
零代码ETL实战:手把手完成CSV、文本与Excel三类文件数据抽取
前言
本次实验围绕 ETL 流程中的“数据抽取”环节展开,主要记录如何在助睿 ETL 数据集成平台中读取和处理三类常见文件数据:CSV 文件、文本文件和 Excel 文件。
在实际业务中,数据不一定都存放在数据库中。很多时候,数据会以 CSV、TXT、Excel 等文件形式进行传递,例如供应商提供的数据、业务系统导出的报表、客户交换文件等。因此,掌握文件类数据源的读取、字段解析、字段筛选和基础加工,是学习 ETL 的基础内容之一。
本次实验主要完成三项任务:
1. 从 CSV 文件中读取项目数据,并计算项目执行天数和绩效等级;
2. 从文本文件中读取足球比赛数据,并完成字段筛选;
3. 从 Excel 文件中读取购房者信息数据,并筛选目标字段。
整体流程如下:
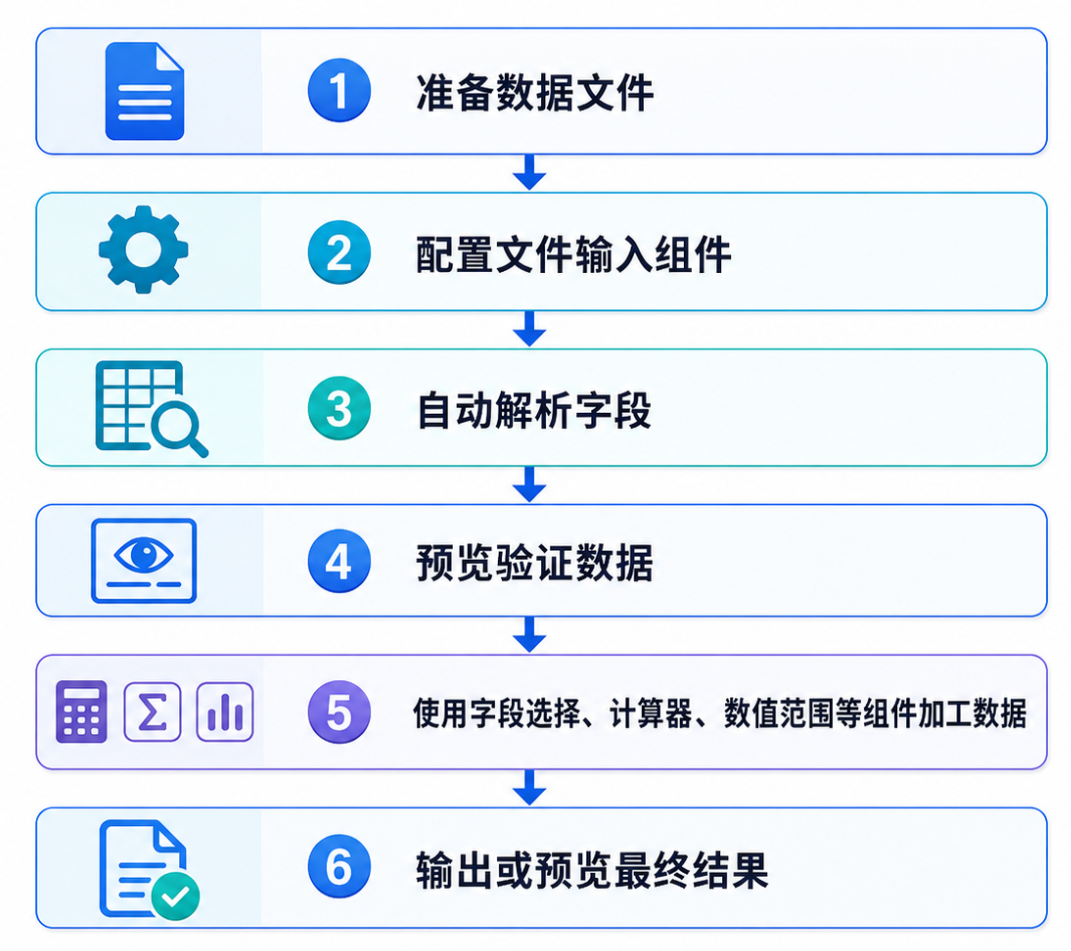
第一部分:实验背景
1.1 实验目的
本次实验使用 助睿数智(Uniplore)一站式数据科学实验平台 完成文件类数据源的读取和基础处理。
通过本次实验,我主要掌握以下内容:
1. 理解 ETL 数据抽取环节的基本作用;
2. 掌握 CSV 文件输入组件的使用方法;
3. 掌握文本文件按指定分隔符解析的方法;
4. 掌握 Excel 输入组件读取工作表数据的方法;
5. 掌握字段选择组件的字段保留与字段移除方法;
6. 掌握计算器组件中日期差计算的配置方法;
7. 掌握数值范围组件根据区间生成分类字段的方法;
8. 掌握文本文件输出组件生成结果文件的方法;
9. 学会通过预览输出验证 ETL 流程是否正确。
本次实验重点不在复杂算法或建模,而是熟悉助睿 ETL 平台中文件读取和基础转换的完整流程。
1.2 实验环境
本次实验基于助睿平台完成。
平台信息如下:
平台全称:助睿数智(Uniplore)一站式数据科学实验平台
平台定位:覆盖数据接入、ETL处理、机器学习建模到可视化分析的全链路 Agentic 零代码数据智能产品
产品官网:https://www.uniplore.com/
实验平台地址:https://lab.guilian.cn/
本次使用的子平台为:
助睿 ETL 数据集成平台
助睿 ETL 平台支持通过组件拖拽和参数配置完成数据接入、字段处理、数据计算、文件输出等操作,适合用于数据集成和数据预处理实验。
1.3 实验数据
本次实验使用的数据文件均来自助睿 ETL 平台的“公共空间”。
| 文件名称 | 文件类型 | 实验用途 |
|---|---|---|
| project.csv / porject.csv | CSV 文件 | 读取项目数据,计算项目执行天数和绩效等级 |
| usa_201209.txt | 文本文件 | 读取足球比赛数据,移除指定字段并验证结果 |
| custinfo.xlsx | Excel 文件 | 读取购房者信息数据,筛选建模分析所需字段 |
说明:实验界面中部分文件名显示为 porject.csv,与常见拼写 project.csv 不一致。实际配置时以平台文件库中显示的文件名为准。
1.4 整体处理流程
本次实验分为三个处理流程。
第一个流程是 CSV 文件读取与加工。通过“CSV 文件输入”组件读取项目数据,使用“字段选择”组件接收字段,再通过“计算器”组件计算项目开始日期和结束日期之间的天数差,最后通过“数值范围”组件生成项目绩效等级,并使用“文本文件输出”组件生成结果文件。
第二个流程是文本文件读取与验证。通过“CSV 文件输入”组件读取分号分隔的文本数据,使用“字段选择”组件移除不需要的 Venue 字段,最后通过“空操作(什么也不做)”组件验证数据是否正常传递。
第三个流程是 Excel 文件读取与字段筛选。通过“Excel 输入”组件读取购房者信息数据,选择指定工作表 Sheet1,自动获取表头字段,再使用“字段选择”组件只保留 education 和 employment 字段,最后通过预览输出验证结果。
第二部分:实验步骤
2.1 准备实验数据文件
实验步骤
登录助睿 ETL 平台后,进入“数据集成”模块,在“我的项目”中打开目标项目。
进入项目页面后,在右侧找到“公共空间”,切换到“数据资源”标签页。这里可以看到平台提供的公共数据文件。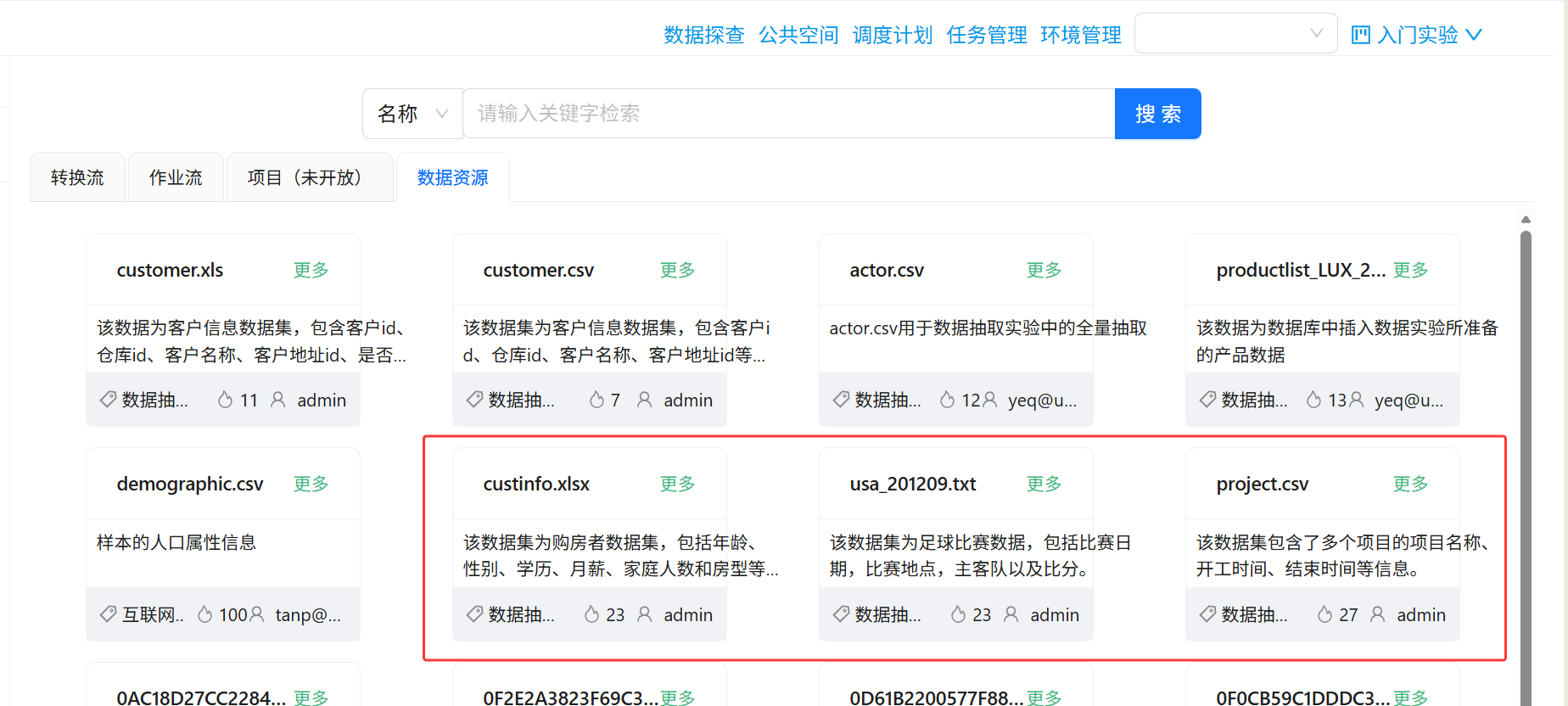
本次实验需要使用三个文件:project.csv 、usa_201209.txt、custinfo.xlsx。将这些文件从公共空间导出到当前项目空间中。
文件导出完成后,进入左侧“文件库”,刷新文件列表,确认实验文件已经出现在项目空间中。
配置要点
数据来源:公共空间
目标位置:当前项目空间文件库
CSV 文件:project.csv
文本文件:usa_201209.txt
Excel 文件:custinfo.xlsx
文件路径:以文件库中实际路径为准
文件名:以平台实际显示名称为准
2.2 读取 CSV 项目数据
实验步骤
新建一个转换流,在组件库中找到“CSV 文件输入”组件,并将该组件添加到画布中。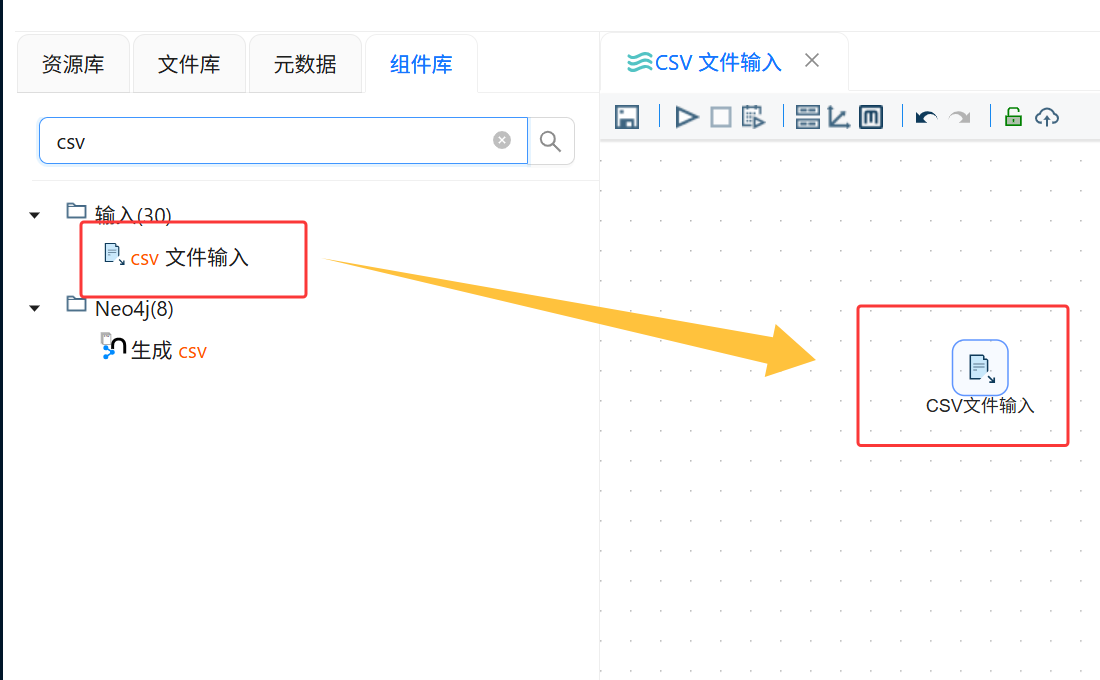
打开“CSV 文件输入”组件配置窗口,在文件选择区域选择项目文件库中的 project.csv 或 porject.csv 文件。文件选择完成后,组件会自动回填文件路径。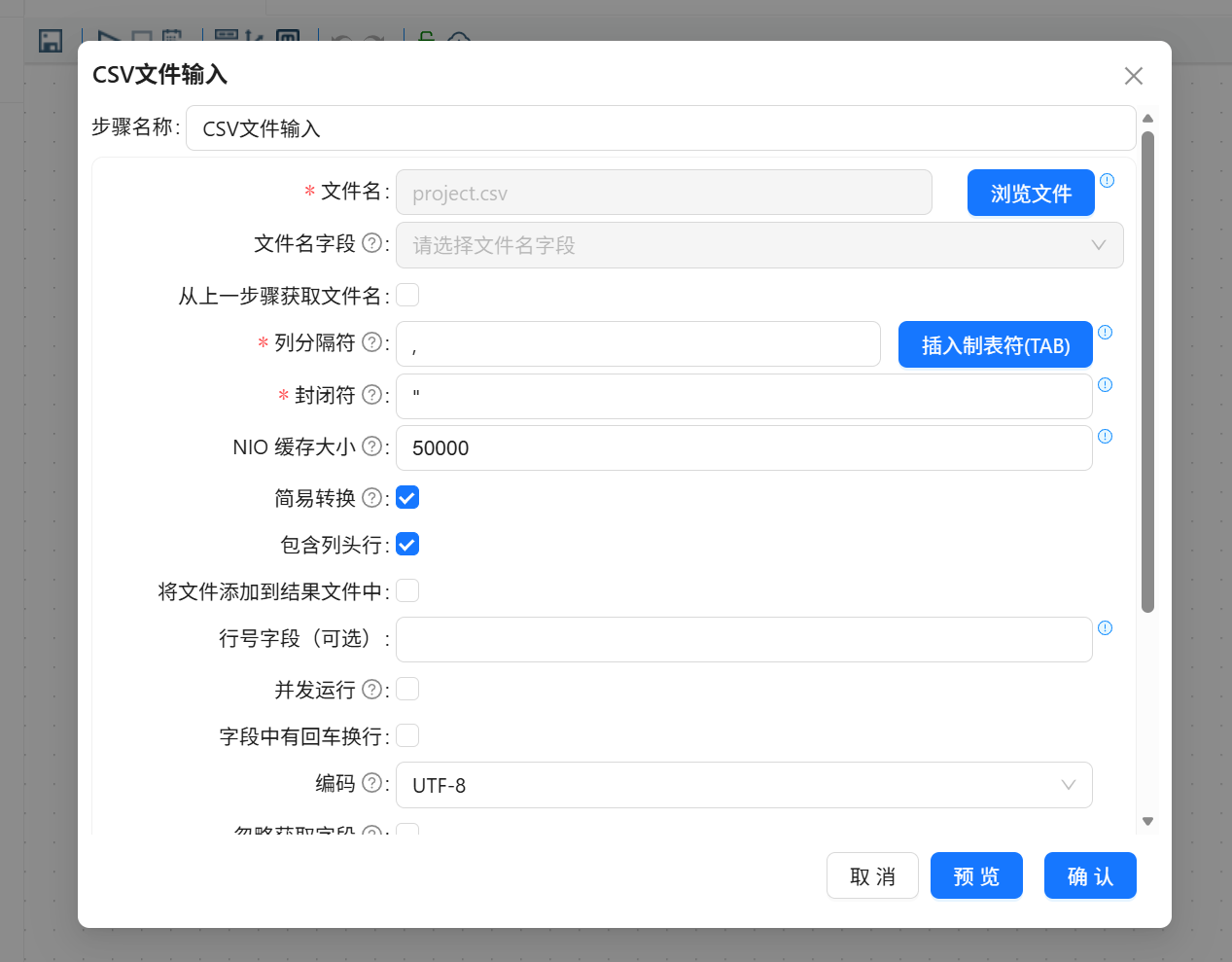
随后在字段区域获取字段,平台会根据 CSV 文件的表头和分隔符自动解析字段信息。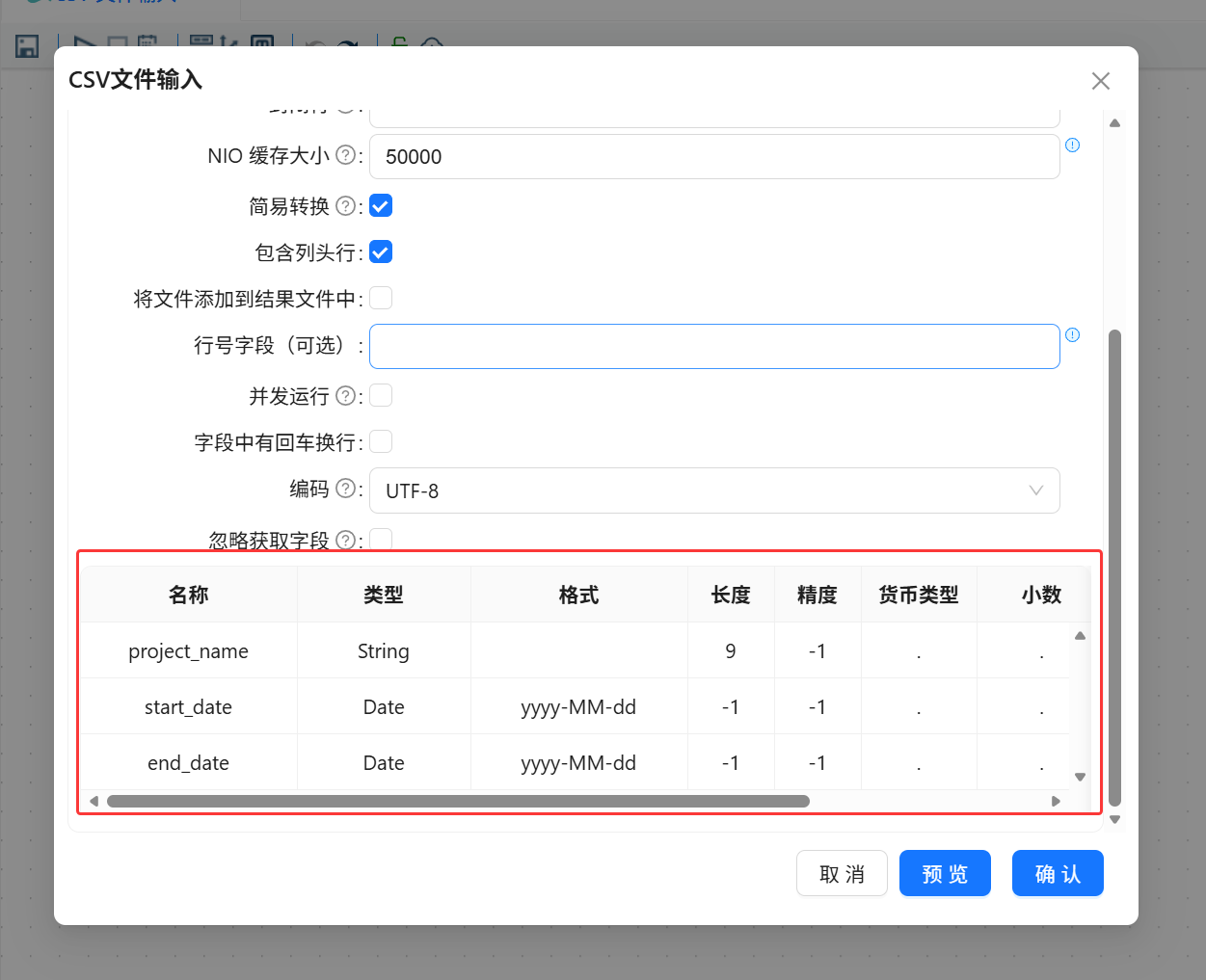
字段解析完成后,对 CSV 文件输入组件进行数据预览,检查项目数据是否能够正常读取。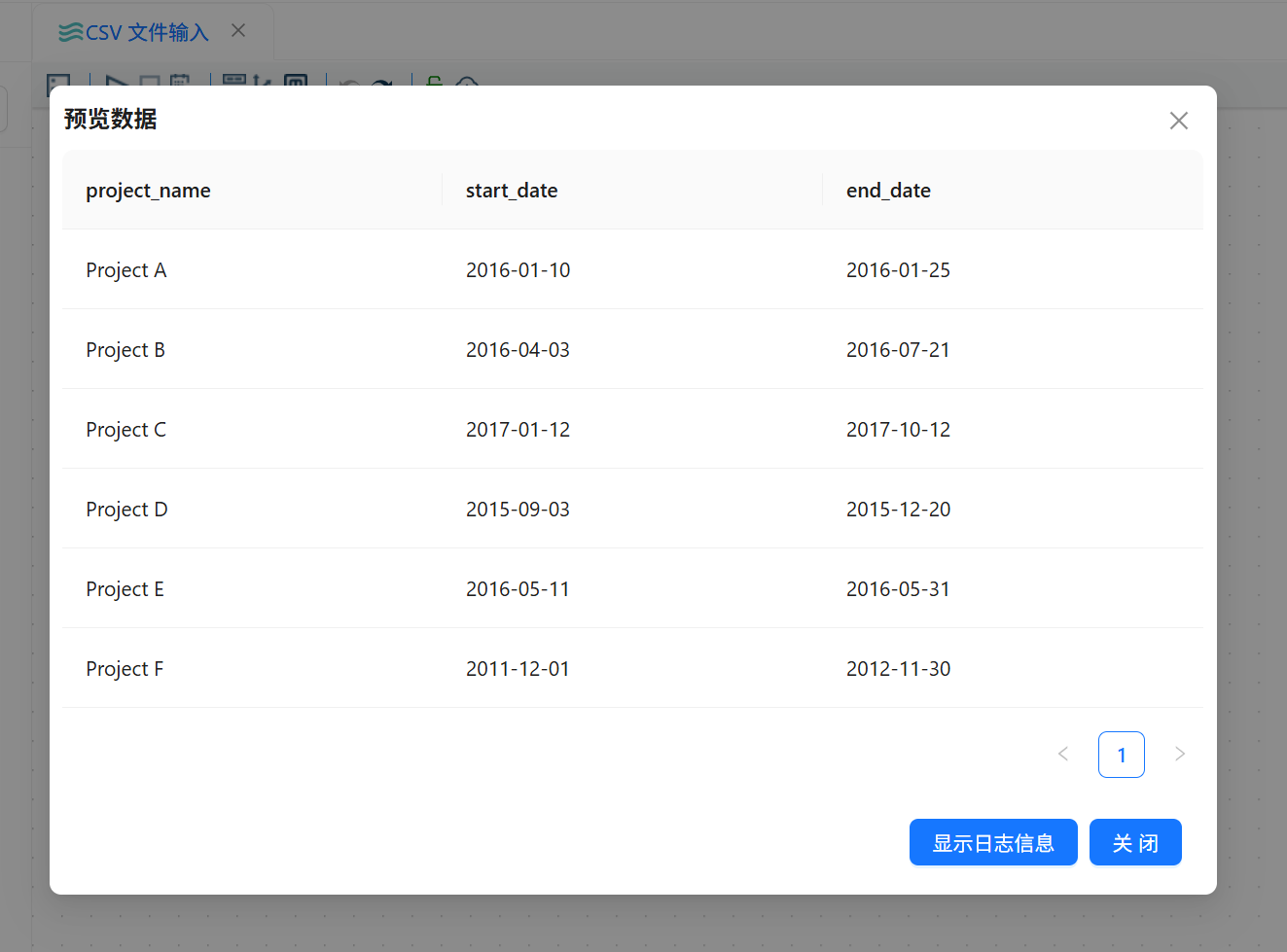
配置要点
组件名称:CSV 文件输入
输入文件:project.csv / porject.csv
文件来源:项目空间文件库
字段来源:CSV 文件头部字段
字段解析方式:自动获取字段
核心日期字段:start_date、end_date
数据验证方式:预览输出
2.3 配置字段选择组件接收 CSV 字段
实验步骤
在 CSV 文件输入组件后添加“字段选择”组件,并建立从“CSV 文件输入”到“字段选择”的连接。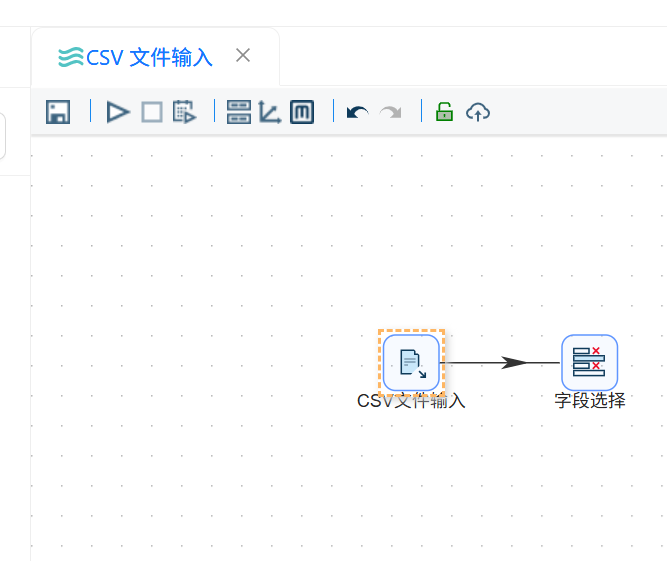
打开“字段选择”组件配置窗口,在“选择和修改”标签页中获取上游字段。由于本次 CSV 流程中暂时不需要修改字段名称、字段类型、长度和精度,因此字段信息保持默认。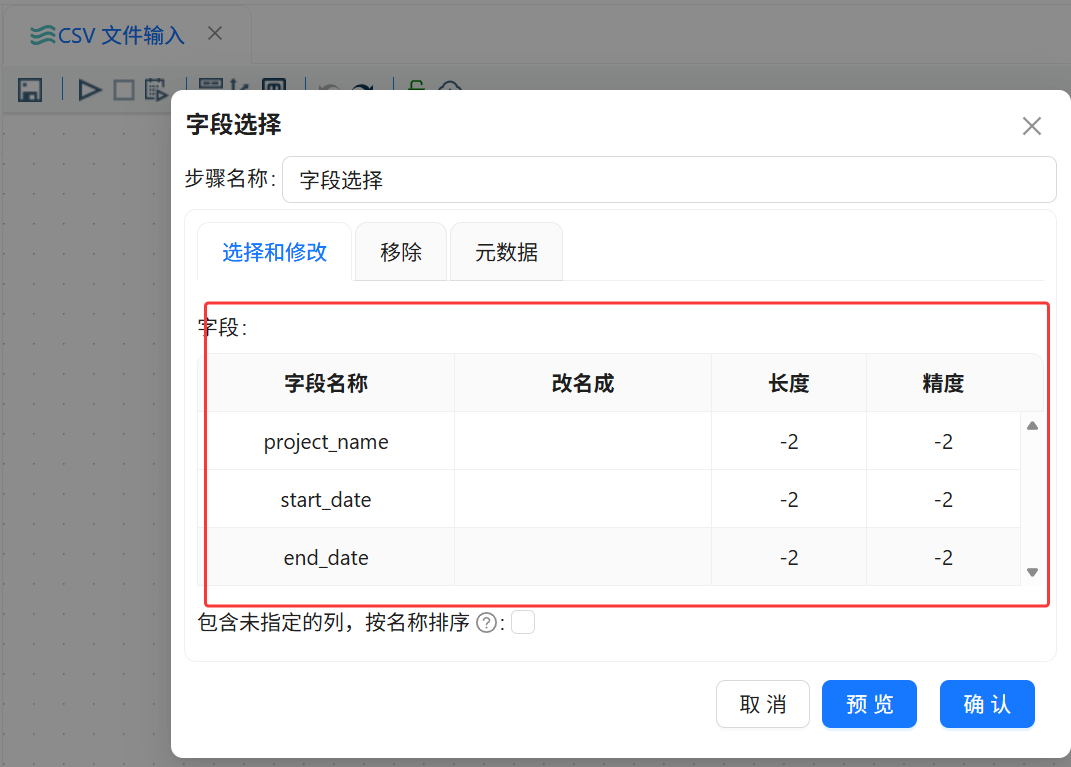
字段选择组件配置完成后,该组件会把 CSV 输入组件读取到的数据继续传递给后续组件。
配置要点
组件名称:字段选择
上游组件:CSV 文件输入
连接类型:主输出步骤
字段处理方式:保留默认字段信息
字段名称:保持原字段名称
字段类型:保持自动识别结果
输出数据:传递给计算器组件
2.4 计算项目执行天数
实验步骤
在“字段选择”组件后添加“计算器”组件,并建立从“字段选择”到“计算器”的连接。连接类型选择“主输出步骤”。
打开“计算器”组件配置窗口,新增一个计算字段 diff_date。该字段用于计算项目结束日期 end_date 与项目开始日期 start_date 之间的天数差。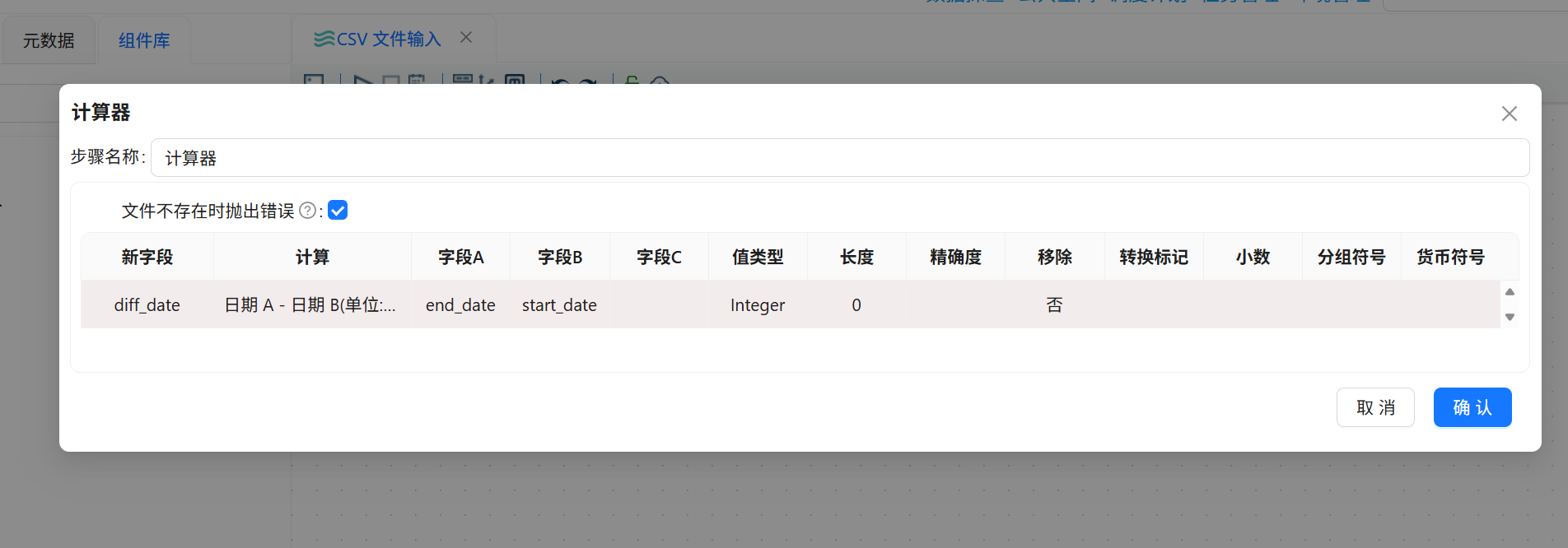
配置完成后,计算器组件会在原有数据基础上新增 diff_date 字段,并将结果传递给后续的数值范围组件。
配置要点
| 配置项 | 配置内容 |
|---|---|
| 组件名称 | 计算器 |
| 上游组件 | 字段选择 |
| 连接类型 | 主输出步骤 |
| 新字段 | diff_date |
| 计算公式 | Date A - Date B (in days) |
| 字段 A | end_date |
| 字段 B | start_date |
| 值类型 | Integer |
| 字段含义 | 项目执行天数 |
计算逻辑为:
diff_date = end_date - start_date
2.5 根据执行天数生成绩效等级
实验步骤
在“计算器”组件后添加“数值范围”组件,并建立从“计算器”到“数值范围”的连接。
打开“数值范围”组件配置窗口,将输入字段设置为 diff_date,输出字段设置为 performance。然后根据项目执行天数设置不同的绩效等级。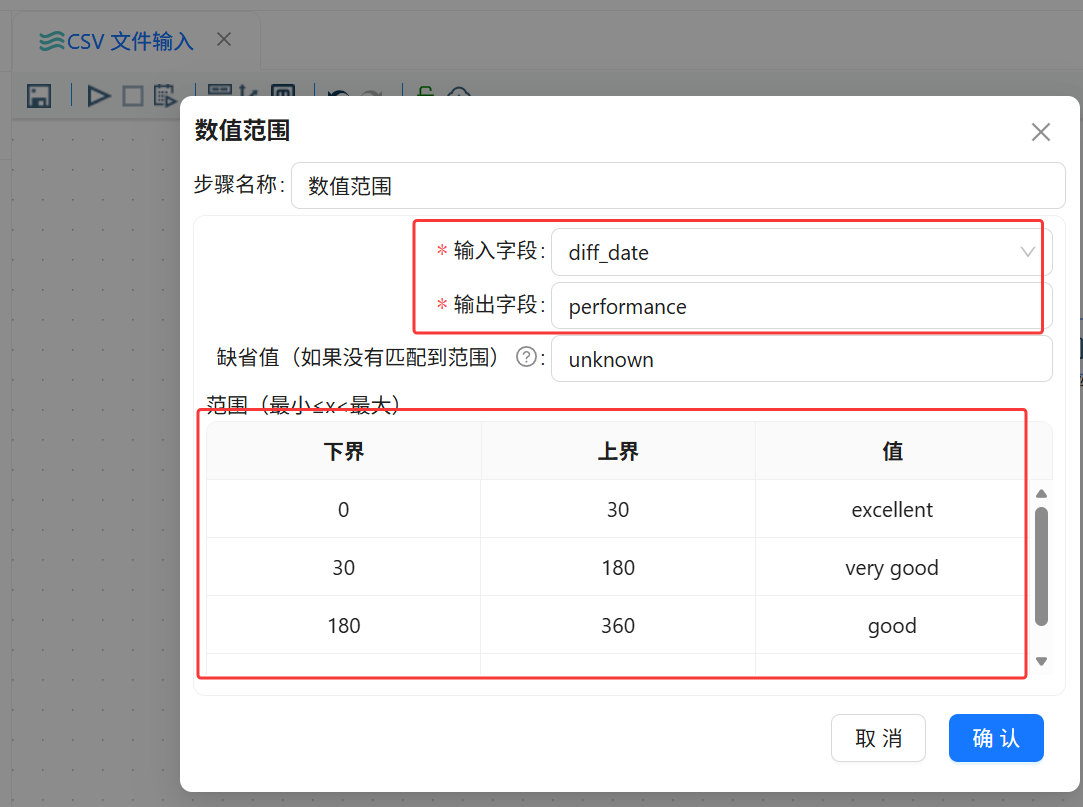
配置完成后,数值范围组件会根据 diff_date 的数值区间自动生成 performance 字段。
配置要点
组件名称:数值范围
上游组件:计算器
输入字段:diff_date
输出字段:performance
范围规则:最小值 ≤ x < 最大值
绩效等级配置如下:
| 下界 | 上界 | performance |
|---|---|---|
| 0 | 30 | excellent |
| 30 | 180 | very good |
| 180 | 360 | good |
| 360 | 空 | poor |
字段含义:
diff_date:项目执行天数
performance:项目绩效等级
2.6 输出 CSV 项目加工结果
实验步骤
在“数值范围”组件后添加“文本文件输出”组件,并建立从“数值范围”到“文本文件输出”的连接。
打开“文本文件输出”组件配置窗口,设置输出文件名称和扩展名。随后配置文件内容格式,将字段分隔符设置为英文逗号。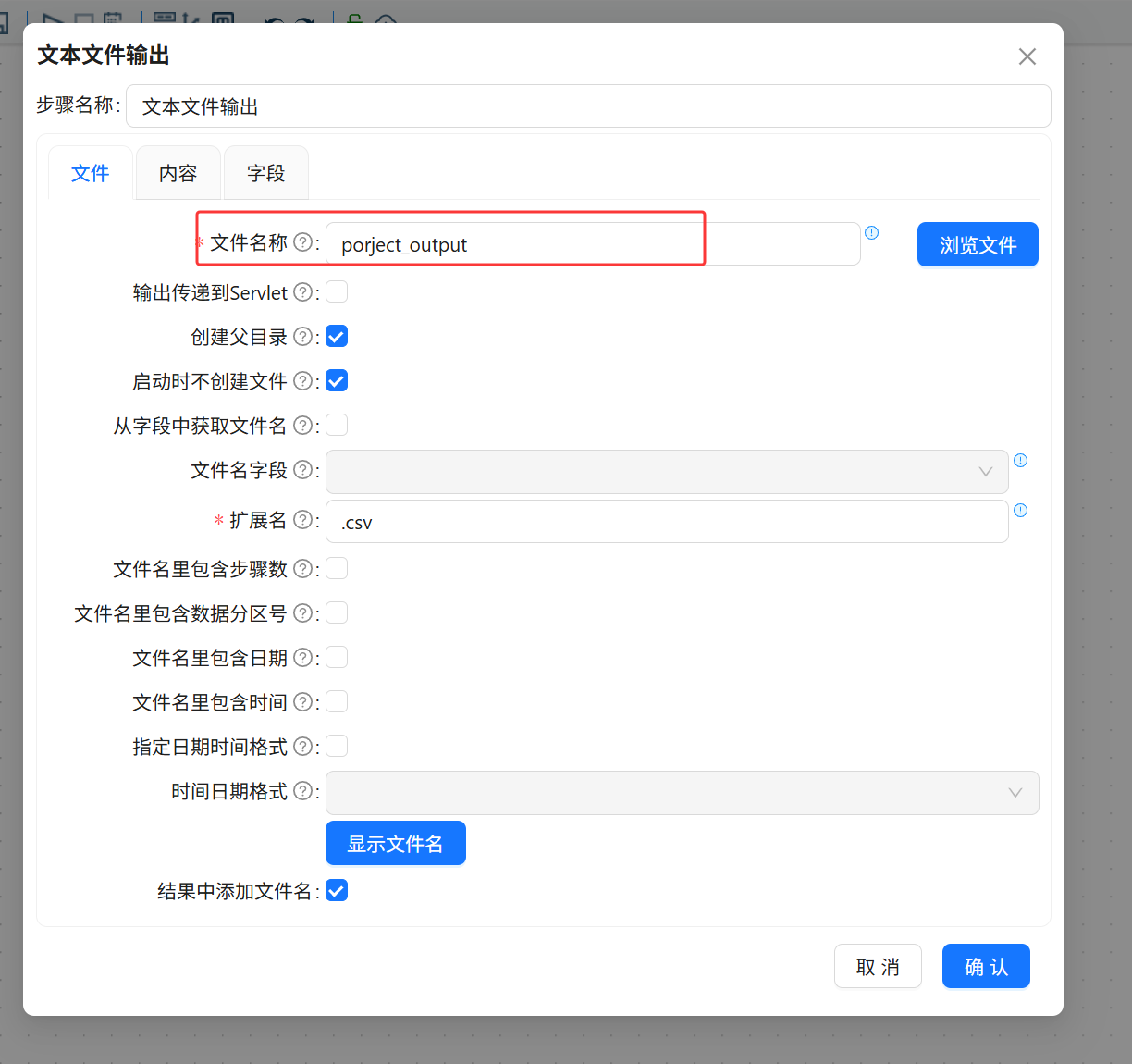
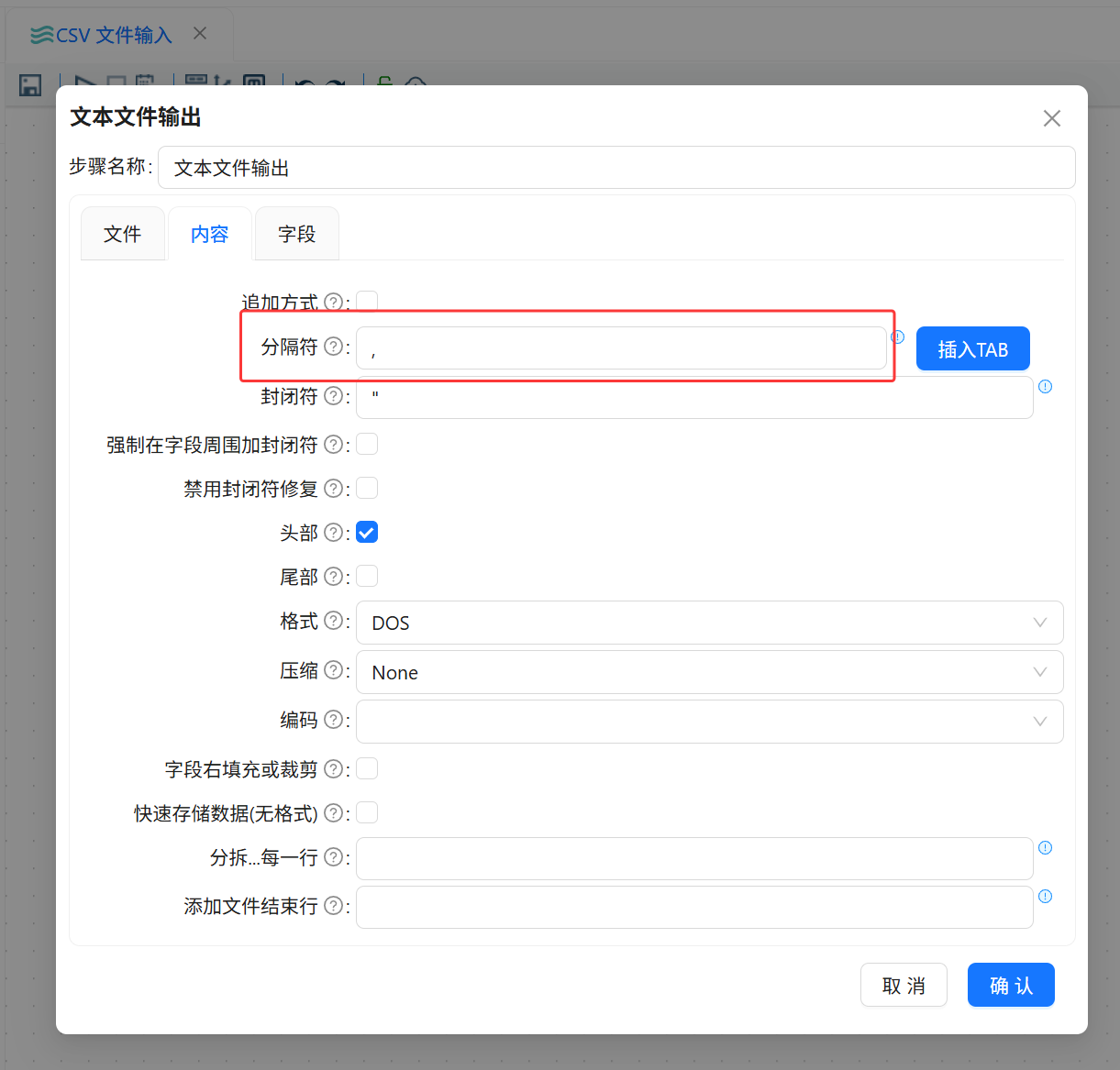
在字段配置页面获取上游字段,使输出文件包含原始字段以及新增的 diff_date 和 performance 字段。
配置完成后,该流程运行时会在文件库中生成新的 CSV 输出文件。
配置要点
组件名称:文本文件输出
上游组件:数值范围
输出文件名称:porject_output
输出扩展名:csv
字段分隔符:英文逗号 ,
输出字段来源:上游全部字段
新增输出字段:diff_date、performance
输出文件:porject_output.csv
2.7 运行 CSV 项目绩效加工流程
实验步骤
完成所有组件配置后,运行转换流程。运行结束后查看执行日志和组件状态,确认各组件执行成功。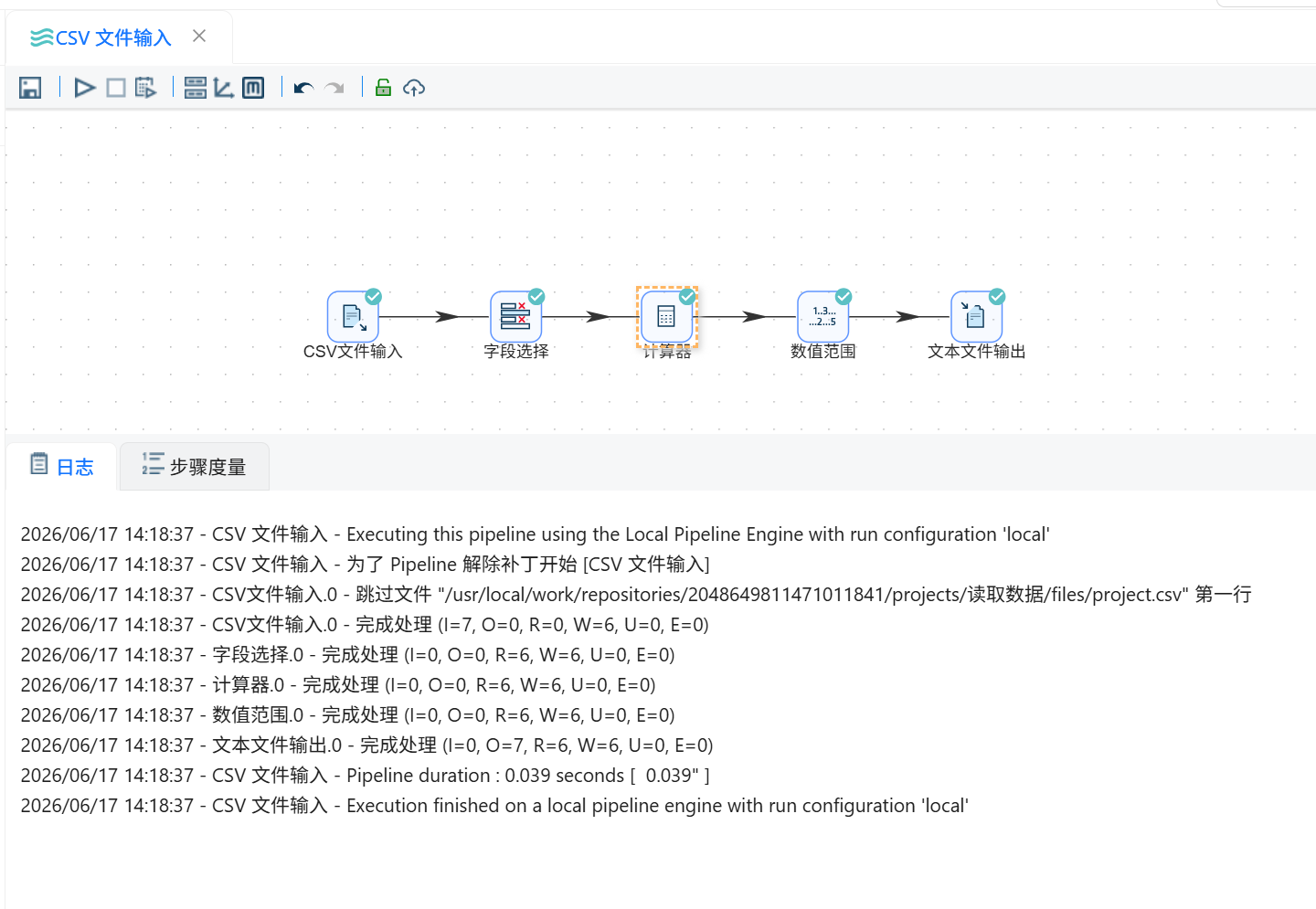
随后进入文件库,查看是否生成 project_output.csv 文件。打开输出文件,检查是否包含 diff_date 和 performance 字段。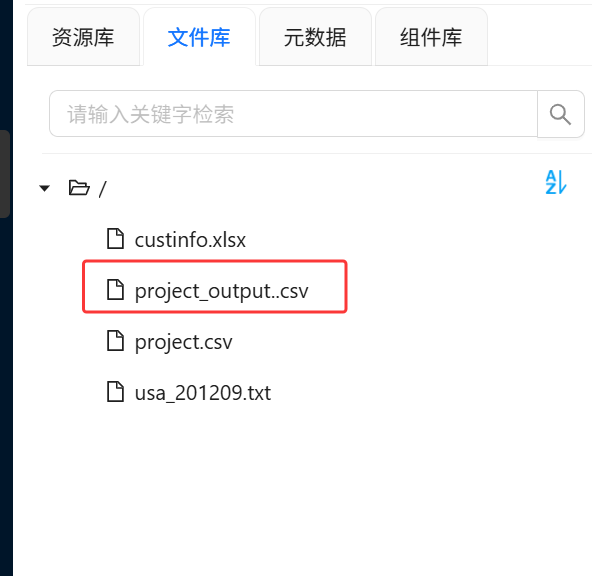
2.8 读取文本文件足球比赛数据
实验步骤
新建一个转换流,在画布中添加“CSV 文件输入”组件。
虽然 usa_201209.txt 是文本文件,但该文件内部是按分隔符组织的结构化数据,因此可以使用“CSV 文件输入”组件进行解析。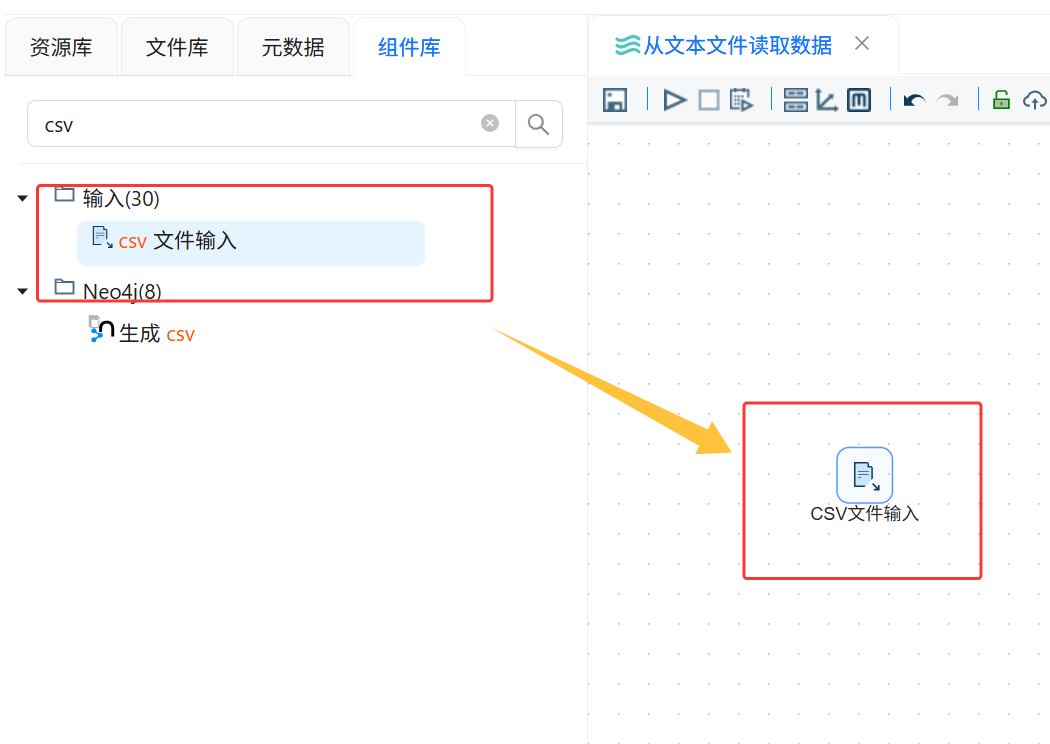
打开组件配置窗口,选择文件库中的 usa_201209.txt 文件,并设置列分隔符。该文本文件使用分号分隔字段,所以需要按照分号进行字段拆分。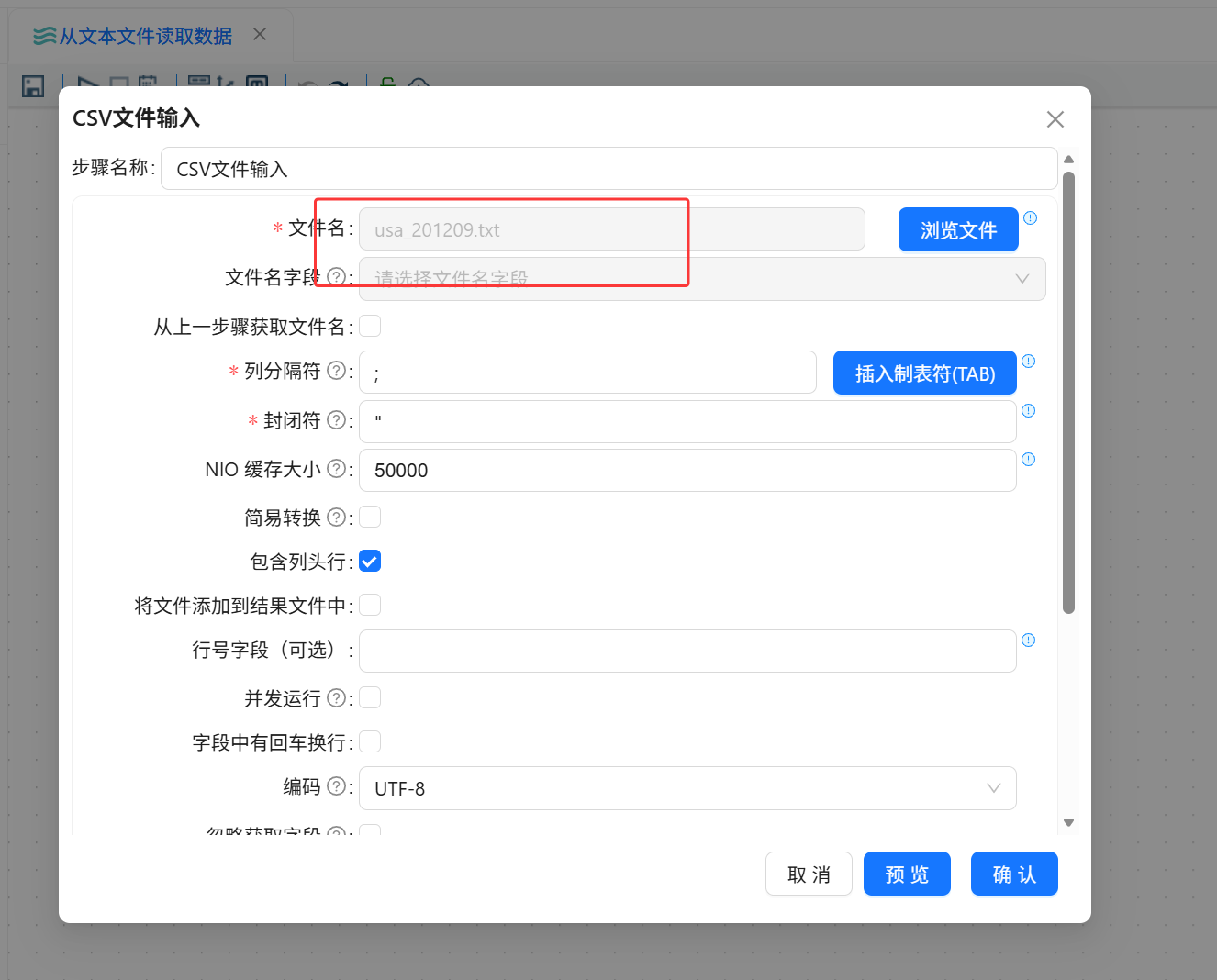
字段配置完成后,点击获取字段。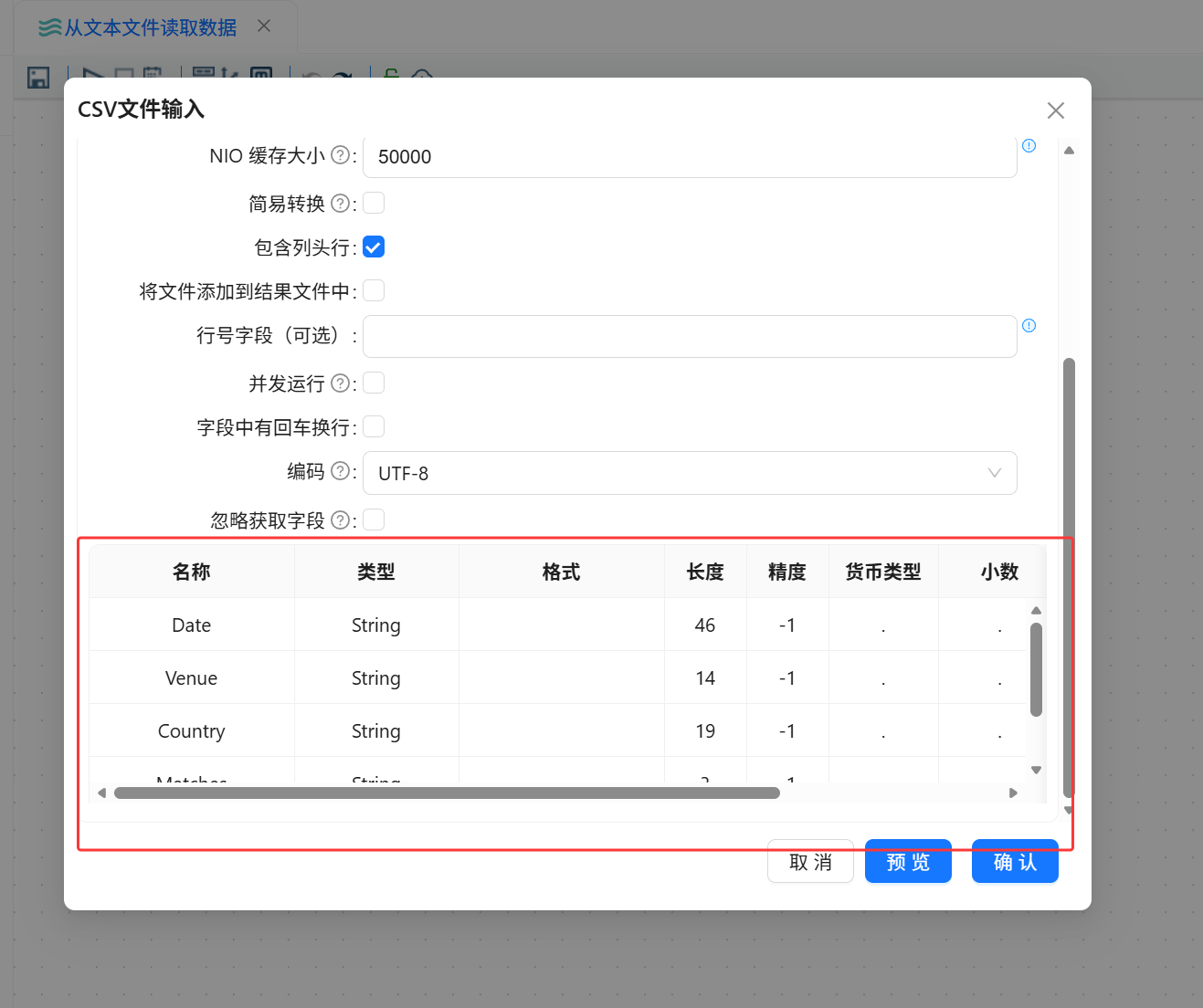
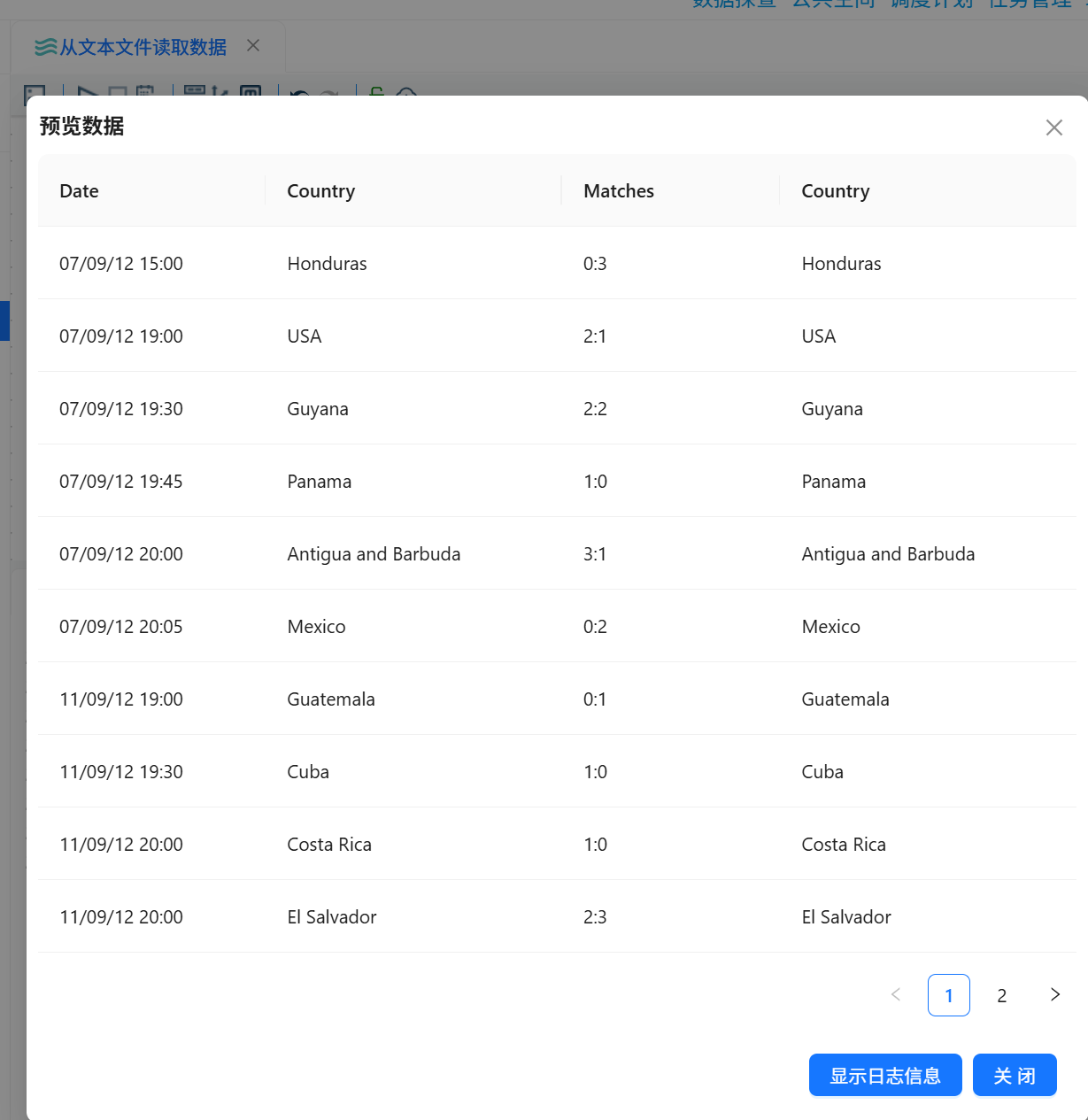
预览输出,检查比赛日期、比赛地点、主队、客队、比分等字段是否正常解析。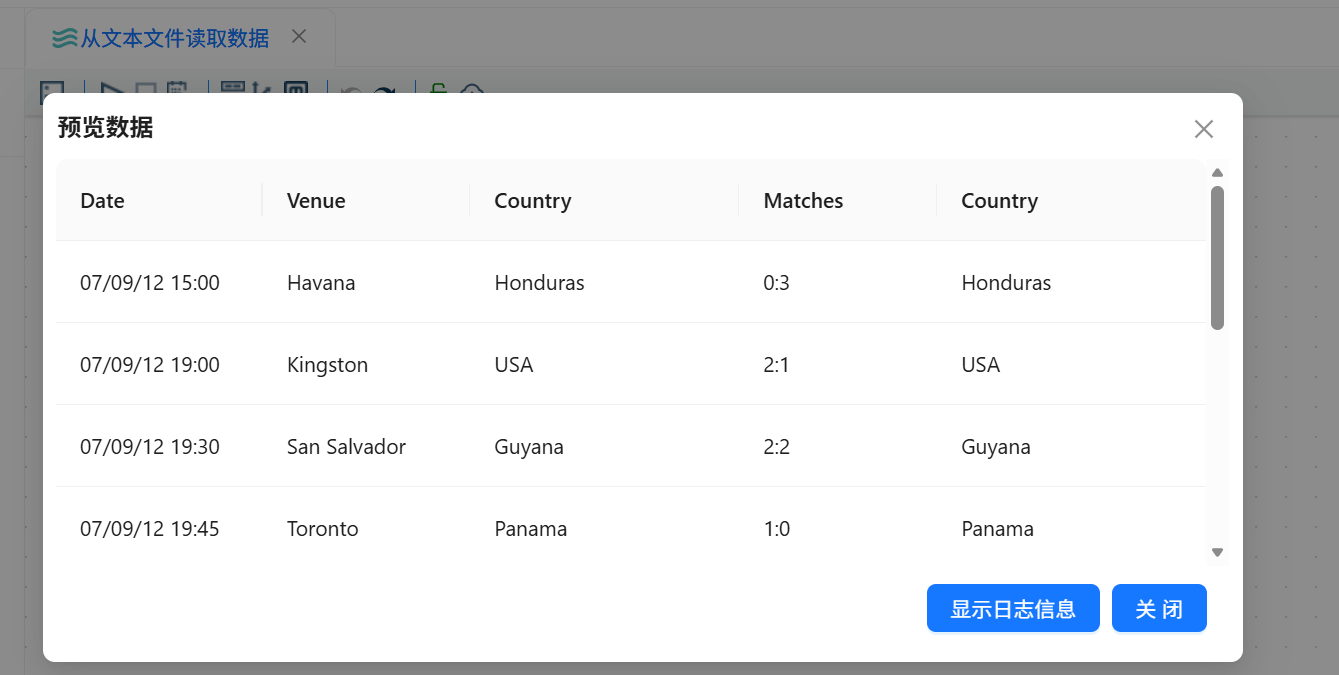
配置要点
组件名称:CSV 文件输入
输入文件:usa_201209.txt
文件类型:文本文件
解析方式:按分隔符解析
列分隔符:英文分号 ;
列头行:包含列头行
字段来源:文件第一行
数据验证方式:预览输出
2.9 移除文本数据中的 Venue 字段
实验步骤
在文本文件输入组件后添加“字段选择”组件,再添加“空操作(什么也不做)”组件,形成完整的数据验证流程。
流程结构如下:
CSV 文件输入
→ 字段选择
→ 空操作(什么也不做)
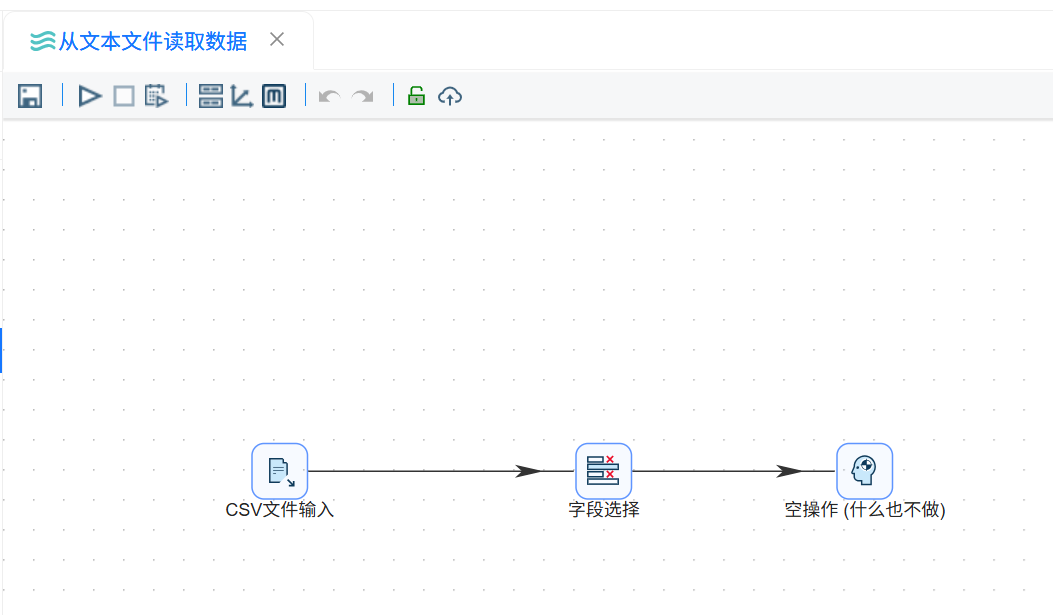
打开“字段选择”组件配置窗口,切换到“移除”标签页。获取上游字段后,将 Venue 字段设置为需要移除的字段。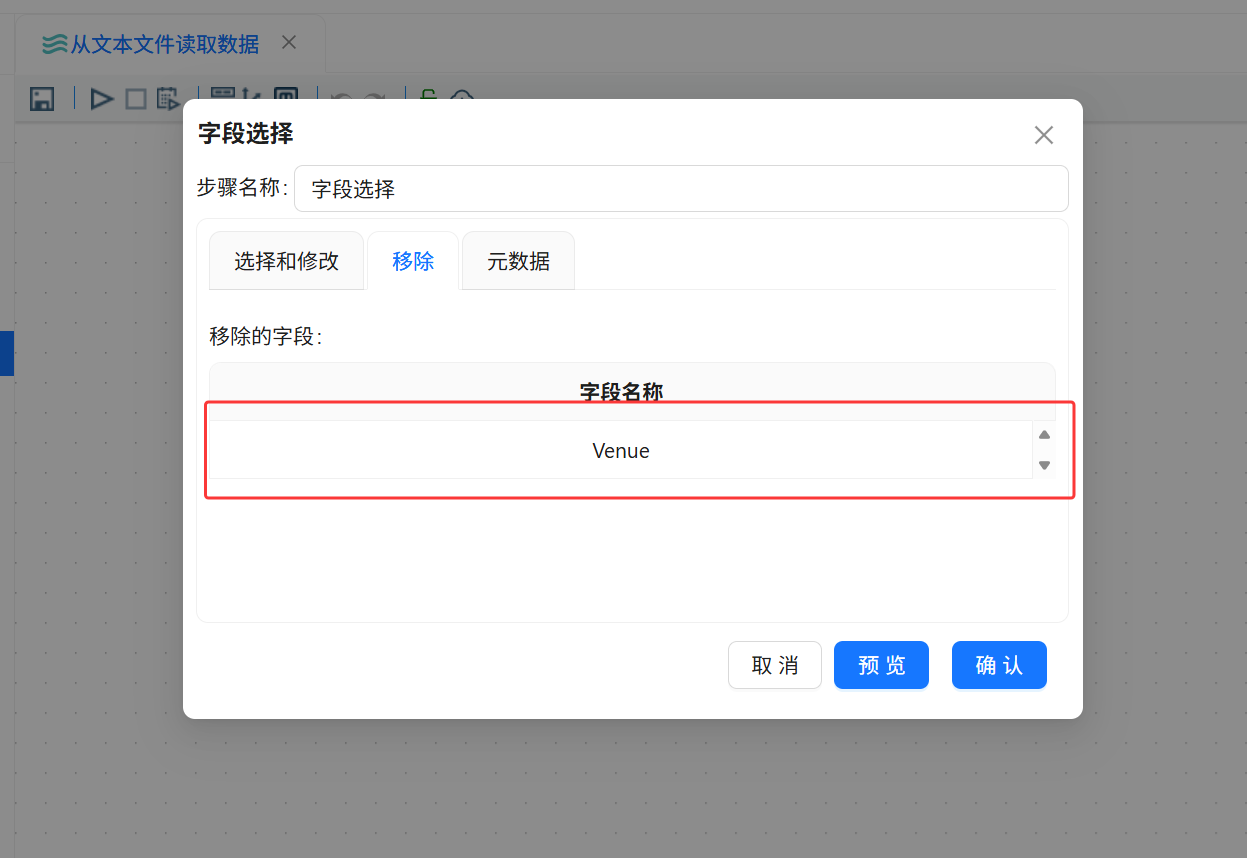
配置完成后,文本数据经过字段选择组件时,Venue 字段会被剔除,其他字段继续传递到“空操作(什么也不做)”组件。
配置要点
组件名称:字段选择
上游组件:CSV 文件输入
下游组件:空操作(什么也不做)
字段处理类型:移除字段
移除字段:Venue
保留字段:除 Venue 外的其他字段
连接类型:主输出步骤
2.10 运行文本文件读取与字段筛选流程
实验步骤
完成文本文件读取和字段选择配置后,运行整个转换流程。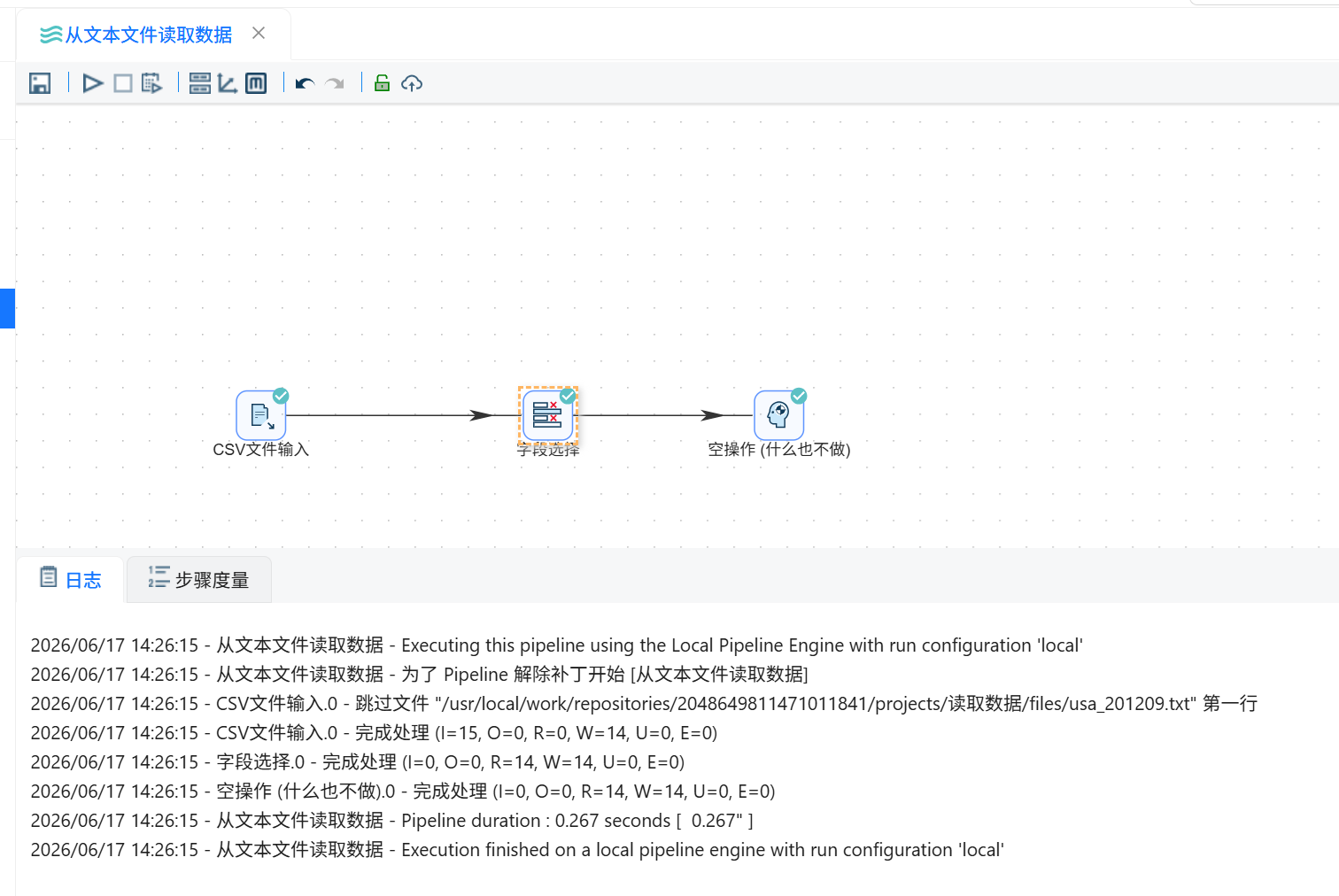
流程运行完成后,查看执行结果,确认各组件执行成功。随后预览“空操作(什么也不做)”组件的输出数据,检查 Venue 字段是否已经被移除,同时确认其他比赛字段是否正常保留。
2.11 读取 Excel 购房者信息数据
实验步骤
新建一个转换流,在画布中添加“Excel 输入”组件。
打开“Excel 输入”组件配置窗口,选择文件库中的 custinfo.xlsx 文件,并将该文件加入选中文件列表。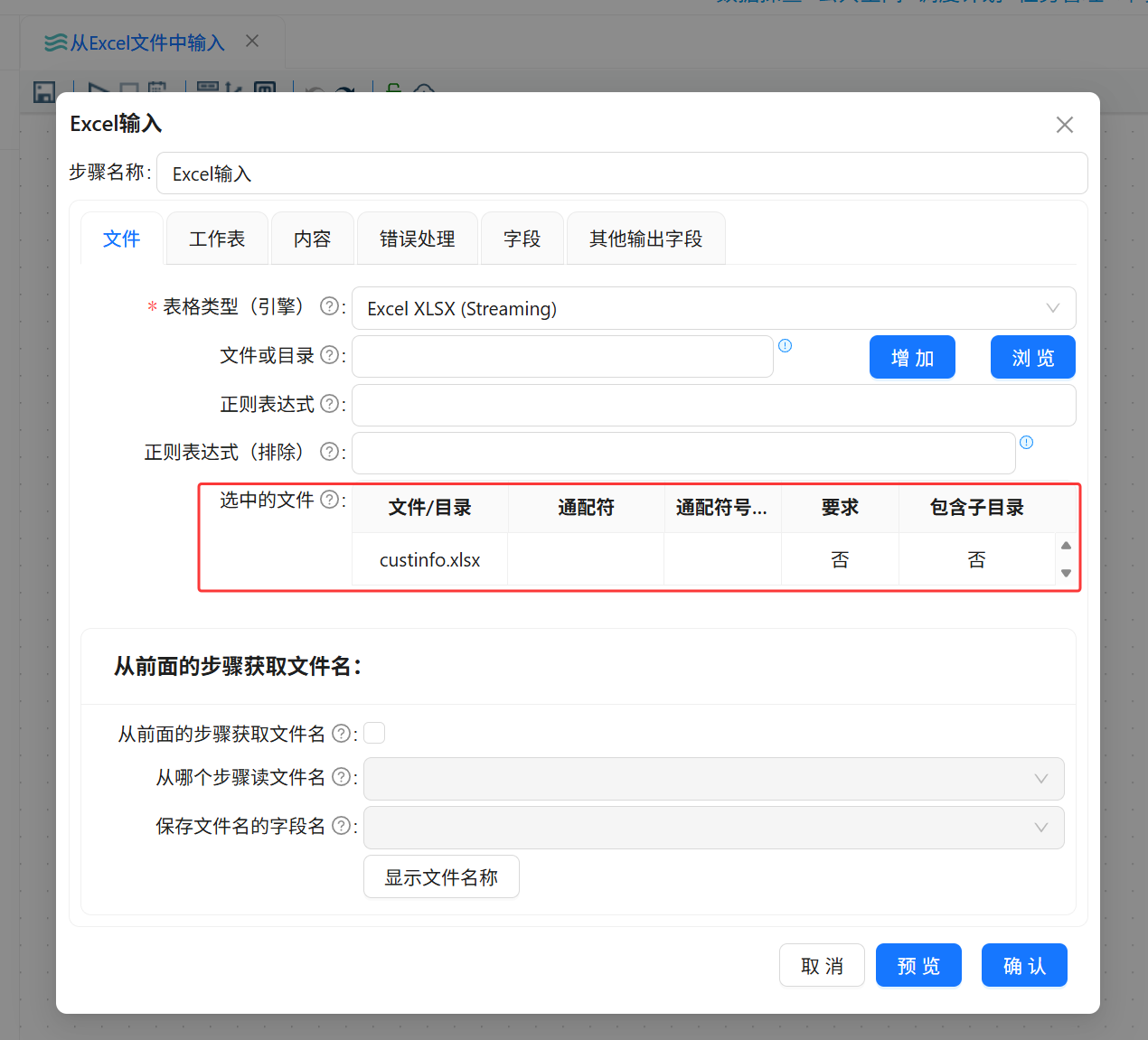
完成文件配置后,继续配置 Excel 文件的内容属性和工作表信息,为后续字段解析做准备。
配置要点
组件名称:Excel 输入
输入文件:custinfo.xlsx
文件类型:Excel xlsx 文件
解析引擎:Excel XLSX(Streaming)
文件来源:项目空间文件库
数据用途:购房者信息字段筛选
2.12 配置 Excel 内容和工作表
实验步骤
在“Excel 输入”组件中进入“内容”标签页,设置 Excel 文件读取规则。该文件第一行为字段名称,因此需要将第一行作为头部字段读取,同时只读取非空记录。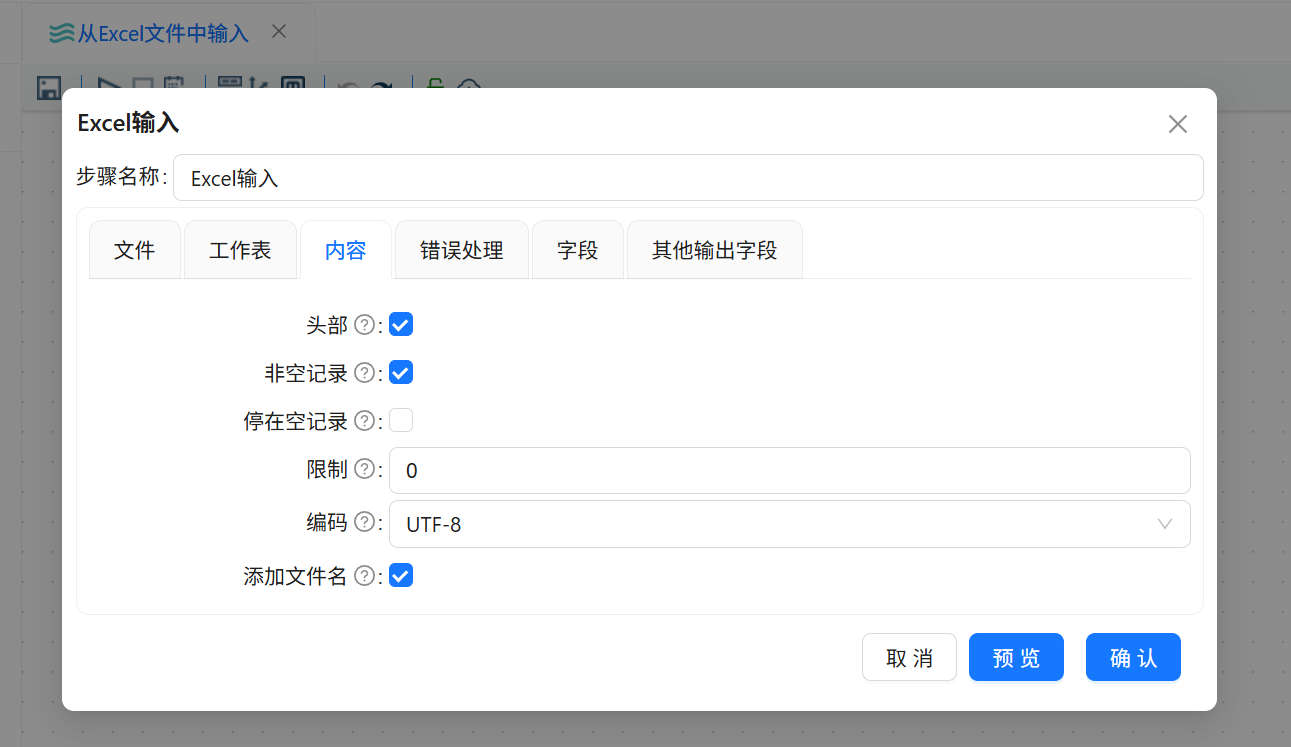
随后进入“工作表”标签页,获取 Excel 文件中的工作表名称,并选择 Sheet1 作为本次实验读取的工作表。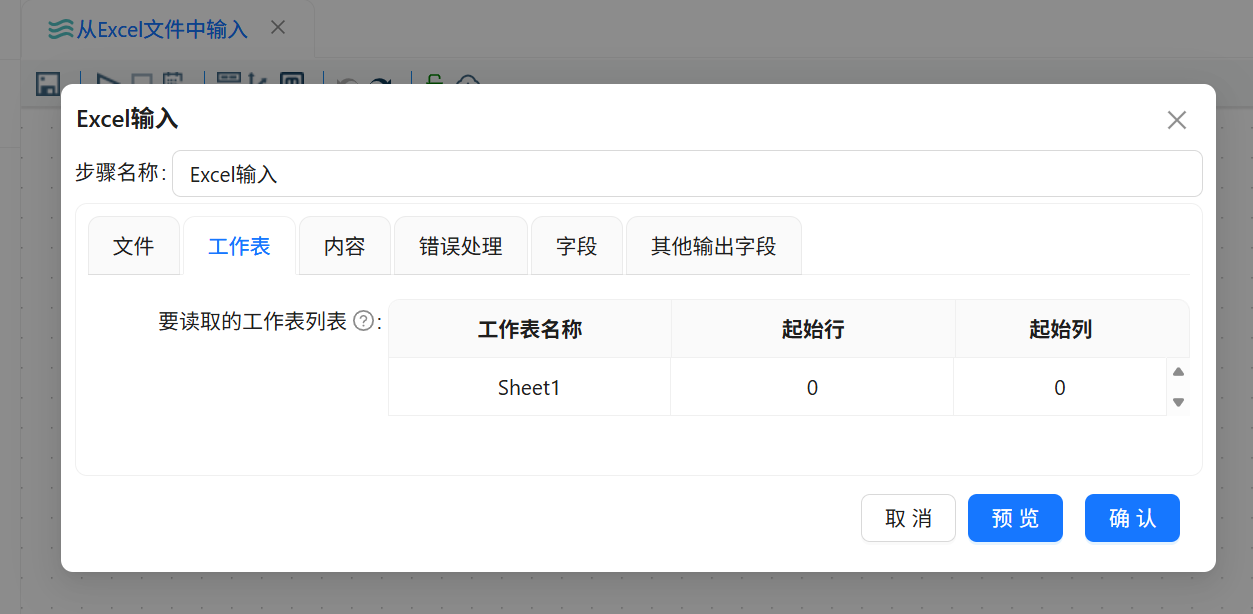
配置要点
内容配置:
头部:勾选
非空记录:勾选
编码:UTF-8
工作表配置:
目标工作表:Sheet1
读取范围:Sheet1 中的非空记录
字段来源:Sheet1 第一行
2.13 获取 Excel 表头字段
实验步骤
在“Excel 输入”组件中切换到“字段”标签页,通过“获取来自头部的字段”功能,让平台自动读取 Sheet1 第一行内容并解析为字段信息。
字段解析完成后,检查字段名称和字段类型是否正确。确认无误后保存 Excel 输入组件配置。
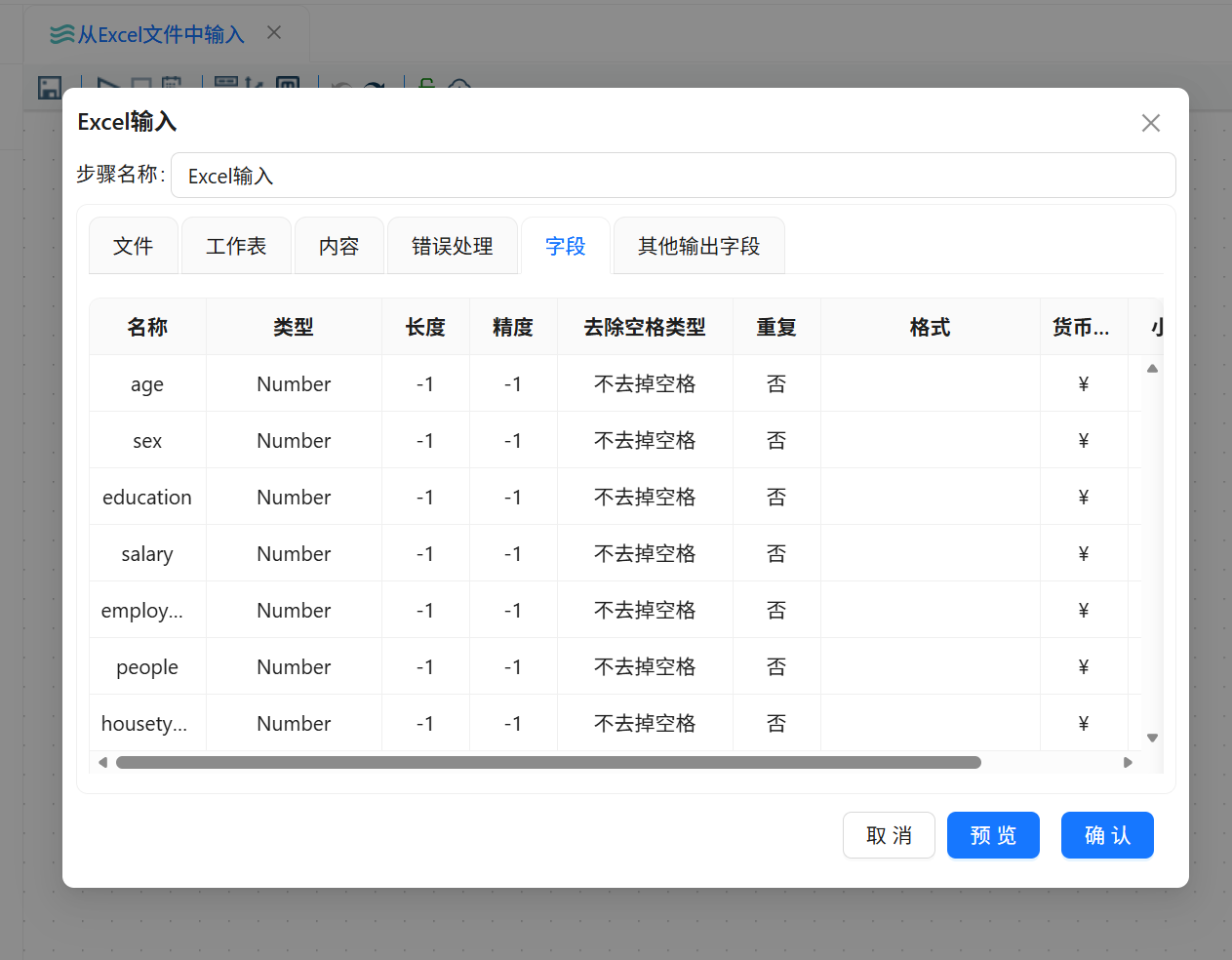
配置要点
字段来源:Excel 表头
表头位置:Sheet1 第一行
字段获取方式:来自头部的字段
字段名称:自动解析
字段类型:自动识别
字段验证重点:字段名、字段类型、空字段、乱码情况
2.14 筛选 education 和 employment 字段
实验步骤
在“Excel 输入”组件后添加“字段选择”组件,再添加“空操作(什么也不做)”组件。
流程结构如下:
Excel 输入
→ 字段选择
→ 空操作(什么也不做)
打开“字段选择”组件配置窗口,获取上游 Excel 输入组件传递的全部字段。根据后续分析需要,仅保留 education 和 employment 两个字段,其他字段不再输出。
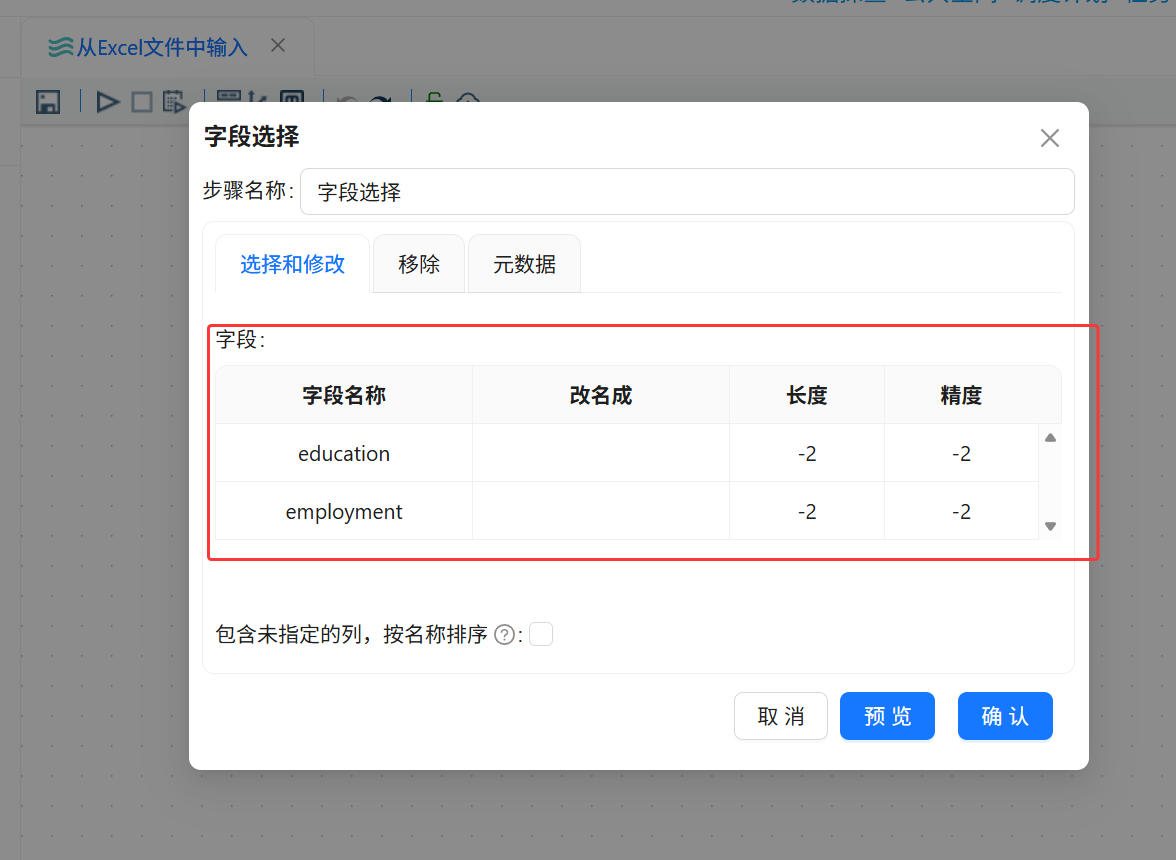
配置要点
组件名称:字段选择
上游组件:Excel 输入
下游组件:空操作(什么也不做)
字段处理类型:字段保留
保留字段:education、employment
输出字段数量:2
连接类型:主输出步骤
2.15 运行 Excel 读取与字段筛选流程
实验步骤
完成 Excel 输入和字段选择配置后,运行整个转换流程。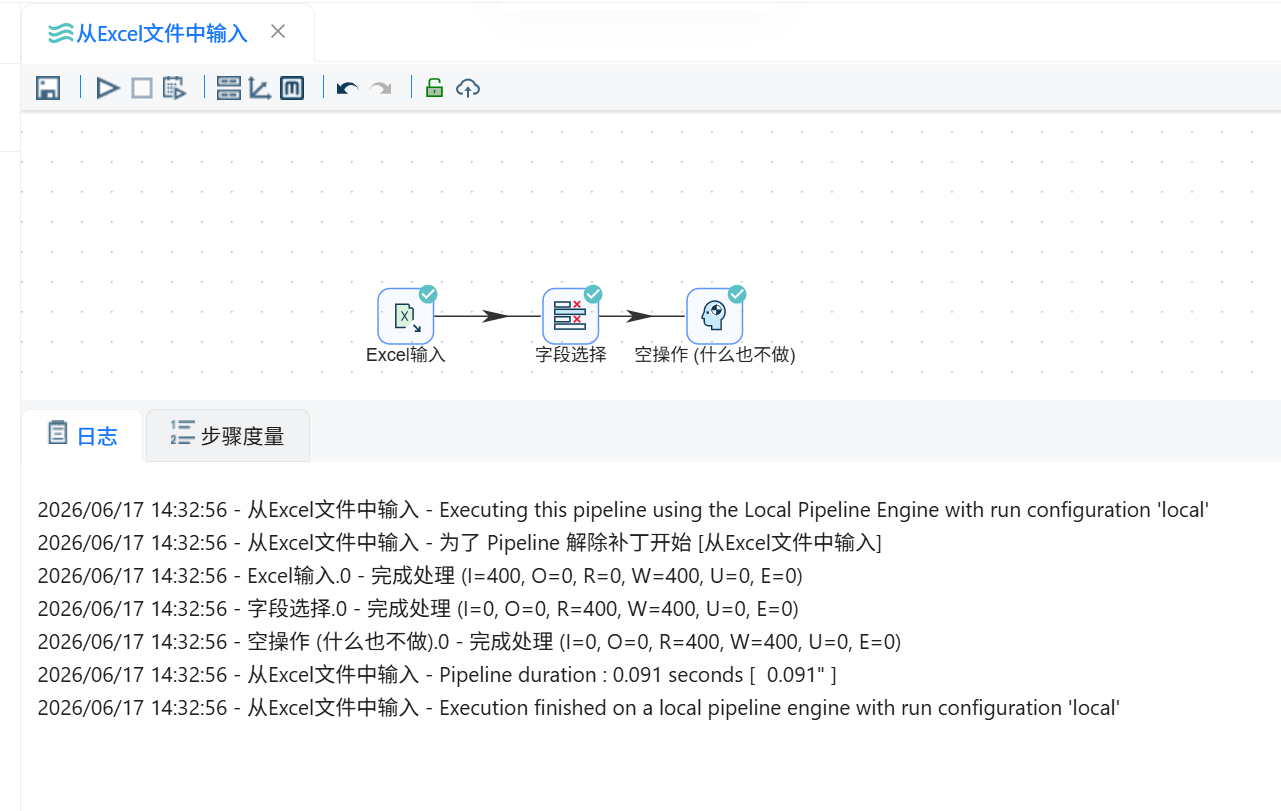
流程运行完成后,查看执行结果,确认 Excel 输入、字段选择和空操作组件均执行成功。随后预览“空操作(什么也不做)”组件的输出数据,检查最终结果中是否只包含 education 和 employment 两个字段。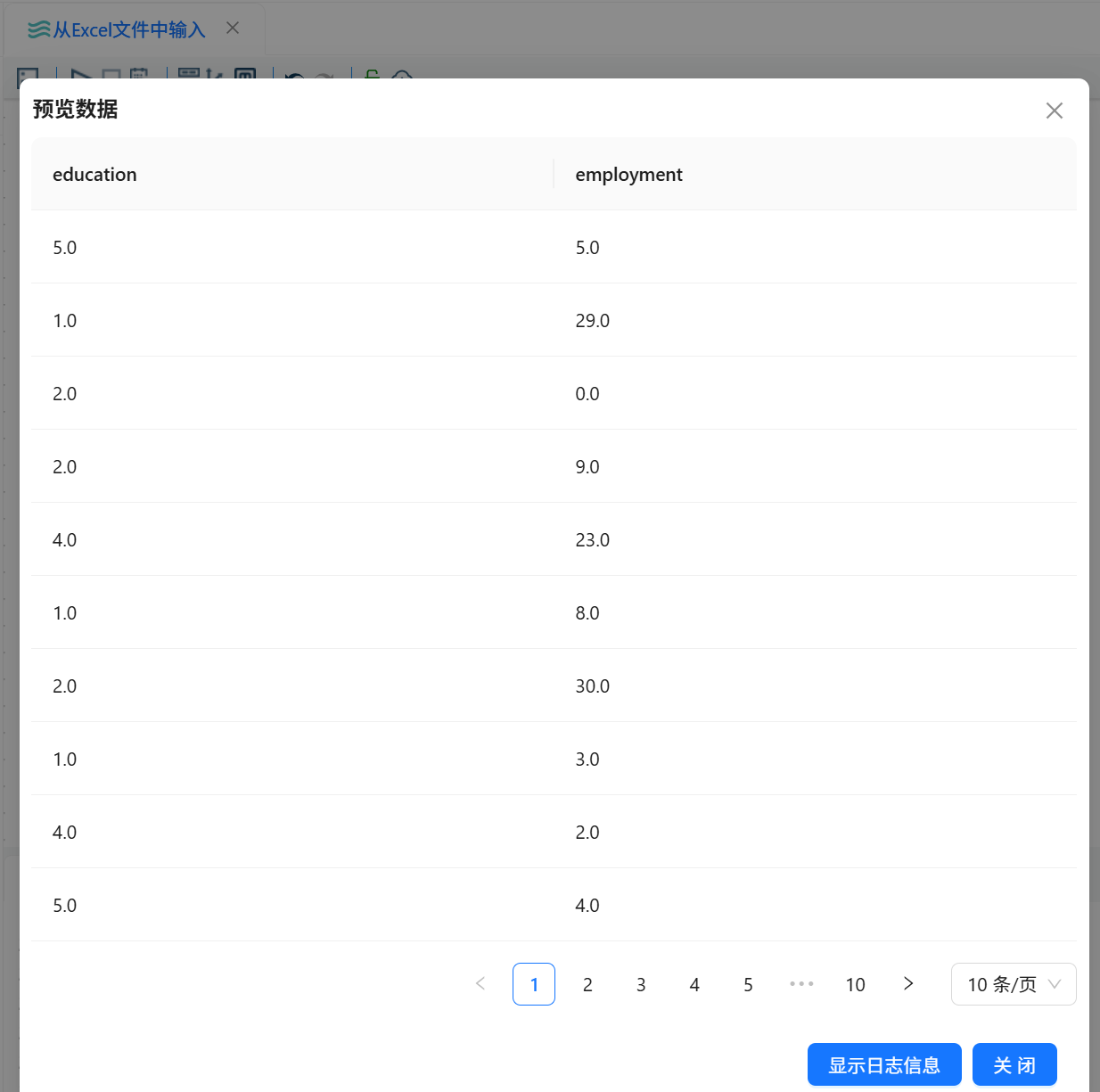
第三部分:实验结果
3.1 CSV 项目绩效加工结果
CSV 项目数据加工流程成功运行后,在文件库中生成了新的输出文件:
porject_output.csv
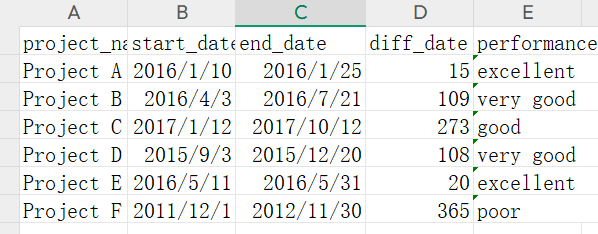
该文件包含原始项目数据,同时新增了两个字段:
diff_date
performance
其中,diff_date 表示项目执行天数,performance 表示根据执行天数生成的绩效等级。
绩效判断规则如下:
| diff_date 范围 | performance |
|---|---|
| 0 ≤ x < 30 | excellent |
| 30 ≤ x < 180 | very good |
| 180 ≤ x < 360 | good |
| x ≥ 360 | poor |
从输出结果可以看出,日期差计算和绩效等级判断均已生效,说明 CSV 文件读取、字段传递、计算器处理、数值范围判断和文件输出流程正常。
3.2 文本文件字段筛选结果
文本文件 usa_201209.txt 成功读取后,平台能够按照英文分号 ; 正确拆分字段。
经过字段选择组件处理后,Venue 字段被移除,其他足球比赛数据字段正常保留。
验证结果说明:
1. 文本文件可以通过 CSV 文件输入组件读取;
2. 分号分隔符配置正确;
3. 文件头部字段解析正确;
4. Venue 字段移除成功;
5. 数据能够完整传递到空操作组件。
3.3 Excel 字段筛选结果
Excel 文件 custinfo.xlsx 成功读取后,平台能够正确识别 Sheet1 工作表中的表头字段。
经过字段选择组件处理后,最终输出结果中只保留:
education
employment
这说明 Excel 文件读取、工作表选择、表头字段解析和字段筛选流程均已正常完成。
3.4 实验结果汇总
本次实验共完成三个 ETL 转换流程。
| 流程 | 输入文件 | 主要处理内容 | 输出结果 |
|---|---|---|---|
| CSV 项目绩效加工 | project.csv / porject.csv | 日期差计算、绩效等级判断 | porject_output.csv |
| 文本文件读取验证 | usa_201209.txt | 分号解析、移除 Venue 字段 | 空操作预览结果 |
| Excel 字段筛选 | custinfo.xlsx | 读取 Sheet1、保留指定字段 | 空操作预览结果 |
从最终结果看,三类文件数据都可以在助睿 ETL 平台中完成读取、解析、字段处理和结果验证。
第四部分:问题与解决
4.1 CSV 或文本文件字段无法正确拆分
问题现象:
预览数据时,多个字段挤在同一列中,字段数量明显不正确。
问题原因:
列分隔符配置错误。CSV 文件通常使用英文逗号分隔,而 usa_201209.txt 使用英文分号分隔。如果分隔符与文件实际格式不一致,字段就无法正确拆分。
解决方法:
根据文件实际内容设置分隔符。CSV 文件使用英文逗号时,分隔符配置为 ,;文本文件使用英文分号时,分隔符配置为 ;。配置后重新获取字段并预览验证。
4.2 日期差计算结果为空或报错
问题现象:
计算器组件运行后,diff_date 字段为空,或者流程执行时出现类型转换错误。
问题原因:start_date 和 end_date 字段没有被正确识别为日期类型,或者日期格式不符合组件识别规则。
解决方法:
检查 start_date 和 end_date 字段的类型和格式。必要时先完成字段类型转换,再使用计算器组件进行日期差计算。
4.3 数值范围组件没有生成 performance 字段
问题现象:
流程运行成功,但输出文件中没有 performance 字段,或者该字段为空。
问题原因:
数值范围组件中的输入字段、输出字段或区间规则配置不完整。常见情况包括输入字段没有选择 diff_date,输出字段名称未填写,或者最后一个区间没有覆盖到较大的数值范围。
解决方法:
确认数值范围组件中输入字段为 diff_date,输出字段为 performance,并完整配置四个绩效区间。
4.4 Excel 没有正确识别字段名
问题现象:
Excel 输入组件读取后,字段名显示异常,或者第一行数据被当成普通数据。
问题原因:
内容配置中没有启用“头部”选项,导致平台没有将第一行识别为字段名称。
解决方法:
在 Excel 输入组件的内容配置中启用“头部”,并重新从表头获取字段。
4.5 Excel 读取到了错误的工作表
问题现象:
Excel 数据预览为空,或者字段和预期不一致。
问题原因:
Excel 文件中可能存在多个工作表,如果没有指定 Sheet1,组件可能读取到错误工作表。
解决方法:
在工作表配置中指定 Sheet1,并基于该工作表重新获取字段和预览数据。
第五部分:实验总结
本次实验使用助睿 ETL 数据集成平台完成了 CSV、文本文件和 Excel 文件三类常见文件数据源的读取与基础处理。
在 CSV 文件处理中,我们读取项目数据,计算项目开始日期和结束日期之间的天数差,并根据天数区间生成绩效等级,最后输出新的 CSV 文件。这个流程完整覆盖了文件读取、字段计算、分类判断和结果输出。
在文本文件处理中,我们使用“CSV 文件输入”组件读取 .txt 文件。实验说明,只要文本文件内部具有稳定的分隔符结构,也可以按照结构化数据进行解析。通过移除 Venue 字段并预览结果,可以验证字段筛选是否生效。
在 Excel 文件处理中,我们通过“Excel 输入”组件读取 custinfo.xlsx,选择 Sheet1 工作表,并从表头获取字段。随后只保留 education 和 employment 字段,为后续购房者信息分析和建模做了基础准备。
整体来看,本次实验帮助我熟悉了助睿 ETL 平台中文件数据抽取的基础流程,也进一步理解了 ETL 中“抽取—转换—验证”的处理逻辑。后续进行商业数据分析、机器学习建模或可视化展示时,可以先通过类似流程完成数据预处理,为后续分析提供结构清晰、字段可用的数据基础。

一站式 AI 云服务平台
更多推荐

 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)