
浏览器市场与用户画像分析:从800万条日志到数据大屏的ETL实战
本文通过助睿数智平台的零代码ETL工具,完整演示了如何从800万条浏览器用户行为日志中加工出市场分析与用户画像所需的聚合数据表。文章首先明确了需要解决的9个核心业务问题(如市场格局、用户粘性、活跃时段等),然后详细拆解了从原始数据到7张目标表(包括周活跃趋势、使用频率分布、用户画像统计等)的加工流程,重点介绍了关键步骤的实现方法,如日期映射、使用频率分级、工作日判断等。整个过程采用"明细
#浏览器 #用户画像 #助睿数智 #可视化 #数据分析 #ELT实战
手把手教你用零代码ETL完成数据加工,支撑业务决策
前言
当你拿到800万条用户行为日志,老板让你一周内出一份“浏览器市场分析大屏”,你该从哪里下手?
是直接写SQL硬查?还是用Excel硬扛?
本文记录了一次完整的浏览器市场与用户画像分析的数据加工过程。我们将使用**助睿数智(Uniplore)**平台的零代码ETL能力,从原始行为日志出发,一步步加工出覆盖市场格局、用户行为、用户画像等多维度的目标表,为后续的数据大屏提供可靠的数据支撑。
文中所有操作均在助睿在线实验平台完成,使用的工具是udi-studio ETL数据集成平台。
一、我们要回答什么业务问题?
在做任何数据处理之前,先要搞清楚:我们最终要回答什么?
在本次分析中,我们需要通过数据大屏回答以下核心业务问题:
|
业务问题 |
为什么重要 |
|---|---|
|
哪个浏览器用户最多? |
了解市场领导者 |
|
哪个浏览器用户用得最久? |
用户粘性比用户数更能反映产品价值 |
|
用户活跃度在增长还是下降? |
判断产品生命周期 |
|
用户什么时候最活跃? |
优化运营时机 |
|
用户是重度使用还是偶尔打开? |
区分核心用户与边缘用户 |
|
用户同时用几个浏览器? |
了解用户忠诚度 |
|
工作日和周末习惯有何不同? |
区分工作场景与娱乐场景 |
|
核心用户是谁?(性别、年龄、职业等) |
指导产品设计与营销方向 |
这些问题的答案,无法直接从原始日志表里秒级返回——原始表有800万+行记录,直接查询会导致大屏卡死。
所以,提前加工好聚合后的目标表,是数据大屏建设的第一步。
二、实验环境与数据说明
2.1 环境
-
平台:助睿在线实验平台 (https://lab.guilian.cn/)
-
ETL工具:助睿数智 udi-studio(零代码数据集成平台)
-
数据规模:1000个用户,800万+条行为记录,约825MB
2.2 数据来源
本实验基于上一阶段清洗后的数据,加上用户属性表:
|
数据表 |
说明 |
|---|---|
behavior_events |
原始用户行为日志(已清洗) |
demographic.csv |
用户人口属性信息(性别、年龄、学历、职业、收入、省份、居住地类型等) |
demographic.csv存放在实验平台的空间数据资源中可直接导出使用
三、整体分析框架:从业务问题到目标表
我们需要将业务问题转化为技术可执行的分析维度,再反推需要加工哪些目标表。
大屏一:浏览器市场行为分析
|
维度 |
目标表 |
核心指标 |
|---|---|---|
|
市场格局 |
browser_coverage |
用户数、使用时长、人均时长 |
|
周活跃趋势 |
browser_weekly_active |
每周活跃用户数 |
|
时段偏好 |
browser_hourly |
24小时活跃分布 |
|
使用频率 |
browser_frequency_stats |
轻/中/重度用户占比 |
|
浏览器使用数量 |
browser_multi_usage |
1种/2种/3种及以上用户占比 |
|
工作日vs周末 |
browser_weekday_weekend |
工作日/周末人均时长 |
|
核心指标卡片 |
browser_overview |
总时长、人均时长、周活率、重度用户率 |
大屏二:用户画像分析
|
维度 |
目标表 |
核心指标 |
|---|---|---|
|
性别、年龄、学历、职业、收入、居住地、省份 |
user_profile_stats |
各维度下的用户数 |
本文重点讲解以上目标表的加工逻辑和操作步骤。
四、第一步:准备核心明细表
在加工各项目标表之前,我们需要一份统一的基础明细表:daily_browser_detail(用户-日-浏览器-小时明细表)。
这份表记录了:每个用户、每一天、每个浏览器、每个小时的使用时长和活跃次数。
4.1 创建明细表结构
首先在团队私有数据库中创建表:
CREATE TABLE IF NOT EXISTS `daily_browser_detail` (
`user_id` VARCHAR(50) NOT NULL COMMENT '用户ID',
`usage_date` DATE NOT NULL COMMENT '使用日期',
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`hour` TINYINT NOT NULL COMMENT '小时',
`total_duration_sec` INT NOT NULL COMMENT '总使用时长(秒)',
`active_count` INT NOT NULL COMMENT '活跃次数'
);4.2 复制并改造清洗转换流
上一实验我们已经有了一个“互联网用户行为日志数据清洗抽取”转换流,里面包含了生成明细数据的完整逻辑。我们直接复制一份,改为输出到daily_browser_detail表。
关键改造点:
-
修正排序字段,确保分组前数据有序
-
增加值映射组件,将进程名映射为浏览器名称(iexplore.exe → IE浏览器,chrome.exe → Google等)
-
添加表输出组件,写入
daily_browser_detail
执行转换流,等待约15-20分钟(800万+数据),即可得到我们的基础明细表。
五、各目标表加工实战
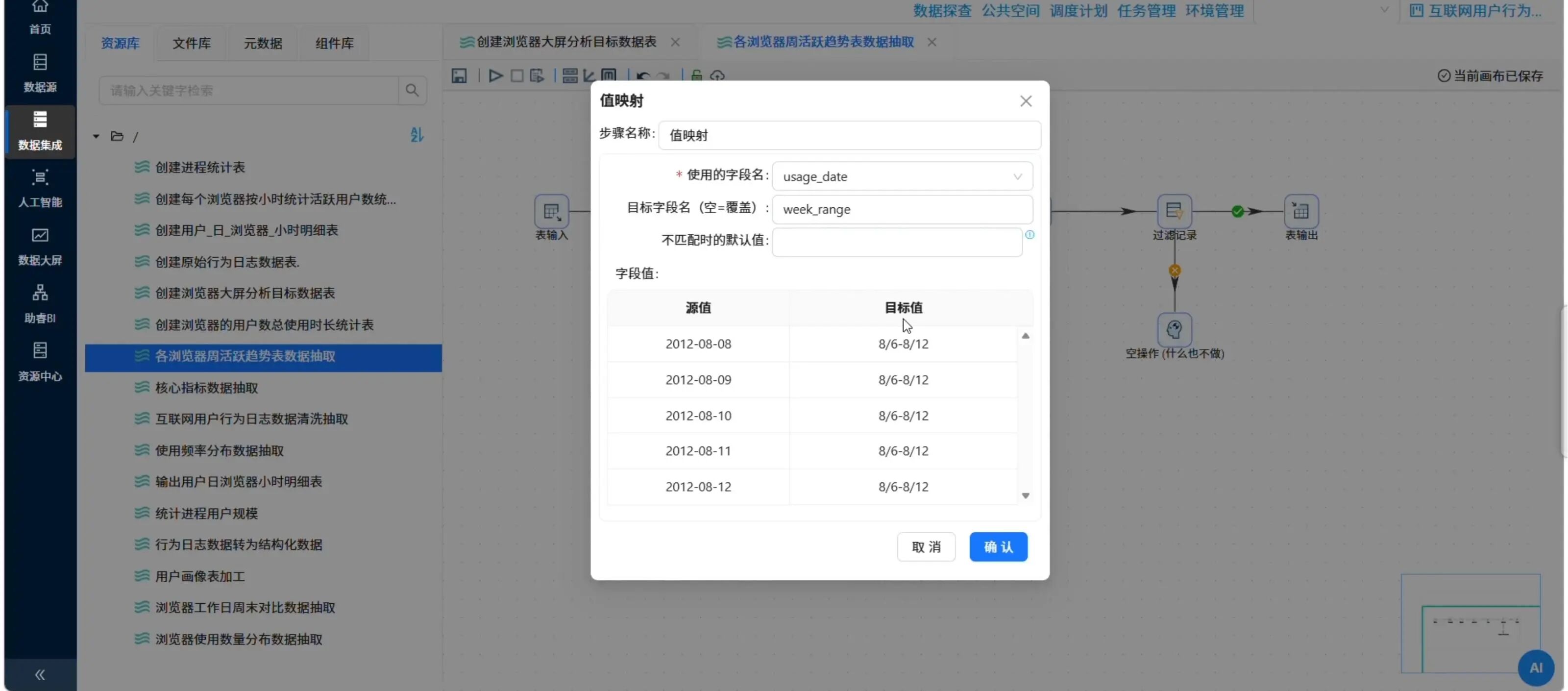
5.1 周活跃趋势表 (browser_weekly_active)
目标:统计每个浏览器在第1-4周的每周活跃用户数。
加工逻辑:
-
从
daily_browser_detail读取数据 -
将
usage_date映射为周区间(如“5/7-5/13”) -
按
browser_name、week_range分组,对user_id去重计数
关键步骤截图位置:值映射组件配置日期→周区间
📸 日期映射周区间的值映射配置
-- 最终结果示例
browser_name | week_range | active_user_count
Google | 5/7-5/13 | 312
Google | 6/4-6/10 | 328
...
5.2 使用频率分布表 (browser_frequency_stats)
目标:按轻/中/重度划分用户使用频率(轻度<3h/周,中度3-10h,重度>10h)。
加工逻辑:
-
按用户+浏览器分组,计算总使用时长(秒→小时)
-
用JavaScript代码划分等级:
<3h→轻度,3-10h→中度,>10h→重度 -
按浏览器+等级分组,统计用户数
📸 JavaScript代码组件中划分频率等级的代码
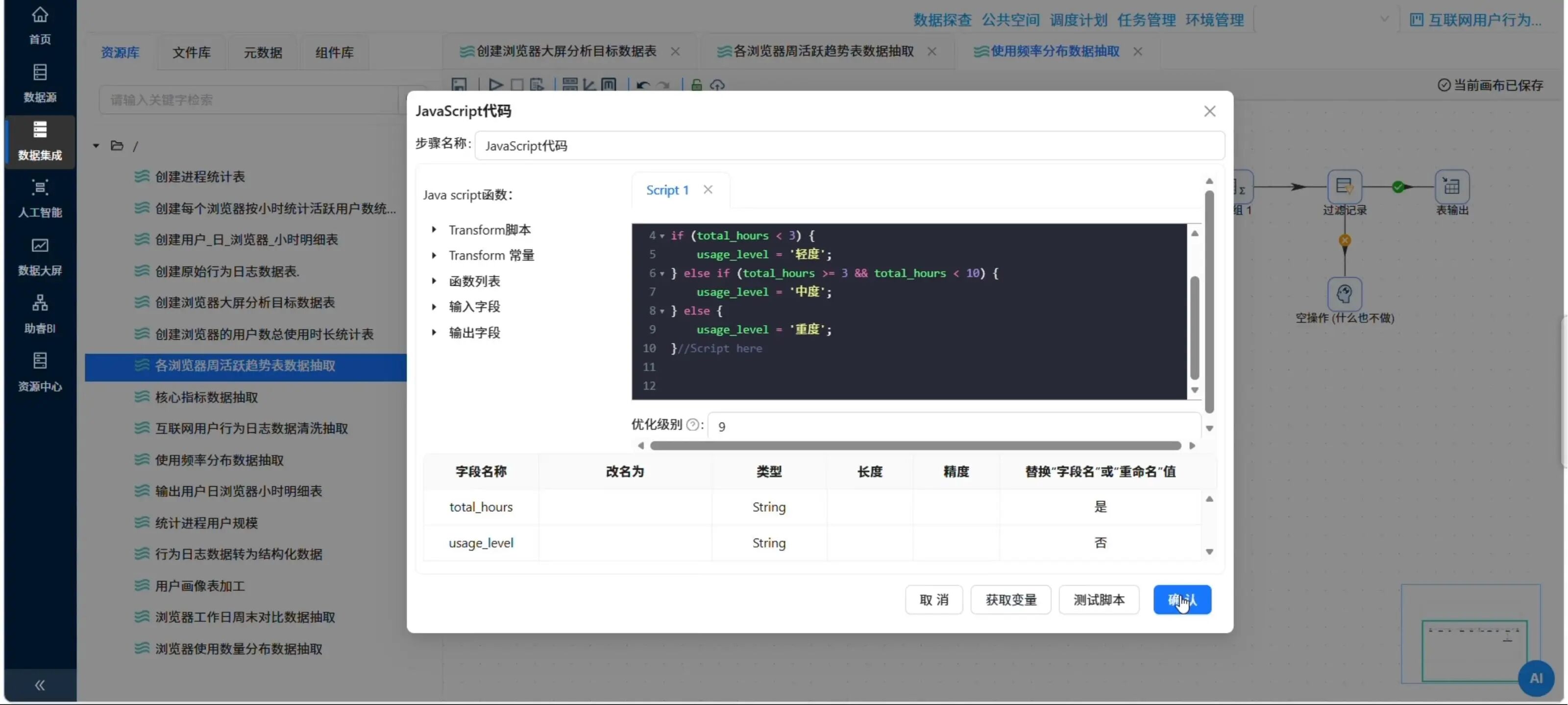
var total_hours = total_hours;
var usage_level = '';
if (total_hours < 3) {
usage_level = '轻度';
} else if (total_hours >= 3 && total_hours < 10) {
usage_level = '中度';
} else {
usage_level = '重度';
}
5.3 浏览器使用数量分布表 (browser_multi_usage)
目标:统计用户使用1种、2种、3种及以上浏览器的用户数。
加工逻辑:
-
按
user_id分组,对browser_name去重计数 → 得到每个用户使用的浏览器种类数 -
划分等级:=1→“1种”,=2→“2种”,≥3→“3种及以上”
-
按等级分组,统计用户数
5.4 工作日vs周末对比表 (browser_weekday_weekend)
目标:统计各浏览器在工作日和周末的人均使用时长、总时长、用户数。
加工逻辑:
-
从
usage_date获取星期几(JavaScript代码) -
判断:周一至周五→“工作日”,周六周日→“周末”
-
按
browser_name、day_type分组,聚合:-
平均时长(秒)
-
总时长(秒→小时)
-
用户数(去重)
-
📸 JavaScript代码判断工作日/周末
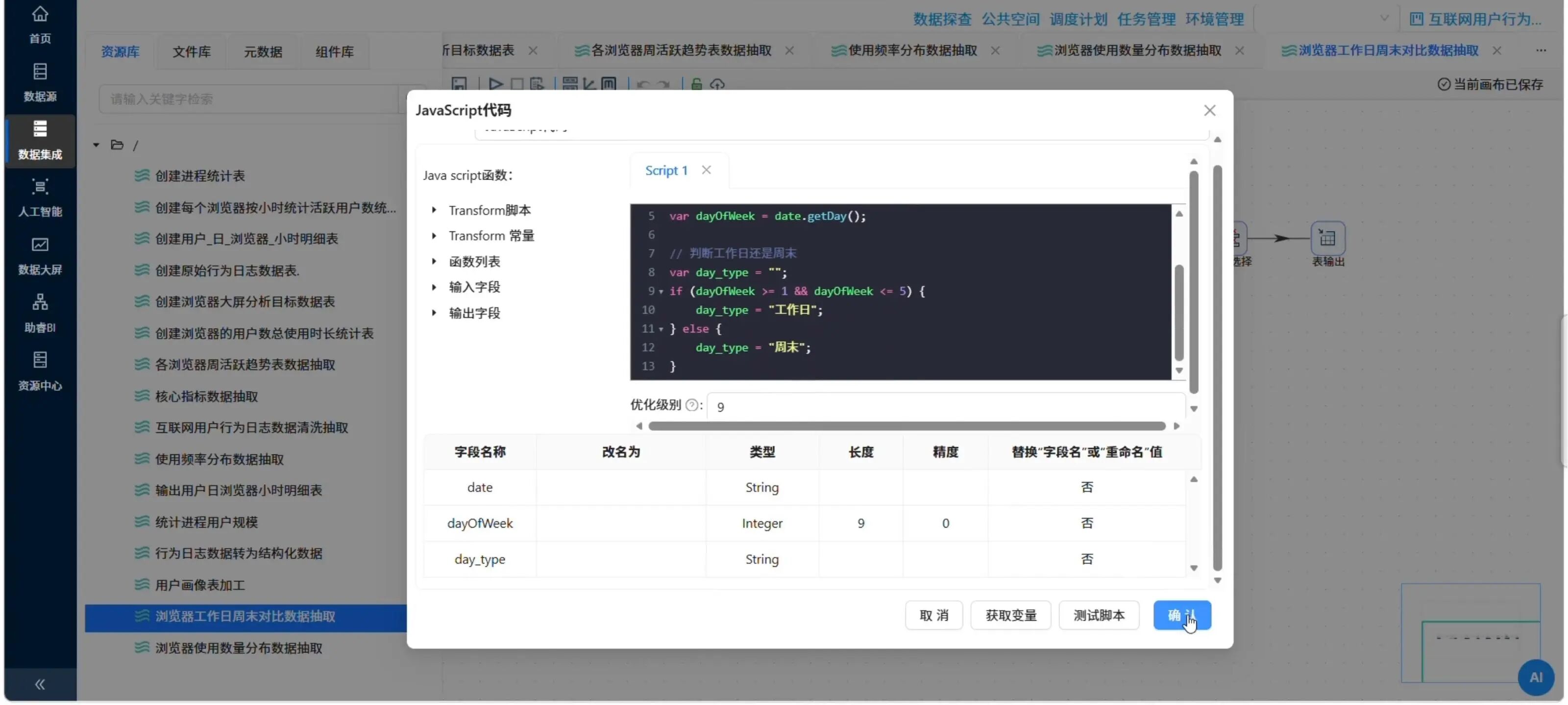
var dayOfWeek = date.getDay();
var day_type = "";
if (dayOfWeek >= 1 && dayOfWeek <= 5) {
day_type = "工作日";
} else {
day_type = "周末";
}
5.5 核心指标表 (browser_overview)
目标:大屏顶部的四个核心指标卡片——总使用时长、人均时长、周活跃率、重度用户率。
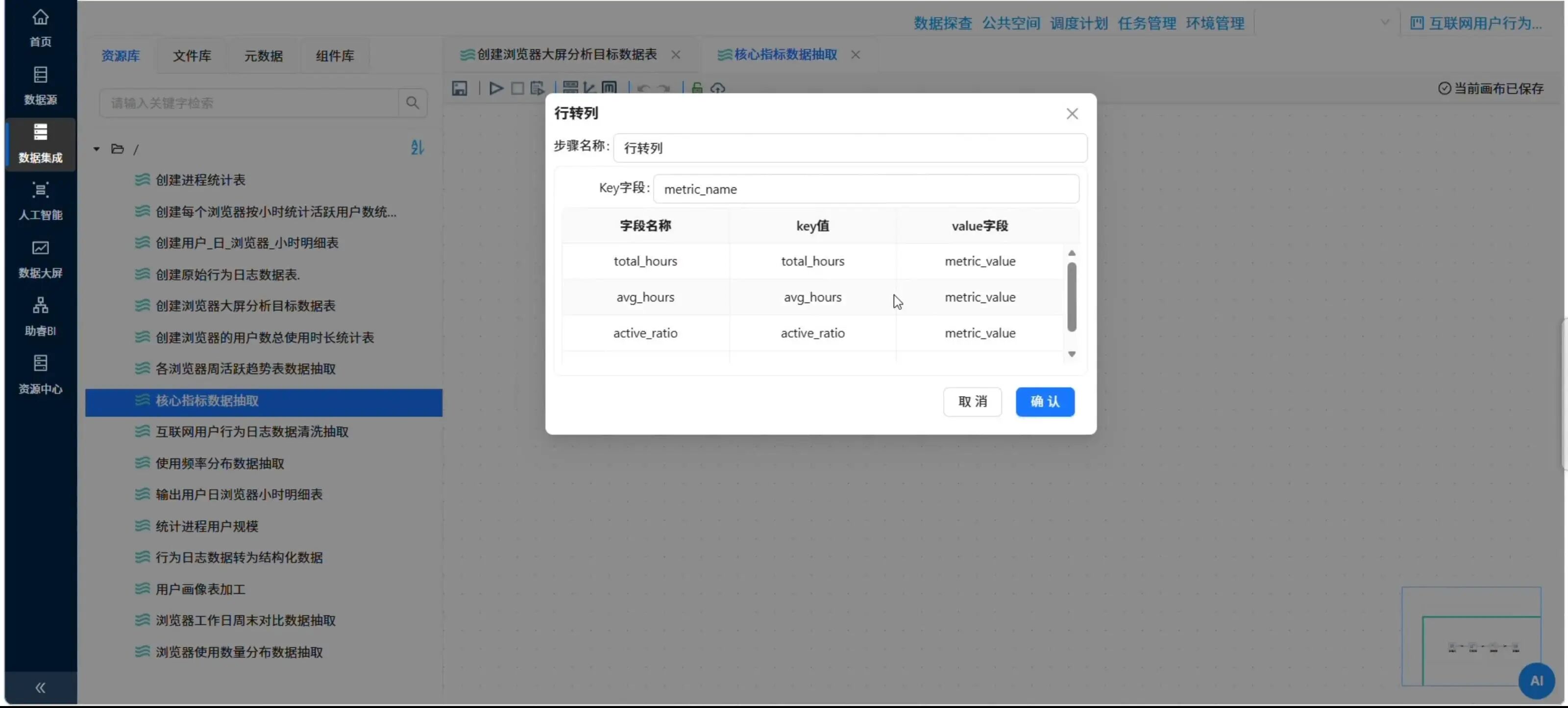
加工逻辑:直接用SQL一次性算出所有指标,再用行转列组件转成键值对形式。
SELECT
ROUND(SUM(total_duration_sec) / 3600, 2) AS total_hours,
ROUND(SUM(total_duration_sec) / 3600 / COUNT(DISTINCT user_id), 2) AS avg_hours,
ROUND( (周活跃用户数) * 100.0 / 总用户数, 2 ) AS active_ratio,
ROUND( (重度用户数) * 100.0 / 总用户数, 2 ) AS heavy_ratio
FROM daily_browser_detail
📸 行转列组件的配置(字段→键值对)
5.6 用户画像表 (user_profile_stats)
目标:按性别、年龄段、学历、职业、收入、居住地类型、省份,统计每个浏览器的用户分布。
关键点:行为数据中没有用户属性,需要通过user_id关联demographic.csv。
5.6.1 获取人口属性数据
从公共空间导出demographic.csv到项目文件库。
5.6.2 年龄分段
demographic.csv中只有出生年份(BIRTHDAY),需要计算年龄并分段。
// 年龄 = 2012 - 出生年份
var age = year - BIRTHDAY;
var age_group = '';
if (age < 18) age_group = '<18';
else if (age <= 25) age_group = '18-25';
else if (age <= 35) age_group = '26-35';
else age_group = '>35';
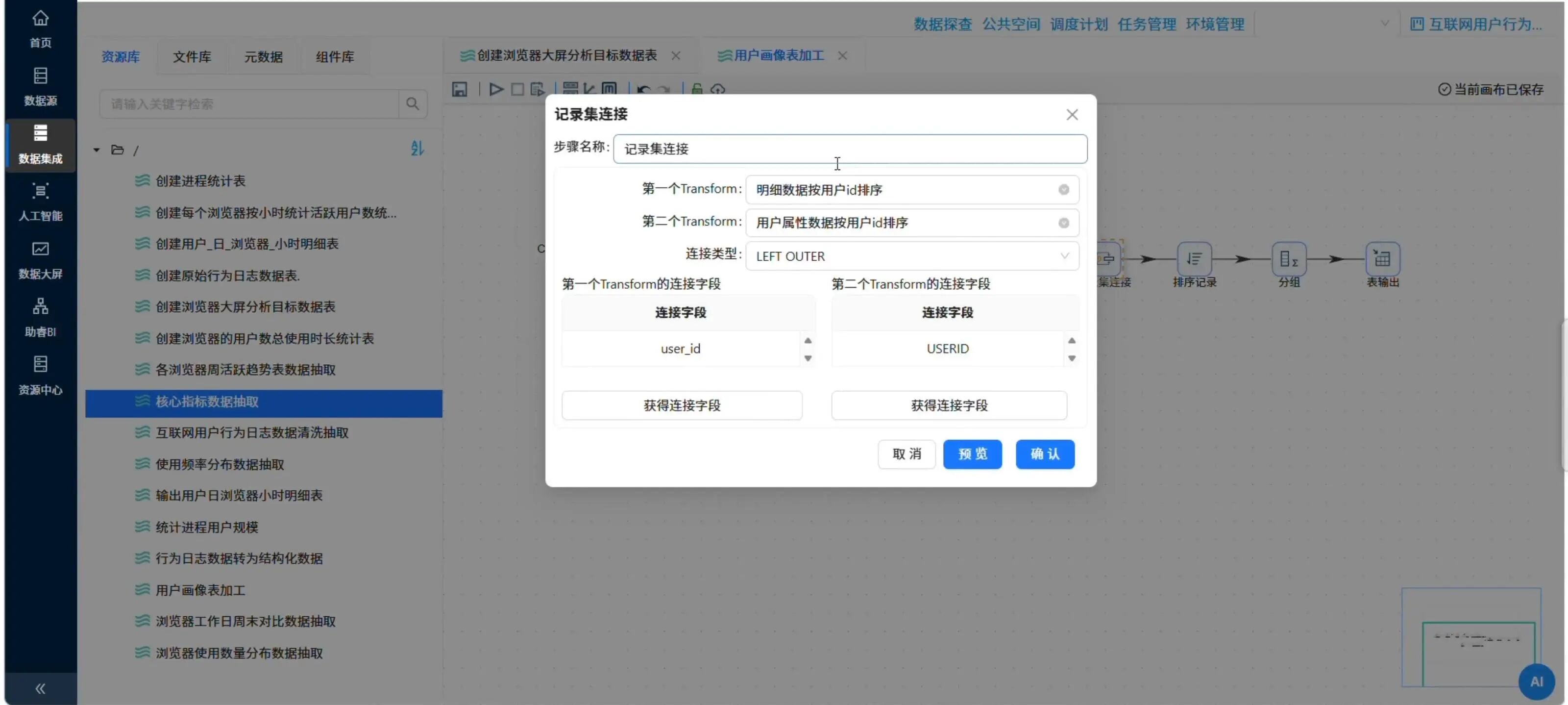
5.6.3 关联两张表
使用记录集连接组件,将明细表(按user_id排序)与人口属性表(按USERID排序)做LEFT OUTER JOIN。
📸记录集连接组件的配置(两个排序记录→连接字段user_id)
5.6.4 分组统计
按browser_name + 所有画像维度分组,对user_id去重计数。
最终写入user_profile_stats表。
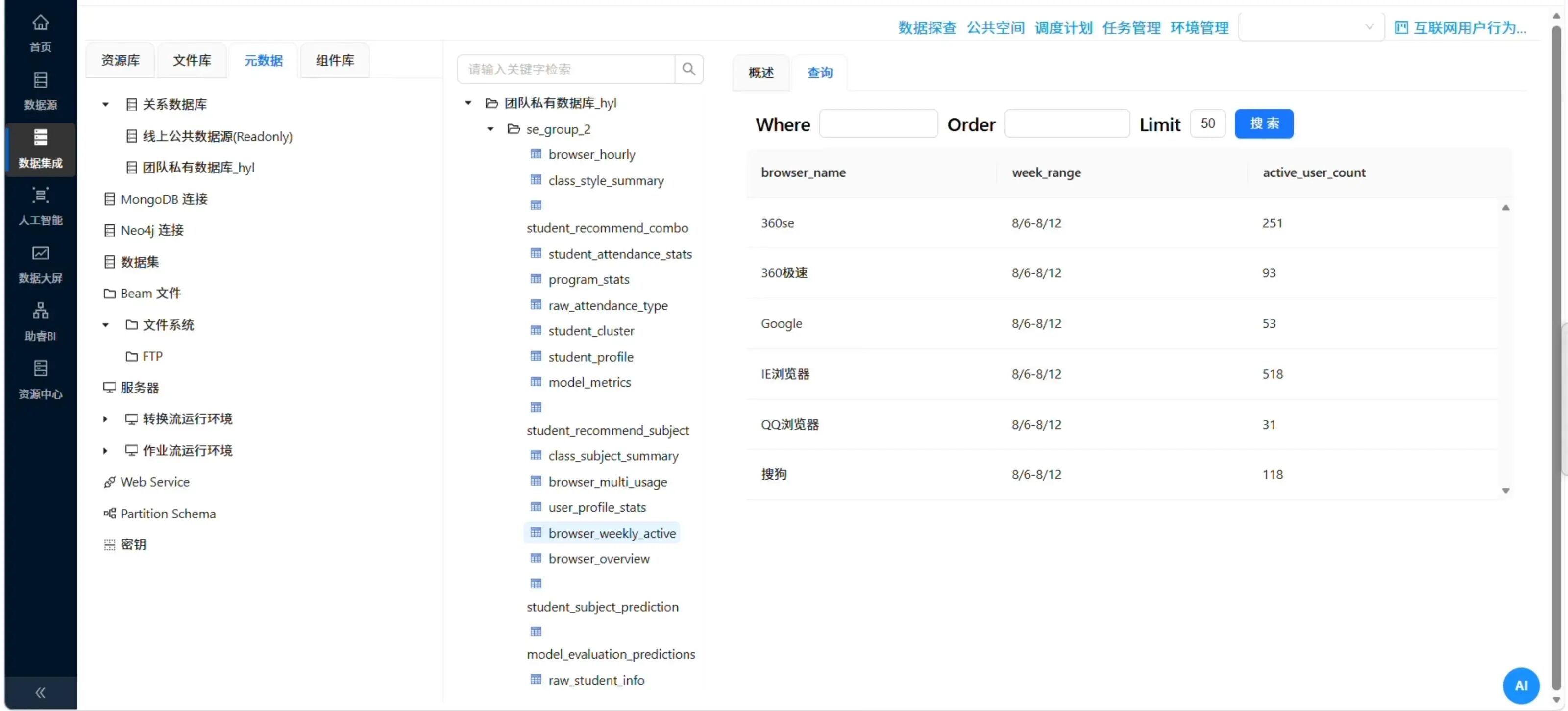
六、结果验证
所有转换流执行完成后,在团队私有数据库中查看各目标表的数据。
以browser_weekly_active为例,应该能看到类似这样的数据:
|
browser_name |
week_range |
active_user_count |
|---|---|---|
|
|
5/7-5/13 |
312 |
|
|
6/4-6/10 |
328 |
|
IE浏览器 |
5/7-5/13 |
287 |
|
... |
... |
... |
📸 数据探查界面,展示某个目标表的前10行
七、总结与思考
7.1 我们完成了什么?
通过本次数据加工实验,我们:
-
从业务问题出发,拆解出分析维度和所需的目标表
-
基于基础明细表,加工了7张不同粒度的聚合表
-
跨源关联:行为日志 + 人口属性CSV,完善用户画像
-
全流程零代码:所有操作均在助睿数智ETL平台通过拖拽组件完成
7.2 可以复用的方法论
-
先问业务问题,再定目标表:不要为了做表而做表
-
公共明细表 + 多项目标表:避免重复计算,保证口径一致
-
提前聚合:大屏直接查聚合表,不查原始大表
-
分层加工:明细层 → 轻度聚合层 → 业务指标层
7.3 下一步
有了这些目标表,我们就可以在数据大屏工具中直接引用,快速搭建出“浏览器市场分析”和“用户画像分析”两大看板。
如果你对数据大屏的搭建也感兴趣,欢迎关注后续文章。
参考资料:助睿在线实验平台《实验5-1:浏览器市场与用户画像分析-数据加工(2)》
工具官网:https://www.uniplore.com/
转载请联系作者。如果你在实验过程中遇到任何问题,欢迎在评论区留言交流。

一站式 AI 云服务平台
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)