
本地千万级保险理赔异常检测实战:用 AI 工作流零代码、零 SQL 完成多表清洗、异常规则判断与风险等级生成
做保险理赔异常检测,不只是多表关联,还要先完成数据清洗、规则判断和风险分级,才能产出真正可用的风控分析结果。传统做法通常需要 Python + SQL 配合完成,门槛高、流程长、上手成本也更高。
今天给大家介绍一种更简单的 AI 工作流 方案:
不用写 Python,也不用懂 SQL,直接在本地电脑上完成千万级 XLSX/CSV 电力数据的清洗、关联、列转行分析和结果输出。
通过提示词配置好 AI 工作流 ,可以进一步生成统计结果表与可视化大盘,如下图:
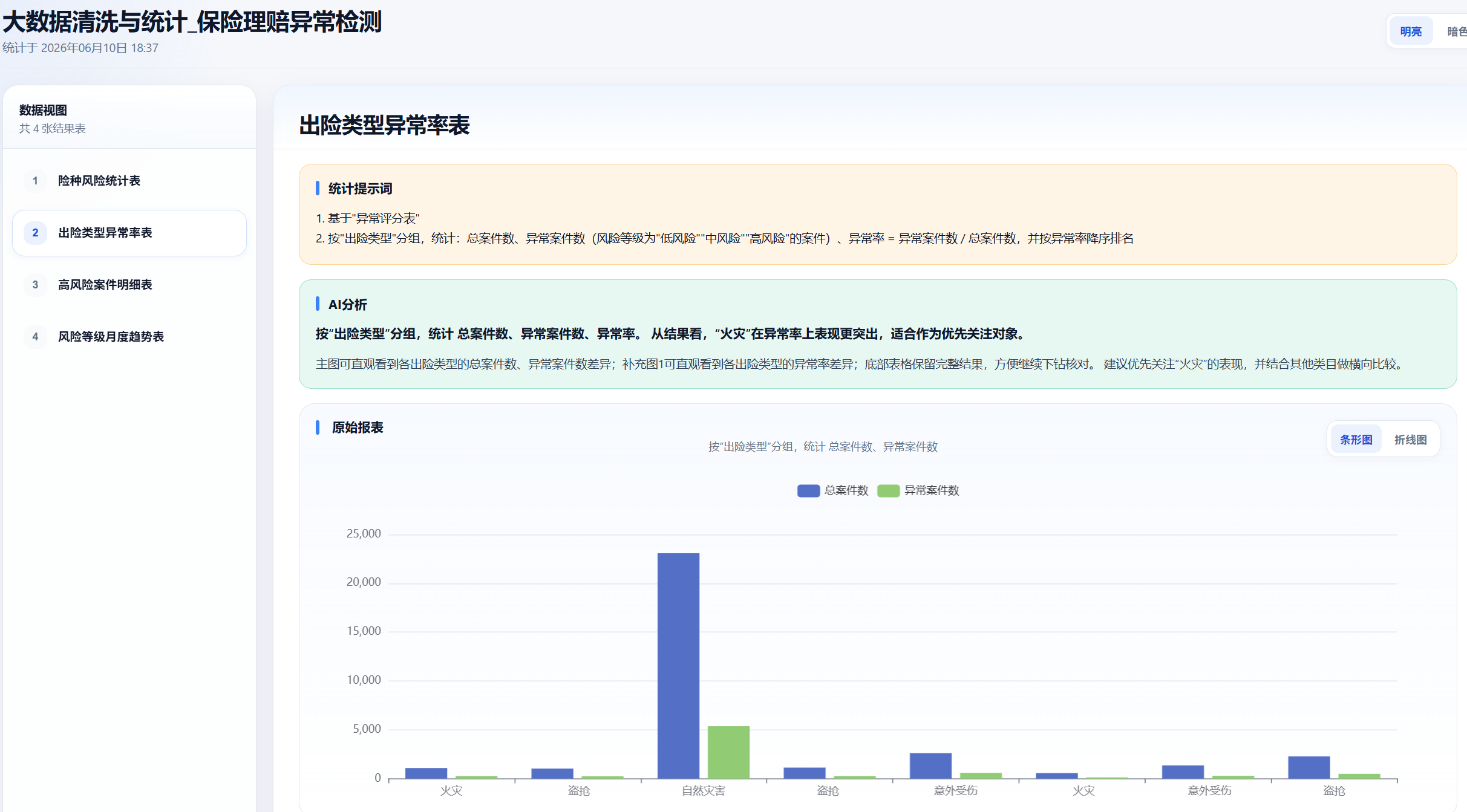
统计出的结果表:
工作流涉及的主要内部技术:
- 数据清洗技术:通过Python智能体,完成日期格式统一、金额字段转数值、空值填充、险种与出险类型归一化等处理,为后续异常检测提供干净一致的数据基础。
- 数据统计技术:通过 SQL 智能体,基于异常评分表完成 GROUP BY 分组聚合、 SUM/COUNT 汇总、异常案件条件统计、占比计算、 ORDER BY 排名以及按月份的趋势统计,并按风险等级筛选高风险案件明细。
- 本地存储技术:通过 DuckDB + 本地磁盘,支持保险理赔相关 XLSX/CSV 数据在本地完成千万级数据导入、清洗、关联与统计分析。
- 可视化技术: 通过 AI + HTML + ECharts 图表组件,自动生成风险分布、异常率和趋势分析图表。
通过对这些复杂技术的包装,即使没有 Python 和 SQL 基础,也可以完成保险理赔场景下千万级数据的异常检测与风险分析。
接下来我们就来看下这个案例实战:保险理赔异常检测与风险分级分析。
一、案例需求分析
本案例聚焦保险理赔数据的异常检测与风险分级。由于数据分散在多张表中,且日期、金额、险种、出险类型等字段口径不统一,因此需要先完成数据清洗、多表关联和宽表构建。
在此基础上,再基于多条异常规则完成风险判断、分级统计和结果输出。
1、源表数据清洗流程
AI工作流内置了Python Agent,通过提示词就能实现任意清洗逻辑,本案例需要清洗的表和具体逻辑如下:
清洗理赔申请表
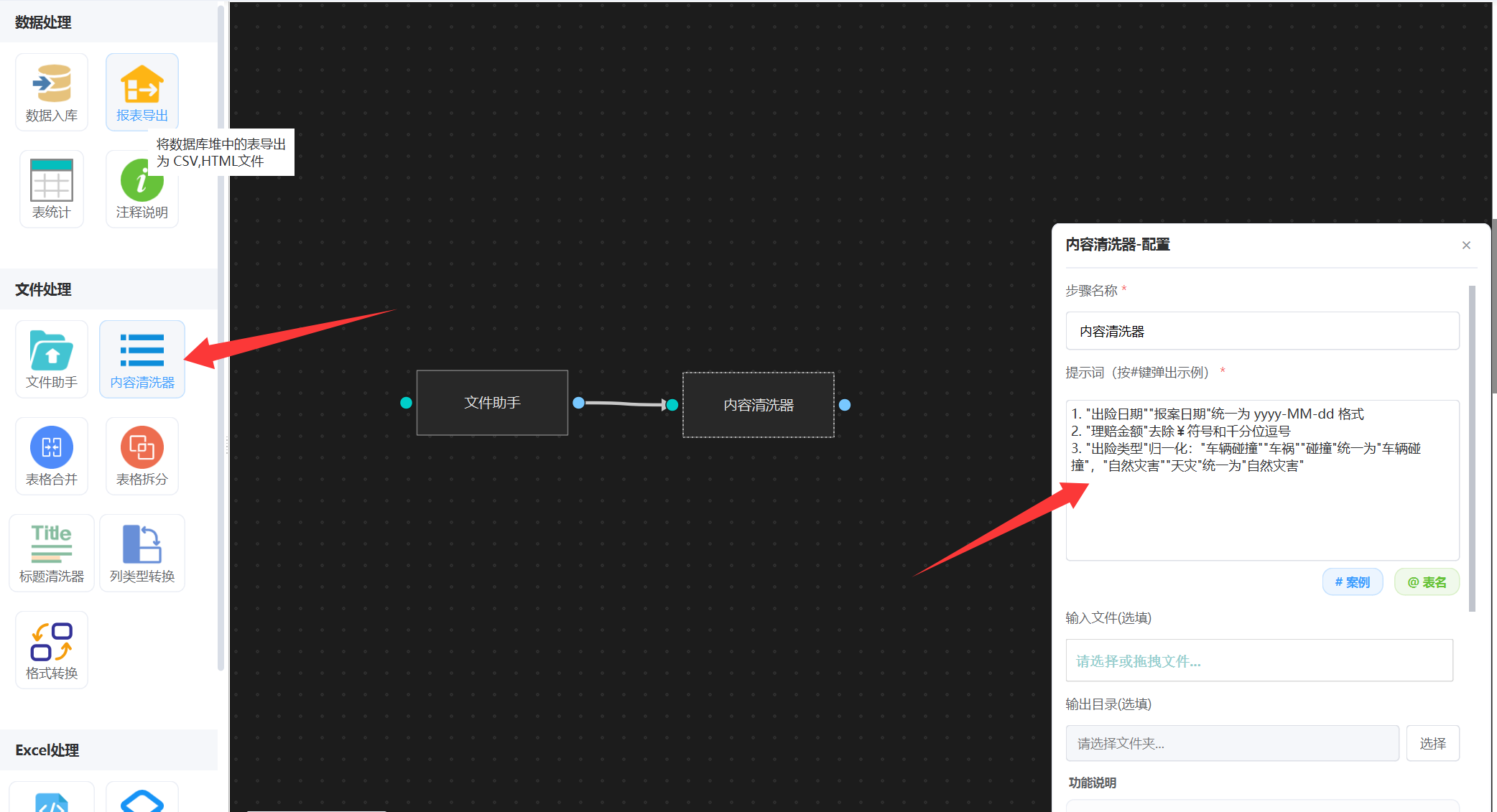
- "出险日期""报案日期"统一为 yyyy-MM-dd 格式
- "理赔金额"去除¥符号和千分位逗号
- "出险类型"归一化:"车辆碰撞""车祸""碰撞"统一为"车辆碰撞","自然灾害""天灾"统一为"自然灾害"
清洗保单信息表
- "生效日期""到期日期"统一为 yyyy-MM-dd 格式
- "保额"去除¥和千分位逗号
- "险种"归一化:"车损险""车辆损失险"统一为"车损险"
清洗历史理赔表
- "历史理赔总额"去除¥和千分位逗号
- "历史理赔次数"空值填充为 0
2、最终输出哪些统计结果表
AI工作流内置了SqlAgent, 会通过你描述的统计提示词,翻译成sql进行统计,这个案例会输出4个结果统计表。
- 险种风险统计表 :以 险种 + 风险等级 为统计维度,统计各险种下不同风险等级的案件数、理赔金额汇总、案件数占比和理赔金额占比,用来观察不同险种的风险分布情况,识别哪些险种的高风险案件更多、风险金额更集中。
- 出险类型异常率表 :以 出险类型 为统计维度,统计总案件数、异常案件数和异常率,并按异常率降序排序,用来比较不同出险类型的异常表现,识别哪些出险类型更容易出现异常理赔。
- 高风险案件明细表 :筛选 风险等级 = 高风险 的理赔记录,保留理赔号、保单号、险种、出险类型、报案日期、理赔金额、风险等级、命中异常规则等字段,用来快速定位需要优先审核的重点案件。
- 风险等级月度趋势表 :以 月份 + 风险等级 为统计维度,统计各月不同风险等级的案件数量变化,用来观察高风险、中风险、低风险案件的月度波动趋势,判断风险分布是否存在阶段性上升或异常变化。
3、业务数据涉及哪些源表
源表是指直接从业务系统沉淀下来的基础数据,它们保存的是最原始的业务明细,不是最终展示用的统计结果表,而是后续进行数据清洗、多表关联、宽表构建、异常检测和统计分析的基础输入。
本案例共涉及 3 张核心源表:
- 理赔申请表 :记录理赔号、保单号、报案日期、出险日期、理赔金额、报案人、出险类型等信息,是理赔异常检测的核心业务明细来源。后续可基于这张表完成日期格式统一、理赔金额转数值、出险类型归一化等处理,并作为理赔关联宽表的主体,支撑异常规则判断、风险分级和高风险案件识别。
- 保单信息表 :记录保单号、投保人、被保人、险种、保额、生效日期、到期日期等信息,是补充保单属性和保障口径的重要维表来源。后续可用于补充险种、保额、生效日期、到期日期等字段,并与理赔申请表按保单号进行关联,为金额异常、时间异常和累计异常等规则判断提供基础信息。
- 历史理赔表 :记录保单号、历史理赔次数、历史理赔总额等信息,是反映保单历史风险表现的重要来源。后续可基于这张表完成历史理赔总额转数值、历史理赔次数空值填充等处理,并与理赔申请表按保单号进行关联,为频度异常和累计异常判断提供历史参考。
二、工作流提示词整理
在工作流配置之前,需要先把这次业务处理逻辑整理成一份提示词。
这一步的作用,就是先明确 清洗哪些表 、 怎么关联 、 输出哪些报表 。整理好之后,这份提示词就可以作为工作流配置输入,指导后续执行。
这里也需要说明一点: 提示词不一定非要写成固定模板 。只要表达得 清晰 、 明确 、 简洁 ,让人一眼能看懂要做什么、按什么顺序做、最后输出什么结果,就可以了。
本次案例整理出的提示词如下:
整体要求:生成保险理赔异常检测和风险分级报告:
第一步 - 清洗理赔申请表:
1. "出险日期""报案日期"统一为 yyyy-MM-dd 格式
2. "理赔金额"去除¥符号和千分位逗号
3. "出险类型"归一化:"车辆碰撞""车祸""碰撞"统一为"车辆碰撞","自然灾害""天灾"统一为"自然灾害"
第二步 - 清洗保单信息表:
1. "生效日期""到期日期"统一为 yyyy-MM-dd 格式
2. "保额"去除¥和千分位逗号
3. "险种"归一化:"车损险""车辆损失险"统一为"车损险"
第三步 - 清洗历史理赔表:
1. "历史理赔总额"去除¥和千分位逗号
2. "历史理赔次数"空值填充为 0
第四步 - 生成理赔关联宽表:
1. 理赔申请表 关联 保单信息表(按"保单号"匹配),再 关联 历史理赔表(按"保单号"匹配)
2. 新增"报案延迟天数" = 报案日期 - 出险日期
3. 新增"月份":取"报案日期"的 yyyy-MM,作为后续月度趋势统计口径
第五步 - 生成异常评分表:
1. 基于"理赔关联宽表",逐行判断是否命中以下异常规则,同一条理赔记录可同时命中多个规则:
- "金额异常":理赔金额 > 保额 * 80%
- "频度异常":历史理赔次数 >= 3
- "时间异常":出险日期距生效日期 < 30天(等待期内出险)
- "累计异常":历史理赔总额 + 本次理赔金额 > 保额 * 150%
- "延迟异常":报案延迟天数 > 7天
2. 新增"命中规则数":统计每条理赔记录命中了几条异常规则
3. 根据"命中规则数"新增"风险等级":命中 3 条及以上为"高风险",命中 2 条为"中风险",命中 1 条为"低风险",命中 0 条为"正常"
第六步 - 生成险种风险统计表:
1. 基于"异常评分表"
2. 按"险种"+"风险等级"分组,统计:案件数、理赔金额汇总、案件数占该险种总案件数比例、理赔金额占该险种总理赔金额比例
3. 输出"险种风险统计表"
第七步 - 生成出险类型异常率表:
1. 基于"异常评分表"
2. 按"出险类型"分组,统计:总案件数、异常案件数(风险等级为"低风险""中风险""高风险"的案件)、异常率 = 异常案件数 / 总案件数,并按异常率降序排名
3. 输出"出险类型异常率表"
第八步 - 生成高风险案件明细表:
1. 基于"异常评分表"
2. 筛选条件:风险等级="高风险"
3. 输出"高风险案件明细表"(含理赔号、保单号、险种、出险类型、报案日期、理赔金额、风险等级、命中的异常规则列表)
第九步 - 生成风险等级月度趋势表:
1. 基于"异常评分表"
2. 按"月份"+"风险等级"分组,统计:各风险等级案件数量趋势
3. 输出"风险等级月度趋势表"三、落地实现:工作流配置
工作流是由多个智能体节点组成的,这个案例我们涉及到下面几个智能体:
- 文件助手: 获取磁盘的文件或目录。
- 内容清洗器: 专门用来做数据清洗的,只要输入清洗描述就可以对文件数据进行任意整理。
- 数据入库:将文件数据转成本地数据库,用于后面作SQL统计。
- 表统计: 对本地数据库表进行SQL统计,不需要写sql,只需要统计的描述就可以了。
- 报表导出: 对数据库表进行导出,支持导出csv,xlsx,HTML(可视化显示) 。
根据这几个智能体还有上面描述的提示词,我们就可以完成工作流的配置了。
1. 配置文件助手
”文件助手“ 可以用来获取磁盘上任意的一个或多个文件。打开DT-Bot工作流, 配置一个 “文件助手”智能体节点,描述原始数据文件位置,如图:
DT-Bot工作流,解决方案获取可以看文章末尾名片。
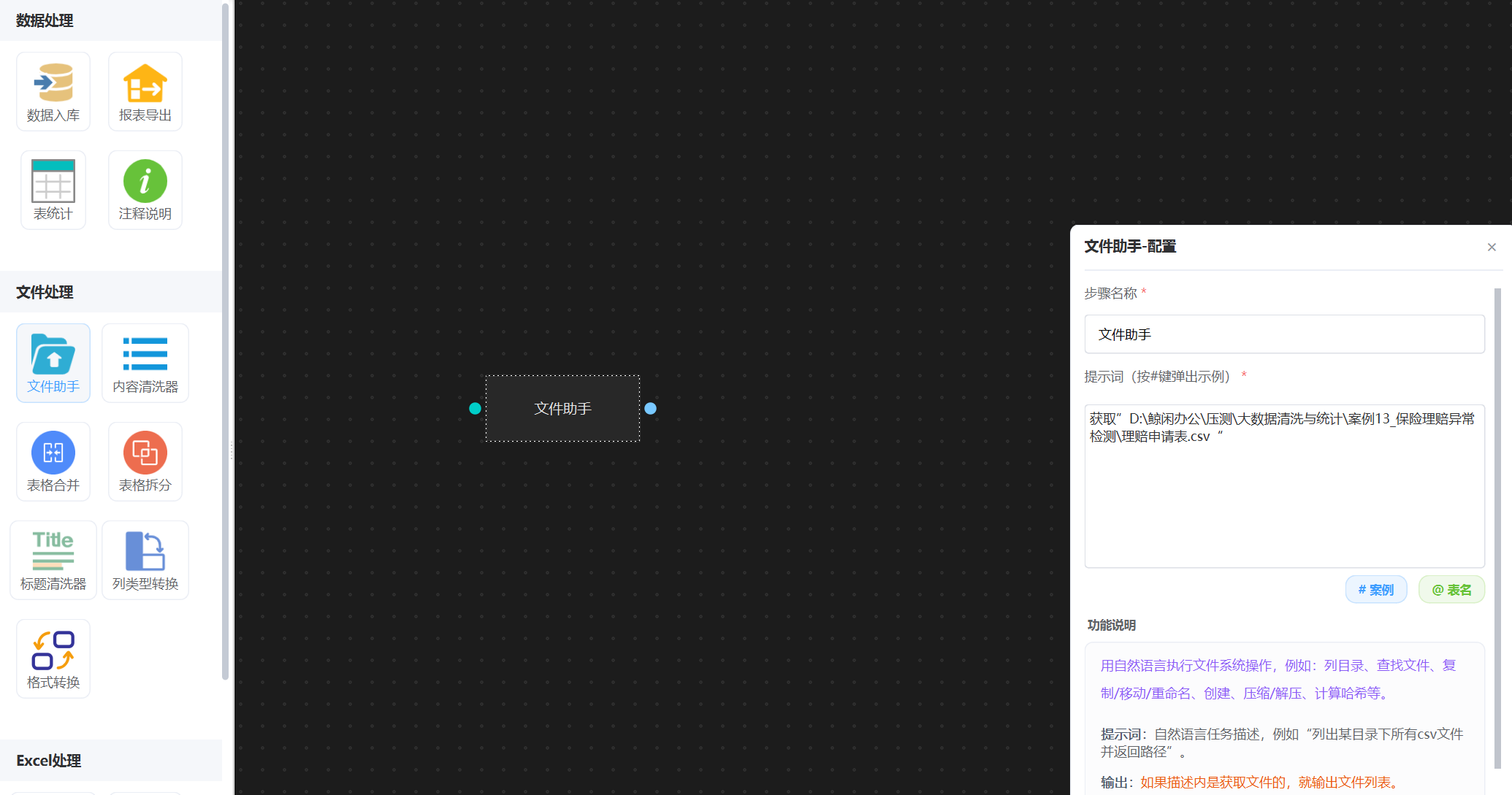
根据提示词描述,获取到了”理赔申请表.csv“原始表格,给后面智能体使用。
2. 配置内容清洗
“内容清洗器” 很强大,内部是通过python agent执行引擎处理的, 可以对文件进行任意数据整理,我们直接输入清洗提示词就可以了, 如图:
3. 数据入库
清洗节点智能体任然返回的是文件,后面需要统计,还必须得入到本地数据库里面,
数据入库内置了本地数据库引擎,支持千万级数据量SQL统计。如图:
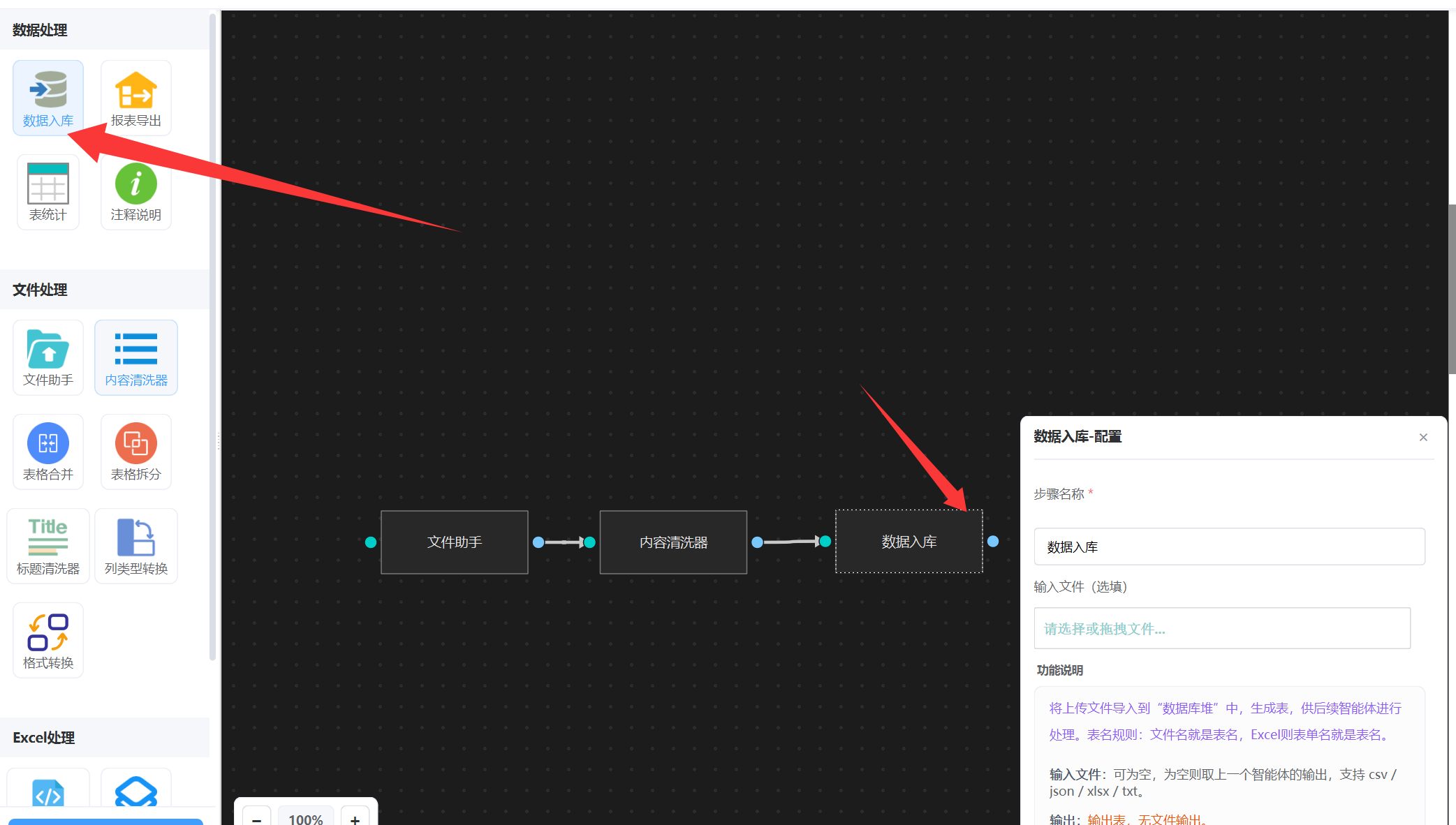
无需配置任何提示词, 入库后,就是在本地开启数据库,并且生成了一张表,表名就是前面的文件名, 支持批量文件入库。
同理,所有的源表清洗都是这个套路。我就不一一配置了。
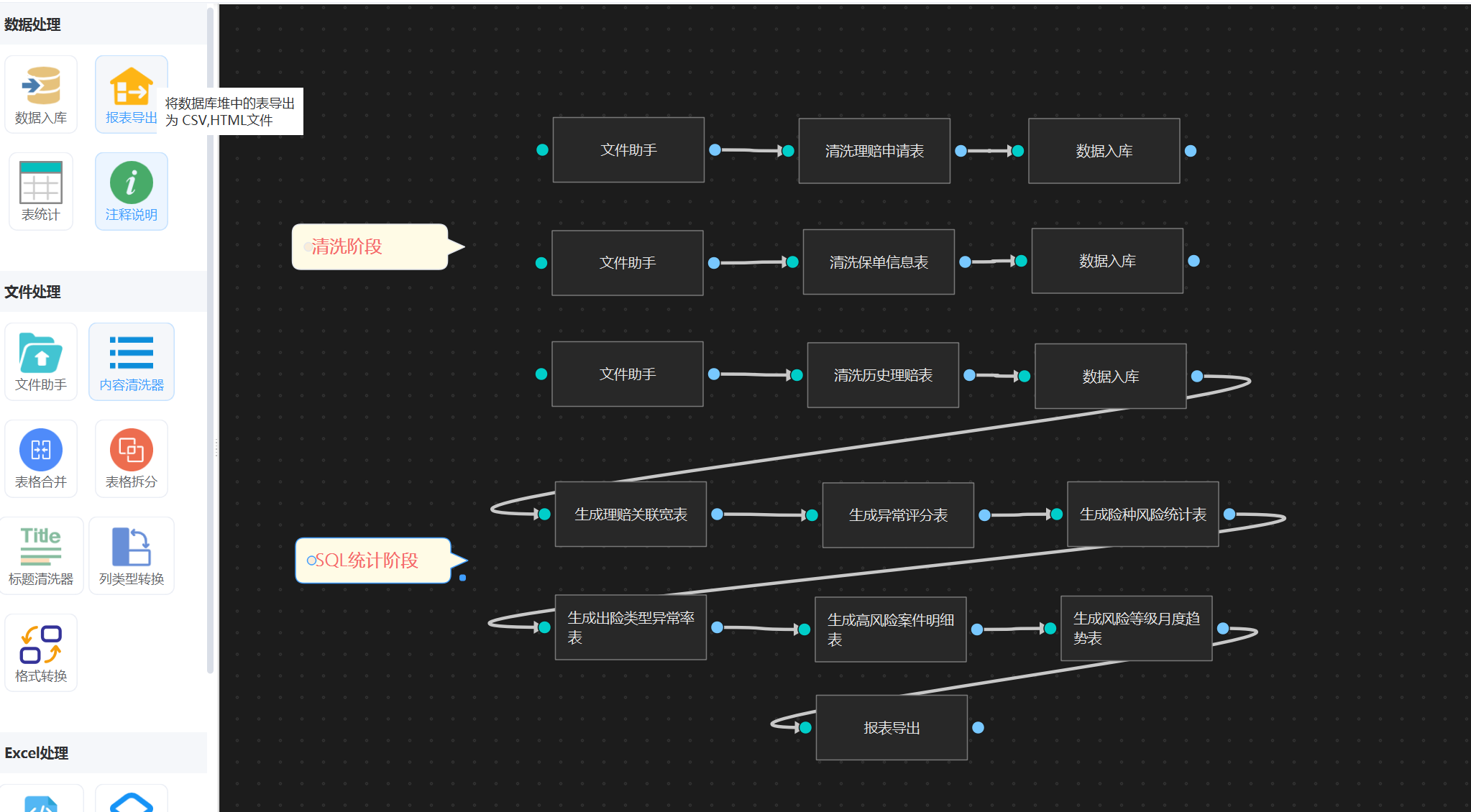
4. 表统计
接下来我们需要进行表统计,直接用“表统计”智能体就好了, 也是直接输入提示词描述,工作流内部会生成相关sql进行统计(全程不用你操心),下面是我配置完成的图:
5. 导出报表
表统计后,只生成了结果表到数据库里面,还需要从数据库里面下载出来,这是要用“报表导出”智能体,可以指定哪些表,下载类型(支持CSV+HTML),如下图:
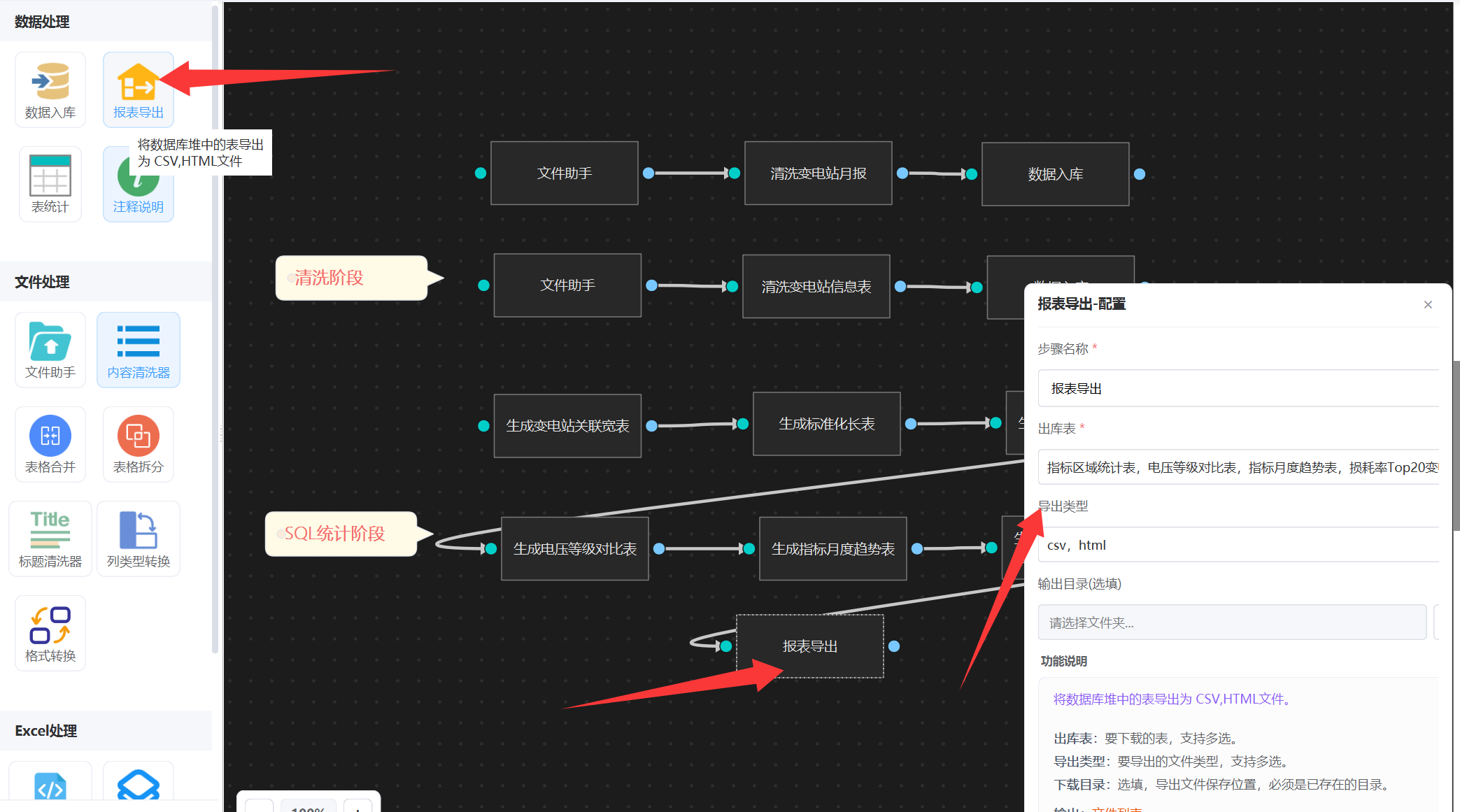
配置完成后,我们发布工作流执行就可以了。
四、结尾语
这个案例的价值,不只是产出了多张风险分析结果表,更重要的是把分散的理赔业务数据整理成了更标准、更适合异常检测和风险分级分析的数据结构。通过清洗、关联、异常判断和统计输出,整个处理链路更清晰,也更贴近保险理赔审核与风控分析的实际场景。
按照 AI 工作流配置好处理要求后,不需要手写 Python 和 SQL,也可以把原始理赔数据快速整理成可直接用于审核、筛查和汇报的结果表。

一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)