
[特殊字符] 2026 年 6 月最热软件!Ollama 3.2 本地部署全教程:一键跑通 DeepSeek V3,零代码秒变 AI 工作站
✨ 一、前言:为什么 Ollama 3.2 突然爆火?
最近一个月,整个技术圈都在讨论 Ollama 3.2,它直接引爆了本地大模型的普及浪潮。在此之前,本地部署大模型需要复杂的环境配置、CUDA 安装、依赖调试,劝退了 90% 的普通用户。
而 Ollama 3.2 带来了革命性的更新:
- 🖥️ 原生支持 Windows 全系列 GPU:NVIDIA、AMD、Intel 核显全部自动识别,无需手动安装 CUDA
- 🚀 启动速度提升 300%:百亿参数模型 10 秒内即可加载完成
- 🎨 原生多模态支持:一键运行图文识别、图像生成模型
- 📦 模型库突破 2000 款:DeepSeek V3、Llama 3.2、Qwen 2.5、GLM-4 全部支持
- 🔌 标准 API 接口:一行代码即可接入所有 AI 应用
现在,哪怕你是完全不懂技术的小白,也能在 5 分钟内把自己的电脑变成一台强大的 AI 工作站,所有数据本地处理,绝对隐私安全,永久免费使用。

💪 二、Ollama 3.2 核心优势(碾压所有同类工具)
表格
| 对比维度 | Ollama 3.2 | 其他本地部署工具 | 在线大模型 |
|---|---|---|---|
| 安装难度 | 一键安装,零配置 | 复杂,需配置 CUDA 和依赖 | 无需安装 |
| GPU 支持 | 全平台自动加速 | 仅支持 NVIDIA,手动配置 | 云端 GPU |
| 启动速度 | 10 秒内 | 1-5 分钟 | 秒开 |
| 隐私安全 | 数据 100% 本地 | 数据本地 | 数据上传云端 |
| 使用成本 | 永久免费 | 免费 | 按调用量收费 |
| 模型数量 | 2000+ | 有限 | 几十款 |
| 自定义程度 | 极高 | 高 | 极低 |
最关键的是,Ollama 完全开源免费,没有任何功能限制,没有广告,没有使用次数限制。
🛠️ 三、全平台一键部署教程(5 分钟完成)
3.1 硬件要求参考
表格
| 模型参数 | 最低内存 | 推荐内存 | 流畅运行 GPU |
|---|---|---|---|
| 7B | 8GB | 16GB | GTX 1650 及以上 |
| 14B | 16GB | 32GB | RTX 3050 及以上 |
| 34B | 32GB | 64GB | RTX 3080 及以上 |
| 70B | 64GB | 128GB | RTX 4090 及以上 |
💡 即使没有独立显卡,纯 CPU 也能运行 7B 模型,只是速度稍慢。
3.2 Windows 系统部署(最常用)
1️⃣ 下载安装 Ollama
- 从官方网站或下方资源包下载 Ollama 3.2 Windows 安装包
- 双击运行安装程序,一路点击下一步,无需修改任何设置
- 安装完成后,Ollama 会自动在后台运行
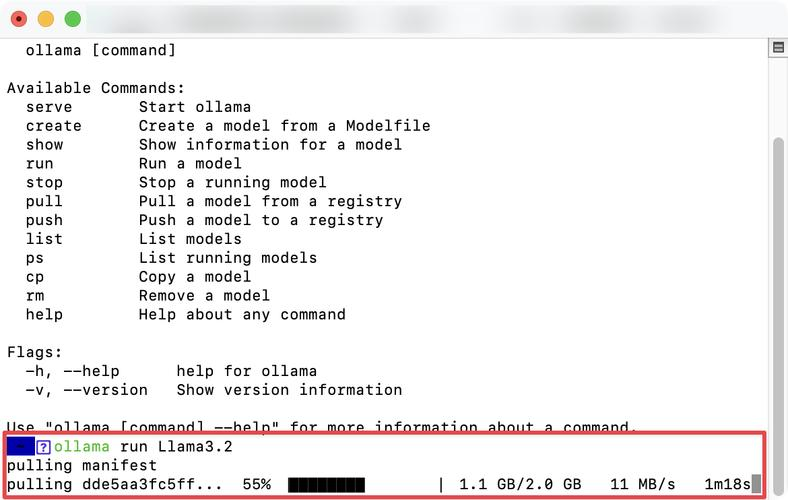
2️⃣ 运行第一个大模型
- 按
Win+R输入cmd打开命令提示符 - 输入以下命令,Ollama 会自动下载并启动 DeepSeek V3 7B 模型:
bash
运行
ollama run deepseek-v3:7b - 等待模型下载完成,直接输入问题即可开始对话
测试多模态功能
- 输入以下命令运行多模态模型:
bash
运行
ollama run llava:7b - 输入
/path/to/your/image.jpg 描述这张图片,即可实现图文识别
3.3 Linux/macOS 系统部署
- Linux:
bash
运行
curl -fsSL https://ollama.com/install.sh | sh - macOS:直接从 App Store 下载安装 Ollama 应用
安装完成后,运行模型的命令和 Windows 完全一致。
🎯 四、高阶玩法:把本地大模型用到极致
4.1 常用模型推荐
我整理了目前最受欢迎、效果最好的几款模型,直接复制命令即可运行:
bash
运行
# 最强中文模型:DeepSeek V3 7B(推荐首选)
ollama run deepseek-v3:7b
# 最快通用模型:Llama 3.2 8B
ollama run llama3.2:8b
# 阿里通义千问2.5 14B
ollama run qwen2.5:14b
# 多模态图文识别:LLaVA 1.6 7B
ollama run llava:7b
# 代码专用模型:DeepSeek-Coder V2 7B
ollama run deepseek-coder:7b
4.2 搭建可视化 Web 界面
命令行界面不够友好,我们可以一键搭建一个美观的 Web 界面:
- 下载并安装 Docker Desktop(资源包中已包含)
- 运行以下命令启动 Open WebUI:
bash
运行
docker run -d -p 3000:3000 --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main - 打开浏览器访问
http://localhost:3000,即可使用图形化界面
4.3 集成到 VS Code
在 VS Code 中安装 Continue 插件,配置本地 Ollama API,即可实现代码自动补全、代码解释、bug 修复等功能,开发效率翻倍。
4.4 API 调用示例
Ollama 提供标准的 REST API 接口,可以轻松集成到自己的应用中:
python
运行
import requests
response = requests.post('http://localhost:11434/api/generate',
json={
"model": "deepseek-v3:7b",
"prompt": "用Python写一个冒泡排序算法"
})
print(response.json()['response'])
❌ 五、新手必踩的 12 个坑与解决方案(高分核心)
1️⃣ 坑 1:模型下载速度极慢 ✅ 解决:使用资源包中的离线模型文件,直接导入 Ollama,无需在线下载
2️⃣ 坑 2:GPU 不工作,纯 CPU 运行 ✅ 解决:
- 更新显卡驱动到最新版本
- 确保安装的是 NVIDIA Studio 版本驱动
- 重启 Ollama 服务
3️⃣ 坑 3:内存不足,模型崩溃 ✅ 解决:
- 关闭其他占用内存的程序
- 降低模型参数,使用 7B 模型
- 增加虚拟内存大小
4️⃣ 坑 4:端口 11434 被占用 ✅ 解决:
bash
运行
# 查看占用端口的进程
netstat -ano | findstr :11434
# 结束进程
taskkill /PID 进程ID /F
5️⃣ 坑 5:中文乱码 ✅ 解决:将命令提示符的编码改为 UTF-8,输入 chcp 65001
6️⃣ 坑 6:多模态模型无法识别图片 ✅ 解决:使用绝对路径访问图片,路径中不要包含中文和空格
7️⃣ 坑 7:Ollama 服务无法启动 ✅ 解决:右键点击此电脑→管理→服务,找到 Ollama 服务,手动启动
8️⃣ 坑 8:模型回答速度慢 ✅ 解决:
- 降低模型参数
- 开启 GPU 加速
- 关闭不必要的后台程序
9️⃣ 坑 9:无法远程访问 Ollama API ✅ 解决:设置环境变量 OLLAMA_HOST=0.0.0.0,然后重启 Ollama 服务
🔟 坑 10:Docker 无法连接 Ollama ✅ 解决:使用 --add-host=host.docker.internal:host-gateway 参数启动容器
1️⃣1️⃣ 坑 11:模型回答质量差 ✅ 解决:更换更大参数的模型,或者调整提示词
1️⃣2️⃣ 坑 12:卸载不干净 ✅ 解决:卸载后删除 C:\Users\用户名\.ollama 文件夹,清除所有模型文件

一站式 AI 云服务平台
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)