数据清洗与聚合表加工
-
根据业务问题设计数据大屏布局与图表选型
-
利用助睿Max的蓝图编辑器配置数据源、SQL查询和数据绑定
-
将真实数据接入图表组件,实现动态展示
实验环境
-
实验平台:助睿在线实验平台(https://lab.guilian.cn/)
-
可视化工具:助睿Max(数据大屏)
-
数据处理:助睿ETL数据集成平台
-
数据来源:团队私有数据库(MySQL)
本次实验使用助睿数智(Uniplore) 作为一站式数据科学平台。该平台覆盖从数据接入、ETL处理、机器学习建模到可视化展示的全链路零代码功能。产品官网:Uniplore iDIS-大数据智能全流程服务平台-BI数据可视化工具
整体处理流程
整个实验分为三个连续部分:
-
数据加工(实验5-1):从原始行为明细表出发,加工出8张聚合表,包括浏览器市场格局、周活跃趋势、使用频率分布、浏览器使用数量分布、工作日/周末对比、核心指标以及用户画像统计表。
-
静态布局制作(实验5-2):在助睿Max中创建大屏,设计标题、导航、图表区域背景,拖拽图表组件并按草图排版。
-
蓝图数据接入(实验5-3):在蓝图编辑器中创建数据源连接,为每个图表编写SQL查询,通过并行数据处理节点分发数据,绑定到图表组件,最终预览并发布。
下面我将按顺序记录详细步骤。
第一部分:数据加工(实验5-1)
步骤1:准备用户-日-浏览器-小时明细表
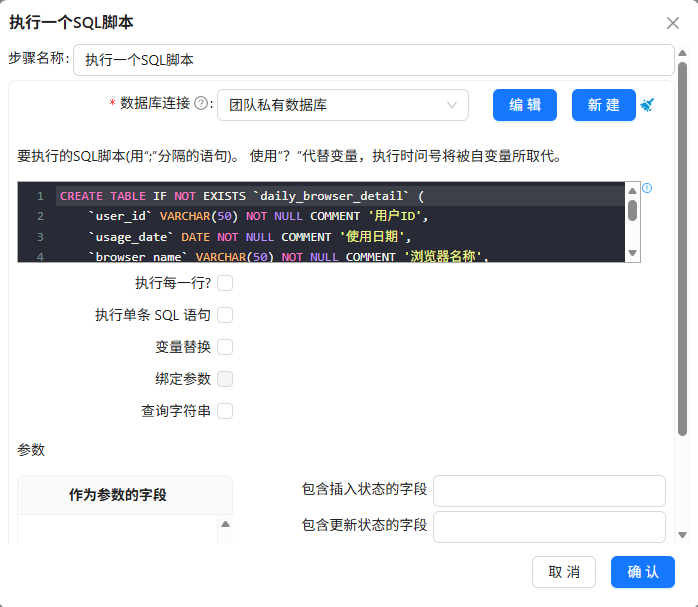
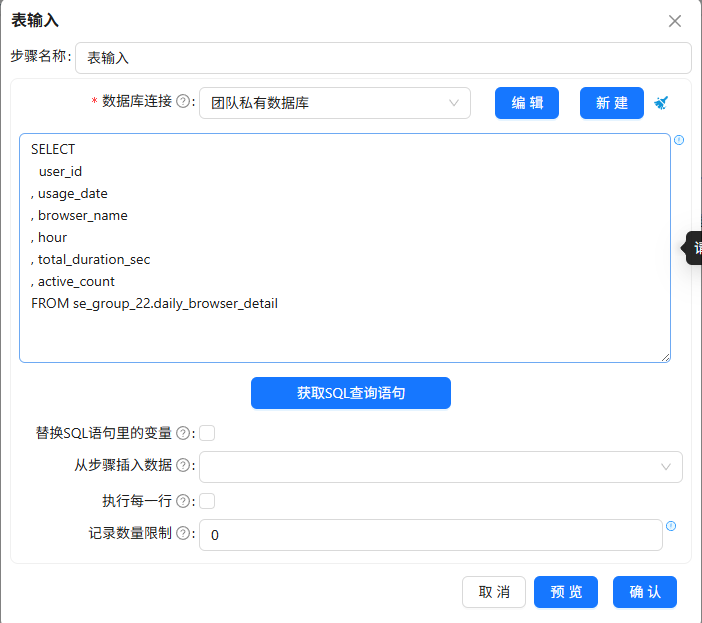
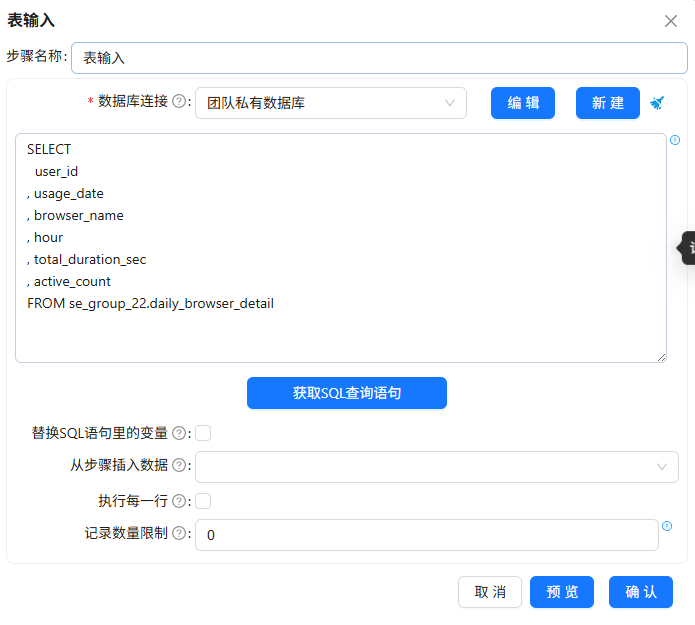
原始数据已经过清洗,生成了daily_browser_detail明细表。我在团队私有数据库中创建该表:
CREATE TABLE IF NOT EXISTS `daily_browser_detail` (
`user_id` VARCHAR(50) NOT NULL COMMENT '用户ID',
`usage_date` DATE NOT NULL COMMENT '使用日期',
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`hour` TINYINT NOT NULL COMMENT '小时',
`total_duration_sec` INT NOT NULL COMMENT '总使用时长(秒)',
`active_count` INT NOT NULL COMMENT '活跃次数'
);
然后复制已有的“互联网用户行为日志数据清洗抽取”转换流,重命名为“输出用户日浏览器小时明细表”,修正排序字段,添加值映射组件将进程名映射为浏览器名称(iexplore.exe→IE浏览器,chrome.exe→Google等),最后用表输出组件写入daily_browser_detail。

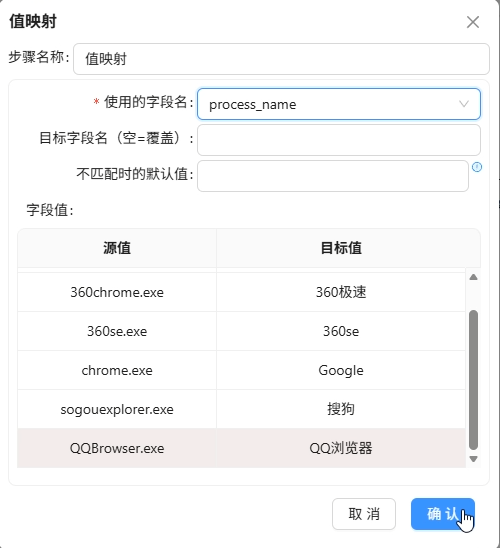
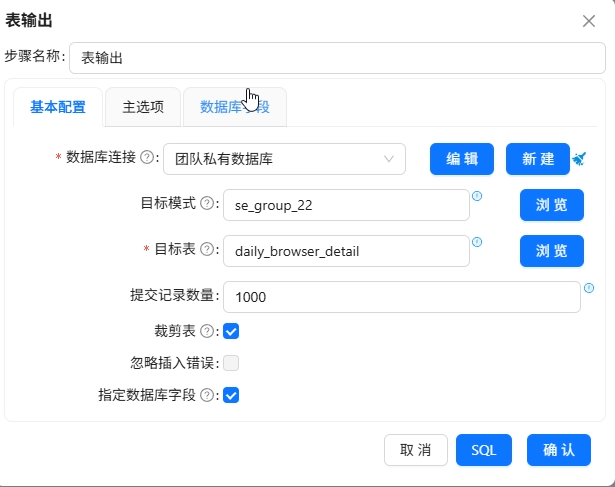
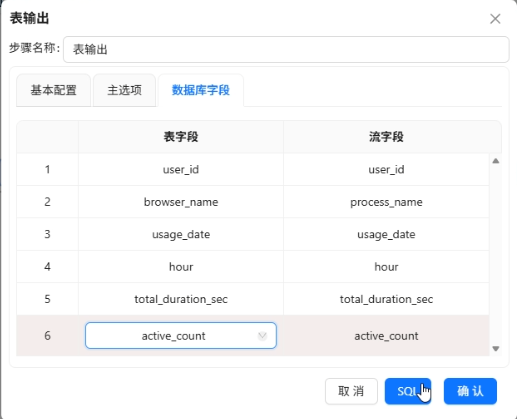
关键点:分组组件前的排序字段必须与分组字段完全一致,否则会产生重复数据。
步骤2:创建目标数据表
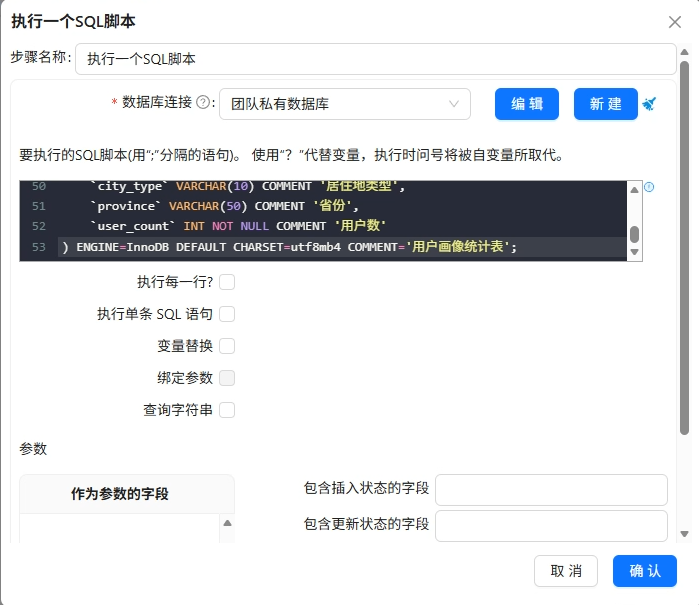
新建转换流“创建浏览器大屏分析目标数据表”,用“执行一个SQL脚本”组件一次性创建以下8张表:
-
browser_overview:核心指标概览 -
browser_weekly_active:各浏览器周活跃趋势 -
browser_frequency_stats:浏览器使用频率分布 -
browser_multi_usage:用户使用浏览器数量分布 -
browser_weekday_weekend:工作日vs周末对比 -
user_profile_stats:用户画像统计
-- 1. 核心指标概览表 DROP TABLE IF EXISTS `browser_overview`; CREATE TABLE `browser_overview` ( `metric_name` VARCHAR(50) NOT NULL COMMENT '指标名称', `metric_value` DECIMAL(12,2) NOT NULL COMMENT '指标值' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='核心指标概览表'; -- 2. 各浏览器周活跃趋势表 DROP TABLE IF EXISTS browser_weekly_active; CREATE TABLE `browser_weekly_active` ( `browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称', `week_range` VARCHAR(20) NOT NULL COMMENT '周日期范围', `active_user_count` INT NOT NULL COMMENT '活跃用户数' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='各浏览器周活跃趋势表'; -- 3. 浏览器使用频率分布表 DROP TABLE IF EXISTS browser_frequency_stats; CREATE TABLE `browser_frequency_stats` ( `browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称', `usage_level` VARCHAR(10) NOT NULL COMMENT '使用等级', `user_count` INT NOT NULL COMMENT '用户数' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器使用频率分布表'; -- 4. 用户使用浏览器数量分布表 DROP TABLE IF EXISTS browser_multi_usage; CREATE TABLE `browser_multi_usage` ( `browser_count` VARCHAR(10) NOT NULL COMMENT '使用浏览器数量', `user_count` DECIMAL(5,2) NOT NULL COMMENT '用户数量' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户使用浏览器数量分布表'; -- 5. 浏览器工作日周末对比表 DROP TABLE IF EXISTS browser_weekday_weekend; CREATE TABLE `browser_weekday_weekend` ( `browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称', `day_type` VARCHAR(10) NOT NULL COMMENT '工作日/周末', `avg_duration_sec` INT NOT NULL COMMENT '人均使用时长(秒)', `total_duration_hour` BIGINT NOT NULL COMMENT '总使用时长(小时)', `user_count` INT NOT NULL COMMENT '用户数' ) COMMENT '浏览器工作日周末对比表'; -- 6. 用户画像统计表 DROP TABLE IF EXISTS `user_profile_stats`; CREATE TABLE `user_profile_stats` ( `browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称', `gender` VARCHAR(10) COMMENT '性别', `age_group` VARCHAR(10) COMMENT '年龄段', `edu` VARCHAR(50) COMMENT '学历', `job` VARCHAR(50) COMMENT '职业', `income` VARCHAR(50) COMMENT '收入', `city_type` VARCHAR(10) COMMENT '居住地类型', `province` VARCHAR(50) COMMENT '省份', `user_count` INT NOT NULL COMMENT '用户数' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户画像统计表';
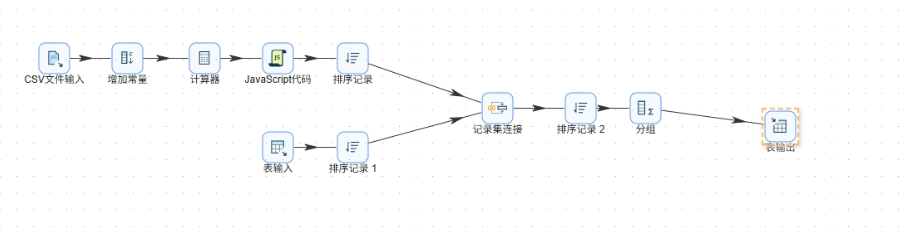
步骤3:各浏览器周活跃趋势表数据抽取
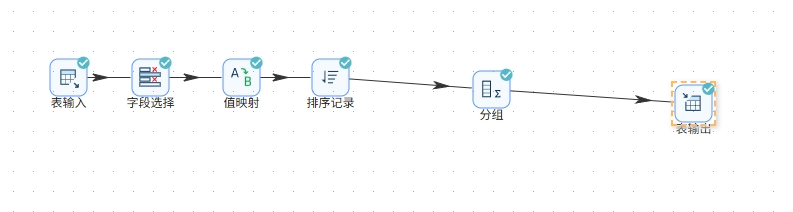
统计每个浏览器在第1-4周的每周活跃用户数。主要流程:
-
表输入读取
daily_browser_detail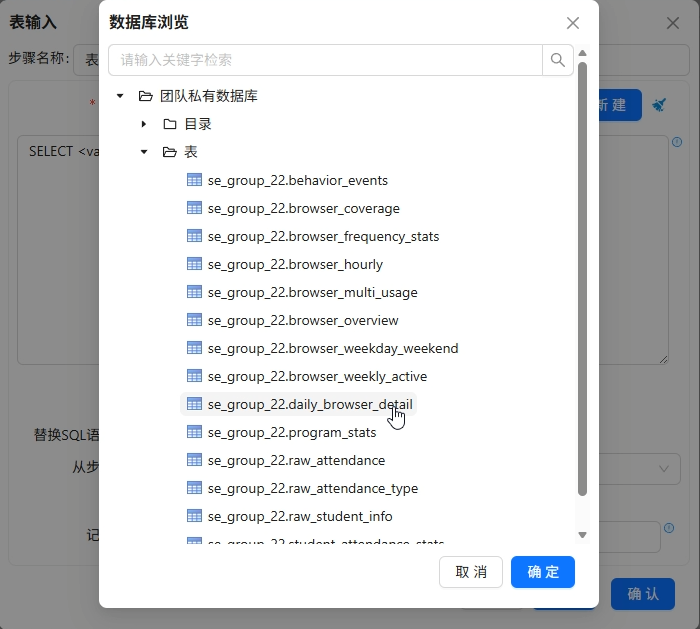
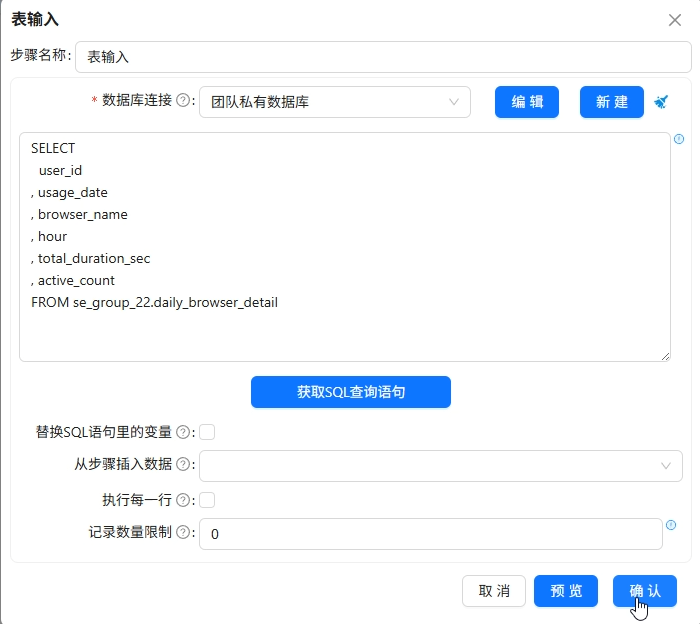
-
字段选择将
usage_date转为Date类型,格式yyyy-MM-DD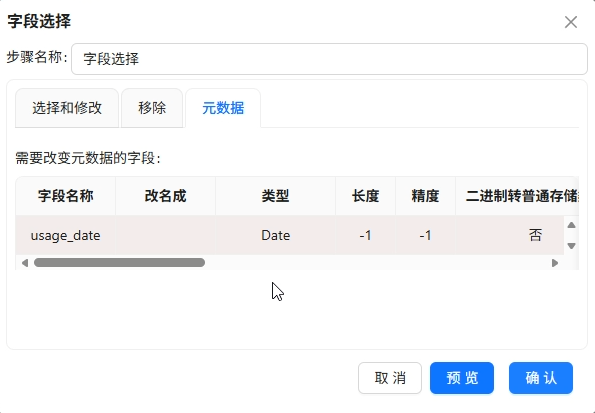
-
值映射将日期映射为周区间(如
2012-05-07→5/7-5/13)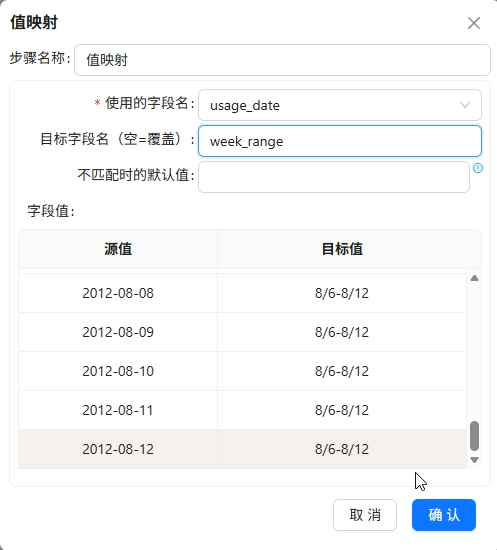
-
排序记录按
browser_name、week_range升序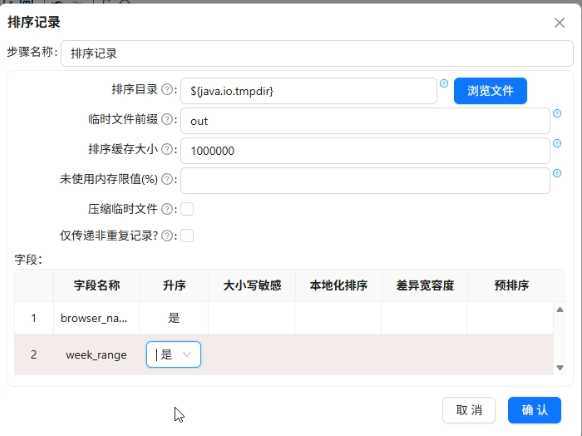
-
分组:分组字段
browser_name、week_range,聚合user_id去重计数得active_user_count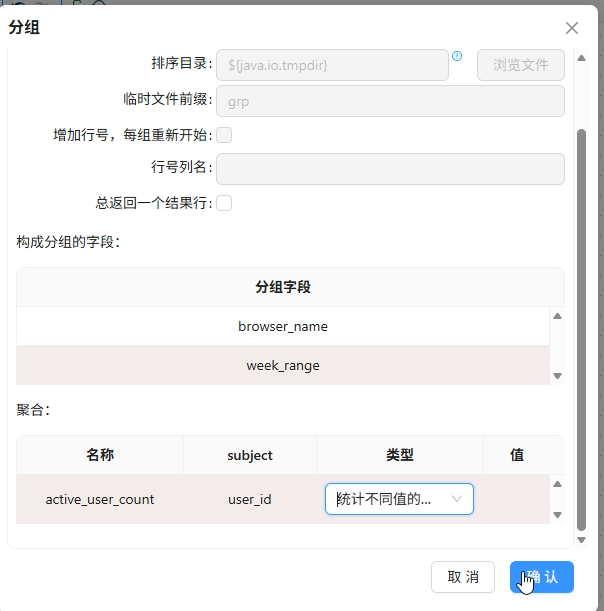
-
表输出写入
browser_weekly_active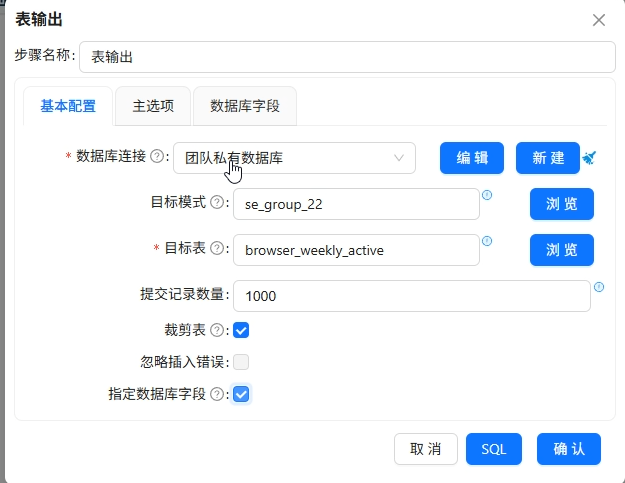
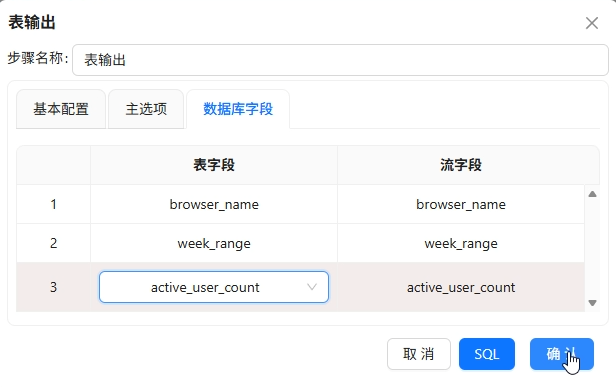
步骤4:各浏览器使用频率分布表数据抽取
划分轻(<3h/周)、中(3-10h)、重(>10h)三类用户:
-
读取表输入
-
按
user_id、browser_name升序排序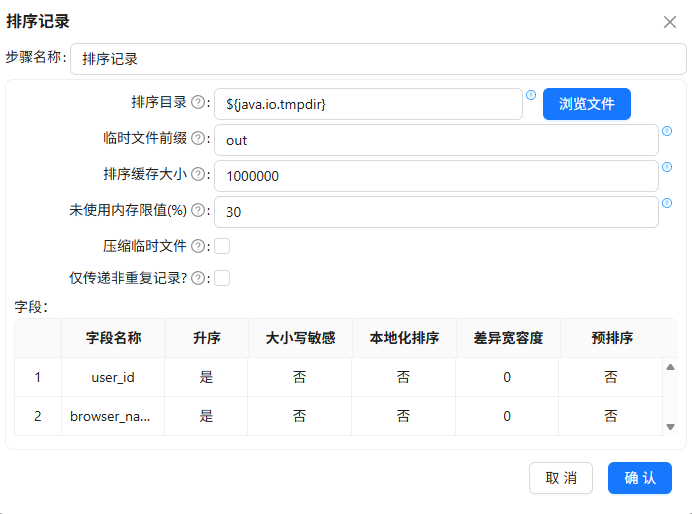
-
从明细表按
user_id、browser_name分组,计算每人每周总使用时长(秒)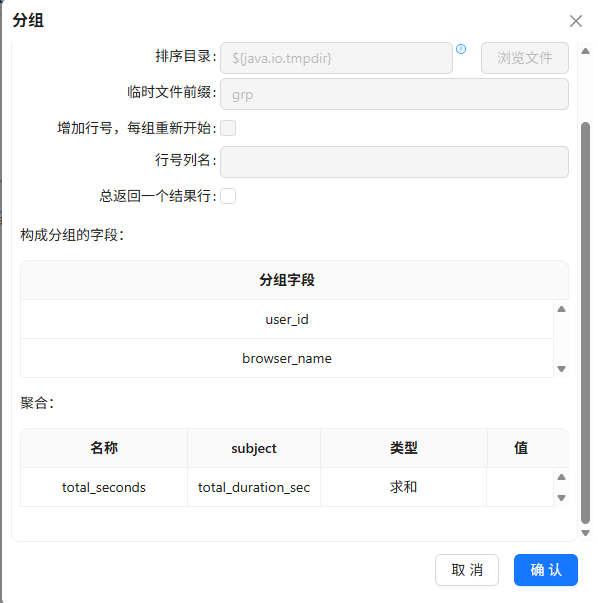
-
增加常量
3600,用计算器转为小时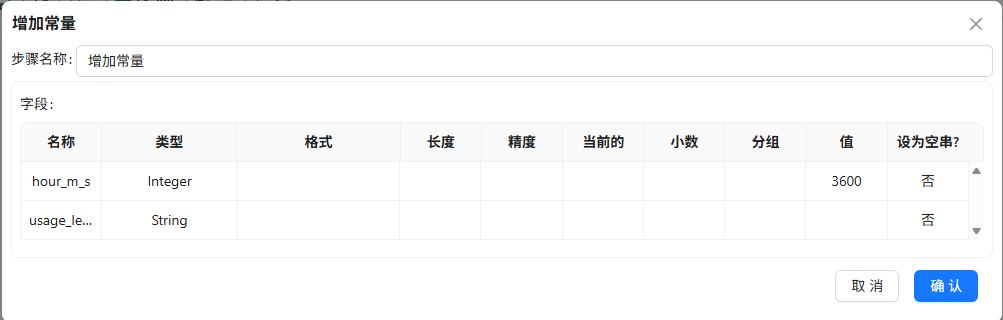
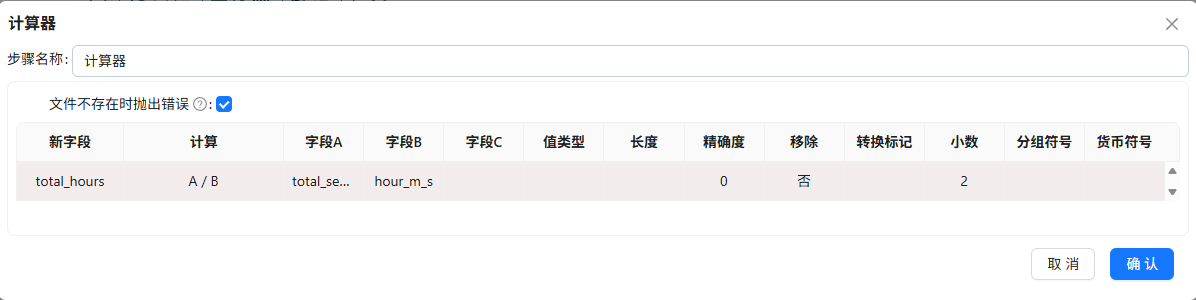
-
JavaScript代码划分等级
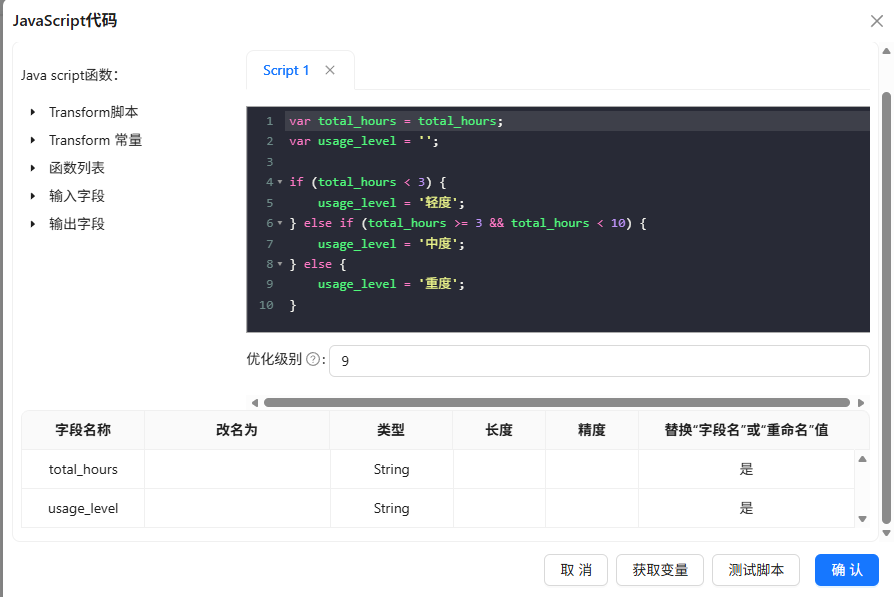
-
按
browser_name、usage_level升序排序后分组统计去重用户数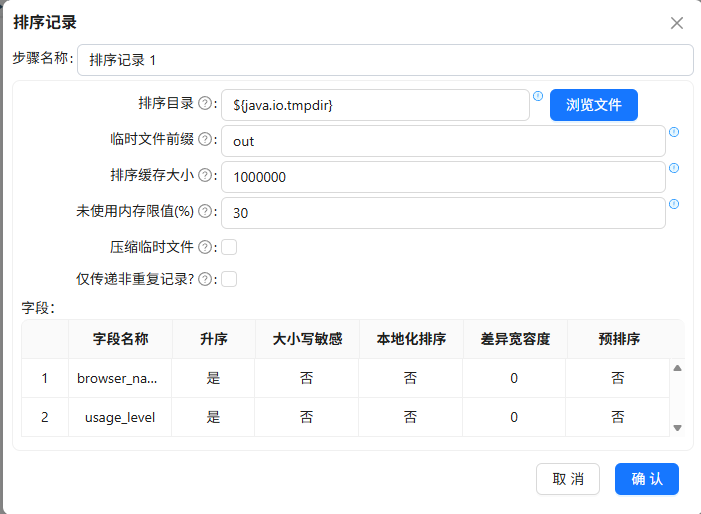
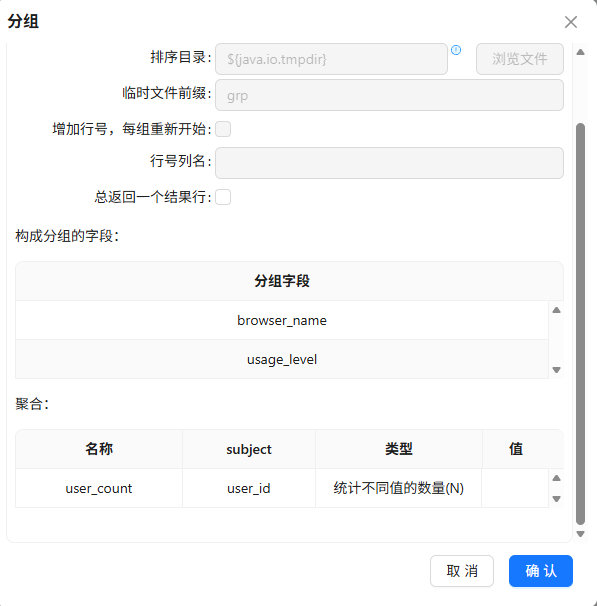
-
输出到
browser_frequency_stats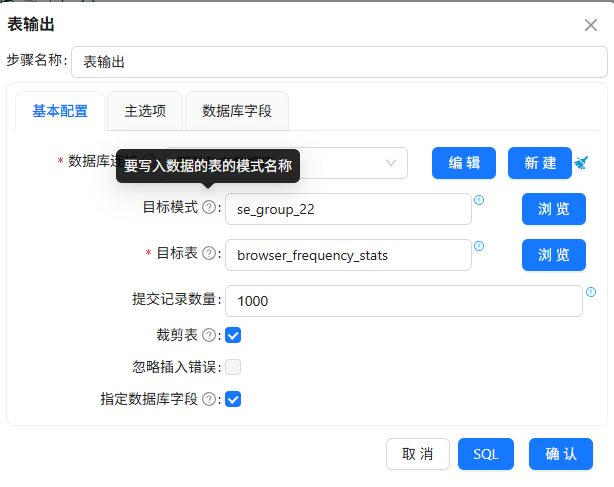
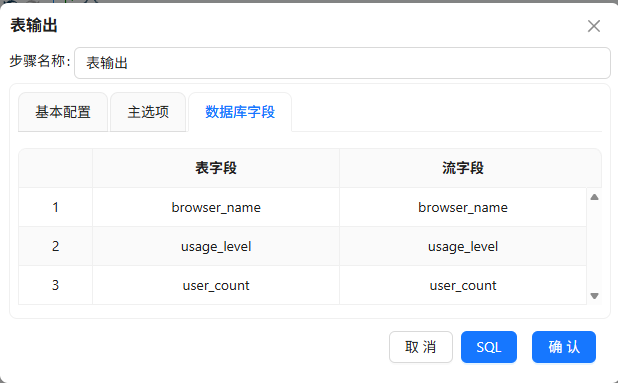

步骤5:浏览器使用数量分布表数据抽取
统计用户使用1种、2种、3种及以上浏览器的用户数:
-
读取表输入(与上一步骤一致,同一个表)
-
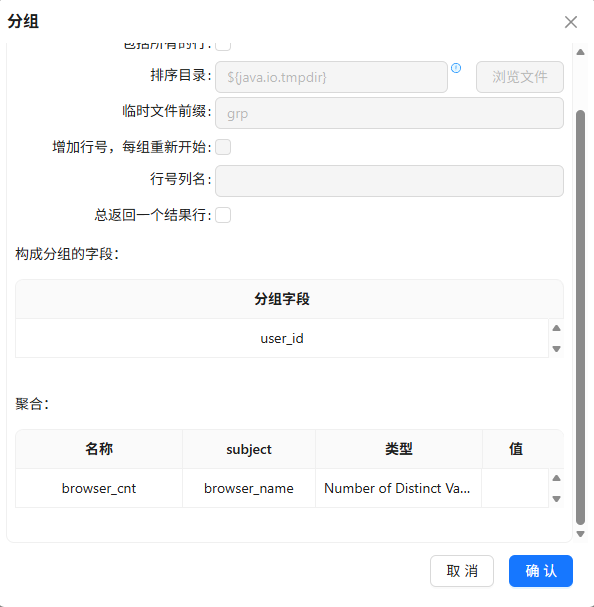
按
user_id升序排序并分组,对browser_name去重计数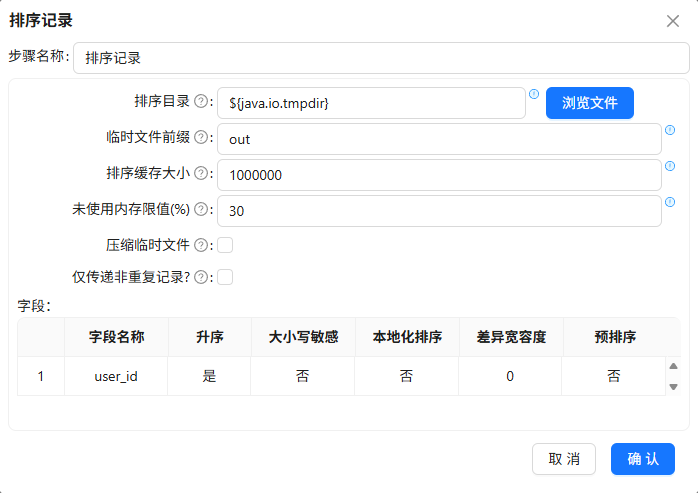
-
JavaScript代码将计数转为分类(
1种、2种、3种及以上)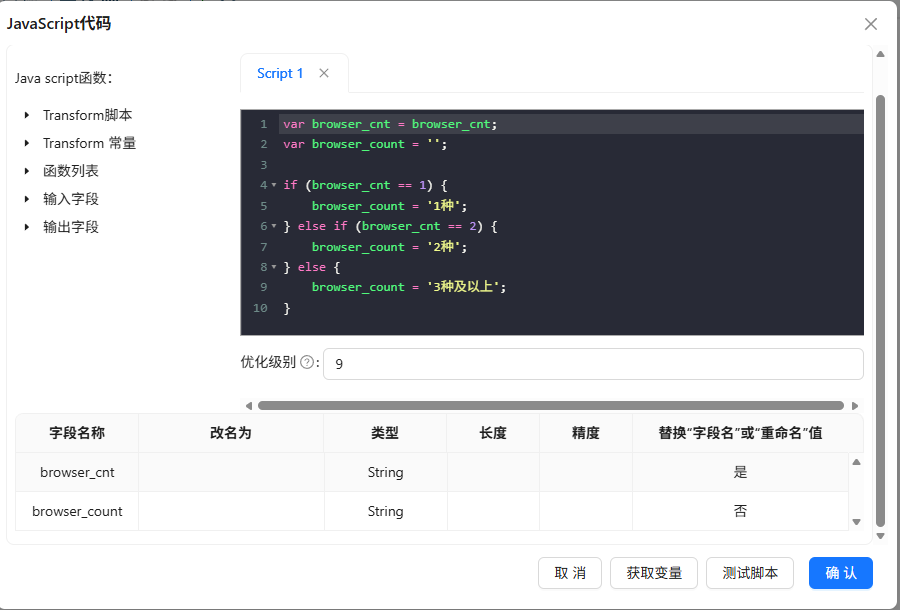
-
按
browser_count升序排序并分类分组统计用户数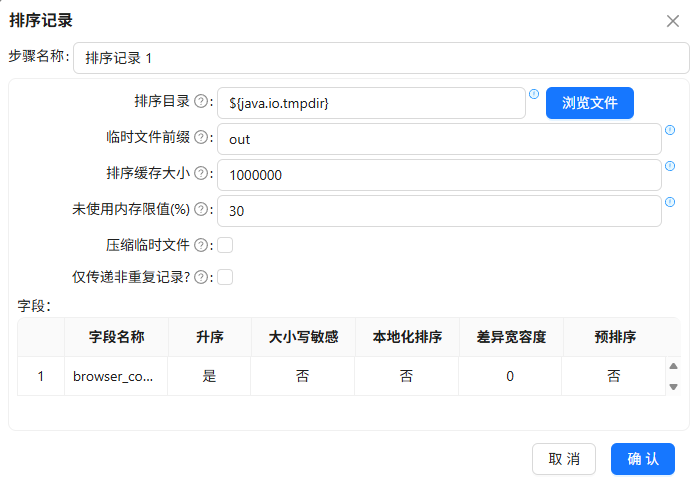
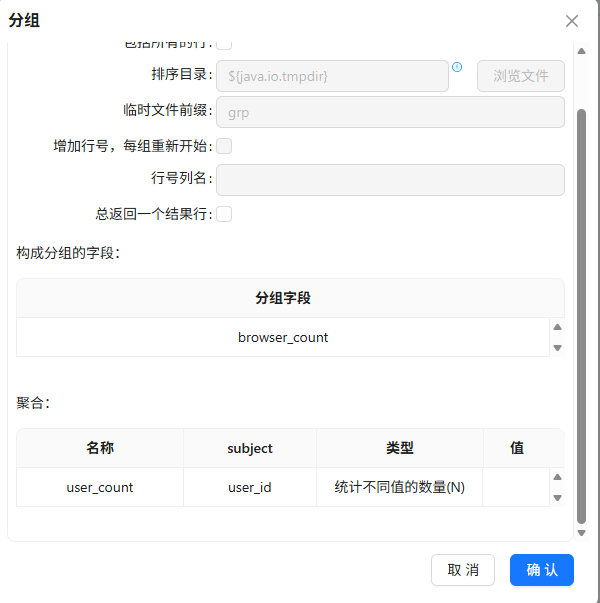
-
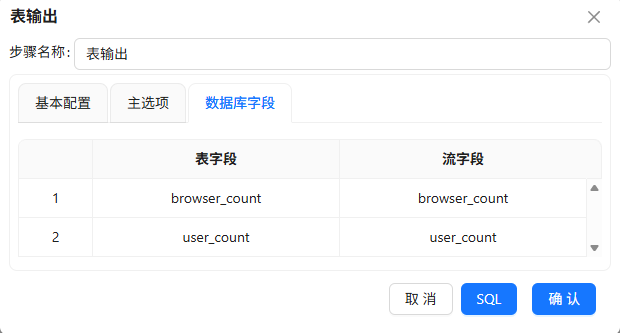
输出到
browser_multi_usage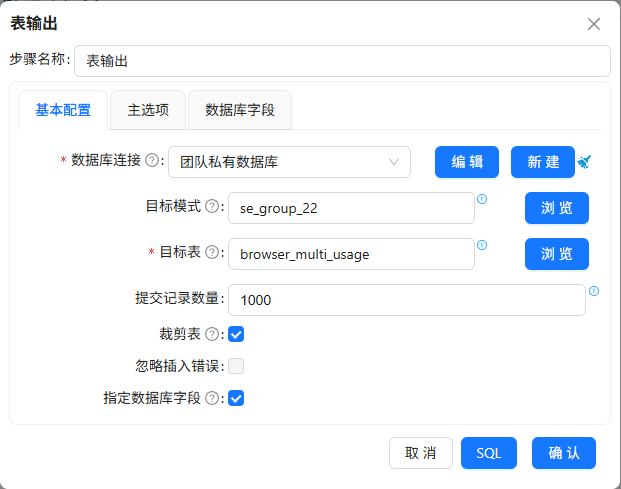

步骤6:工作日vs周末对比表数据抽取
-
读取明细表,通过JavaScript获取日期对应的星期几,判断工作日/周末
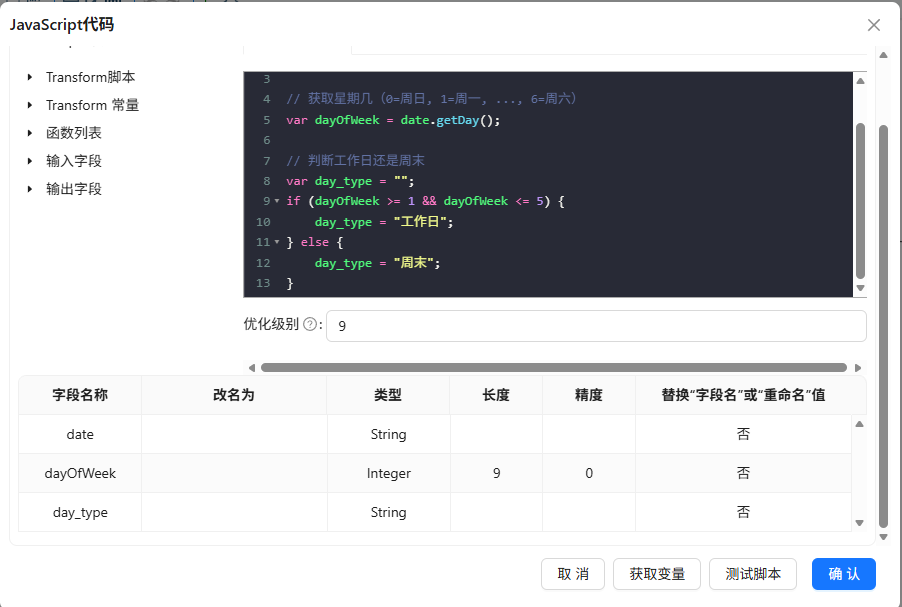
-
按
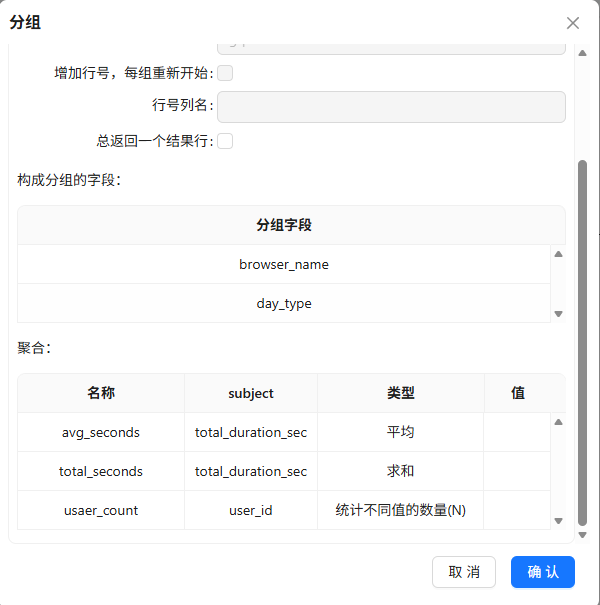
browser_name、day_type分组,计算人均时长(秒)、总时长(秒)、用户数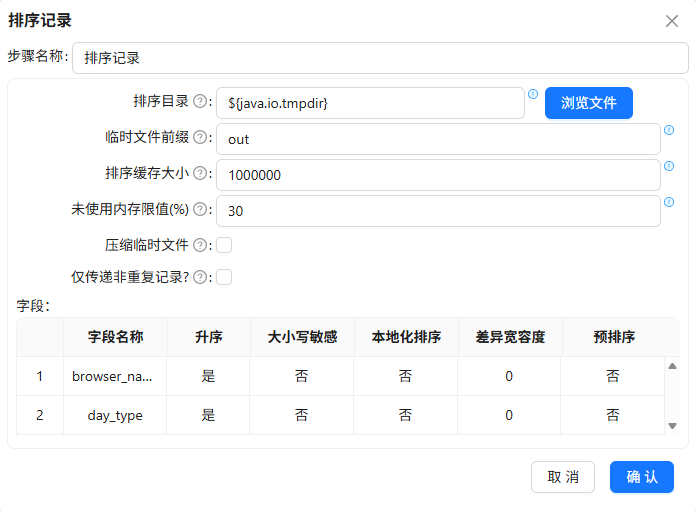
-
增加常量3600,将总时长转为小时
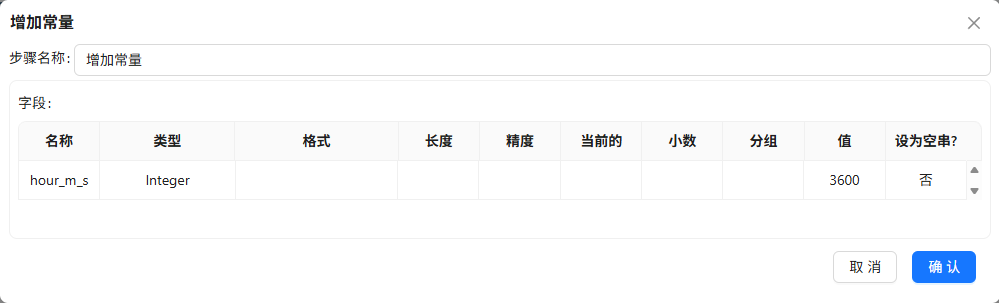
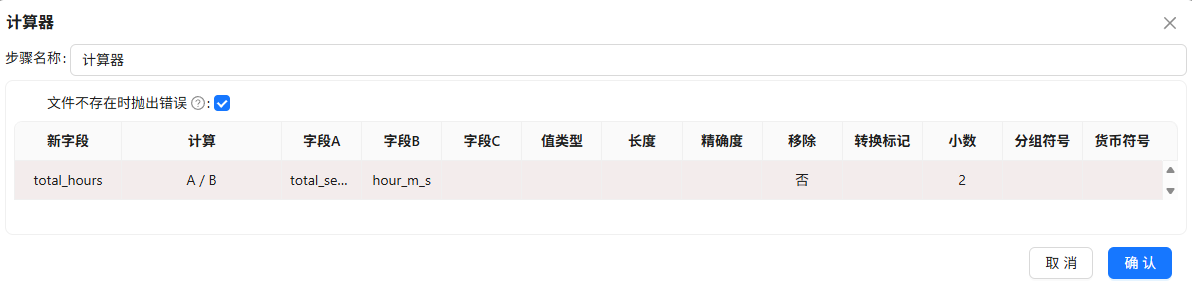
-
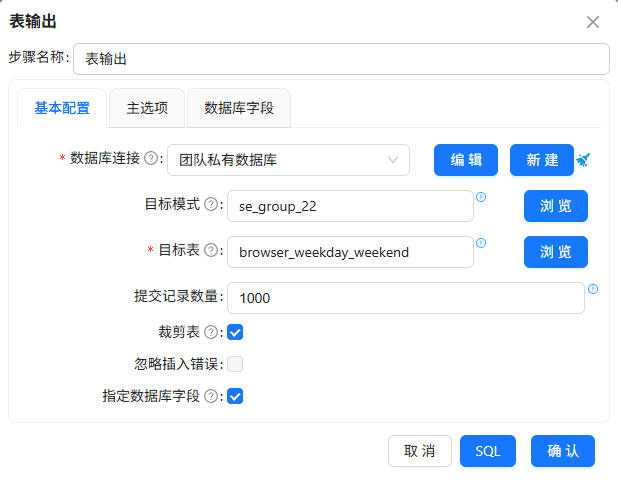
移除不需要的字段后输出到
browser_weekday_weekend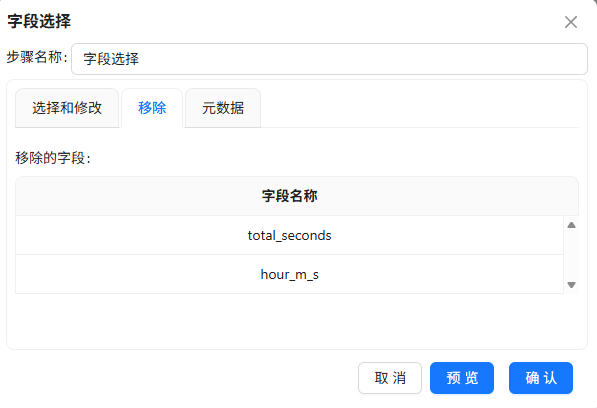
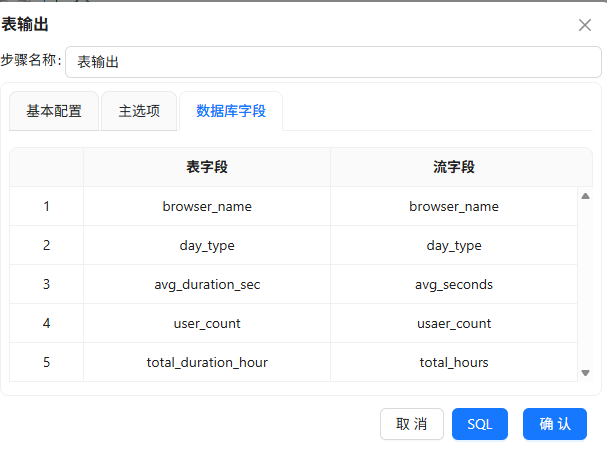
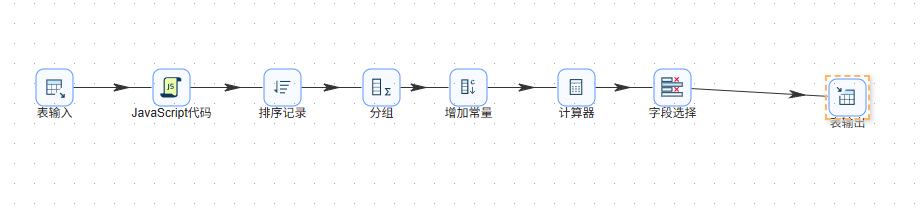
步骤7:核心指标数据抽取
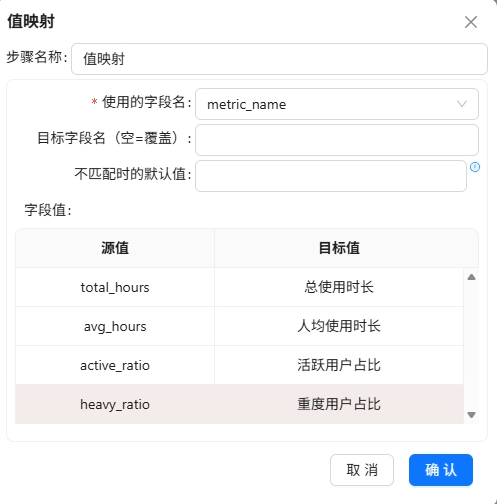
用一条SQL直接计算出全局的总使用时长、人均时长、活跃用户占比、重度用户占比,然后通过行转列组件将一行数据转为四行,再用值映射将指标名称转为中文,最终写入browser_overview。
SELECT
ROUND(SUM(total_duration_sec) / 3600, 2) AS total_hours,
ROUND(SUM(total_duration_sec) / 3600 / COUNT(DISTINCT user_id), 2) AS avg_hours,
ROUND(
(SELECT COUNT(DISTINCT user_id) FROM daily_browser_detail
WHERE usage_date BETWEEN '2012-08-06' AND '2012-08-12'
) * 100.0 / COUNT(DISTINCT user_id), 2
) AS active_ratio,
ROUND(
(SELECT COUNT(*) FROM (
SELECT user_id FROM daily_browser_detail
WHERE usage_date BETWEEN '2012-05-07' AND '2012-07-08'
GROUP BY user_id
HAVING SUM(total_duration_sec) / 3600 > 30
) t) * 100.0 / COUNT(DISTINCT user_id), 2
) AS heavy_ratio
FROM daily_browser_detail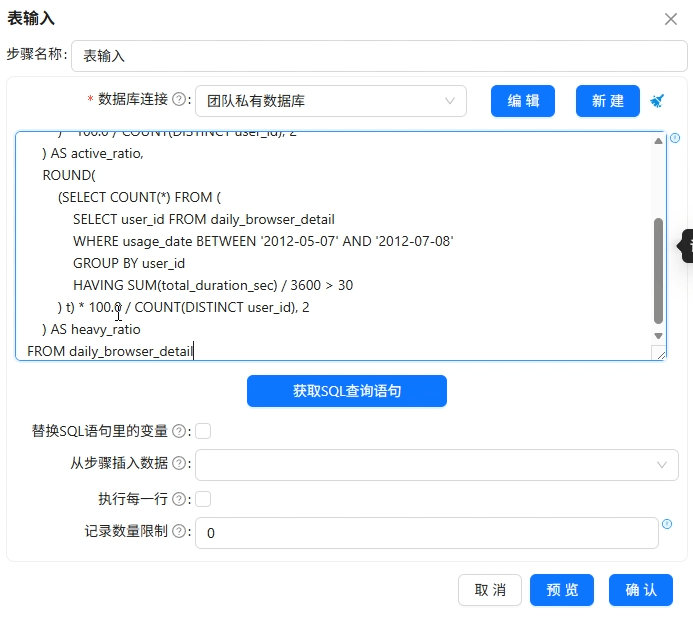

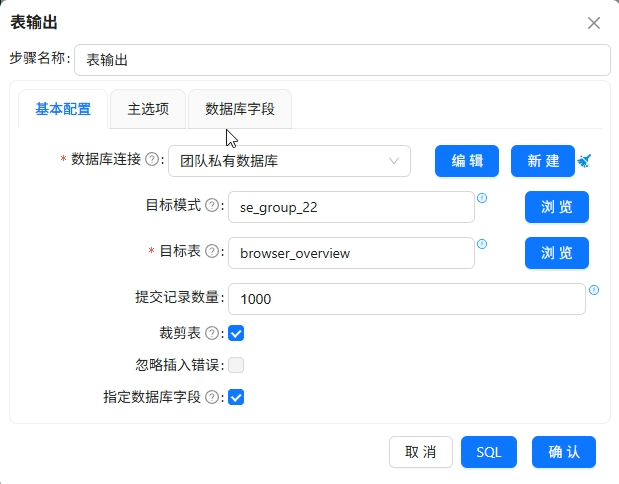
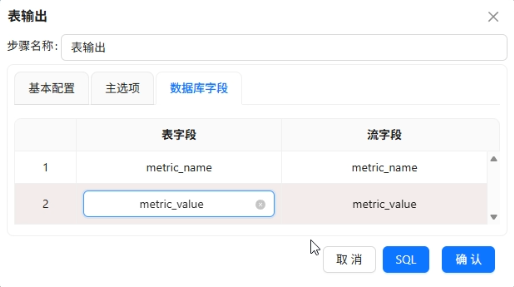
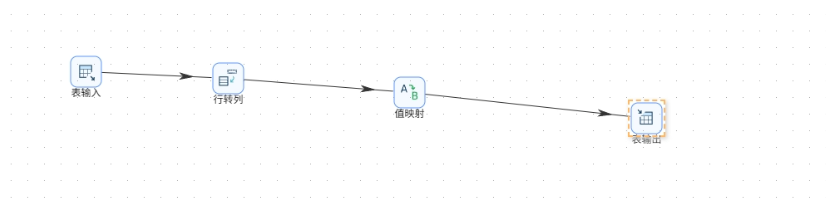
步骤8:用户画像表加工
人口属性数据来自demographic.csv(从公共空间导出)。
主要流程:
-
CSV文件输入读取demographic.csv(右键获取字段)
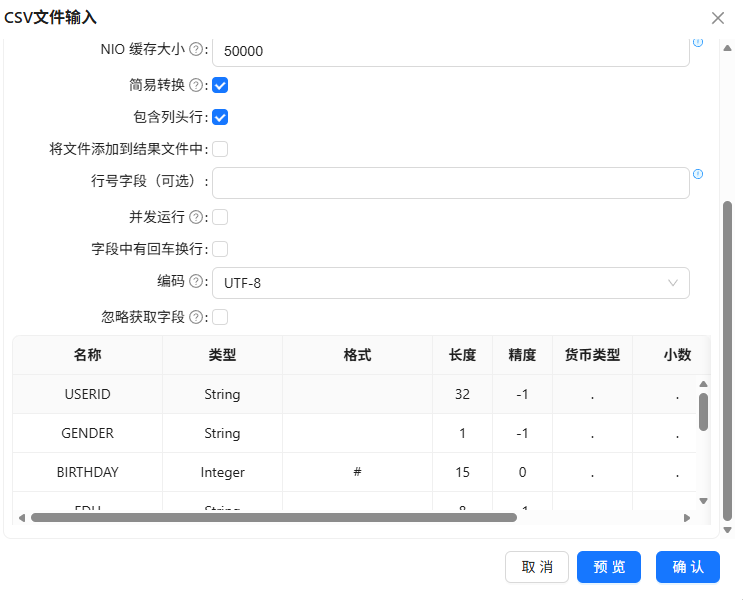
-
增加常量
2012,用计算器算出年龄 = 2012 - BIRTHDAY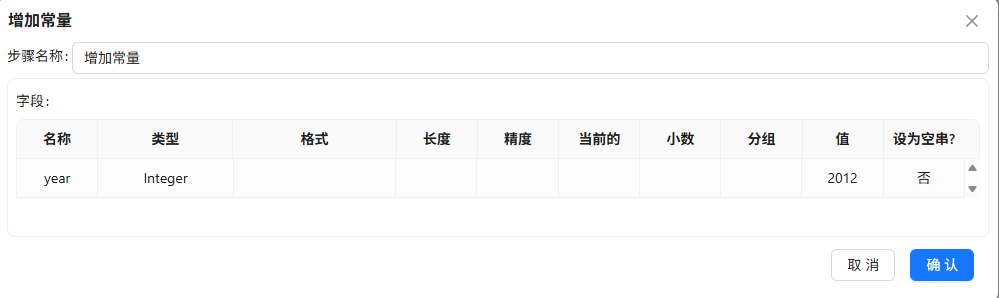
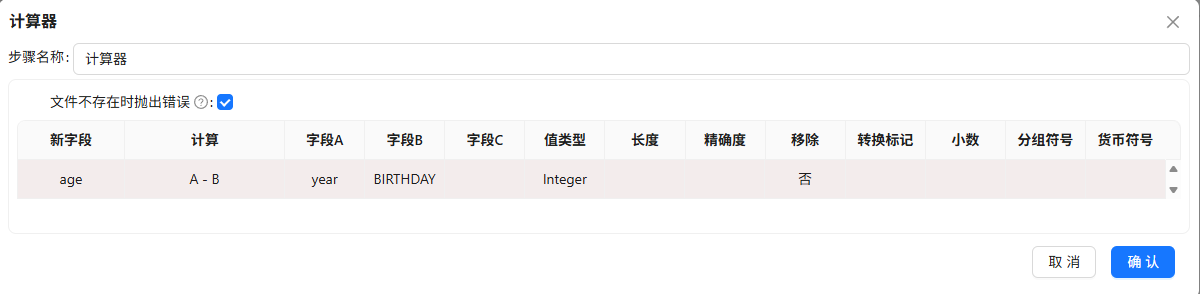
-
JavaScript代码将年龄分段(<18,18-25,26-35,>35)
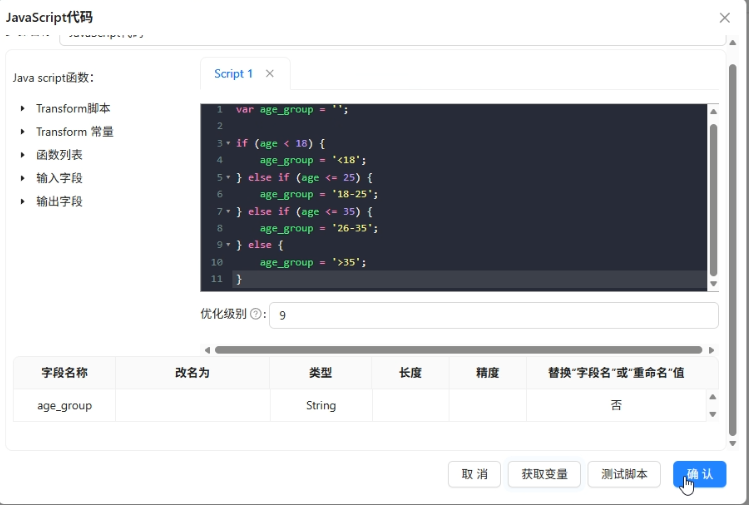
-
表输入读取
daily_browser_detail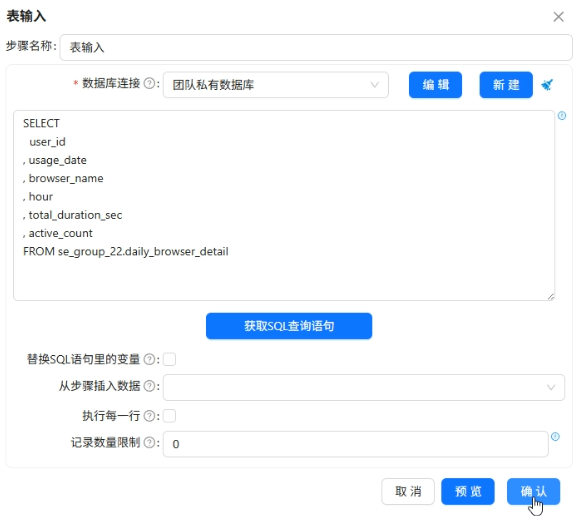
-
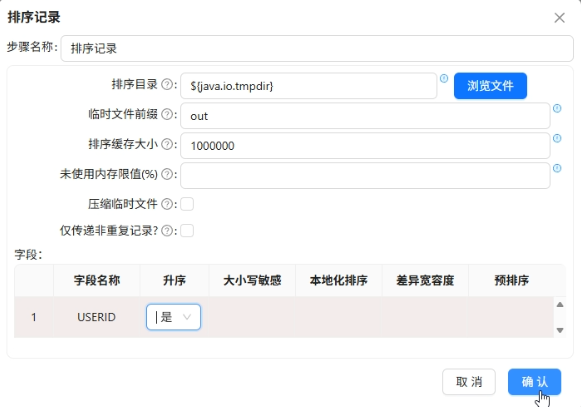
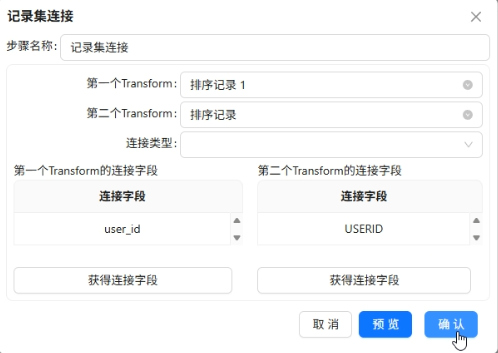
两个数据源分别按
user_id排序,然后用记录集连接左关联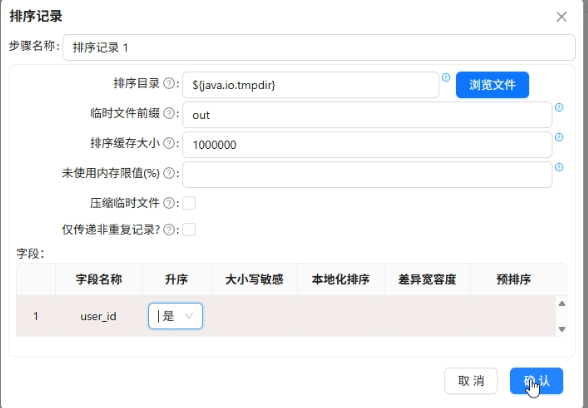
-
按浏览器、性别、学历、职业、收入、省份、居住地类型、年龄段升序排序并分组,统计用户数
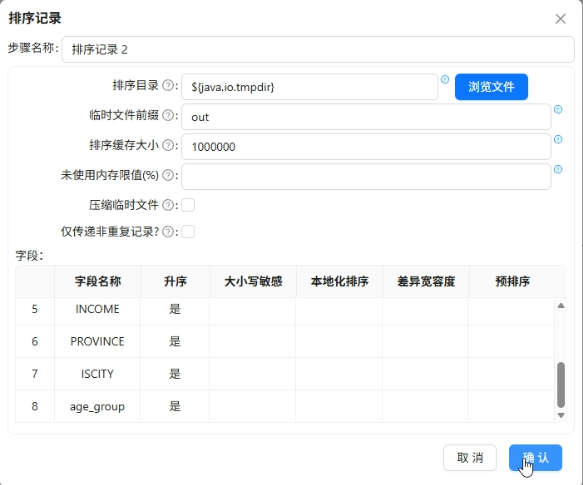
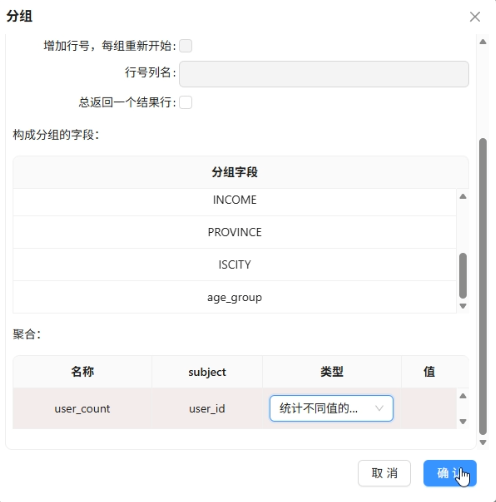
-
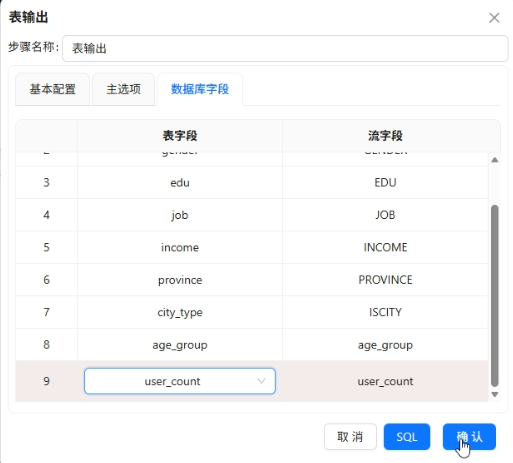
写入
user_profile_stats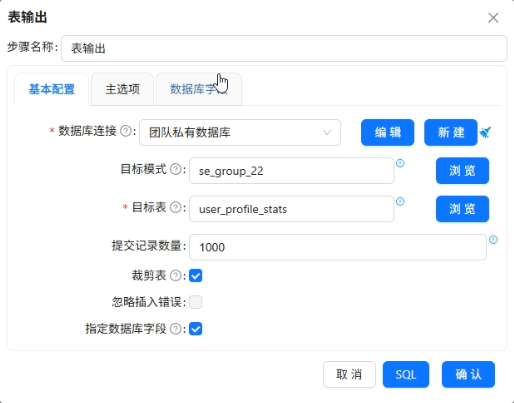
实验结果(第一部分)
所有目标表成功生成,数据探查结果符合预期。例如browser_coverage表包含6个浏览器的用户数、总时长、人均时长;browser_weekly_active包含每个浏览器4周的去重活跃用户数。这些表将作为后续大屏的数据源。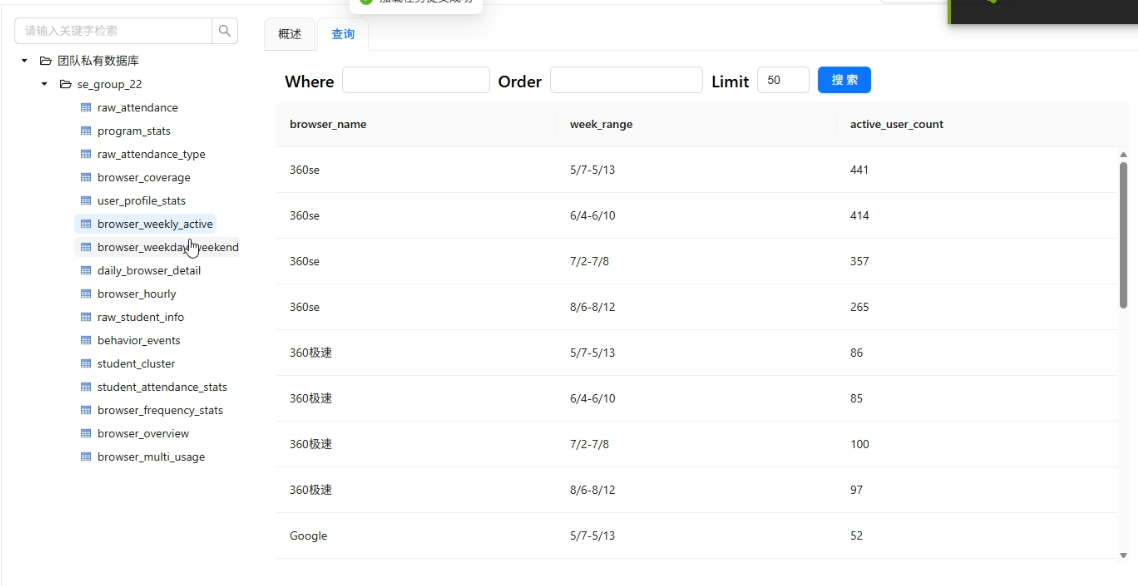
第二部分:静态布局制作(实验5-2)
步骤1:创建大屏
进入助睿Max,点击“新建大屏” → “空白模板”,命名为“市场分析”。
步骤2:设置大屏样式
-
背景图片:使用提供的
bg-2.png链接
-
标题banner:添加“单张图片”组件,重命名“标题banner”,设置图片链接为banner01.png,位置(x=0,y=0,宽=1920,高=80)
-
导航按钮:添加“单张图片”作为按钮背景,添加“通用标题”作为按钮文字。复制一份得到“用户画像”按钮,调整x坐标。
步骤3:按布局草图添加图表区域
每个图表区域由三部分组成:区域背景(单张图片)、标题背景(单张图片)、标题(通用标题)、具体图表组件。
我按照草图依次制作了以下模块:
-
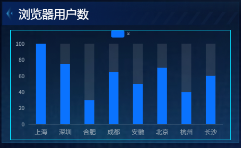
浏览器用户数(基础柱状图)
-
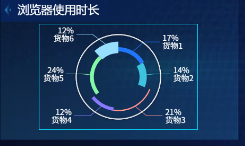
浏览器使用时长占比(多维度饼图,设置内外半径和系列颜色)
-
浏览器人均使用时长(基础柱状图)
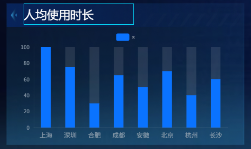
-
数据概览(4个数字翻牌器,每个配图标)

-
工作日vs周末使用时长(分组柱状图)
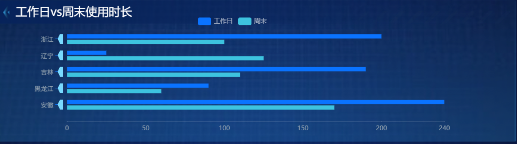
-
24小时活跃用户数分布(区域图)
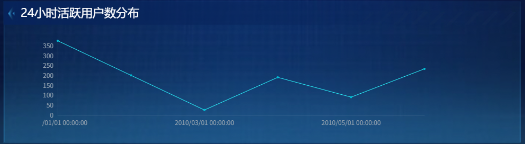
-
浏览器周活跃用户数变化(折线图)
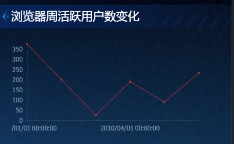
-
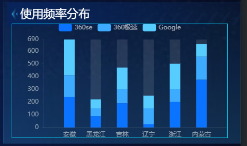
使用频率分布(垂直基本柱图)
-
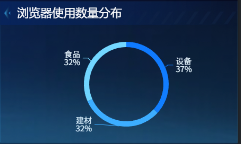
浏览器使用数量分布(基本饼图)
关键样式调整
-
饼图:隐藏外圈,设置标签可见,为6个浏览器分配固定色值(#2177FC、#3DC3DF等)
-
分组柱状图:系列2颜色改为#3DC3DF
-
区域图:颜色设为#29F1FA
-
数字翻牌器:设置标题、后缀、居中对齐
实验结果(第二部分)
大屏静态布局完成,所有图表组件已放置到位,但尚未接入数据(显示为模拟数据或空白)。整体叙事顺序符合“从上到下、从左到右”,核心指标突出。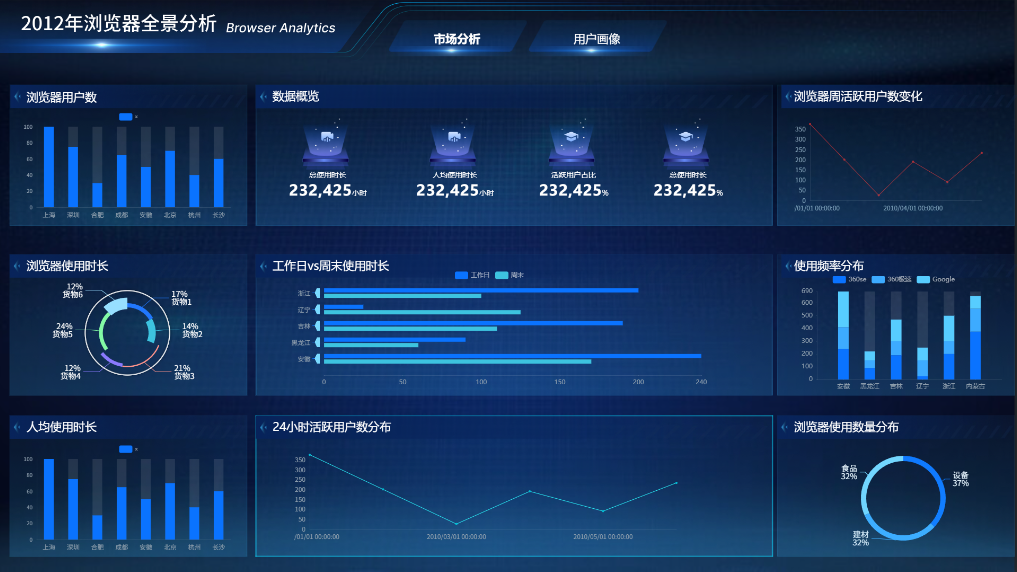
第三部分:蓝图数据接入(实验5-3)
步骤1:创建数据库数据源
进入“我的数据” → “+新建” → “新建数据源”,填写团队私有数据库的连接信息(主机、端口、数据库名、用户名、密码),点击“立即添加”。稍等片刻刷新即可看到新数据源。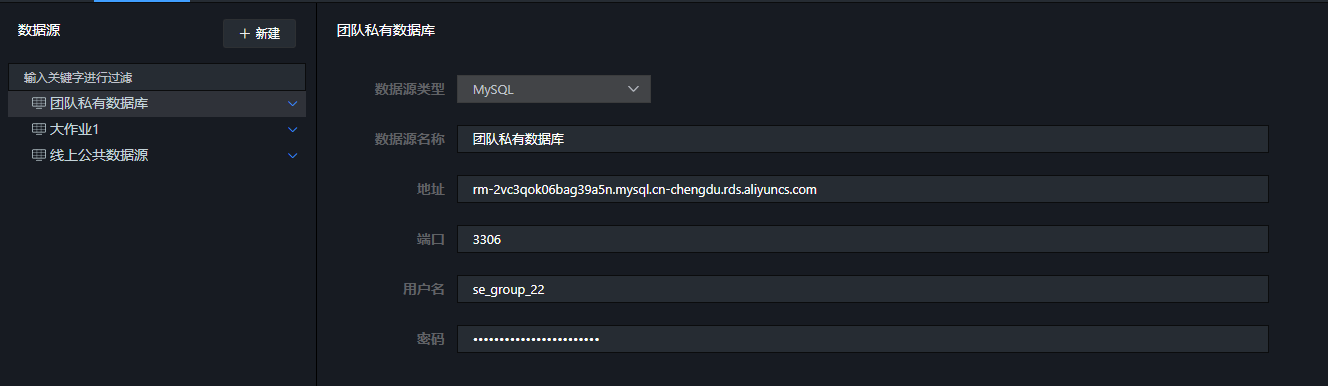
步骤2:导出组件到蓝图编辑器
在大屏编辑器中,右键单击每个需要接入数据的组件(柱状图、饼图、折线图、数字翻牌器等),选择“导出到蓝图编辑器”。导出成功后,切换到“蓝图编辑器”页面,可以在“导入节点”列表中看到这些组件节点。
步骤3:添加全局节点
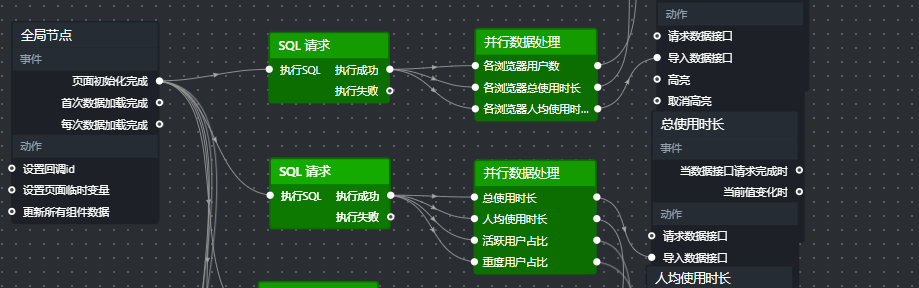
在蓝图编辑器的“逻辑节点”面板中,拖入“全局节点”,它将作为页面加载时的触发器。
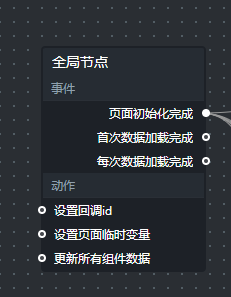
步骤4:为市场格局3个图表配置数据
这三个图表(浏览器用户数柱状图、使用时长占比饼图、人均使用时长柱状图)共用同一张表browser_coverage,一次查询即可。
-
添加“SQL请求”节点,从全局节点的“页面初始化完成”连接到它的“执行SQL”。
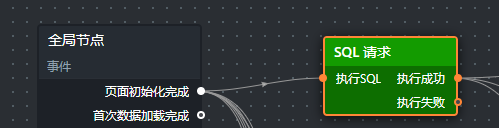
-
配置SQL:
let sql = `
select
browser_name as x,
user_count as y1,
round(total_duration_sec/3600,0) as y2,
round((total_duration_sec/3600)/user_count,1) as y3
from labs.browser_coverage
order by browser_name`
return sql-
添加“并行数据处理”节点,SQL请求节点的“执行成功”连接到它的输入。在并行节点中增加3个处理方法,分别命名为“各浏览器用户数”、“各浏览器总使用时长”、“各浏览器人均使用时长”。
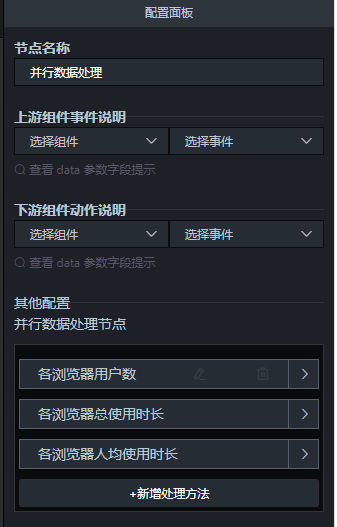
-
编写处理代码(数据映射):
-
用户数:
return data.map(item => ({ x: item.x, y: item.y1, s: '用户数' })); -
总时长:
return data.map(item => ({ name: item.x, value: item.y2 })); -
人均时长:
return data.map(item => ({ x: item.x, y: item.y3, s: '人均时长(小时)' }));
-
-
将三个图表的节点添加到画布,分别将三个处理方法的输出连接到对应图表的“导入数据接口”。
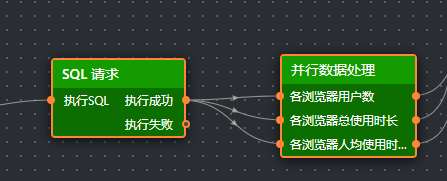
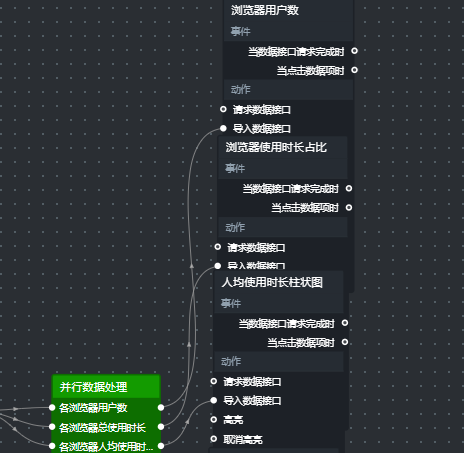
保存后预览,三个图表已显示真实数据。饼图需调整内外半径使样式协调。
步骤5:为指标区域4个数字翻牌器配置数据
-
新建SQL请求节点,查询
browser_overview表:
let sql = `select metric_name, metric_value from labs.browser_overview`
return sql-
并行数据处理增加4个方法(总使用时长、人均使用时长、活跃用户占比、重度用户占比),每个方法用
data.find提取对应指标值,返回[{ value: xxx }]。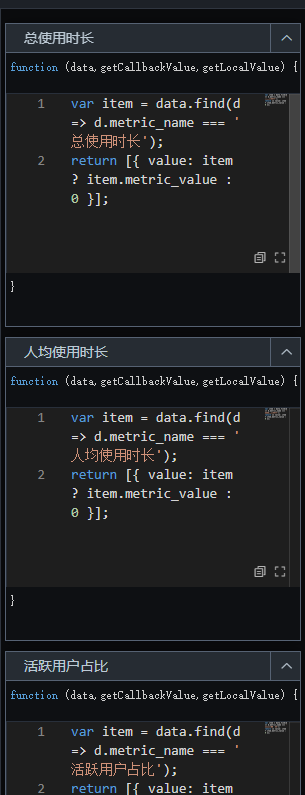
-
将四个数字翻牌器节点添加到画布,连接对应处理方法输出。
步骤6:为其余图表逐个配置SQL请求
每个图表单独配置SQL请求节点,并直接连接图表的“导入数据接口”(因为不需要并行分发)。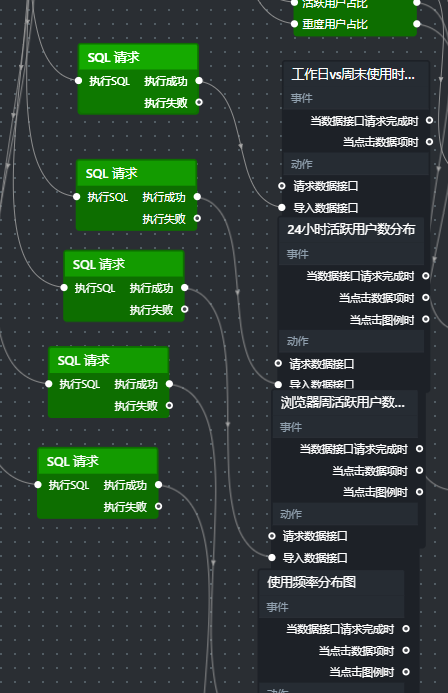
以“工作日vs周末使用时长”为例:
let sql = `
select
browser_name as x,
avg_duration_sec as y,
day_type as s
from labs.browser_weekday_weekend
order by browser_name, day_type`
return sql其他图表类似,注意折线图(24小时活跃分布、周活跃趋势)有6个系列,需要在画布编辑器的“数据系列”中分别设置每个系列的折线和标记颜色,确保图例与线条颜色一致。
步骤7:预览并发布
所有蓝图连接完成后,点击“保存”,然后点击大屏右上角“预览”按钮,检查每个图表数据是否正确显示。确认无误后,点击“发布” → “发布分享” → 复制分享链接,即可在线访问。
最终发布的大屏链接示例:http://47.109.66.142:30887/#/dataScreen/release?shareId=6c8835415fd44ee88317766691976922
实验结果(第三部分)
所有图表成功接入真实数据,实现了:
-
市场格局一目了然(Chrome用户数最多,IE使用时长占比最高)
-
时段偏好清晰(晚间20-22点为活跃高峰)
-
周活跃趋势显示部分浏览器活跃度波动
-
使用频率分布显示Chrome重度用户占比最高
-
浏览器使用数量分布显示约50%用户只用1种浏览器
问题与解决
问题1:分组组件前未按分组字段排序导致重复数据
在加工browser_weekly_active时,分组前没有对数据按browser_name和week_range排序,结果出现重复行。
原因:分组组件依赖排序来合并相同键值,未排序时可能将同一分组的数据分散在不同块中。
解决:在分组前添加“排序记录”组件,排序字段与分组字段完全一致。
问题2:饼图外圈显示多余白色环形
饼图默认有外圈(圆环图样式),影响美观。
解决:在饼图样式中,将外圈颜色的透明度调为0,即可隐藏外圈。
问题3:折线图图例与折线颜色不一致
24小时活跃分布折线图有6个浏览器,默认颜色自动分配,但预览时发现图例颜色和折线颜色不对应。
解决:在画布编辑器中选中图表,点开“数据系列”,为6个系列分别手动设置固定颜色(与饼图色值保持一致)。
问题4:数字翻牌器不显示数据
按照蓝图配置后,数字翻牌器仍显示0或空白。
原因:并行数据处理返回的格式不正确,翻牌器要求[{ value: 数值 }]结构,但我最初返回了{ value: xxx }对象。
解决:修改处理方法,用数组包裹对象。
问题5:复制组件后不显示内容
在布局阶段,复制整个组后,新组的图表或文字不显示。
原因:复制后组件的内部状态未刷新。
解决:选中复制的组件,在右侧“数据”tab中点击“刷新数据”即可。
实验总结
收获
通过本次完整的实验,我掌握了以下技能:
-
数据加工:使用助睿ETL的“表输入”、“分组”、“值映射”、“JavaScript代码”、“记录集连接”等组件,高效完成多张聚合表的加工,理解了数据仓库“分层加工”的思想。
-
大屏布局设计:从业务问题出发,设计合理的图表选型和布局,利用成组、背景图片、标题装饰等提升大屏美观度。
-
蓝图编辑器:理解了数据源、触发器、动作、并行数据处理等核心概念,能够为不同图表配置SQL查询,并通过数据处理节点灵活转换数据格式,实现图表与真实数据的绑定。
-
零代码平台优势:整个过程无需编写后端代码,仅通过拖拽组件和简单SQL即可完成复杂的数据分析可视化项目,极大提升了效率。
对助睿数智平台的评价
助睿数智(Uniplore)真正实现了从数据接入、ETL处理到可视化的全链路零代码操作。其ETL组件丰富(排序、分组、连接、计算器等),基本覆盖了日常数据加工需求;大屏制作支持灵活的样式定制和蓝图交互;蓝图编辑器虽然有一定学习曲线,但熟练后可以高效管理复杂数据流。对于教学场景和企业快速数据分析原型验证,这是一个非常实用的平台。

一站式 AI 云服务平台
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)