
保姆级零代码ETL实战|CSV/TXT/Excel三大文件数据抽取全流程,小白也能一键拿捏
哈喽各位数据小伙伴👋 做数据分析、数据仓库、报表开发的朋友,一定绕不开ETL 数据抽取!日常工作里,80% 的原始数据都藏在 CSV、纯文本 TXT、Excel 表格这三类文件中,手动复制粘贴不仅耗时费力,还容易出现格式错乱、数据遗漏、统计失误等问题。
今天这篇超详细实战教程,全程零代码、纯可视化拖拽操作,手把手教大家用通用可视化 ETL 平台,搞定三大主流文件的数据抽取、字段筛选、数据计算、结果输出全流程。从文件准备、组件拖拽、参数配置到流程运行、结果校验,每一步都标注清楚细节和避坑要点,零基础职场新人、在校实训党、业务数据分析岗都能直接上手,看完就能落地实操!
一、先搞懂基础:ETL 文件抽取的核心逻辑 & 前期准备
(一)为什么要用 ETL 抽取文件数据?
ETL 是数据处理的基础流程(抽取 Extract→转换 Transform→加载 Load),针对文件类数据源,相比手动处理优势拉满:
-
适配复杂场景:外部合作方、客户、业务部门交付的数据大多是离线文件,无法直连数据库,文件交换是最主流的对接方式;
-
批量高效处理:上万行数据、多文件联动也能一键运行,告别人工搬运;
-
标准化转换:自动完成日期计算、数据分级、字段筛选,统一数据格式,为后续报表、建模、分析打底;
-
可复用可追溯:搭建好的流程可反复使用,运行日志完整,出错快速定位。
(二)运行环境 & 文件资源准备
本次实操基于在线可视化零代码 ETL 平台(网页端操作,无需本地安装软件),全程浏览器即可完成,核心前期准备分两步:
1. 平台基础操作
-
登录在线数据集成平台,进入「数据集成」核心模块;
-
找到「我的项目」,打开已有项目(也可新建空白项目),所有流程都在项目内搭建;
-
左侧菜单栏核心分区:文件库(存放待处理 / 已输出文件)、组件库(所有数据处理工具,拖拽即用)、公共空间(平台自带示例数据)。
2. 三大示例文件获取(实操必备)
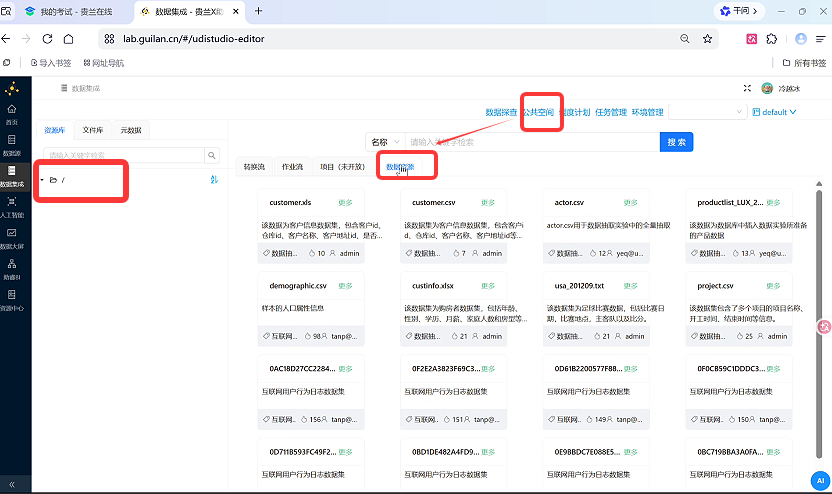
本次实操用到 3 份测试文件,统一从平台「公共空间 - 数据资源」导出到个人项目文件库,操作步骤通用(三个文件操作一致):
-
进入项目页面,点击右侧「公共空间」,切换到数据资源标签;
-
搜索找到对应文件:
project.csv(项目数据)、usa_201209.txt(足球比赛文本数据)、custinfo.xlsx(购房者 Excel 数据); -
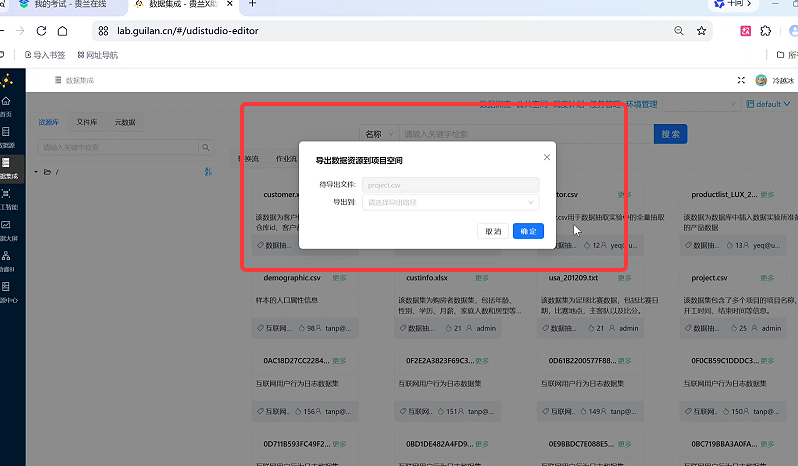
点击文件右侧「更多」→「导出」,弹出窗口选择导出路径(推荐根目录
/),点击「确定」;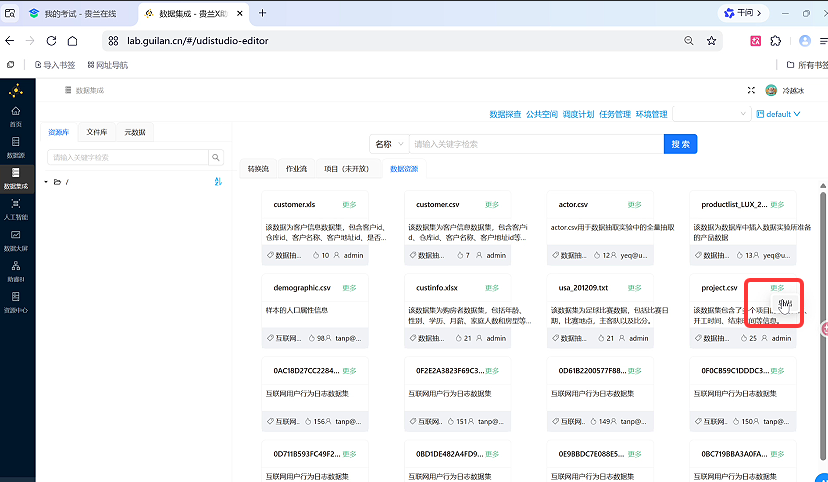
-
切换到左侧「文件库」,右键空白处点击「刷新」,看到对应文件即代表导出成功。
小提示:后续所有文件读取、输出,都基于「文件库」内的文件,路径不要选错!
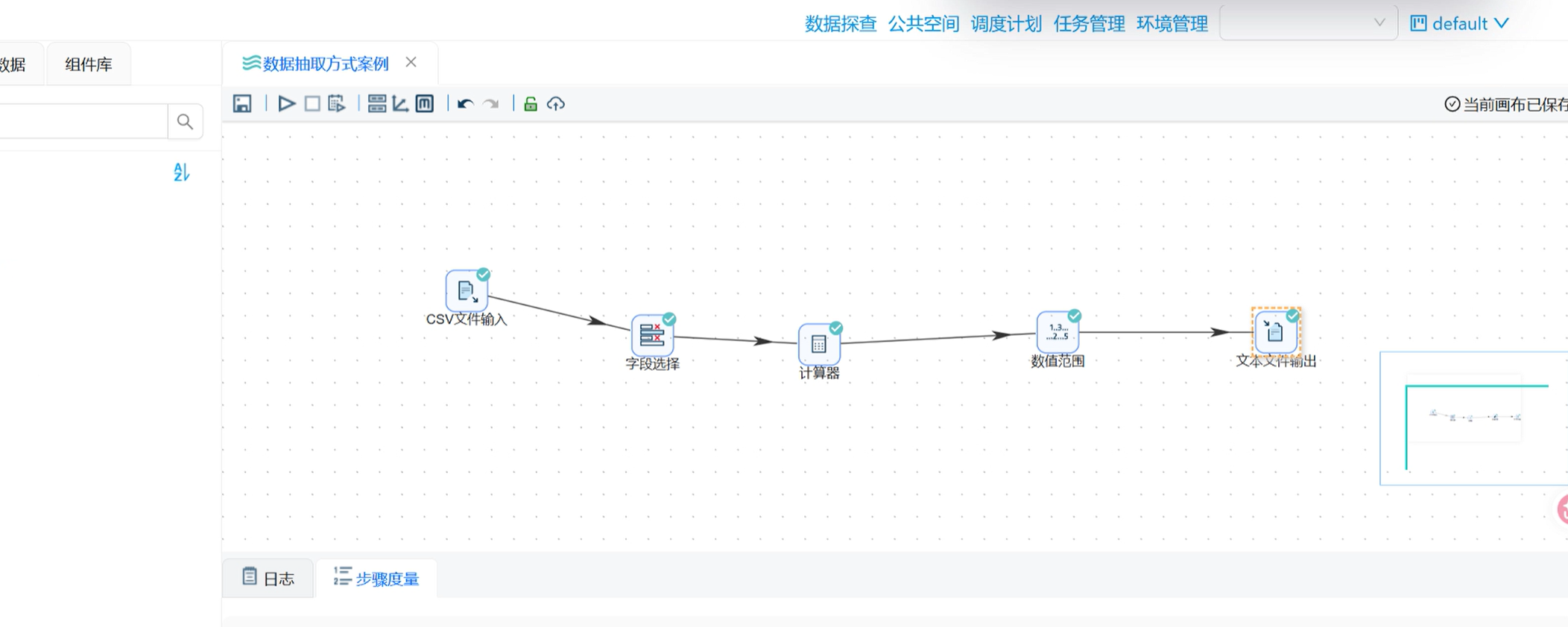
二、实战第一弹:CSV 文件抽取 + 数据计算 + 绩效分级(全流程高阶玩法)
CSV 是数据分析最常用的文件格式,格式简洁、兼容性强。本次案例目标:读取项目 CSV 数据,自动计算项目执行天数,再根据天数划分绩效等级,最终输出标准化结果文件。
涉及组件:CSV 文件输入 → 字段选择 → 计算器 → 数值范围 → 文本文件输出(全部拖拽式搭建,零代码)
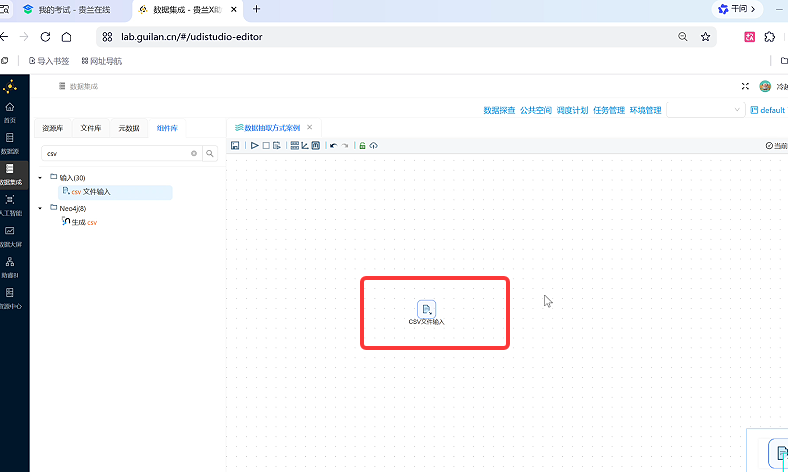
步骤 1:新建转换流,拖拽「CSV 文件输入」组件
-
在项目内新建转换流(ETL 流程载体,所有组件都放在转换流画布上);
-
打开左侧「组件库」,找到「数据源 - 输入」分类,拖拽CSV 文件输入组件到空白画布。
步骤 2:配置 CSV 文件读取(核心参数详解)
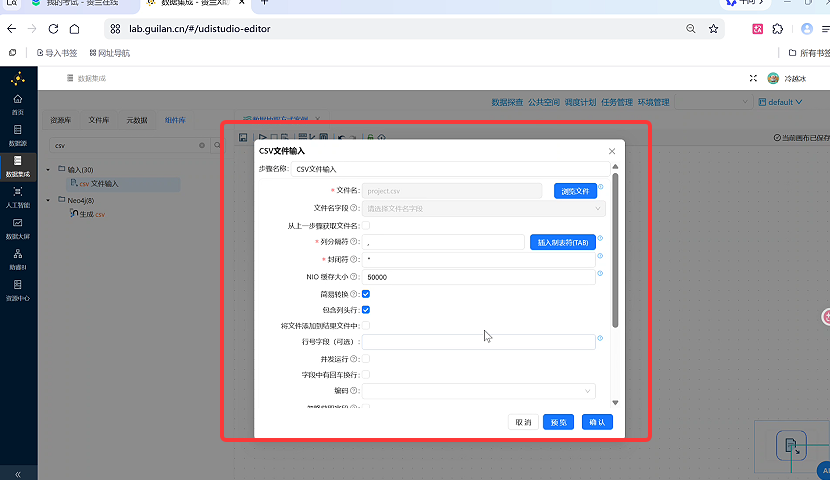
这一步是数据抽取的根基,参数错一个就会读取失败,逐行配置:
-
双击画布上的「CSV 文件输入」组件,打开配置弹窗;
-
点击「浏览文件」,在文件浏览器中选中文件库内的
project.csv,点击「确定」,自动回填文件路径; -
基础参数保持默认:列分隔符(英文逗号)、NIO 缓存大小 50000、勾选包含列头行(CSV 第一行是字段名,必选);
-
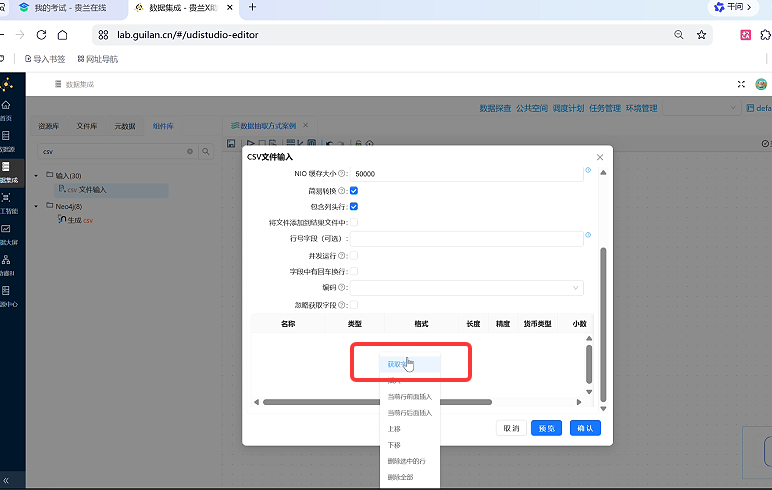
自动解析字段(关键):在组件下方数据区域右键,选择「获取字段」,平台自动识别 CSV 的字段名称、类型;
-
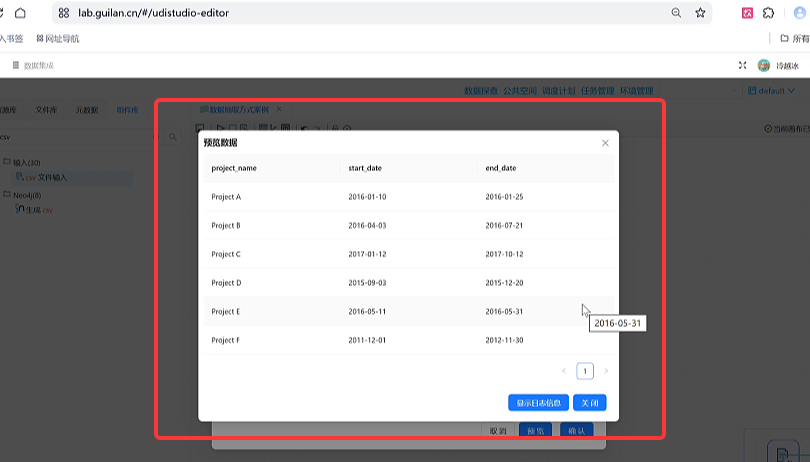
点击「预览」,查看原始数据:包含
project_name(项目名)、start_date(开工日期)、end_date(结束日期)三大字段,数据正常显示后点击「确认」保存配置。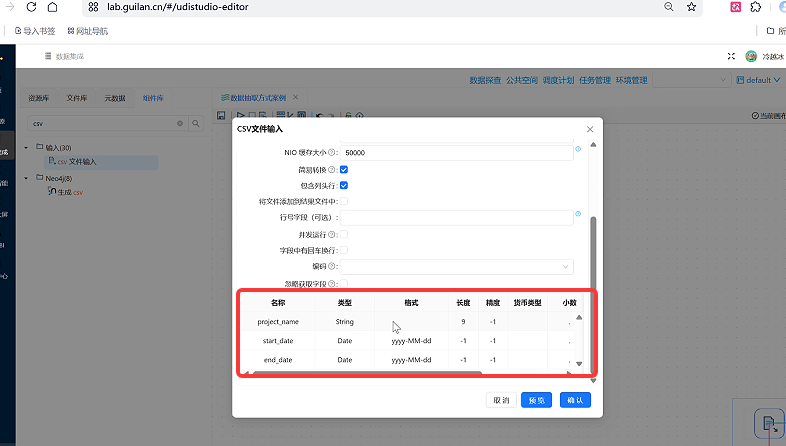
步骤 3:添加「字段选择」组件,精简数据字段
作用:筛选保留有效字段,剔除冗余数据,减轻后续计算压力。
-
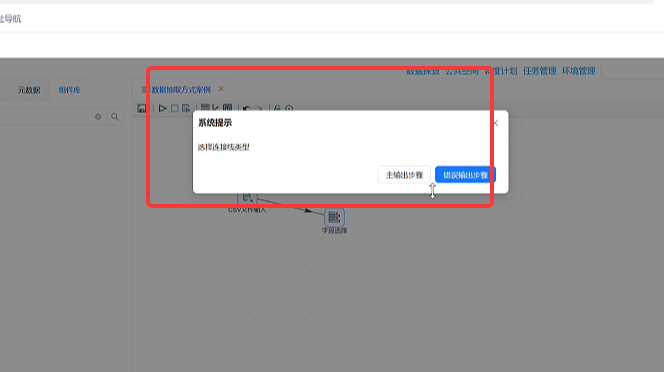
从组件库拖拽字段选择组件到画布,用鼠标连接「CSV 文件输入」→「字段选择」,连接类型选择主输出步骤(正常数据流转,错误数据单独分流,本次暂不处理错误数据);
-
双击「字段选择」打开配置页,在「选择和修改」标签下右键→「获取字段」,自动加载上游 CSV 的所有字段;
-
本案例保留全部 3 个原始字段,无需删除 / 改名,直接点击「确认」。
步骤 4:添加「计算器」组件,计算项目执行天数
核心需求:用结束日期 - 开工日期,算出项目运行天数,生成新字段diff_date。
-
拖拽计算器组件,连接「字段选择」→「计算器」,依旧选择「主输出步骤」;
-
双击计算器进入配置页,点击「插入」新增一条计算规则:
-
新字段:手动输入
diff_date(自定义字段名,存储天数结果); -
计算规则:下拉选择
Date A - Date B (in days)(日期相减,输出天数); -
字段 A:选择
end_date(结束日期); -
字段 B:选择
start_date(开工日期); -
值类型:选择
Integer(整数类型,天数为整数);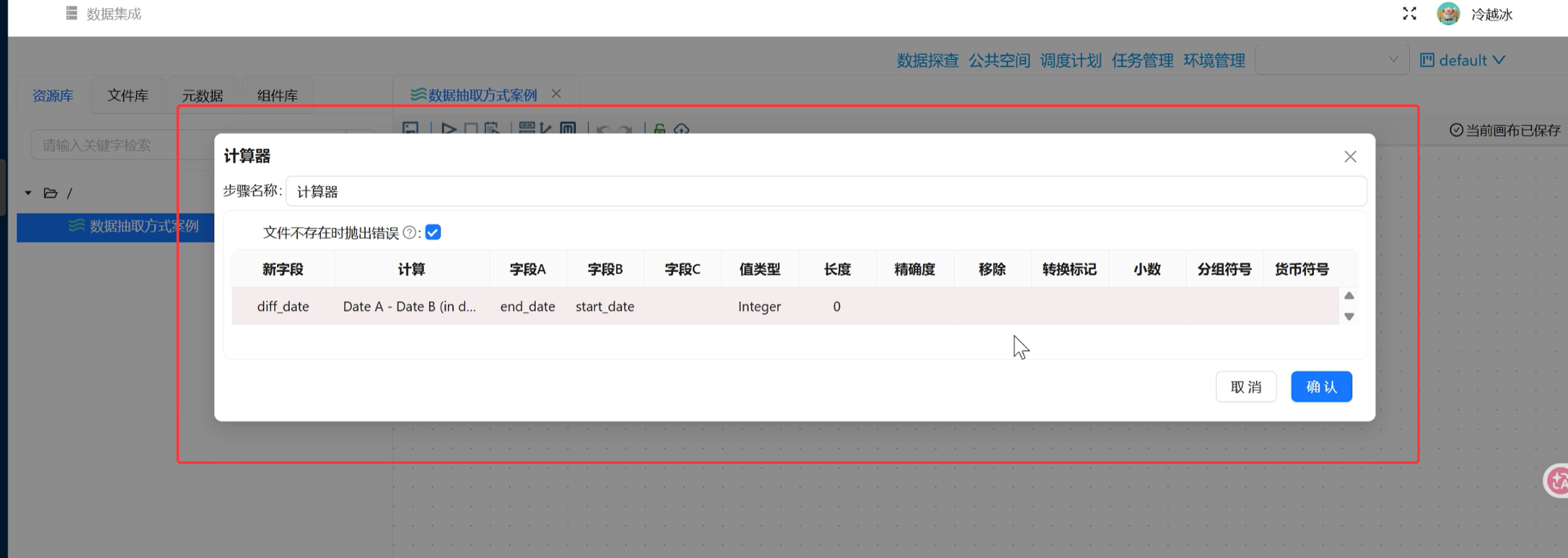
-
-
配置完成点击「确认」,此时数据中已新增「执行天数」字段。
步骤 5:添加「数值范围」组件,自动划分绩效等级
根据项目执行天数,自动生成performance(绩效)字段,分级规则提前约定:
|
执行天数区间 |
绩效等级 |
|
0 ≤ 天数 < 30 |
excellent(优秀) |
|
30 ≤ 天数 < 180 |
very good(良好) |
|
180 ≤ 天数 < 360 |
good(合格) |
|
天数 ≥ 360 |
poor(较差) |
-
拖拽数值范围组件,连接「计算器」→「数值范围」;
-
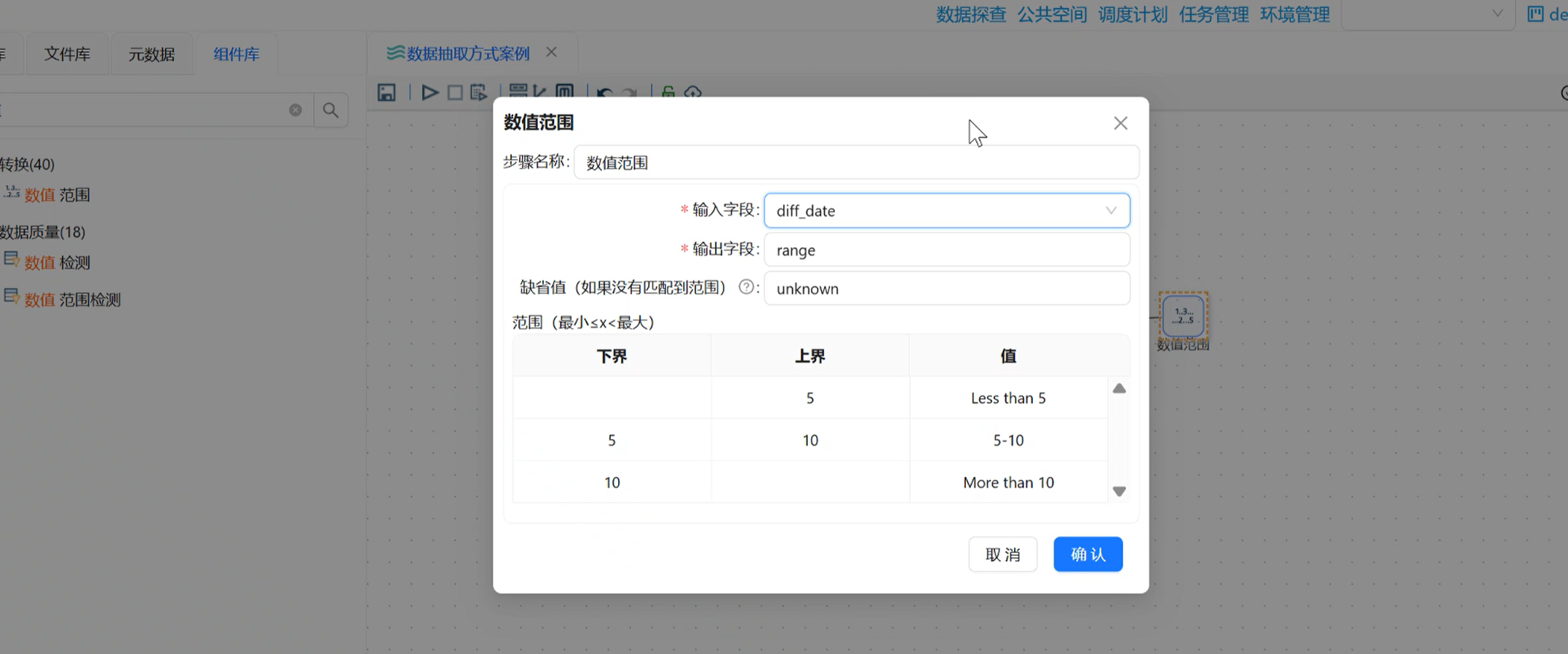
双击打开配置页:
-
输入字段:选择刚计算出的
diff_date(以天数为判断依据); -
输出字段:手动输入
performance(存储绩效结果); -
按照上表依次配置下界、上界、对应评价值;
-
-
核对区间无误后,点击「确认」保存。
步骤 6:添加「文本文件输出」组件,导出最终结果
将加工完成的全量数据,导出为新 CSV 文件,落地保存结果。
-
拖拽文本文件输出组件,连接「数值范围」→「文本文件输出」;
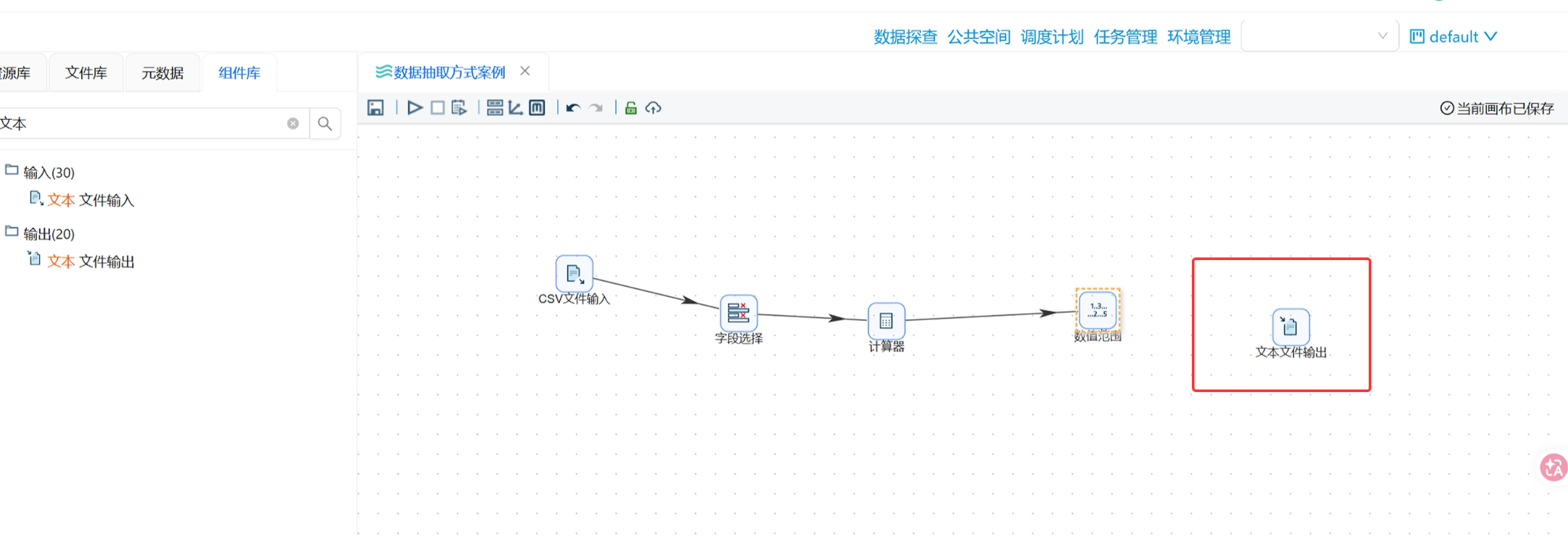
-
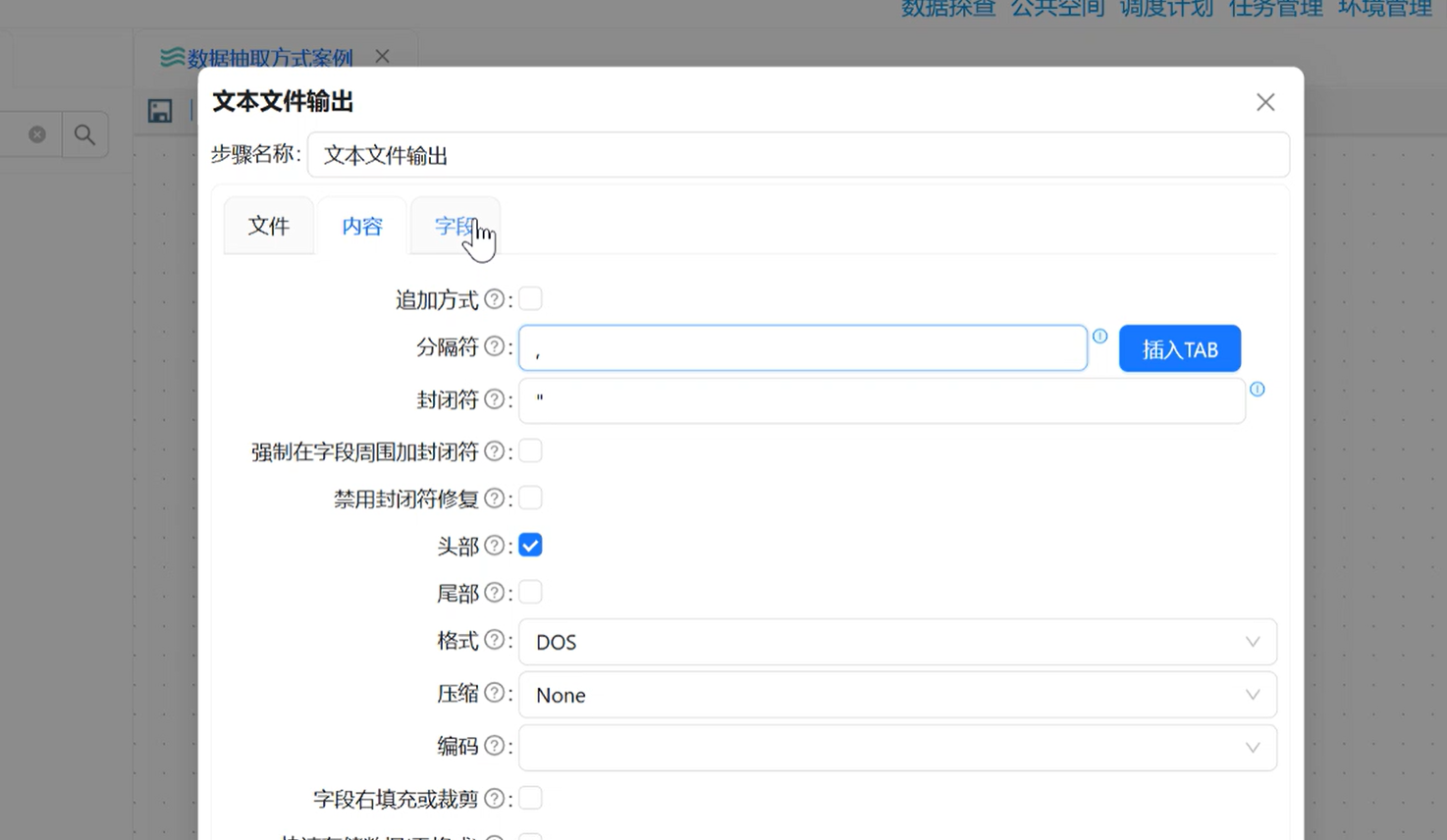
双击组件,分 3 个标签页精细化配置:
-
【文件】标签:文件名称填
project_output,扩展名填csv(最终生成 project_output.csv); -
【内容】标签:分隔符修改为英文逗号,(和标准 CSV 格式统一,必改!中文分号会导致格式错乱);
-
【字段】标签:右键→「获取字段」,加载所有上游字段(项目名、日期、天数、绩效),全部保留;
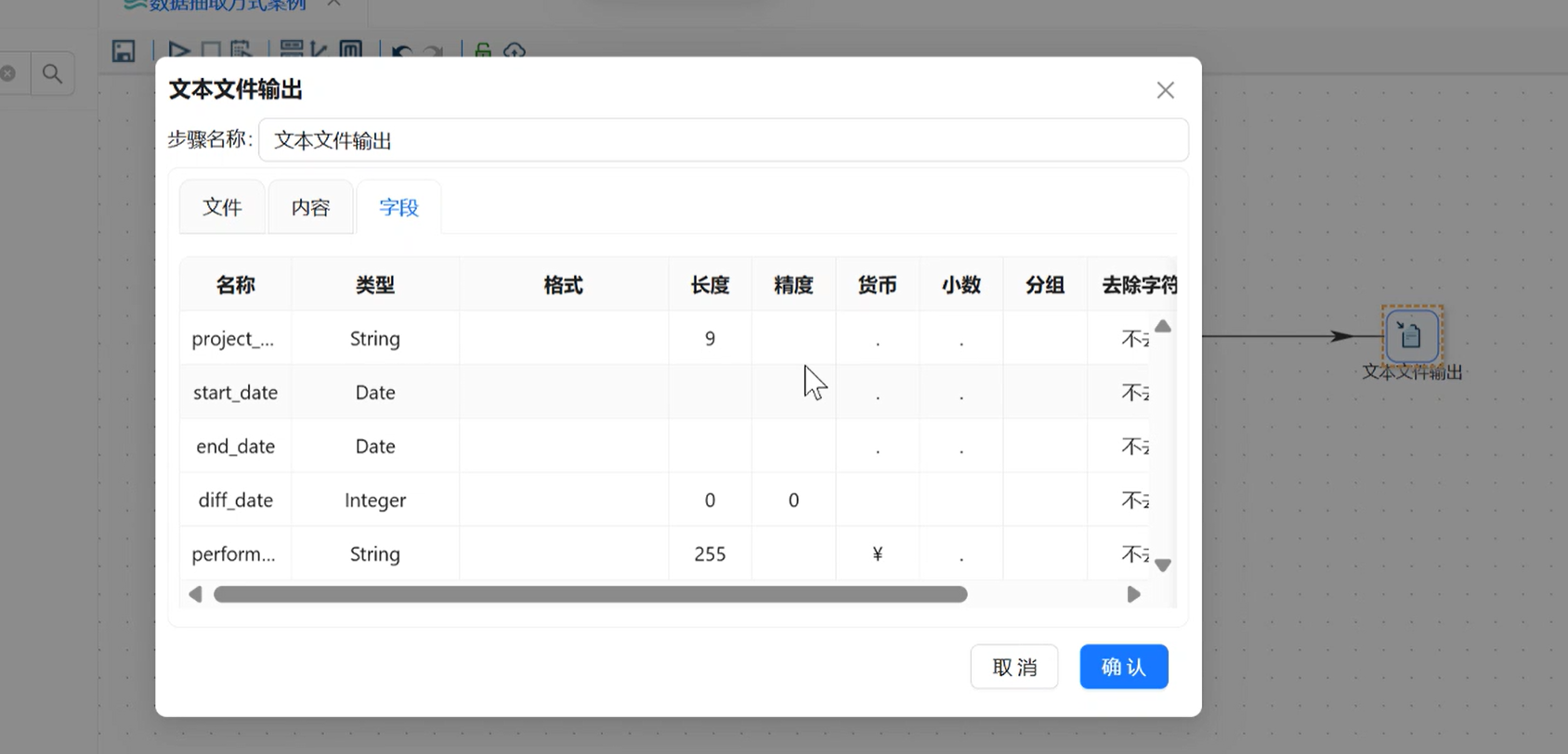
-
-
全部配置完成,点击「确认」。
步骤 7:运行全流程 + 结果校验
-
检查完整链路:CSV 文件输入 → 字段选择 → 计算器 → 数值范围 → 文本文件输出(链路无断开);
-
点击画布左上角「运行」→「启动」,执行 ETL 流程;
-
查看运行日志:所有组件状态显示「已完成」,记录数匹配原始数据(6 条),无报错、无拒绝数据;
-
回到「文件库」,刷新后找到
project_output.csv,预览数据:每条数据都包含计算后的天数和自动划分的绩效等级,CSV 抽取 + 转换流程圆满完成!
📌 CSV 避坑总结:
分隔符必须和文件本身一致(默认英文逗号);
含表头的文件一定要勾选「包含列头行」;
日期计算务必选择对应日期函数,字段 A/B 不要填反。
三、实战第二弹:TXT 纯文本文件抽取 + 字段筛选(轻量数据校验)
很多日志数据、赛事数据、流水数据都会用 TXT 文本存储,这类文件大多自定义分隔符,读取难点在于匹配分隔符。本次案例:读取足球比赛 TXT 数据,剔除无用字段,验证数据流转完整性。
涉及组件:CSV 文件输入(通用读取 TXT) → 字段选择 → 空操作(数据校验)
步骤 1:新建转换流,拖拽读取组件
-
新建空白转换流,依旧拖拽CSV 文件输入组件(平台通用组件,可兼容标准 TXT 文本);
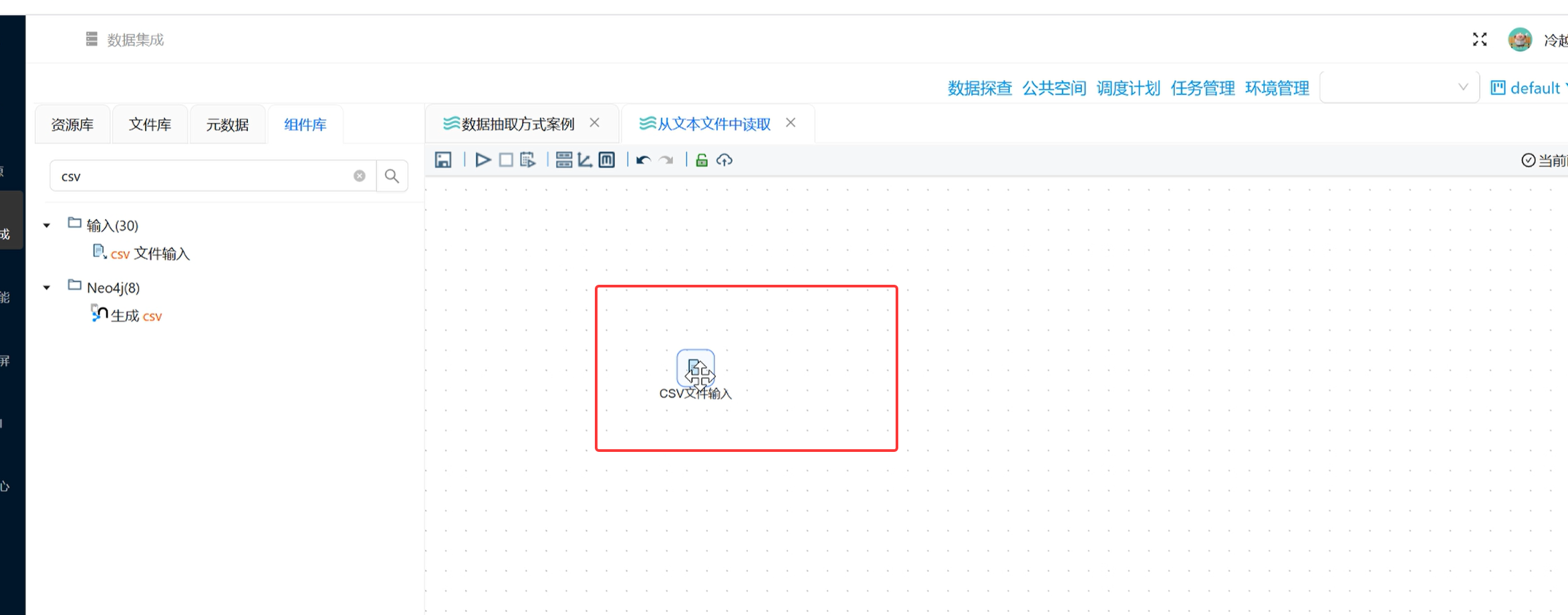
-
双击组件,点击「浏览文件」,选中文件库内的
usa_201209.txt比赛数据文件。
步骤 2:重点配置 TXT 专属参数(分隔符是核心)
TXT 没有统一格式,分隔符由文件制作者自定义,本次文件使用英文分号; 分割列,配置如下:
-
列分隔符:下拉选择 / 手动输入 英文分号;(重中之重!选错直接乱码、列错位);
-
勾选「包含列头行」(文件第一行为字段名:比赛日期、地点、国家、比分等);
-
右键数据区域→「获取字段」,自动解析 TXT 所有字段;
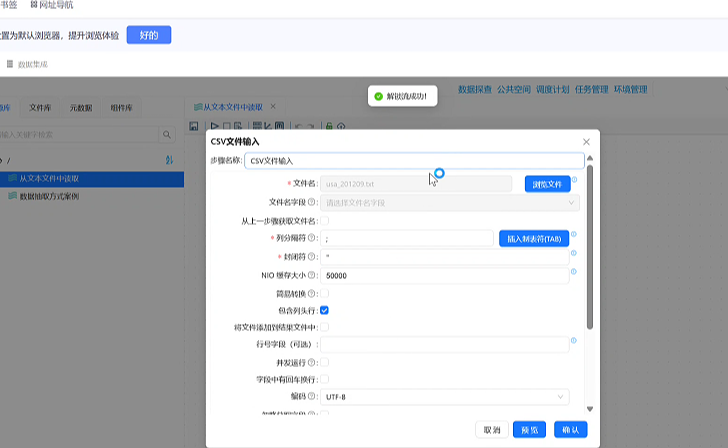
-
点击「预览输出」,查看原始比赛数据,确认列分割正常、数据无错乱后,点击「确认」。
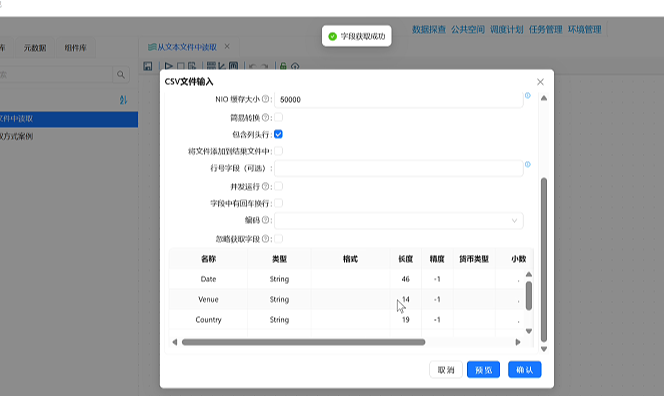
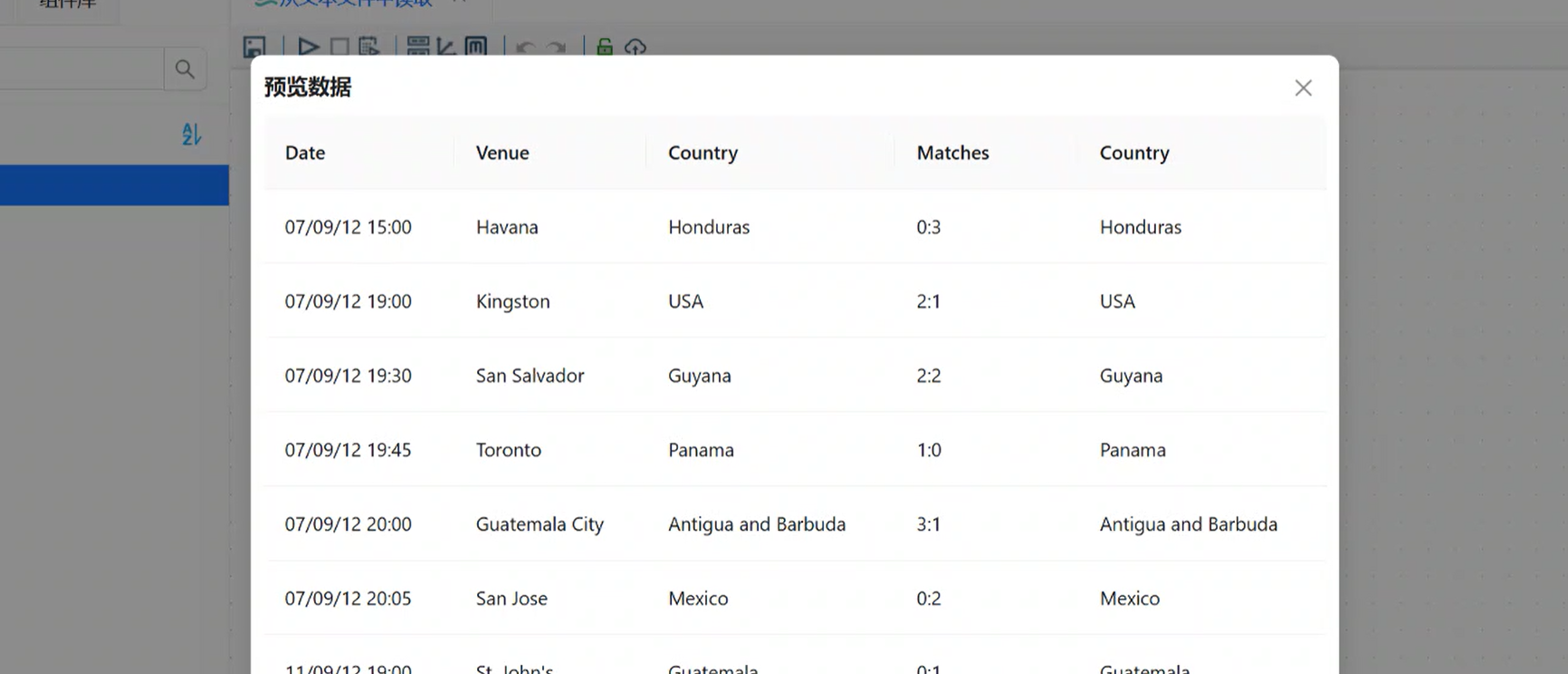
步骤 3:字段筛选,剔除无用列
业务需求:仅保留比赛日期、国家、比分,删除Venue(比赛地点)字段。
-
拖拽字段选择组件,连接「CSV 文件输入」→「字段选择」,选择主输出步骤;
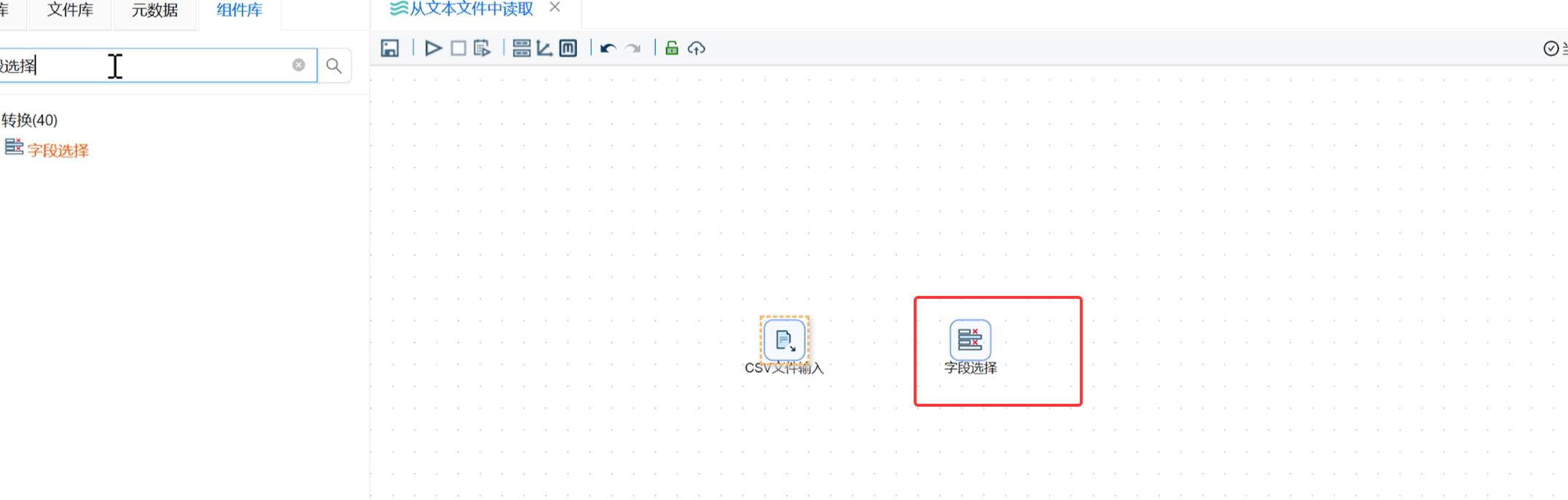
-
双击组件,切换到移除标签页;
-
右键→「获取字段」,加载全部字段,选中
Venue字段,点击「删除选中的行」(代表剔除该字段);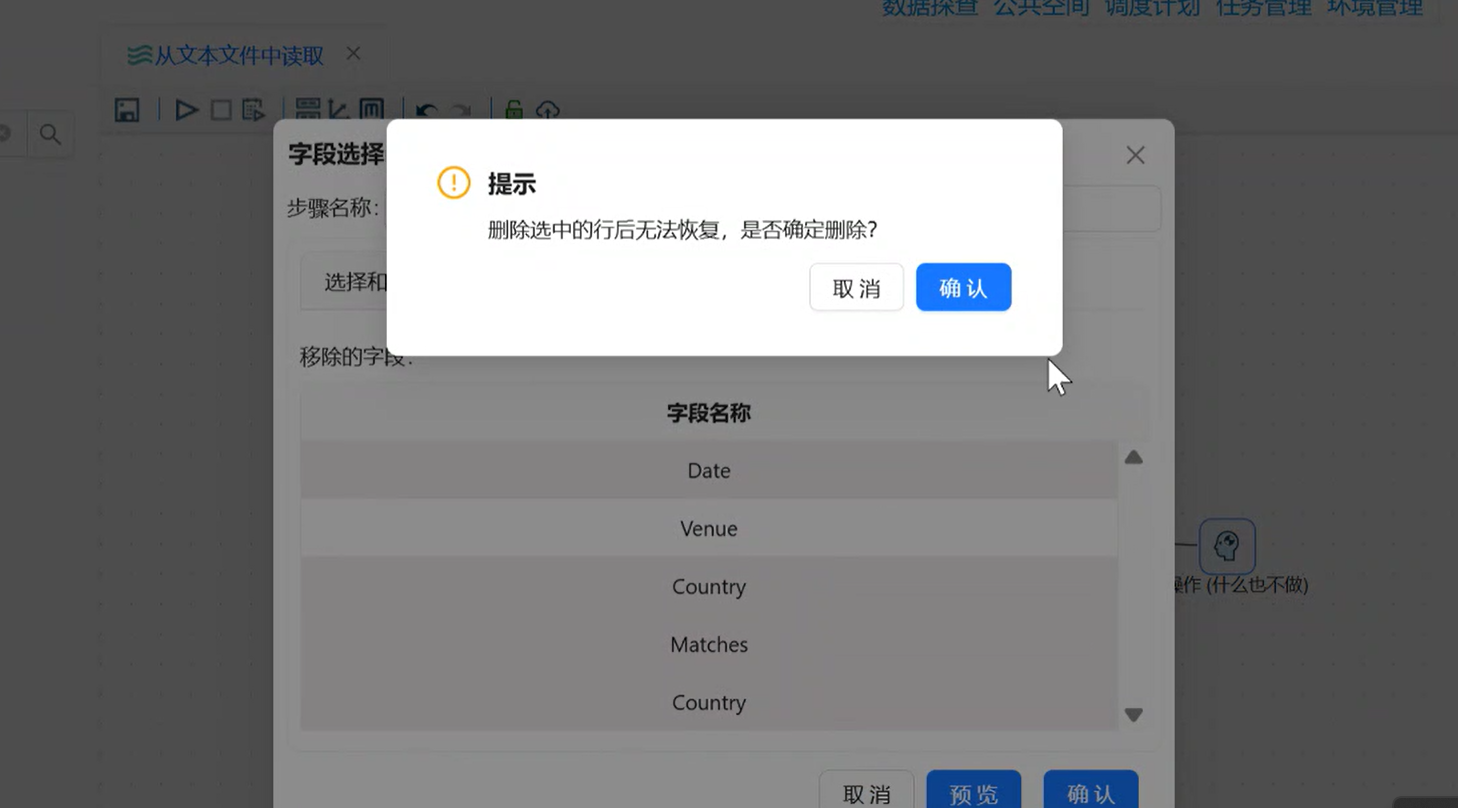
-
确认移除列表仅保留
Venue,点击「确认」。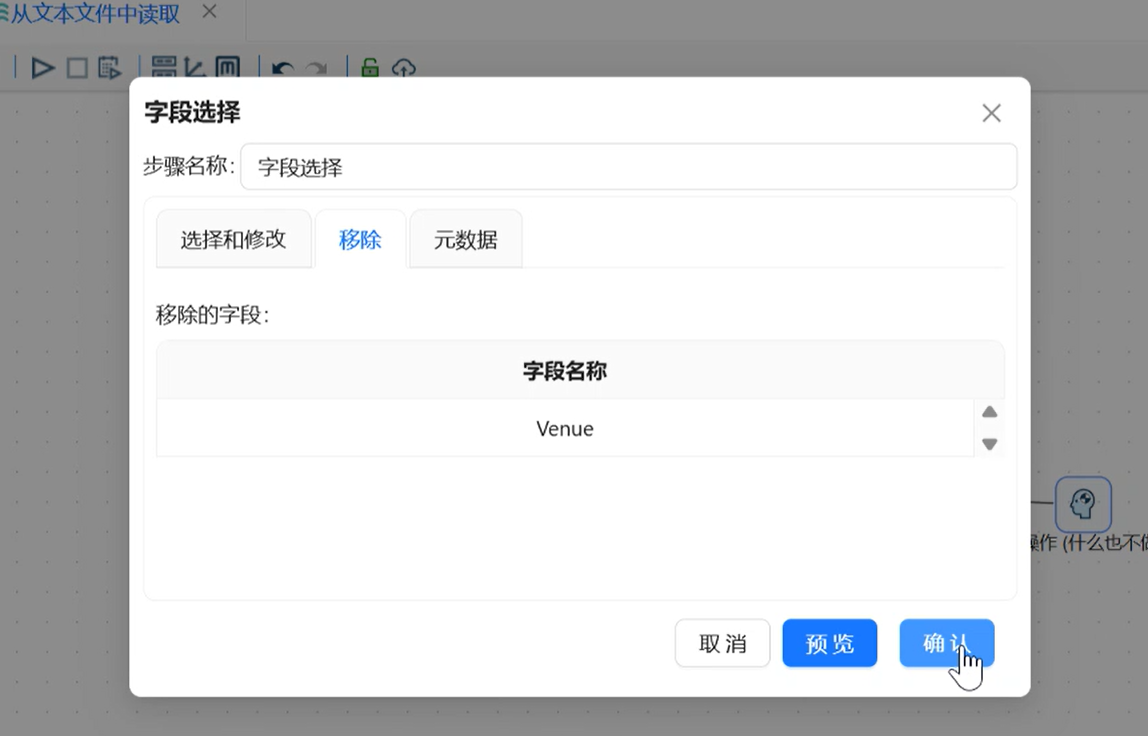
步骤 4:添加「空操作」组件,校验数据流转
「空操作(什么也不做)」是 ETL 调试神器:只接收数据、不做任何加工,专门用来验证整条流程是否通畅、字段筛选是否生效。
-
拖拽空操作组件,连接「字段选择」→「空操作」;
-
无需任何配置,组件默认即可。
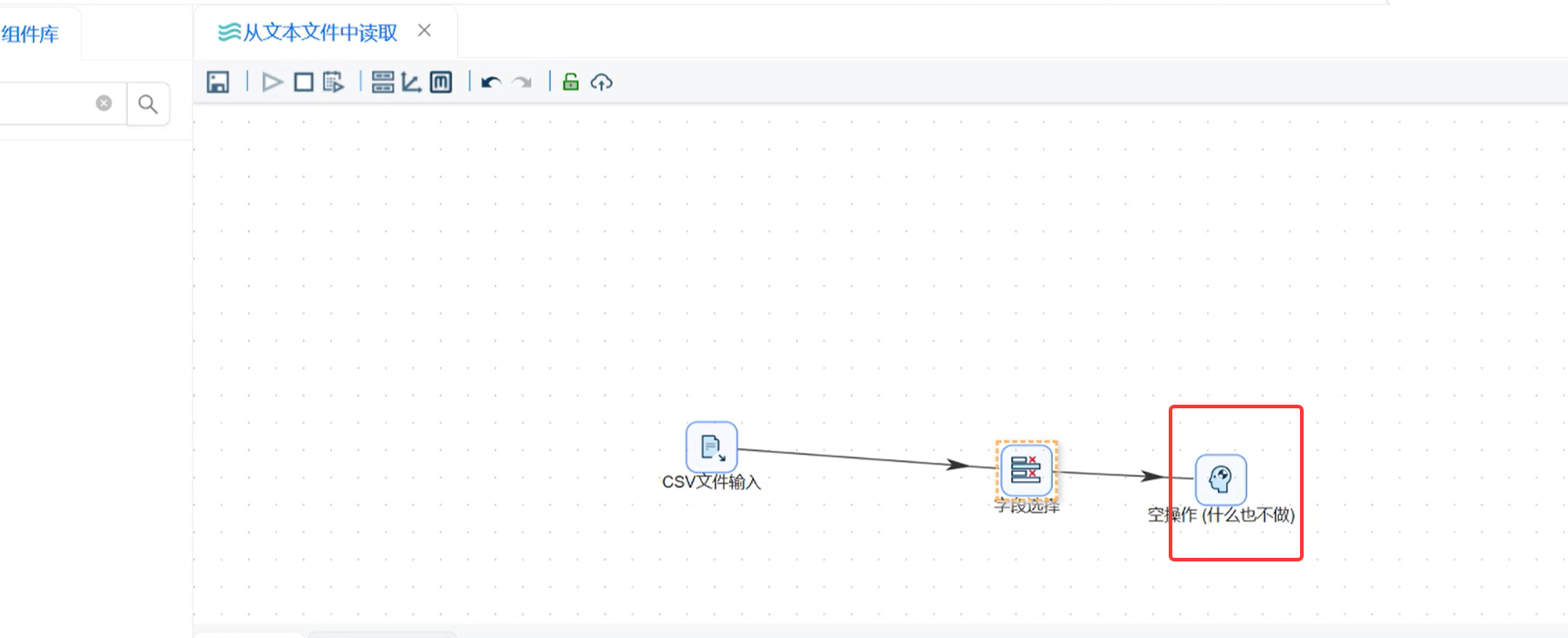
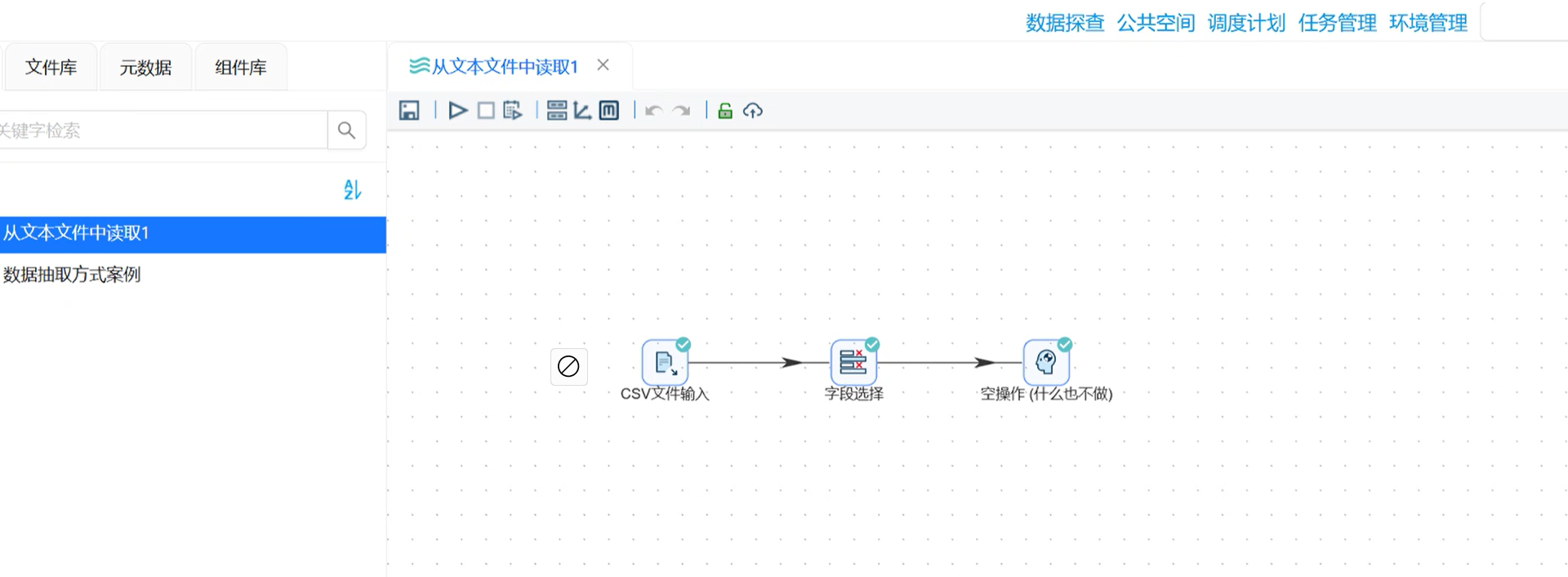
步骤 5:运行流程 + 结果验证
-
完整链路:CSV 文件输入 → 字段选择 → 空操作;
-
点击「运行 - 启动」,查看日志:14 条比赛数据全部正常流转,无报错;
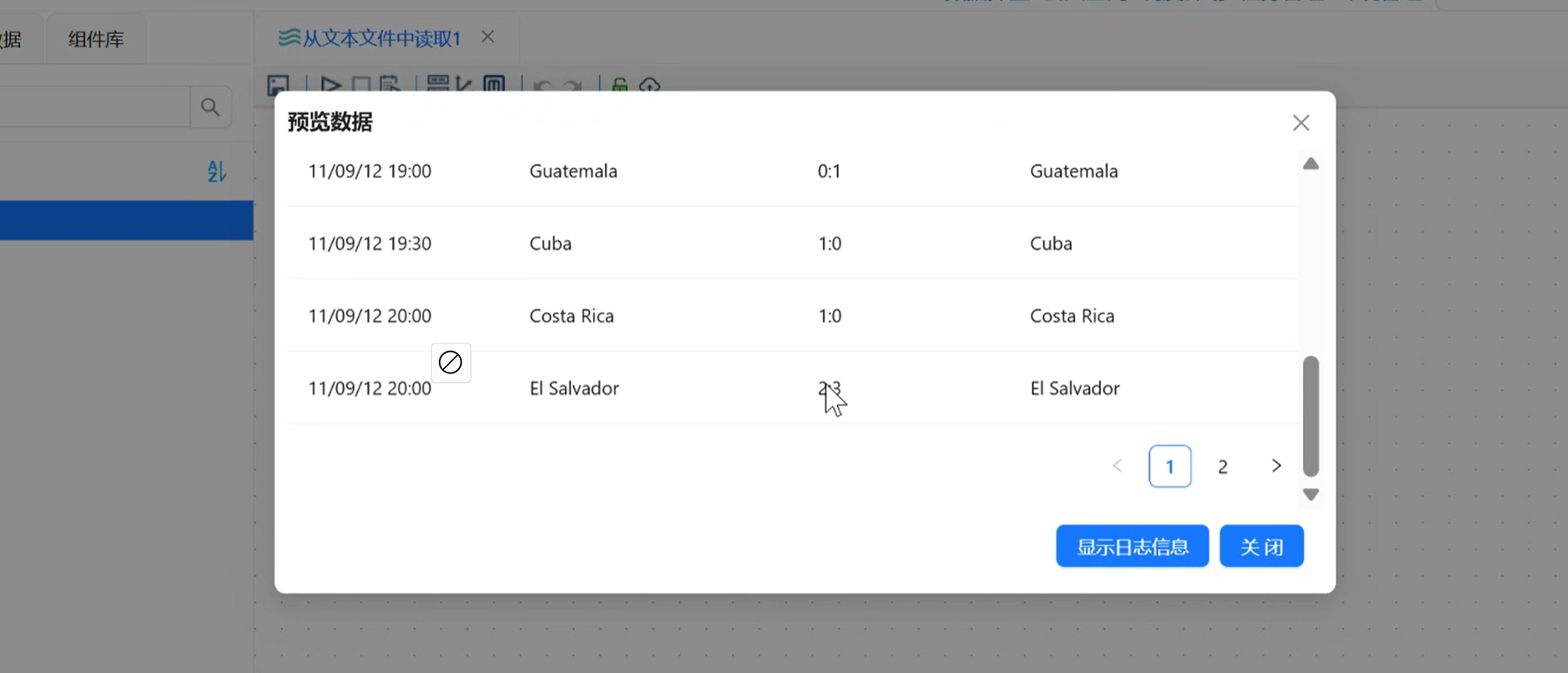
-
右键「空操作」→「预览输出」:数据中已彻底删除「比赛地点」字段,剩余字段完整、数据无误,TXT 抽取流程完成。
📌 TXT 文本避坑总结:
优先查看原始 TXT 文件,确认分隔符(逗号、分号、制表符 Tab 最常见);
区分英文符号 / 中文符号,90% 的读取错误都是符号混用导致;
不确定格式时,先用「预览」功能测试,再继续后续流程。
四、实战第三弹:Excel 文件抽取 + 精准字段筛选(办公文件标配)
Excel 是职场最常用的表格文件,分为.xlsx(新版)和.xls(旧版),平台有专属 Excel 读取组件,支持多工作表、表头识别、非空数据过滤。本次案例:读取购房者 Excel 信息,筛选出「学历、职业」两大核心分析字段。
涉及组件:Excel 输入 → 字段选择 → 空操作(数据校验)
步骤 1:新建转换流,拖拽「Excel 输入」专属组件
-
新建转换流,在组件库找到Excel 输入组件(不要用 CSV 组件读取 Excel,兼容性差),拖拽到画布;
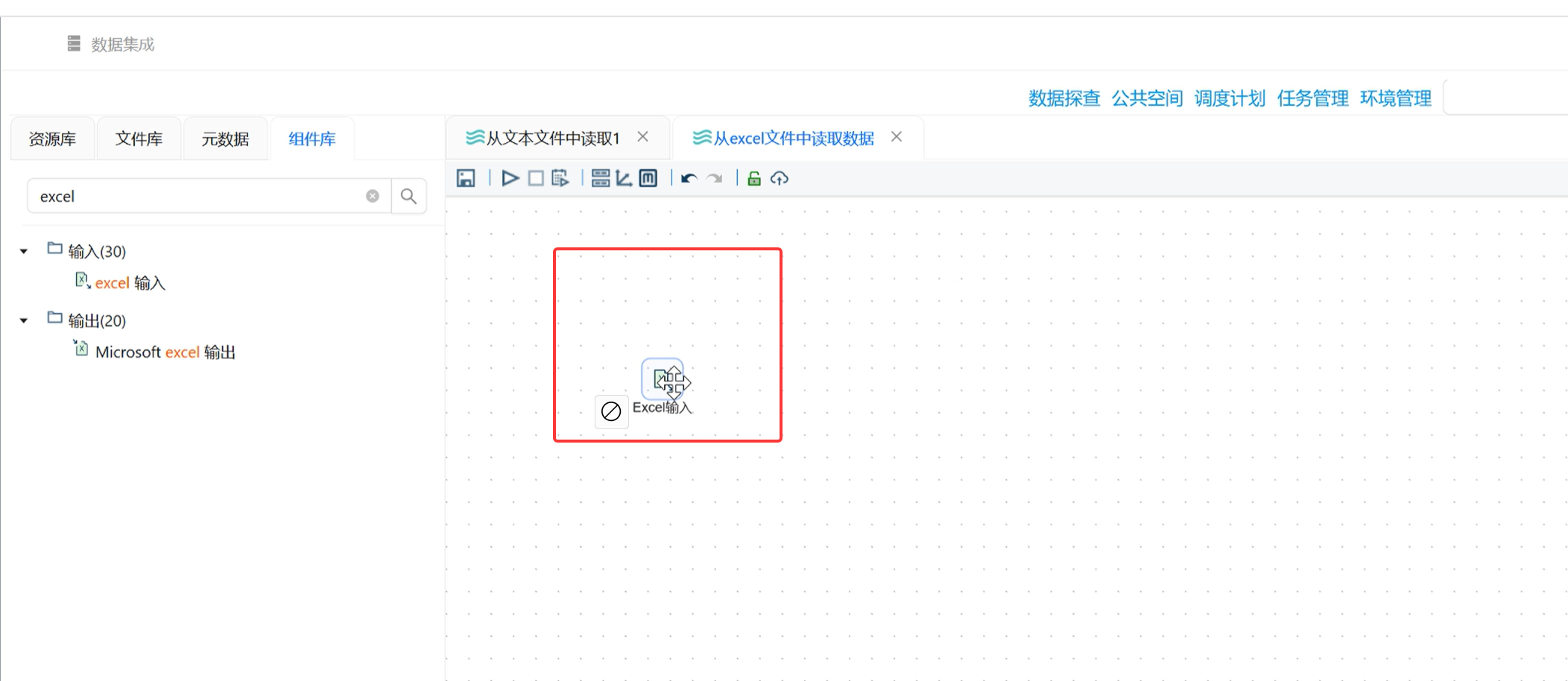
-
双击组件,进入多标签配置页(文件、工作表、内容、字段四大核心标签)。
步骤 2:【文件】标签:选择 Excel 文件 & 解析引擎
-
表格类型(引擎):选择
Excel XLSX (Streaming)(适配主流新版 xlsx 格式); -
点击「浏览」选中文件库内的
custinfo.xlsx,再点击「增加」,将文件加入「选中的文件」列表(必须点增加,否则读取不到文件);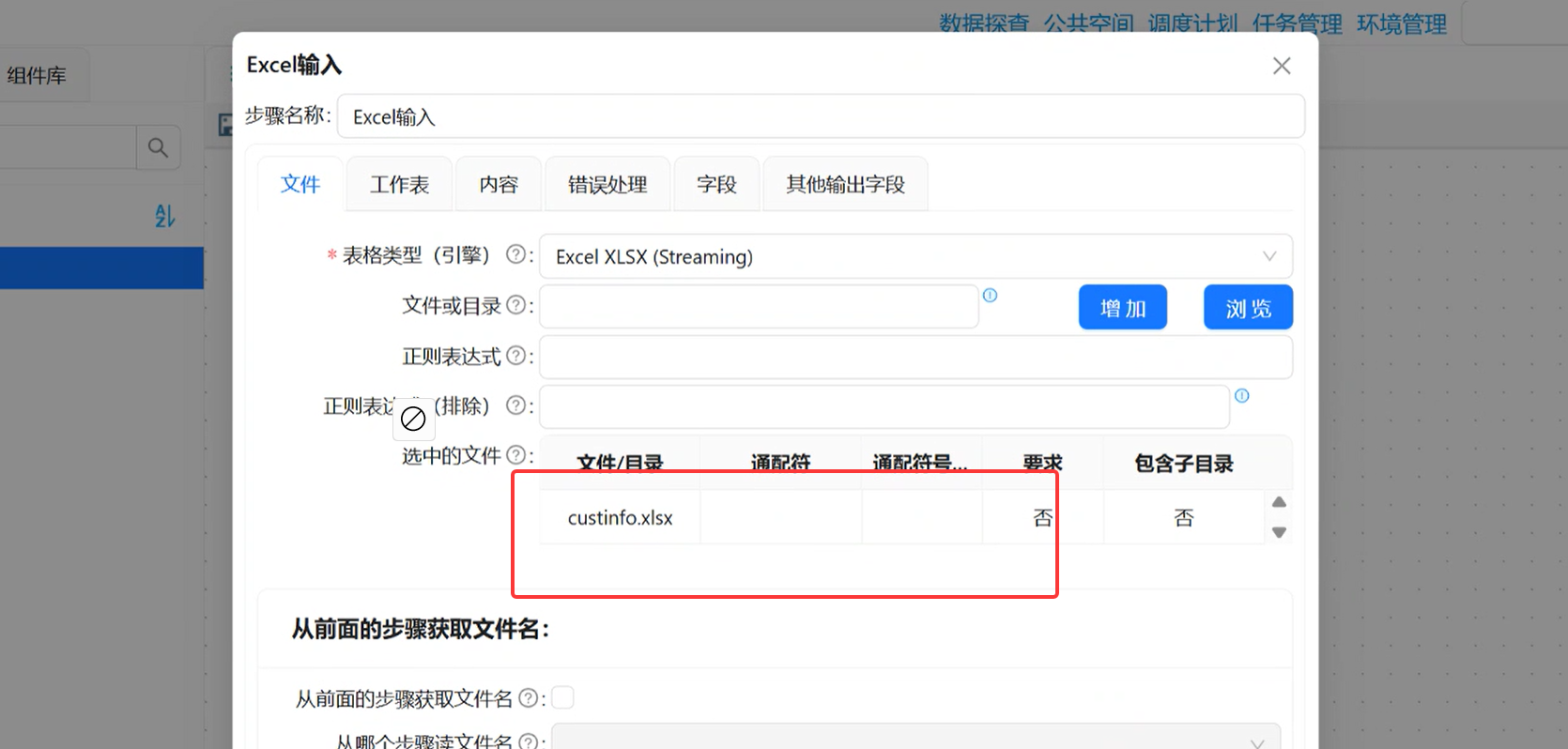
步骤 3:【工作表】标签:选择读取指定工作表
Excel 文件可包含多个工作表,需指定读取哪一张:
-
切换到「工作表」标签,点击「获取工作表名称」,平台自动读取文件内所有工作表;
-
选中
Sheet1(本次数据所在工作表),点击中间箭头添加到右侧读取列表;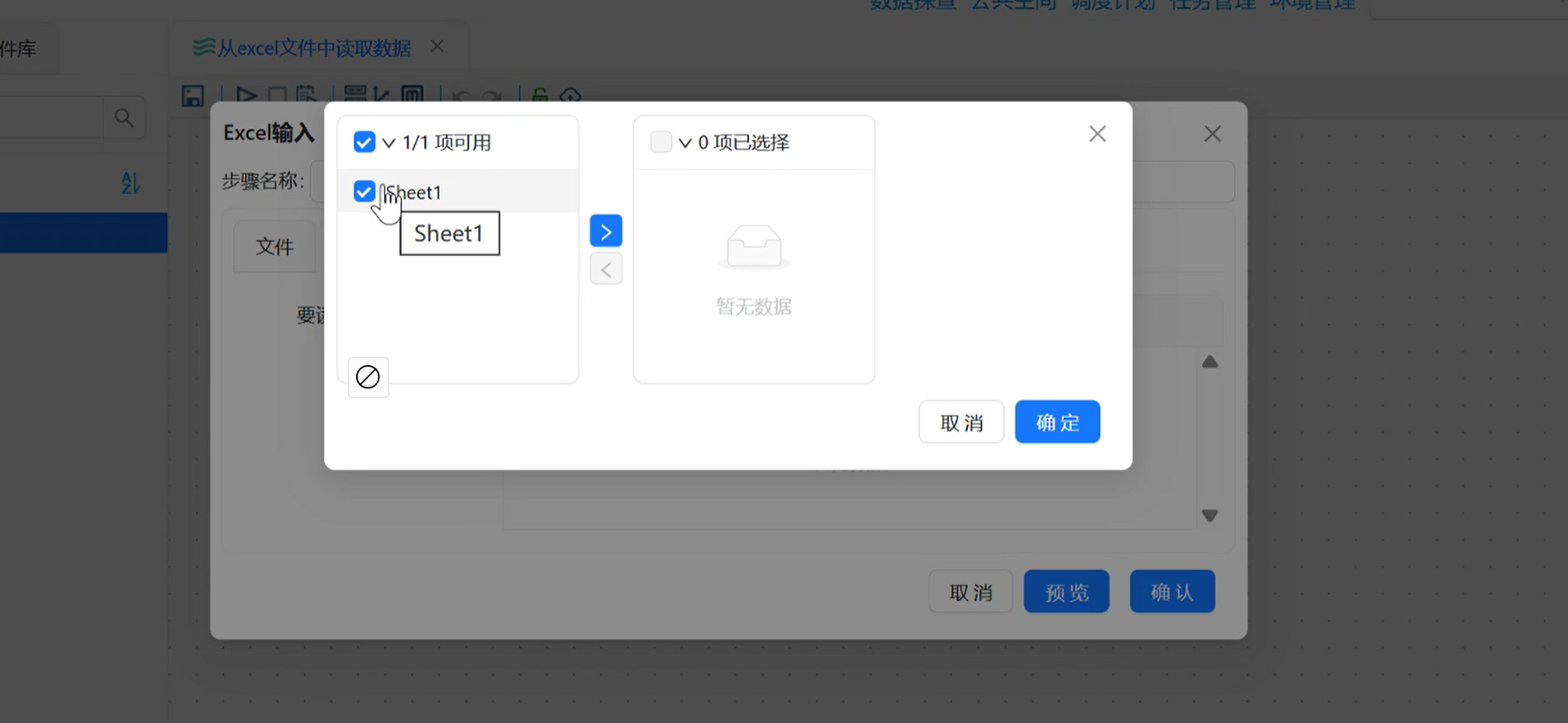
-
确认仅读取 Sheet1,跳过空工作表。
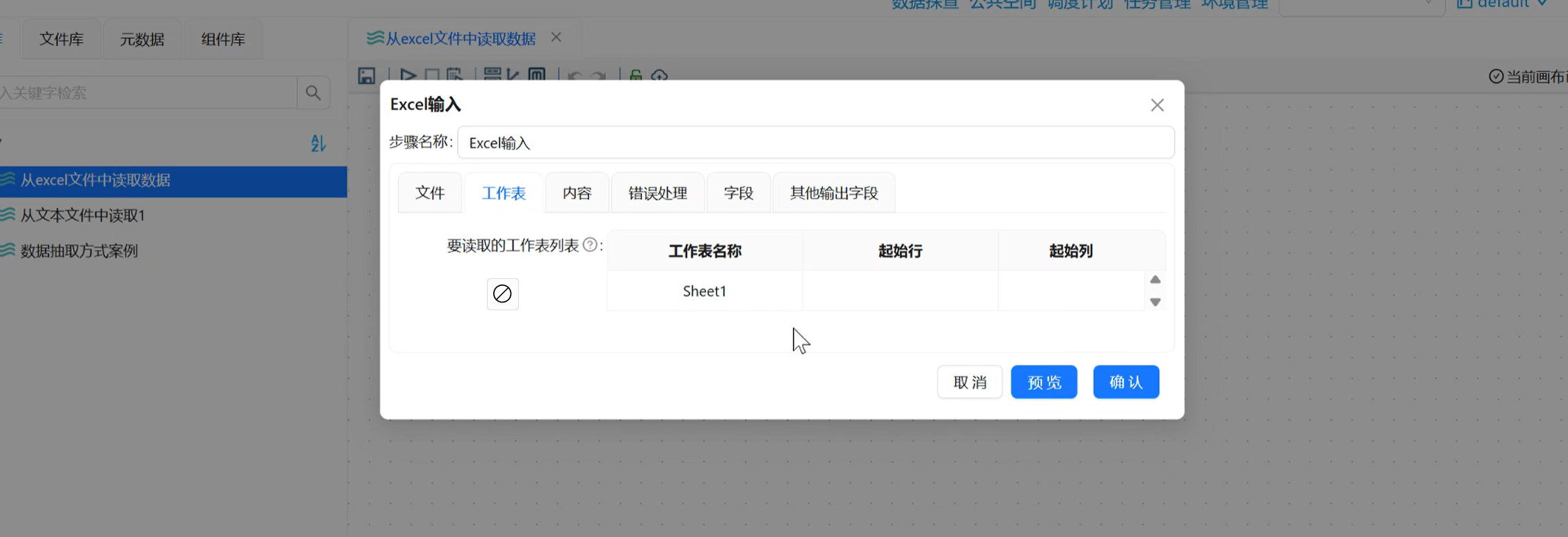
步骤 4:【内容】标签:设置表头、数据过滤、编码
-
勾选头部(Excel 第一行为字段名)、非空记录(自动过滤空白行,避免无效数据);
-
编码下拉选择
UTF-8(通用编码,防止中文乱码); -
「停在空记录」不勾选,「限制行数」保持 0(读取全量数据)。
步骤 5:【字段】标签:自动解析表格字段
切换到「字段」标签,右键空白处 → 获取来自头部的字段,平台自动读取 Excel 表头,生成字段列表(年龄、性别、学历、月薪、家庭人数、房型等),字段类型自动识别为数值型,点击「确认」保存 Excel 读取配置。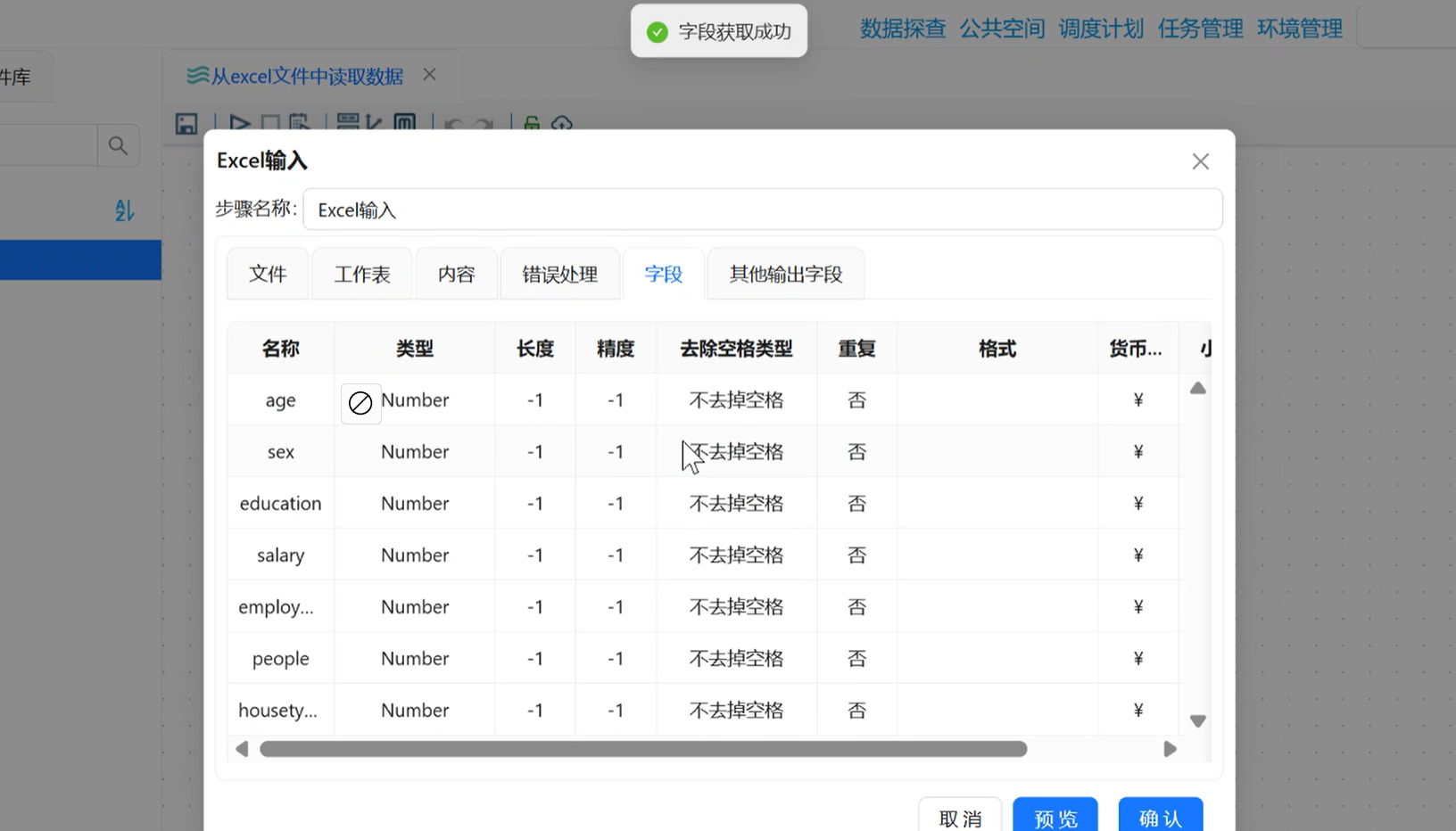
步骤 6:字段选择,筛选目标分析字段
业务需求:仅保留education(学历)、employment(职业)两个字段,用于后续购房行为分析。
-
拖拽字段选择组件,连接「Excel 输入」→「字段选择」;
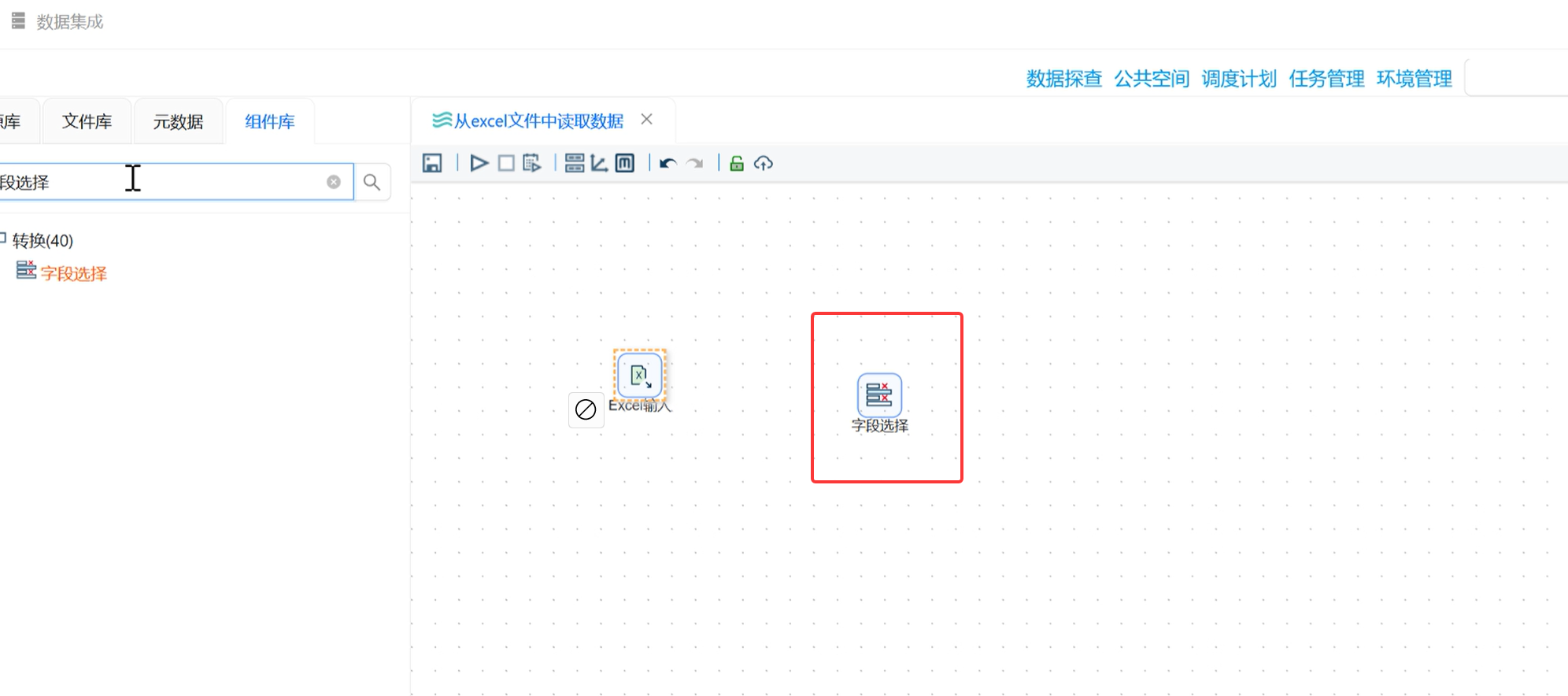
-
双击组件,「选择和修改」标签下右键→「获取字段」,加载全部 Excel 字段;
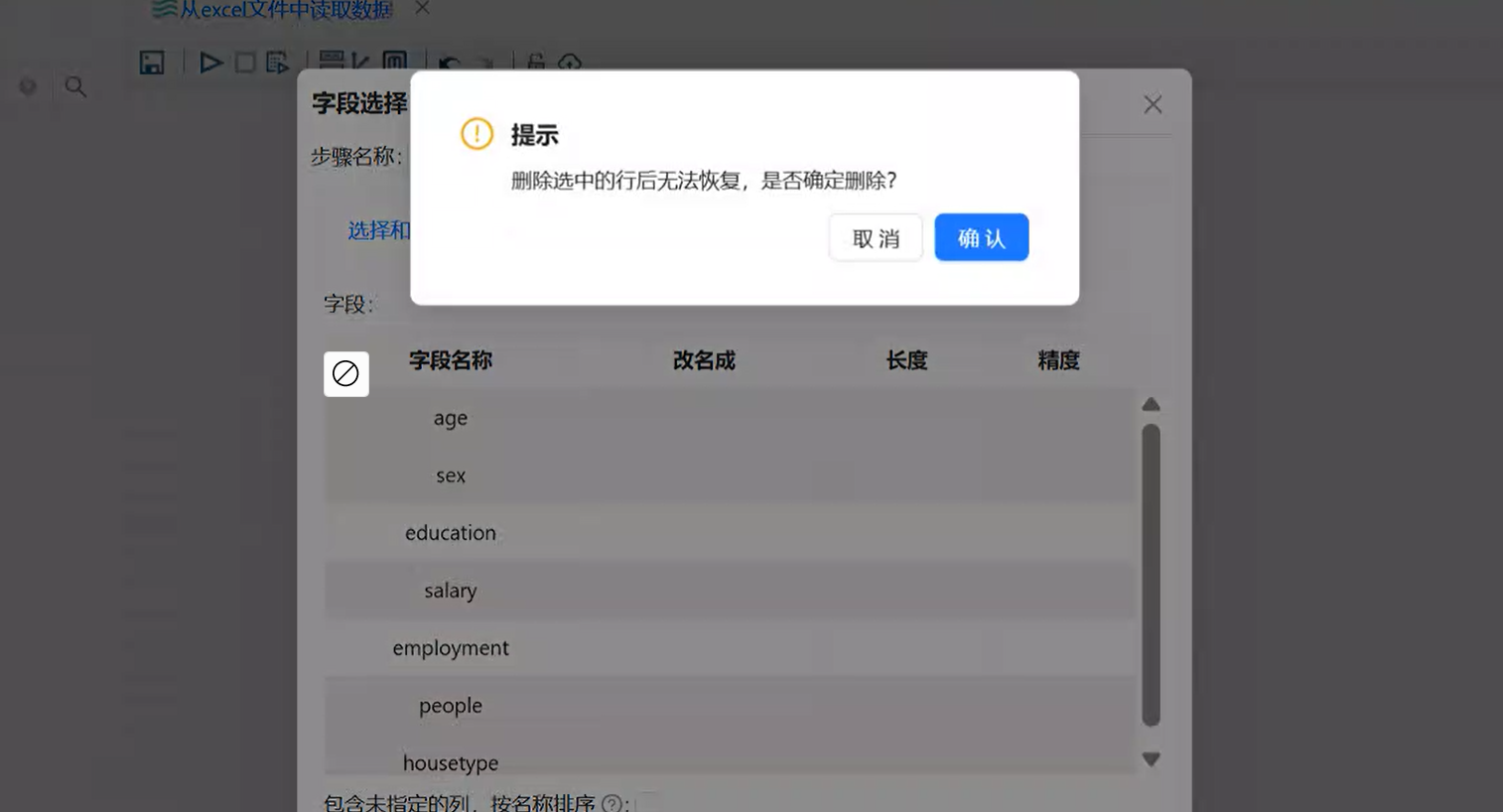
-
只保留
education和employment两个字段,删除其余所有字段; -
点击「确认」完成筛选。
步骤 7:空操作校验 + 流程运行
-
拖拽「空操作」组件,搭建完整链路:Excel 输入 → 字段选择 → 空操作;
-
启动流程,查看日志:400 条购房者数据全部正常读取、流转;
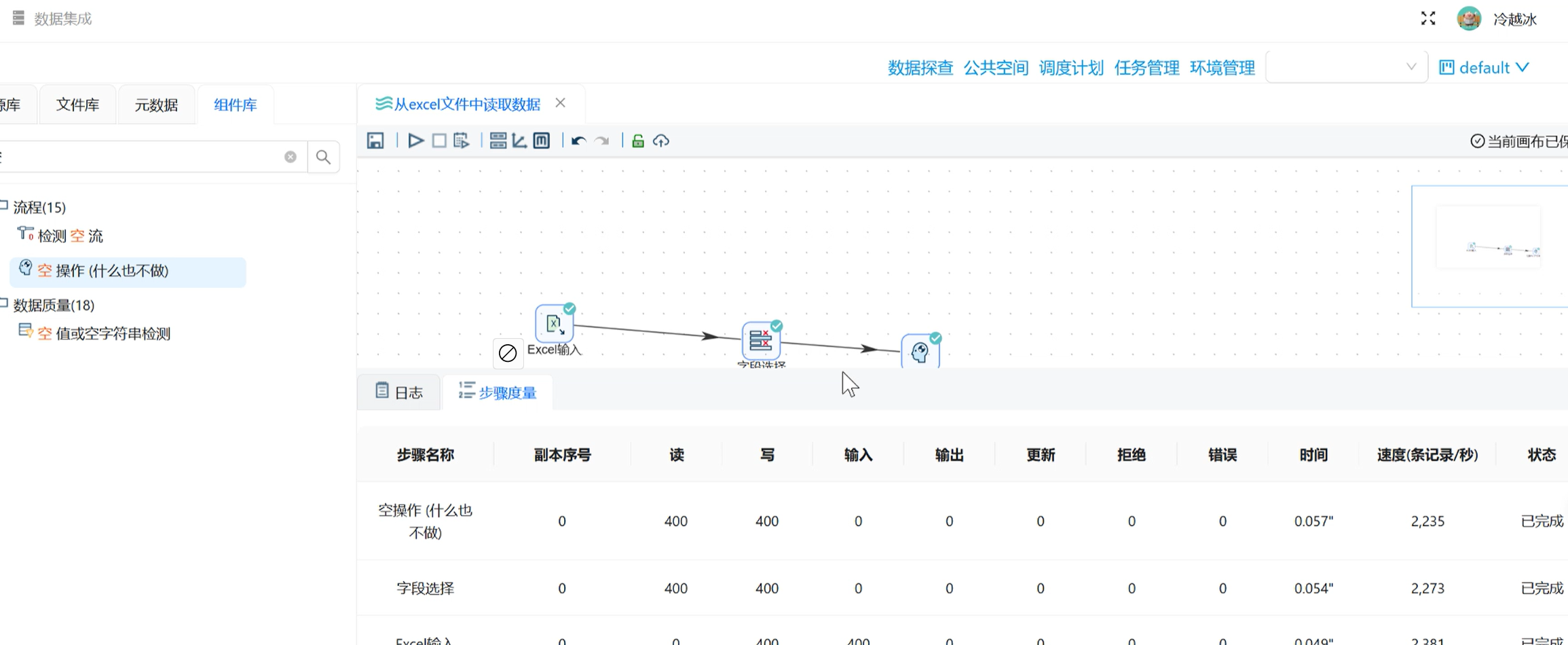
-
预览「空操作」输出结果:仅展示学历、职业两列数据,筛选精准,Excel 抽取流程完成。
📌 Excel 避坑总结:
区分文件格式:xlsx 选对应流式引擎,旧版 xls 切换兼容引擎;
多工作表必须手动指定读取表,不要默认全读;
中文乱码优先切换 UTF-8 编码,空白行用「非空记录」过滤。
五、三大文件抽取通用复盘 + 高频问题解答
(一)三大文件 ETL 抽取核心差异汇总
|
文件类型 |
推荐组件 |
核心配置难点 |
适用场景 |
|
CSV |
CSV 文件输入 |
列分隔符、表头勾选 |
结构化数据、跨平台交互、大数据量 |
|
TXT 纯文本 |
CSV 文件输入(通用) |
自定义分隔符(分号 / Tab) |
日志、赛事、流水等轻量文本数据 |
|
Excel |
Excel 输入(专属) |
工作表选择、编码、空白行过滤 |
职场报表、业务台账、手工统计数据 |
(二)高频报错 & 一键解决方案
-
数据列错位、字段混乱 原因:分隔符不匹配、中英文符号混用。解决:打开原始文件核对分隔符,统一使用英文符号。
-
中文乱码 原因:编码错误。解决:所有文件读取组件编码统一设置为 UTF-8。
-
读取不到文件 原因:文件路径错误、Excel 未点击「增加」、文件未导出到项目文件库。解决:回到文件库核对文件,重新配置文件路径。
-
表头变成数据行 原因:未勾选「包含列头行 / 头部」。解决:读取组件中勾选表头选项。
-
流程运行无数据输出 原因:组件链路断开、连接选错「错误步骤」。解决:重新连接组件,统一选择「主输出步骤」。
(三)进阶使用小技巧
-
流程复用:搭建好的转换流可直接导出,新项目导入即可使用,不用重复配置;
-
批量文件处理:多个同格式文件,可在输入组件中批量添加文件,一次性抽取;
-
错误数据分流:连接组件时选择「错误步骤」,搭配日志组件,单独收集异常数据,提升数据质量;
-
定时调度:流程调试完成后,可配置定时任务,实现文件数据自动抽取更新。
六、写在最后
看完这三套完整实战流程,相信大家已经彻底掌握零代码 ETL 抽取三大主流文件的核心玩法了!从最简单的文件读取、字段筛选,到进阶的日期计算、数据分级,整套流程贴合企业真实数据处理场景,也是数据分析师、数据开发入门的必备技能。
ETL 本身并不复杂,尤其是可视化零代码平台,核心就是选对组件 + 配对参数 + 核对格式。前期多留意分隔符、编码、表头这些细节,就能避开 80% 的坑。大家可以跟着教程一步步复刻流程,替换自己的业务文件动手实操,练熟之后,日常文件数据处理效率直接翻倍!
后续还可以基于这套基础流程,拓展数据去重、数据过滤、多文件合并、数据入库等高阶玩法,逐步搭建完整的数据处理流水线~
需要我帮你整理一份快速自查清单,方便你实操时对照排查报错吗?

一站式 AI 云服务平台
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)