
数据结构 —— KMP算法详解(配图解)
目录
一、 为什么朴素算法效率慢?——“遗忘”带来的代价
朴素匹配算法之所以在最坏情况下的时间复杂度高达 O(n×m)O(n×m) 。最主要的原因就是它完全丢弃了已经匹配过的信息。
1. “回溯”机制导致的重复劳动
在朴素算法中,当主串的第 i 个字符与模式串的第 j 个字符失配时,算法会做两件事:
1.主串指针回退:回到上一次开始匹配位置的下一个字符(即 i−j+1i−j+1 )。
2.模式串指针重置:回到起点(即 00 )。
问题的所在: 主串指针的回退意味着我们重新扫描了那些已经被验证过的字符。在很多场景下(特别是模式串包含大量重复前缀时),这些被回退扫描的区域根本不可能产生新的匹配,但朴素算法依然机械地进行了比较。
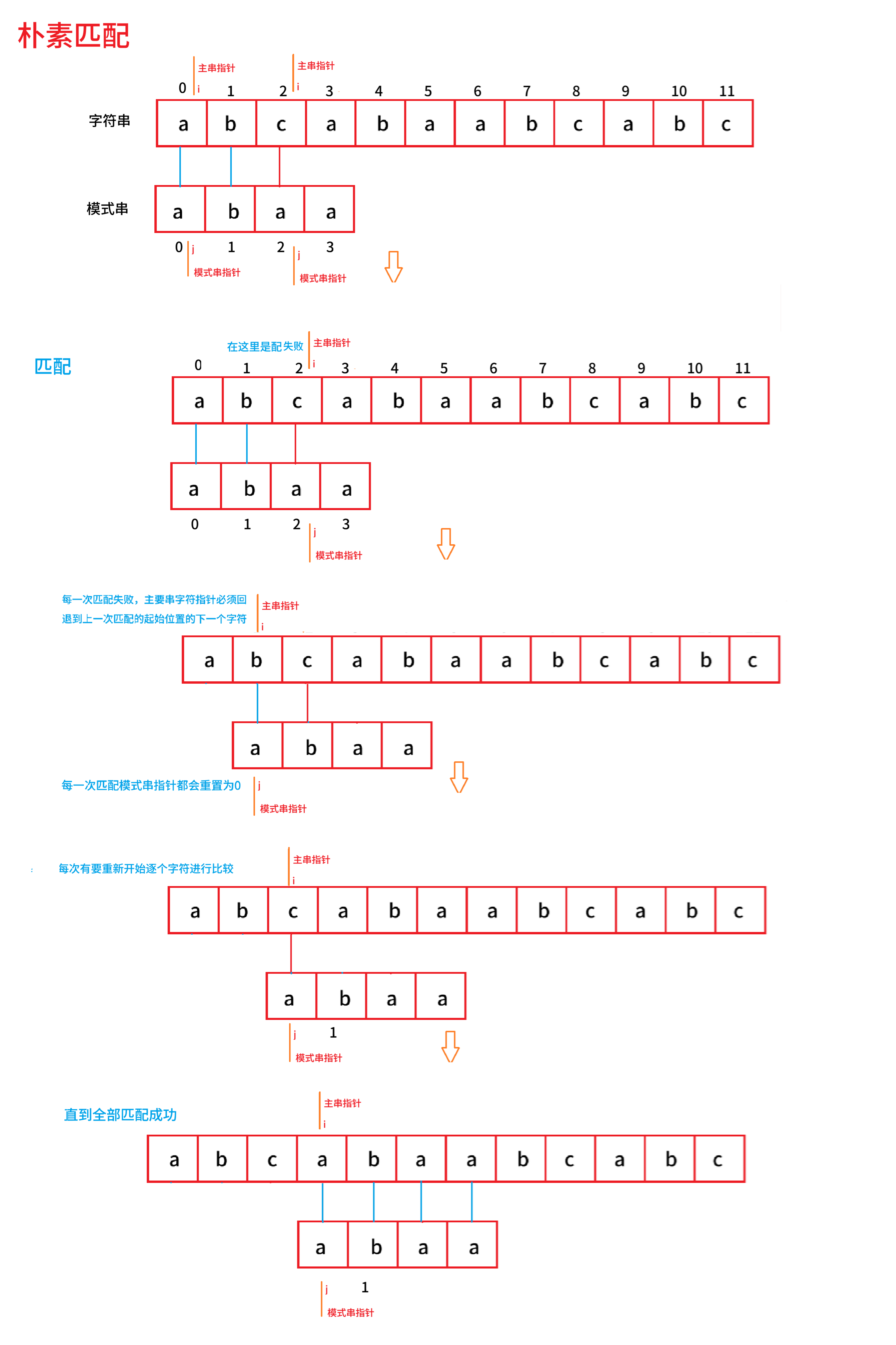
2.图解和代码演示
下面的图解是简单的字符匹配,图解后面给出了在“极端情况”进行匹配出现的一些问题.
朴素算法代码实现
int strMatch(char* str, char* pattern)
{
//获取字符串长度
int m = strlen(str);
int n = strlen(pattern);
//主要串指针
int i = 0;
for (i = 0; i <= m - n; i++)
{
//模串指针
int j = 0;
while (j < n)
{
//只有相等时i和j才++
if (str[i] == pattern[j])
{
i++;
j++;
}
else
{
i = i - j;
break;
}
}
//这里说明匹配成功了,范围下标的位置.
if (j == n)
{
return i - j;
}
}
return -1;
}3.极端案例演示
如果是图片中的字符串显然是可以匹配成功,但假设主串 S="AAAAAA...B" 摸串 P="AAAAB" 呢?
- 第一次匹配:前4个 'A' 都匹配,第5个字符 'B' vs 'A' 失败。朴素算法回退主串指针。
- 第二次匹配:从主串第2个 'A' 开始,又匹配了3个 'A',再次失败。
- ...
- 每一次失配,主串指针都要回头走很远,导致大量的无效比较。这就是所谓的 “由于缺乏记忆而导致的指数级爆炸”。
- 显然这种算法是非常低效的。所以就有了三位大哥发明了KMP算法,这个算法就可以很好的去解决这个问题。
二、 KMP算法如何高效解决问题?——“记忆”与“滑动”
KMP算法的核心是:主串指针绝不回头。为了实现这一点,它必须解决一个问题:“当失配发生时,主串不动,那么模式串要何去何从呢?”
1. 挖掘模式串的“自相似性”
KMP发现,失配点之前的子串往往蕴含着规律。如果模式串的前缀和后缀有重叠部分(例如 "ABCDAB" 中,前缀 "AB" 和后缀 "AB" 相同),那么当后缀部分匹配成功但随后失配时,我们可以直接把前缀“滑”到后缀的位置继续比对。
这种“最长相等前后缀”的信息,就是KMP的记忆。
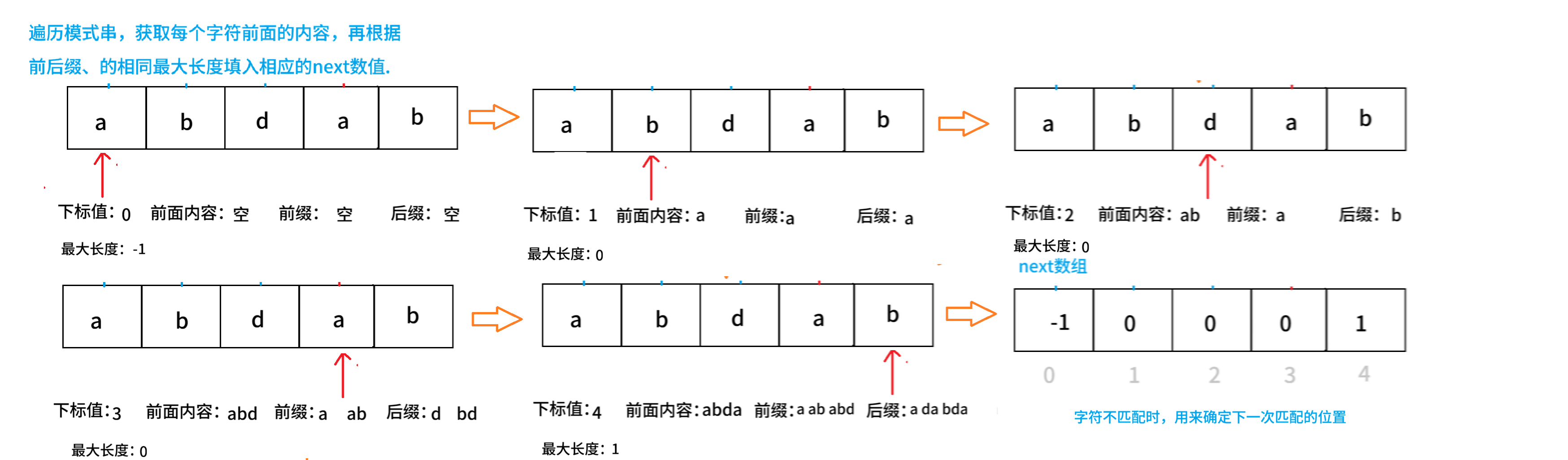
2. Next数组的创建
next数组的创建:基于模式串进行创建的next数组
用途:利用next数组来完成字符串的匹配。当失配时,用来确定下一次所要匹配的位置。
例如:模式串 S = “abdab”。创建方法图所示:
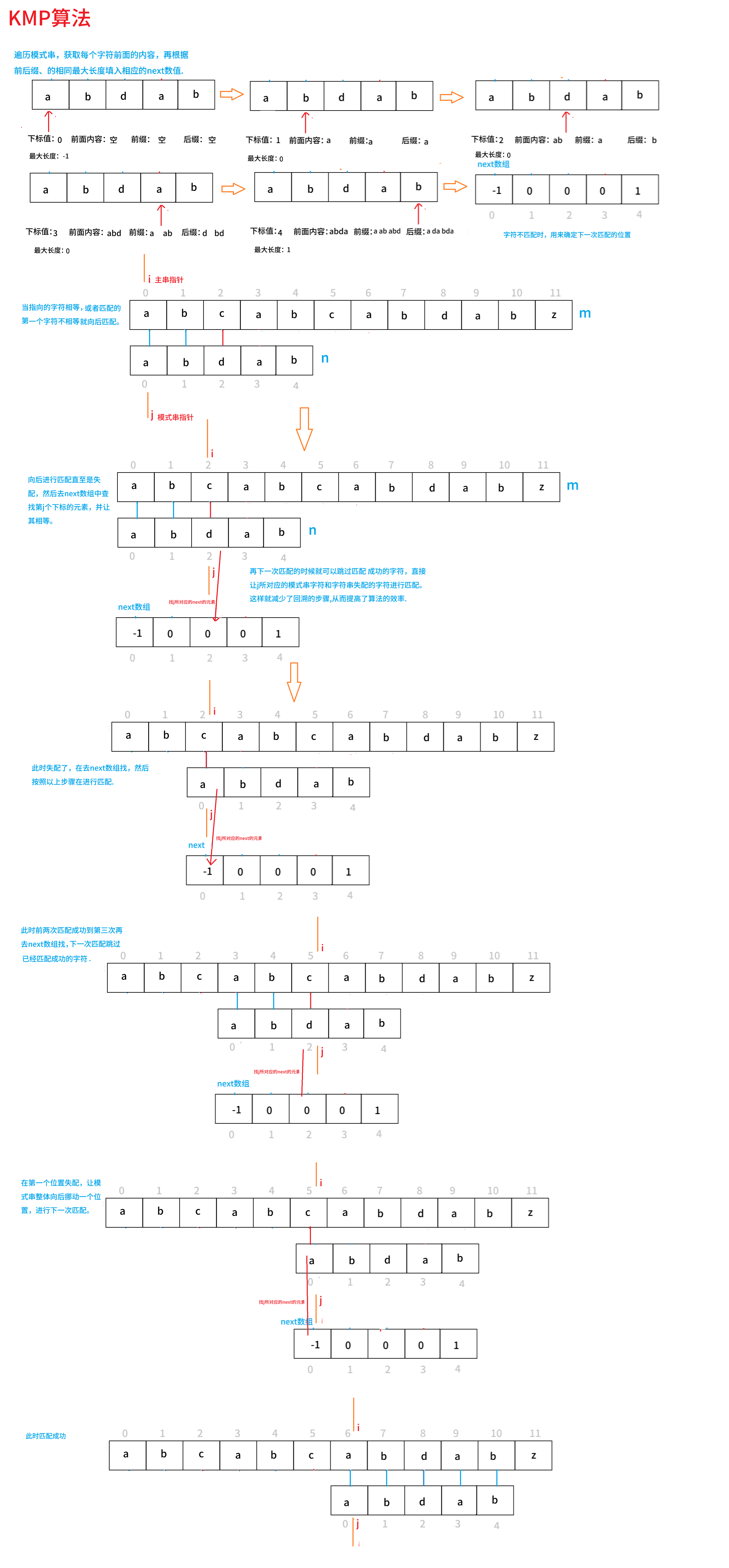
3.KMP具体优化的过程和代码(图解)
KMP算法代码实现
//kmp算法实现
//查找在文本中是否出现过此字符串,返回早出现的位置。
void getNext(char* pattern, int* next)
{
//获取模式串
int m = strlen(pattern);
int i = 0;//后缀指针(当前正在计算的字符位置)
int j = -1;//前缀指针(当前最长相等前后缀的长度索引)
next[0] = -1;//初始化:第一个字符没有前缀
while (i < m)
{
//情况1:j回退到了起点,或者当前字符匹配成功
if (j == -1 || pattern[i] == pattern[j])
{
i++;
j++;
next[i] = j;//记录当前位置的最长匹配长度
}
//情况2:字符不匹配,利用已有的 next 数组进行"回退"
else
{
j = next[j];
}
}
}
int kmp(char* str, char* pattern)
{
//获取字符串个数
int n = strlen(str);
int m = strlen(pattern);
//动态内从开辟 next 数组空间
int* next = (int*)malloc((m + 1) * sizeof(int));
if (next == NULL)
{
perror("kmp:next");
return 0;
}
//计算模式串的 next 数组
getNext(pattern, next);
//主串指针
int i = 0;
//模式串指针
int j = 0;
//开始匹配循环
while (i < n && j < m)
{
//情况1:j == -1模式串第一个字符就匹配失败,或者当前字符匹配成功
if (j == -1 || str[i] == pattern[j])
{
i++;//主串指针后移
j++;//模式串指针后移
}
//情况2:当前字符失配
else
{
//模式串指针后退,主串指针 i 不动
j = next[j];
}
}
//匹配成功
if (j == m)
{
//返回起始下标.
return i - j;
}
//匹配失败
else
{
return -1;
}
//释放空间
free(next);
next = NULL;
}4.KMP算法解决极端案例
如果回到上面的极端案例效率是否会提高呢?极端案例:主串 S="AAAAAA...B",摸串P="AAAAB"
朴素算法:失配后,主串指针回退,模式串归零。
KMP算法:
- 当在第5位失配时,KMP查看 next 数组。
- 发现前4个字符 "AAAA" 的最长相等前后缀长度是 3(即 "AAA")。
- 动作:主串指针不动!模式串指针直接跳到索引 3 的位置(也就是第4个 'A')。
- 结果:直接利用已知的 "AAA" 重叠部分,跳过了中间无意义的比较步骤。
5. 复杂度质变的主要原因
主串单向扫描:主串指针 i 在整个过程中只增不减,最多移动 n 次。
模式串的高效跳跃:虽然模式串指针 j 会回退,但它是根据 next 数组进行“大幅度跳跃”,而不是盲目归零。数学上可以证明,模式串指针回退的总次数也是线性的。
结论:两者相加,总操作次数被严格控制在 O(n+m)O(n+m) 级别。
三、算法的差异总结
| 特性 | 朴素算法 (BF) | KMP算法 |
|---|---|---|
| 对待历史的态度 | 健忘:一旦失配,抛弃所有已匹配信息,从头再来。 | 铭记:利用已匹配部分的内部结构(前后缀),保留有效信息。 |
| 指针行为 | 双指针回溯(主串回退,模式串重置)。 | 单指针前进(主串不回退,模式串智能滑动)。 |
| 核心瓶颈 | 在重复字符多的文本中,存在大量冗余比较。 | 消除了所有冗余比较,每个字符至多被有效比较常数次。 |
| 本质区别 | 暴力穷举搜索。 | 基于状态机的确定性转移。 |

一站式 AI 云服务平台
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)