
800万条数据背后的秘密:谁才是真正的王者?(实验5)
实验平台:助睿在线实验平台 https://lab.guilian.cn/本实验依托助睿数智(Uniplore)一站式数据科学平台开展。该平台打通了数据接入、ETL 加工、机器学习建模到可视化呈现的完整流程,支持零代码操作,适用于教学实训及企业级数据处理场景。助睿数智官网:Uniplore iDIS-大数据智能全流程服务平台-BI数据可视化工具数据加工工具:助睿 ETL 数据集成平台建模工具:助
【实验5-1】
1 实验目的
本实验以"用户 - 日 - 浏览器 - 小时"明细表为基础数据源,针对数据大屏展示需求,逐步完成以下统计表的加工处理:
- 浏览器市场格局分析(覆盖率与使用时长)
- 浏览器周活跃走势分析
- 浏览器使用强度分布分析
- 用户多浏览器使用情况分析
- 浏览器在工作日与周末的差异化分析
- 用户画像多维分析(性别、年龄段、学历、职业、收入水平、居住地性质、省份分布)
2 实验环境
实验平台:助睿在线实验平台 https://lab.guilian.cn/
本实验依托助睿数智(Uniplore)一站式数据科学平台开展。该平台打通了数据接入、ETL 加工、机器学习建模到可视化呈现的完整流程,支持零代码操作,适用于教学实训及企业级数据处理场景。
- 助睿数智官网:Uniplore iDIS-大数据智能全流程服务平台-BI数据可视化工具
- 数据加工工具:助睿 ETL 数据集成平台
- 建模工具:助睿 AI 人工智能平台
- 数据规模:涵盖 1000 名用户、超 800 万条行为记录,数据总量约 825MB
3 实验数据
本实验所用数据来源于前序实验《浏览器用户行为分析与流失预测 - 数据加工》的产出结果,同时还会引入原始数据中的 demographic 用户属性表。
前序实验已产出的数据表如下:
| 表名 | 说明 |
|---|---|
| daily_browser_detail | 用户 - 日 - 浏览器 - 小时明细表(本实验第 4.1 节中将输出该表) |
| browser_coverage | 浏览器市场覆盖率统计表 |
| browser_hourly | 浏览器时段活跃统计表 |
4 整体分析框架
4.1 需要解答哪些业务问题?
在动手搭建数据大屏之前,首要任务是厘清一个关键问题:大屏上究竟需要呈现哪些内容?
大屏中的每一个图表、每一个数值背后,都必须有经过加工的数据作为支撑。我们不适合在大屏上直接读取原始明细表(behavior_events),原因如下:
- 原始明细数据体量庞大,实时查询效率低,会拖慢大屏的响应速度
- 大屏展示的是经过汇总和聚合后的结果,而非逐条原始记录
- 不同图表之间可能复用相同的聚合结果,提前处理可以有效避免重复运算
所以,在大屏设计之初,我们必须先梳理清楚:数据分析需要回答哪些核心业务问题?
| 业务问题 | 分析价值 |
|---|---|
| 哪款浏览器的用户基数最大? | 识别行业领头羊,评估自身产品所处的市场位置 |
| 哪款浏览器的使用时长最高? | 用户规模大并不等同于粘性强,使用时长才能体现用户的真实依赖程度 |
| 用户活跃度呈上升还是下降态势? | 把握产品所处的生命周期阶段,及早捕捉衰退迹象 |
| 用户在什么时段最为活跃? | 为消息推送和运营活动选择最佳触达时机 |
| 用户属于高频用户还是偶尔使用? | 区分核心用户与边缘用户,为差异化运营提供依据 |
| 用户通常同时使用几款浏览器? | 衡量用户忠诚度,评估被竞品替代的潜在风险 |
| 用户还在使用哪些竞品浏览器? | 锁定主要竞争对手,有针对性地制定竞争策略 |
| 工作日和周末的使用行为有何差异? | 区分办公场景与休闲场景,据此优化产品功能设计 |
| 核心用户群体的画像特征是什么? | 明晰目标受众,为产品迭代和营销决策提供方向 |
| 用户的受教育程度如何? | 影响产品的功能复杂度设计,高学历群体可能更易接受复杂功能 |
| 用户的收入状况如何? | 决定商业变现策略,高收入群体往往具有更强的付费意愿 |
| 用户地理分布情况如何? | 指导区域化市场拓展和资源配置 |
4.2 从哪些分析维度切入来解答这些问题?
基于以上业务问题,我们将分析内容划分为两大板块:市场行为分析与用户画像分析,各板块涵盖以下分析维度:
大屏一:浏览器市场行为分析
| 维度 | 对应的业务问题 | 核心衡量指标 |
|---|---|---|
| 市场格局 | 哪款浏览器用户量最大?哪款使用最久? | 用户数、使用时长占比、人均时长 |
| 周活跃走势 | 用户活跃度是增是减? | 各周活跃用户数 |
| 时段偏好 | 用户何时最为活跃? | 24 小时活跃分布 |
| 使用强度 | 用户属于重度还是轻度使用? | 轻/中/重度用户占比 |
| 浏览器使用数量 | 用户同时使用几款浏览器? | 1 种/2 种/3 种及以上用户占比 |
| 竞品交叉 | 用户还在用哪些其他浏览器? | 两两浏览器共同用户数 |
| 工作日 vs 周末 | 办公时段和休息时段的使用习惯有何不同? | 工作日/周末使用时长对比 |
大屏二:浏览器用户画像分析
| 维度 | 对应的业务问题 | 核心衡量指标 |
|---|---|---|
| 性别构成 | 男女用户的比例情况? | 男/女用户数及占比 |
| 年龄结构 | 哪个年龄段的用户最集中? | 各年龄段用户数及占比 |
| 学历层次 | 用户整体受教育水平如何? | 各学历用户数及占比 |
| 职业类型 | 哪些职业的用户最活跃? | 各职业用户数及占比 |
| 收入层级 | 用户整体收入水平如何? | 各收入段用户数及占比 |
| 居住地性质 | 城镇用户多还是乡村用户多? | 城市/城郊/乡村用户占比 |
| 地域分布 | 用户集中在哪些省份? | 各省用户数 |
4.3 需要产出哪些目标表?
根据以上分析维度,我们倒推出需要加工生成的目标表:
大屏一对应的目标表:
| 目标表 | 对应维度 | 数据来源 |
|---|---|---|
| browser_overview | 核心指标 | daily_browser_detail |
| browser_coverage | 市场格局 | daily_browser_detail |
| browser_weekly_active | 周活跃走势 | daily_browser_detail |
| browser_hourly | 时段偏好 | daily_browser_detail |
| browser_frequency_stats | 使用强度 | daily_browser_detail |
| browser_multi_usage | 浏览器使用数量 | daily_browser_detail |
| browser_cooccurrence | 竞品交叉 | daily_browser_detail |
| browser_weekday_weekend | 工作日 vs 周末 | daily_browser_detail |
大屏二对应的目标表:
| 目标表 | 对应维度 | 数据来源 |
|---|---|---|
| user_profile_stats | 性别、年龄、学历、职业、收入、省份、居住地性质 | demographic、daily_browser_detail |
4.4 目标表与数据来源的关联关系
(此处预留关系图截图位置)
【截图位置】
5 各目标表加工说明
| 目标表 | 用途 | 加工逻辑 | 数据来源 |
|---|---|---|---|
| browser_coverage | 解答"哪款浏览器用户最多?哪款使用最久?" | 按 browser_name 汇总,计算用户数、总时长、人均时长 | daily_browser_detail(前序实验已输出) |
| browser_hourly | 解答"用户何时最活跃?" | 按 browser_name、hour 汇总,计算活跃用户数 | daily_browser_detail(前序实验已输出) |
| browser_weekly_active | 解答"用户活跃度是增是减?" | 按 browser_name 和周编号汇总,计算各周活跃用户数 | daily_browser_detail |
| browser_frequency_stats | 解答"用户是重度还是轻度使用?" | 计算各用户的周使用时长,依据阈值(轻度 <3h、中度 3-10h、重度 >10h)划分等级,再按浏览器汇总 | daily_browser_detail |
| browser_multi_usage | 解答"用户同时使用几款浏览器?" | 统计各用户使用的浏览器种类数,按 1 种、2 种、3 种及以上分段 | daily_browser_detail |
| browser_cooccurrence | 解答"用户还在用哪些竞品浏览器?" | 统计每对浏览器被同一用户共同使用的人数 | daily_browser_detail |
| browser_weekday_weekend | 解答"工作日和周末使用习惯有何差异?" | 按浏览器和日期类型(工作日/周末)汇总,计算人均使用时长 | daily_browser_detail |
| user_profile_stats | 解答"核心用户是谁?教育/收入水平如何?"等 | 按性别、年龄段、学历、职业、收入、省份、居住地性质分组汇总 | demographic、daily_browser_detail |
6 实验步骤
6.1 准备"用户 - 日 - 浏览器 - 小时"明细表
前序实验中"互联网用户行为日志数据清洗抽取"转换流已经包含了生成明细数据的完整处理逻辑,但当时仅输出了分支 A 和分支 B(即 browser_coverage 和 browser_hourly)。本步骤需要将该转换流复制一份,修改输出目标为明细表,作为本实验后续所有加工环节的基础数据。
6.1.1 创建用户_日_浏览器_小时明细表
首先,在团队私有数据库中创建用于存储"用户 - 日 - 浏览器 - 小时"明细数据的表结构。
打开前序实验建立的项目"互联网用户行为日志":
新建转换流"创建用户_日_浏览器_小时明细表",将"执行一个 SQL 脚本"组件拖入画布:
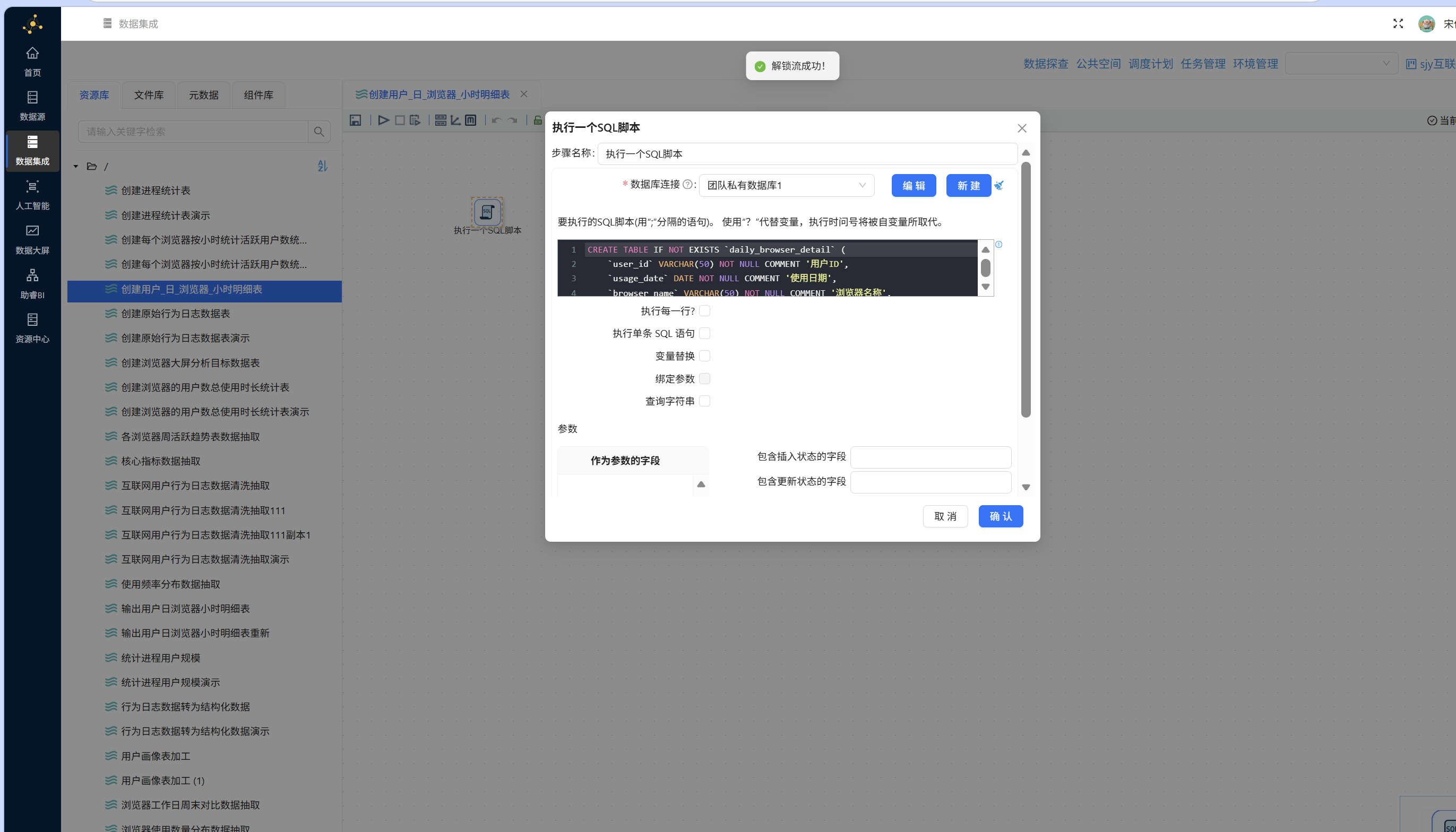
双击该组件,数据库连接选择"团队私有数据库",在 SQL 编辑框中输入以下建表语句:
CREATE TABLE IF NOT EXISTS `daily_browser_detail` (
`user_id` VARCHAR(50) NOT NULL COMMENT '用户 ID',
`usage_date` DATE NOT NULL COMMENT '使用日期',
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`hour` TINYINT NOT NULL COMMENT '小时',
`total_duration_sec` INT NOT NULL COMMENT '总使用时长 (秒)',
`active_count` INT NOT NULL COMMENT '活跃次数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户_日_浏览器_小时明细表';
点击"运行"按钮执行该转换流:
6.1.2 复制并调整转换流
在前序实验的项目中,定位到"互联网用户行为日志数据清洗抽取"转换流,右键选择"复制":
在根目录位置右键点击"粘贴":

粘贴完成后,右键将其重命名为"输出用户日浏览器小时明细表":
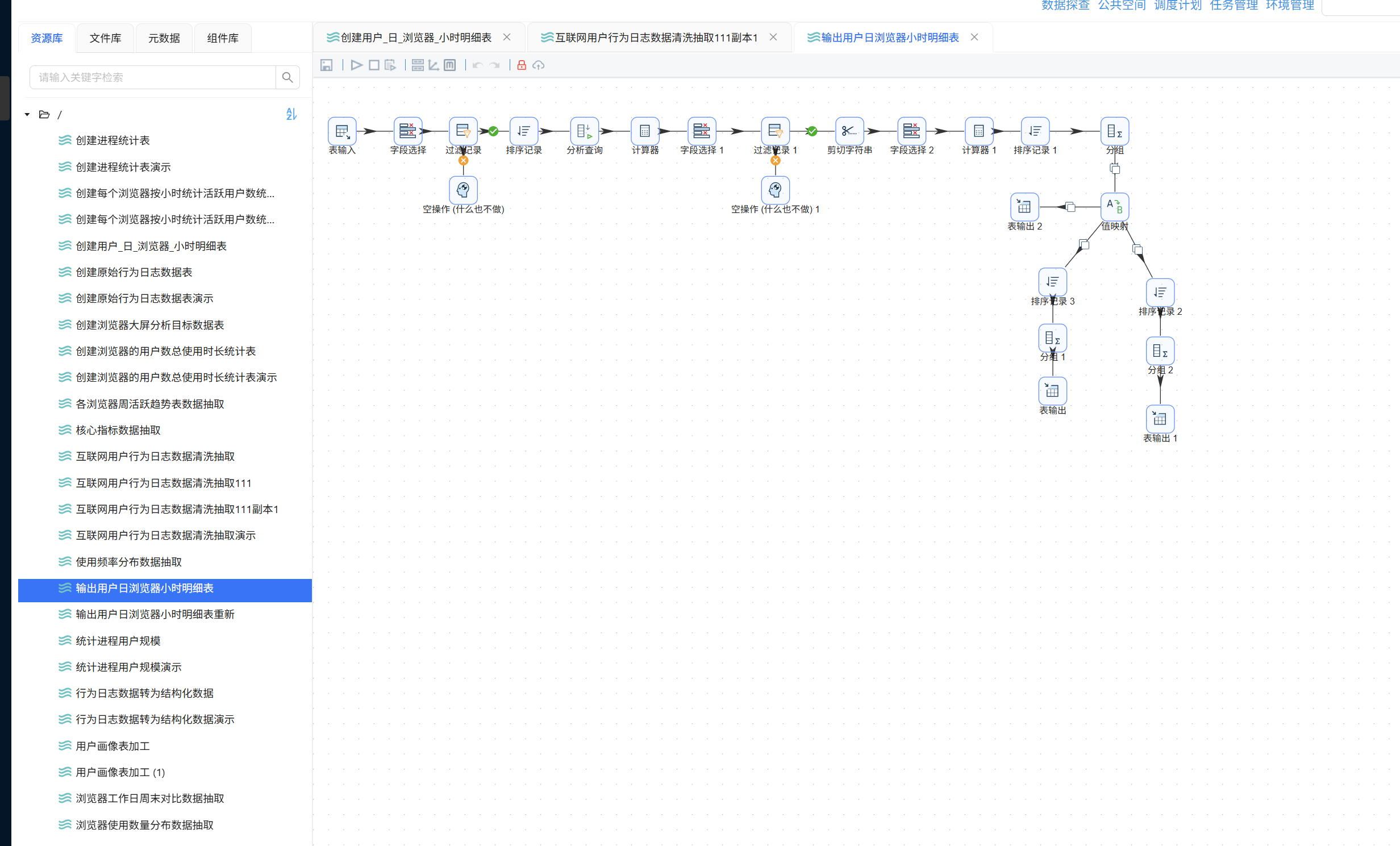
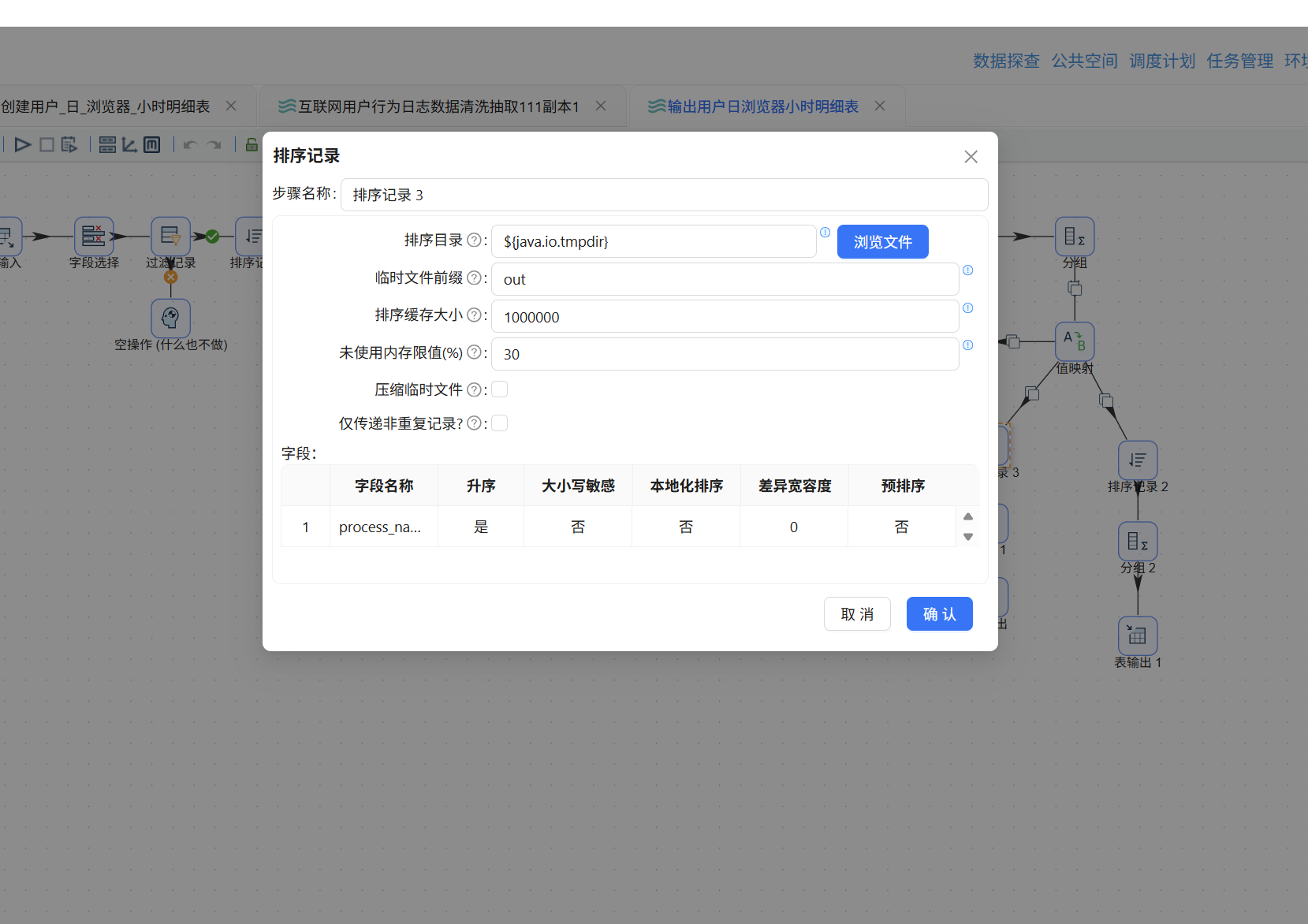
注意事项:前序实验中"排序记录 1"组件仅按 process_name 做了升序排序,但后续分组组件的分组字段包含 user_id、usage_date、process_name、hour 四个字段。因此,必须将"排序记录 1"的排序字段与分组字段保持一致,否则会产生重复数据:
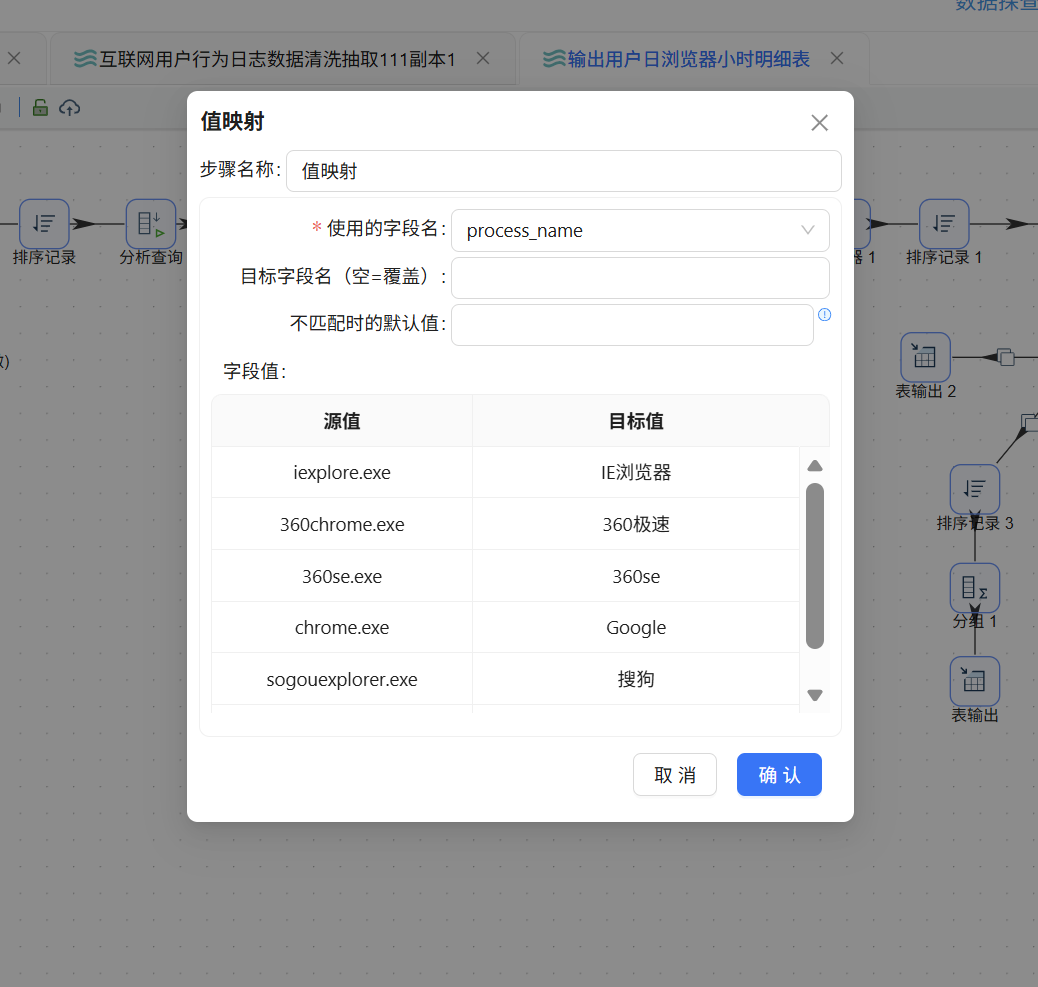
6.1.3 浏览器名称映射
在分组组件之后添加"值映射"组件。该组件一端连接原分支 A 的"分组 1"组件,另一端通过"复制发送"连接原分支 B 的"排序记录 2"组件:
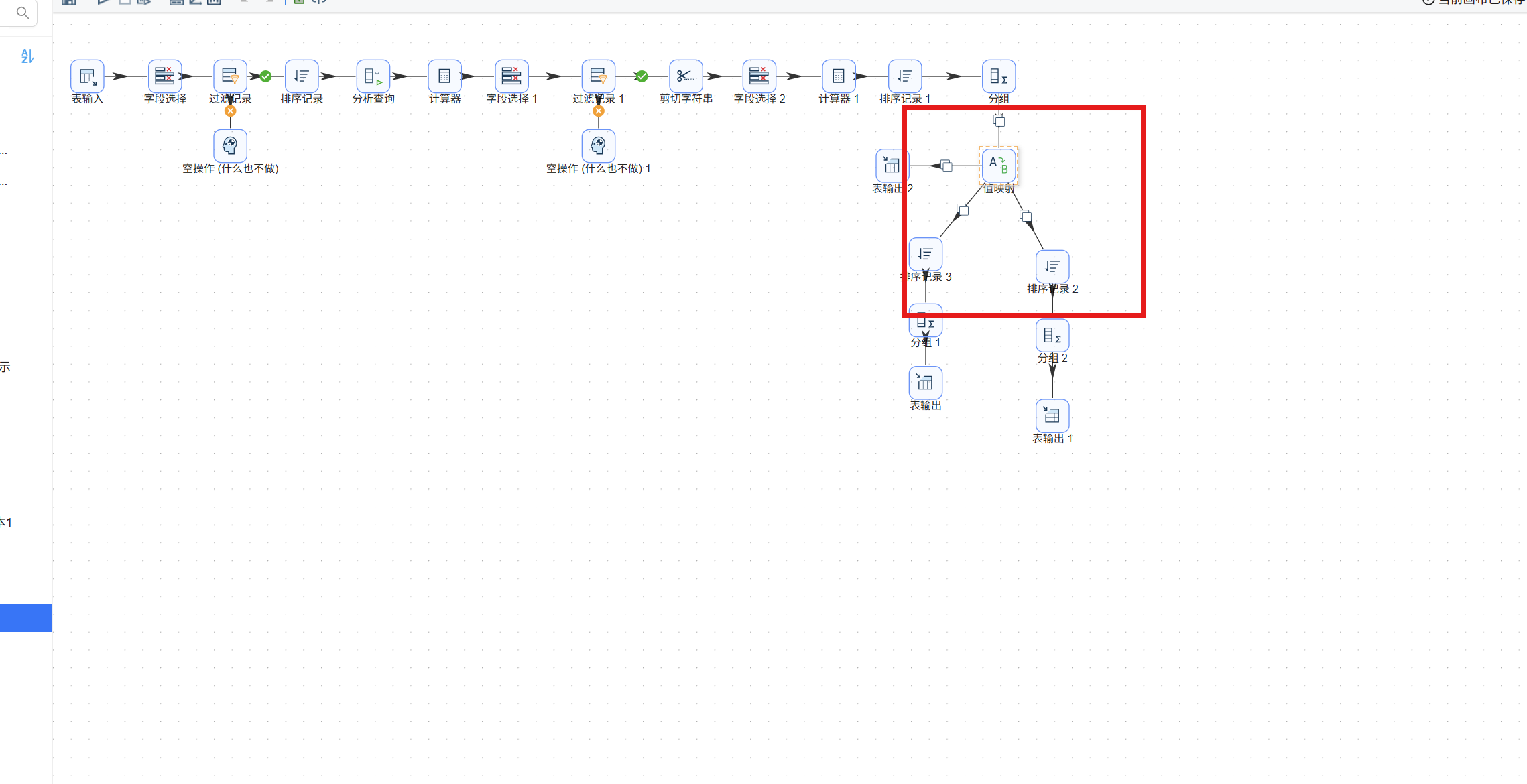
在值映射组件中按如下规则添加映射关系:
| 进程名 | 映射后名称 |
|---|---|
| iexplore.exe | IE 浏览器 |
| 360chrome.exe | 360 极速 |
| 360se.exe | 360se |
| chrome.exe | |
| sogouexplorer.exe | 搜狗 |
| QQBrowser.exe | QQ 浏览器 |
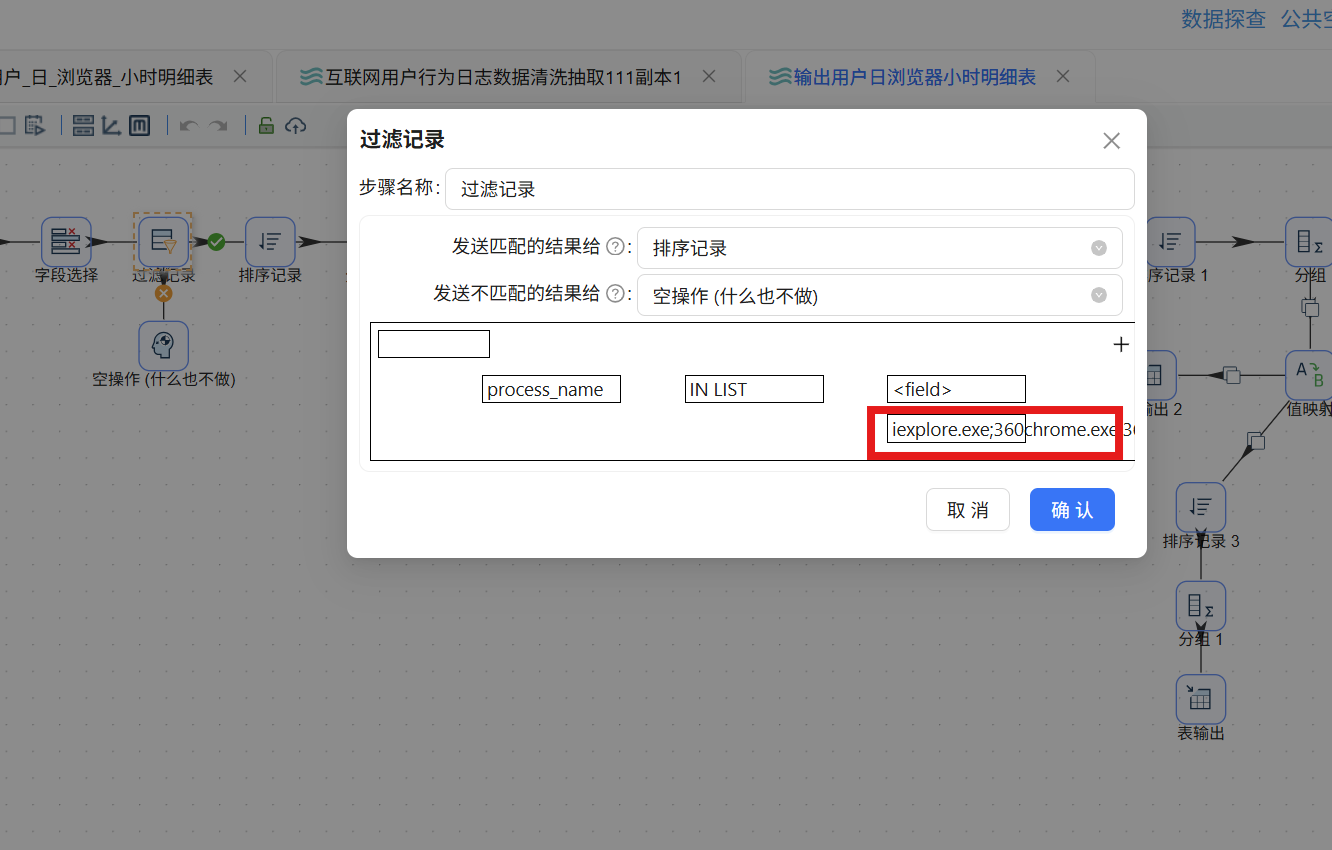
特别提醒:前序实验"4.5.3 过滤记录:筛选进程为主要浏览器的数据"步骤中——
- 若匹配条件为
process_name IN LIST "iexplore.exe;360chrome.exe;360se.exe;chrome.exe;sogouexplorer.exe;QQBrowser.exe",则无需调整 - 若匹配条件包含了 EXCEL.EXE、WINWORD.EXE、AlilM.exe 等非浏览器进程,需要将其移除
此外,转换流中分组组件的聚合字段如果聚合类型设置为"个数",需改为"统计不同值的数量 (N)"。同时在分支 A 的"分组 1"组件前补充一个排序记录组件,按 process_name 升序排列:
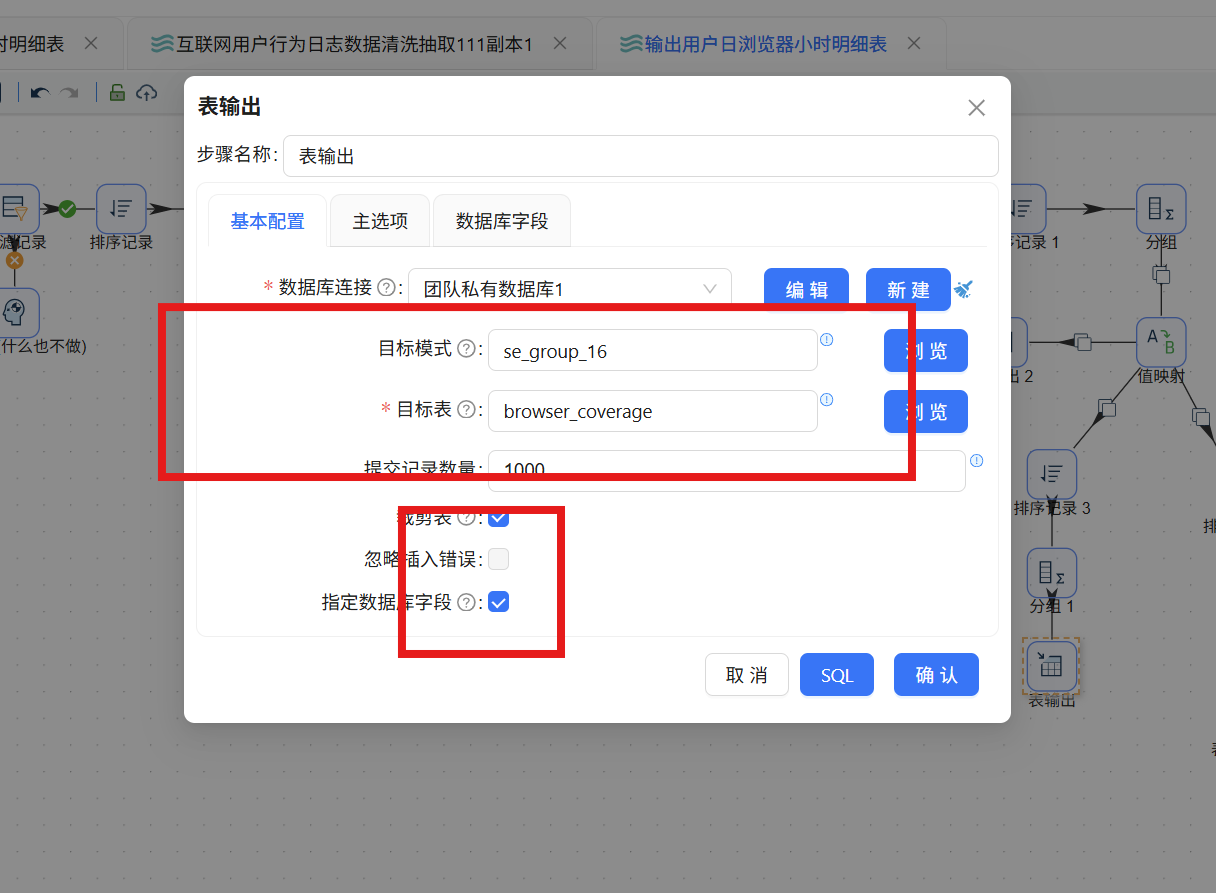
6.1.5 添加表输出组件
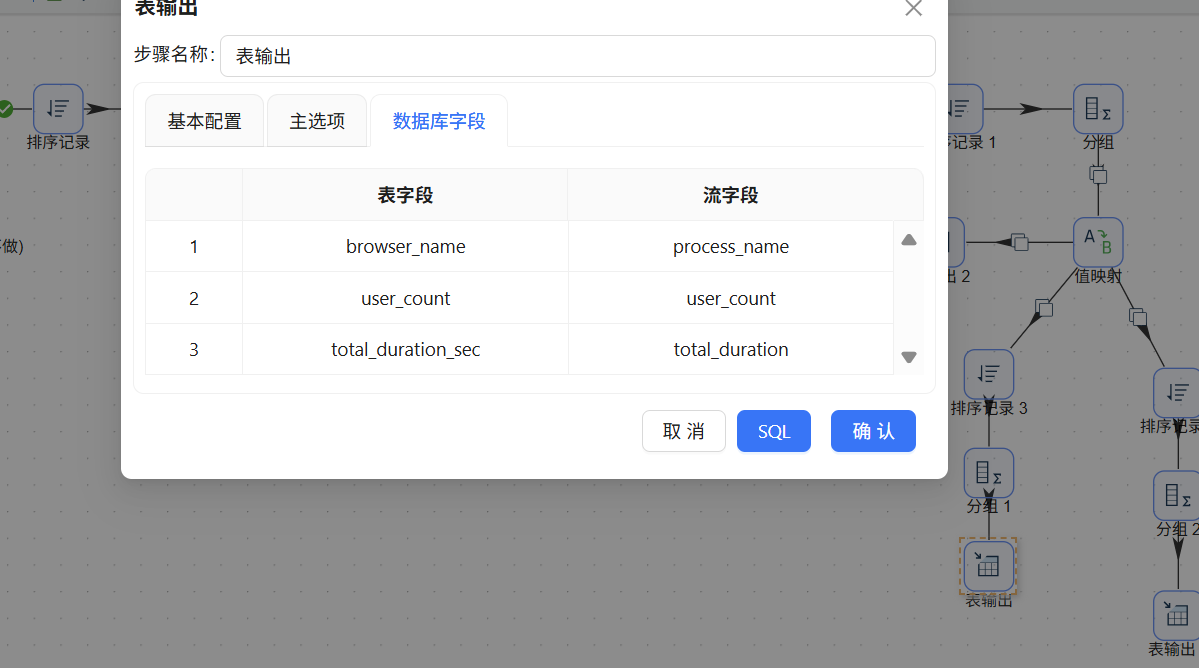
将"表输出"组件拖入画布,并将值映射组件的输出连接到该组件:
【截图位置】
双击"表输出"组件,按如下方式配置:
- 数据库连接:团队私有数据库
- 目标表:daily_browser_detail
- 勾选"裁剪表"以清空已有数据
- 勾选"指定数据库字段"并完成字段映射
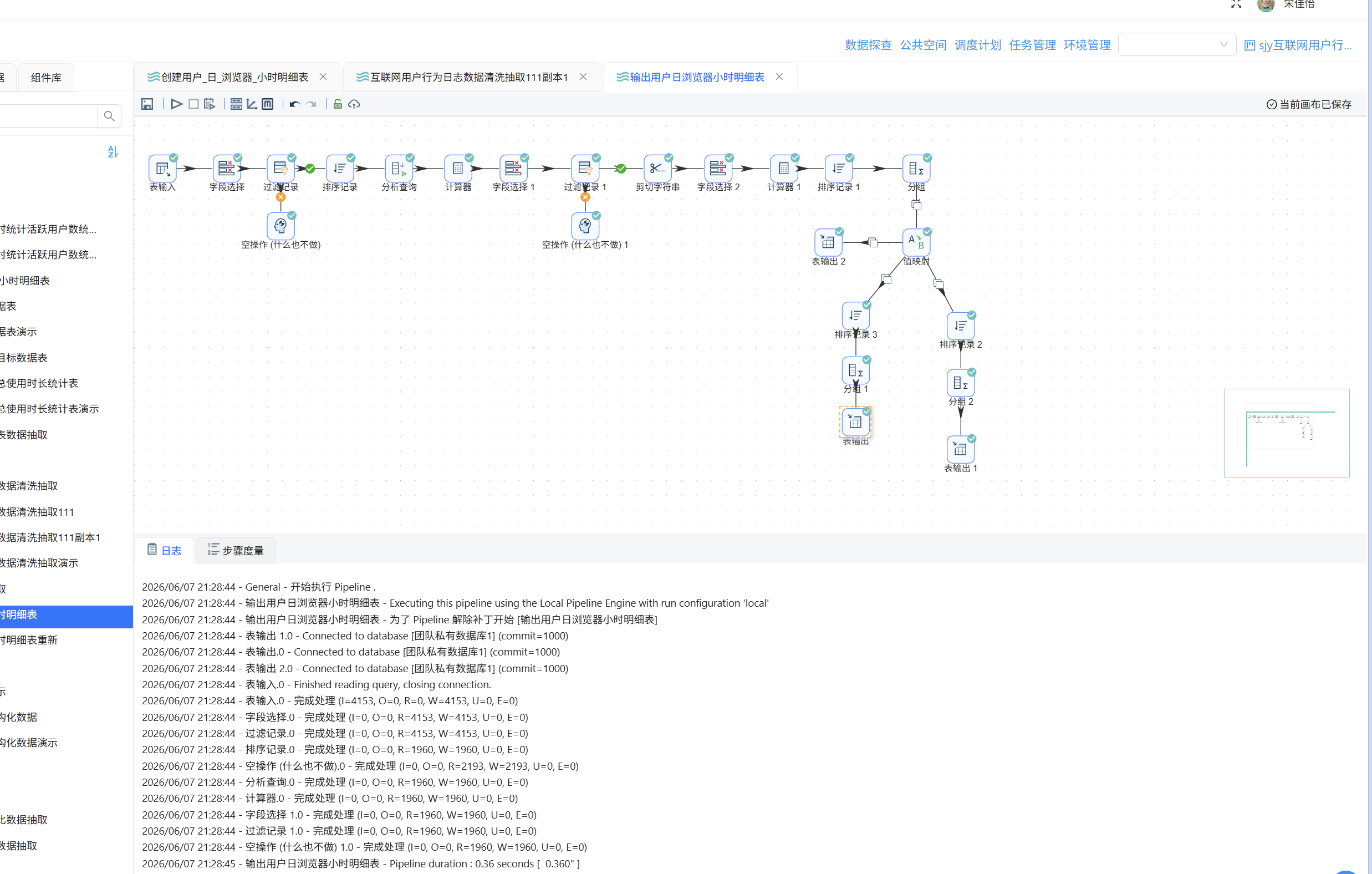
6.1.6 执行转换流
点击"运行"按钮启动转换流:
6.2 创建目标数据表
在团队私有数据库中创建本实验需要输出的全部目标表结构。
新建转换流"创建浏览器大屏分析目标数据表",将"执行一个 SQL 脚本"组件拖入画布:
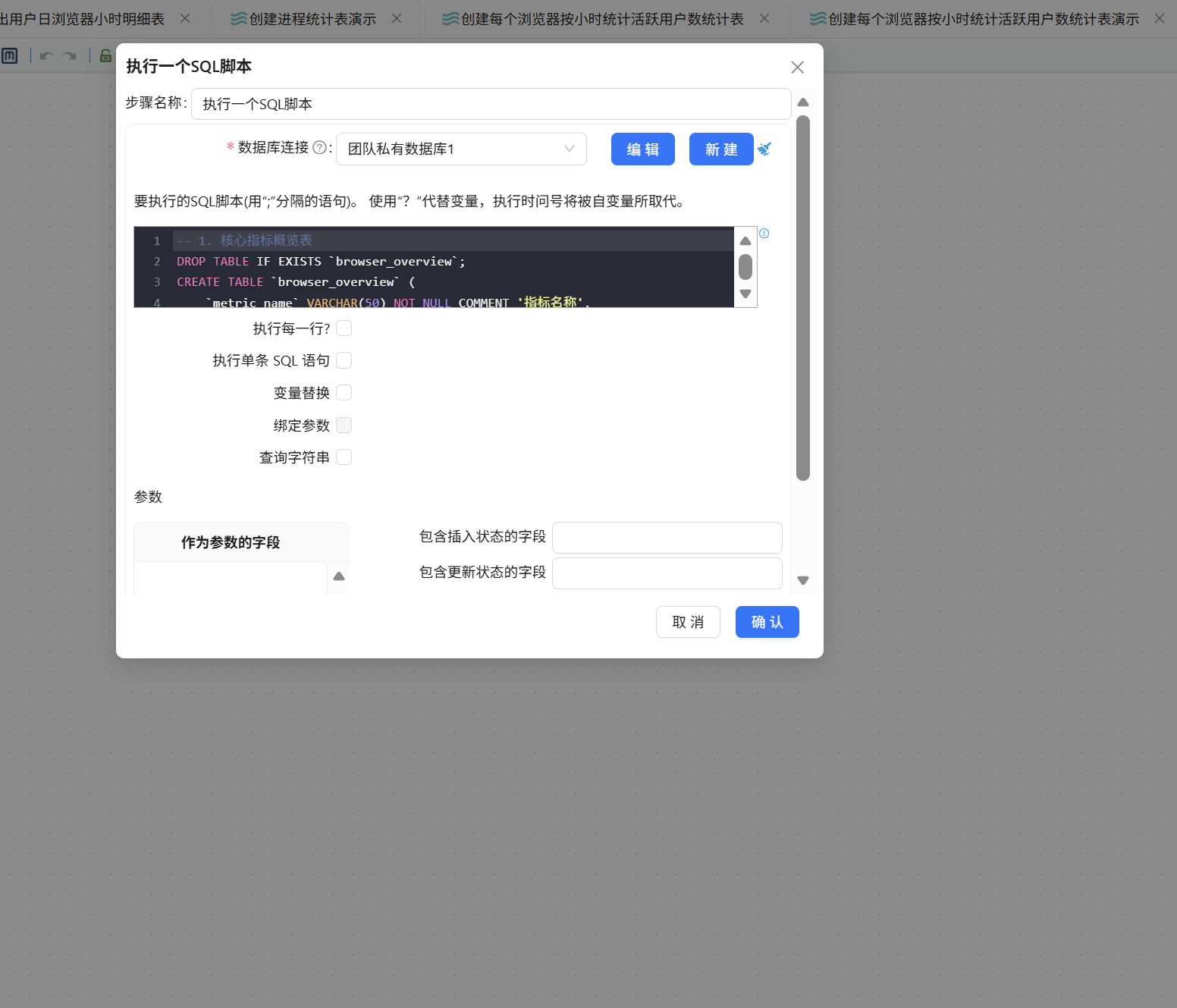
双击该组件,数据库连接选择"团队私有数据库",在 SQL 编辑框中输入以下建表语句(使用 DROP TABLE 可以在需要重建表时避免报错):
-- 1. 核心指标概览表
DROP TABLE IF EXISTS `browser_overview`;
CREATE TABLE `browser_overview` (
`metric_name` VARCHAR(50) NOT NULL COMMENT '指标名称',
`metric_value` DECIMAL(12,2) NOT NULL COMMENT '指标值'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='核心指标概览表';
-- 2. 各浏览器周活跃趋势表
DROP TABLE IF EXISTS browser_weekly_active;
CREATE TABLE `browser_weekly_active` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`week_range` VARCHAR(20) NOT NULL COMMENT '周日期范围',
`active_user_count` INT NOT NULL COMMENT '活跃用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='各浏览器周活跃趋势表';
-- 3. 浏览器使用频率分布表
DROP TABLE IF EXISTS browser_frequency_stats;
CREATE TABLE `browser_frequency_stats` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`usage_level` VARCHAR(10) NOT NULL COMMENT '使用等级',
`user_count` INT NOT NULL COMMENT '用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='浏览器使用频率分布表';
-- 4. 用户使用浏览器数量分布表
DROP TABLE IF EXISTS browser_multi_usage;
CREATE TABLE `browser_multi_usage` (
`browser_count` VARCHAR(10) NOT NULL COMMENT '使用浏览器数量',
`user_count` DECIMAL(5,2) NOT NULL COMMENT '用户数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户使用浏览器数量分布表';
-- 5. 浏览器工作日周末对比表
DROP TABLE IF EXISTS browser_weekday_weekend;
CREATE TABLE `browser_weekday_weekend` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`day_type` VARCHAR(10) NOT NULL COMMENT '工作日/周末',
`avg_duration_sec` INT NOT NULL COMMENT '人均使用时长 (秒)',
`total_duration_hour` BIGINT NOT NULL COMMENT '总使用时长 (小时)',
`user_count` INT NOT NULL COMMENT '用户数'
) COMMENT '浏览器工作日周末对比表';
-- 6. 用户画像统计表
DROP TABLE IF EXISTS `user_profile_stats`;
CREATE TABLE `user_profile_stats` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`gender` VARCHAR(10) COMMENT '性别',
`age_group` VARCHAR(10) COMMENT '年龄段',
`edu` VARCHAR(50) COMMENT '学历',
`job` VARCHAR(50) COMMENT '职业',
`income` VARCHAR(50) COMMENT '收入',
`city_type` VARCHAR(10) COMMENT '居住地类型',
`province` VARCHAR(50) COMMENT '省份',
`user_count` INT NOT NULL COMMENT '用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户画像统计表';
点击"运行"按钮执行该转换流
6.3 各浏览器周活跃趋势表数据加工
目标:计算各浏览器在第 1~4 周的每周活跃用户数量。
新建转换流"各浏览器周活跃趋势表数据抽取",将"表输入"组件拖入画布,数据库连接选择"团队私有数据库",点击"获取 SQL 查询语句",选中 daily_browser_detail 表以获取查询语句:
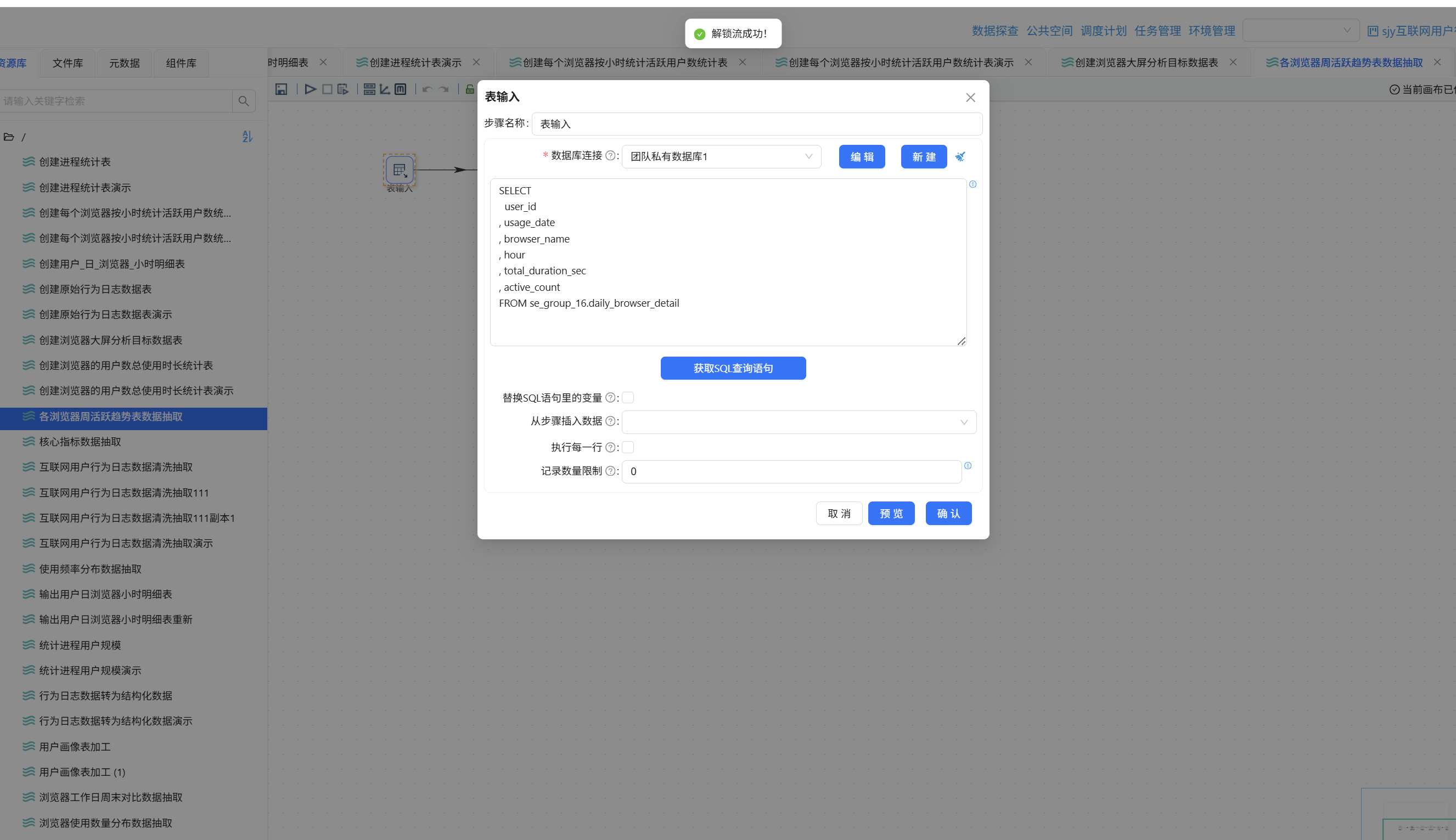
此处需要将各浏览器的使用日期转换为对应的周区间:5/7-5/13、6/4-6/10、7/2-7/8、8/6-8/12。可以借助值映射组件实现,但在此之前,需要先通过字段选择组件对 usage_date 进行格式转换。
拖入字段选择组件,建立表输入到字段选择的连线:
双击字段选择组件,切换到"元数据"页签,右键插入一行,字段名称填写 usage_date,类型设为 Date,格式设为"yyyy-MM-dd":
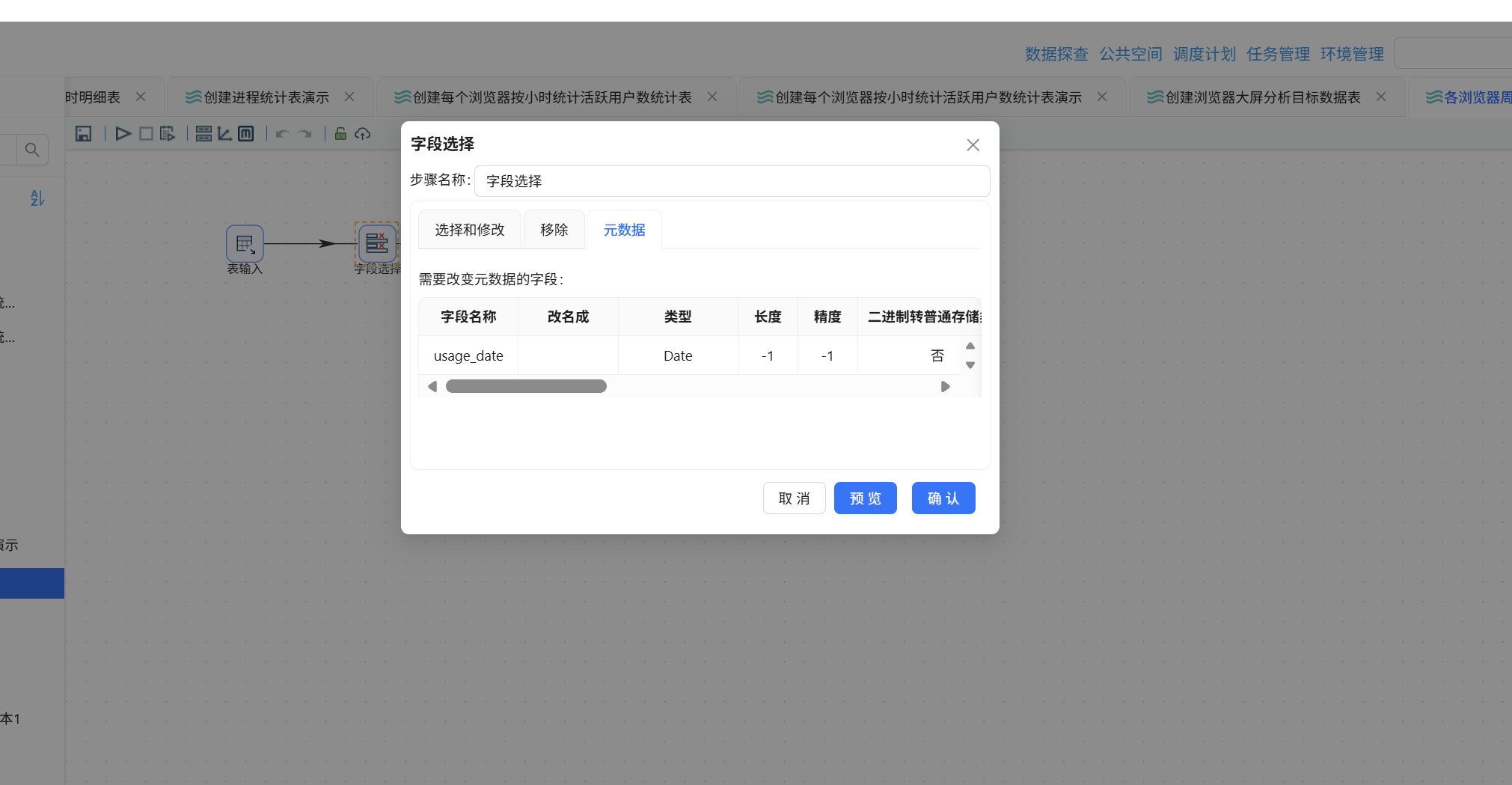
继续拖入值映射组件,将字段选择组件连接至值映射组件:
双击值映射组件,"使用的字段名"选择 usage_date,"目标字段名"填写 week_range(表示新建一个字段用于存放映射结果)。随后逐行添加映射规则,将每个具体日期映射到其所属的周区间:
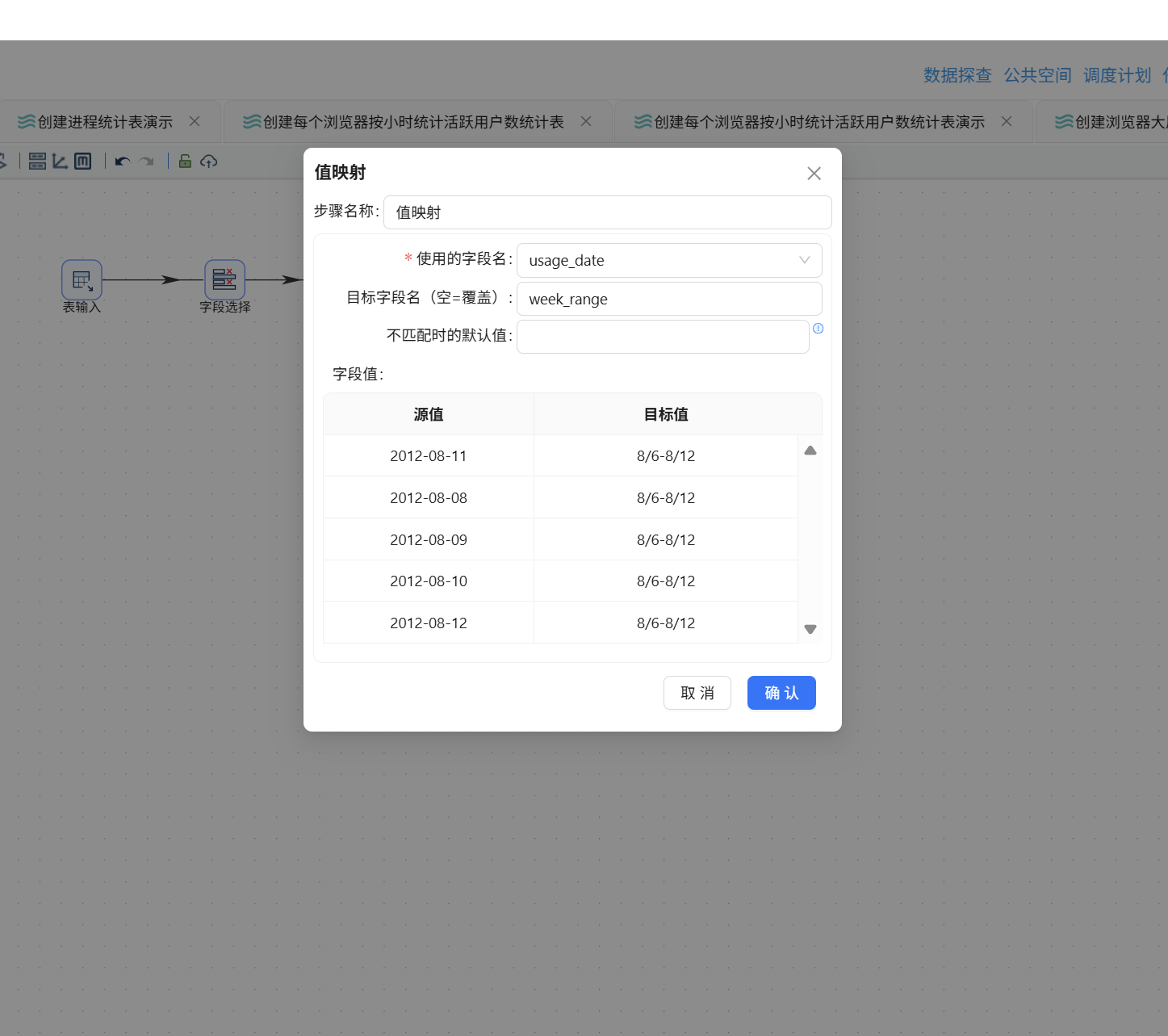
下一步,按浏览器和周进行分组统计用户数。分组操作前务必对数据做排序处理,以确保统计结果的准确性。拖入排序记录组件,值映射组件连接至排序记录组件:
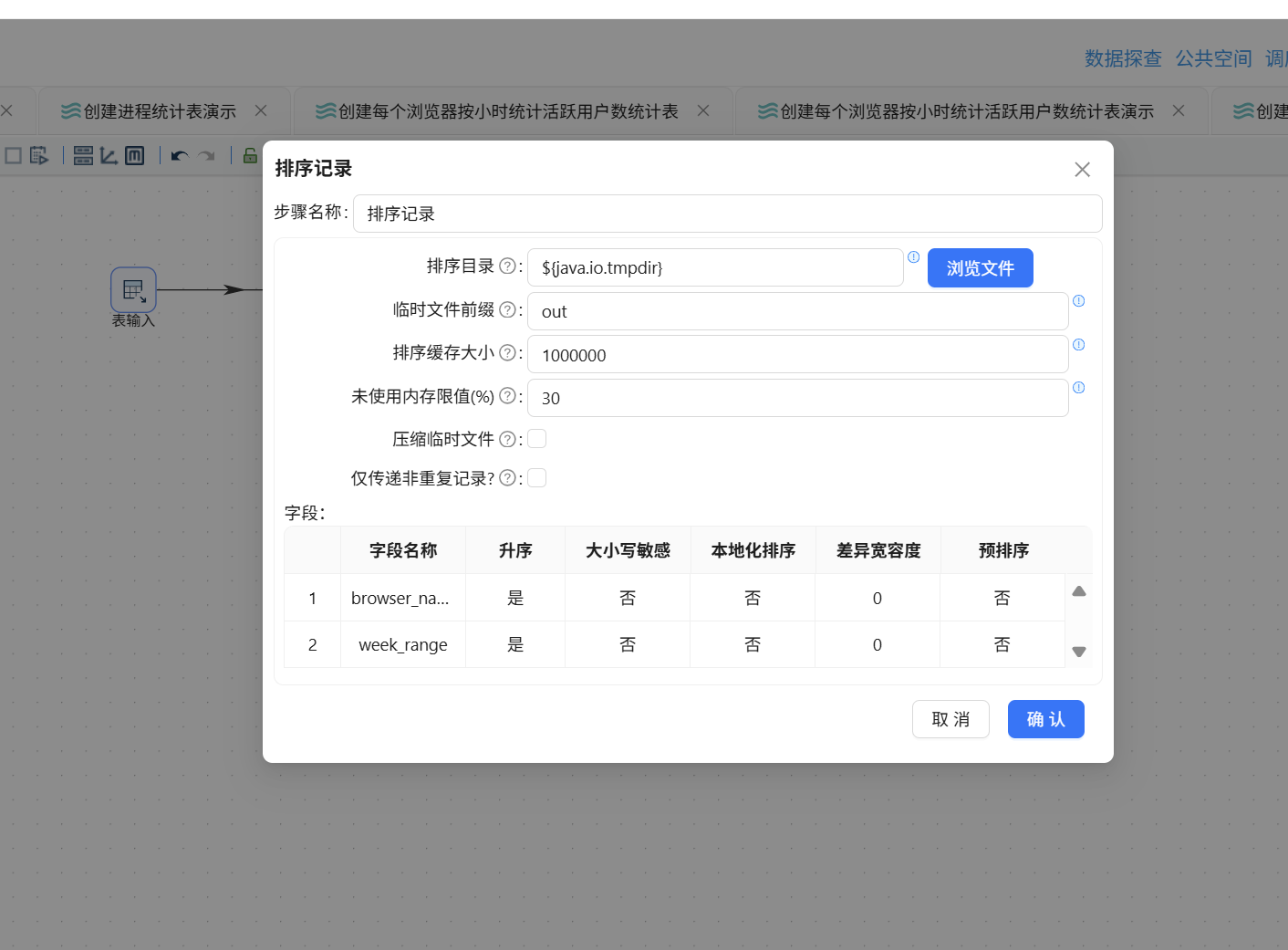
将排序规则设置为按 browser_name、week_range 升序:
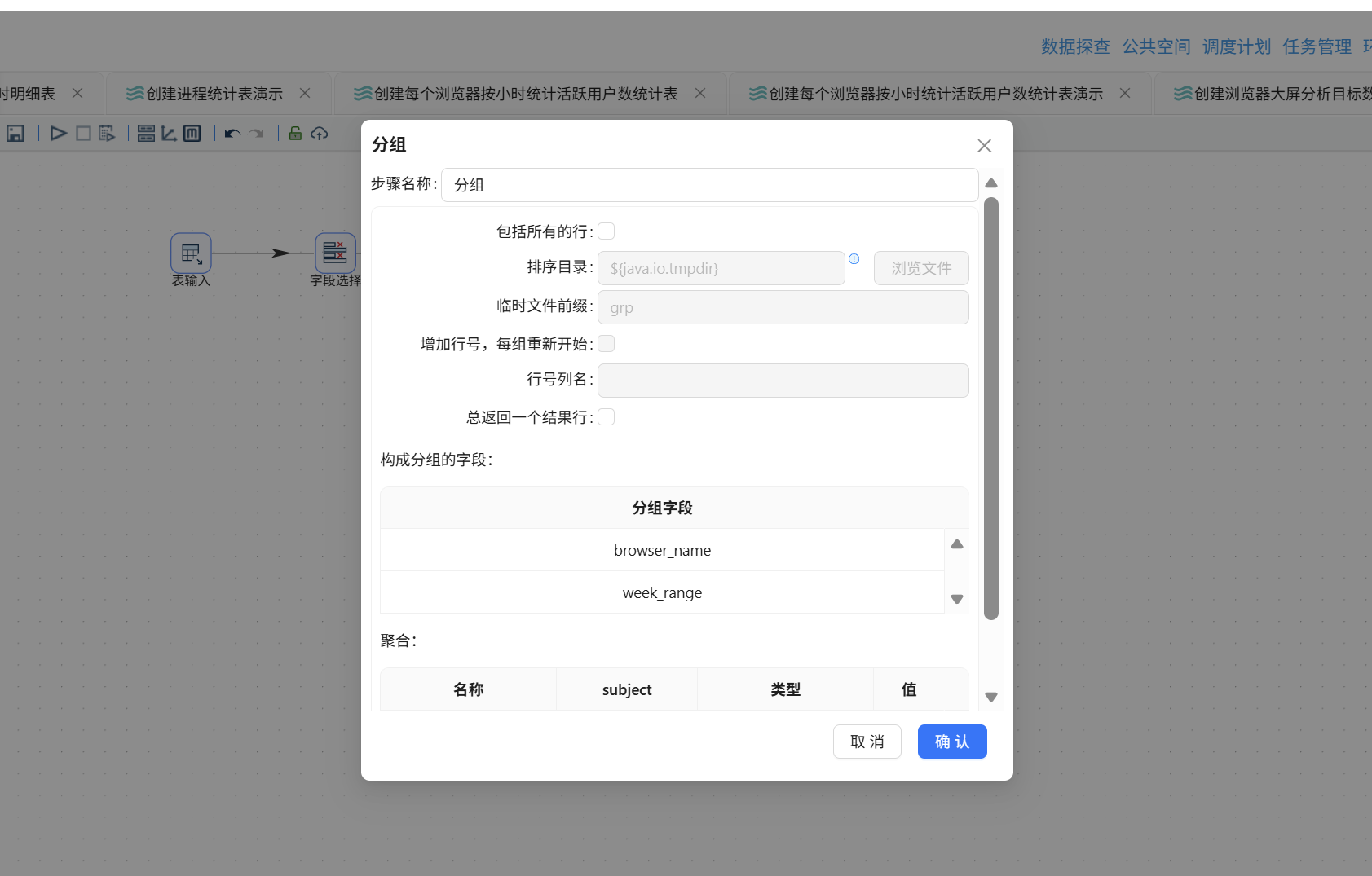
排序完成后拖入分组组件,排序记录组件连接至分组组件:
分组字段设置为 browser_name 和 week_range。聚合方式为对 user_id 执行去重计数以获得 active_user_count,即:输入字段名 active_user_count,subject 填 user_id,聚合类型选择"统计不同值的数量 (N)":
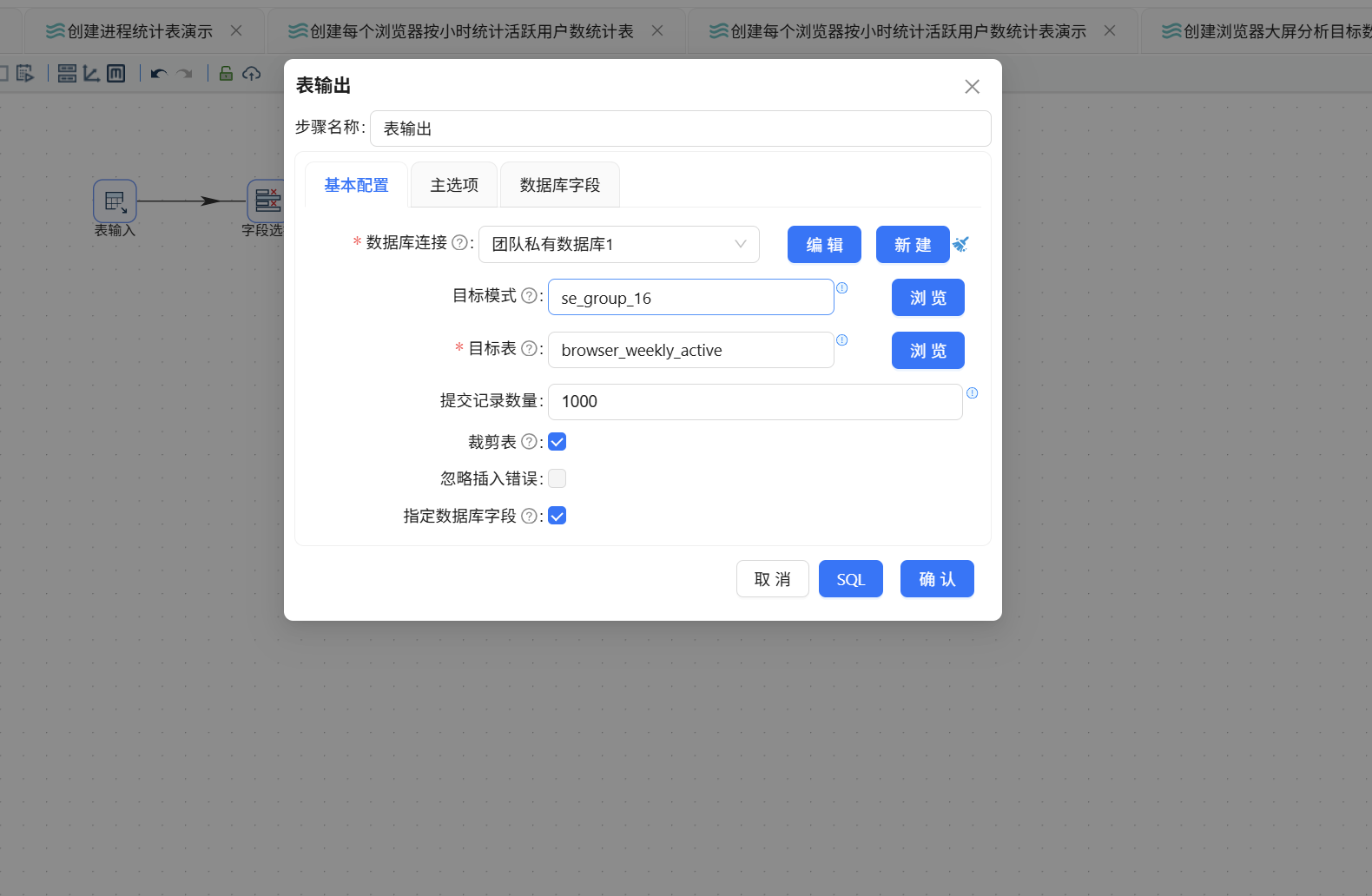
最后拖入表输出组件,将聚合结果写入数据库。组件配置如下:
- 数据库连接:团队私有数据库
- 目标表:browser_weekly_active
- 勾选"裁剪表"以清空历史数据
- 勾选"指定数据库字段"并完成字段映射
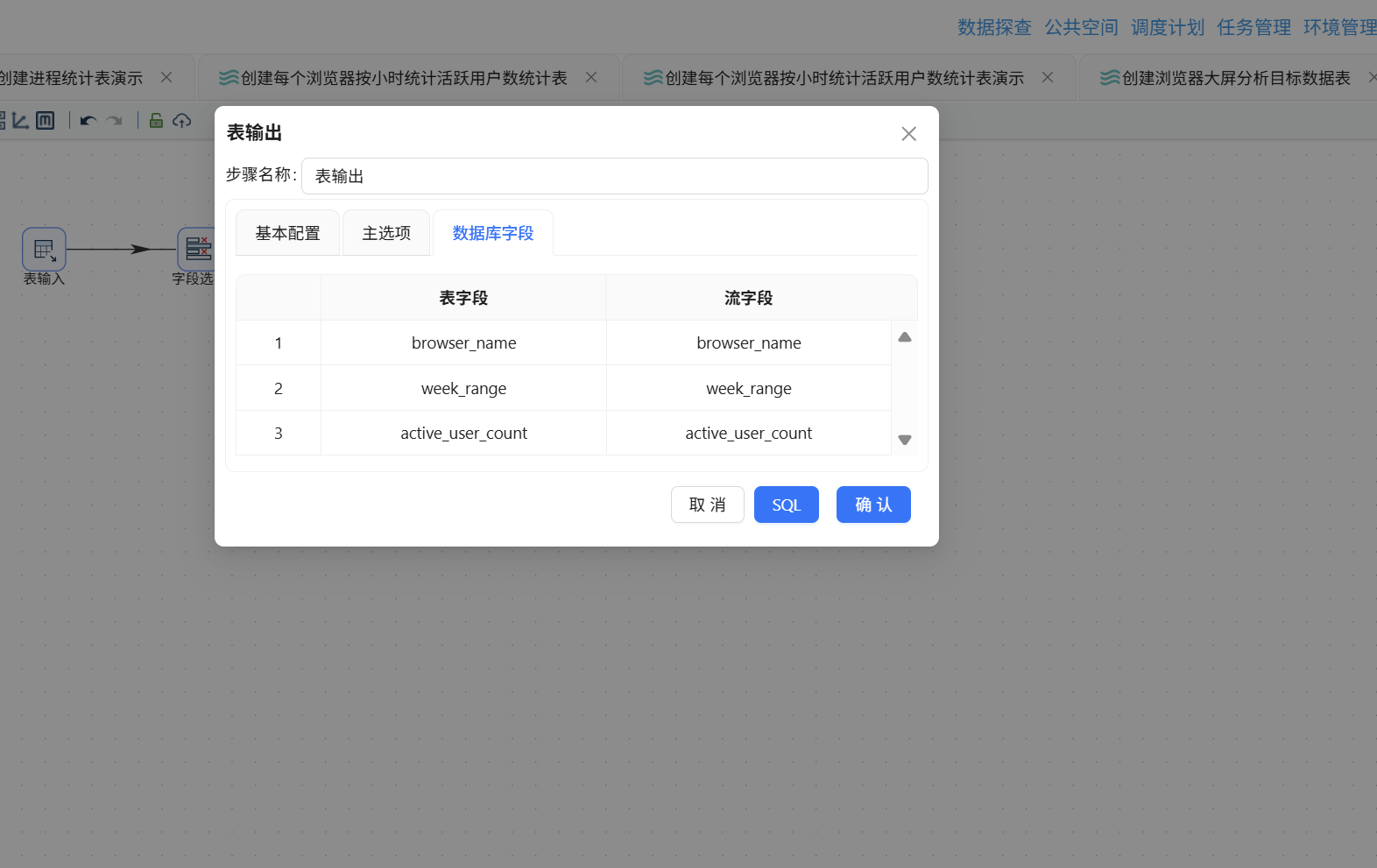
点击"运行"按钮执行转换流:
6.4 各浏览器使用频率分布表数据加工
目标:将用户按轻度/中度/重度划分使用频率等级。
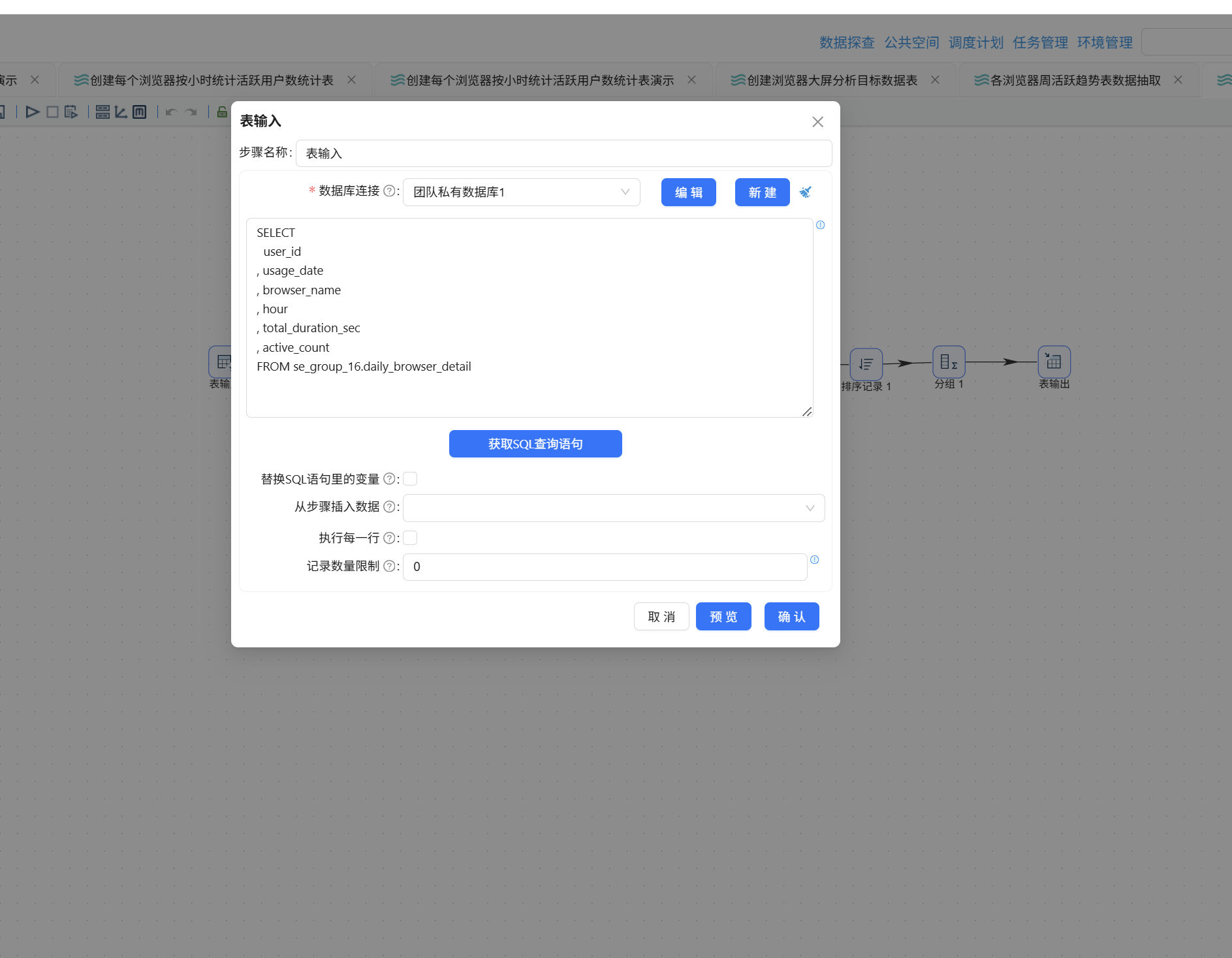
新建转换流"使用频率分布数据抽取",拖入"表输入"组件,数据库连接选择"团队私有数据库",获取 daily_browser_detail 的查询语句:
接下来统计每位用户在各浏览器上的累计使用时长。拖入排序记录组件,建立表输入到排序记录的连线:
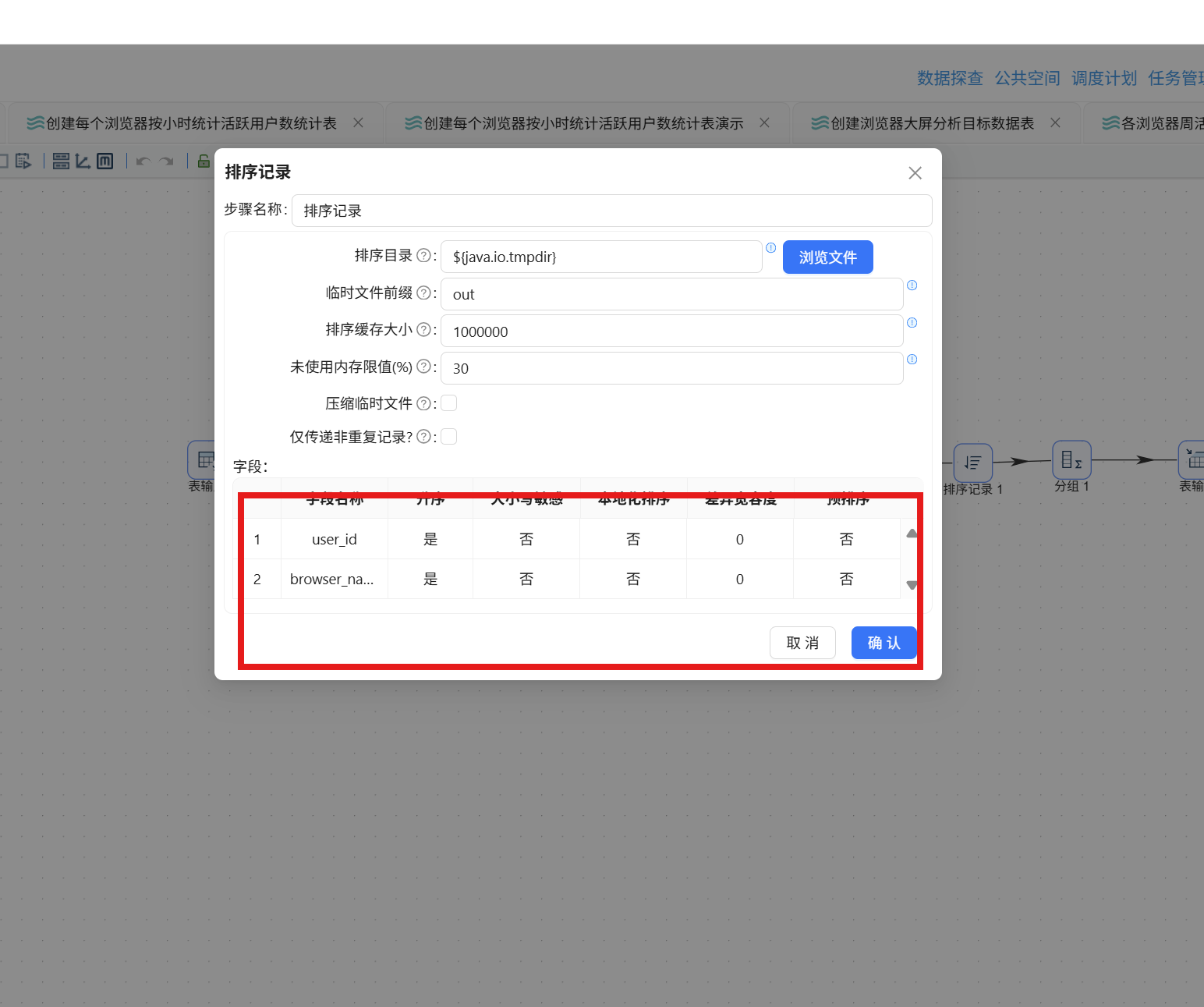
排序规则设为按 user_id、browser_name 升序:
排序后拖入分组组件,连接排序记录组件:
分组字段为 user_id 和 browser_name,聚合方式为对 total_duration_sec 求和,得到总使用时长:
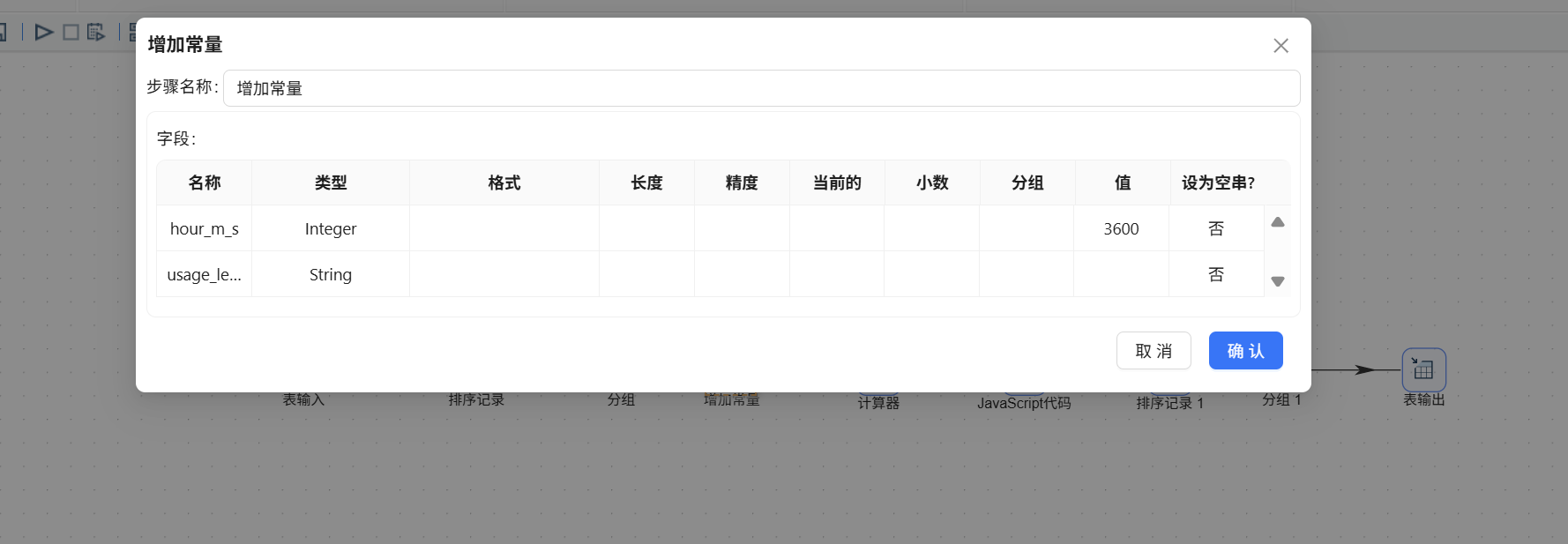
上述计算得到的时长单位为秒,为了便于理解和划分等级,我们将其转换为小时(小时 = 秒 ÷ 3600)。由于数据中没有现成的 3600 常量字段,需要先通过增加常量组件添加。拖入增加常量组件,分组组件连接至该组件:
在增加常量组件中新增字段"hour_m_s",类型设为 Integer,固定值为 3600:
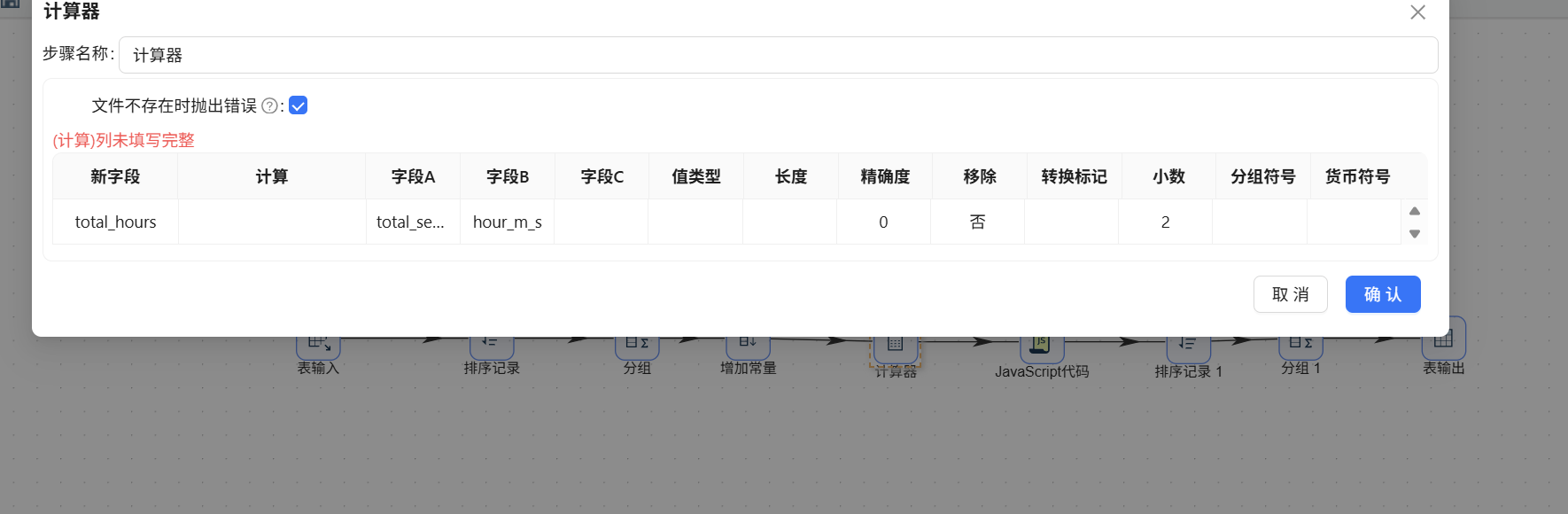
随后拖入计算器组件:
在计算器中新增字段"total_hours",计算方式选择"A / B",字段 A 为 total_seconds,字段 B 为 hour_m_s,保留 2 位小数:
接下来为使用频率划分等级。拖入 JavaScript 代码组件,计算器组件连接至该组件:
双击 JavaScript 代码组件,输入以下脚本,然后点击"获取变量"自动识别输出变量:
var total_hours = total_hours;
var usage_level = '';
if (total_hours < 3) {
usage_level = '轻度';
} else if (total_hours >= 3 && total_hours < 10) {
usage_level = '中度';
} else {
usage_level = '重度';
}
注意:usage_level 这个字段需要提前在增加常量组件中声明:
现在可以按浏览器统计各使用等级的用户数量了。
先拖入排序记录组件,按 browser_name、usage_level 升序排列:
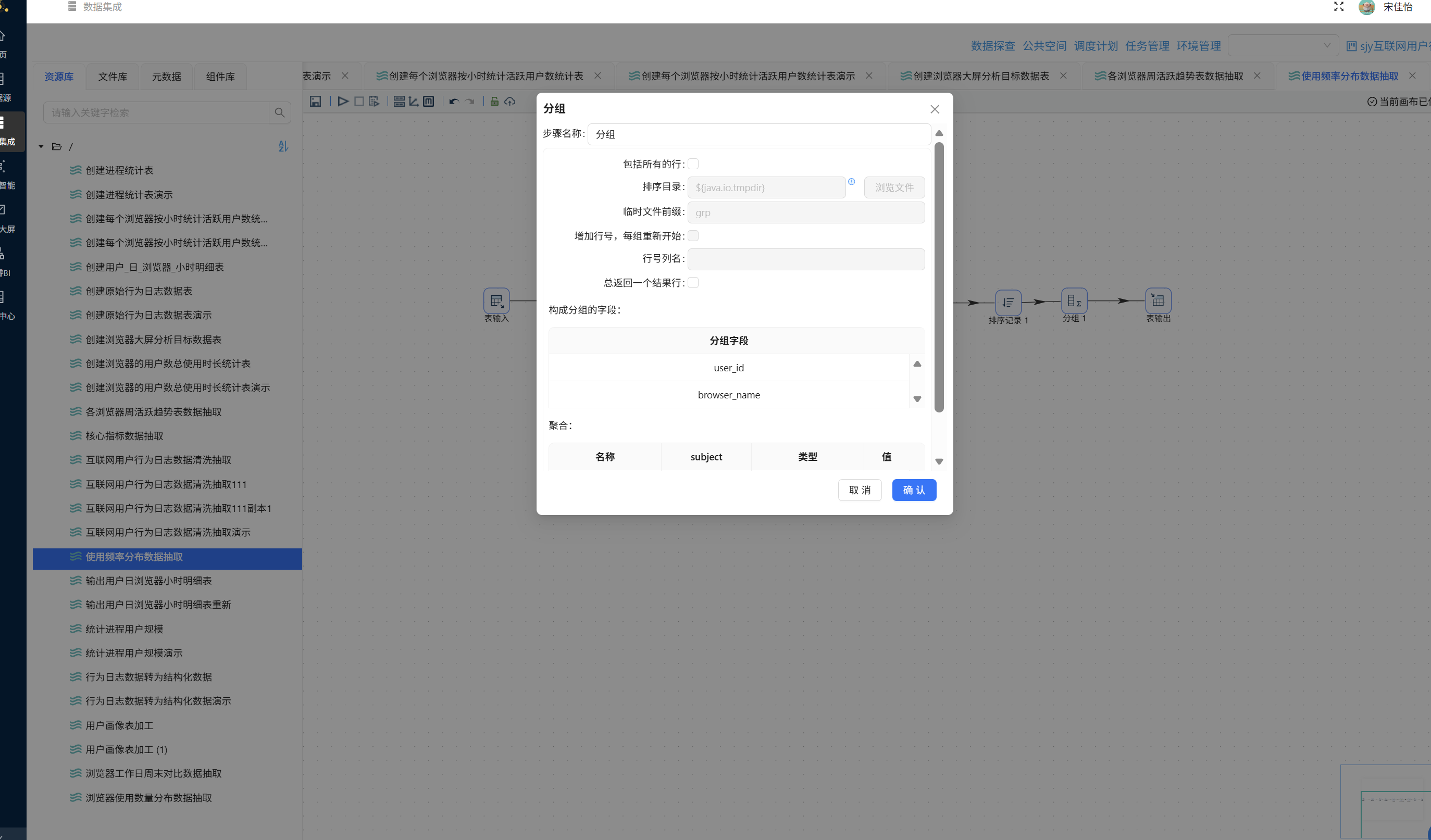
再拖入分组组件,按 browser_name、usage_level 分组,统计 user_count(对 user_id 去重计数):
最后拖入表输出组件写入目标表,配置如下:
- 数据库连接:团队私有数据库
- 目标表:browser_frequency_stats
- 勾选"裁剪表"
- 勾选"指定数据库字段"并完成映射
点击"运行"按钮执行转换流:
6.5 用户浏览器使用数量分布表数据加工
目标:统计使用 1 种、2 种、3 种及以上浏览器的用户各有多少。
新建转换流"浏览器使用数量分布数据抽取",拖入"表输入"组件,获取 daily_browser_detail 的查询语句:
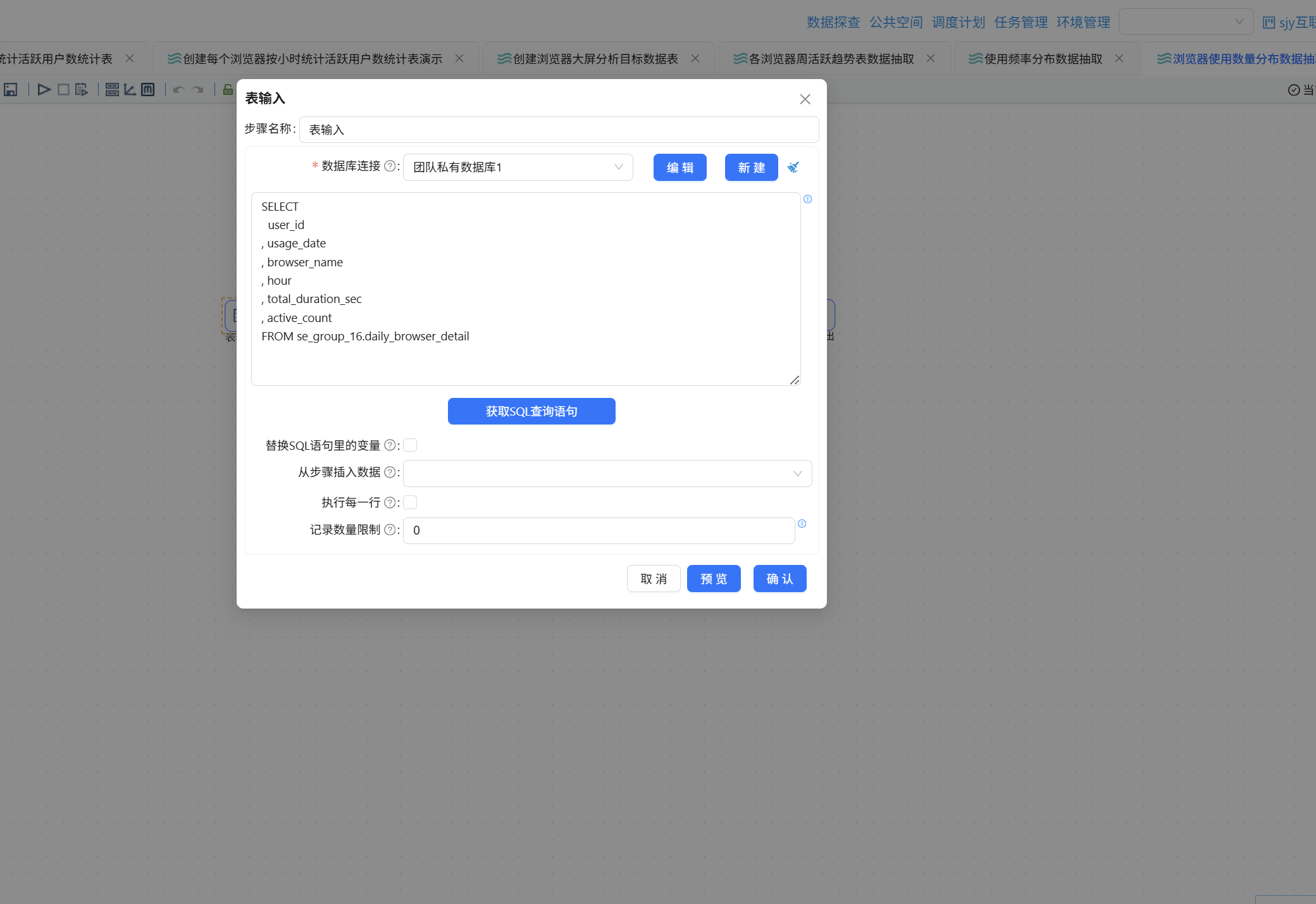
首先统计每位用户使用了多少种不同的浏览器。拖入排序记录组件,表输入连接至排序记录:
排序规则设为按 user_id 升序:
排序后拖入分组组件并建立连线:
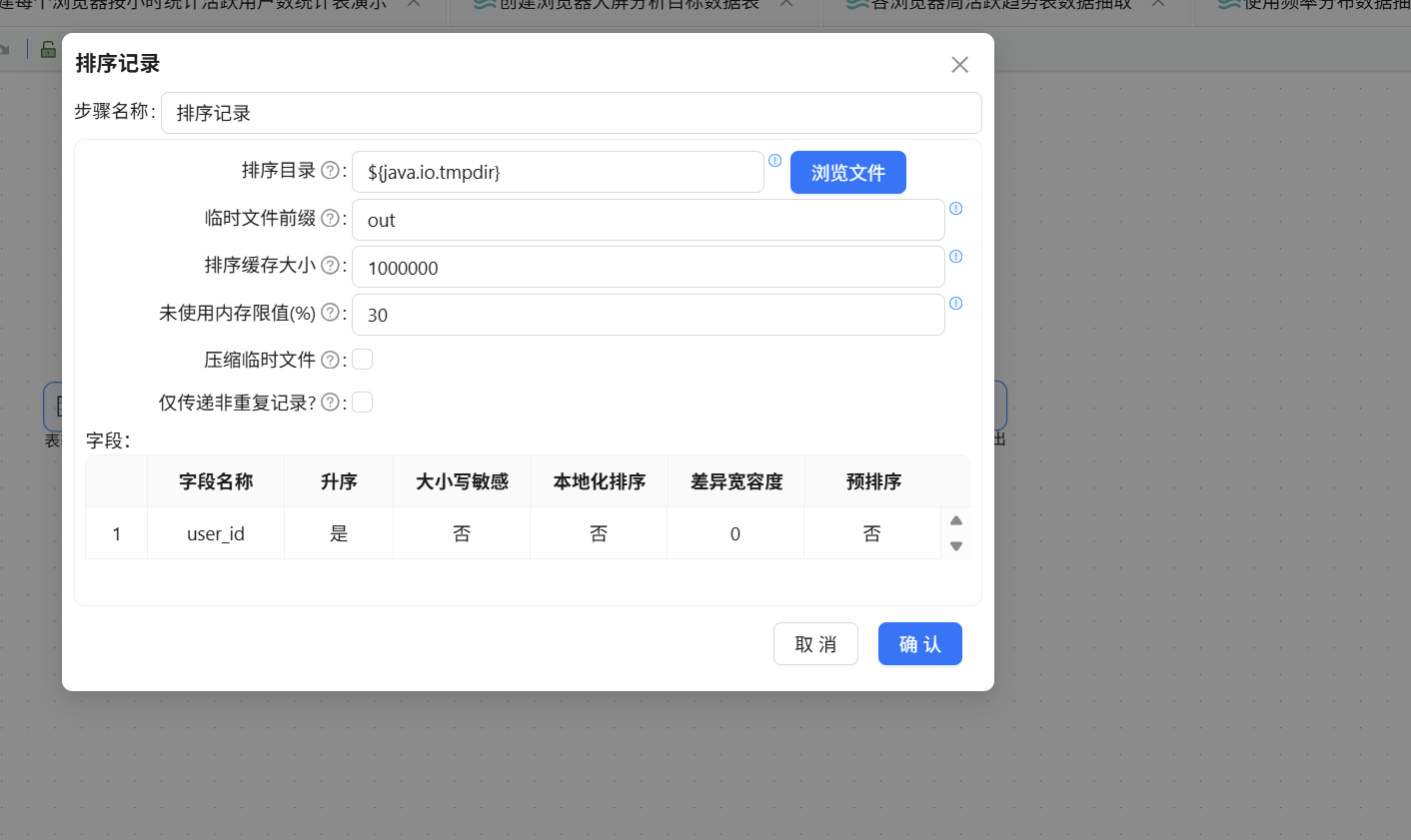
分组字段为 user_id,聚合方式为对浏览器名称去重计数,得到每位用户使用的浏览器种类数:
接下来对浏览器数量进行分段标记。拖入 JavaScript 代码组件:
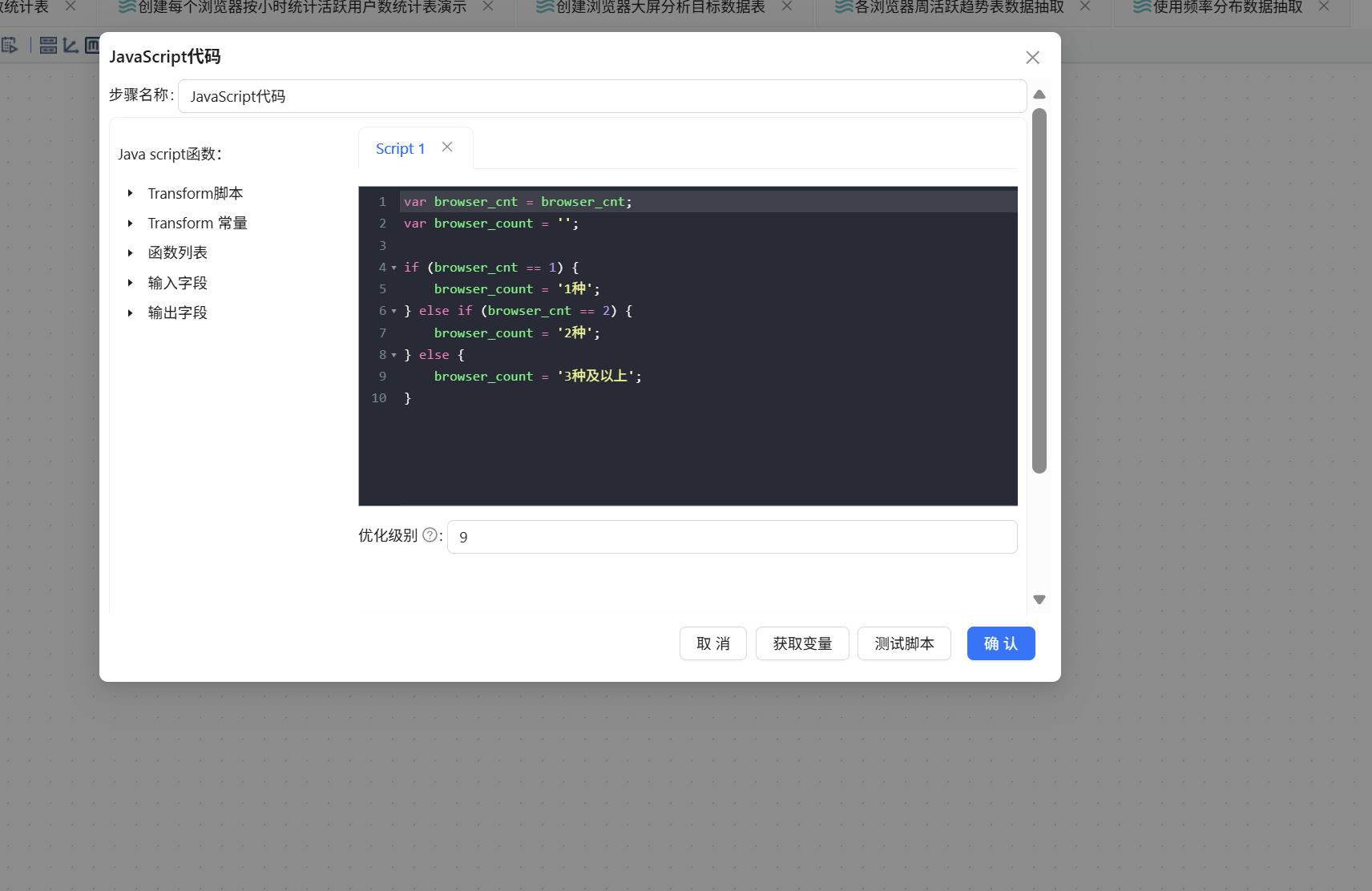
双击该组件,输入以下脚本并点击"获取变量":
var browser_cnt = browser_cnt;
var browser_count = '';
if (browser_cnt == 1) {
browser_count = '1 种';
} else if (browser_cnt == 2) {
browser_count = '2 种';
} else {
browser_count = '3 种及以上';
}
然后按分段统计用户数。先拖入排序记录组件,按 browser_count 升序排列:
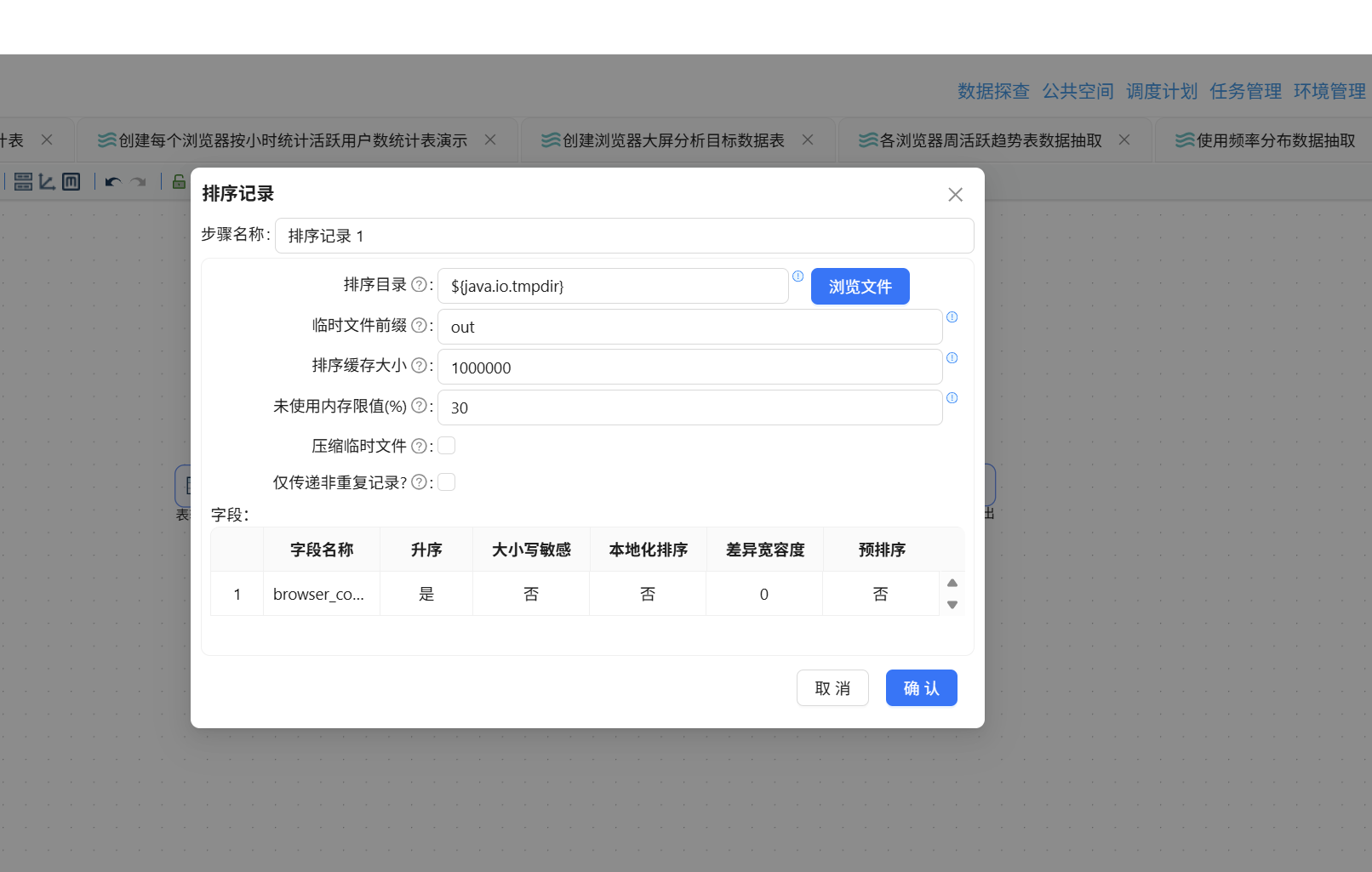
再拖入分组组件,按 browser_count 分组,统计 user_count(对 user_id 去重计数):
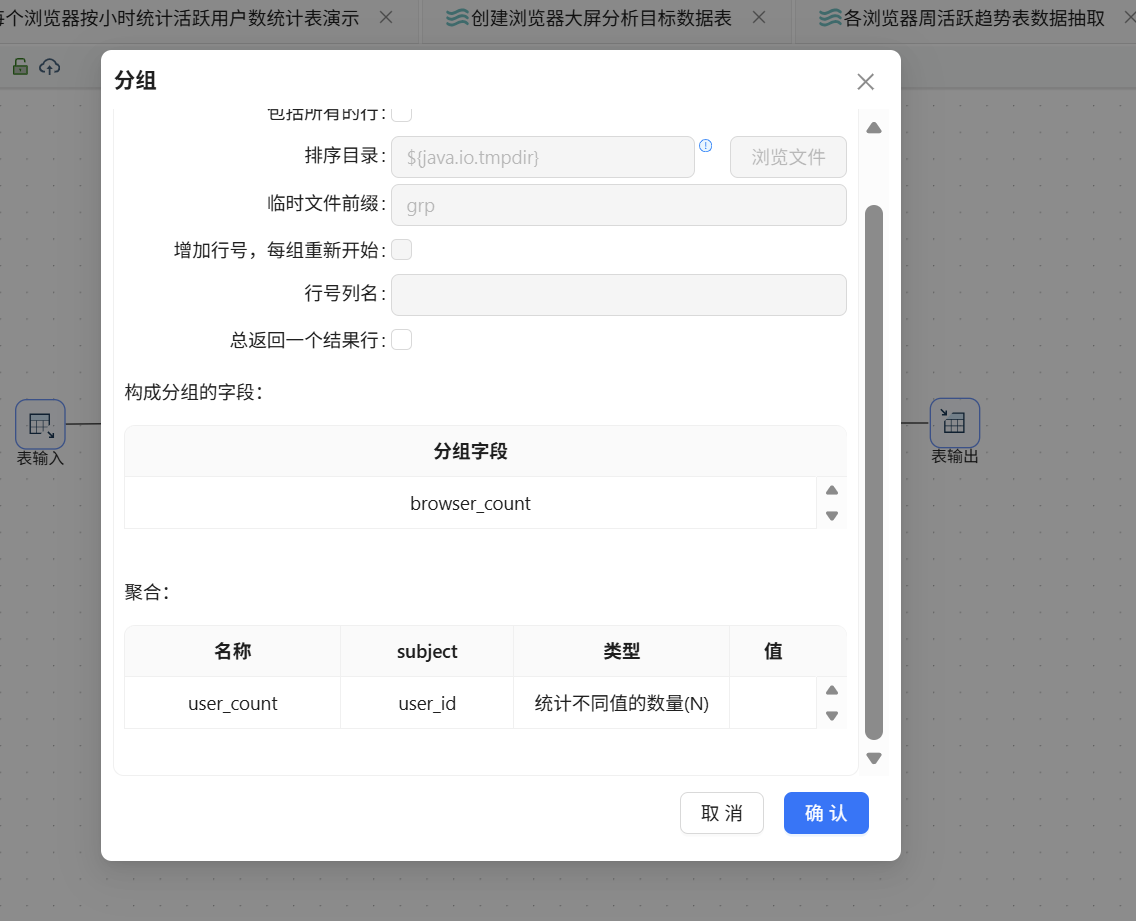
最后拖入表输出组件写入目标表,配置如下:
- 数据库连接:团队私有数据库
- 目标表:browser_multi_usage
- 勾选"裁剪表"
- 勾选"指定数据库字段"并完成映射
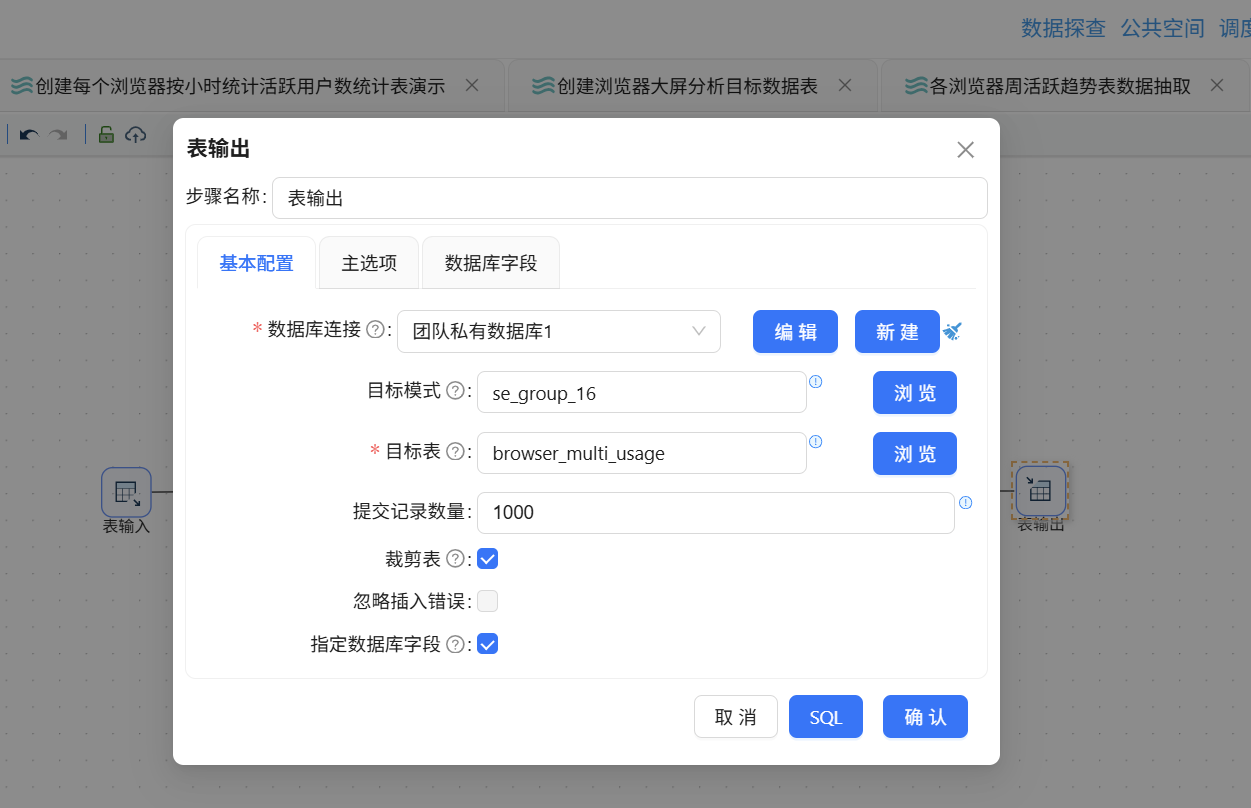
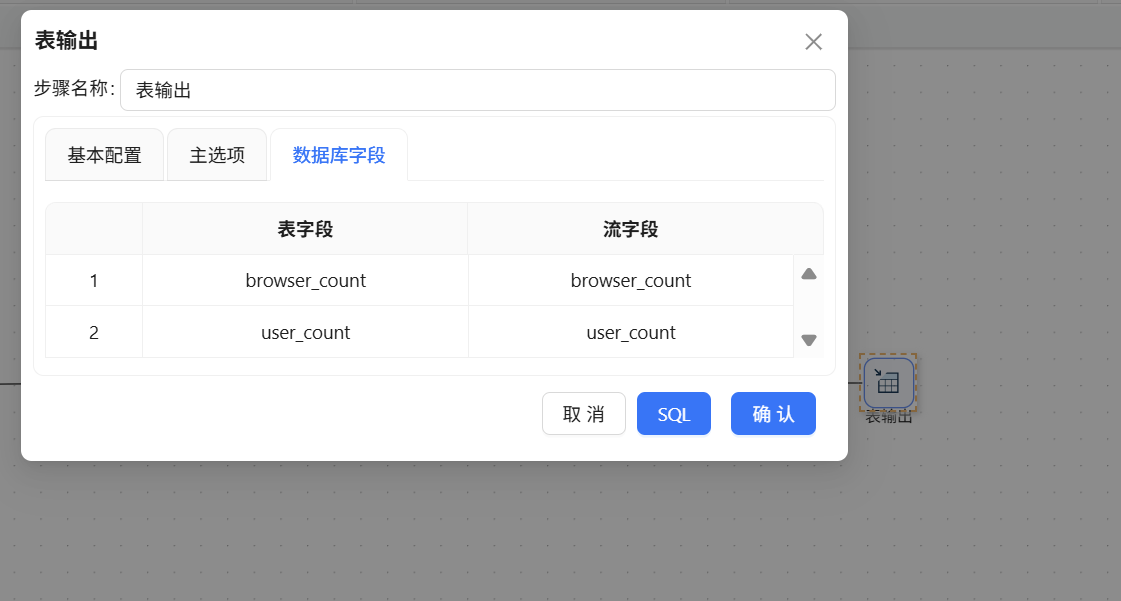
点击"运行"按钮执行转换流:
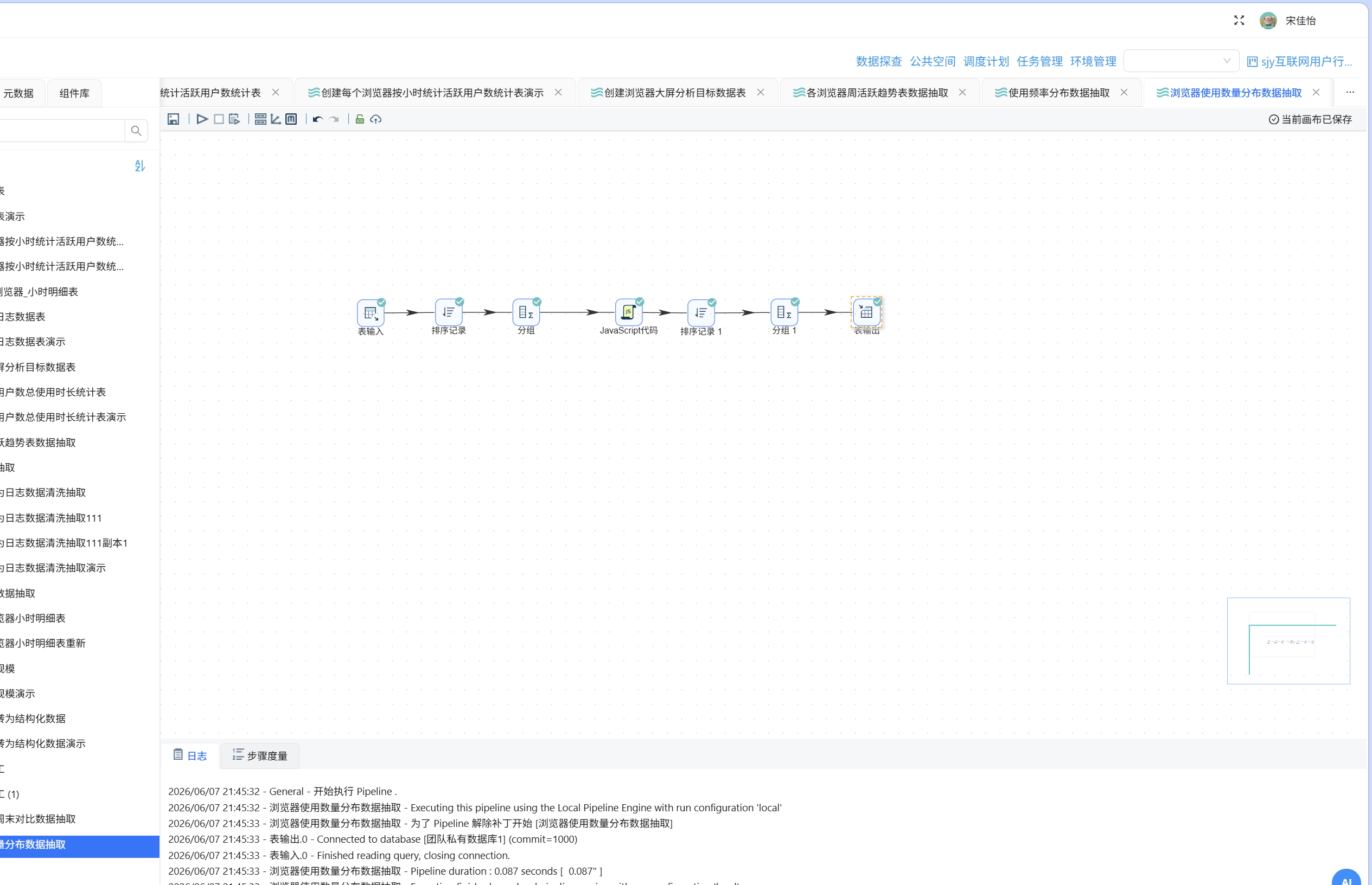
6.6 各浏览器工作日周末对比表数据加工
目标:对比各浏览器在工作日与周末的使用时长差异。
新建转换流"浏览器工作日周末对比数据抽取",拖入"表输入"组件获取 daily_browser_detail 的查询语句:
下一步,根据使用日期判断当天是星期几。拖入 JavaScript 代码组件,表输入连接至该组件:
双击该组件,输入以下脚本并点击"获取变量":
// 获取日期
var date = usage_date;
// 获取星期几(0=周日,1=周一,..., 6=周六)
var dayOfWeek = date.getDay();
// 判断工作日还是周末
var day_type = "";
if (dayOfWeek >= 1 && dayOfWeek <= 5) {
day_type = "工作日";
} else {
day_type = "周末";
}
现在可以分别统计工作日和周末的使用时长及用户数了。先拖入排序记录组件:
按 browser_name、day_type 升序排列:
再拖入分组组件,按 browser_name 和 day_type 分组。聚合配置如下:
- avg_seconds = 平均使用时长(秒)
- total_seconds = 总使用时长(秒)
- user_count = COUNT(DISTINCT user_id)
总使用时长如果以秒为单位,数值过大不便直观理解,因此需将其转为小时。参照"6.4 各浏览器使用频率分布表数据加工"中的做法,使用增加常量组件和计算器组件完成单位换算:
加工过程中产生了若干中间字段,通过字段选择组件剔除冗余字段:
最后拖入表输出组件写入目标表,配置如下:
- 数据库连接:团队私有数据库
- 目标表:browser_weekday_weekend
- 勾选"裁剪表"
- 勾选"指定数据库字段"并完成映射

点击"运行"按钮执行转换流:
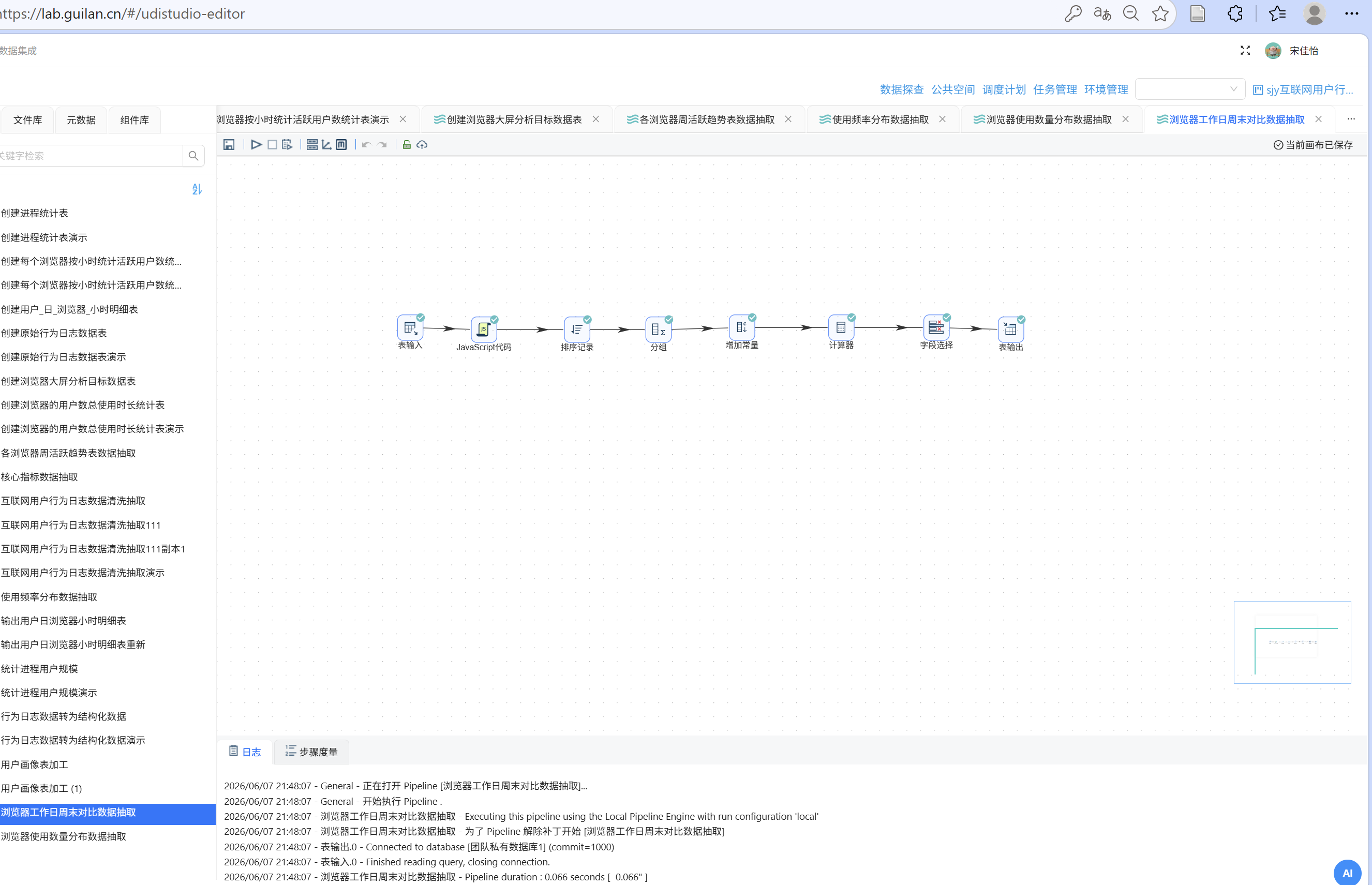
6.7 核心指标数据加工
目标:将大屏顶部四张指标卡所需的数据统一存入一张键值对结构的表中。
在前面的加工流程中,我们已经分别得到了各浏览器的用户数、使用时长、活跃用户数和重度用户数。但核心指标是面向全局的汇总数据,除了使用时长以外,其他与用户数相关的指标在不同浏览器间存在重叠,因此需要重新计算。
具体思路是:通过一条 SQL 一次性算出所有指标,再利用列转行操作将单行结果拆分为四行记录。
新建转换流,拖入表输入组件,数据库连接选择团队私有数据库,在 SQL 语句框中输入以下查询:
SELECT
ROUND(SUM(total_duration_sec) / 3600, 2) AS total_hours,
ROUND(SUM(total_duration_sec) / 3600 / COUNT(DISTINCT user_id), 2) AS avg_hours,
ROUND(
(SELECT COUNT(DISTINCT user_id) FROM daily_browser_detail
WHERE usage_date BETWEEN '2012-08-06' AND '2012-08-12'
) * 100.0 / COUNT(DISTINCT user_id), 2
) AS active_ratio,
ROUND(
(SELECT COUNT(*) FROM (
SELECT user_id FROM daily_browser_detail
WHERE usage_date BETWEEN '2012-05-07' AND '2012-07-08'
GROUP BY user_id
HAVING SUM(total_duration_sec) / 3600 > 30
) t) * 100.0 / COUNT(DISTINCT user_id), 2
) AS heavy_ratio
FROM daily_browser_detail
接着使用行转列组件,将字段名称转为指标名称,字段值转为指标值:
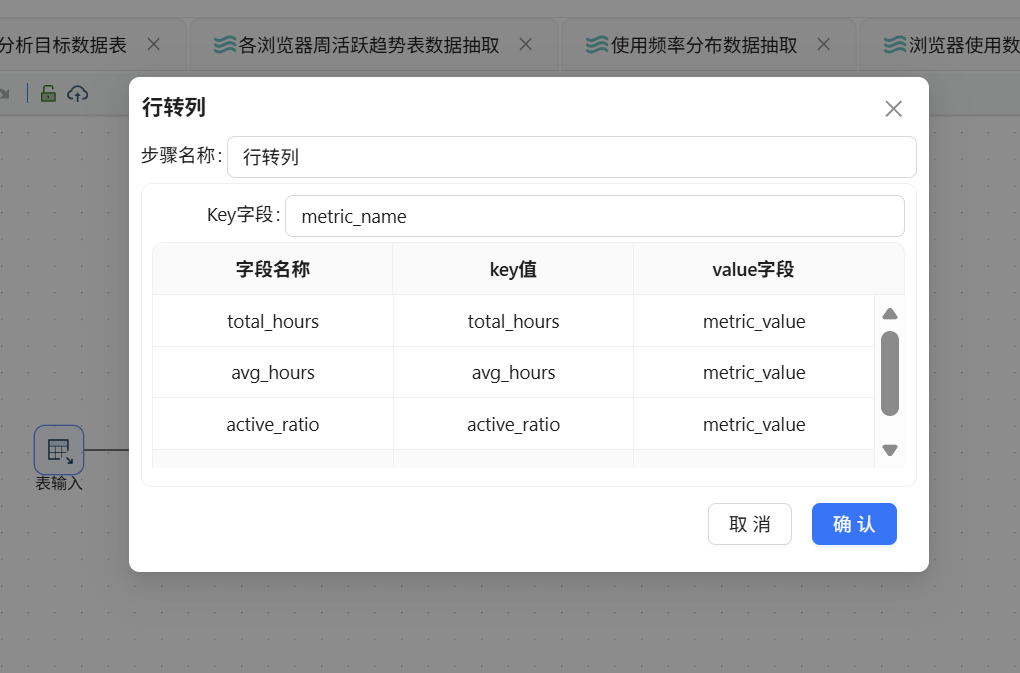
| 字段名称 | key 值 | value 字段 |
|---|---|---|
| total_hours | total_hours | metric_value |
| avg_hours | avg_hours | metric_value |
| active_ratio | active_ratio | metric_value |
| heavy_ratio | heavy_ratio | metric_value |
随后使用值映射组件,将英文指标名称映射为中文名称:
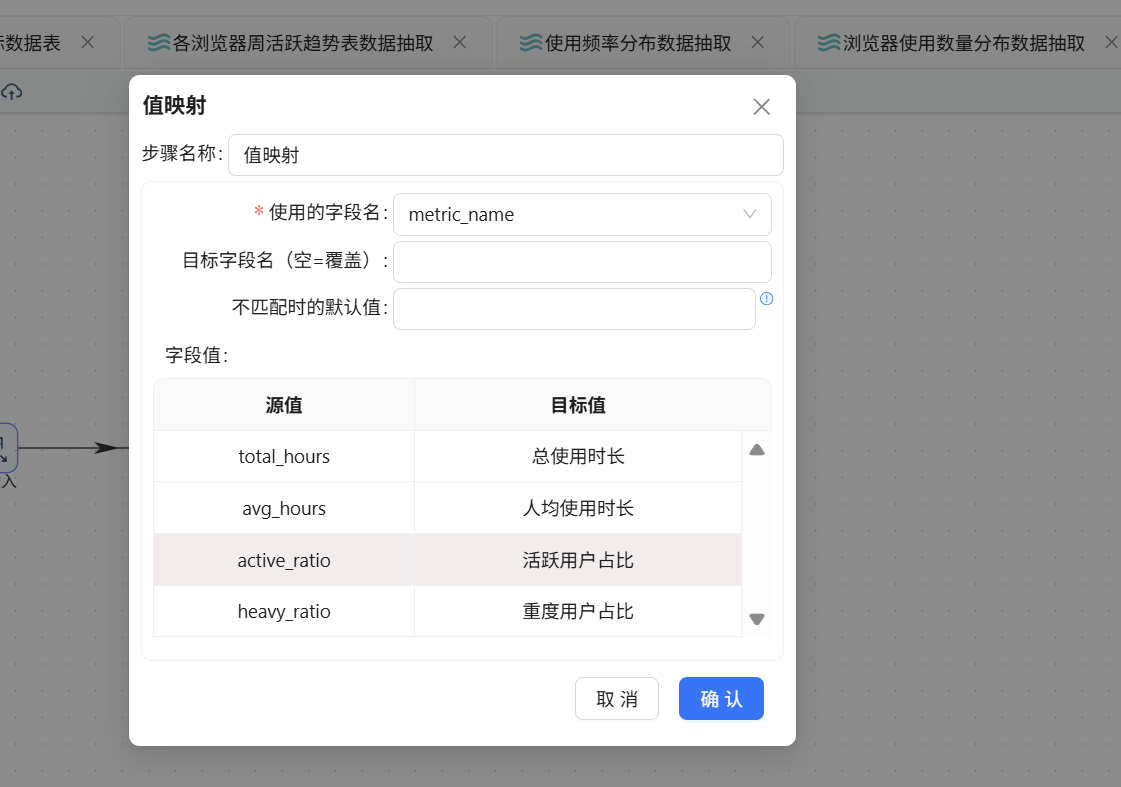
最后通过表输出组件将结果写入 browser_overview 表:
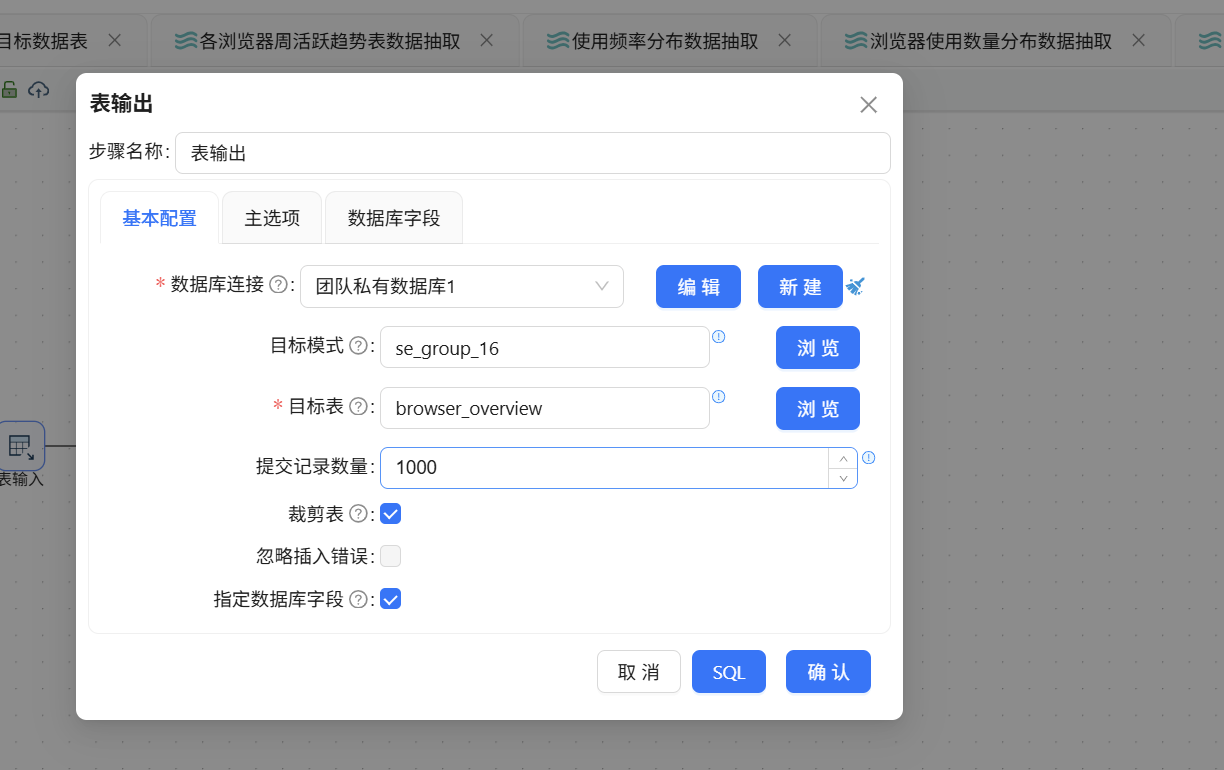
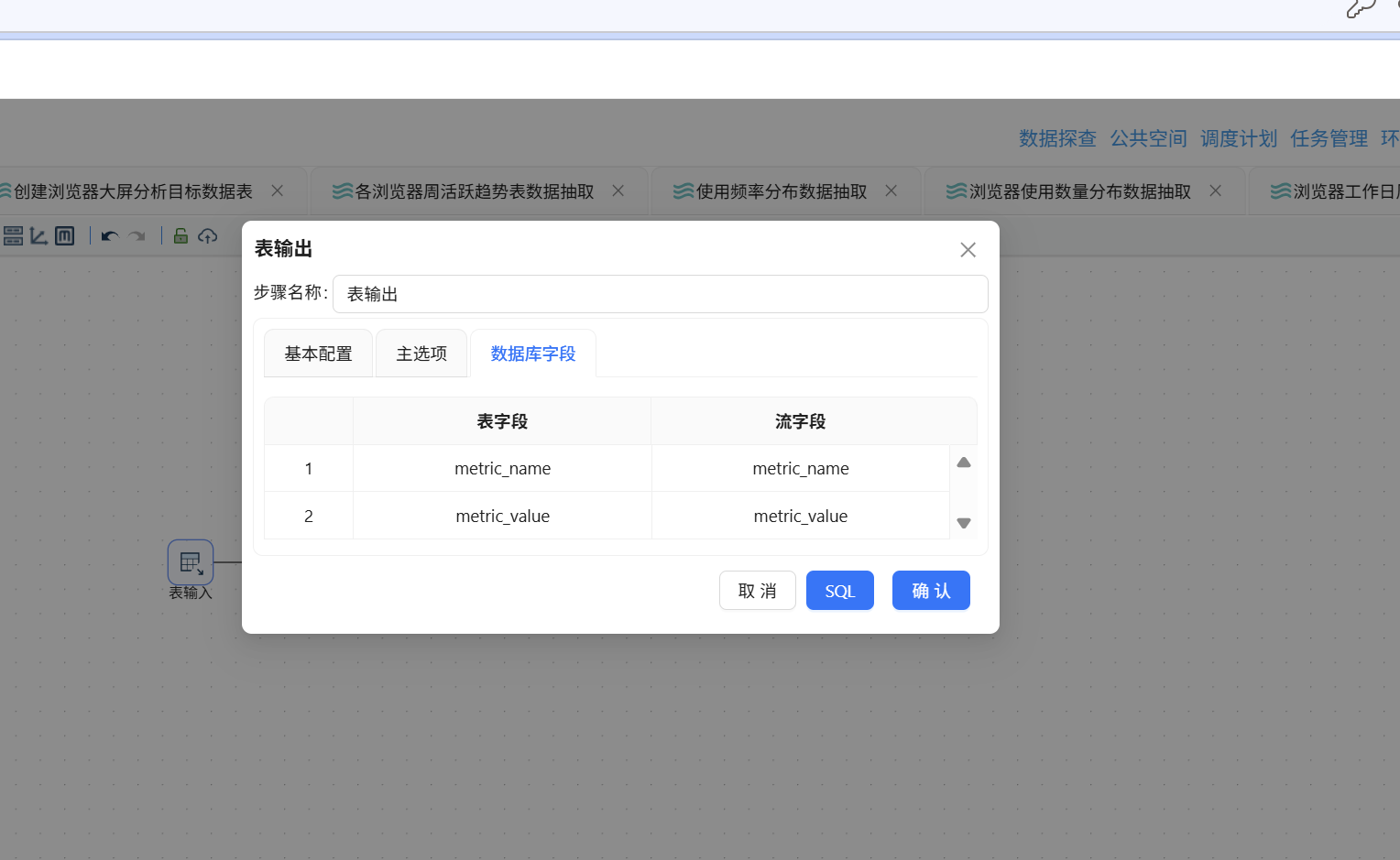
点击"运行"按钮执行转换流即可。
6.8 用户画像表加工
目标:按性别、年龄段、学历、职业、收入、居住地性质等维度,统计各浏览器的用户分布。
6.8.1 获取人口属性信息表
用户画像表的加工需要用到用户的属性信息。行为日志数据中仅包含行为记录,缺少用户属性数据,因此需要引入数据集中的人口属性信息表 demographic.csv。两份数据通过用户 ID 进行关联。
本实验已预先将 demographic.csv 存放在实验平台的公共空间数据资源区,可直接导出至项目文件库。
点击"公共空间":
切换到"数据资源"选项卡,即可看到 demographic.csv:
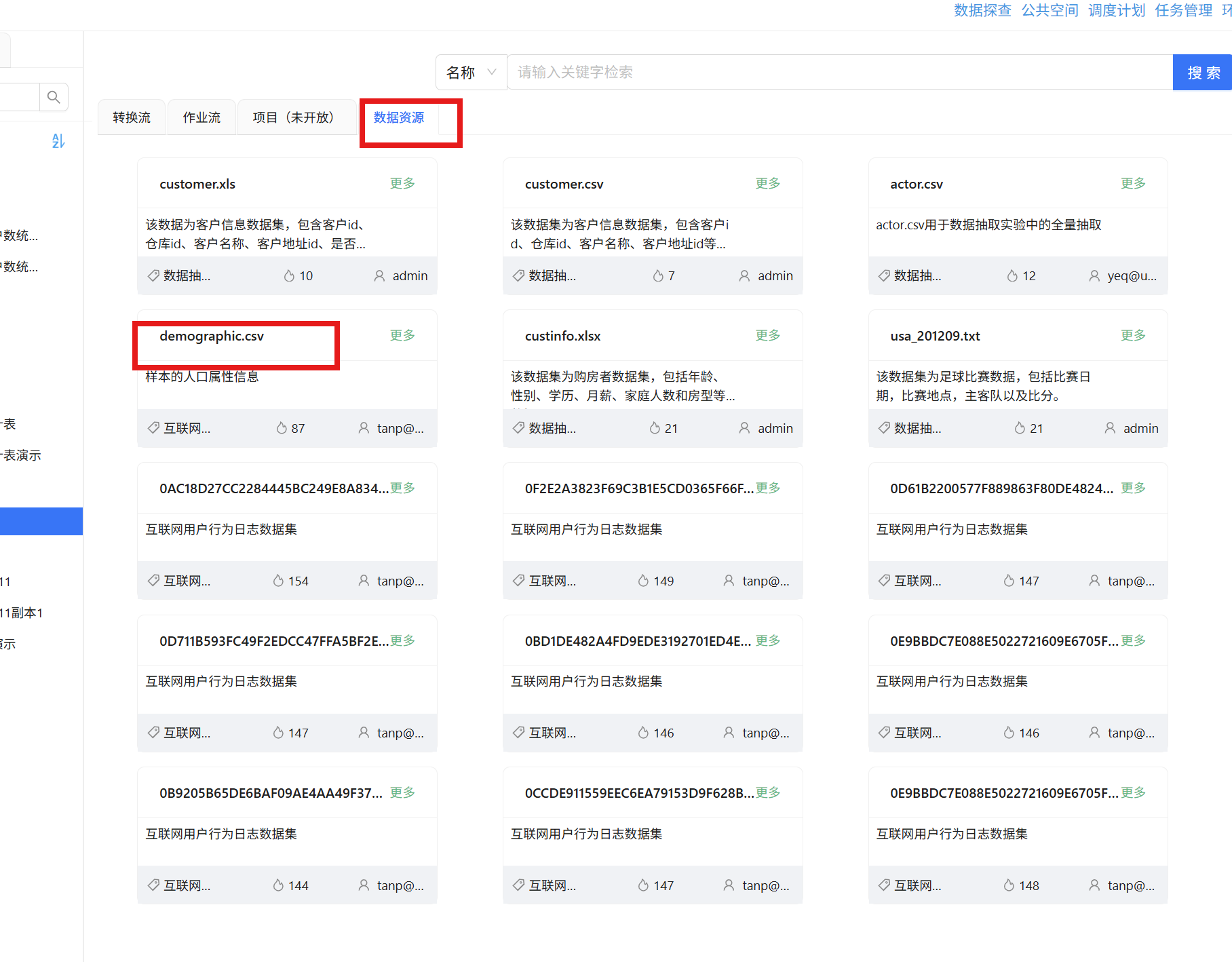
点击 demographic.csv 卡片右上角的"更多" > “导出”:
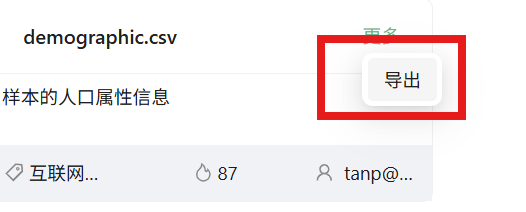
选择导出的目标目录(如根目录):
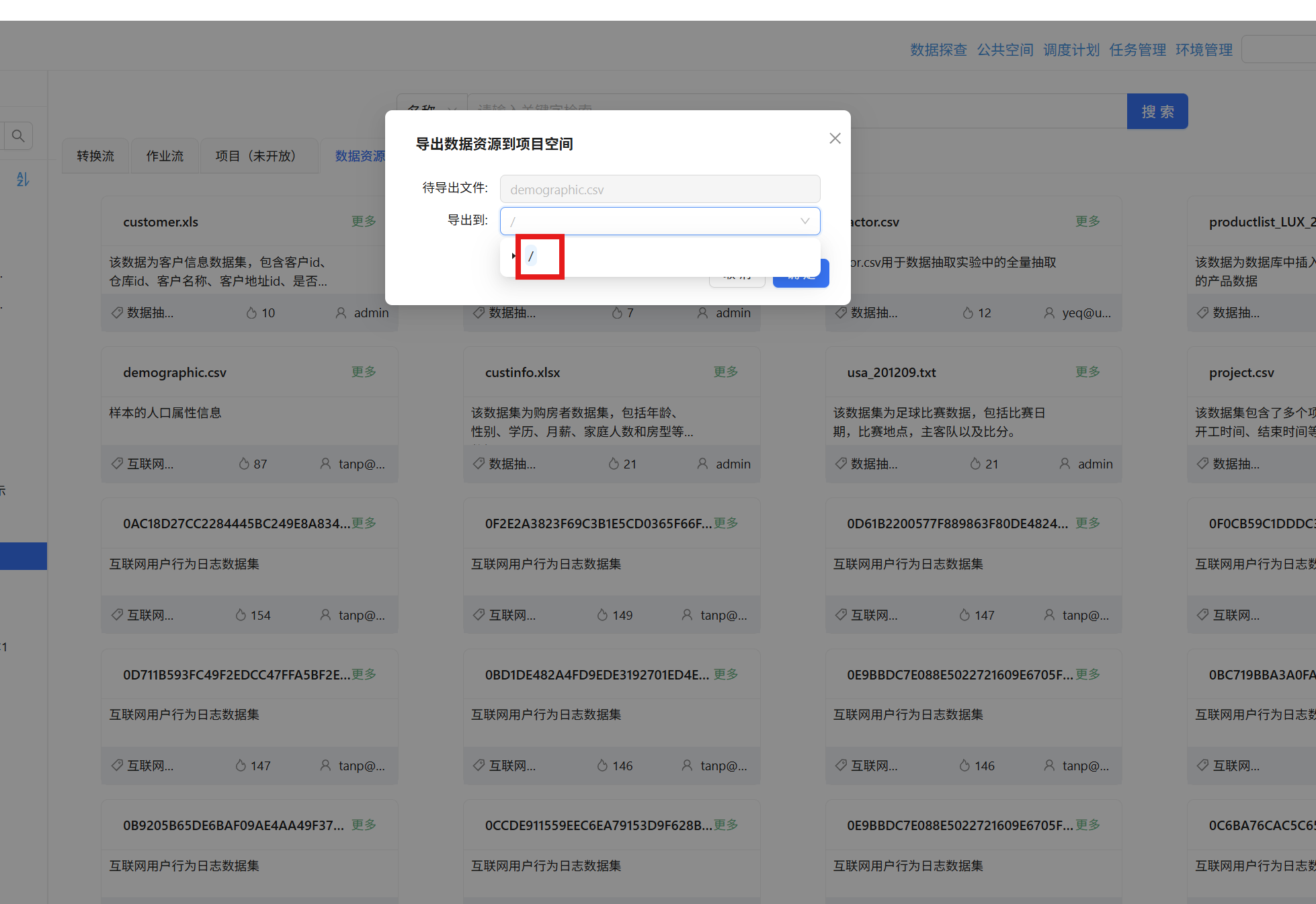
点击"确定"完成导出:
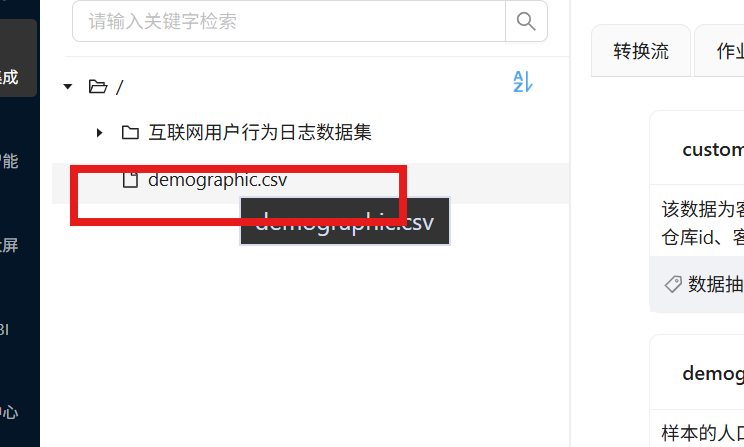
刷新文件库的根目录,确认 demographic.csv 已出现在列表中:
6.8.2 CSV 文件输入:加载人口属性数据
新建转换流"用户画像表加工",将"CSV 文件输入"组件拖入画布:
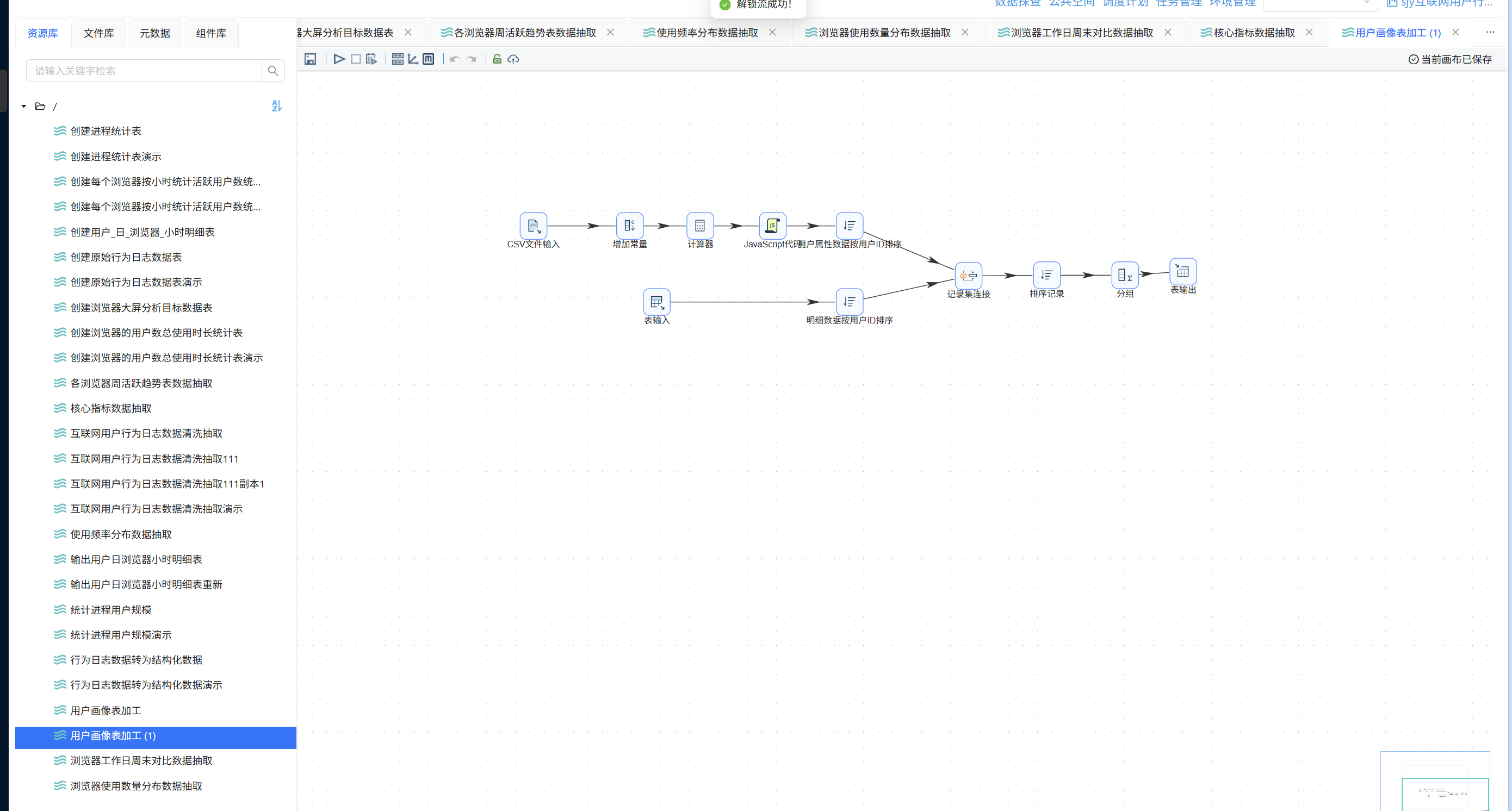
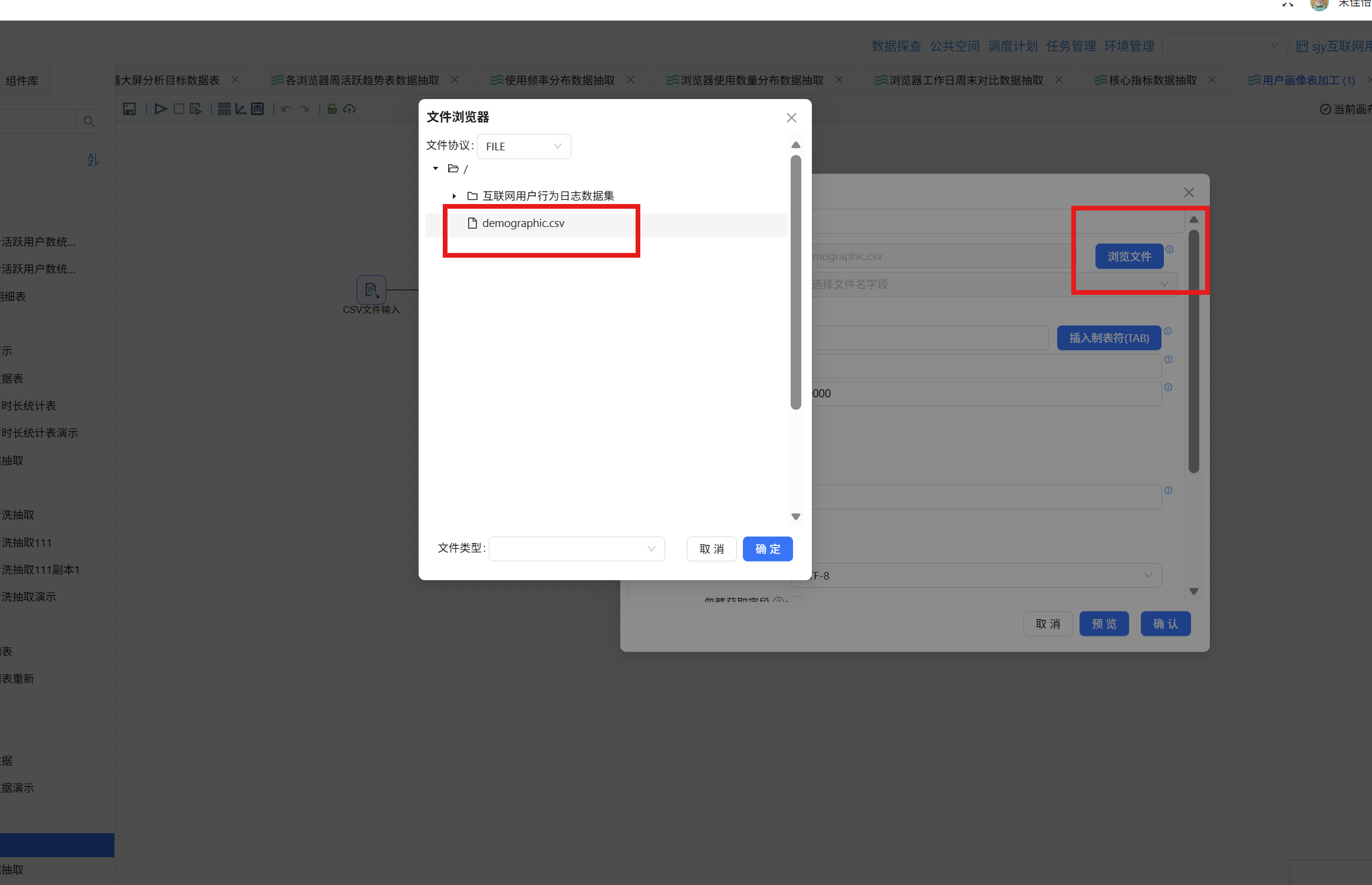
双击该组件,点击"浏览文件"按钮,在弹出窗口中选中 demographic.csv 后点击"确定":
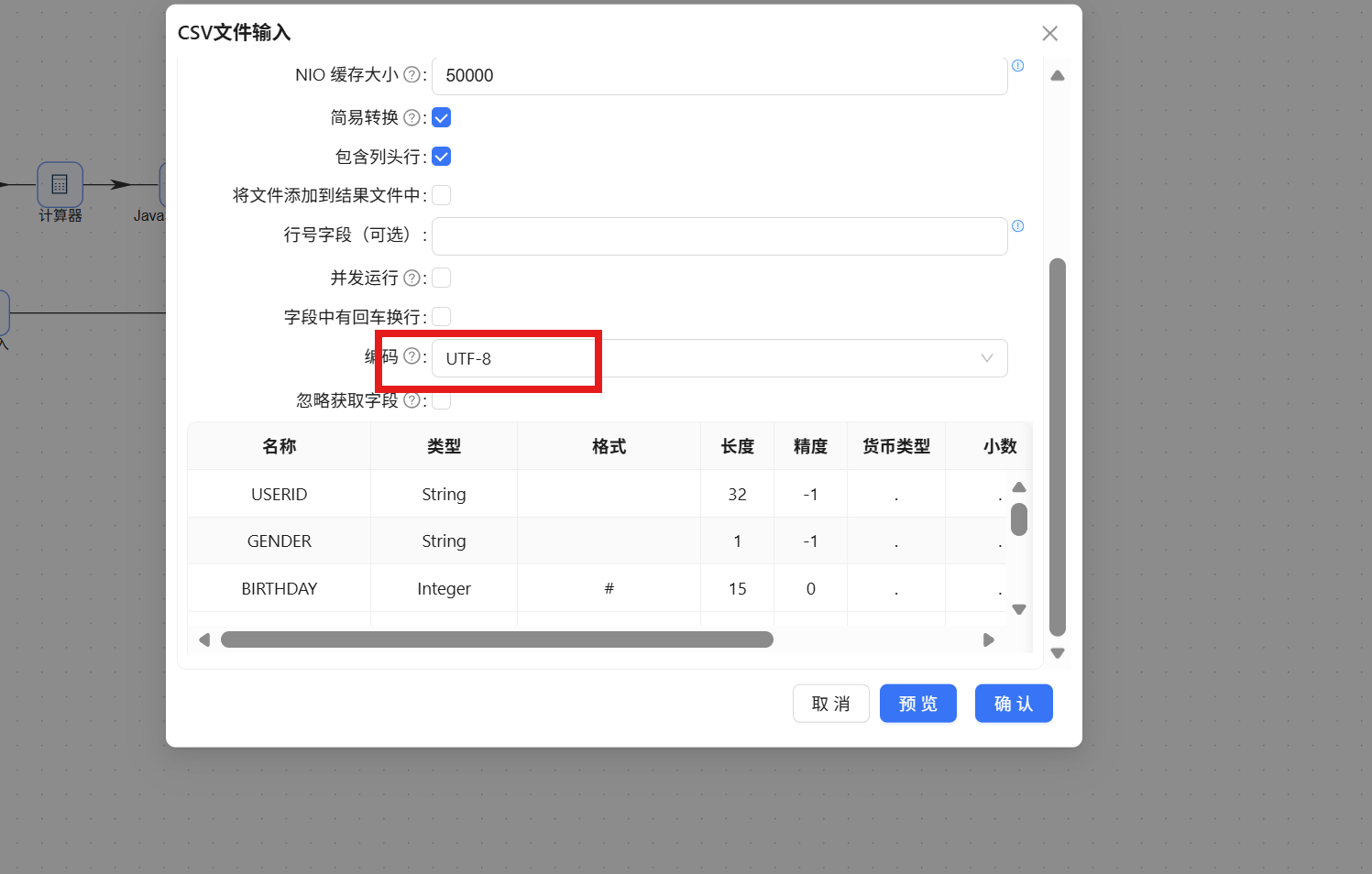
列分隔符和封闭符维持默认设置,编码方式选择"UTF-8":
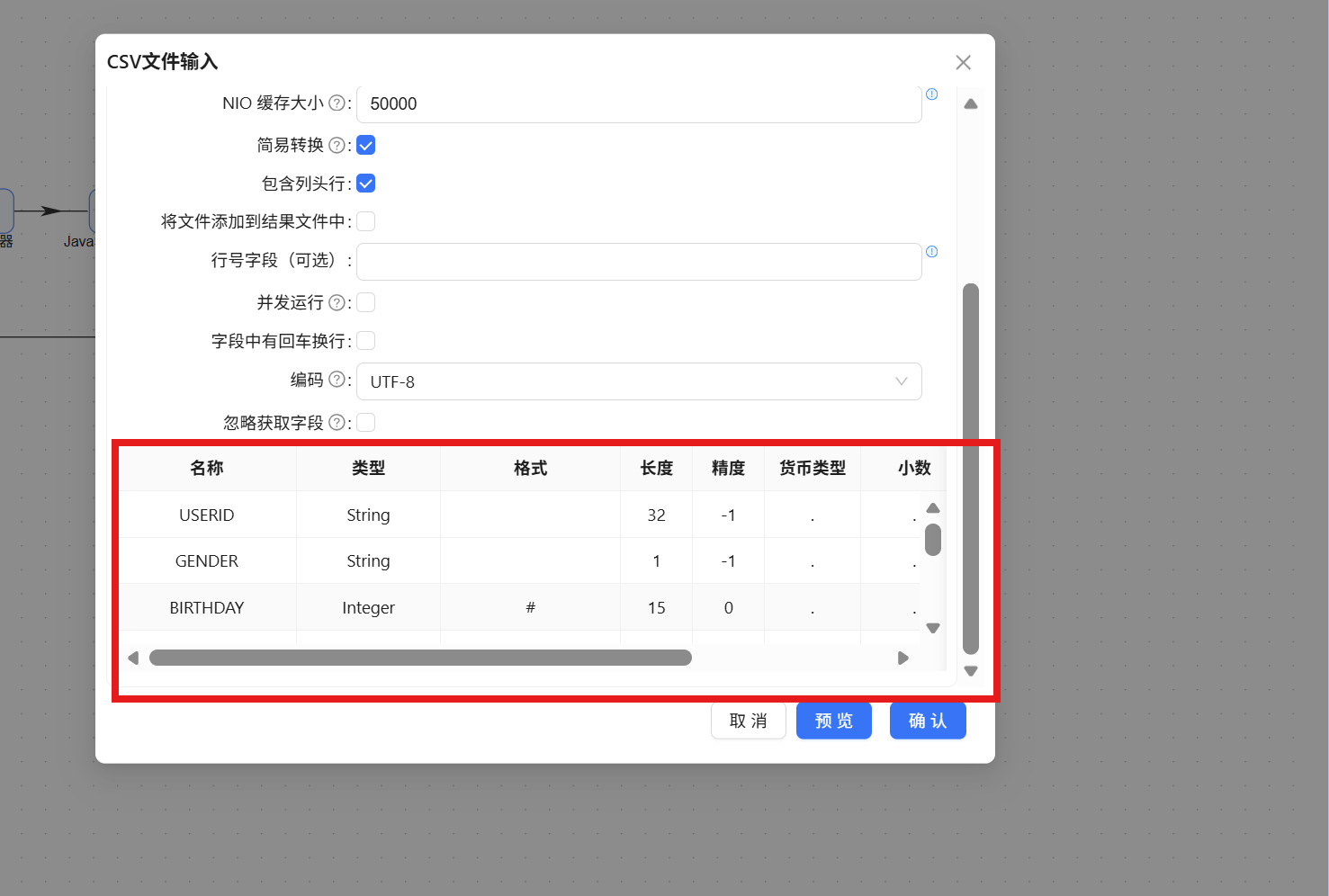
向下滚动到空白表格区域,右键点击"获取字段":
字段成功获取后点击"确认":
6.8.3 年龄分段处理
原始人口属性数据中并没有直接的年龄字段,但包含出生年份信息,因此可以通过计算得出用户年龄。
首先拖入增加常量组件,添加常量字段"year",值设定为"2012"(因为数据采集于 2012 年):
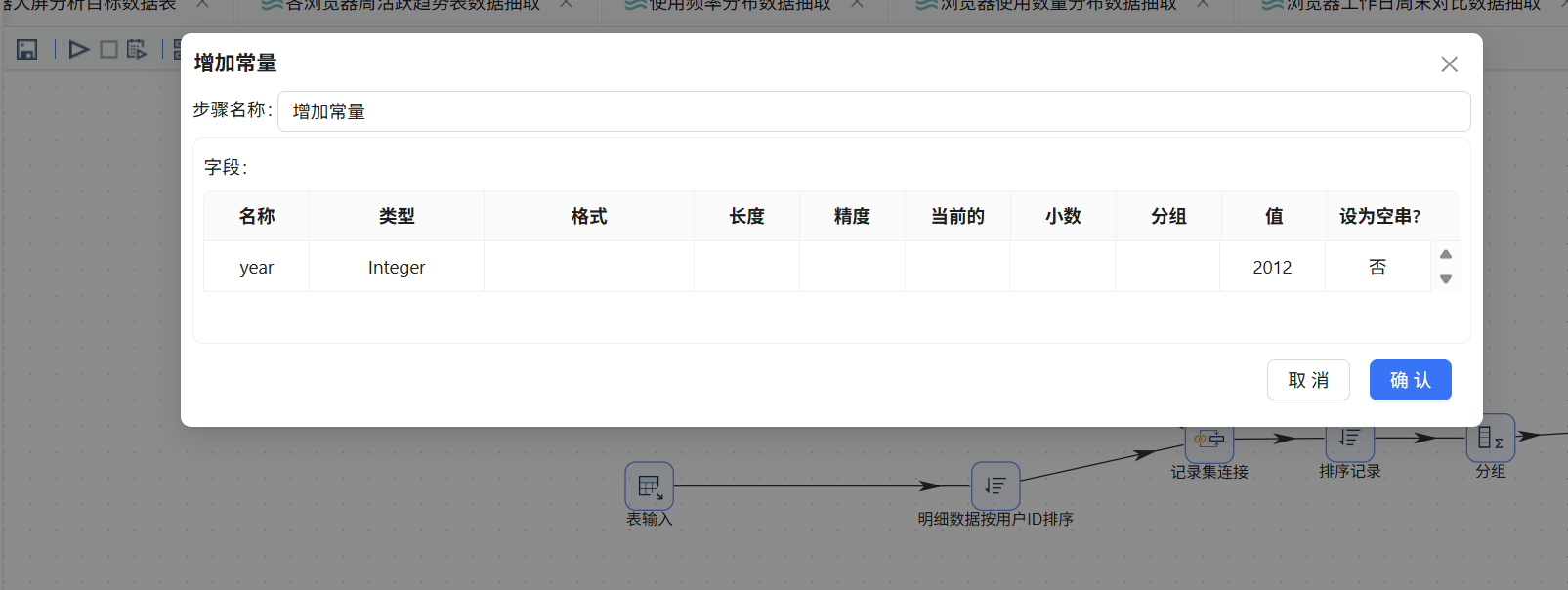
拖入"计算器"组件来计算用户在 2012 年的实际年龄,公式为:age = year - BIRTHDAY
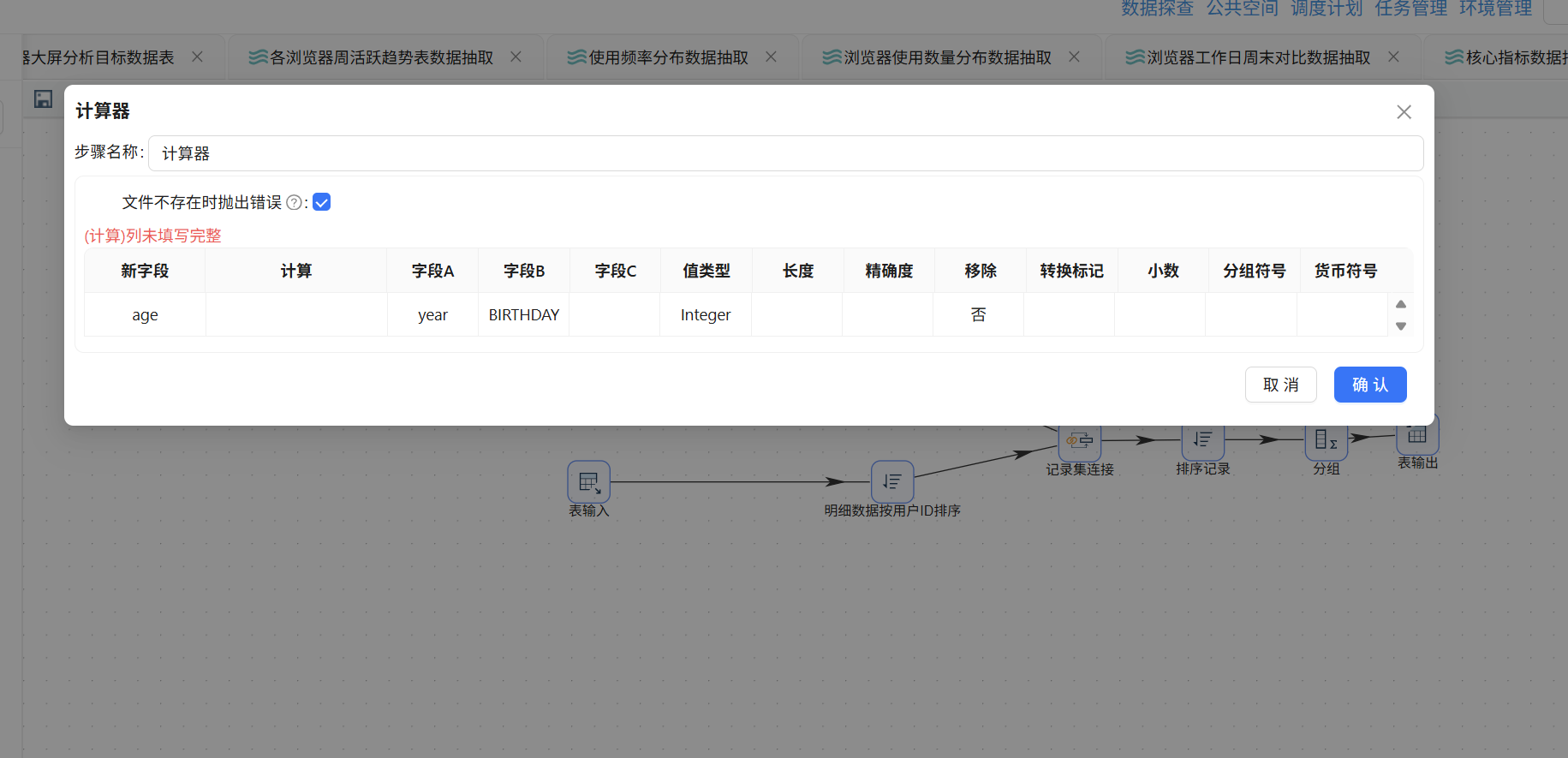
接下来将年龄划分为四个区间:<18、18-25、26-35、>35。
拖入 JavaScript 代码组件,计算器连接至该组件:
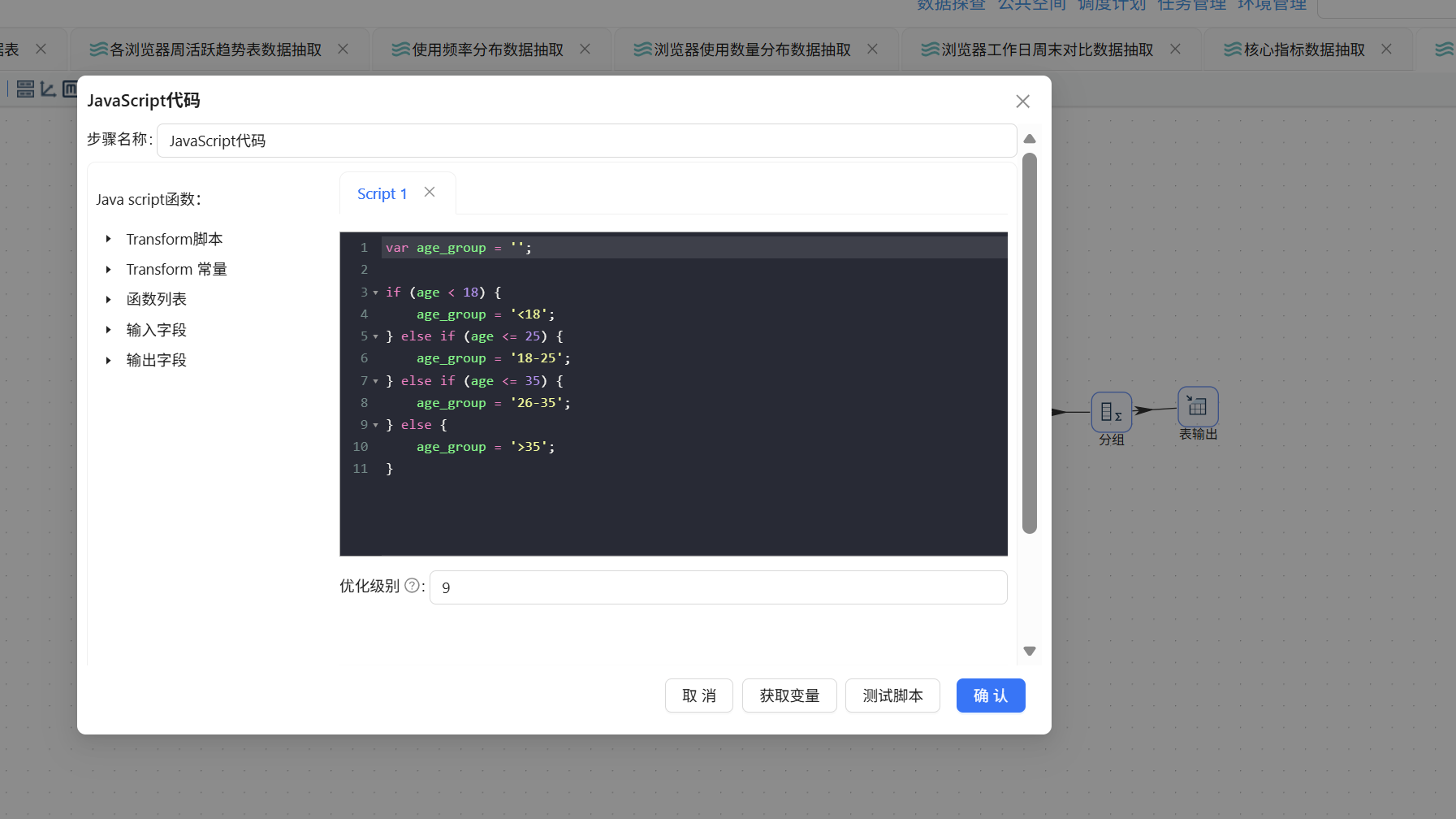
双击该组件,输入以下脚本并点击"获取变量":
var age_group = '';
if (age < 18) {
age_group = '<18';
} else if (age <= 25) {
age_group = '18-25';
} else if (age <= 35) {
age_group = '26-35';
} else {
age_group = '>35';
}
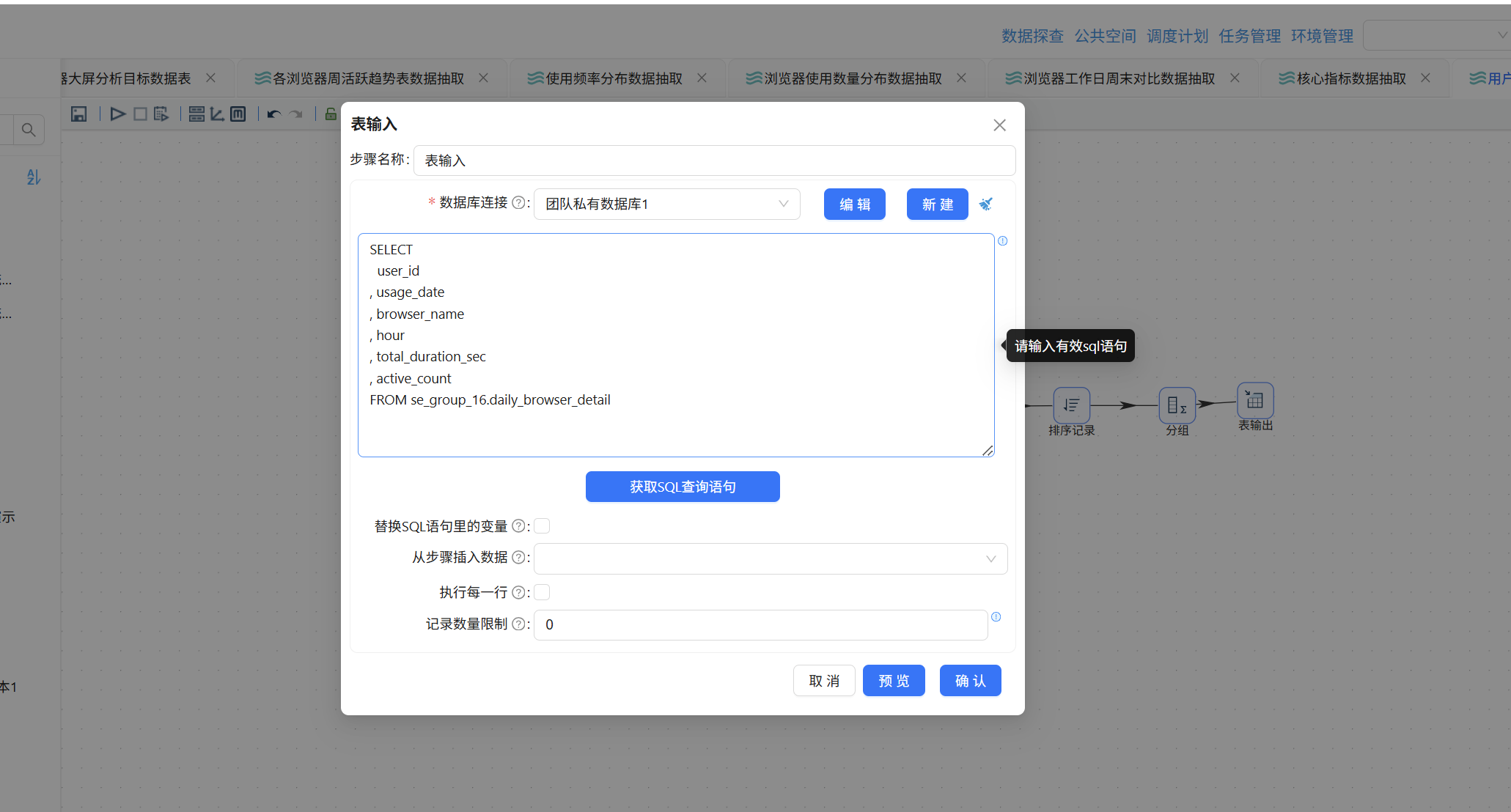
6.8.4 表输入:加载用户_日_浏览器_小时明细数据
拖入"表输入"组件到画布:
双击该组件,数据库连接选择"团队私有数据库",点击"获取 SQL 查询语句":
在弹出窗口中选中 daily_browser_detail 表:
系统提示时选择"确认":
获取到 SQL 查询语句后点击"确认":
6.8.5 关联用户属性信息
记录集连接组件能够实现两张表的连接操作,等同于数据库中的 join。使用时需注意两个输入数据集中是否存在可用于关联的公共字段。
重要提示:在执行"记录集连接"之前,必须先对两个输入数据集分别排序,否则可能导致结果异常。
拖入 2 个"排序记录"组件,分别建立"表输入"到"排序记录 1"、JavaScript 代码组件到"排序记录"的连线。其中后者的连线类型选择"主输出步骤":
双击"排序记录 1",将其重命名为"明细数据按用户 ID 排序",在空白区域右键"获取字段":
仅保留 user_id 字段,其余全部选中后右键"删除选中的行":
设置 user_id 为升序后点击"确认":
同理,双击另一个排序记录组件,重命名为"用户属性数据按用户 ID 排序",设置按 USERID 升序:
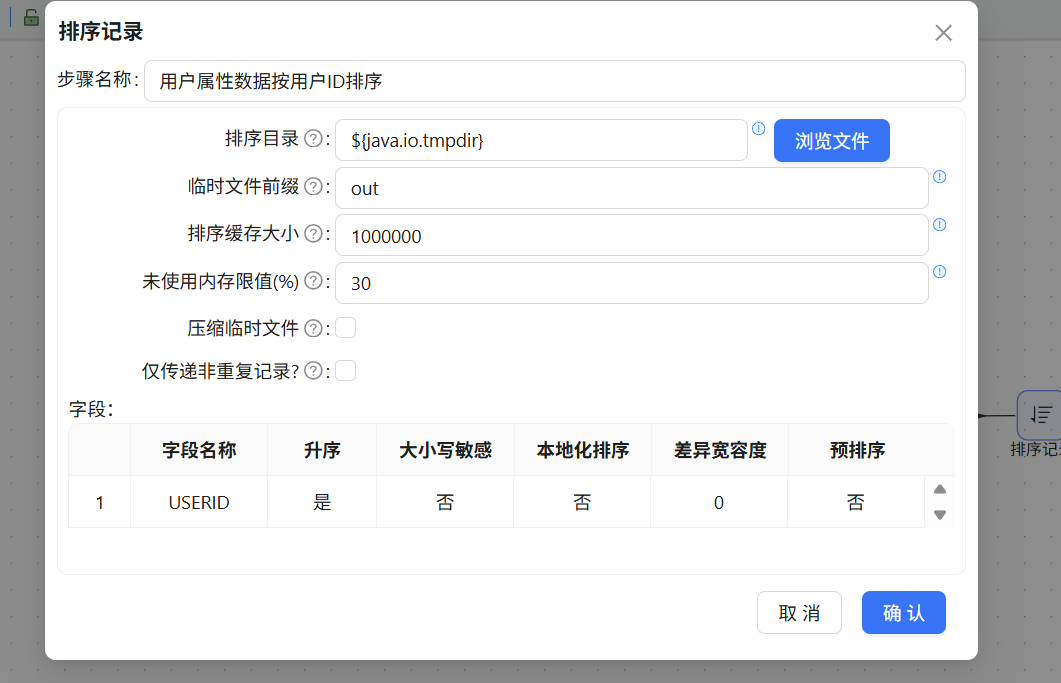
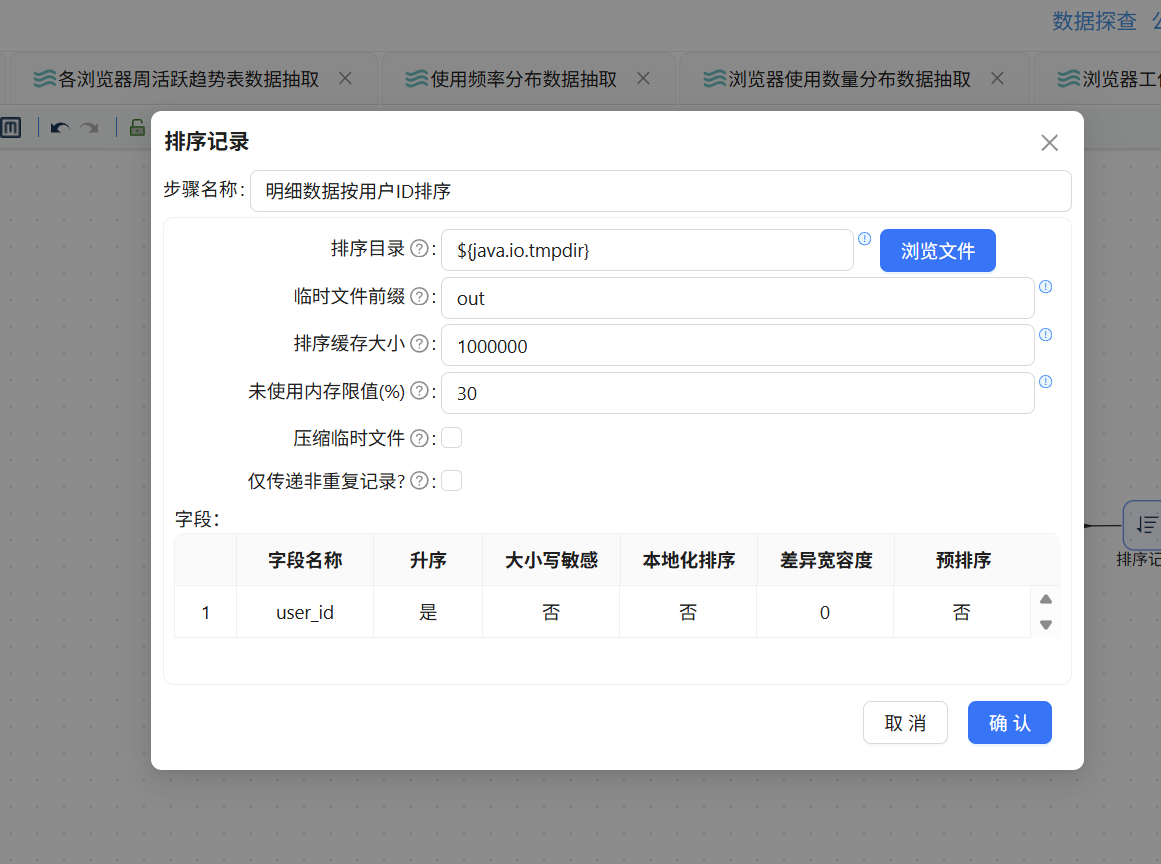
完成排序后,两路数据即可通过记录集连接组件进行关联。拖入"记录集连接"组件,两个排序记录组件分别连接到该组件。由于数据已完成排序,右上角的提示信息可以忽略:
双击"记录集连接"组件,第一个 Transform 选择"明细数据按用户 ID 排序",第二个 Transform 选择"用户属性数据按用户 ID 排序",连接类型选择"LEFT OUTER":
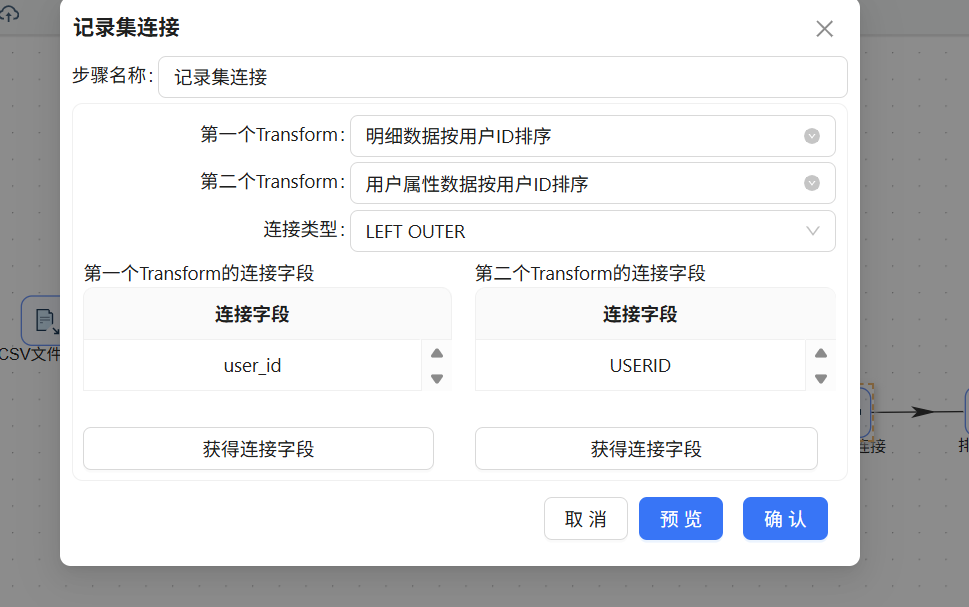
分别点击两个"获得连接字段"按钮以获取各自的字段列表:
两路数据通过用户 ID 进行关联,因此第一个 Transform 的连接字段仅保留 user_id,第二个 Transform 仅保留 USERID,其余字段通过"删除选中的行"移除:
6.8.6 分组统计用户数
分组聚合之前,须先对数据排序。拖入排序记录组件,记录集连接的输出连接到排序记录。排序字段与后续分组字段保持一致,即:browser_name、GENDER、EDU、JOB、INCOME、PROVINCE、ISCITY、age_group,均为升序:
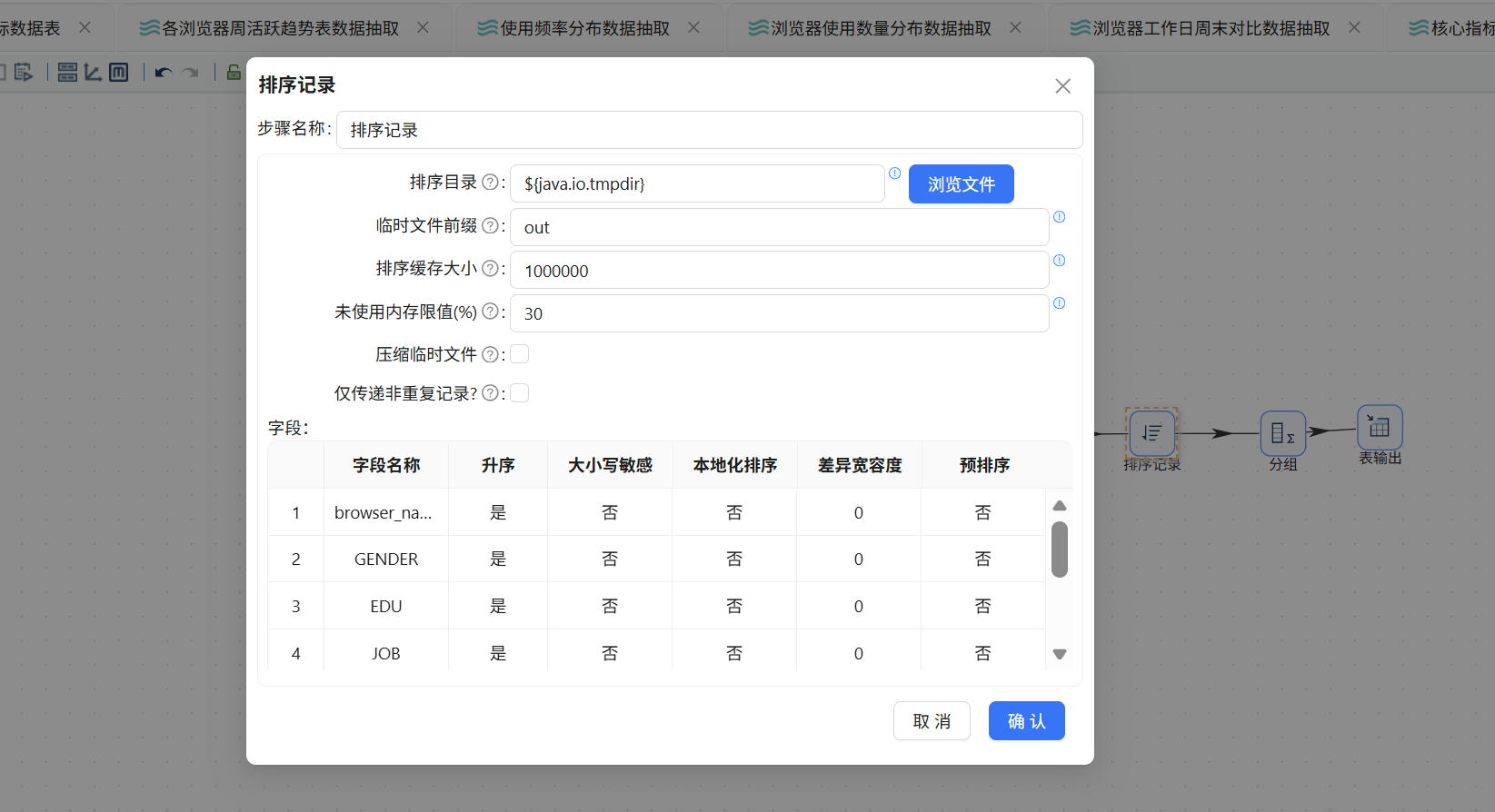
拖入分组组件,排序记录连接至分组组件。分组字段设为 browser_name、GENDER、EDU、JOB、INCOME、PROVINCE、ISCITY、age_group。聚合方式为对 user_id 执行"统计不同值的数量 (N)",得到 user_count:
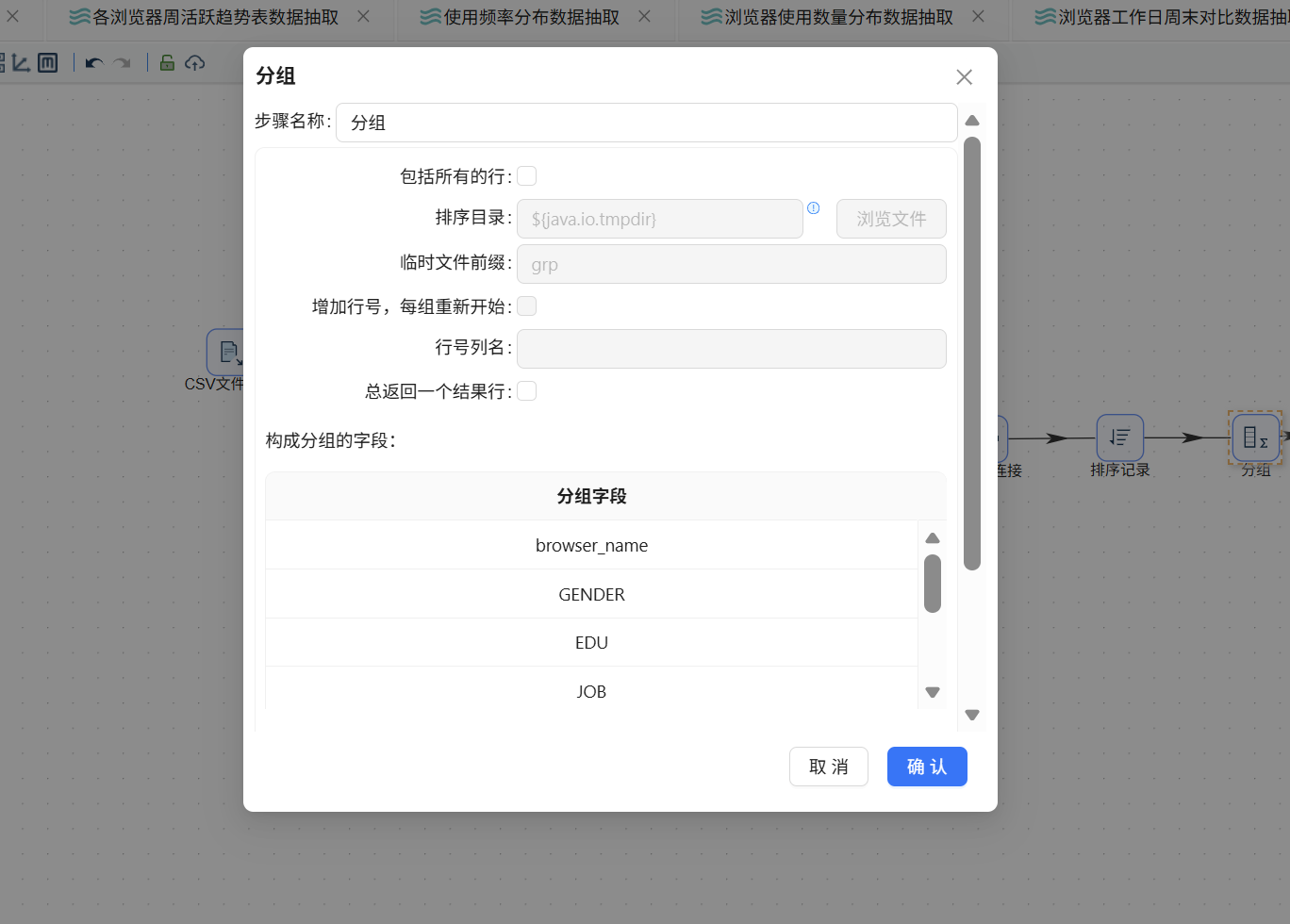
6.8.7 表输出
拖入表输出组件将聚合结果写入数据库,配置如下:
- 数据库连接:团队私有数据库
- 目标表:user_profile_stats
- 勾选"裁剪表"以清空已有数据
- 勾选"指定数据库字段"并完成字段映射
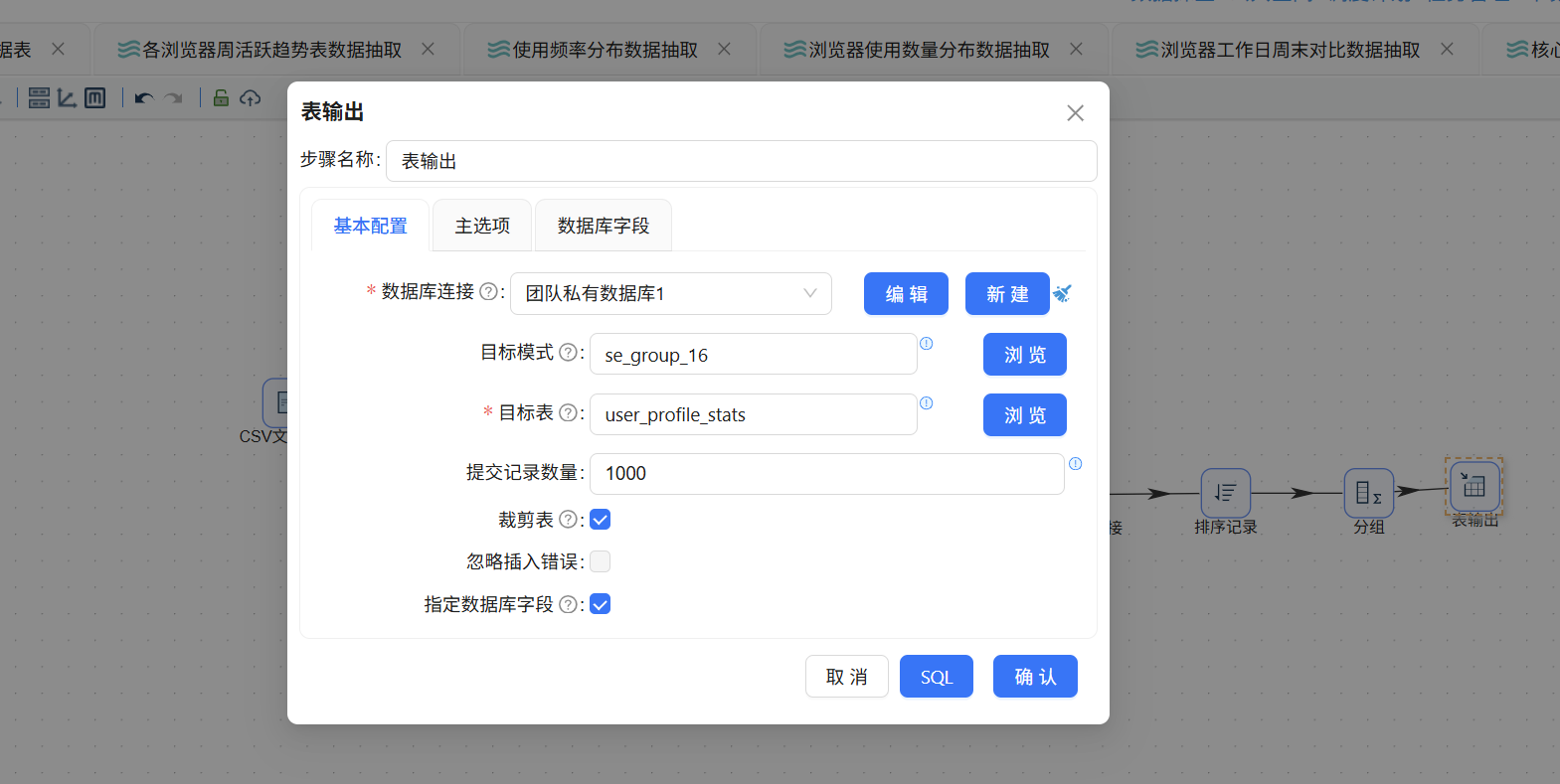
6.8.8 执行转换流
点击"运行"按钮启动转换流:
6.8.9 验证结果数据
切换到"元数据"选项卡,右键点击团队私有数据库,选择"加载元数据":
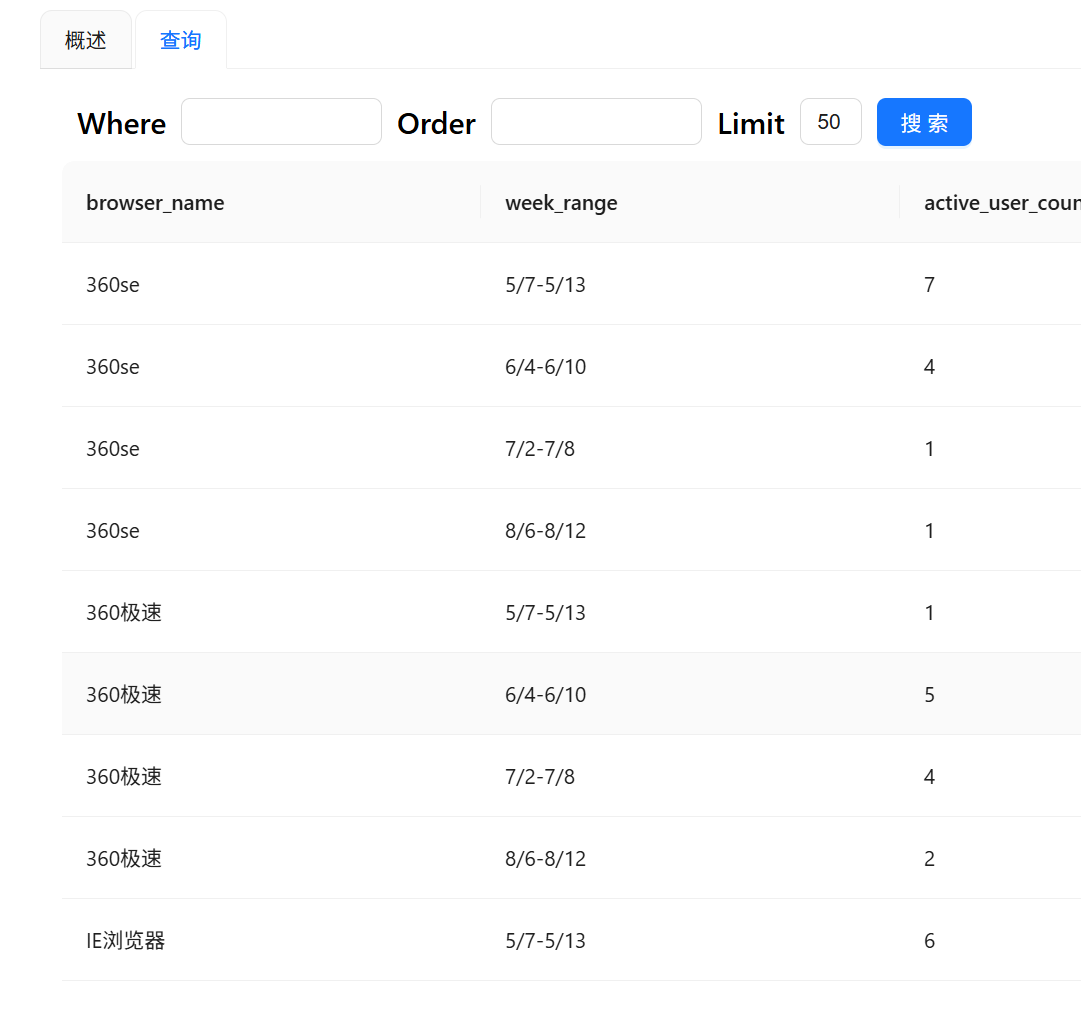
点击"数据探查",逐一检查上述生成的各目标表,确认数据是否符合预期:
【实验5-2】
1 实验目的
本实验以前两个实验《浏览器市场与用户画像分析 - 数据加工》中产出的各类统计表为数据基础,借助助睿 Max 数据大屏工具,搭建浏览器市场行为分析可视化大屏。
通过本实验的学习与实践,学生应能够:
- 依据业务需求规划大屏的整体布局与图表类型选择
- 将已完成加工的聚合数据表对接到可视化工具中
- 构建具备交互能力的数据大屏,并从中归纳提炼业务洞察
2 实验环境
实验平台:助睿在线实验平台 https://lab.guilian.cn/
本实验依托助睿数智(Uniplore)一站式数据科学平台进行。该平台覆盖数据接入、ETL 处理、机器学习建模到可视化呈现的全链路零代码能力,适用于教学实训与企业级数据加工场景。
- 助睿数智官网:Uniplore iDIS-大数据智能全流程服务平台-BI数据可视化工具
- 可视化工具:助睿 Max(数据大屏)
3 实验数据
本实验直接复用前序实验加工完成的大屏一(市场行为分析)目标表,聚焦于浏览器自身的市场格局、使用行为特征、时段偏好以及竞争态势。
| 模块 | 子模块 | 指标项 | 组件 | 关联数据表 | 备注 |
|---|---|---|---|---|---|
| 数据概览 | 浏览器市场 | 总使用时长 | 指标卡 | browser_coverage | 全部用户累计使用时长(小时) |
| 人均使用时长 | 指标卡 | browser_coverage | 总使用时长 / 覆盖用户数(小时/周) | ||
| 活跃用户占比 | 指标卡 | browser_coverage | 周活跃用户数 / 覆盖用户数 | ||
| 重度用户占比 | 指标卡 | browser_frequency_stats | 使用时长>10 小时/周的用户占比 | ||
| 市场格局 | 用户规模 | 用户数 | 柱状图 | browser_coverage | 展示 6 款浏览器的用户数量 |
| 使用规模 | 使用时长 | 饼图 | browser_coverage | 展示各浏览器使用时长占比 | |
| 使用粘性 | 人均使用时长 | 柱状图 | browser_coverage | ||
| 用户行为 | 时间趋势 | 周活跃趋势 | 折线图 | browser_weekly_active | 展示第 1-4 周各浏览器活跃用户数变化 |
| 使用习惯 | 使用频率分布 | 堆叠柱状图 | browser_frequency_stats | 轻/中/重度用户在各浏览器中的占比 | |
| 时段偏好 | 全天时段 | 24 小时活跃分布 | 折线图 | browser_hourly | X 轴为小时,Y 轴为活跃用户数,不同颜色区分浏览器 |
| 周内对比 | 工作日 vs 周末 | 分组柱状图 | daily_browser_detail | 对比工作日与周末的使用时长 | |
| 竞争关系 | 使用数量 | 浏览器使用数量分布 | 饼图 | browser_multi_usage | 使用 1 种/2 种/3 种及以上浏览器的用户比例 |
4 整体分析框架
4.1 业务问题
我们期望通过数据大屏来回答以下几个关键业务问题:
| 业务问题 | 对应的分析维度 |
|---|---|
| 哪款浏览器的用户基数最大?哪款使用时间最长? | 市场格局 |
| 用户活跃度呈上升还是下降趋势? | 周活跃趋势 |
| 用户在一天中哪个时段最为活跃? | 时段偏好 |
| 用户属于高频使用还是偶尔打开? | 使用频率 |
| 用户同时使用几款浏览器? | 浏览器使用数量 |
| 用户还在使用哪些竞品浏览器? | 竞品交叉 |
| 工作日与周末的使用行为有何差异? | 工作日 vs 周末 |
4.2 大屏设计原则
- 叙事顺序:遵循从上到下、从左到右的阅读逻辑,先呈现整体概况再展开局部细节,先展示趋势再深入分析
- 核心指标醒目呈现:在大屏顶部放置关键指标卡(覆盖用户数、总时长、人均时长、活跃占比、重度占比)
- 图表类型与数据特征匹配:趋势变化用折线图,对比分析用条形图/柱状图,占比分布用环形图/饼图
- 颜色体系统一:为 6 款浏览器分配固定配色方案(IE 蓝、Chrome 红、360 绿等),确保视觉辨识度
- 交互能力:提供浏览器筛选控件,支持查看全局数据或聚焦某一浏览器
4.3 大屏布局草图
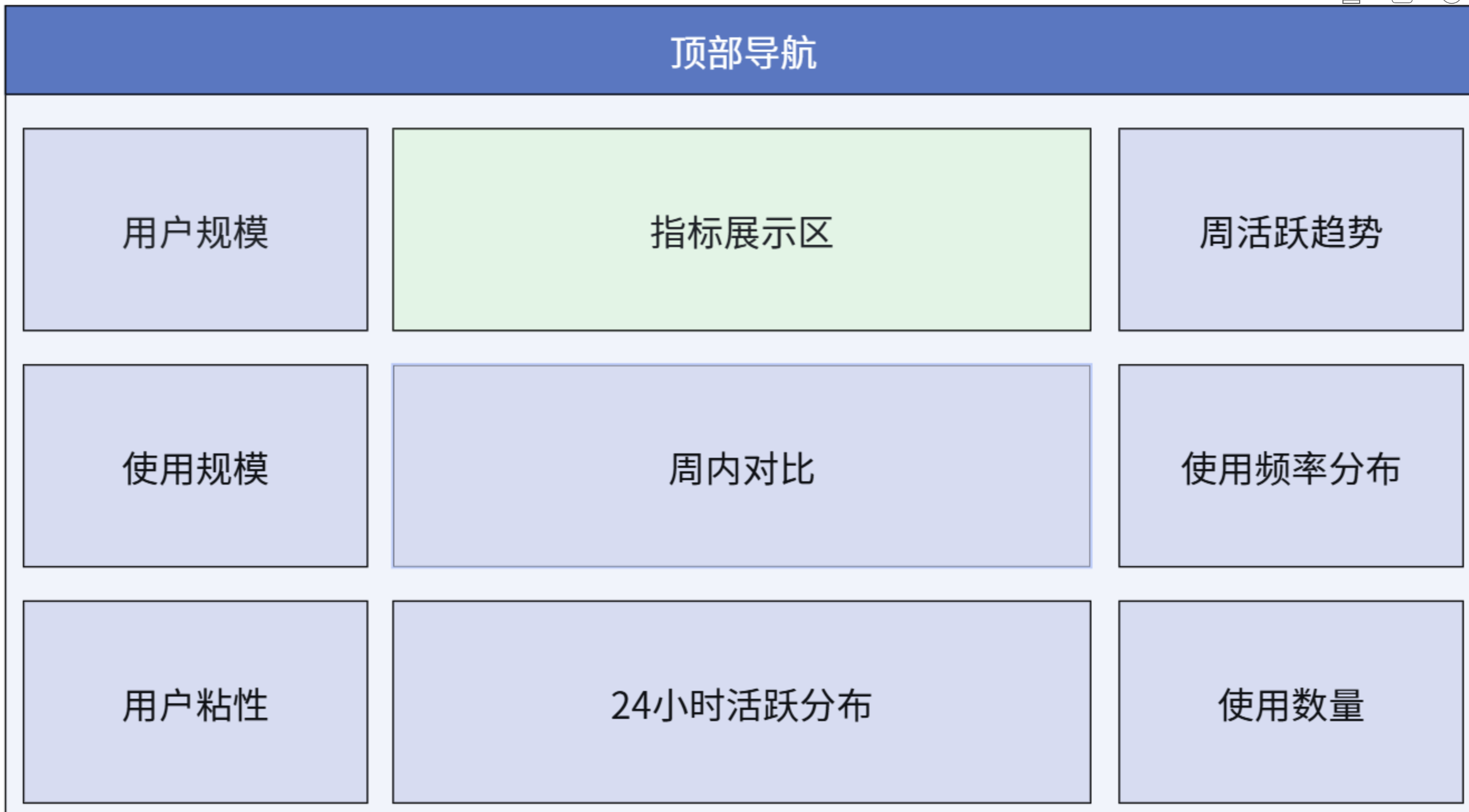
5 实验步骤
点击实验平台左侧导航栏中的"数据大屏"入口:
随后进入助睿数据大屏可视化子平台:
助睿数据大屏可视化是一款支持通过图形化界面快速搭建专业级可视化应用的产品,广泛应用于会议展示、业务监控、风险预警、地理分析等场景。与传统图表相比,它能够以更加直观生动的方式即时展现数据背后的业务洞察,在零售、物流、电力、环保、交通等行业均有深度应用。其核心能力包括:丰富的基础组件库、地理信息可视化(轨迹/飞线/热力图等)、多数据源支持(含 CSV)、拖拽式搭建无需编程,以及低代码蓝图编辑器(为开发者提供高级控制与数据处理能力)。
5.1 创建数据大屏
首先为本次实验新建一个市场分析大屏。点击"+新建"按钮,选择"新建大屏":
在模板选择页面中,点击"空白模板":
页面随即弹出大屏名称输入框:
输入名称"市场分析",点击下一步后自动跳转至大屏编辑界面:
5.2 设置大屏样式
5.2.1 背景设置
助睿数据大屏的背景可以通过更换背景图片来进行自定义。
平台中使用的图片元素统一通过 oss-browser 进行存储并获取访问链接。本实验涉及的所有图片链接将在文末附录中统一汇总,如有新增图片需求,可联系@谭萍 协助处理。
本次大屏使用的背景图片链接如下:
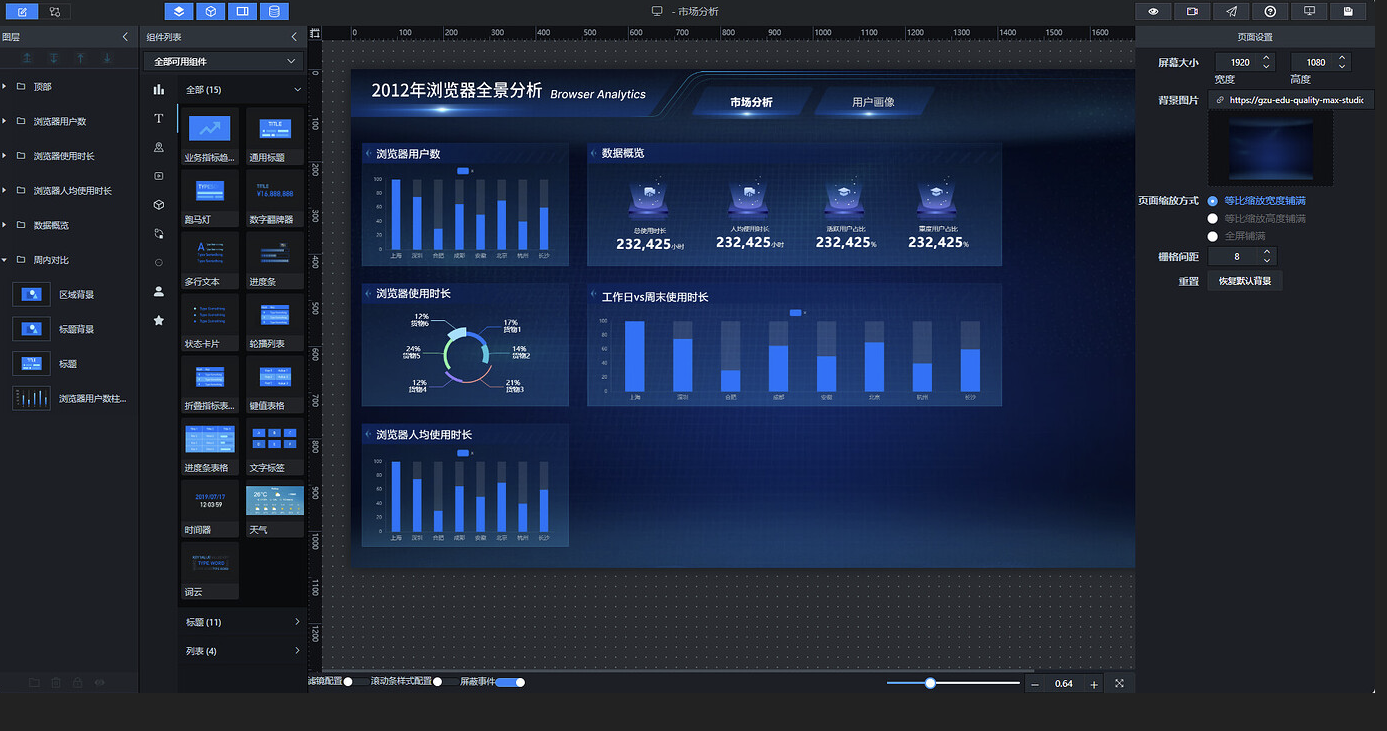
进入大屏编辑页面后,右侧可见页面设置面板,屏幕分辨率默认为 1920×1080,可根据实际展示屏幕尺寸进行调整。
将上述背景图链接复制后,粘贴到"背景图片"后方的文本输入框中,替换掉原有链接:

其余设置项保持默认即可。
5.2.2 标题设置
大屏的标题既可以使用组件手动拼接,也可以预先设计好图片直接引入。本实验已提前制作好标题图片,链接为:
https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/practice/browser-analysis/banner01.png
大屏左侧是组件列表面板,提供了包括图表、文字、地图、媒体素材、交互控件等在内的丰富组件。此处我们使用图片组件来承载标题图。
点击"媒体"组件分类,选择"单张图片"组件:
画布中会自动添加一个图片组件:
为便于后续管理,右键该组件并点击"重命名":
输入名称"标题 banner":
选中该图片组件后,右侧面板显示其属性配置:
展开"基础属性",设置组件的宽高和位置坐标,配置如下:
展开"基本设置",将标题图片链接粘贴进去,覆盖原有链接:
https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/practice/browser-analysis/banner01.png
标题 banner 配置完成后,点击"保存":
保存后点击"预览",可随时查看当前效果:
5.2.3 导航设置
由于我们共有两个大屏页面,因此需要设置导航按钮实现页面间的跳转。
同样添加一个"单张图片"组件,重命名为"市场分析按钮背景":
除了在属性面板中直接输入数值外,也可以通过鼠标拖拽和缩放来调整组件的尺寸与位置:
不过精细调整时还是使用属性值更为精确。导航按钮的背景图链接为:
https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/comprehensive-data/navigation-bg-1.png
将其粘贴到基础设置的背景图链接字段中:
按钮上的文字通过"通用标题"组件来实现。点击文字分类下的"通用标题",重命名为"市场分析":
调整该标题组件的基础属性,使其与"市场分析按钮背景"图片组件对齐:
展开基本设置,将标题文本改为"市场分析":
切换到"数据"选项卡,点击"刷新数据":
文字内容随即更新为我们修改后的文本:
展开"文本样式",可以对字体、字号、颜色和粗细进行调整:
第二个大屏的导航按钮可以直接复制当前按钮的配置:
将复制的图片组件重命名为"用户画像按钮背景",标题组件重命名为"用户画像":
只需修改"用户画像按钮背景"和"用户画像"组件的横坐标位置即可:
复制后的组件如未正常显示,刷新数据即可恢复。
将用户画像标题组件的文本内容改为"用户画像",同时调整颜色和粗细(当前页面为市场分析大屏,因此"市场分析"按钮显示为选中态,其余按钮为未选中态):
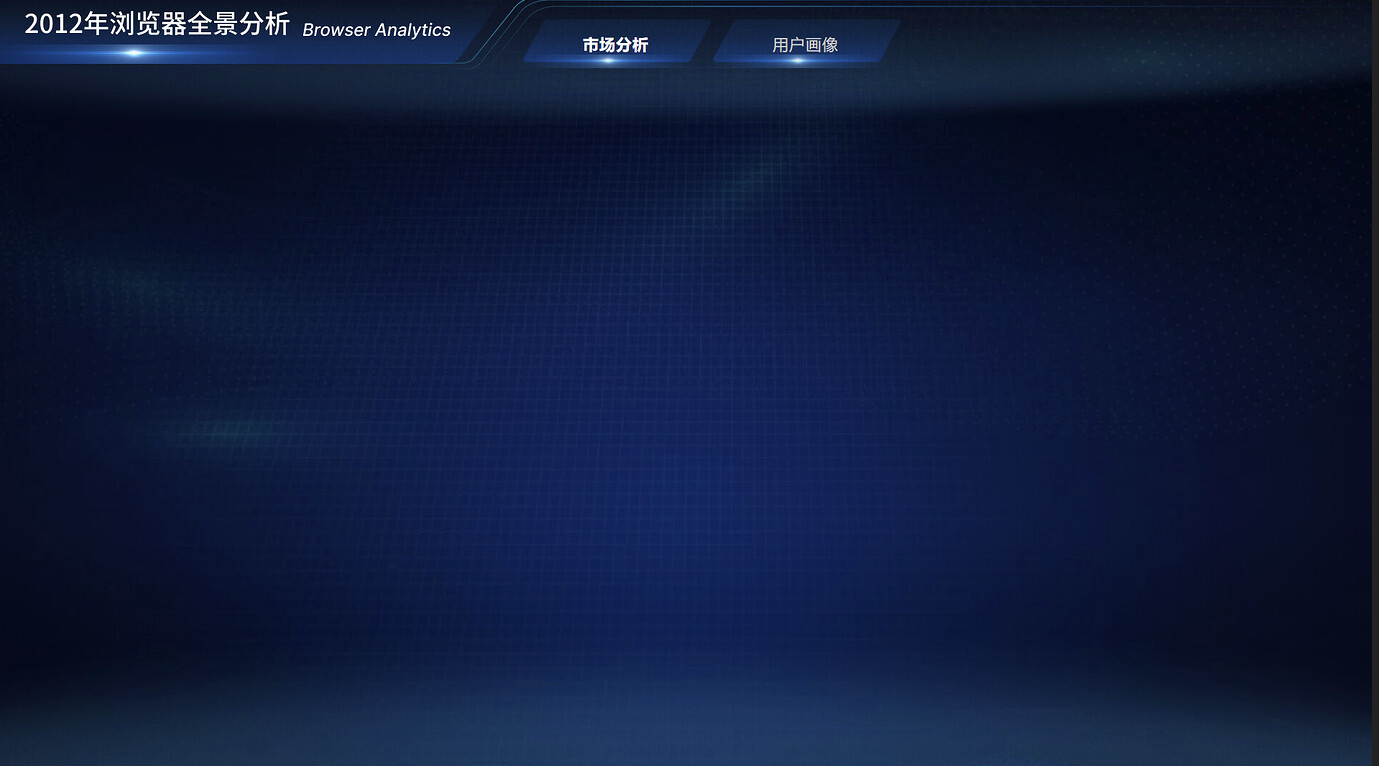
保存后预览效果:
至此,顶部标题与导航区域配置完毕。为便于统一管理,将这些组件全部选中后右键"成组":
将该组命名为"顶部":
5.3 设置内容布局与样式
接下来,依照"4.3 大屏布局草图"中的规划,逐一完成各图表区域的排版工作。
根据参考效果图,每个图表区域一般包含以下构成要素:
- 区域背景:使用单张图片组件
- 标题背景:使用单张图片组件
- 标题文字:使用通用标题组件
- 图表主体:使用对应的图表组件
5.3.1 用户规模——浏览器用户数
我们从左上角第一个图表区域开始制作。添加一个"单张图片"组件,重命名为"区域背景",参照布局草图和效果图设定其尺寸和坐标:
将区域背景图片链接粘贴到背景图字段中:
https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/public-material/area-bg.png
再添加一个"单张图片"组件,重命名为"标题背景",用于图表标题的底图。该图表在布局中属于短尺寸图表,因此使用短标题背景图:
https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/public-material/title-bg-short.png
调整好位置和尺寸后粘贴链接即可:
添加"通用标题"组件,重命名为"标题",参照效果图调整尺寸和位置,将标题内容改为"浏览器用户数",对齐方式设为左对齐。其他配置参考如下:
依据"3 实验数据"中的规划,浏览器用户数对应的图表类型为柱状图。点击添加"基础柱状图"组件:
重命名为"浏览器用户数柱状图",调整尺寸和位置:
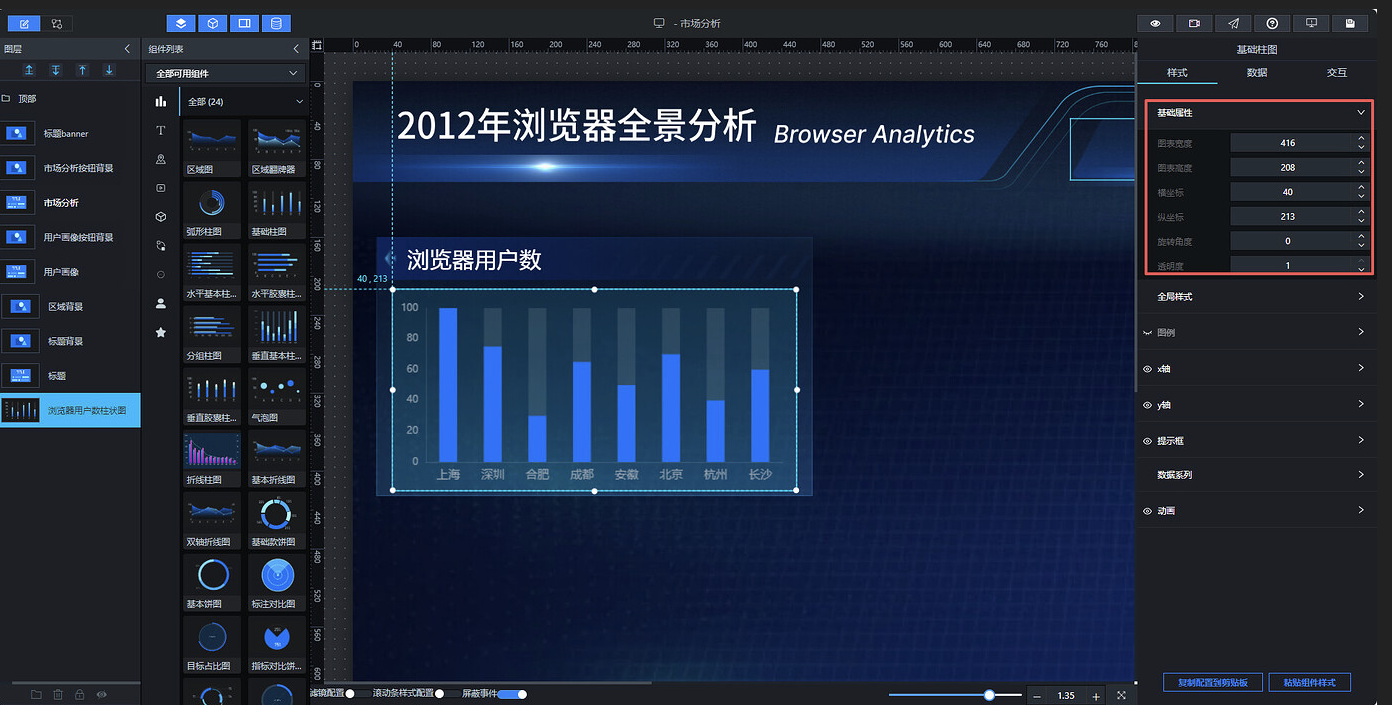
图表的图例默认为隐藏状态,将其设置为可见,并将水平对齐方式调整为居中:
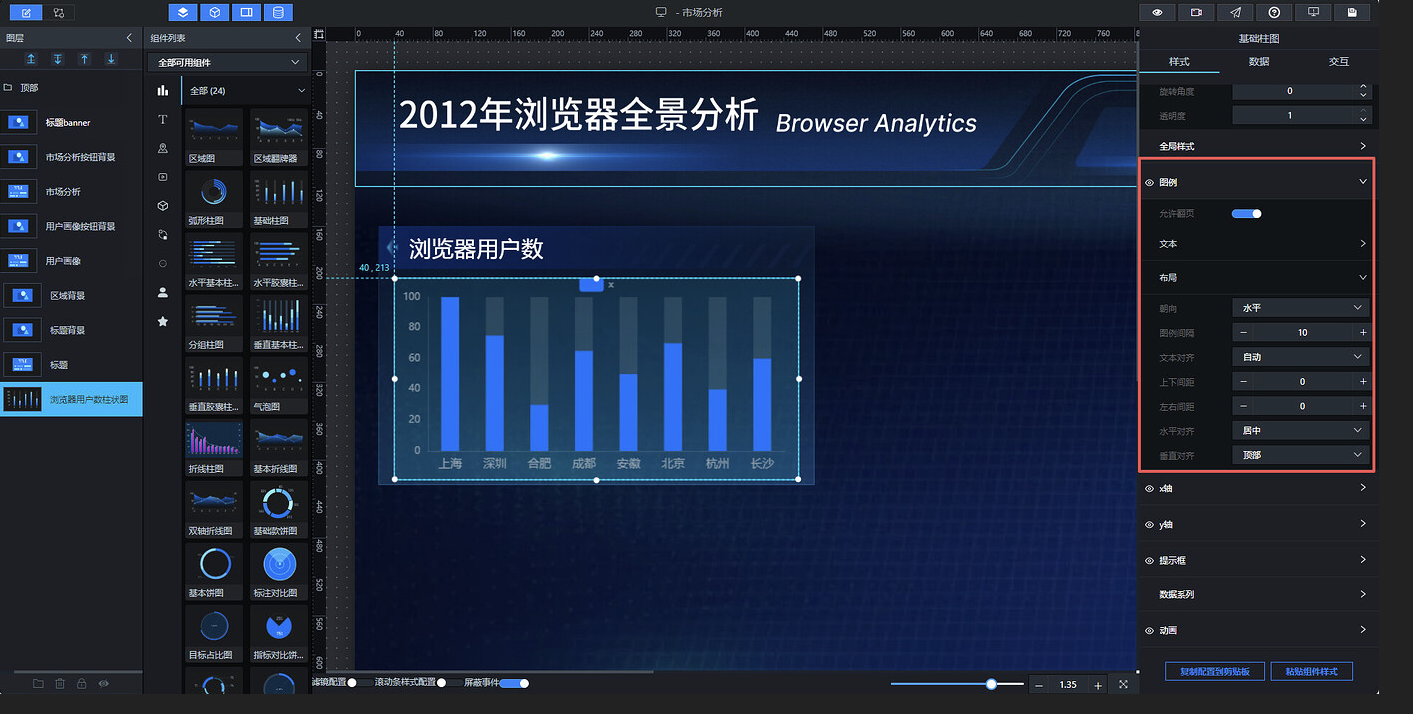
此时可能会发现柱体与图例之间间距过小,视觉效果欠佳。展开"全局样式"进行调整,适当增大柱体的上边距即可:
其余样式细节可根据个人偏好自行调整。
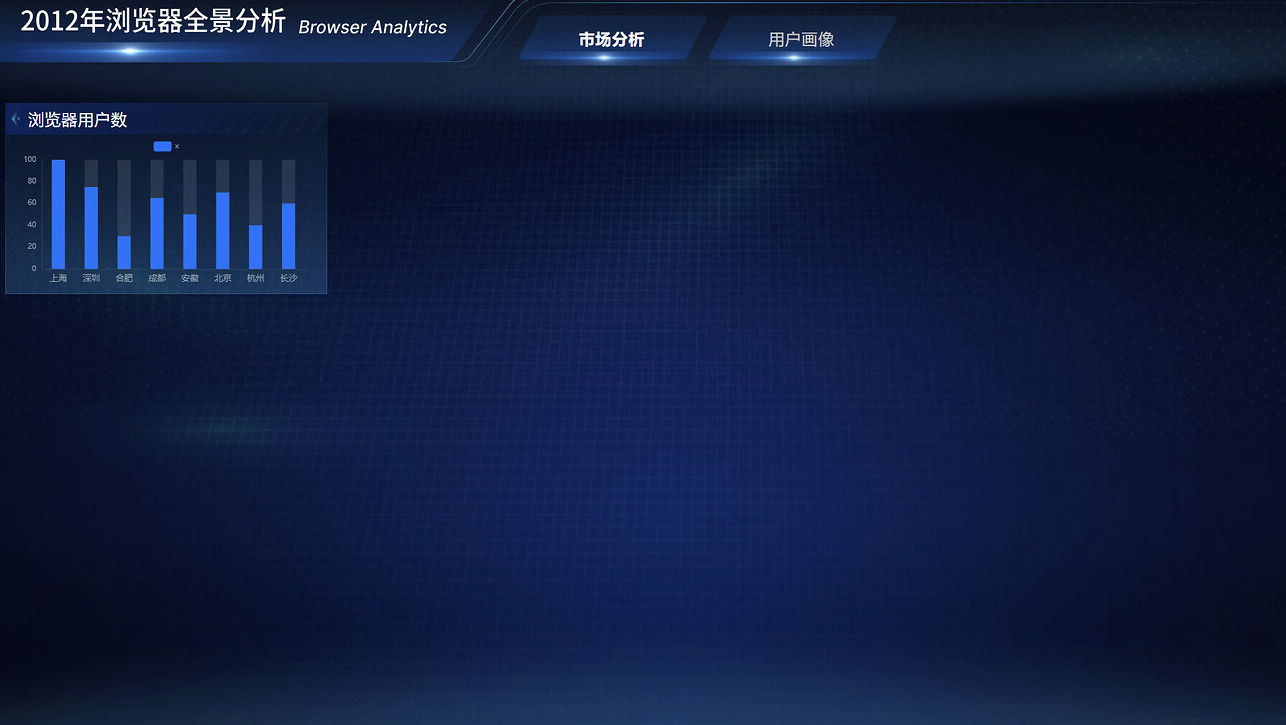
将本小节新增的所有组件打包成组,命名为"浏览器用户数"。
保存后预览效果:
5.3.2 使用规模——浏览器使用时长占比
复制上一小节制作的"浏览器用户数"组,重命名为"浏览器使用时长":
参照布局草图,将"浏览器使用时长"组拖拽到对应位置:
复制后的组件可能不显示内容,刷新数据即可恢复:
将标题文本改为"浏览器使用时长"并刷新数据:
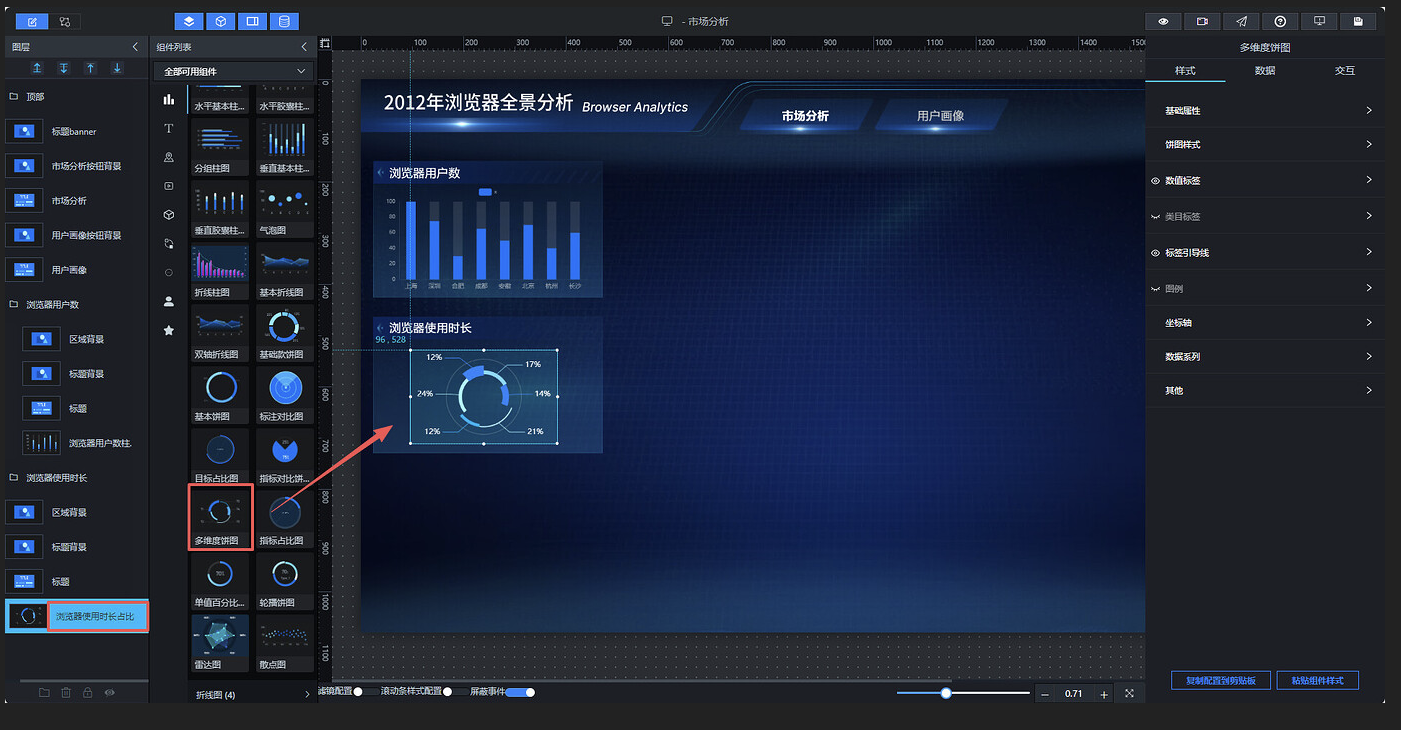
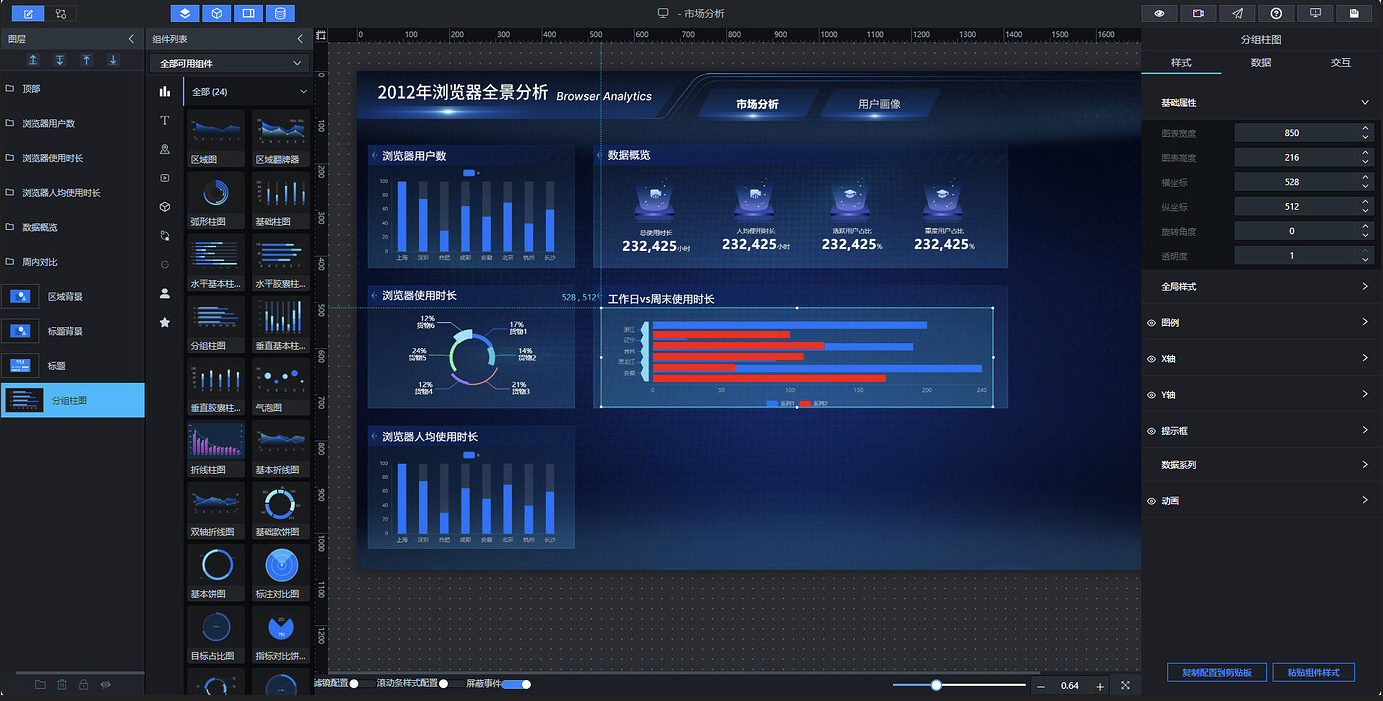
浏览器使用时长占比应使用饼图展示,因此删除复制过来的柱状图,重新添加饼图组件。助睿大屏提供了多种饼图样式可供选择,此处我们选用"多维度饼图",调整好尺寸和位置后重命名为"浏览器使用时长占比":
接下来优化饼图的外观样式。取消外圈的显示效果:点开"饼图样式",点击外圈颜色后面的色值方块,将透明度滑块拖至 0,然后点击"确定":
将标签类目设置为可见状态:
下一步为各浏览器设定饼图中的颜色。展开"数据系列",每个系列对应一个分类(即一款浏览器),数据中共有 6 款浏览器,为系列 1~6 分别设定不同颜色,参考色值:
#2177FC、#3DC3DF、#FF948B、#8A79FE、#82F9A5、#97DFFF
将饼图组件拖入"浏览器使用时长"组中,及时保存。
5.3.3 使用粘性——浏览器人均使用时长
复制 5.3.1 小节的"浏览器用户数"组,重命名为"浏览器人均使用时长":
参照布局草图拖拽到相应位置:
刷新数据使组件内容正常显示:
将标题文本修改为"浏览器人均使用时长"并刷新数据:
人均使用时长的图表类型同样为柱状图,因此无需更换图表类型,直接将复制的柱状图重命名为"人均使用时长柱状图"即可。
5.3.4 指标区
复制 5.3.1 小节的"浏览器用户数"组,重命名为"数据概览":
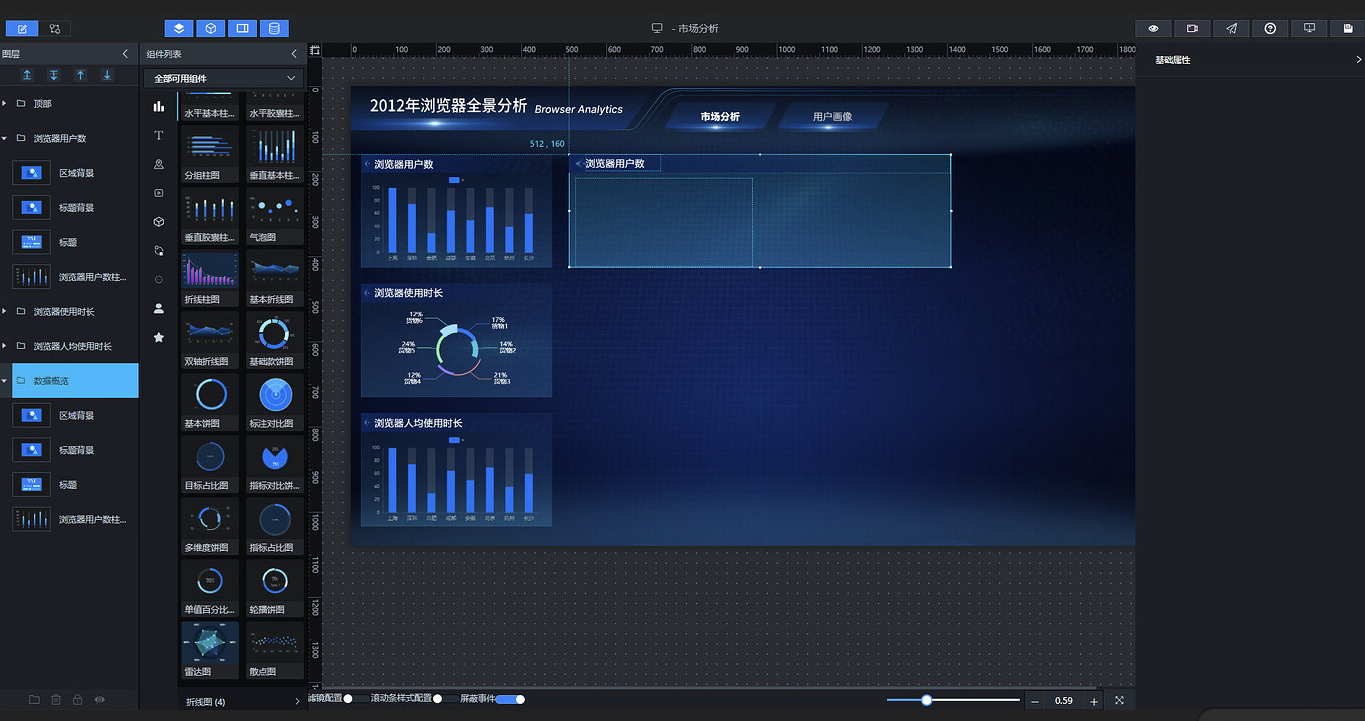
参照布局草图拖拽到相应位置,调整组件尺寸并刷新数据:
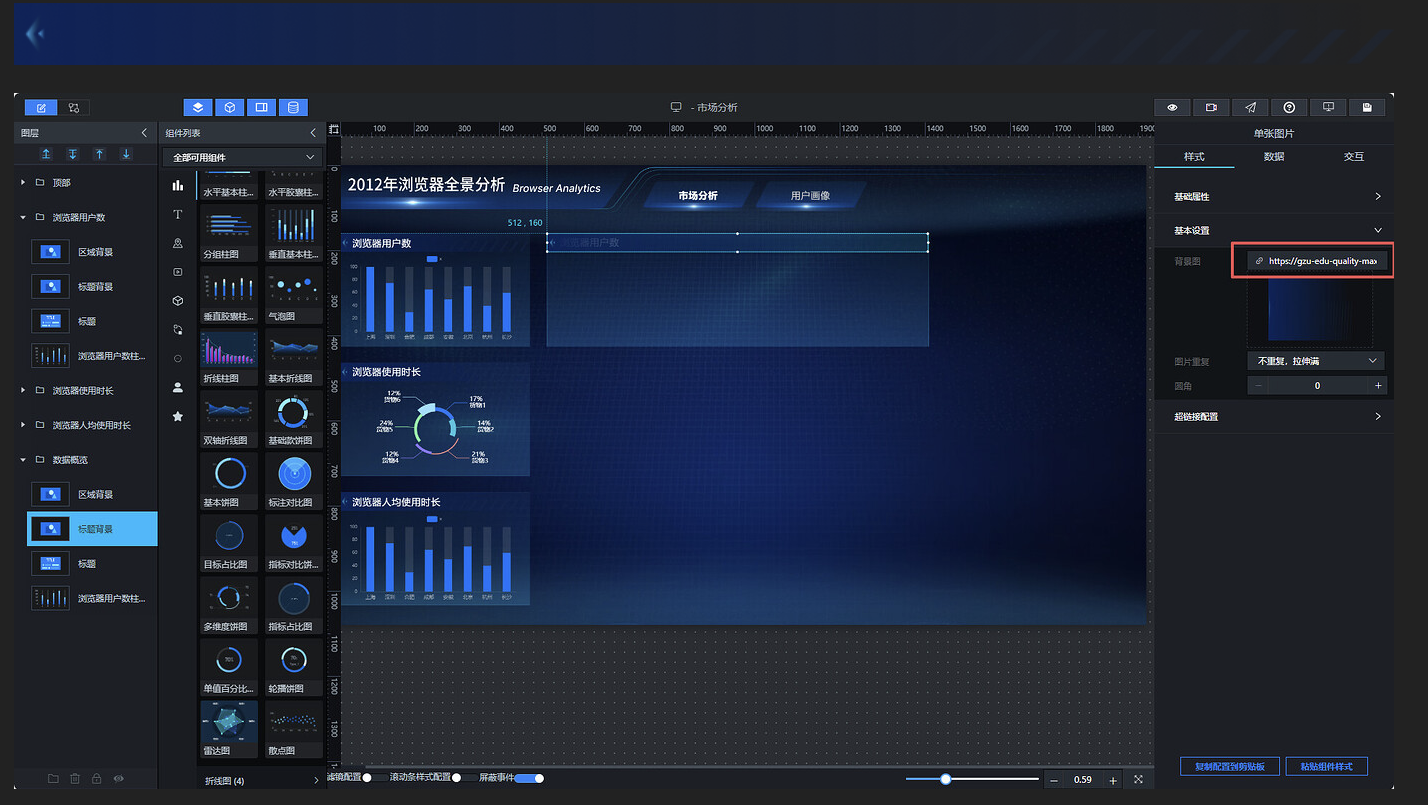
可以看到标题背景图被拉伸变形了,这是因为当前使用的是短标题背景图,需要替换为长标题背景图:
将标题文本改为"数据概览"并刷新数据:
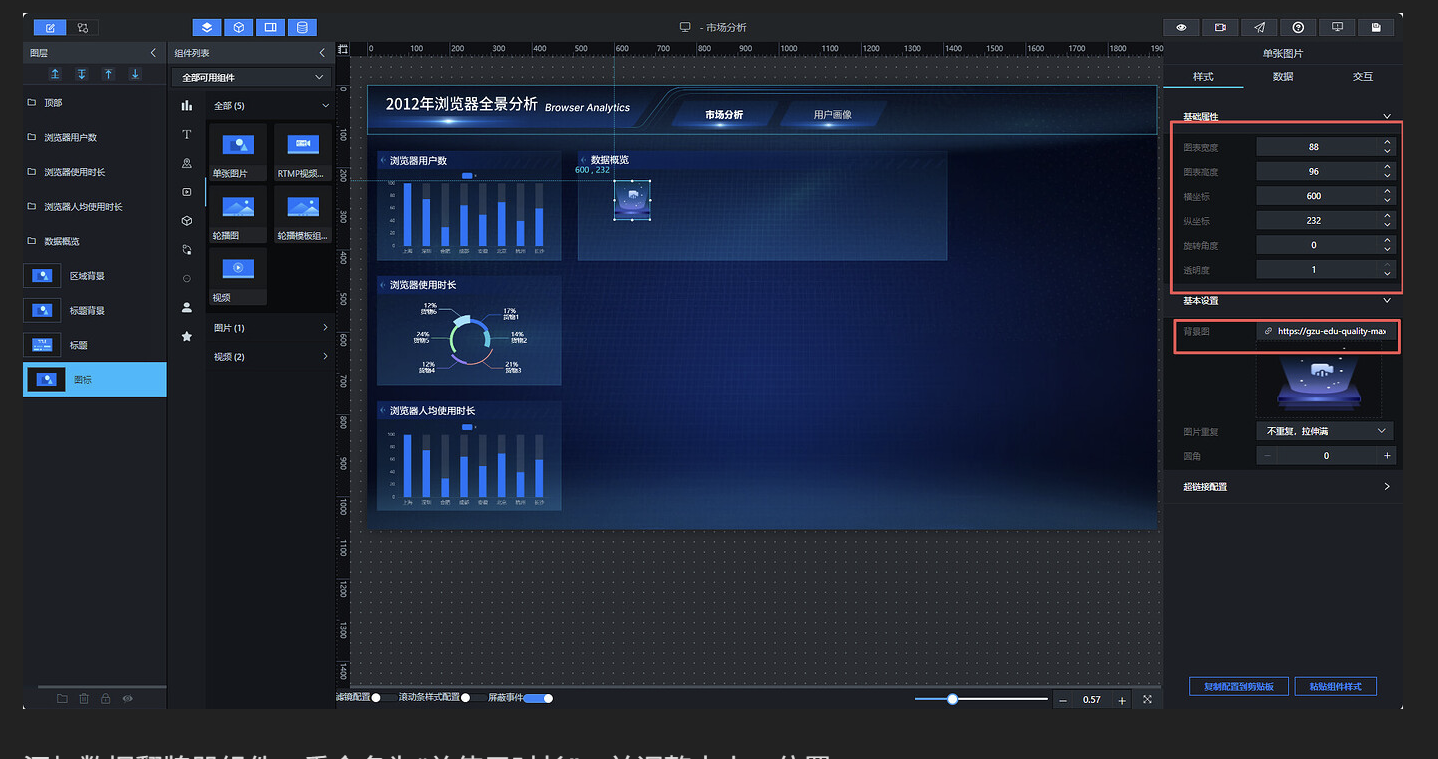
删除复制的柱状图。大屏中的指标卡通过文字类组件实现,我们选用"数据翻牌器"来展示各项指标。为了让单个指标的视觉效果更加丰富,可以搭配一些装饰元素。
首先添加一个"单张图片"组件,重命名为"图标",设置背景图链接:
https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/library-data/audio-video.png
调整尺寸和位置如下:
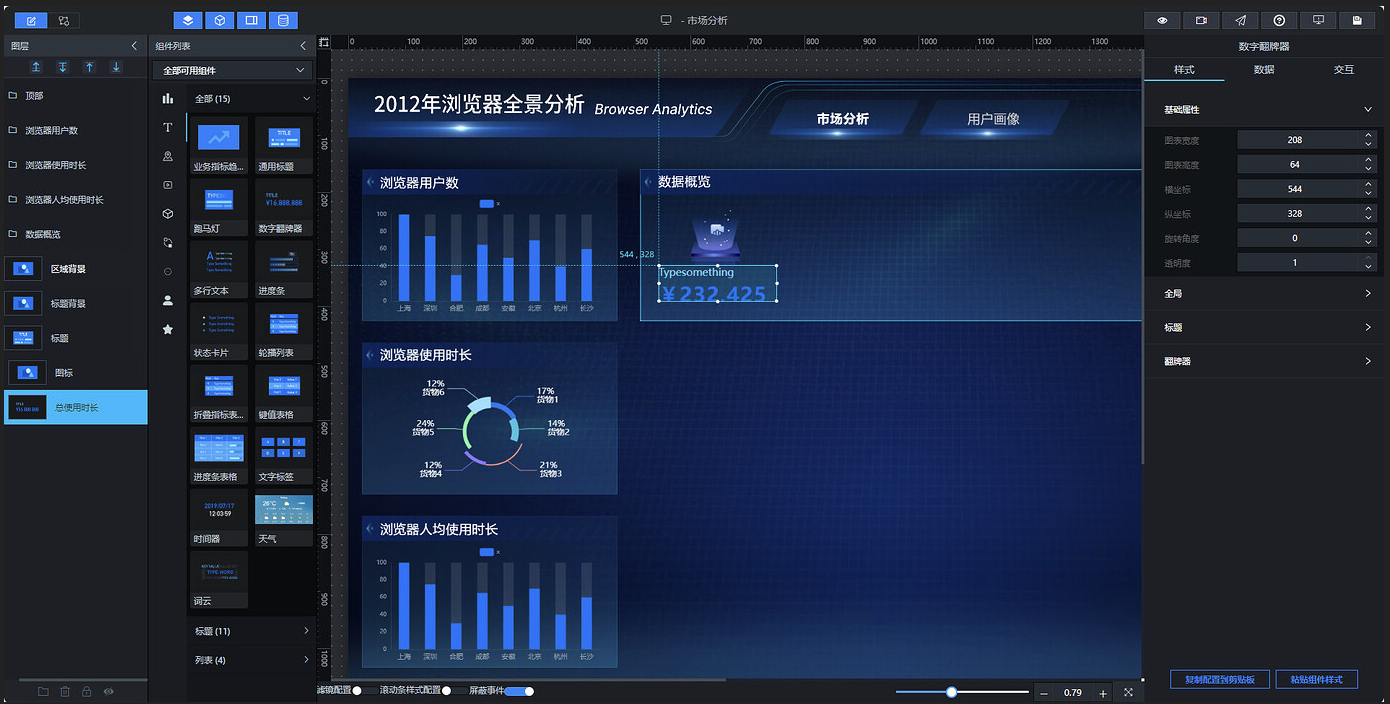
添加"数据翻牌器"组件,重命名为"总使用时长",调整尺寸和位置:
接下来优化翻牌器的显示样式。
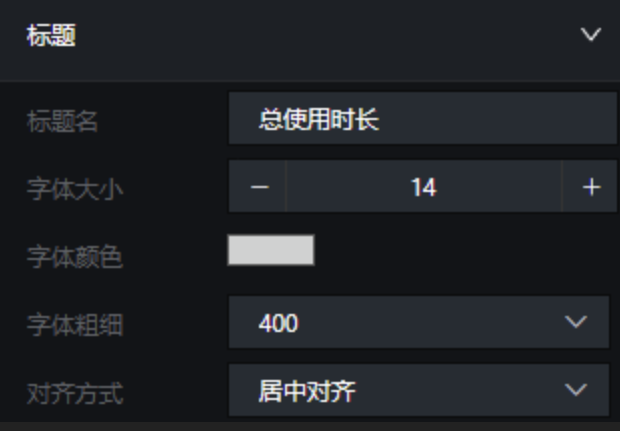
展开"标题"设置,将标题名改为"总使用时长",对齐方式改为"居中对齐",并对字体大小、颜色、粗细做相应调整:
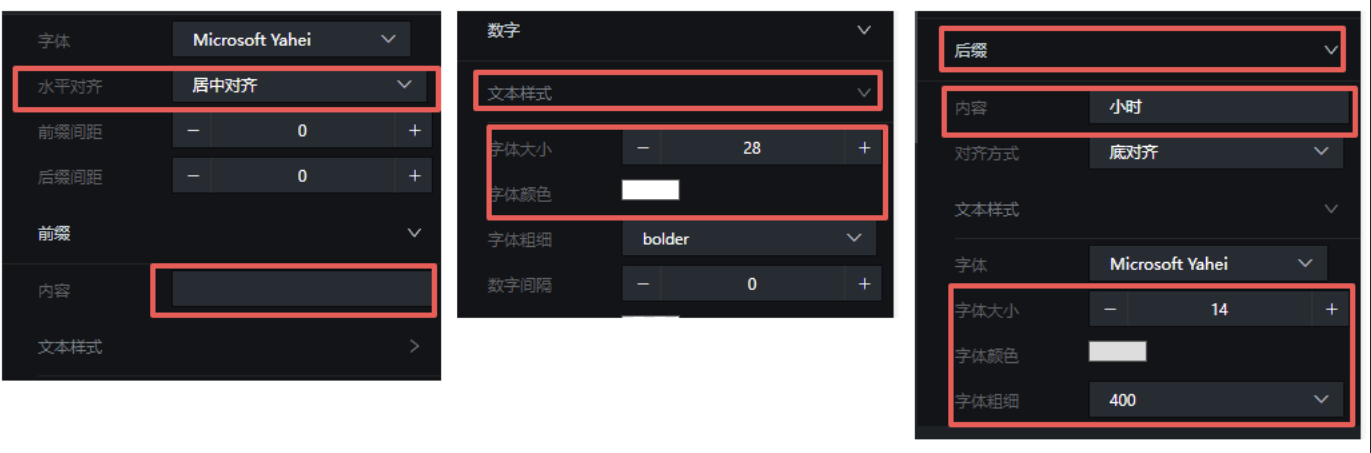
展开"翻牌器"设置,将水平对齐改为"居中对齐",其他配置参考如下:
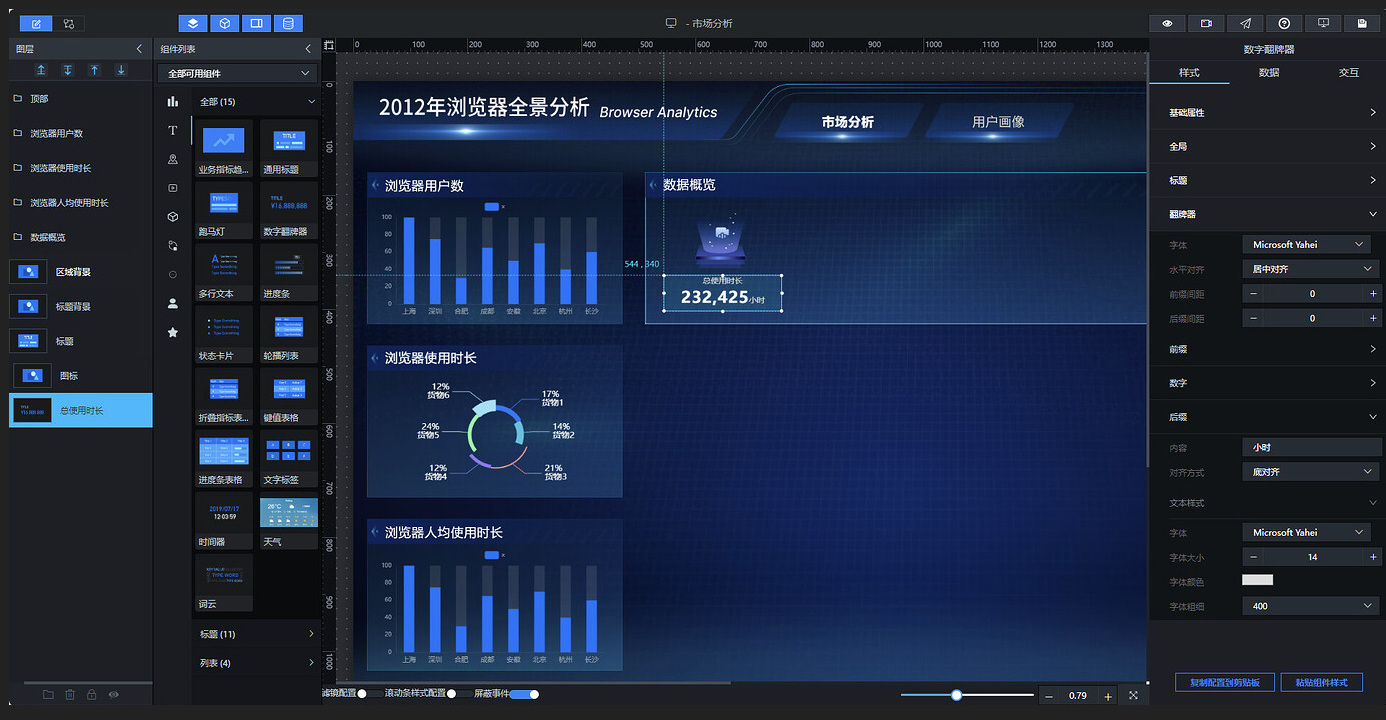
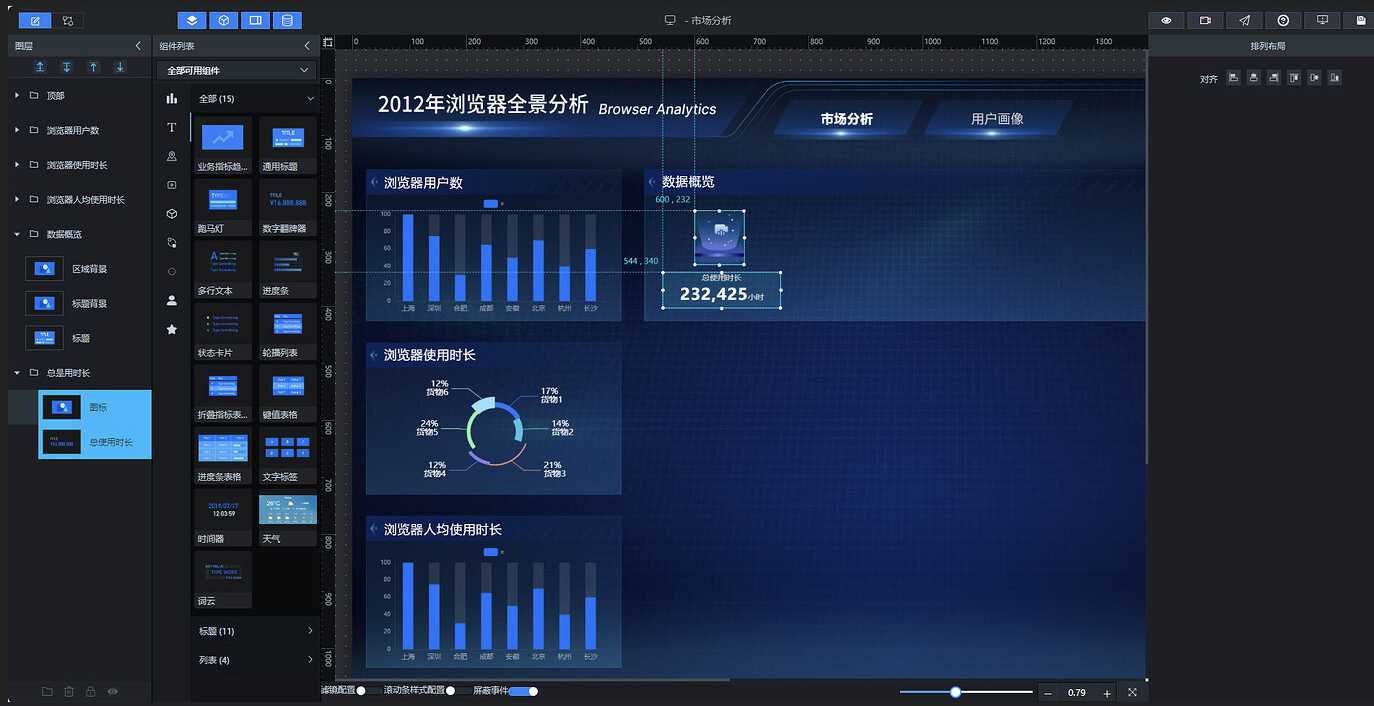
将图标和总使用时长两个组件打包成组,命名为"总使用时长":

复制 3 份"总使用时长"组,分别重命名为"人均使用时长"、“活跃用户占比”、“重度用户占比”。其中"活跃用户占比"和"重度用户占比"两组中的图标背景图链接更换为:
https://gzu-edu-quality-max-studio.oss-cn-chengdu.aliyuncs.com/library-data/degree-thesis.png
修改各翻牌器的标题和后缀,最终调整位置效果如下:
5.3.5 时段偏好——周内对比
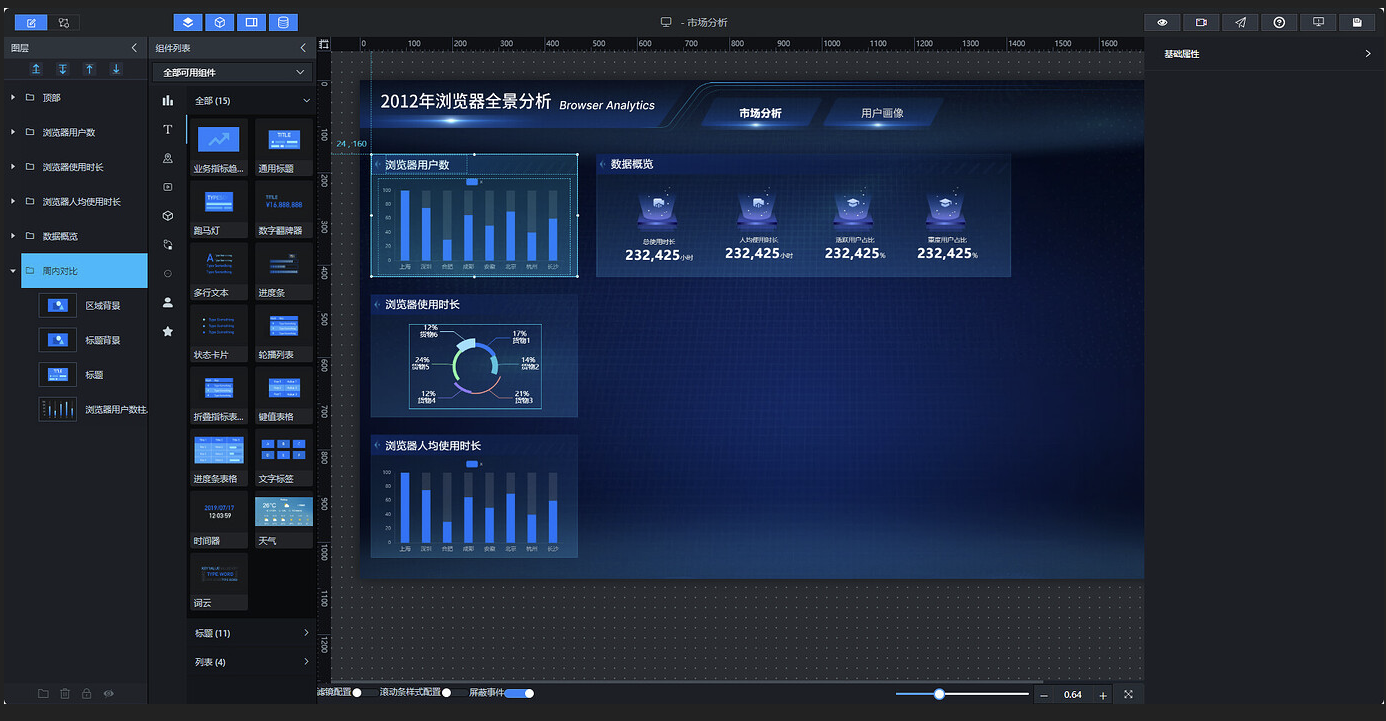
复制 5.3.1 小节的"浏览器用户数"组,重命名为"周内对比":
参照布局草图拖拽到对应位置:
刷新复制组件的数据,将标题背景图替换为长标题背景图,标题内容改为"工作日 vs 周末使用时长":
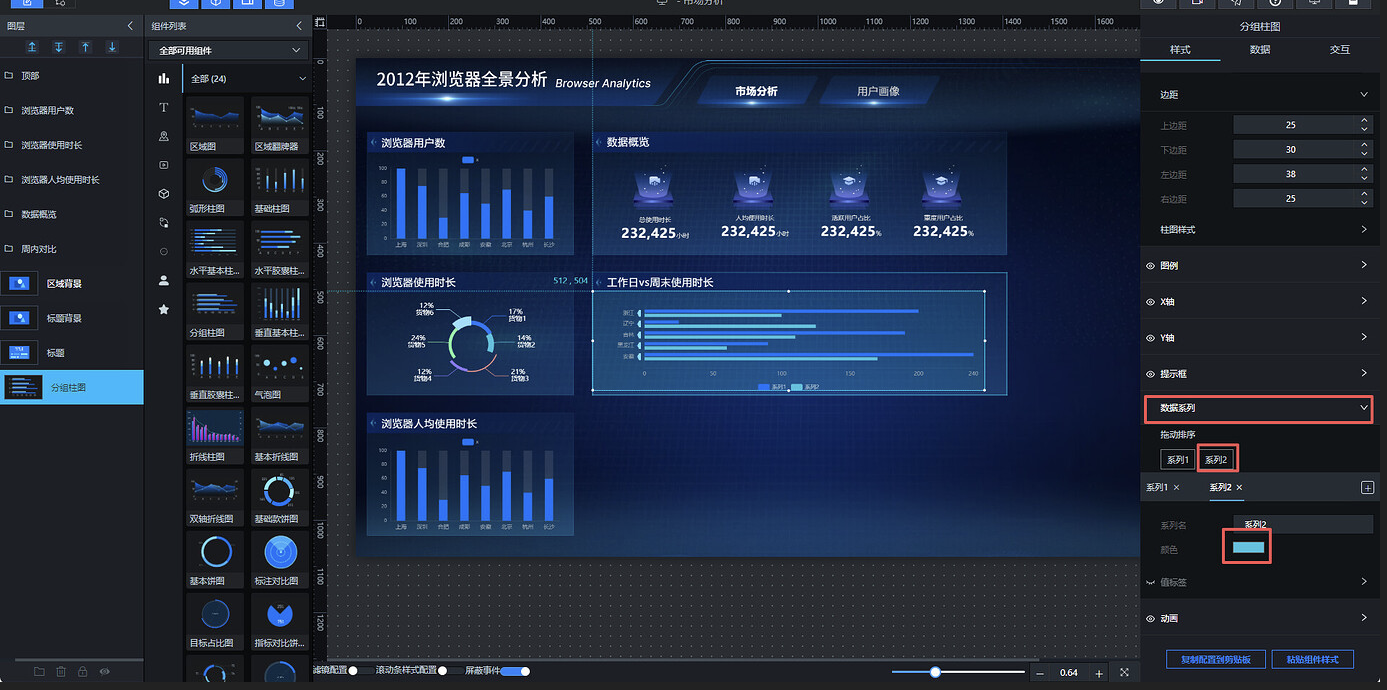
删除柱状图组件,重新添加"分组柱状图",命名为"工作日 vs 周末使用时长分组柱状图",调整尺寸和位置:
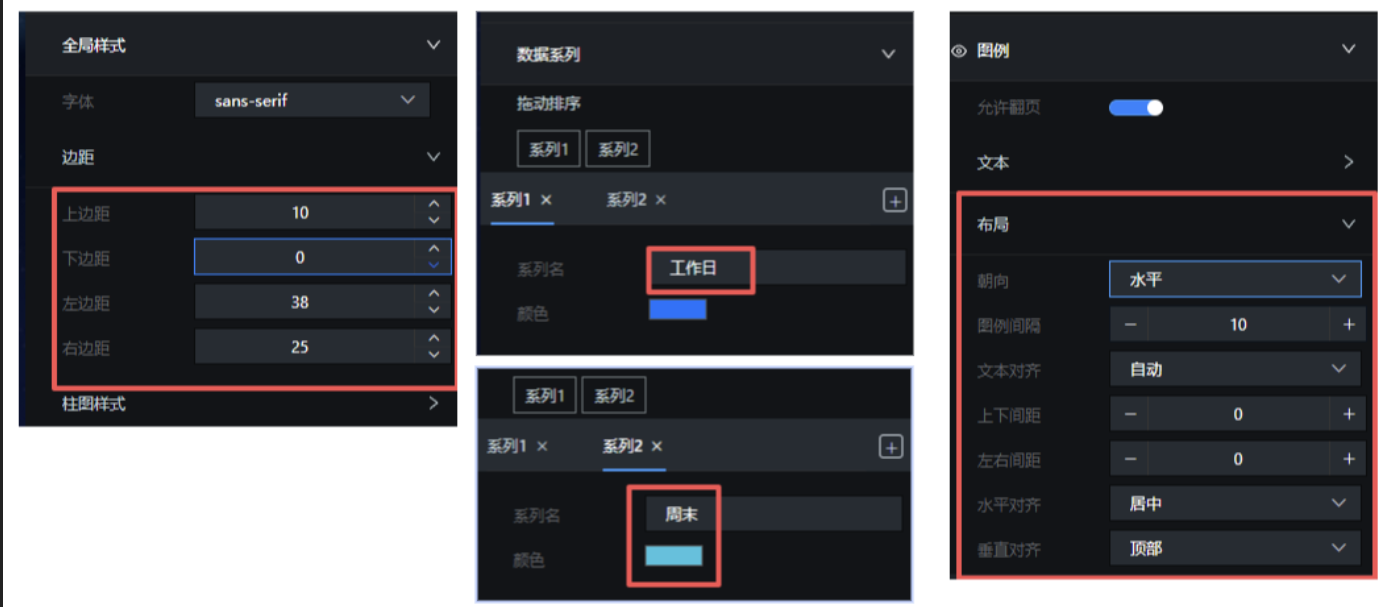
将系列 2 的柱体颜色调整为 #3DC3DF:
其他样式调整可参考如下配置:
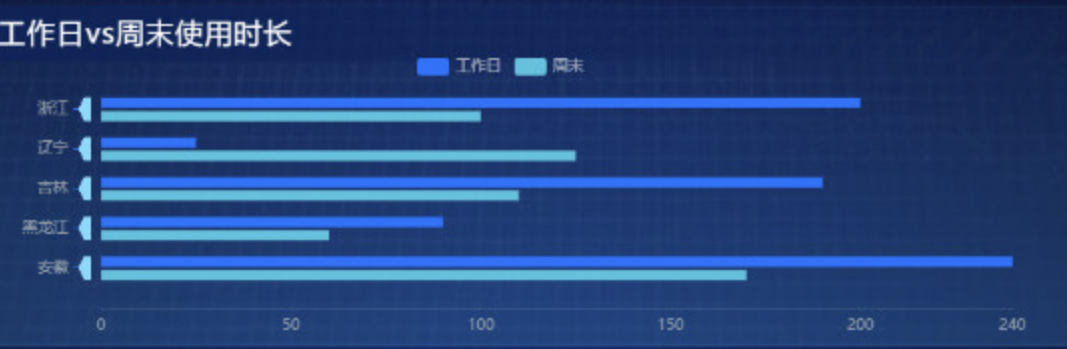
最终效果:
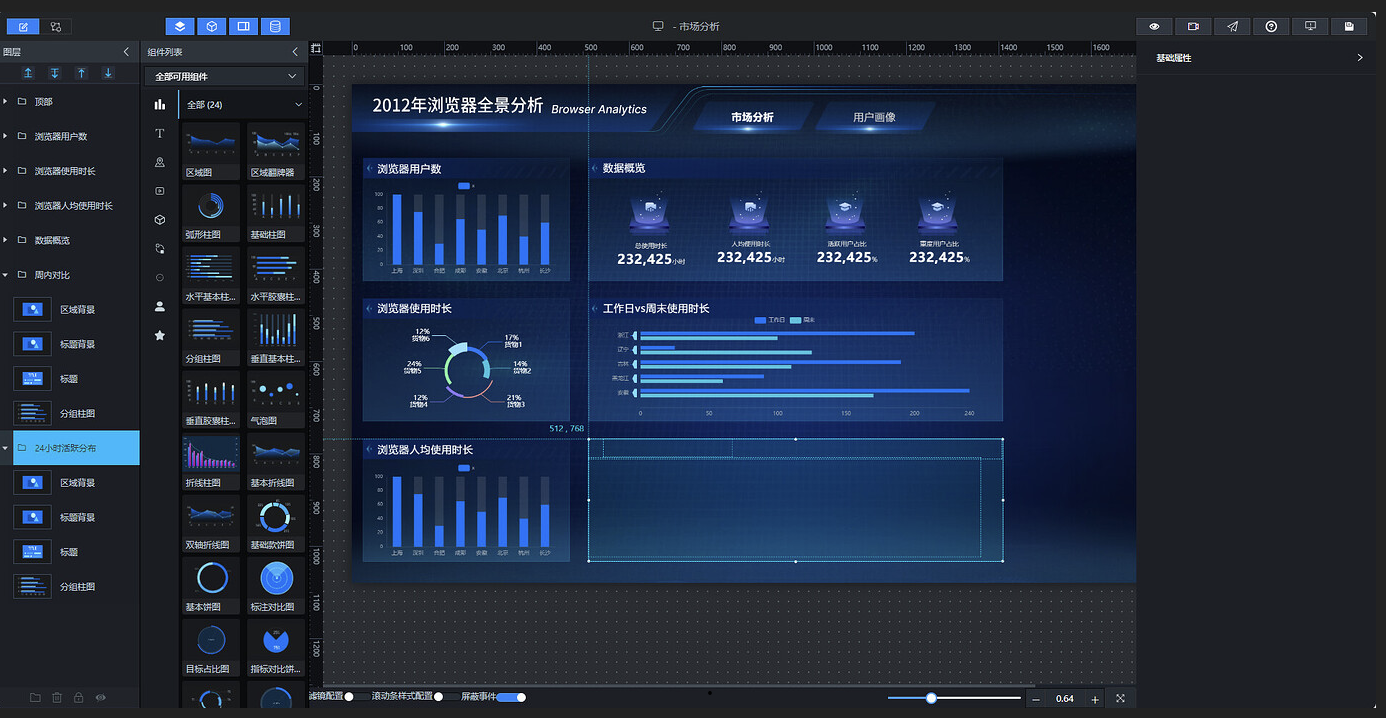
5.3.6 时段偏好——24 小时活跃分布
复制上一小节的"周内对比"组,重命名为"24 小时活跃分布":
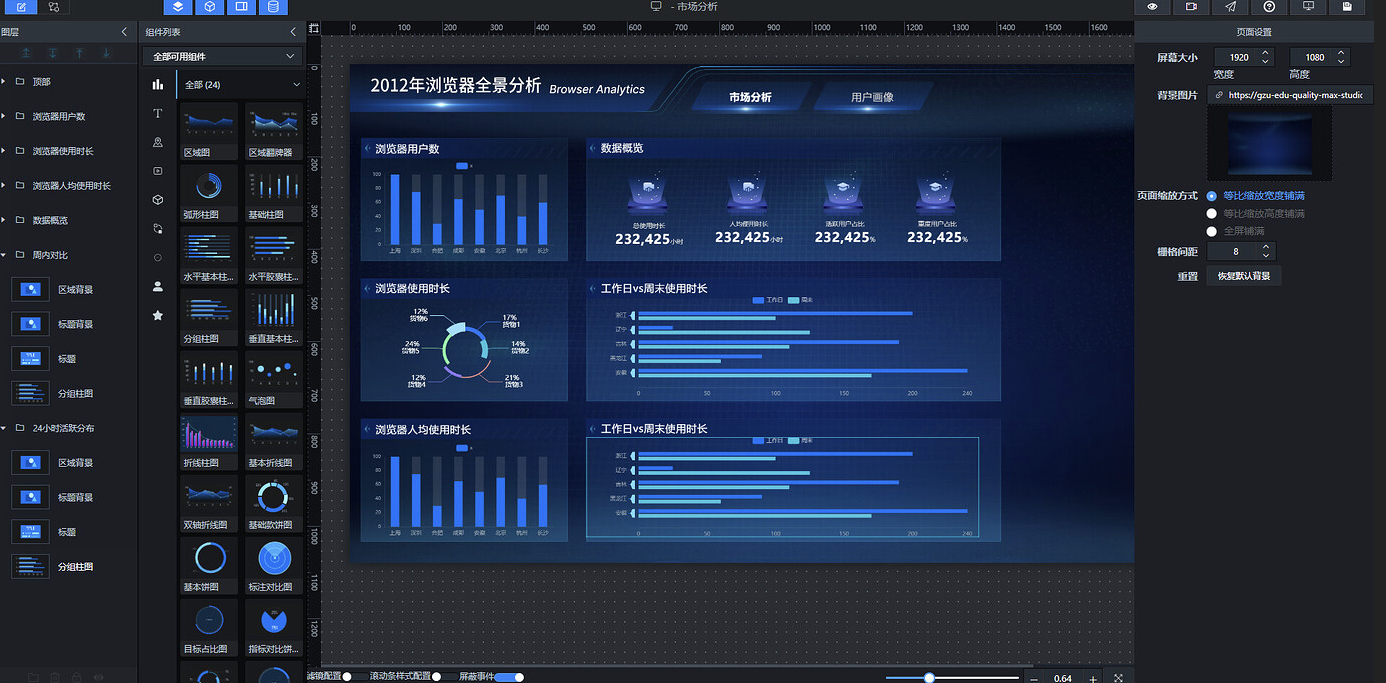
参照布局草图拖拽到对应位置:
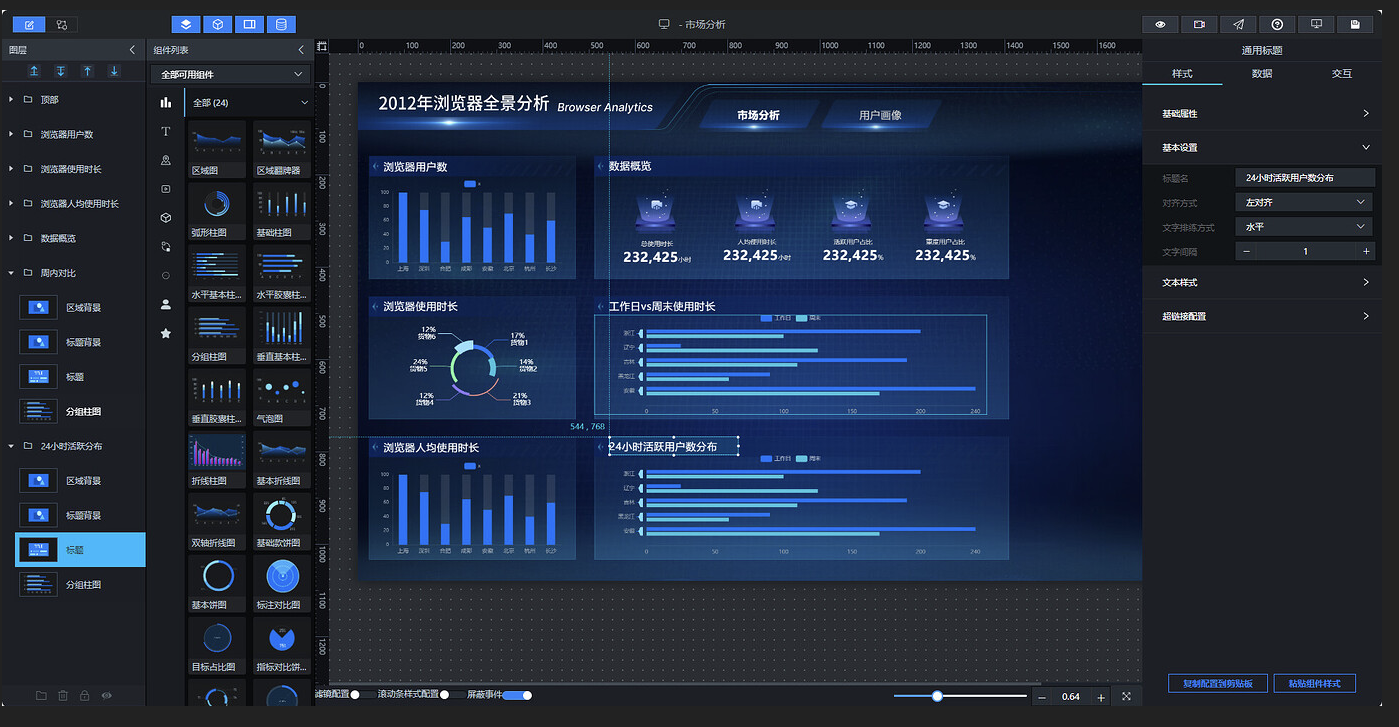
复制后的组件如未正常显示,刷新数据即可:
将标题文本修改为"24 小时活跃用户数分布"并刷新数据:
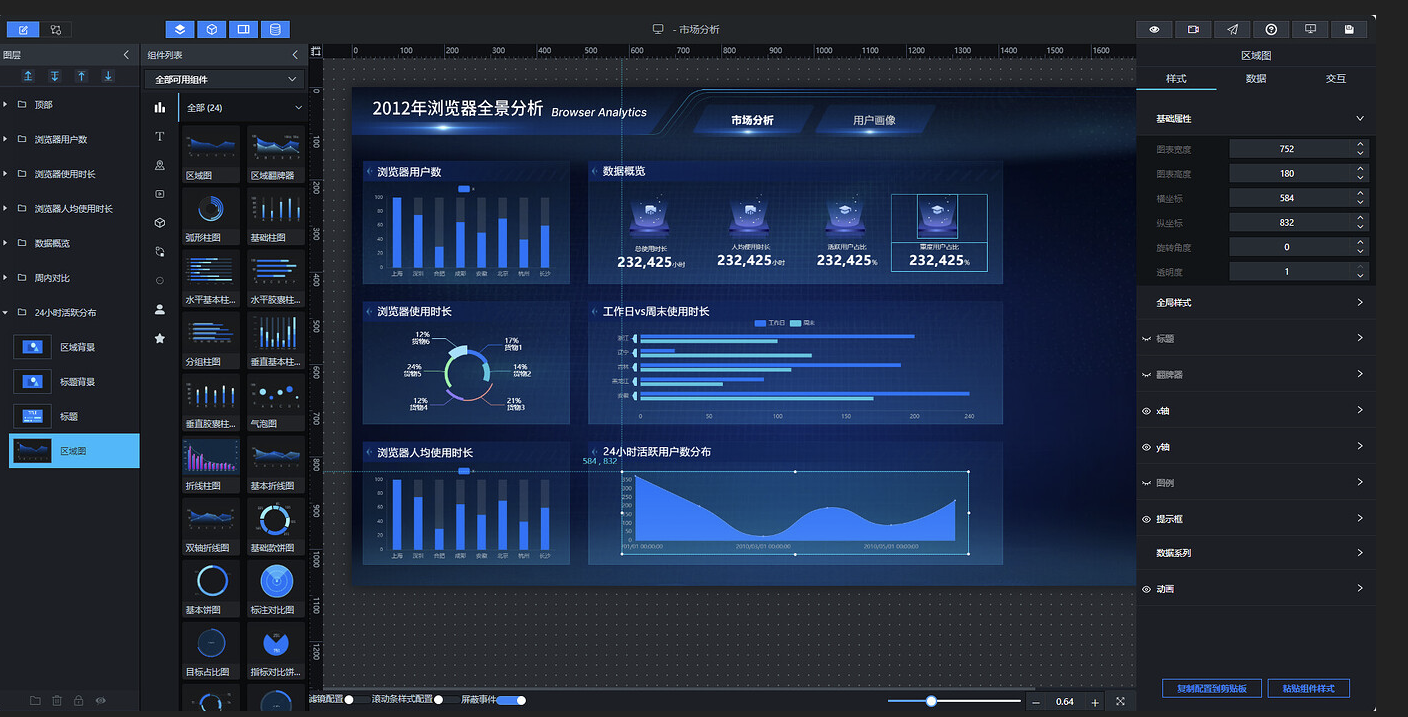
删除复制的分组柱状图,添加"区域图"组件,调整好尺寸和位置:
样式调整参考如下,推荐主色为 #29F1FA:
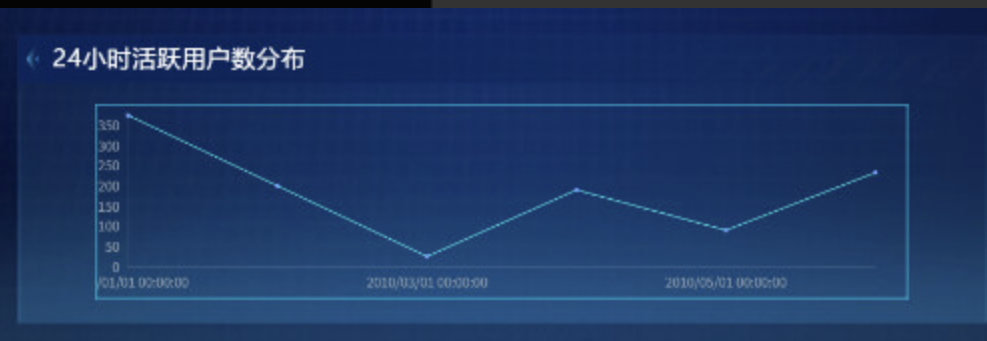
最终效果:
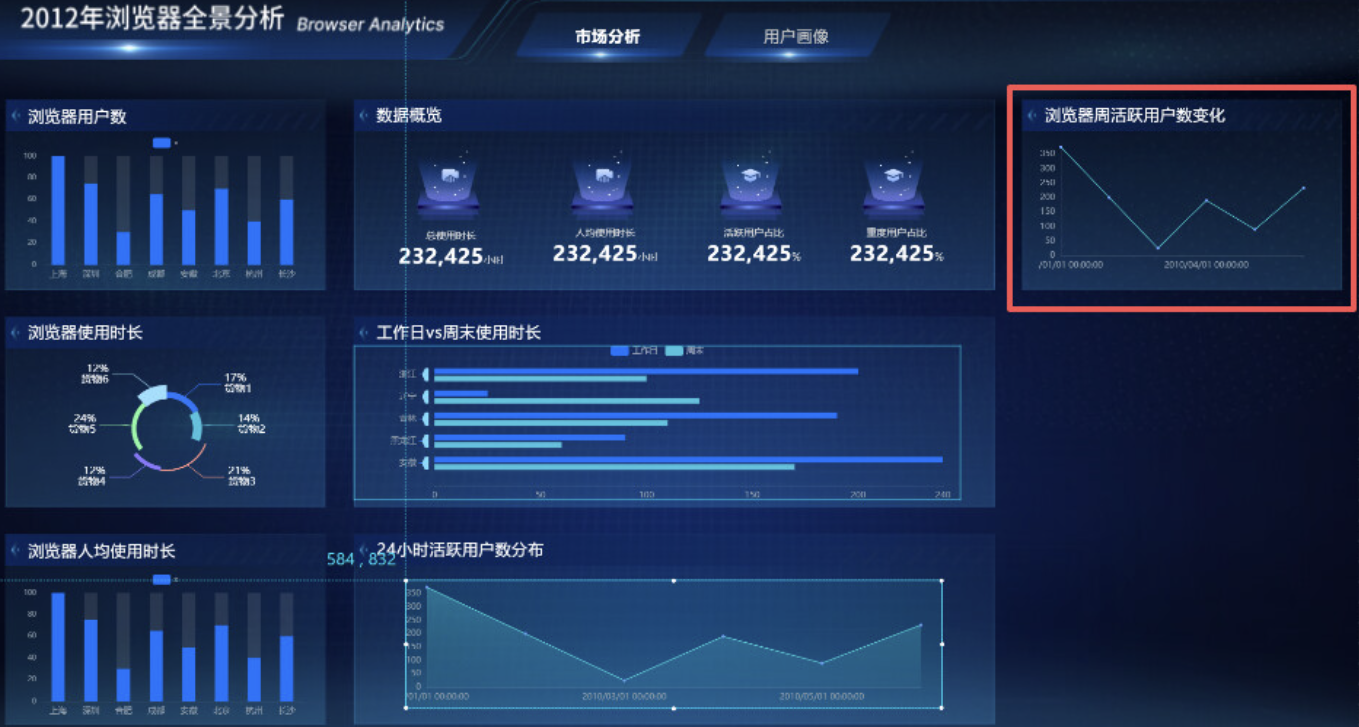
5.3.7 周活跃趋势——浏览器周活跃用户数变化
复制 5.3.1 小节的"浏览器用户数"组,重命名为"浏览器周活跃用户数变化"。参照前述步骤,调整位置、修改标题并更换为合适的图表类型,实现如下效果:
5.3.8 使用习惯——使用频率分布
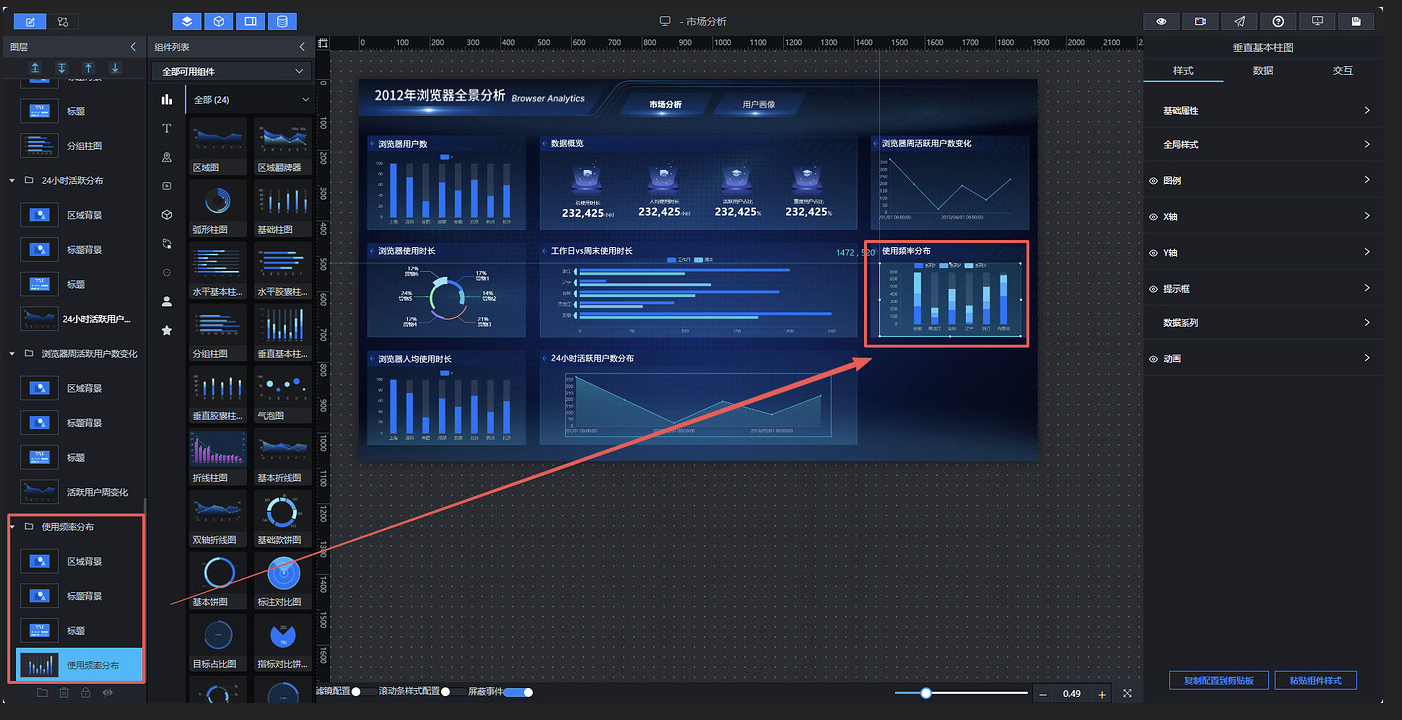
复制上一小节的"浏览器周活跃用户数变化"组,重命名为"使用频率分布"。参照前述步骤,调整位置、修改标题并将图表类型更换为"垂直基本柱图":
5.3.9 竞争关系——浏览器使用数量分布
复制上一小节的"使用频率分布"组,重命名为"浏览器使用数量分布"。参照前述步骤,调整位置、修改标题并将图表类型更换为"基本饼图":
基本饼图的样式调整可参考如下配置:
保存大屏,最终预览效果如下:
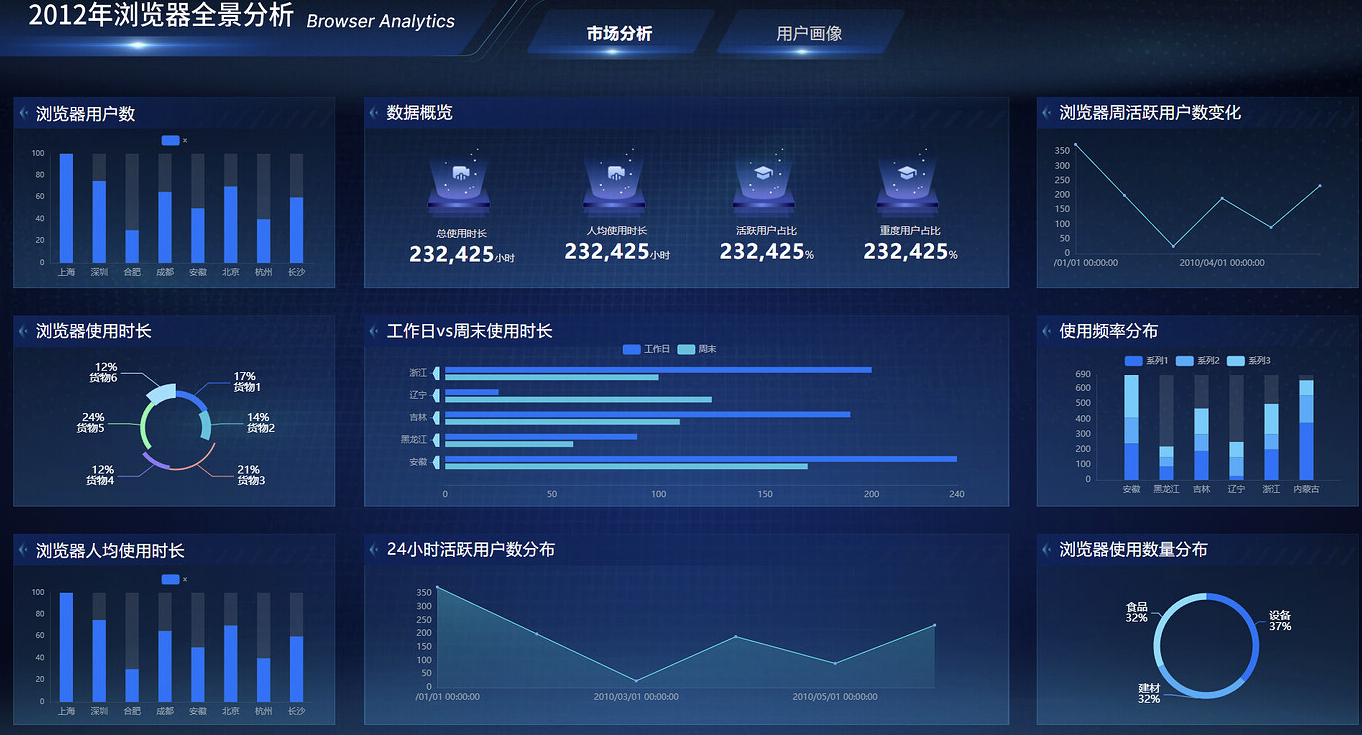
至此,市场分析大屏的静态布局搭建全部完成。在下一个实验中,我们将通过蓝图编辑器完成数据的接入与联动配置。
附录:图片资源链接汇总
【实验5-3】
1 实验目的
本实验在前序实验《浏览器市场分析 - 数据大屏静态布局制作》所搭建的大屏框架之上展开。我们将借助助睿 Max 的蓝图编辑器,把先前已处理完毕的数据表对接到大屏中的各类图表组件,从而让原本静态的图表能够实时呈现真实业务数据。
完成本实验后,学习者应当能够:
- 厘清蓝图编辑器中的几个关键要素(数据源、触发器、动作)的含义
- 独立完成数据库数据源的连接配置
- 针对不同图表组件编写相应的 SQL 查询
- 把查询得到的结果对接并渲染到图表组件上
2 实验环境
实验平台:助睿在线实验平台 https://lab.guilian.cn/
本次实验依托助睿数智(Uniplore)这一一体化数据科学平台开展。该平台以零代码方式贯通了数据接入、ETL 处理、机器学习建模直至可视化呈现的完整链路,既契合数据分析教学,也能胜任企业级数据加工需求。
助睿数智官方网站:Uniplore iDIS-大数据智能全流程服务平台-BI数据可视化工具
可视化工具:助睿 Max(数据大屏)
数据来源:团队私有数据库(MySQL)
3 实验数据
本实验沿用上一实验加工产出的大屏目标表,合计 6 张,明细如下:
| 表名 | 用途 | 关联图表 |
|---|---|---|
| $browser_coverage | $ 浏览器市场覆盖率统计 | 指标卡、柱状图、饼图 |
| $browser_hourly | $ 浏览器时段活跃统计 | 24 小时活跃分布折线图 |
| $browser_weekly_active | $ 各浏览器周活跃趋势 | 周活跃趋势折线图 |
| $browser_frequency_stats | $ 浏览器使用频率分布 | 使用频率堆叠柱状图 |
| $browser_multi_usage | $ 用户浏览器使用数量分布 | 浏览器使用数量饼图 |
| $browser_weekday_weekend | $ 浏览器工作日周末对比 | 工作日 vs 周末分组柱状图 |
4 蓝图编辑器概述
4.1 蓝图编辑器是什么?
蓝图编辑器是助睿 Max 内置的一款可视化编程工具,专门用来配置数据流转与交互逻辑。它以"节点连线"的形式运作,让你能够灵活地组织可视化应用中众多组件之间的协作关系。
蓝图编辑器的主要优势:
- 能够确保交互响应与数据更新的实时同步
- 内置数据请求合并与数据分发能力
- 支持按交互链路进行模块化拆分,使用者无需关注代码的整洁与规范,把精力集中在业务逻辑和交互诉求上即可
4.2 核心概念
| 概念 | 说明 |
|---|---|
| 数据源 | 数据库连接的配置,规定数据从何处获取 |
| 查询 | 即 SQL 语句,规定要取哪些数据 |
| 触发器 | 引发数据加载的事件,例如页面载入、组件点击、定时刷新等 |
| 动作 | 触发器命中后所执行的操作,例如发起查询、刷新图表 |
| 变量 | 在多个查询之间传递参数的载体,例如筛选器当前选中的浏览器名称 |
5 实验步骤
5.1 创建数据库数据源
第一步是建立与团队私有数据库的连接。登录数据大屏平台后,点击"我的数据"。
依次点击"+新建" → “新建数据源”。
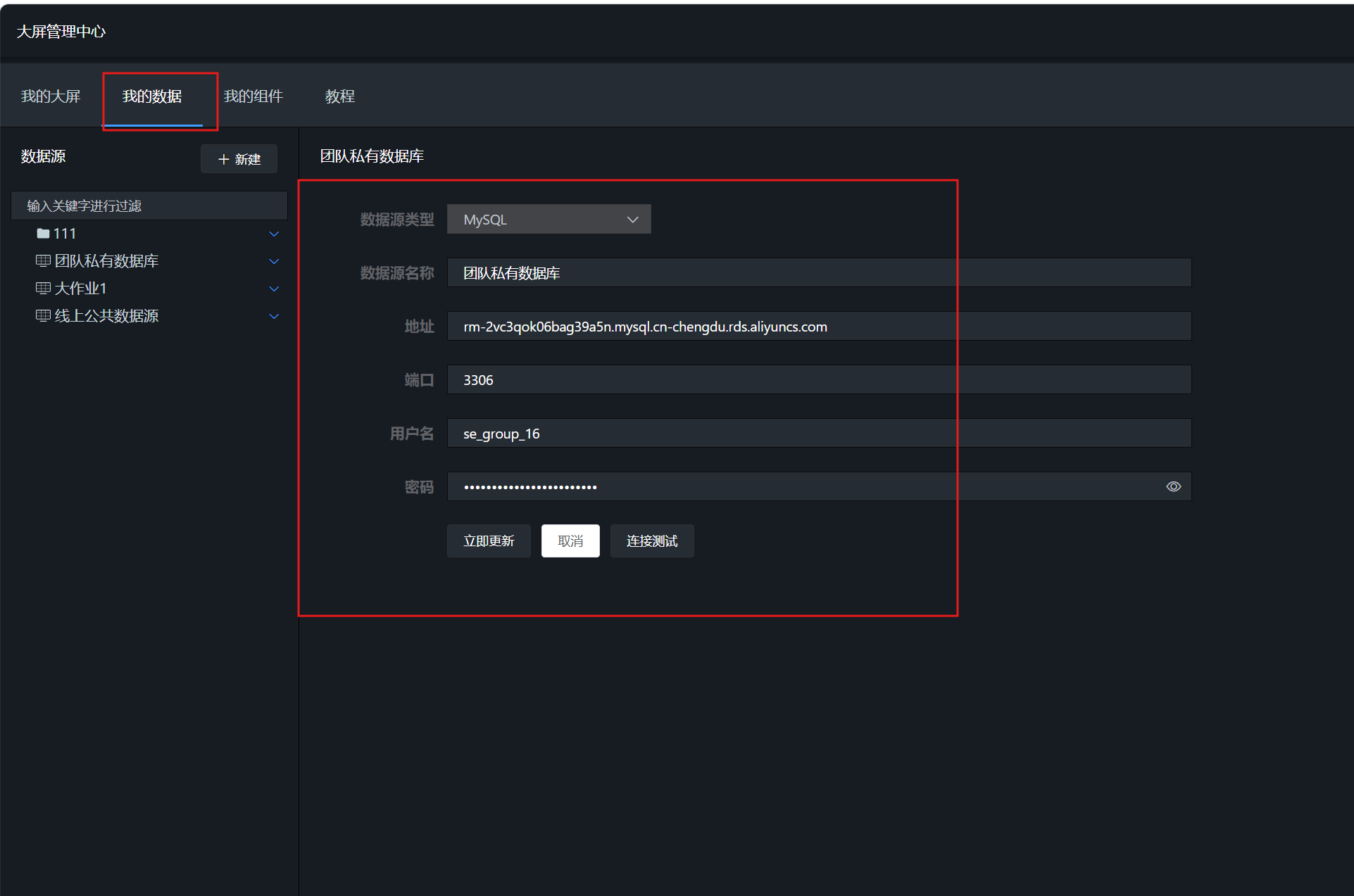
填写团队私有数据库的连接信息,完成后点击"立即添加"。
在标签页之间切换一次再返回"我的数据",便能看到刚刚加入的团队私有数据库。
5.2 将组件导出到蓝图编辑器
需要说明的是,组件只有先被导入蓝图编辑器,才能为其设置交互。
打开上一实验完成的"市场分析"数据大屏。
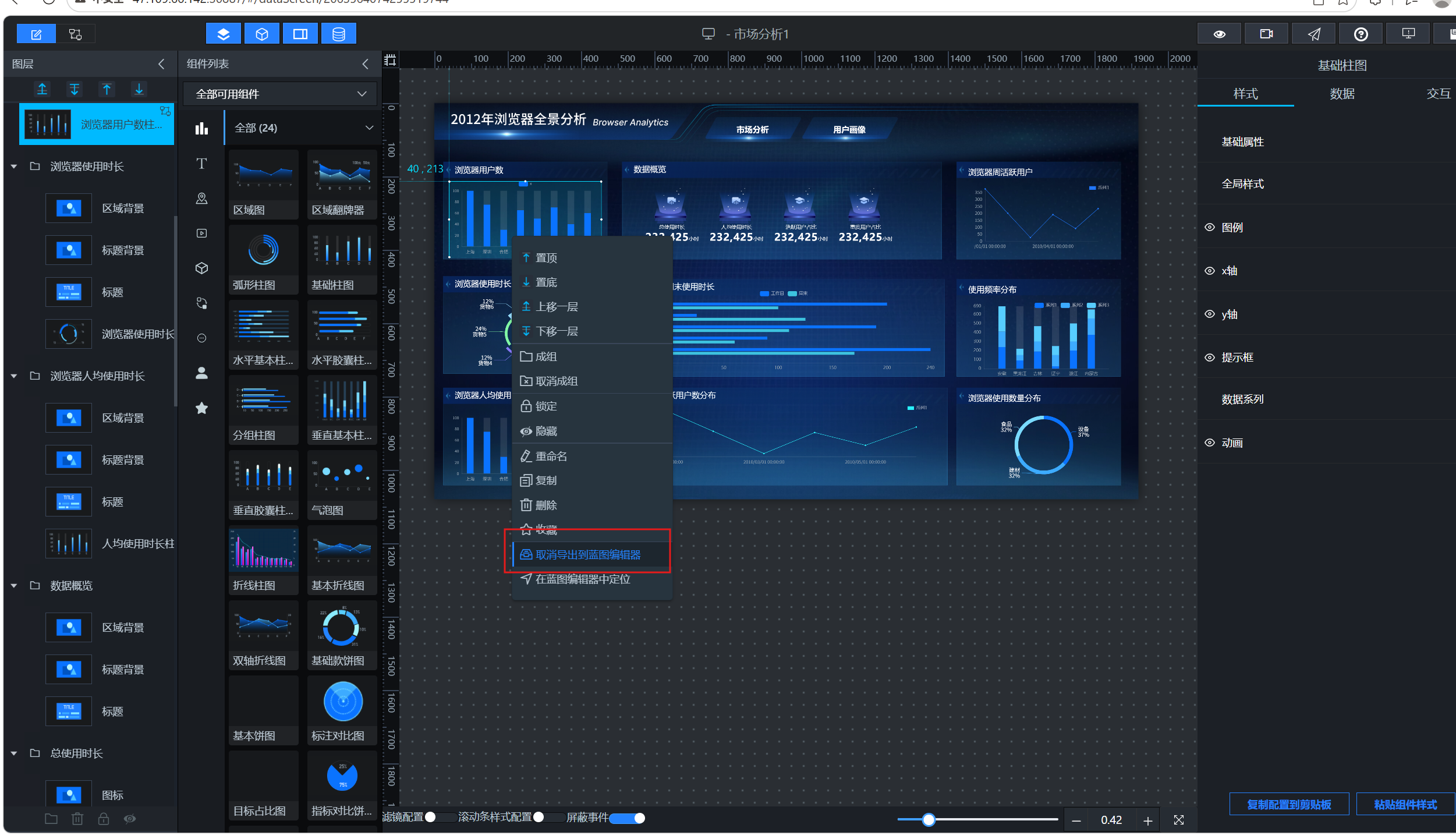
在画布编辑器中,于左侧图层栏或中央画布区域的组件上点击鼠标右键,选择"导出到蓝图编辑器",即可把该组件送入蓝图编辑器。
照此方法,把所有待接入数据的组件逐一导出到蓝图编辑器。
导出完成后,点击"蓝图编辑器"图标进入对应页面,可在导入节点列表中找到这些节点。列表中的每一个节点都可在后续步骤中用于配置交互。
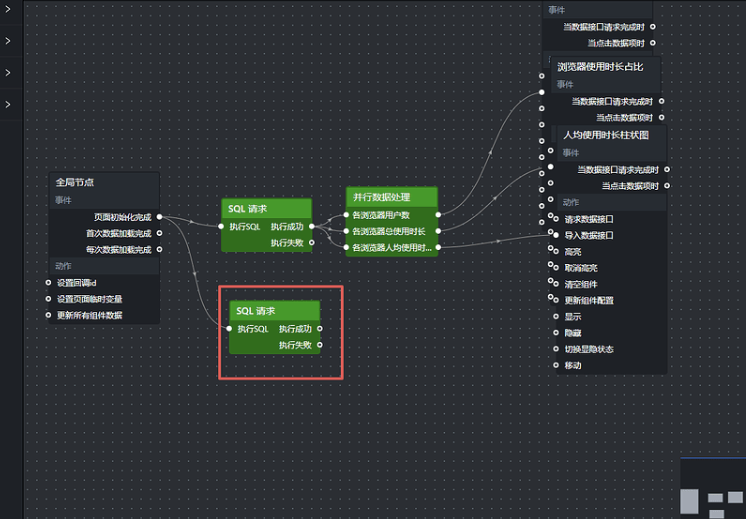
5.3 添加全局节点
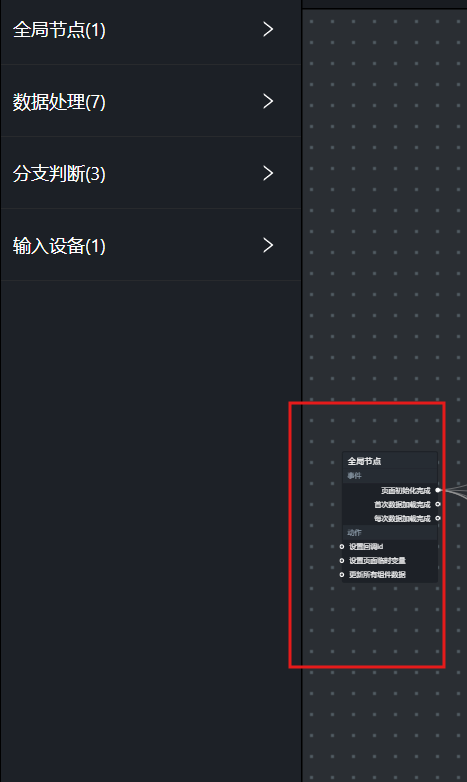
进入蓝图编辑器后,在"逻辑"节点面板中,将所需的逻辑节点点击拖拽至中央画布。逻辑节点涵盖全局节点、数据处理类节点、流程控制类节点以及输入设备类节点等。
先来添加全局节点,画布上会自动出现 1 个全局节点。该节点的作用是在大屏打开时自动执行随后的动作(例如加载数据)。
5.4 为市场格局区的 3 个图表配置数据
5.4.1 添加 SQL 请求节点
在逻辑节点面板中点击"SQL 请求"节点,并把全局节点的"页面初始化完成"输出接口连接到"SQL 请求"节点的"执行 SQL"输入接口。
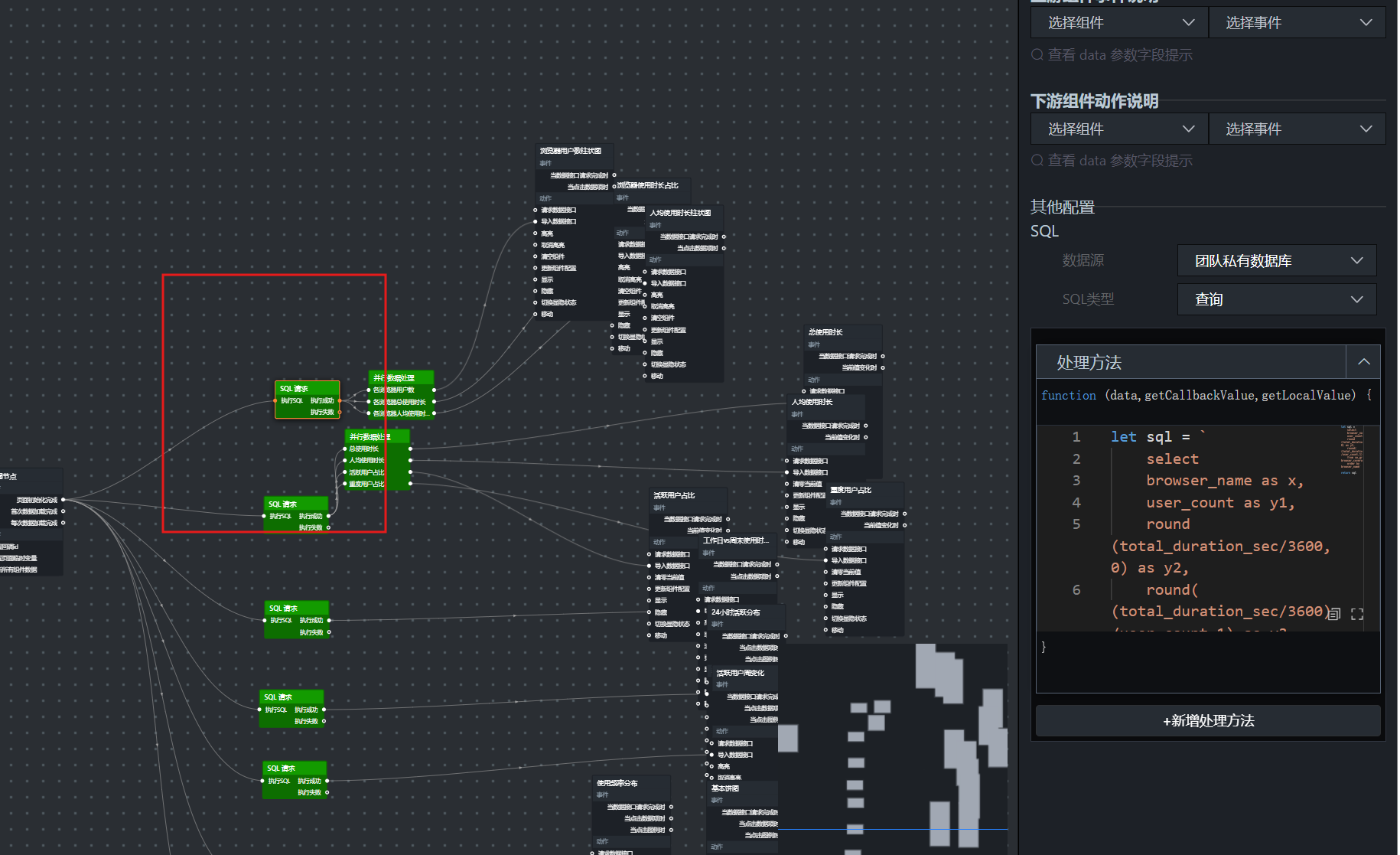
选中"SQL 请求"节点,在配置面板里把数据源设为"团队私有数据库",SQL 类型选"查询",并在处理方法的代码框中填入下列 SQL,一次性取出 表的数据:
let sql = `
select
browser_name as x,
user_count as y1,
round(total_duration_sec/3600,0) as y2,
round((total_duration_sec/3600)/user_count,1) as y3
from labs.browser_coverage
order by browser_name`
return sql
5.4.2 并行数据处理
在蓝图编辑器里,可以利用并行数据处理节点把同一条 SQL 查询的结果分流给多个图表,每个图表各取所需字段。具体做法如下:
加入并行数据处理组件,并在其处理方法中再补充 2 个,使其总数达到 3 个,依次命名为:各浏览器用户数、各浏览器总使用时长、各浏览器人均使用时长。
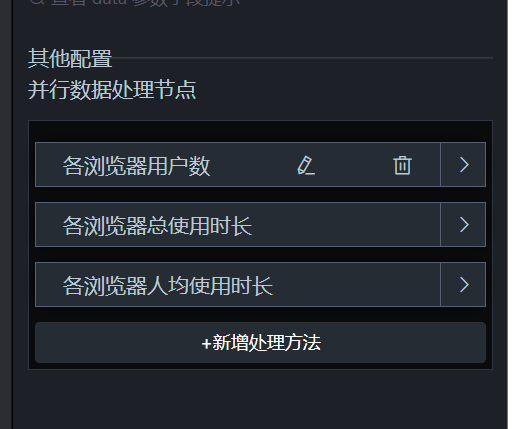
把 SQL 请求节点的"执行成功"输出接口分别连到并行数据处理的这 3 个处理方法接口,如下所示:
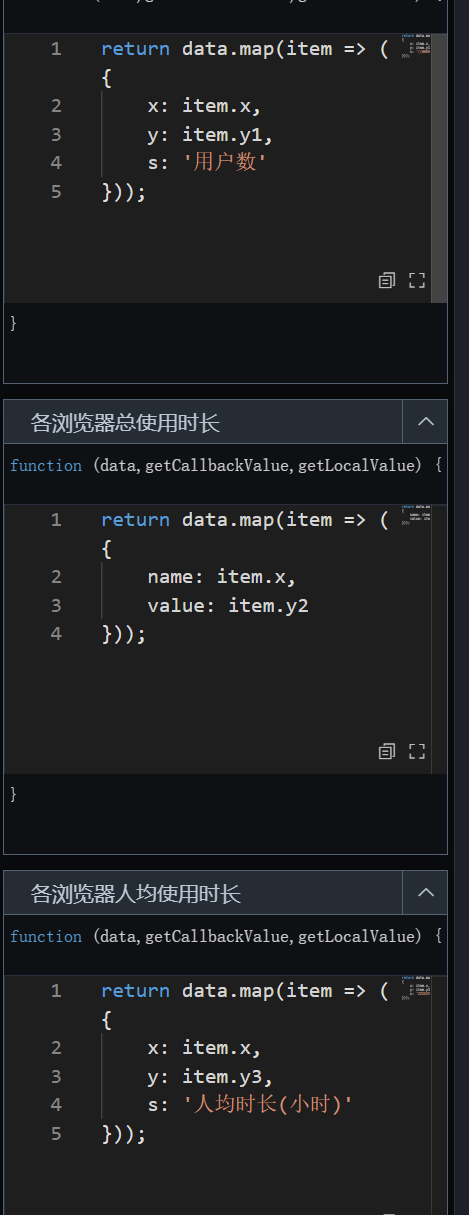
接着,按各图表的数据接口映射规则对查询结果进行加工。在画布编辑器中选中某图表,即可在"数据"标签页查看其数据接口映射:
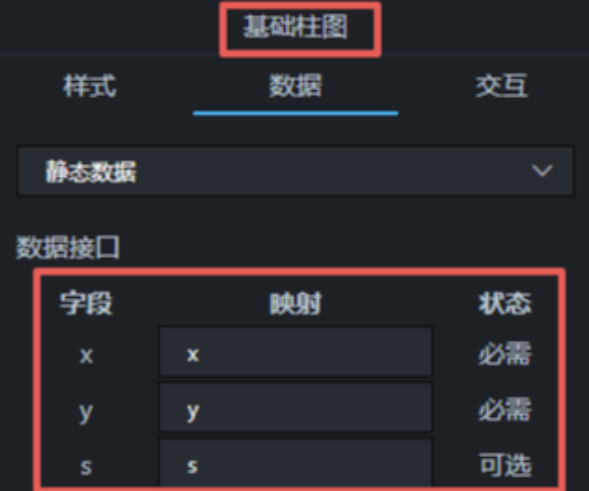
依据查询结果,三个图表各自需要的字段为:
- 浏览器用户数柱状图:x(浏览器名称)、y1(用户数)
- 浏览器使用时长占比:name(浏览器名称)、value(使用时长)
- 人均使用时长柱状图:x(浏览器名称)、y3(人均时长)
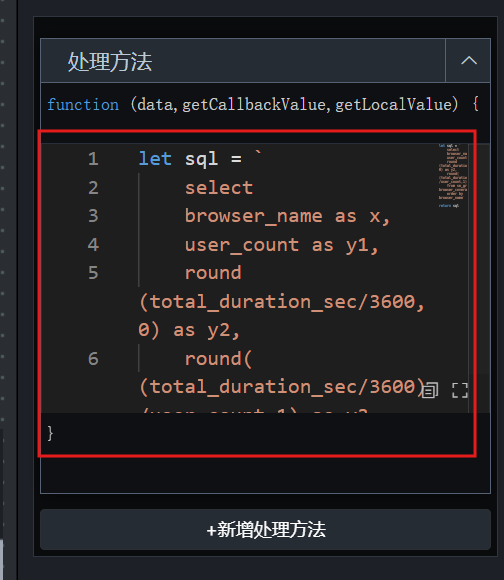
由此,并行数据处理 3 个处理方法的代码如下,分别粘贴进各自的代码块即可:
各浏览器用户数
return data.map(item => ({
x: item.x,
y: item.y1,
s: '用户数'
}));
各浏览器总使用时长
return data.map(item => ({
name: item.x,
value: item.y2
}));
各浏览器人均使用时长
return data.map(item => ({
x: item.x,
y: item.y3,
s: '人均时长 (小时)'
}));
5.4.3 添加图表节点
依次点击浏览器用户数柱状图、浏览器使用时长占比、人均使用时长柱状图这 3 个节点,将它们放入画布,再把并行数据处理 3 个处理方法的输出接口对应连接到各图表的"导入数据接口",如下:
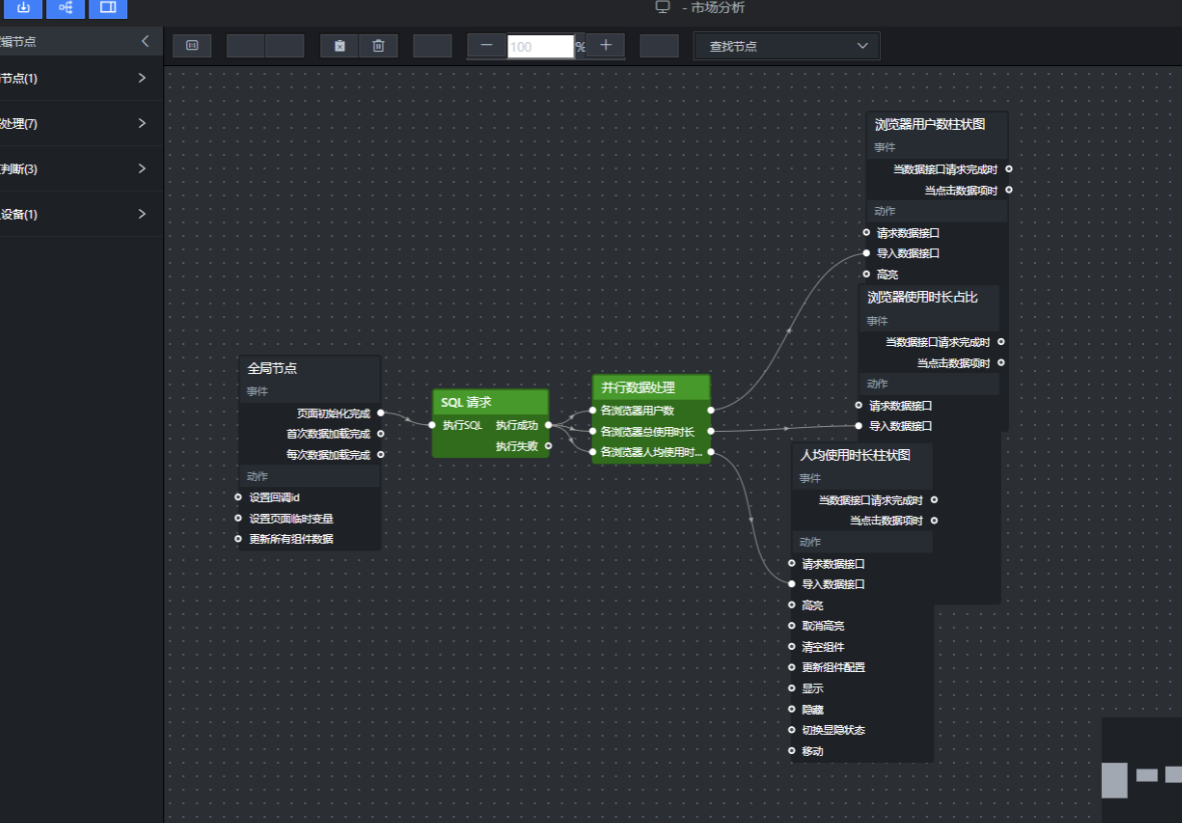
点击保存,预览一下数据是否如预期那样呈现。
可以看到,图表已替换为数据库中的真实数据。
若预览时出现下图所示情况:
可参照以下方式进行配置:
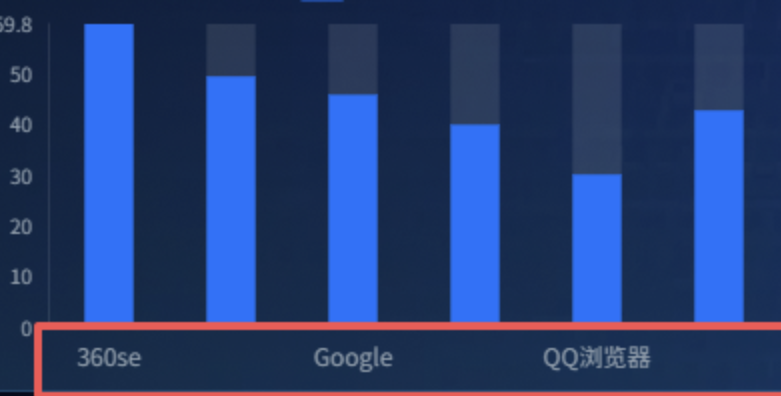
饼图样式也可稍作优化,使整体更为协调。在画布编辑器中选中浏览器使用时长占比饼图,在数据系列里调整各系列的内、外半径,达到类似下方的效果:
5.5 为指标区域图表配置数据
5.5.1 添加 SQL 请求节点
在逻辑节点面板中点击"SQL 请求"节点,并把全局节点的"页面初始化完成"输出接口连接到"SQL 请求"节点的"执行 SQL"输入接口。
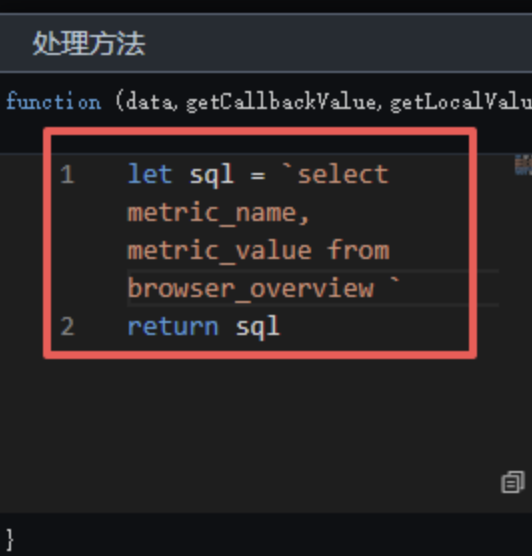
选中"SQL 请求"节点,在配置面板中将数据源设为"团队私有数据库",SQL 类型选"查询",并在处理方法的代码框中输入以下 SQL,一次性取出 表的数据:
let sql = `select metric_name, metric_value from labs.browser_overview `
return sql
该查询会返回一个数组,结构如下:
$${"metric_name": "总使用时长", "metric_value": 456800.00},
{"metric_name": "人均使用时长", "metric_value": 8.20},
{"metric_name": "活跃用户占比", "metric_value": 71.30},
{"metric_name": "重度用户占比", "metric_value": 23.50}$$
5.5.2 并行数据处理
加入并行数据处理组件,并在其处理方法中再补充 3 个,使总数达到 4 个,依次命名为:总使用时长、人均使用时长、活跃用户占比、重度用户占比。
把 SQL 请求节点的"执行成功"输出接口分别连到并行数据处理的这 4 个处理方法接口,如下所示:
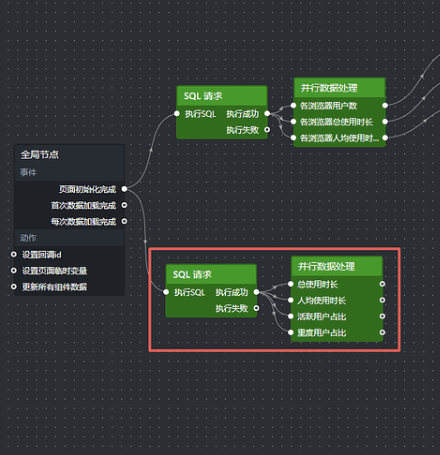
随后按数字翻牌器的数据接口映射格式来加工查询结果。在画布编辑器中选中数字翻牌器,即可在"数据"标签页查看其数据接口映射:
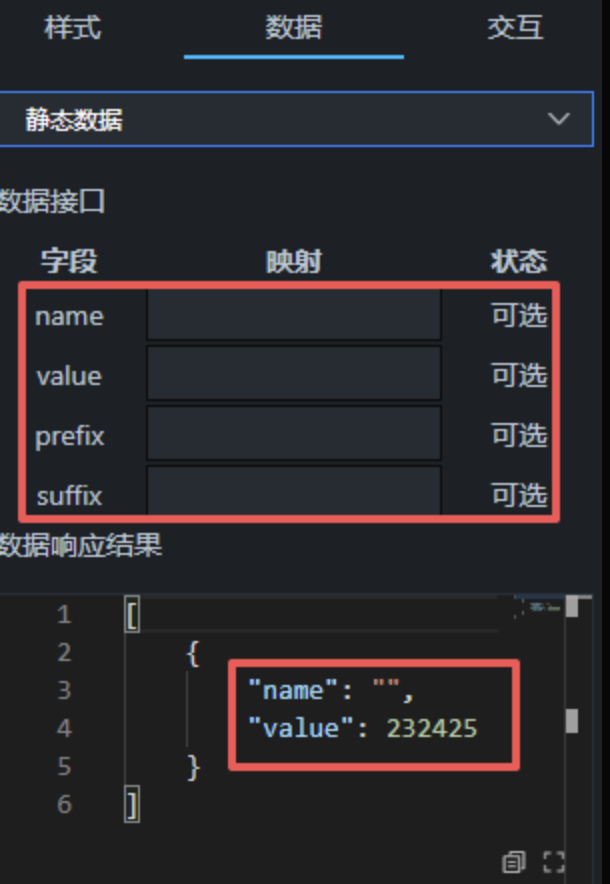
其中 name 字段已在数字翻牌器中预先设定,此处只需处理 value 字段的映射。依据查询结果:
总使用时长
var item = data.find(d => d.metric_name === '总使用时长');
return [{ value: item ? item.metric_value : 0 }];
人均使用时长
var item = data.find(d => d.metric_name === '人均使用时长');
return [{ value: item ? item.metric_value : 0 }];
活跃用户占比
var item = data.find(d => d.metric_name === '活跃用户占比');
return [{ value: item ? item.metric_value : 0 }];
重度用户占比
var item = data.find(d => d.metric_name === '重度用户占比');
return [{ value: item ? item.metric_value : 0 }];
每个分支的输出格式均为 [{ value: xxx }],指标卡组件会直接读取 value 字段展示数值。指标名称则已事先配置在指标卡组件的标题中。
5.5.3 添加图表节点
依次点击 4 个数字翻牌器组件节点,把它们放入画布,再将并行数据处理 4 个处理方法的输出接口对应连接到各图表的"导入数据接口"
点击保存,预览数据是否符合预期。
5.6 为工作日 vs 周末使用时长图表配置数据
5.6.1 添加 SQL 请求节点
参照前面 SQL 请求节点的配置流程完成本节点配置,查询代码如下:
let sql = `
select
browser_name as x,
avg_duration_sec as y,
day_type as s
from labs.browser_weekday_weekend
order by browser_name, day_type
`
return sql
5.6.2 添加图表节点
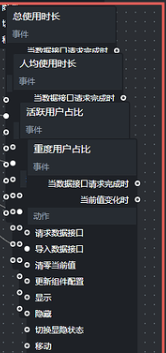
点击工作日 vs 周末使用时长节点,将它加入画布,再把 SQL 请求节点的"执行成功"输出接口连接到"导入数据接口",如下:
点击保存,预览数据是否符合预期。
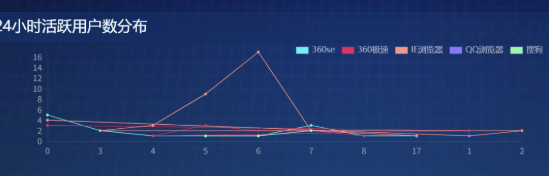
5.7 为 24 小时活跃用户分布图表配置数据
5.7.1 添加 SQL 请求节点
参照前面 SQL 请求节点的配置流程完成本节点配置,查询代码如下:
let sql = `
select hour as x,
active_user_count as y,
browser_name as s
from labs.browser_hourly
order by browser_name, hour
`
return sql
5.7.2 添加图表节点
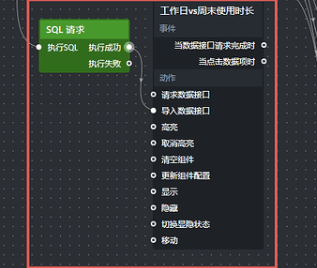
点击 24 小时活跃用户分布节点,将它加入画布,再把 SQL 请求节点的"执行成功"输出接口连接到"导入数据接口",如下:
点击保存,预览数据是否符合预期。
此处需留意:图例颜色是跟随折线上标签点的颜色而变化的。为使折线、标签点、图例三者颜色保持统一,需逐一设置。在画布编辑器中选中该图表,展开数据系列,由于这张折线图有 6 个图例(即 6 款浏览器),因此要分别设置 6 个系列的折线与标记颜色。
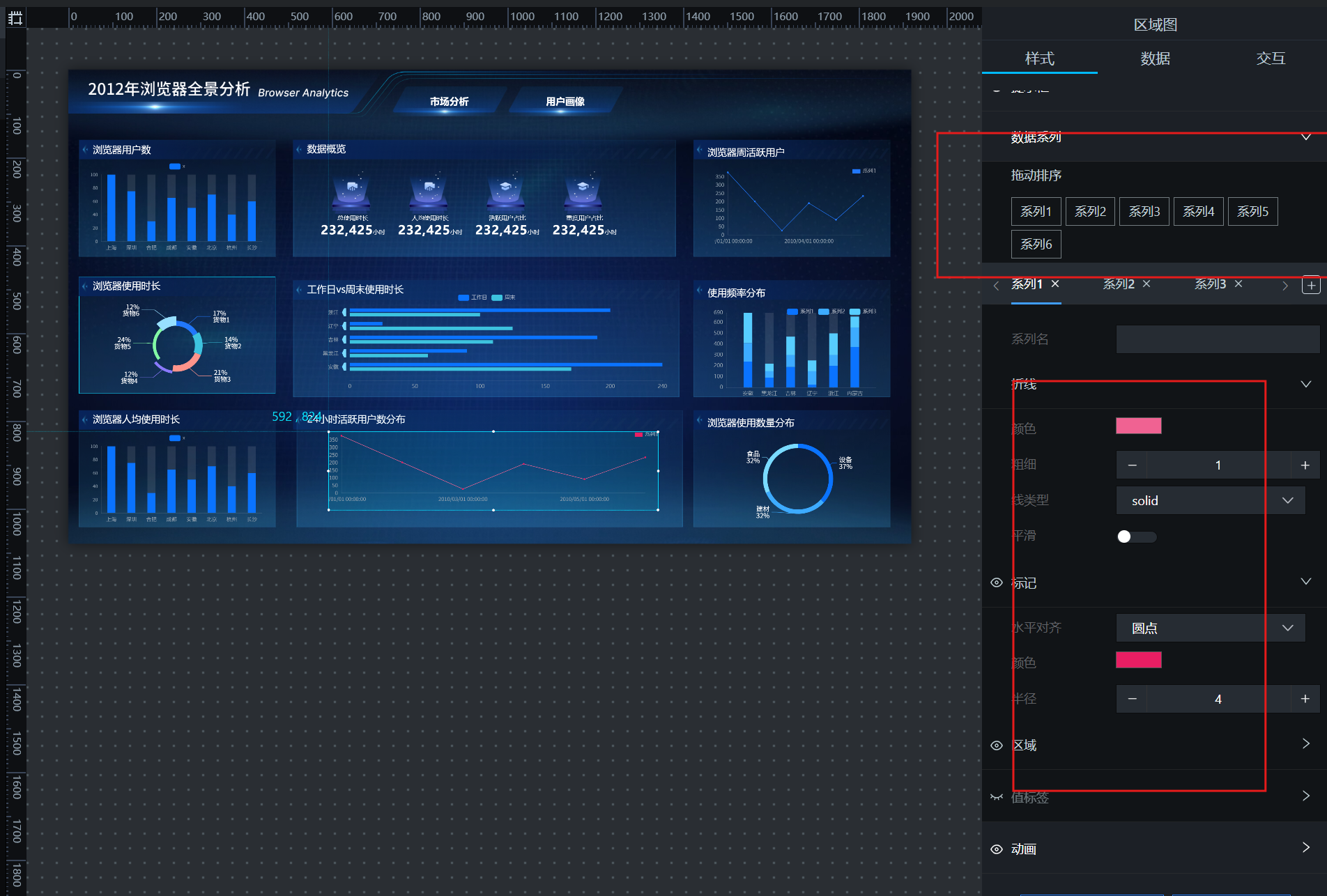
设置完成后,效果如下:
5.8 为活跃用户周变化图表配置数据
5.8.1 添加 SQL 请求节点
参照前面 SQL 请求节点的配置流程完成本节点配置,查询代码如下:
let sql = `
select hour as x,
active_user_count as y,
browser_name as s
from labs.browser_hourly
order by browser_name, hour
`
return sql
5.8.2 添加图表节点
点击活跃用户周变化节点,将它加入画布,再把 SQL 请求节点的"执行成功"输出接口连接到"导入数据接口",如下:
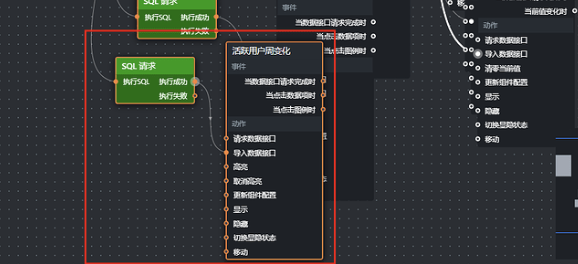
点击保存,预览数据是否符合预期。
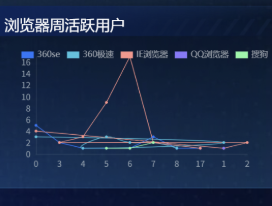
同样需要留意:图例颜色随折线上标签点的颜色而变。为让折线、标签点、图例颜色一致,需逐项设置。在画布编辑器中选中图表,展开数据系列,由于该折线图含 6 个图例(即 6 款浏览器),需分别配置 6 个系列的折线与标记颜色。
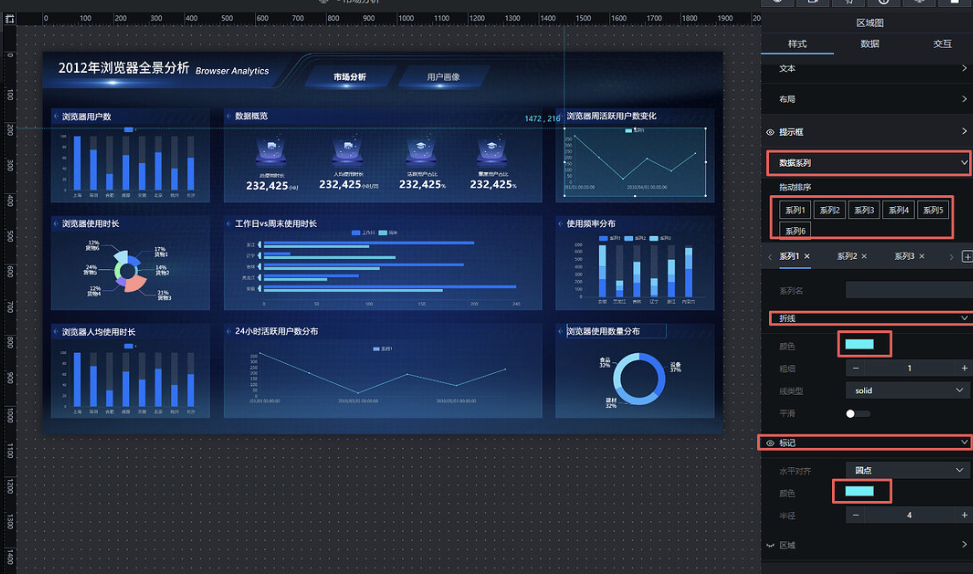
5.9 为使用频率分布图表配置数据
5.9.1 添加 SQL 请求节点
参照前面 SQL 请求节点的配置流程完成本节点配置,查询代码如下:
let sql = `
select
browser_name as s,
user_count as y,
usage_level as x
from labs.browser_frequency_stats
order by browser_name
`
return sql
5.9.2 添加图表节点
点击使用频率分布节点,将它加入画布,再把 SQL 请求节点的"执行成功"输出接口连接到"导入数据接口",如下:
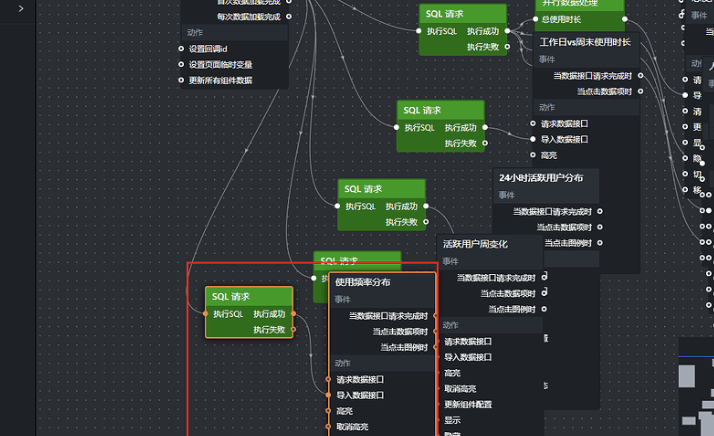
点击保存,预览数据是否符合预期。
5.10 为浏览器使用数量分布图表配置数据
5.10.1 添加 SQL 请求节点
参照前面 SQL 请求节点的配置流程完成本节点配置,查询代码如下:
let sql = `
select
browser_count as name,
user_count as value
from labs.browser_multi_usage
order by browser_count
`
return sql
5.10.2 添加图表节点
点击浏览器使用数量分布节点,将它加入画布,再把 SQL 请求节点的"执行成功"输出接口连接到"导入数据接口",如下:
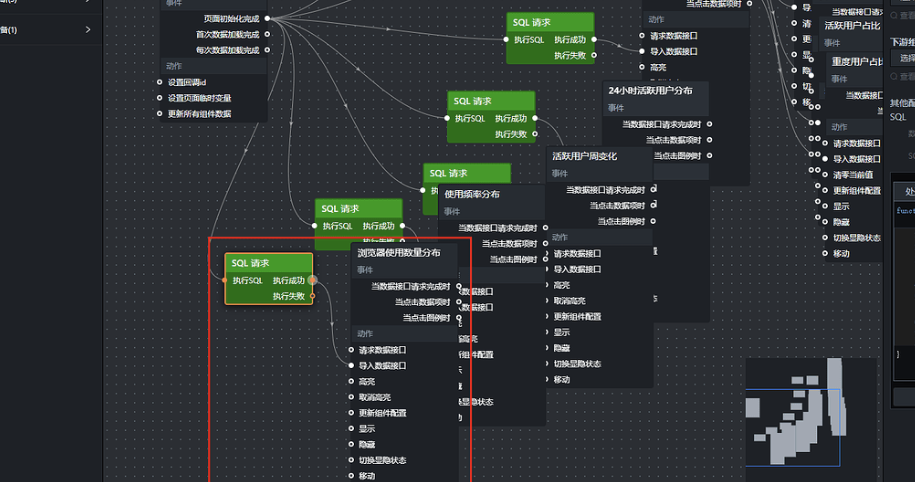
点击保存,预览数据是否符合预期。
5.11 预览与发布
当组件的样式与数据全部配置就绪后,便可预览并发布该可视化应用,实现在线播放与演示。
点击大屏页面右上角的预览图标,对可视化应用进行预览。
确认无误后,点击大屏页面右上角的发布图标。
在弹出的发布对话框中点击"发布分享"。
点击分享链接右侧的复制按钮。
打开浏览器,把复制好的链接粘贴到地址栏,即可在线浏览大屏。
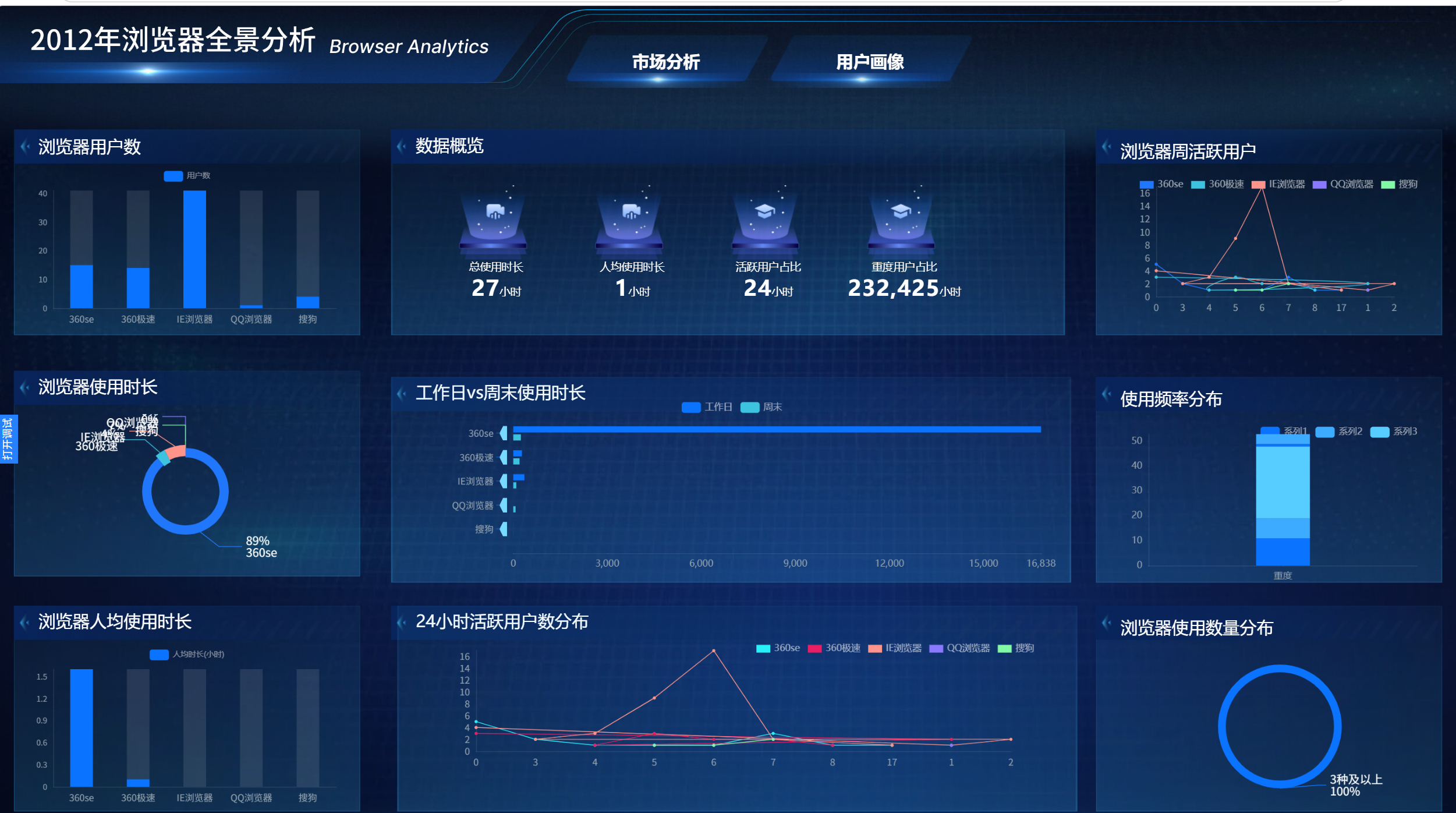
2012 年浏览器市场分析大屏链接:
http://47.109.66.142:30887/#/dataScreen/release?shareId=adf21b15f1a146a092979664e9f915ff
实验总结:
本系列实验以1000名用户、超800万条互联网浏览器行为日志为数据基础,通过三个递进式实验完整走通了数据分析全链路。实验一聚焦原始日志的清洗与整理,借助助睿ETL平台完成进程筛选、名称映射、时间拆解与分组聚合,产出"用户-日-浏览器-小时"明细表及基础统计表,为后续分析奠定数据根基;实验二面向大屏展示需求,在明细表基础上系统加工出涵盖市场格局、周活跃走势、使用频率分布、多浏览器使用情况、工作日与周末对比以及用户画像在内的八张目标统计表,将分散的明细数据浓缩为可直接驱动可视化的聚合结果;实验三利用助睿Max大屏工具,按照"先整体后局部、先趋势后细节"的叙事逻辑,将聚合数据转化为包含柱状图、饼图、折线图、区域图、翻牌器等组件的交互式可视化大屏。三个实验层层推进,不仅揭示了各浏览器在用户规模与使用粘性上的分化格局、活跃度的增减信号、轻中重度用户的结构差异、24小时及工作日与周末的行为规律等关键业务洞察,更传递了一套"问题先行、分层加工、结构化思维、工具赋能"的可复用分析方法论,整个过程全程零代码操作,适用于教学实训与企业数据加工场景,也可迁移至电商用户分析、APP行为洞察等各类数据驱动的业务领域。

一站式 AI 云服务平台
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
所有评论(0)