
商业数据分析实验六
实验六:浏览器用户画像分析-大屏静态布局制作+数据接入+交互设置
一、实验背景
1.1 实验目的
本系列实验基于之前加工完成的用户画像统计表(user_profile_stats),利用助睿Max数据大屏平台,完成一个完整的浏览器用户画像分析大屏的设计、开发与交互配置。
通过本实验,将掌握:
大屏静态布局设计:根据分析需求,合理设计大屏的信息结构与叙事逻辑,选择合适的图表类型(地图、饼图、柱状图、指标卡等)来表达不同维度的数据。
数据接入与联动:使用助睿Max的蓝图编辑器,通过可视化的“节点-连线”方式,配置数据源、SQL查询、参数传递和组件间的交互联动。
高级交互设置:实现多屏切换(市场分析/用户画像)、地图热力渲染以及省份下钻(点击地图省份,联动更新核心指标)等企业级大屏功能。
1.2 实验环境
实验平台:助睿在线实验平台 (https://lab.guilian.cn/)。
该平台提供从数据接入、ETL处理到可视化展示的全链路服务。本实验主要使用其助睿Max(数据大屏) 模块。
数据来源:团队私有数据库(MySQL)中的 user_profile_stats 表。
该表按浏览器维度(browser_name)统计了用户在各人口属性上的分布,字段包括:性别、年龄、年龄段、学历、职业、收入、居住地类型、省份及用户数。
1.3 整体处理流程
实验整体分为三个逻辑阶段,对应三个子实验:
静态布局制作:在大屏画布上,通过拖拽组件(地图、图表、指标卡、筛选器等)搭建出大屏的视觉框架。
数据接入与蓝图配置:将组件导出至蓝图编辑器,配置数据查询SQL和数据处理节点,实现筛选器与所有图表的联动。
交互设置与发布:配置大屏切换按钮,并实现地图省份点击下钻至核心指标卡的高级交互。
二、实验步骤
6-1浏览器用户画像分析-大屏静态布局制作
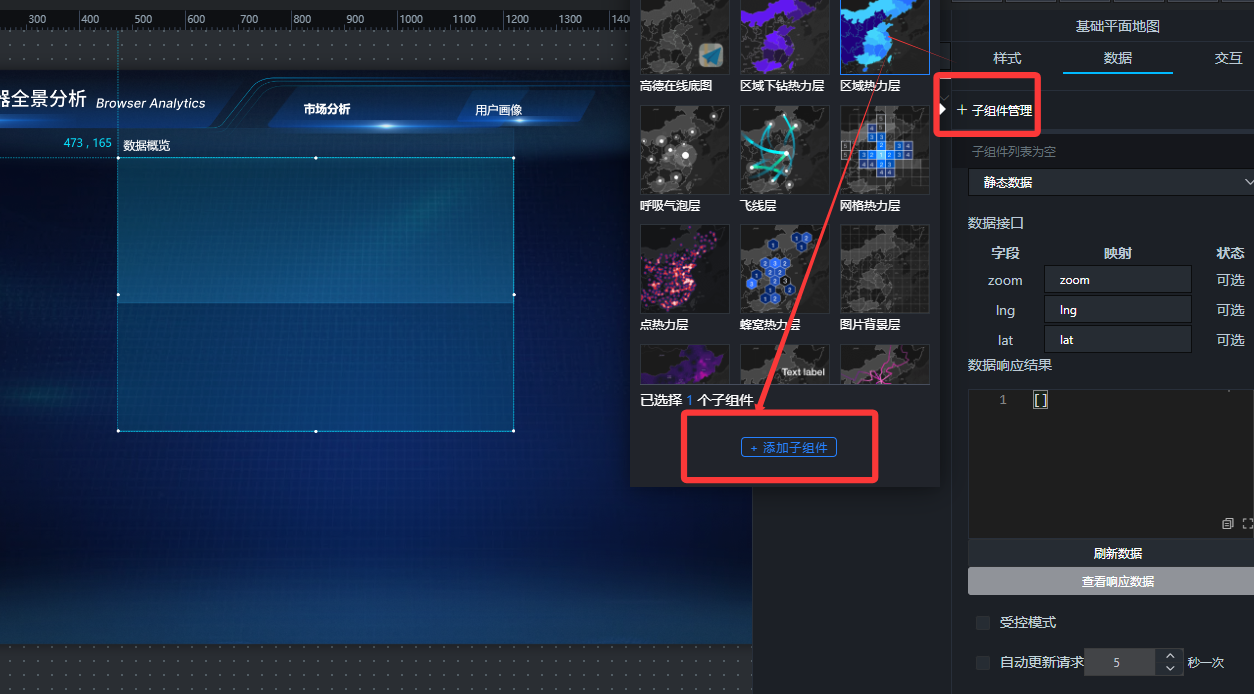
- 添加“基础平面地图”组件

点击“区域热力层”进入子组件配置页面
- 添加4个“数字翻牌器”
- 用户数TOP5省份排行榜

- 性别分布
(1)使用“单张图片”组件设置区域背景,并设置好标题
(2)添加“基础饼图”组件,调整大小和位置

- 年龄段分布
(1)使用“单张图片”组件设置区域背景,并设置好标题
(2)助睿Max 支持多种柱状图:基础柱图、弧形柱图、水平基础柱图、水平胶囊柱图、垂直胶囊柱图、垂直基本柱图(堆叠柱状图),这里我们使用基础柱图:

- 学历分布
实验步骤:
(1)使用“单张图片”组件设置区域背景,并设置好标题
(2)这里我们使用助睿Max 的水平基础柱图:

- 职业分布
实验步骤:
(1)使用“单张图片”组件设置区域背景,并设置好标题
(2)这里我们使用助睿Max的基础柱图:
- 收入分布
实验步骤:
(1)使用“单张图片”组件设置区域背景,并设置好标题
(2)这里我们使用助睿Max 的水平基础柱图:
- 居住地类型分布
实验步骤:
(1)使用“单张图片”组件设置区域背景,并设置好标题
(2)为了使大屏可视化效果更丰富,这里我们使用助睿Max 的轮播饼图:

- 筛选器
实验步骤:
(1)在大屏顶部右侧合适位置,添加“下拉选择”组件(位于“交互”组件分类中),重命名为“浏览器筛选”,调整组件位置和大小
(2)在组件右侧属性面板中,调整样式如下:

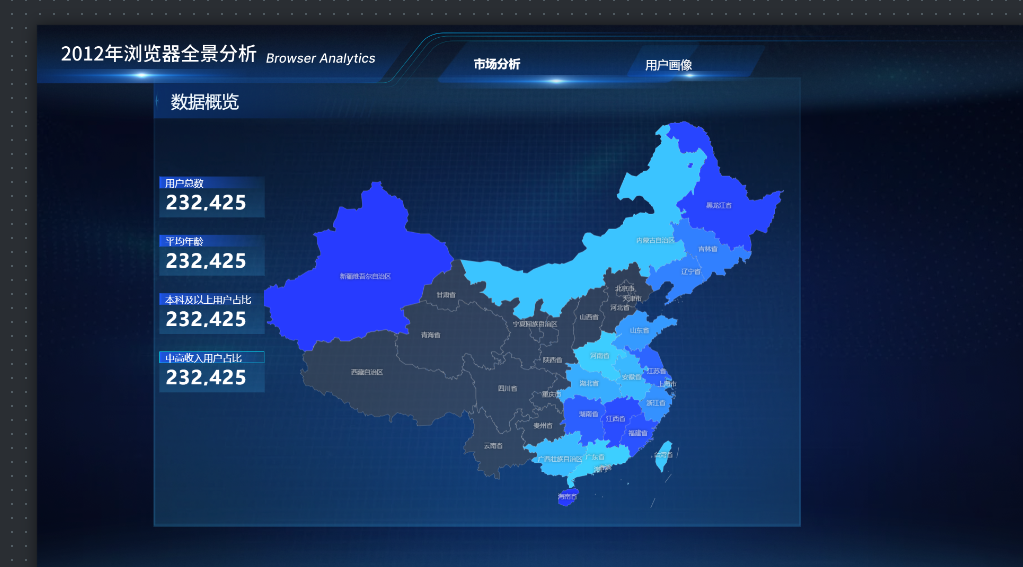
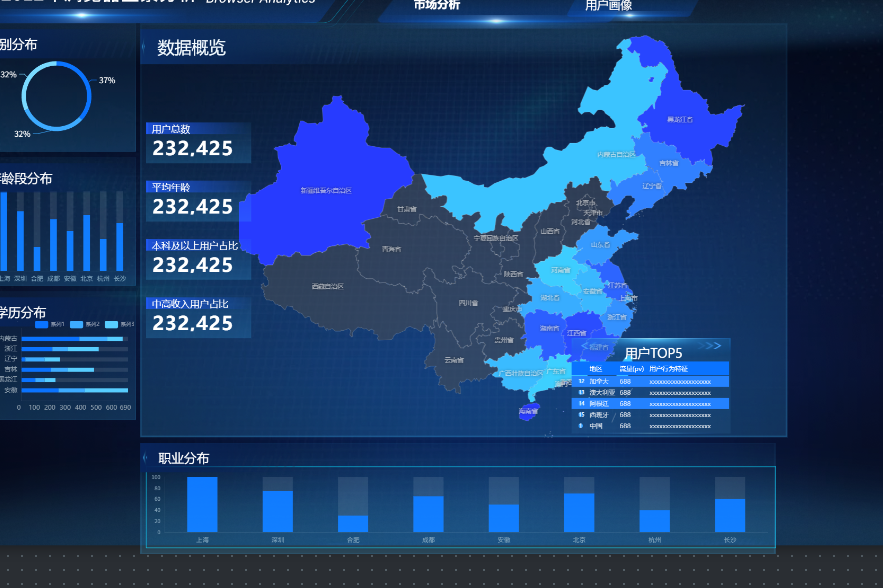
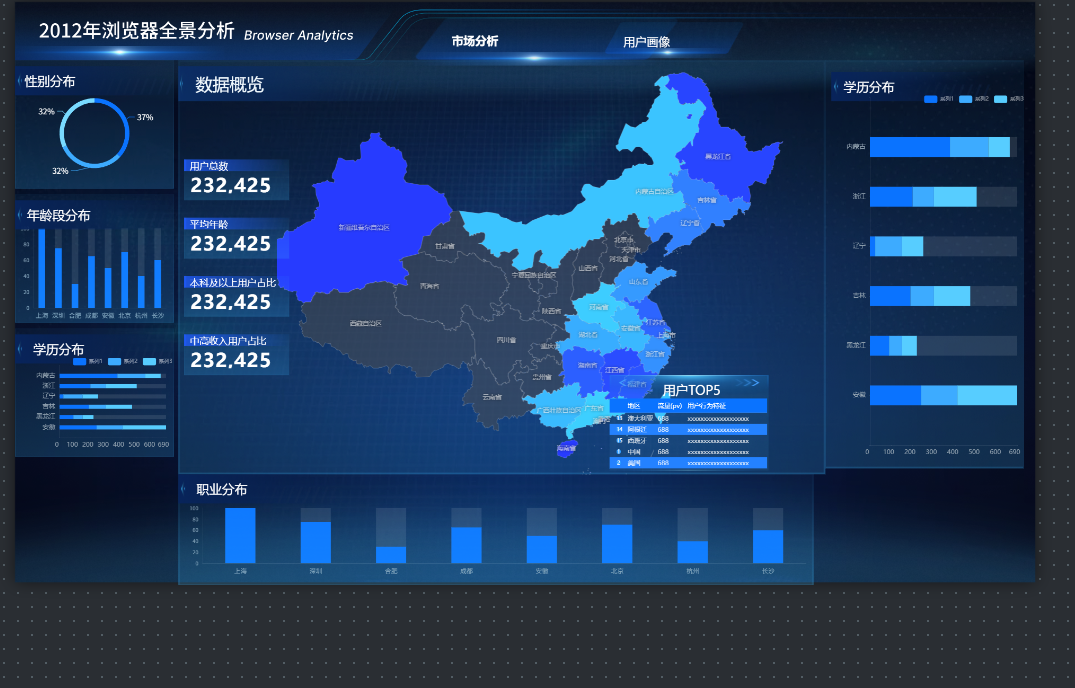
- 预览与总结

6-2浏览器用户画像分析-大屏数据接入
- 前置准备:添加年龄字段
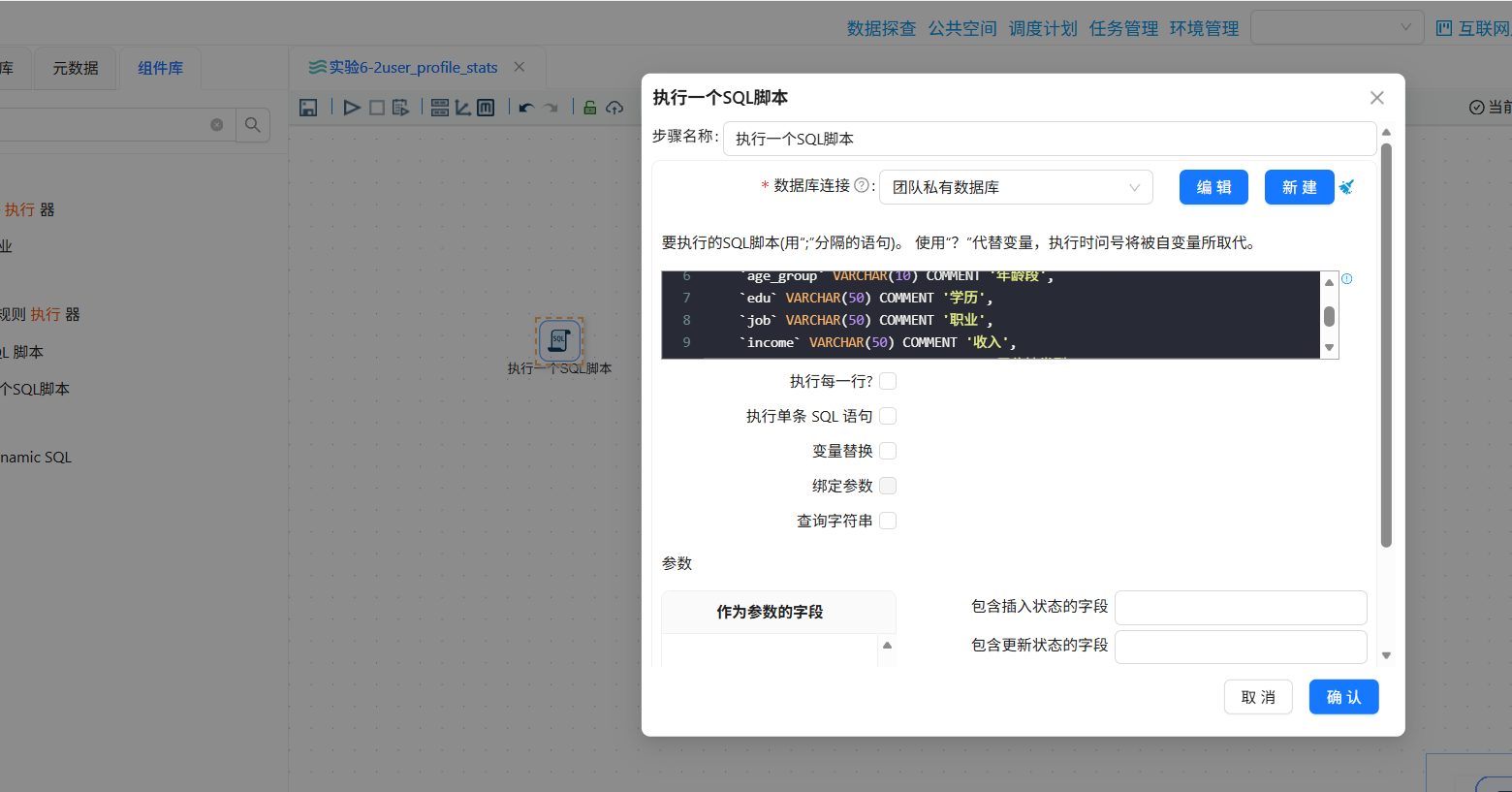
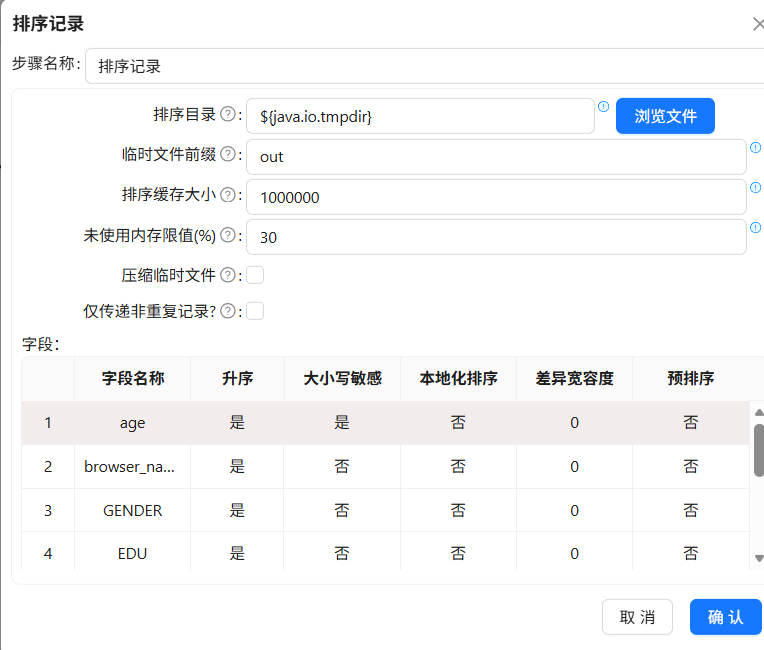
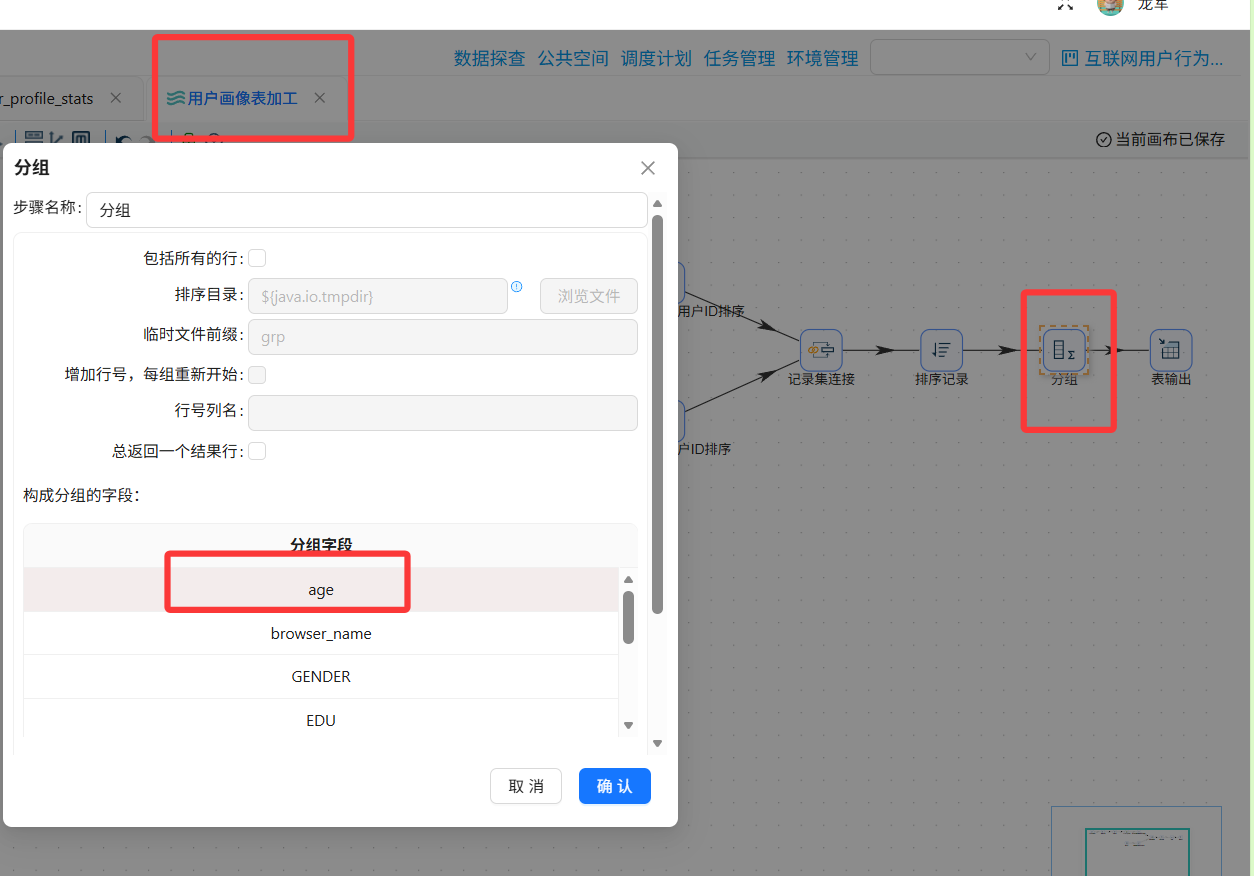
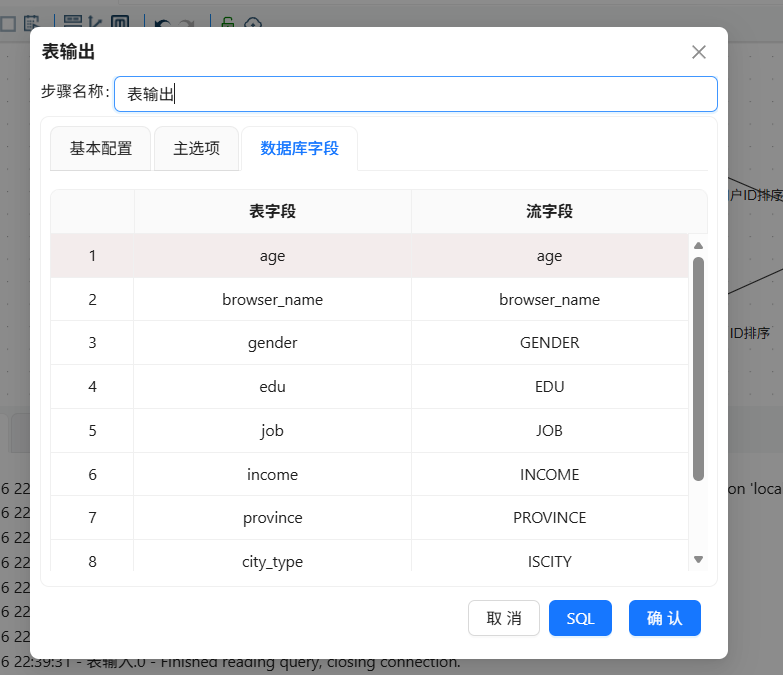
执行转换流
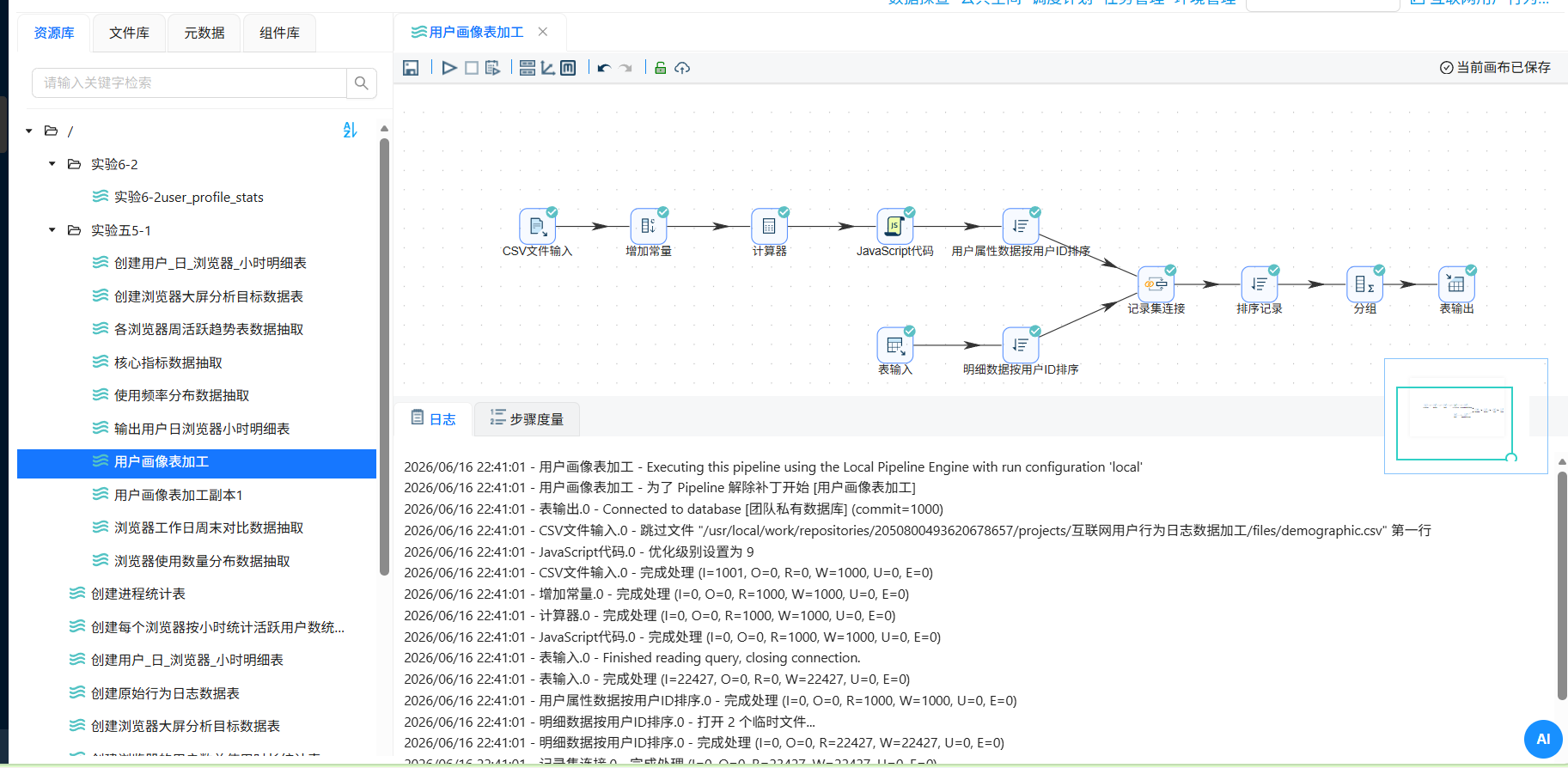
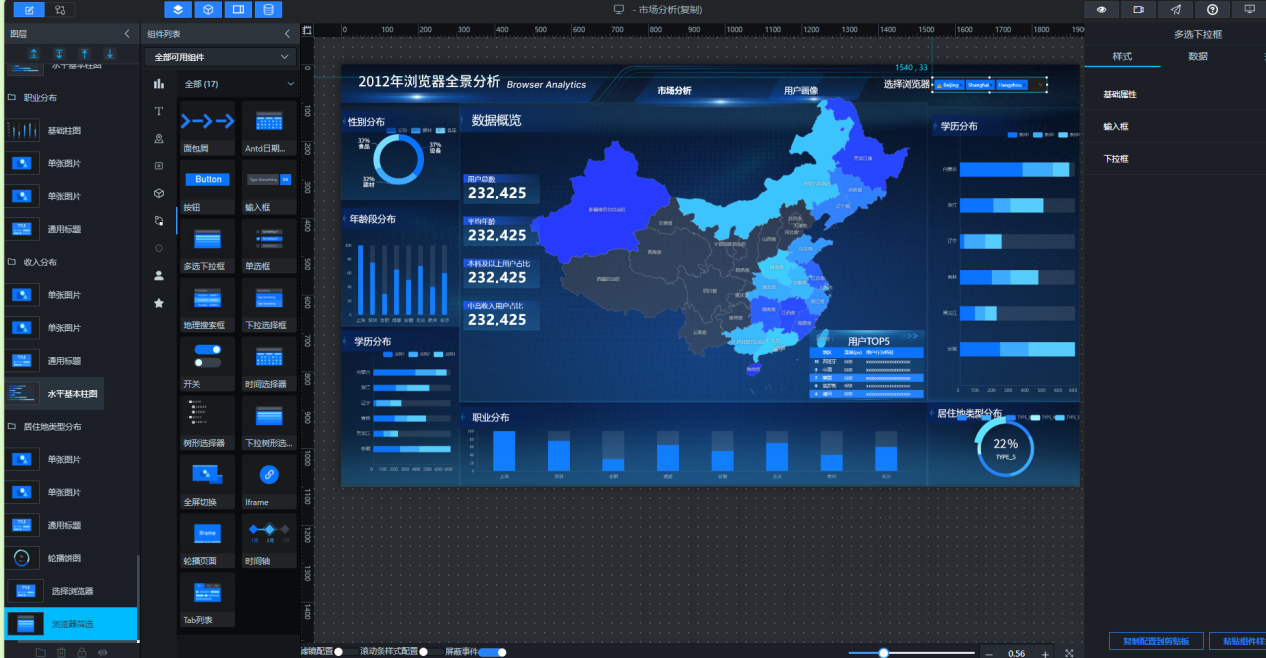
- 组件导出到蓝图编辑器
上周的实验【浏览器市场分析-大屏数据接入】已经介绍了如何连接数据源,本实验不再教学。
只有当组件导入到蓝图编辑器后,才可以为该组件配置交互。
打开上一实验制作的“用户画像”数据大屏,在画布编辑器内,右键单击左侧图层栏或中间画布区的组件,选择导出到蓝图编辑器,即可将对应组件导出到蓝图编辑器中。
将以下组件依次导出到蓝图编辑器:
浏览器筛选器(下拉多选)
性别分布饼图
年龄段分布柱状图
学历分布条形图
职业分布柱状图
收入分布柱状图
居住地类型饼图
用户省份分布地图
省份排行榜(轮播列表)
核心指标卡(总用户数、平均年龄、中高收入占比)
导出成功后,单击“蓝图编辑器”图标切换到蓝图编辑器页面,可在导入节点列表中查看对应的节点。列表内所有节点都可供后续配置交互使用。
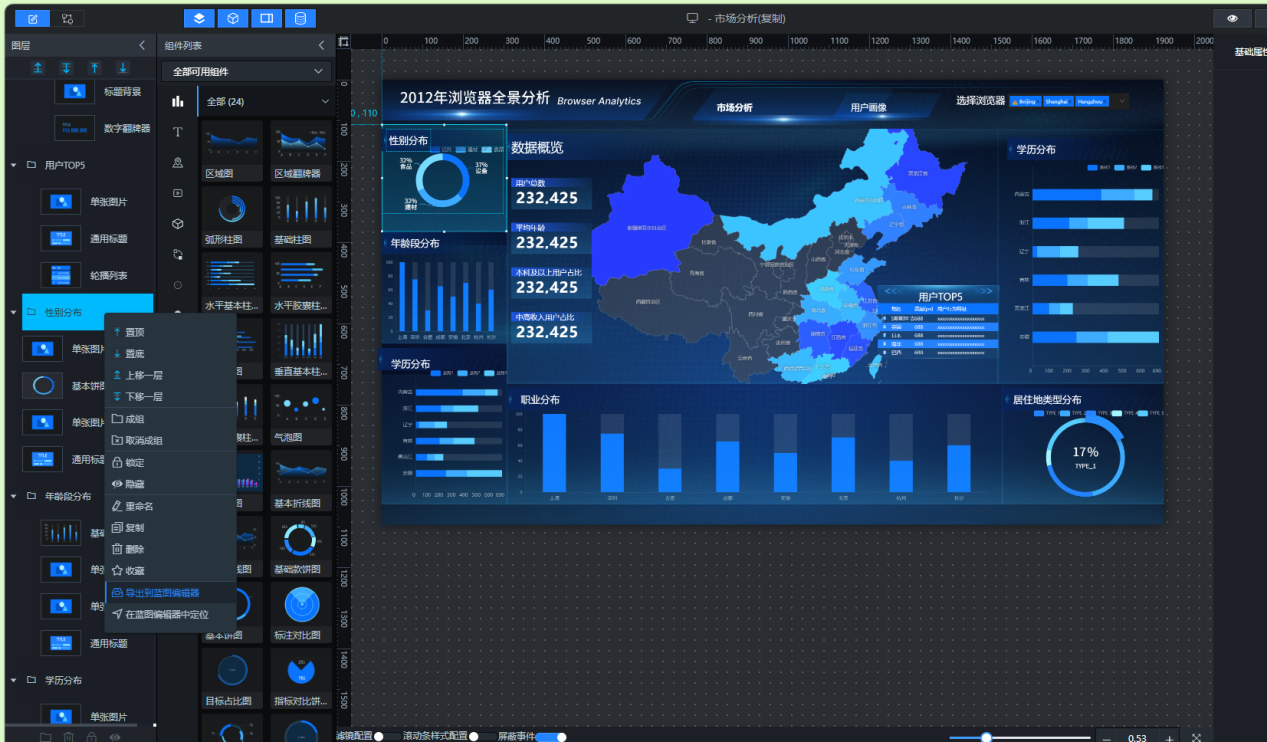
导入8个图表
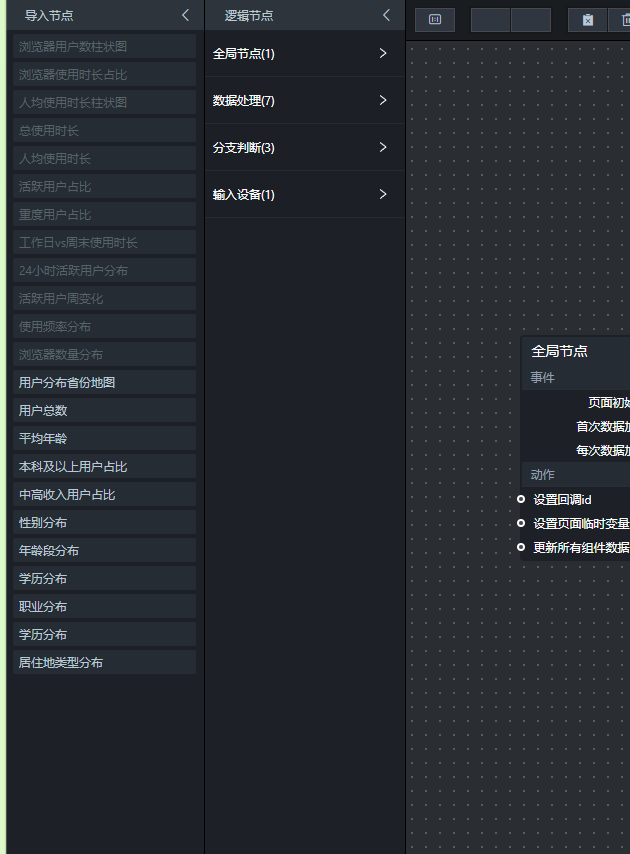
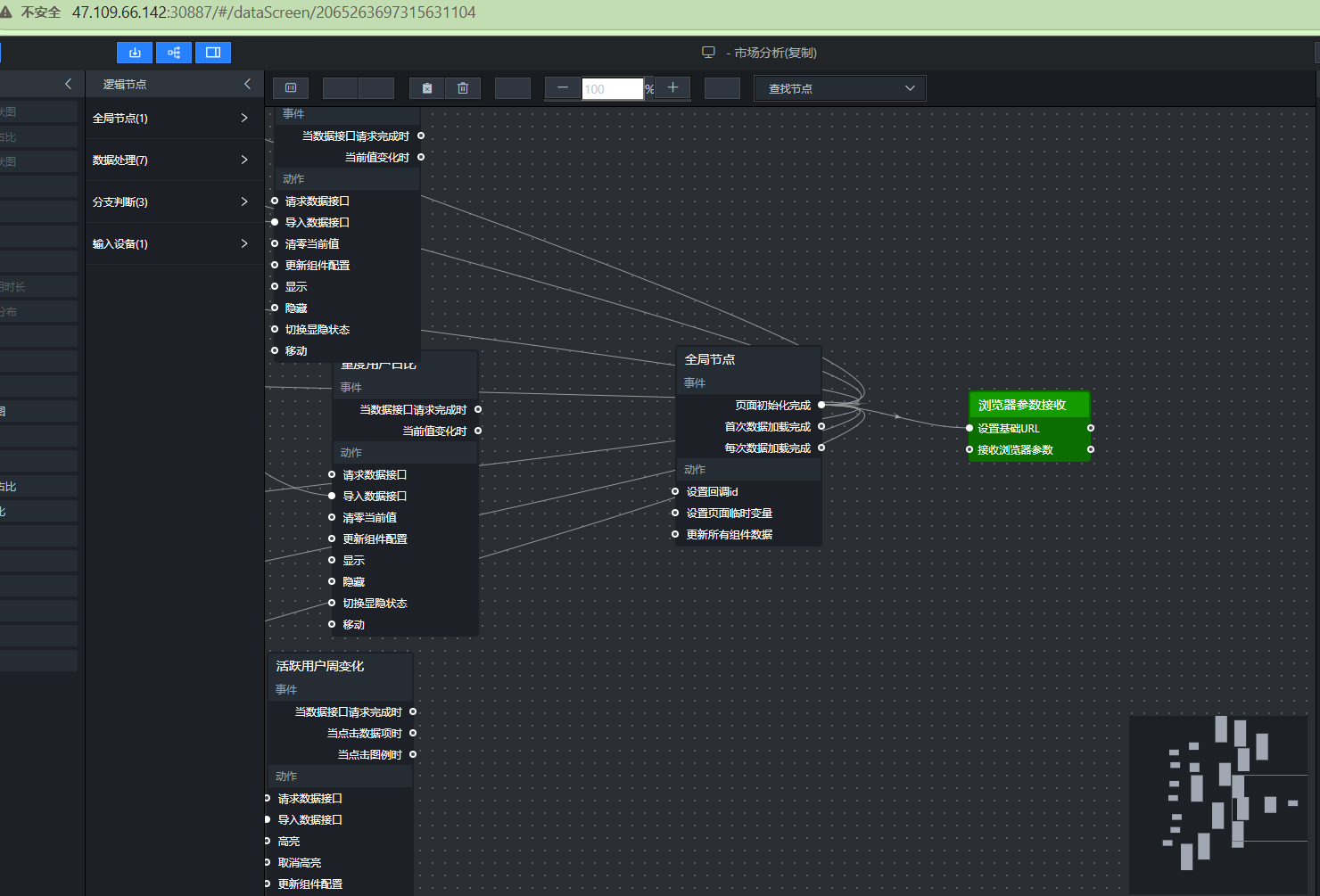
- 添加浏览器参数接收节点(并行数据处理)
这个节点就是“浏览器参数接收”,它用“并行数据处理”组件来实现,更改名字为”浏览器参数接收”
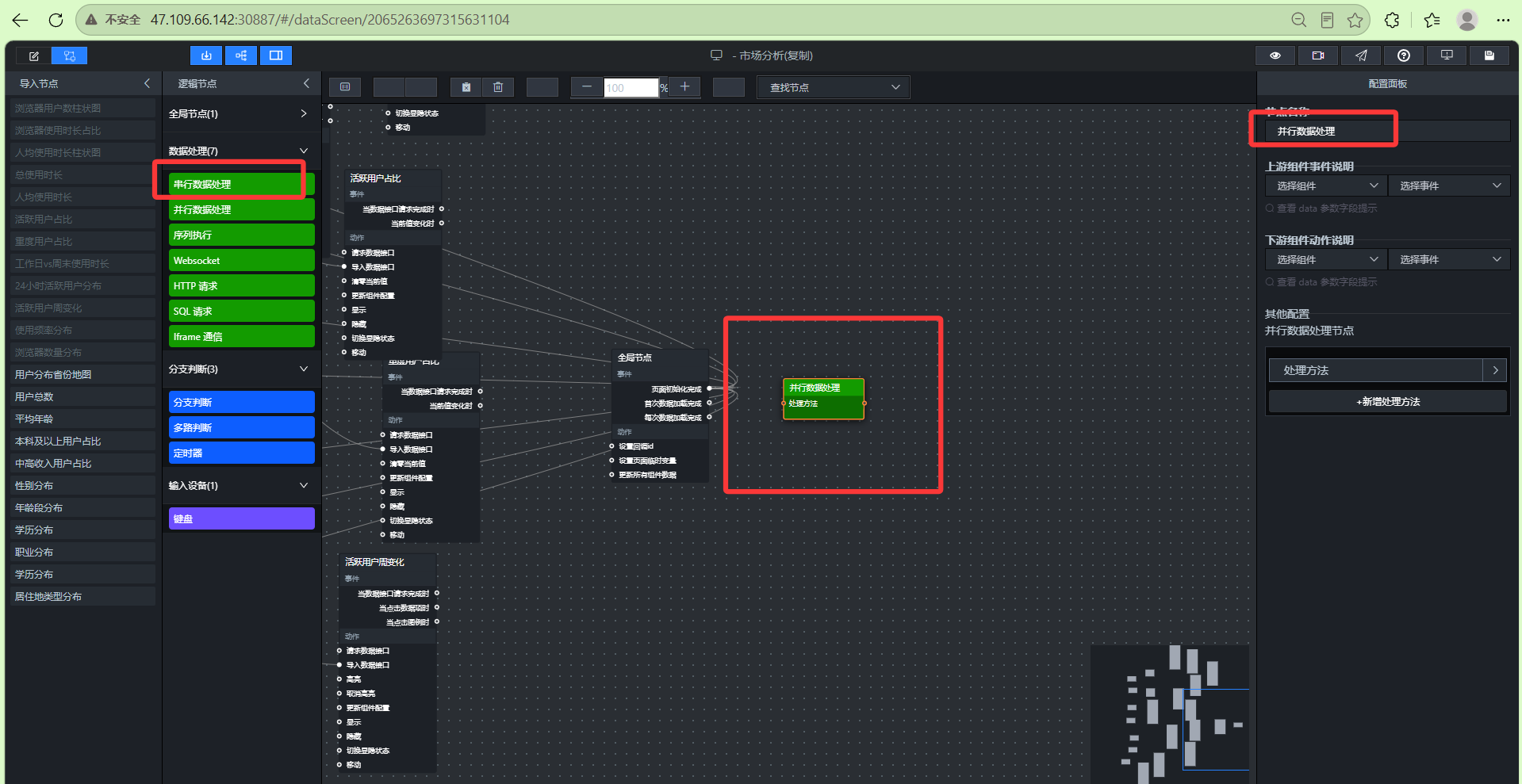
双击节点,添加两个处理方法:
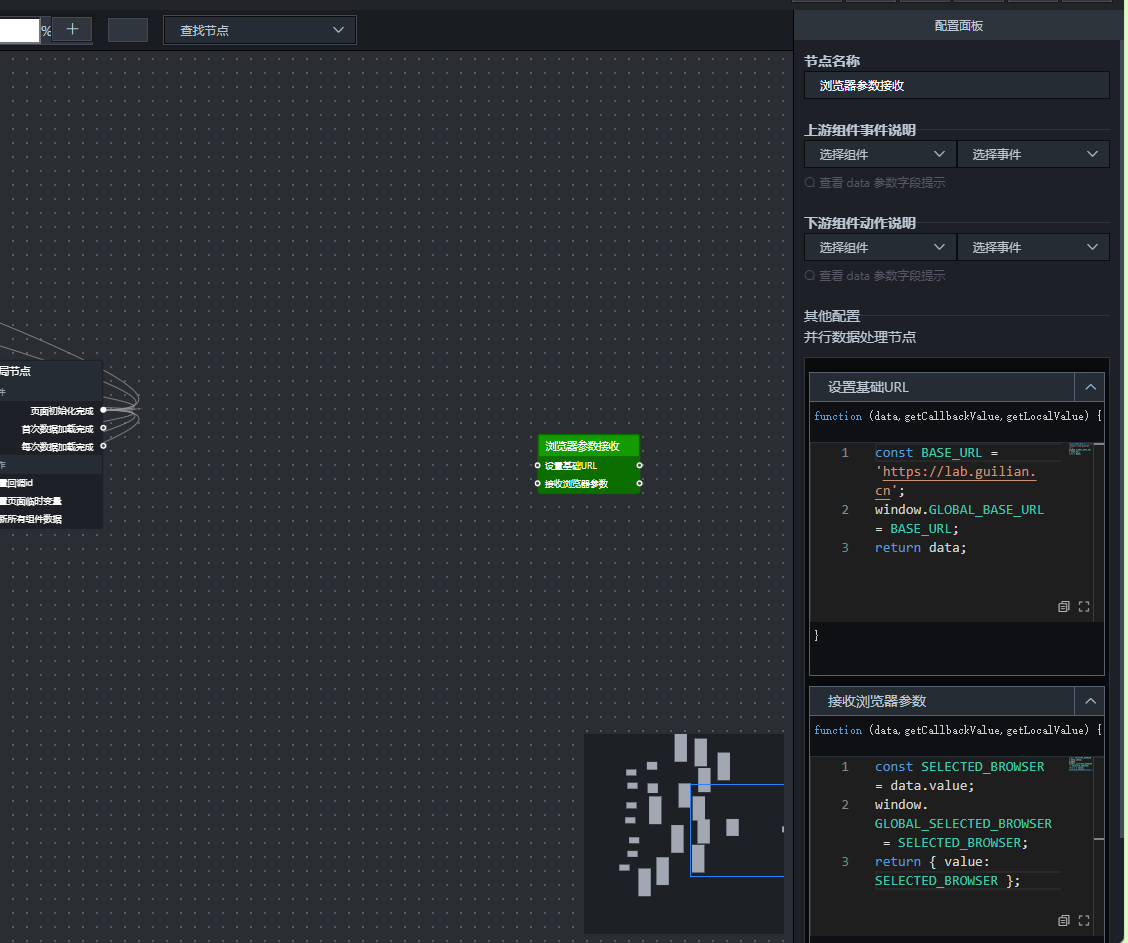
方法一(页面加载时执行一次,设置基础URL)
const BASE_URL = 'https://lab.guilian.cn';
window.GLOBAL_BASE_URL = BASE_URL;return data;
这个方法主要是为后续可能用到的外部API预留一个基础地址,本实验用不上,但保留结构。
方法二(每次筛选器变化时执行,接收浏览器参数)
const SELECTED_BROWSER = data.value;
window.GLOBAL_SELECTED_BROWSER = SELECTED_BROWSER;return { value: SELECTED_BROWSER };
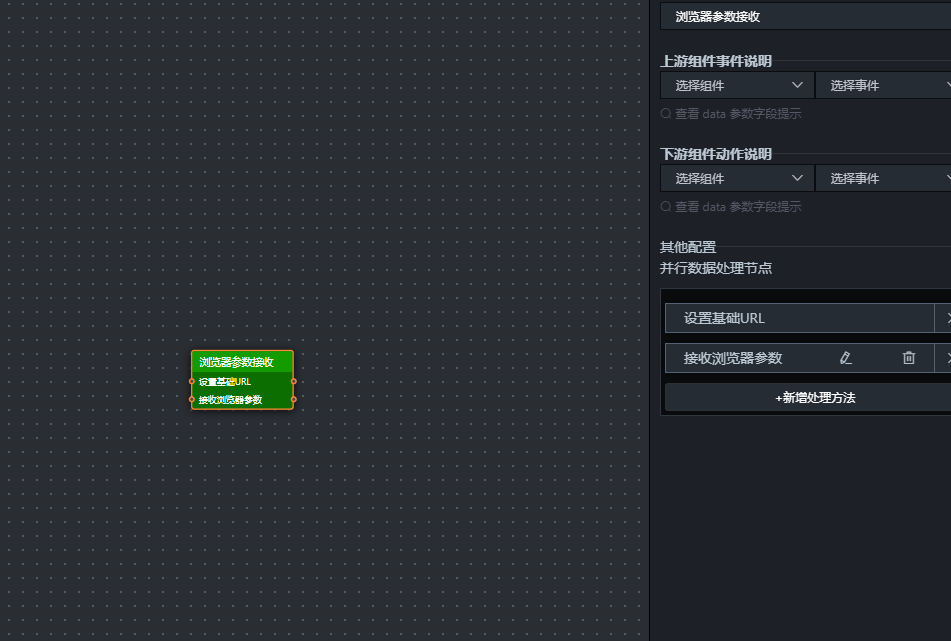
这个方法把用户选中的浏览器存到 window.GLOBAL_SELECTED_BROWSER 这个全局变量里。后面的SQL请求节点只要读取这个变量,就知道该查哪个浏览器的数据了。
连好线之后,整个流程是这样的:
大屏打开 → 页面加载触发 → 节点初始化
用户切换浏览器 → 筛选器输出新值 → 节点更新全局变量 → SQL重新执行 → 所有图表刷新
其中,浏览器的选项我们可以直接使用静态数据(因为个数不多):title为前端显示内容,value为实际查询内容,即数据库中存储的对应 browser_name,如:
{
"title": "IE浏览器",
"value": "IE浏览器"
}
我们需要填写6个浏览器的对应内容,并刷新数据,同时,输入框中默认选中设置为“IE浏览器”

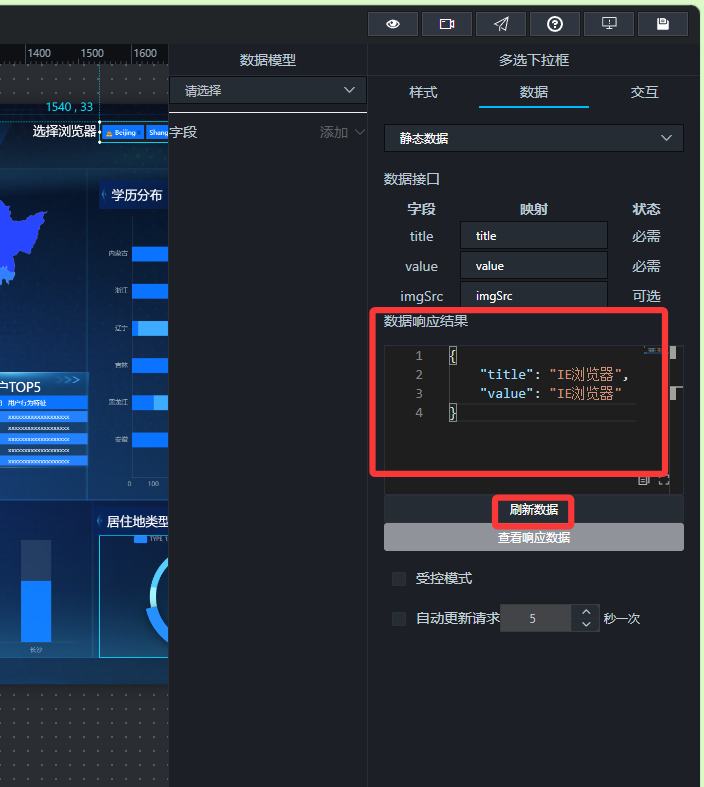
这样,一个筛选器就同时控制了所有图表。
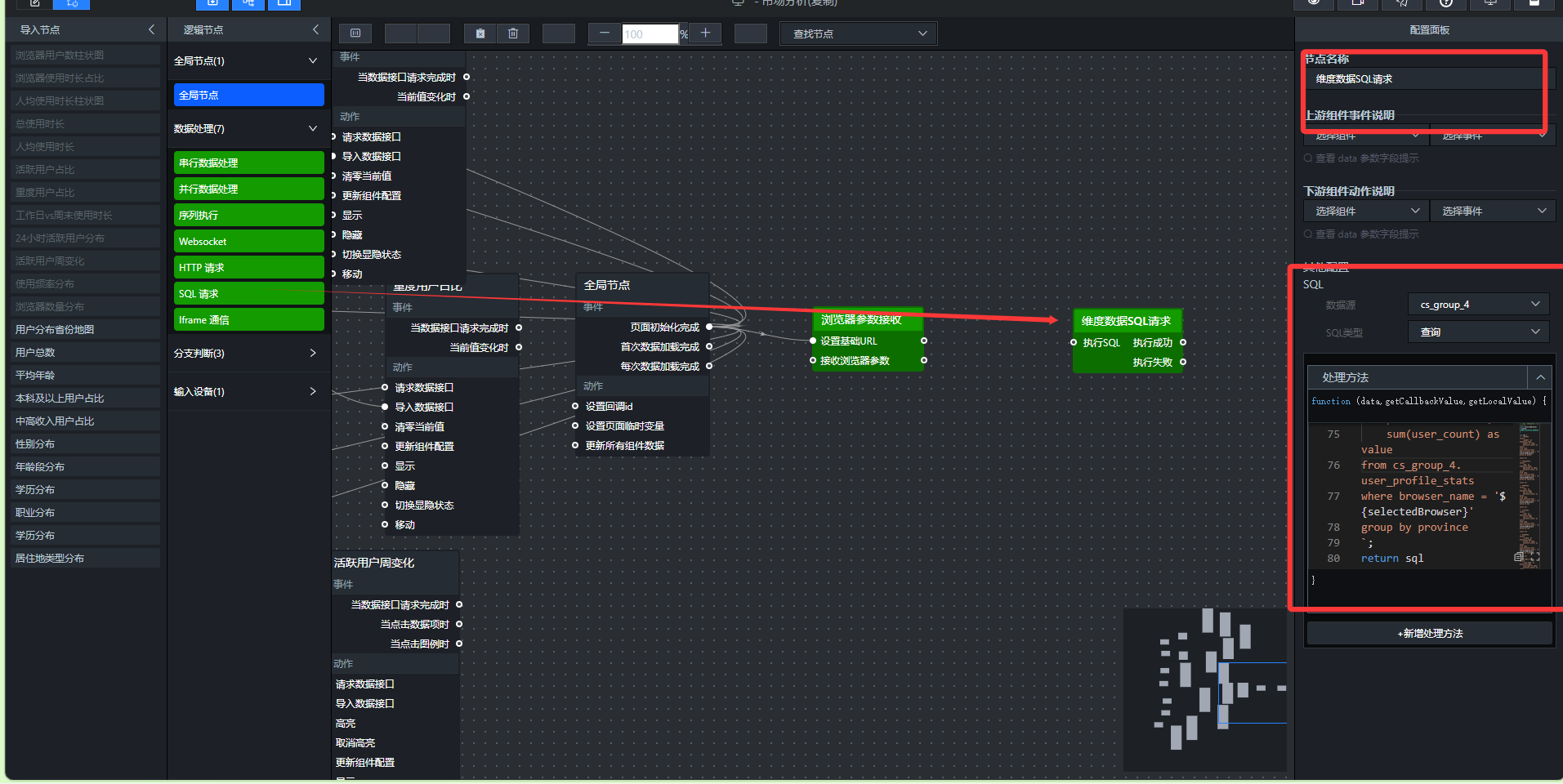
- 添加SQL请求节点(一次除指标外所有维度数据)
这个节点负责查询性别、年龄、学历、职业、收入、居住地类型、省份等维度数据,使用 UNION ALL 合并,输出格式为 (dimension_type, name, value)。
添加“SQL请求”节点,重命名为“维度数据SQL请求”
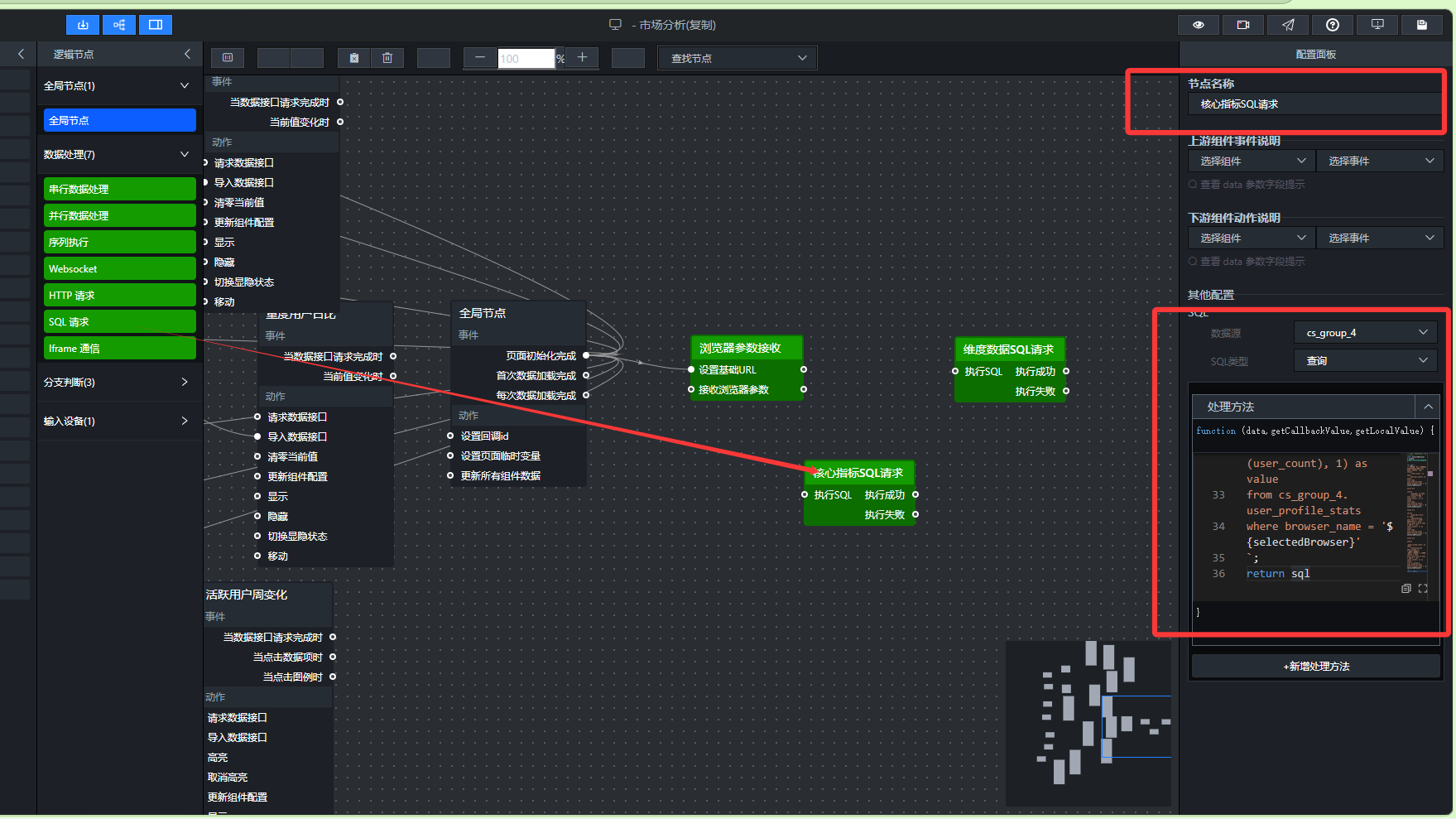
- 添加核心指标SQL请求节点(单独查询四个指标)
这个节点只查询四个核心指标,输出单行多列格式(一行包含四个字段),不需要 UNION ALL,取值更简单。
添加“SQL请求”节点,重命名为“核心指标SQL请求”
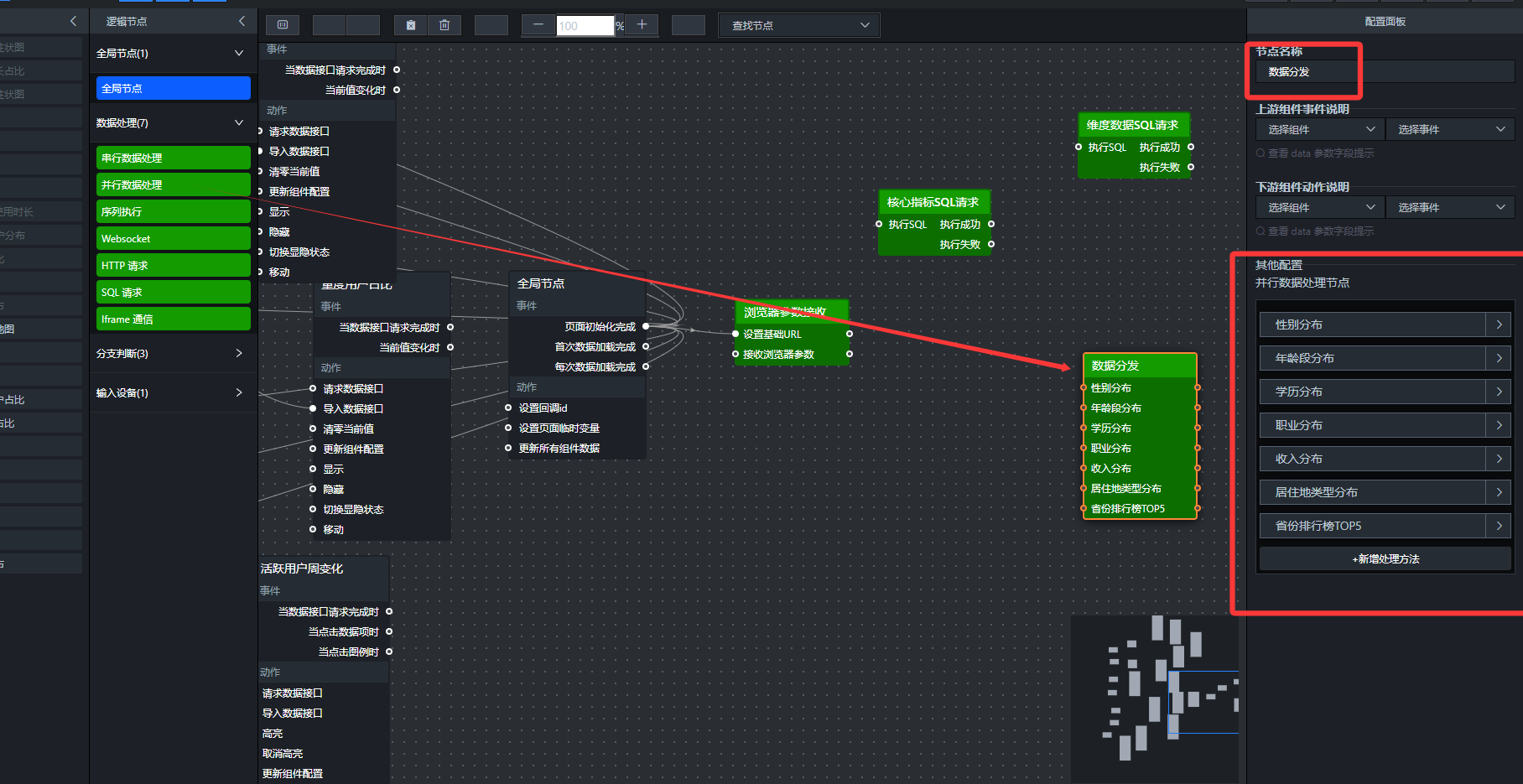
- 添加维度数据分发节点(并行数据处理)
添加“并行数据处理”节点,重命名为“数据分发”。将SQL请求节点的“执行成功”连接到该节点。
双击节点,为每个图表添加一个处理方法:
分支1:性别分布(饼图)
var filtered = data.filter(item => item.dimension_type === 'gender');return filtered.map(item => ({
name: item.name,
value: item.value
}));
分支2:年龄段分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'age');var order = ['<18', '18-25', '26-35', '36-45', '>45'];
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));return filtered.map(item => ({
x: item.name,
y: item.value,
s: '用户数'
}));
分支3:学历分布(条形图)
var filtered = data.filter(item => item.dimension_type === 'edu');
var order = ['小学及以下', '初中', '高中/中专/技校', '大专', '大学本科', '硕士及以上'];
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));return filtered.map(item => ({
x: item.name,
y: item.value,
s: '学历'
}));
分支4:职业分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'job');return filtered.map(item => ({
x: item.name,
y: item.value,
s: '职业'
}));
分支5:收入分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'income');
// 按收入金额升序排序(提取数字进行比较)
filtered.sort((a, b) => {
// 提取收入段中的最小金额
var getMinIncome = (incomeStr) => {
// 处理 "无收入"、"500元及以下" 等特殊情况
if (incomeStr === '无收入') return -1;
if (incomeStr === '500元及以下') return 0;
// 提取数字,如 "1501~2000元" 提取 1501
var match = incomeStr.match(/(\d+)/);
return match ? parseInt(match[1]) : 999999;
};
return getMinIncome(a.name) - getMinIncome(b.name);
});
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '收入'
}));
分支6:居住地类型分布(饼图)
var filtered = data.filter(item => item.dimension_type === 'city_type');return filtered.map(item => ({
name: item.name === 'unknown' ? '未知' : item.name,
value: item.value
}));
分支7:省份排行榜TOP5
这里需要注意,轮播列表的映射字段是通过“数据系列”中的系列1、系列2来决定的
/ 过滤出省份数据var filtered = data.filter(item => item.dimension_type === 'province');// 按用户数降序排序
filtered.sort((a, b) => b.value - a.value);// 取前5条var top5 = filtered.slice(0, 5);// 直接返回组件需要的字段名return top5.map(item => ({
province: item.name,
user_count: item.value
}));
以上的输出结果不正确的话,可以在最终输出结果的节点的处理方法代码中添加以下代码,查看返回的数据:
// console.log("返回的数据",data)
- 添加核心指标分发节点(并行数据处理)
添加另一个“并行数据处理”节点,重命名为“核心指标分发”。将“核心指标SQL请求”节点的“执行成功”连接到该节点。
分支示例(总用户数):
var item = data.find(item => item.name === 'total_users');return [{ value: item ? item.value : 0 }];
其他分支类似,只需修改 item.name === 'total_users'的条件即可

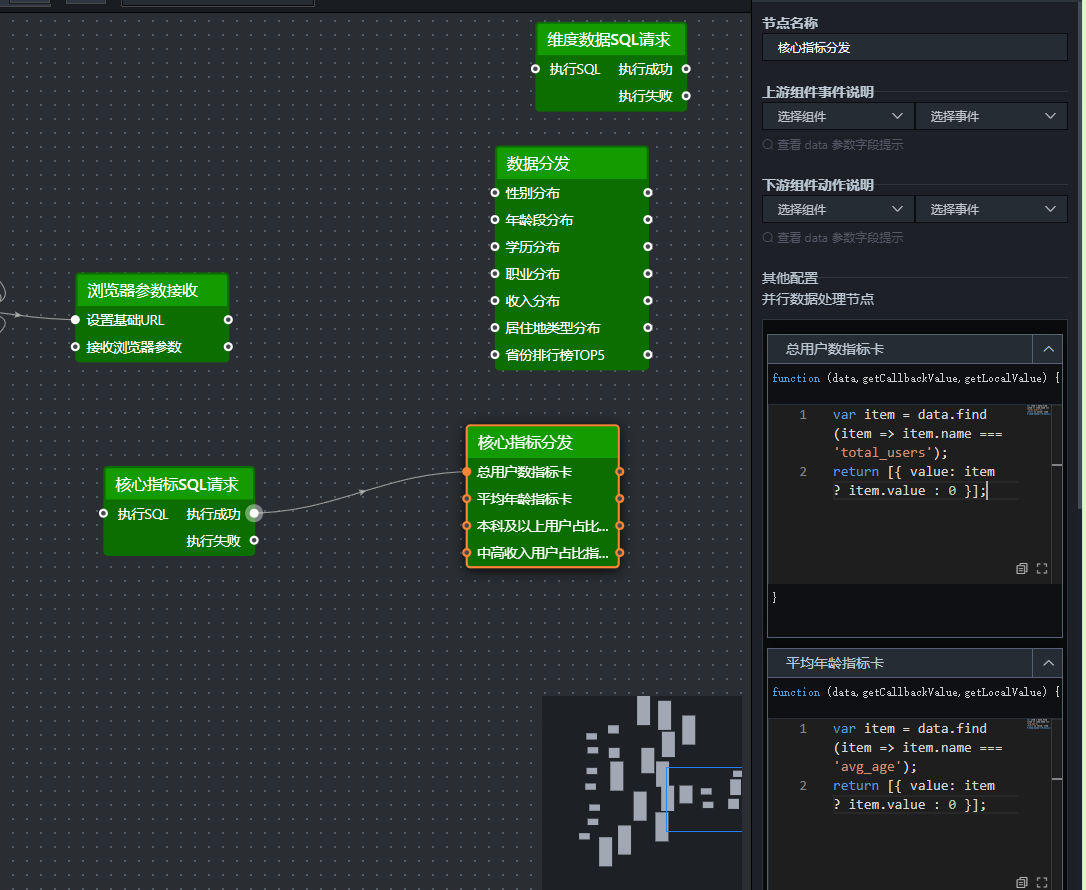
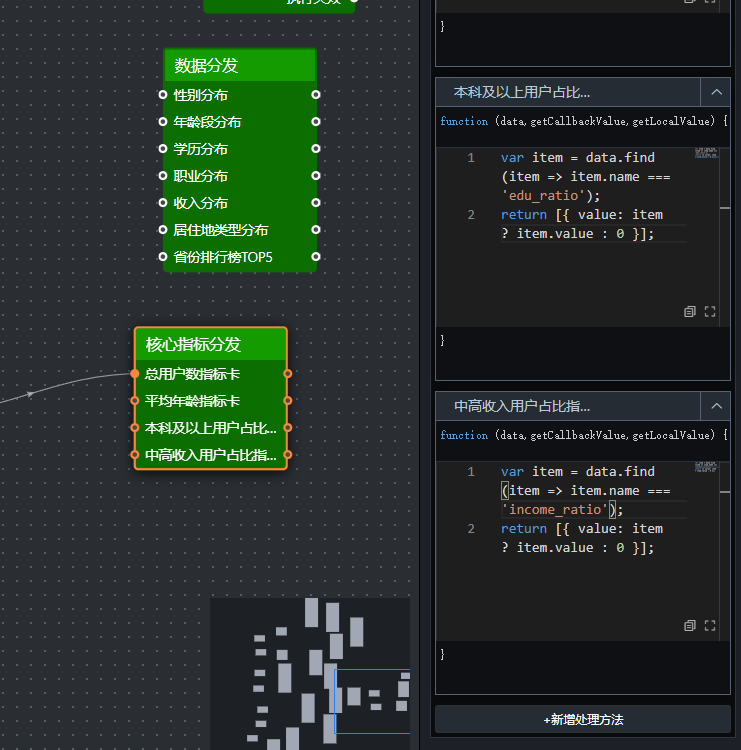
- 连接节点
按照4.6节的蓝图连接示意图,依次连接所有节点:
页面加载 → 浏览器参数接收(输入)
浏览器筛选器 → 浏览器参数接收(输入)
浏览器筛选器 → 维度数据SQL请求(执行SQL)
浏览器筛选器 → 核心指标SQL请求(执行SQL)
维度数据SQL请求(执行成功) → 维度数据分发(输入)
核心指标SQL请求(执行成功) → 核心指标分发(输入)
维度数据分发(分支1-8) → 各维度图表组件(导入数据接口)
核心指标分发(分支1-4) → 四个核心指标卡(导入数据接口)
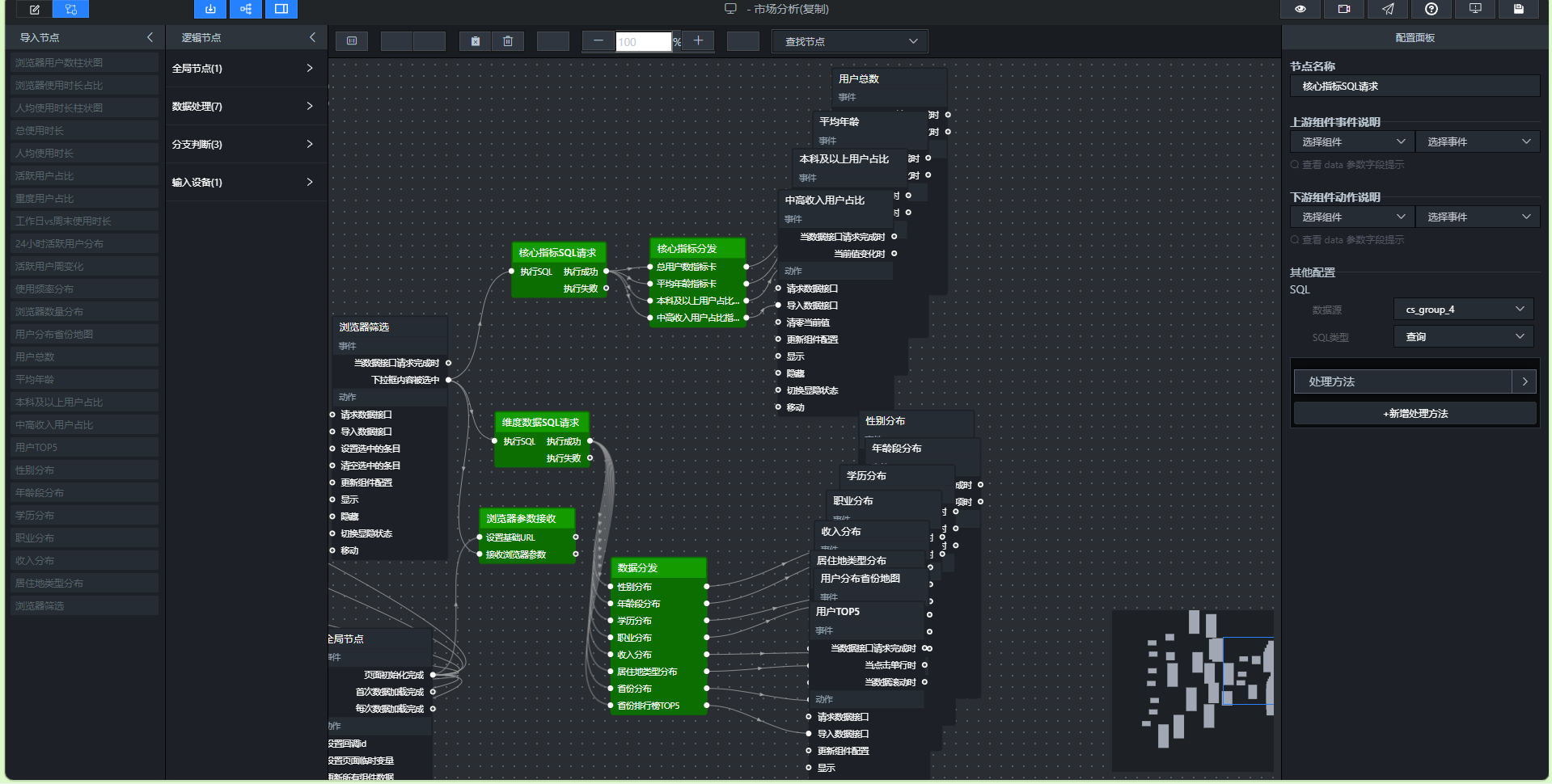
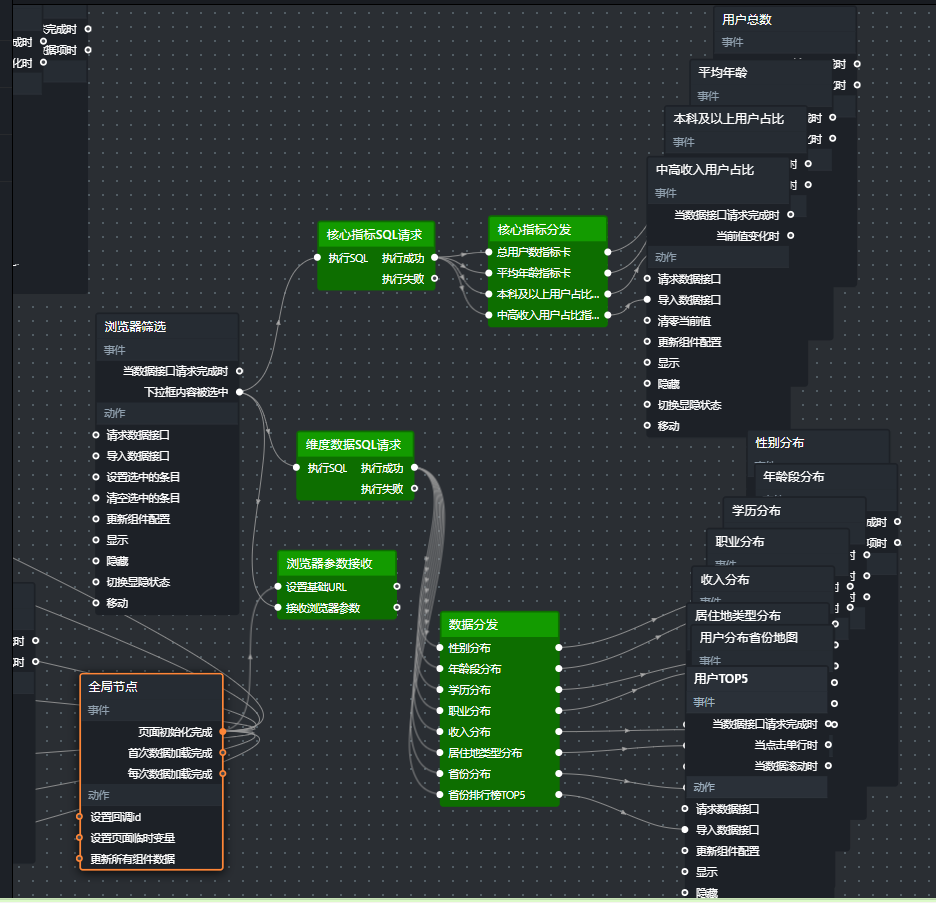
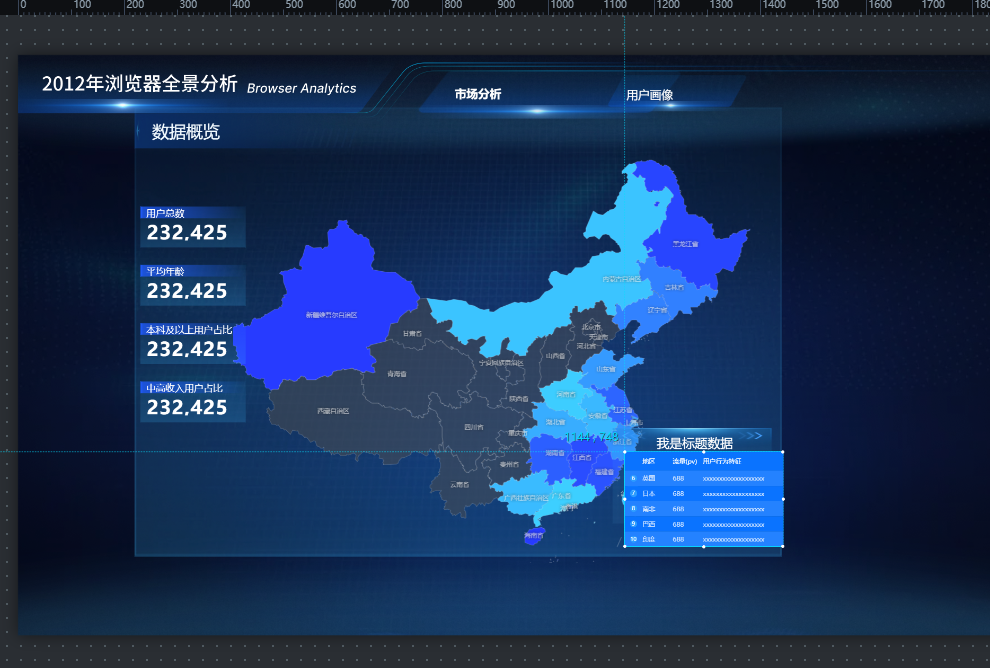
预览参考如下

6-3 2012年浏览器全景分析-大屏交互设置
- 配置大屏切换
(1)添加Tab列表组件,调整大小、位置,两个导航按钮重合

(2)Tab列表组件的基本设置中,设置行数为1,列数为2,再标签默认配置中,将“背景颜色”、“选中背景色”、“悬浮背景色”的透明度设置为0,这样就看不见Tab列表组件,给用户的感觉就是只有2个按钮

- 设置Tab列表组件每个选项的id:在数据中,保留2列数据,id分别为1、2,content为空,设置后记得刷新数据

(4)将“市场分析”组、“用户画像”组、Tab列表组件导出到蓝图编辑器
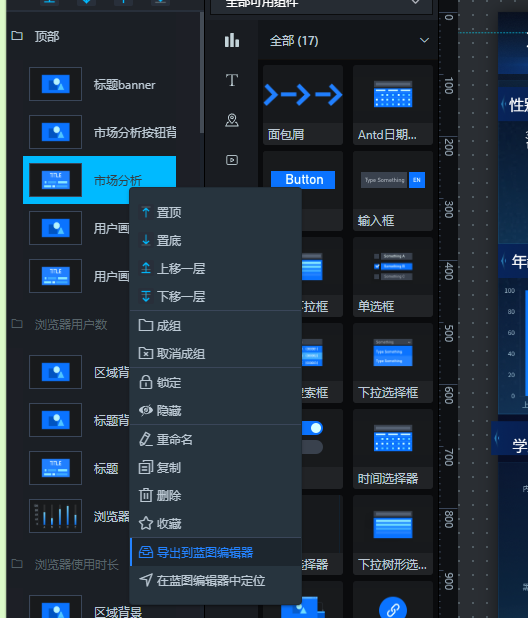
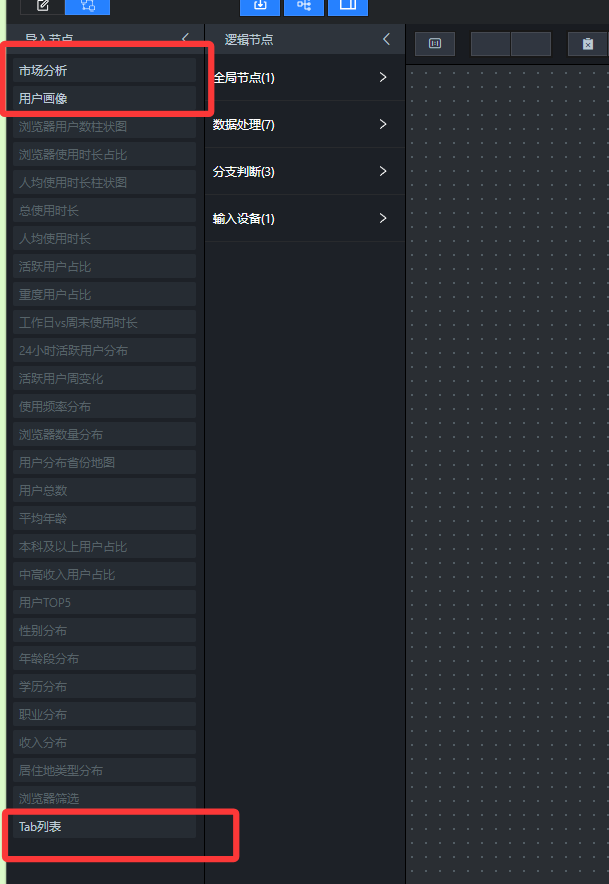
- 在蓝图编辑器中,将“市场分析”组、“用户画像”组、Tab列表组件添加到蓝图编辑器画布中,通过“分支判断”节点来做“当Tab点击时”的id判断,处理刚发为:
return data.id == 1;
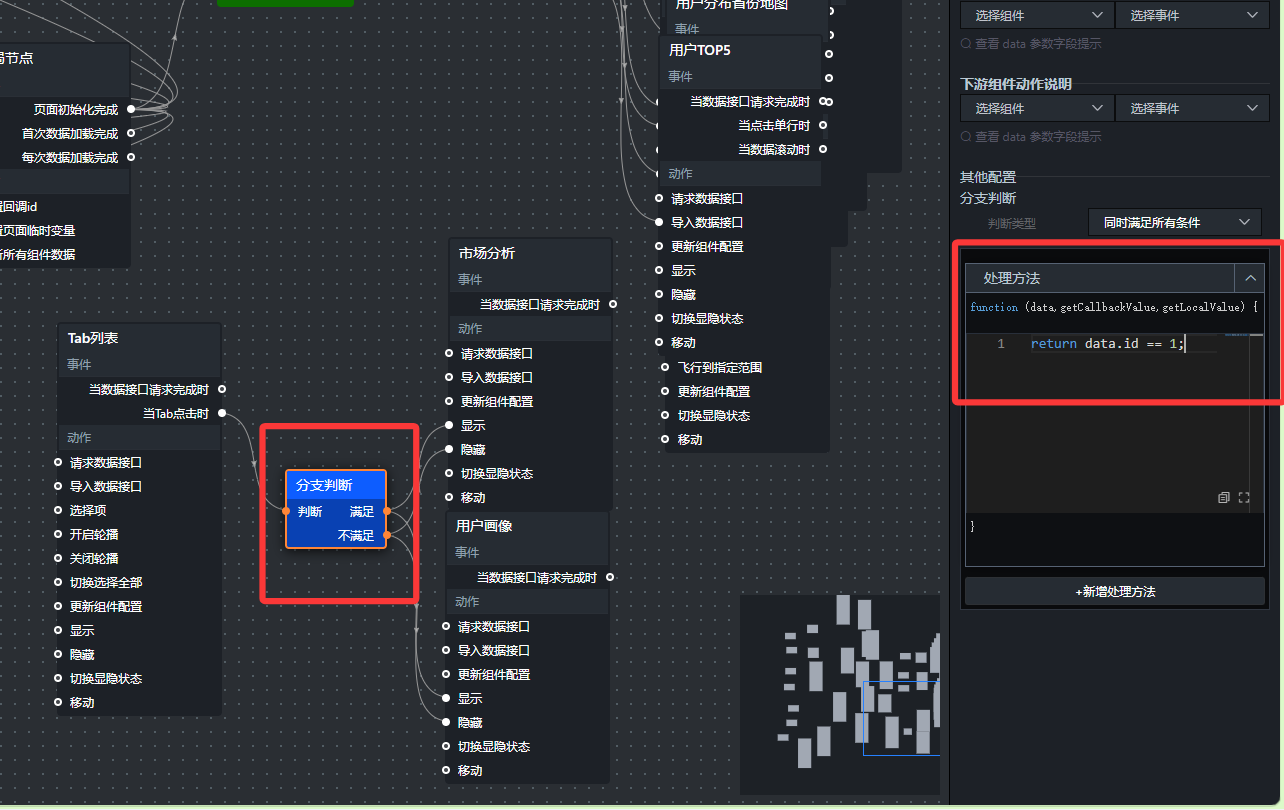
(6)在“分支判断”的 满足 分支上,添加两个“设置图层可见性”动作:
目标图层:市场分析组 → 显示
目标图层:用户画像组 → 隐藏
(7)在“判断选项卡”的 不满足 分支上,添加两个“设置图层可见性”动作:
目标图层:市场分析组 → 隐藏
目标图层:用户画像组 → 显示
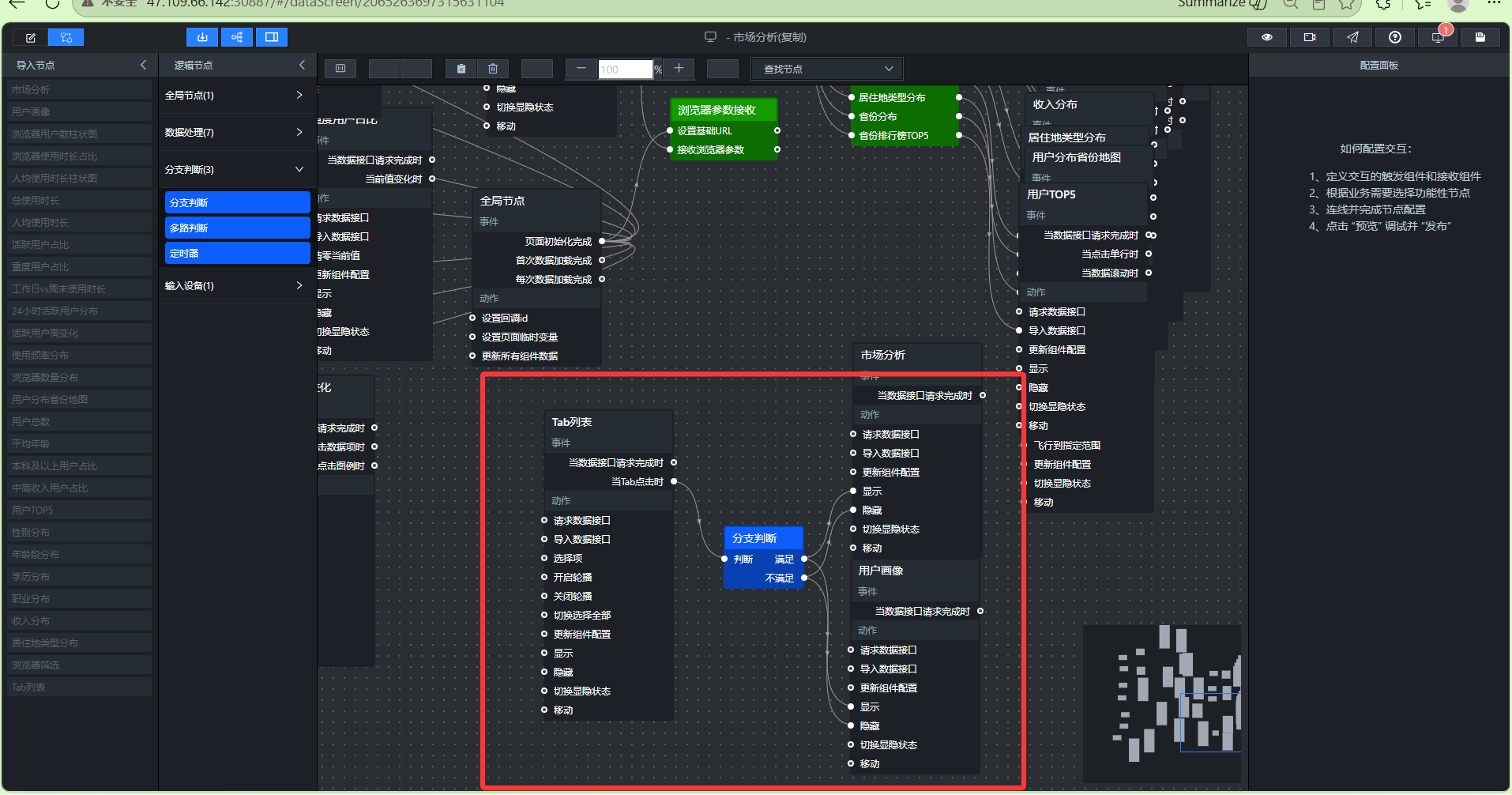
- 配置地图省份点击联动
事件驱动:地图组件的“点击区域时”事件是起点,它会输出被点击区域的地理信息(如省份名称),前提是需要开启组件的交互事件。

变量传递:通过 window.globalProvinceName 全局变量,可以将省份名称在不同节点间共享,避免重复连线。
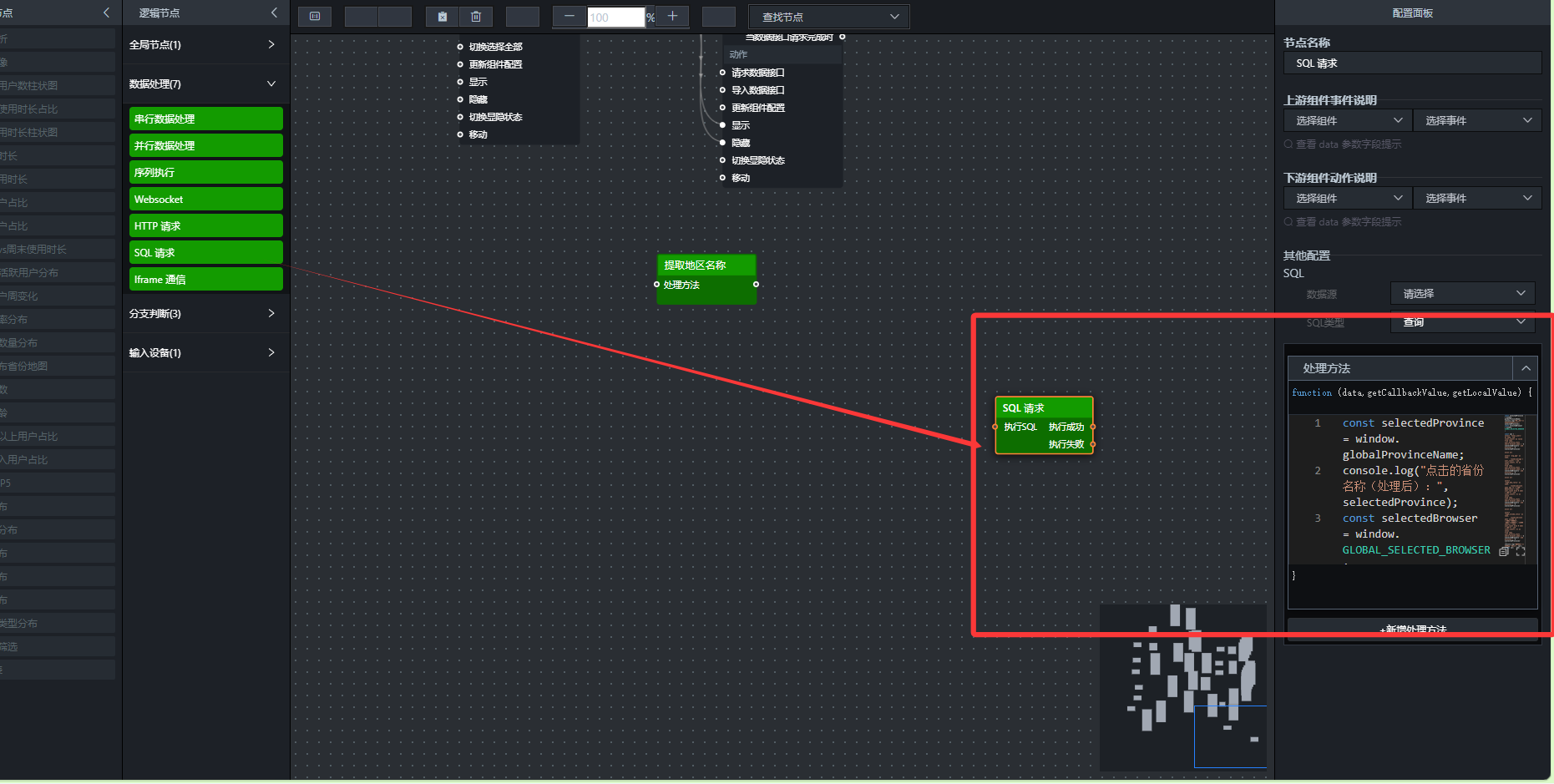
动态SQL:SQL请求节点可以接收外部变量,实现“根据用户点击的省份查询不同数据”。
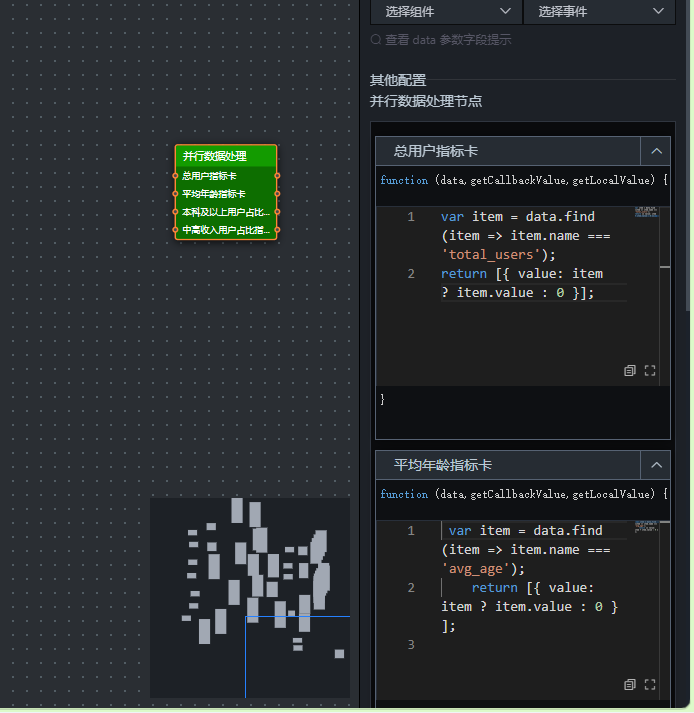
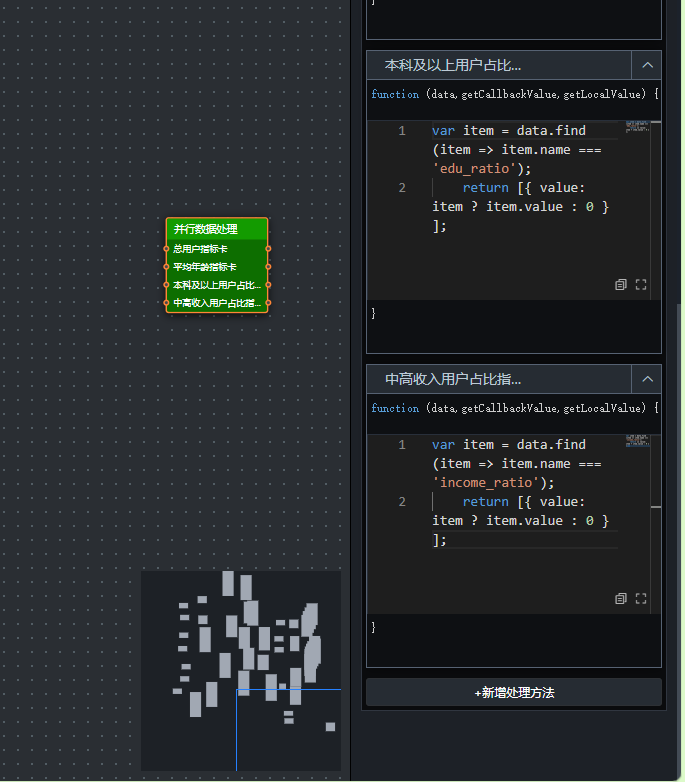
并行数据处理:将一次查询返回的多行数据(每个指标一行)拆分、过滤,分别发送给不同的目标组件。
核心组件配置
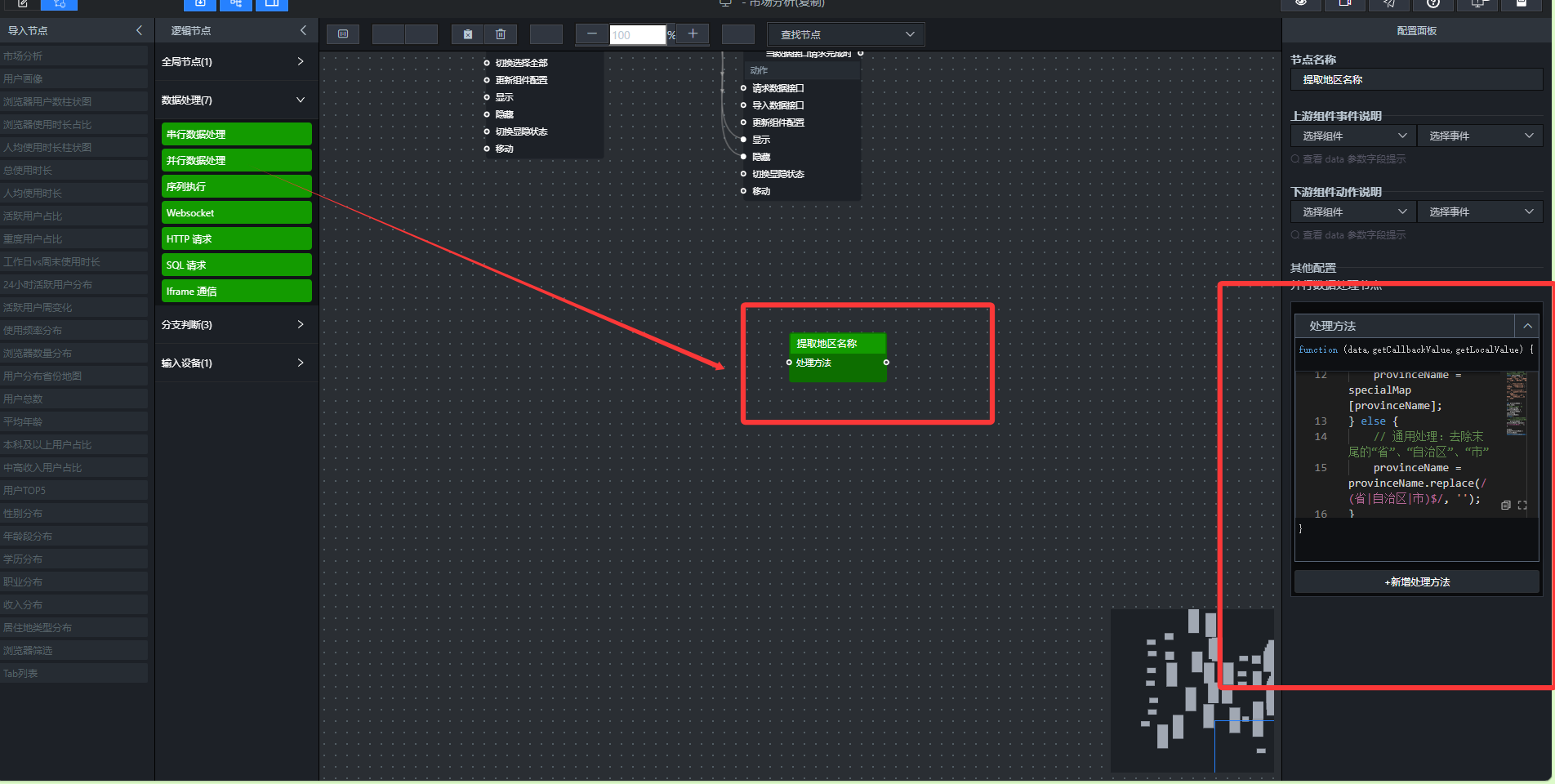
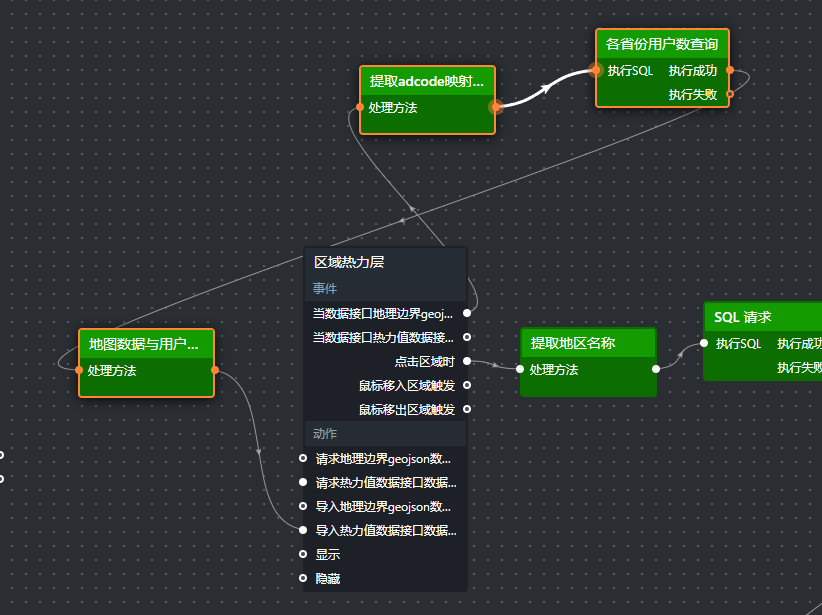
(1)提取地区名称(并行数据处理)
- 省份核心指标查询(SQL请求节点)
- 省份核心指标分发(并行数据处理)
.蓝图连线与数据流
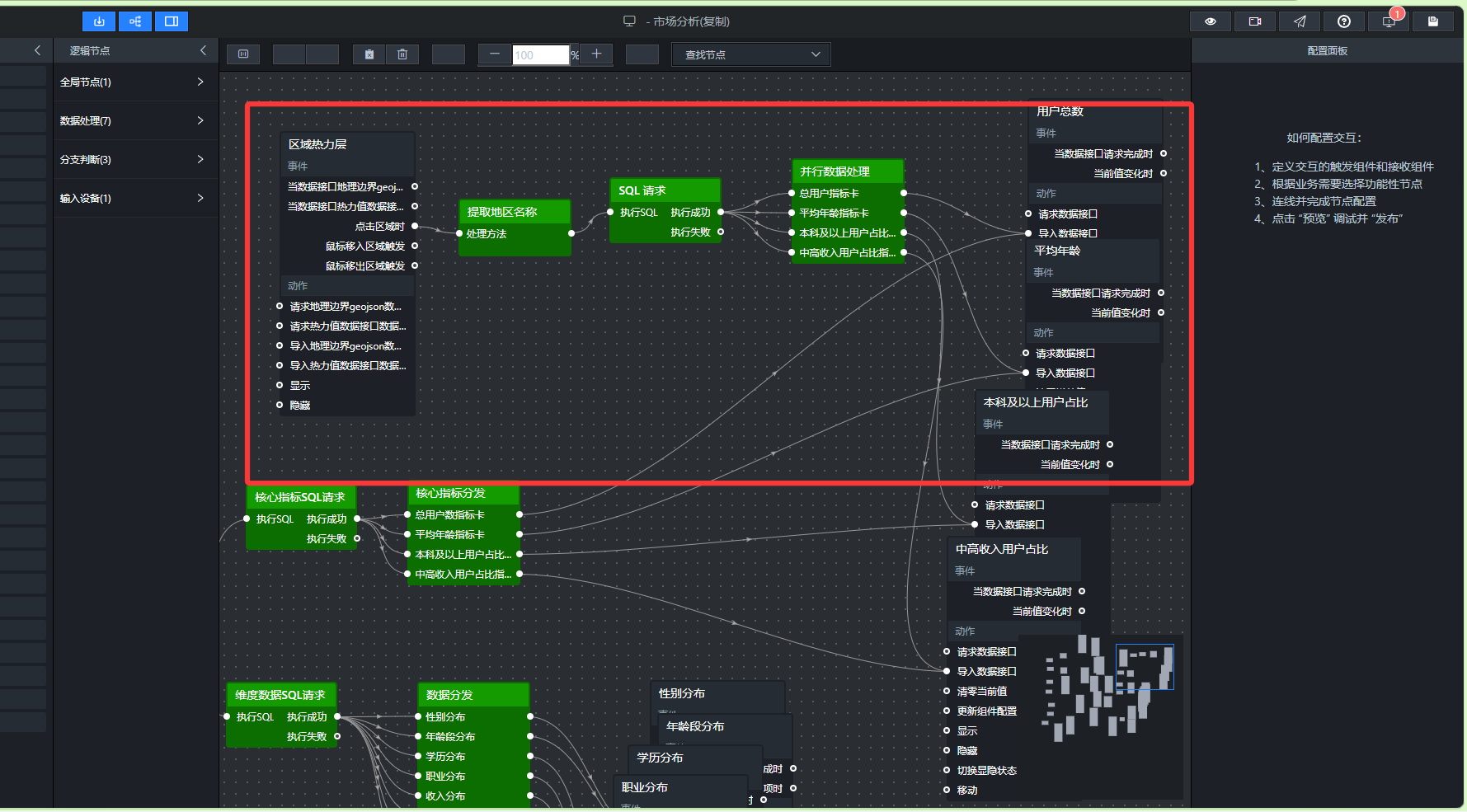
- 地图热力层根据用户数渲染颜色
要完成以下步骤:
提取地理数据中的 adcode 和 name:地图组件内部包含全国各省份的 GeoJSON 边界数据,其中包含 adcode(行政区划代码)和标准名称。我们需要提取并建立一个“省份名称 → adcode”的映射表,存储在全局变量中。
查询所有省份的用户数:根据当前选中的浏览器,从 user_profile_stats 表中统计每个省份的用户总数。
数据映射与格式化:将查询结果中的省份名称与 adcode 映射表匹配,输出格式 { name, value, area_id }。
导入热力值数据:将格式化后的数据导入地图的“区域热力层”子组件,即可自动渲染颜色深浅。
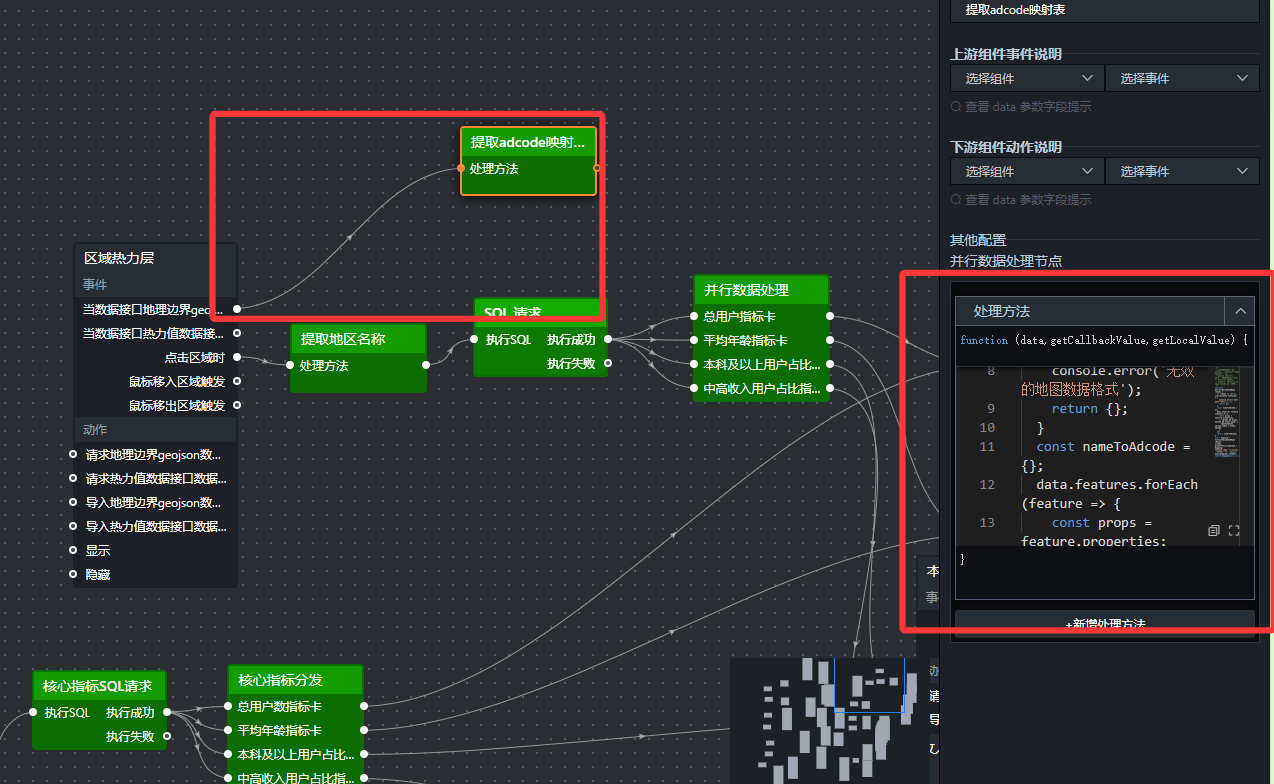
核心组件配置
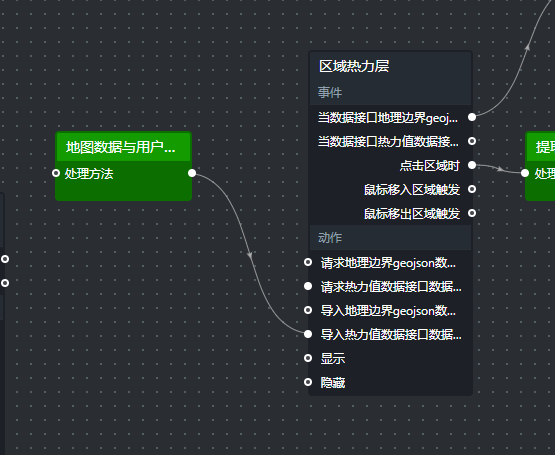
(1)提取 adcode 映射表(并行数据处理)
在蓝图中添加“并行数据处理”节点,命名为“提取adcode映射表”。
将区域热力层的“当数据接口地理边界geojson数据加载完成时”事件连接到该节点(确保地图数据加载后执行)。
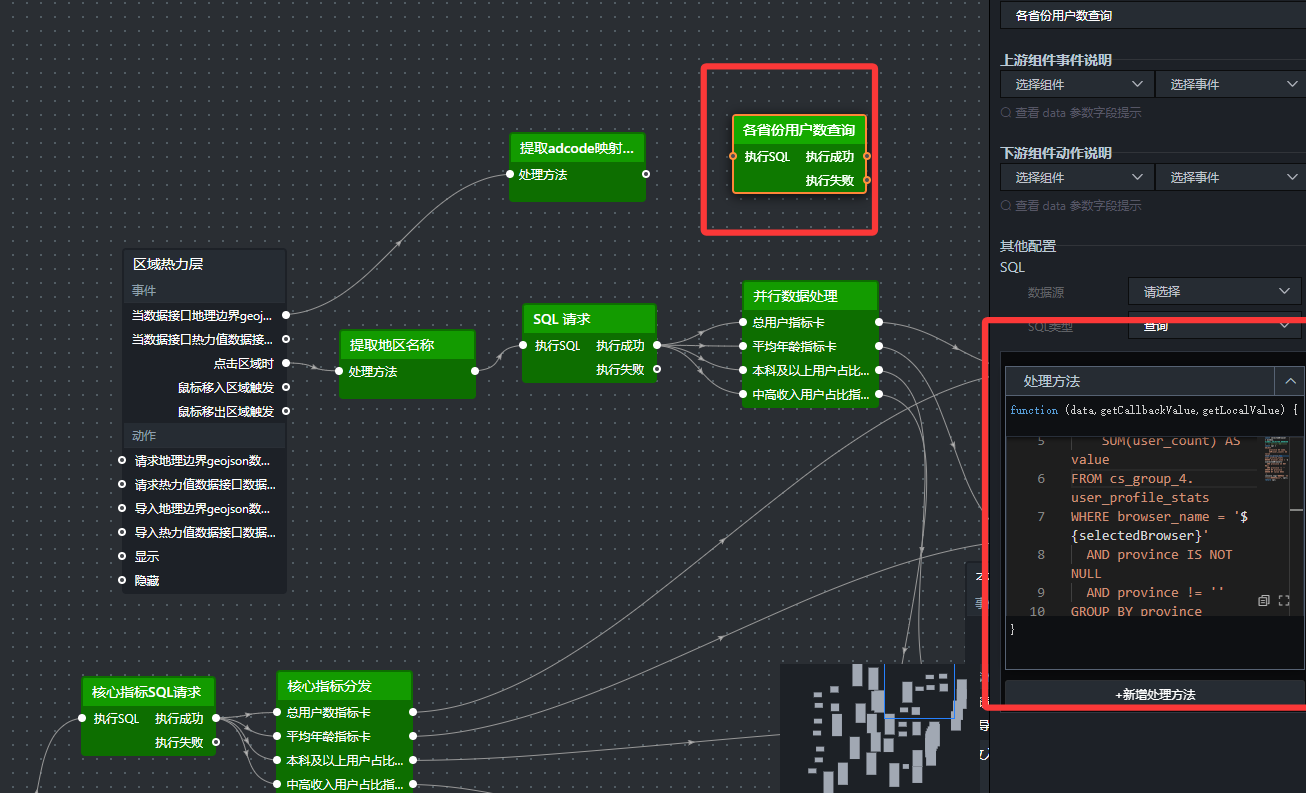
- 查询所有省份的用户数(SQL请求节点)
添加“SQL请求”节点,命名为“各省份用户数查询”。
- 地图数据映射(并行数据处理节点)
添加“并行数据处理”节点,重命名为“地图数据与用户数映射”。
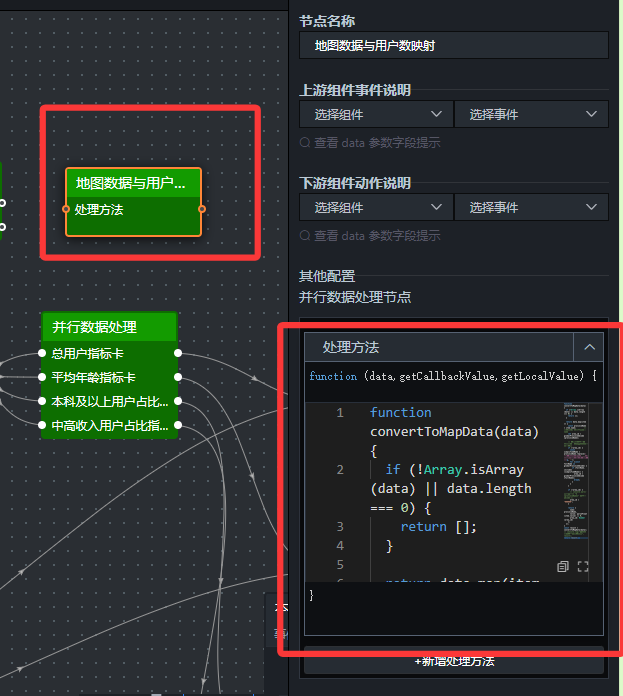
(4)导入地图热力层
将“地图数据与用户数映射”节点的输出端口连接到“区域热力层”的“导入热力值数据接口”。
蓝图连线与数据流
- 预览与发布
完成上述所有配置后,大屏应具备三个核心交互功能:
大屏切换:点击 tab 列表的“市场分析”/“用户画像”,正确显示对应大屏内容。
地图热力层:地图上各省份颜色深浅反映该省份在当前浏览器下的用户数(用户数越多颜色越深)。
省份点击联动:点击地图上的省份,右侧四个核心指标卡自动更新为该省份的数据。
参考图
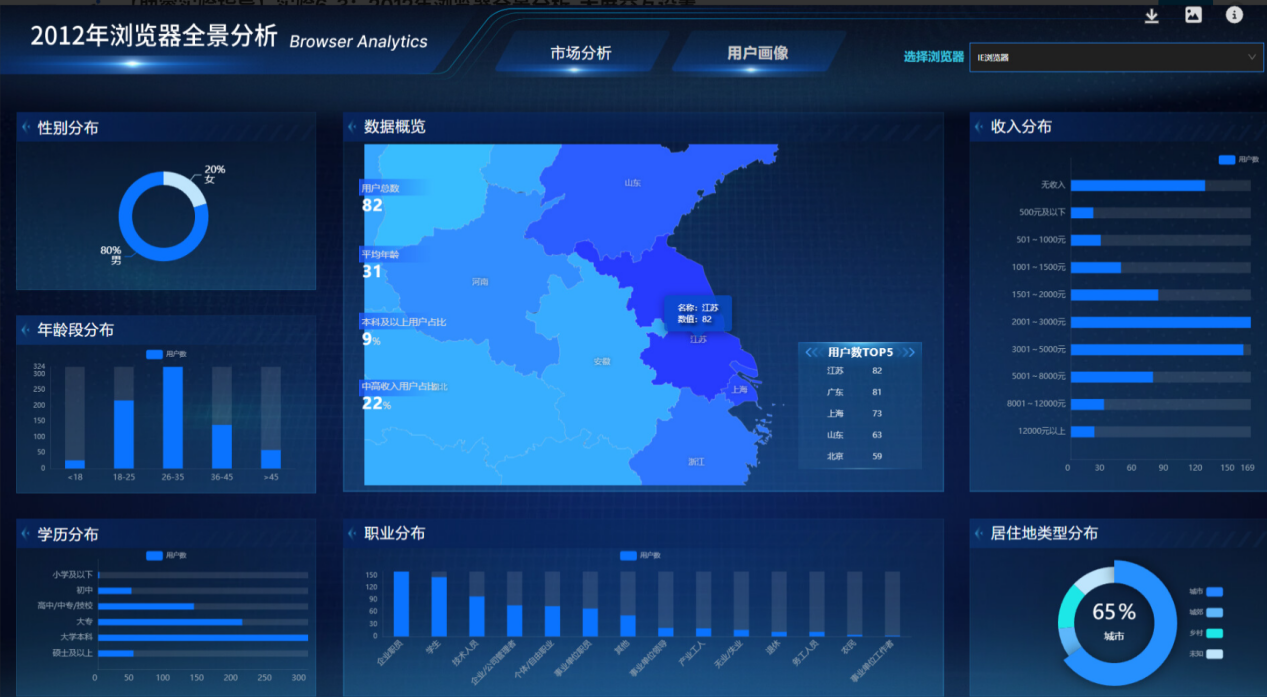
三、实验结果
实验产出:
成功在助睿Max平台上构建了一个功能完整的“浏览器用户画像分析”数据大屏。
结果验证:
布局与视觉:大屏布局清晰,主次分明,符合设计方案。所有图表(地图、饼图、柱状图等)正确展示。
筛选器联动:切换顶部的“浏览器”下拉多选框,所有图表(地图热力、各维度分布图、核心指标卡)的数据均能同步刷新为对应浏览器的数据。
大屏切换:点击顶部导航的“市场分析”和“用户画像”按钮,画面可以在两个不同主题的大屏间无缝切换。
省份下钻:在“用户画像”大屏中,点击地图上的任意省份,右侧的“总用户数”、“平均年龄”、“本科及以上占比”、“中高收入占比”四个核心指标卡会立即更新为该省份的精确数据。
四、问题与解决
问题1:地图热力层颜色无变化
问题现象:配置完热力数据映射并连线后,地图上所有省份颜色一致,未按用户数深浅渲染。
问题原因:导入“区域热力层”的数据格式不正确。经过检查,发现映射后输出的 value 是字符串类型,且 area_id 必须是数字类型。
解决方法:在“地图数据与用户数映射”节点的处理代码中,使用 parseFloat() 将 value 转换为数字,使用 Number() 将 area_id 转换为数字,并确保 area_id 是有效的6位行政区划代码。
问题2:省份点击后指标卡数据未更新
问题现象:点击地图省份,四个核心指标卡数据变为 0 或空白。
问题原因:排查后发现,地图点击事件输出的省份名称是“贵州省”,而数据表中存储的是“贵州”。名称不匹配导致SQL查询无结果。
解决方法:在“提取地区名称”的并行数据处理节点中,增加了完整的省份名称映射逻辑。对直辖市、自治区和特别行政区进行特殊映射(如“北京市”映射为“北京”),对其他省份则使用正则表达式去除“省”、“自治区”、“市”等后缀,确保名称匹配。
五、实验总结
收获:
通过本次实验,我对低代码/零代码平台构建企业级数据大屏的流程有了非常深入的理解。特别是助睿Max的蓝图编辑器,它通过可视化的方式将数据流转、交互逻辑(筛选、下钻、切换)串联起来,极大降低了复杂前端交互的开发门槛。我不仅掌握了如何根据分析目标选择合适的图表,更学会了如何从全局视角设计数据流,通过配置“并行数据处理”节点实现数据的高效分发与复用,这比编写大量代码更加直观和高效。
对平台评价:
助睿数智(Uniplore)平台功能强大,其组件丰富度、图层管理能力以及蓝图编辑器的灵活性足以满足企业级的数据可视化需求。特别是地图组件支持热力层、散点层等多种子图层,配合蓝图的事件驱动机制,能轻松实现像“省份下钻”这样的高级分析功能。整个实验过程文档详尽,平台响应迅速,是一款非常适合教学和实际生产使用的数据科学工具。
#助睿数智#商业数据分析

一站式 AI 云服务平台
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)